面向异构体系结构的GA模型拓展
2017-11-07卢宇彤王晨旭
程 鹏 卢宇彤 高 涛 王晨旭
(高性能计算国家重点实验室(国防科学技术大学) 长沙 410073)
(国防科学技术大学计算机学院 长沙 410073)
(peng_cheng_13@163.com)
随着科学与工程应用对计算性能要求的不断增加,基于CPU的同构系统已经不能满足计算需求.而图形处理单元(GPU)、英特尔至强融核(many integrated core, MIC)或其他加速单元在处理高度并行性负载的情况下可以提供远强于CPU的浮点计算能力,因此使用GPU或MIC等加速单元作为协处理器负责数据密集型负载的异构计算得到了迅速发展[1-5].在2015年6月的TOP500排名中,共有88台超级计算机为异构系统,使用英特尔Xeon Phi(MIC)协处理器的超级计算机共有33台,其中也包括排名第一的天河二号[6].近年来,为了简化异构编程难度,CUDA[7],OpenCL[8]等编程模型也得到了广泛应用.由于MIC结构是基于现有的X86架构进行设计,采用与CPU相同的X86指令集,支持OpenMP[9],TBB[10]等现有并行编程模型,因此CPU+MIC的异构编程难度小于CPU+GPU的异构编程难度.尽管如此,使用MIC高效进行异构计算还存在2个难点:1)由于CPU与MIC之间没有共享内存空间,程序员必须区分数据的本地或远程访问,并显式地指定数据在CPU和MIC之间的传递情况;2)传统的加载模式,如英特尔的语言拓展加载模式(LEO)受限于在单个计算节点之内实现,并且无法在MIC之间直接进行传输数据.
分块全局地址空间(PGAS)模型适用于分布式存储系统,通过提供逻辑上共享的寻址空间和允许所有处理单元访问位于共享内存空间的数据,简化数据管理和进程间通信.常见的PGAS模型包括UPC,CAF(co-array Fortran),Titanium[11]和全局数组(global arrays, GA).GA模型[12]基于聚合远程内存拷贝接口(ARMCI)为分布式存储系统提供异步单边通信、共享内存的编程环境,通过允许编程人员创建一个分布在多个计算节点之间的全局共享数组,并对共享数组的直接访问隐藏数据在不同内存空间的传输细节.GA近年来应用广泛,相比于UPC和CAF,GA允许编程人员显式控制数据局部性,且GA基于库实现而不依赖编译器,具有很好的可移植性.因此,结合异构系统特点实现GA模型可以为CPU与加速单元之间提供逻辑上共享的数据结构,从而隐藏数据在CPU和MIC之间的传输细节,达到简化编程并优化数据传输的目的.然而,ARMCI通信接口是GA模型实现的关键,也关系到GA模型的可移植性,即在新的系统中使用GA模型前必须结合该平台特点实现ARMCI接口.而此时尚未有AMRCI针对CPU+MIC异构系统的实现,因此通过标准GA模型简化异构编程难度并优化数据传输的目标难以实现.
为了在CPU+MIC的异构系统中高效实现GA模型,我们在本文中提出了CoGA,并基于MIC上的对称传输接口(symmetric communication interface, SCIF)[13]实现对GA模型的异构拓展.CoGA通过为CPU与MIC之间提供逻辑上共享的全局数组,隐藏数据在CPU与MIC之间的传输细节.通过CoGA,编程人员可以像访问本地数组一样去访问全局数组而不必关心数据的具体存储位置.此外,我们还结合SCIF接口的特点,对CPU与MIC间的数据传输进行优化,针对小数据通信特点提供低延迟的通信接口,并允许节点内MIC之间直接进行数据传递,而不必像offload模式那样先将数据传送回CPU,再由CPU传递至另一个MIC.本文的主要贡献有3点:
1) 结合GA模型特点,针对CPU+MIC异构系统设计并实现了CoGA库,简化了异构编程难度;
2) 分析MIC协处理器特点,逻辑上拓展了MIC内存,并结合SCIF接口优化数据传输性能;
3) 通过数据传输带宽、消息传递延迟和稀疏矩阵乘问题评估CoGA性能并证明其有效性和实用性.
1 背景及动机
1.1 MIC协处理器和SCIF接口
英特尔MIC结构基于X86架构,支持包括OpenMP和MPI在内的多种并行模型,采用C,C++,Fortran等语言进行软件移植开发,特点以编程简单(引语方式)著称,工具链丰富.MIC卡含有57~61个核,每个核可以支持4个线程,浮点运算性能超过1TFLOPS,含有512 b的向量宽度,支持8个双通道GDDR内存控制器,内存大小为6 GB或8 GB[14].由于MIC既可以作为CPU的协处理器也可以单独作为处理节点,因此MIC与CPU的协同方式非常灵活.常用协同方式包括:加载模式、原生模式和对等模式.在加载模式下,CPU作为主机端并将数据密集型任务加载到MIC上运行;在原生模式下,MIC作为一个独立的计算节点,程序只在MIC上单独运行;在对等模式下,MIC设备可以看作与CPU对等的计算节点.在异构计算中,加载(offload)模式是最常用的模式,MIC设备的启动、关闭和数据传输操作都通过编译指导命令动态实现.
SCIF作为一种简单高效的对称传输接口,允许数据从MIC设备通过PCIE总线与CPU进行数据传输.SCIF应用程序接口提供了2种类型的数据传输操作:点对点的发送-接收操作和远程内存访问(RMA)操作.发送-接收语义支持阻塞和非阻塞传输,一端作为源而另一端作为目的地;RMA操作则支持单边通信,当知道本地和远程数据地址的时候,数据就可以被传输.2个端点之间成功的数据通信必须通过注册地址空间,即本地进程注册其部分地址空间作为远端进程访问的窗口,并建立该段地址空间与物理内存的映射关系.
Sreeram等人[15]在其近期工作中通过共享内存,IB verbs和SCIF接口设计了含有MIC的异构节点内的高效数据传输方式.Nishkam等人[16]在其近期工作中提出了一组新的指令,以更为宽松的语义添加到原有的指令基础语言中,从而允许使用者在源代码中建议而不是指定加载区域.然而,由于CPU与MIC之间没有共享内存空间,程序员必须区分数据的本地或远程访问,并显式地指定数据在CPU和MIC之间的传递情况.此外,如图1所示,现有的offload模式中,由于MIC设备之间没有建立直接连接,因此数据在MIC设备之间的传输较为复杂,数据必须经CPU中转才能加载到另一块MIC上.
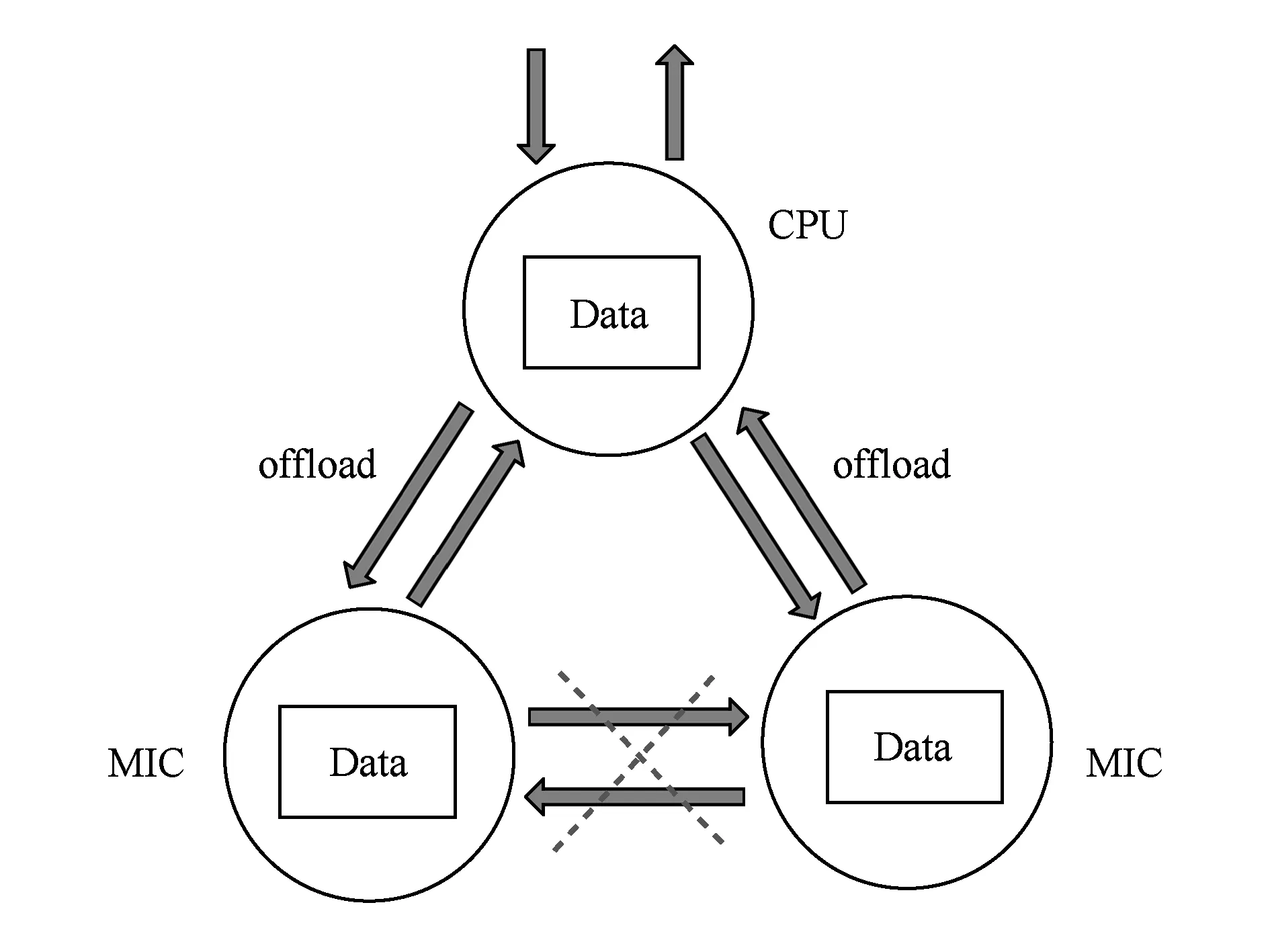
Fig. 1 Data transmission in offload mode图1 offload数据传输方式
1.2 GA模型
GA模型是一种PGAS语言,可以为分布式存储系统提供异步单边通信、共享内存的编程环境,同时优化整体性能,减少处理器之间显式的通信开销.传统的GA模型通过聚合远程内存拷贝接口(ARMCI)实现put和get单边通信,最新版本的GA模型(GA-5-4b)增加了对拓展性通信库ComEx的兼容性,允许GA通过MPI双边通信语义(即MPI_Send和MPI_Recv)实现单边通信协议,并将默认通信模式由socket改为MPI双边通信,从而允许GA模型在任何支持MPI编程模型的平台上实现[17].
近期的使用C++库拓展并行编程模型研究包括UPC++[18],Coarrays C++[19-20]和Charm++[21]等.Manojkumar等人[22]提出了在Blue GeneP超级计算机上通过IBM DCMF(deep computing messaging framework)框架实现GA模型.其中,ARMCI put和get操作通过DCMF应用接口实现并表现出比原本的GA和MPI接口更好的性能.Daniel等人[23]则基于PGAS动态消息传递范例提出了global futures,增加可拓展性的同时保持与GA和MPI兼容,通过一系列API允许用户定义的计算任务(futures)在拥有GA数据分块的位置远程执行.James等人[24]则通过协调MPI RMA和PGAS模型语义,通过MPI单边通信实现GA模型.
然而,现有的offload模式下,编程人员必须区分数据是本地或远程访问,并显式地指定数据在CPU和MIC之间的传递情况,而且同一节点内MIC之间无法直接进行通信.此外,迄今为止还未出现在异构系统中使用GA模型简化CPU和MIC之间显式的数据传输的方案,现有的GA模型也没有针对MIC结构的高效实现.而若GA模型在CPU+MIC异构系统中通过MPI双边通信网络模式进行数据传输必然导致性能低下.
2 CoGA拓展
为了能够在CPU+MIC的异构系统中实现GA模型并保证数据传输性能,我们提出CoGA,基于SCIF接口在CPU与MIC之间高效实现GA模型,通过提供逻辑上共享数组隐藏数据传输细节,简化异构编程难度.本节简要介绍CoGA的拓展方式及API接口.
图2对比了GA与CoGA的软件层次结构.原本的GA模型使用Fortran或C语言等应用接口实现对分布式共享数组的管理,通过ARMCI或ComEx动态库内部的网络通信接口,如MPI双边通信接口,调用网络驱动及操作系统库实现内存管理和数据传输等操作;而CoGA则通过SCIF接口直接调用网络驱动及操作系统库,更高效地实现对CPU和MIC的内存管理及CPU与MIC间的数据传输.
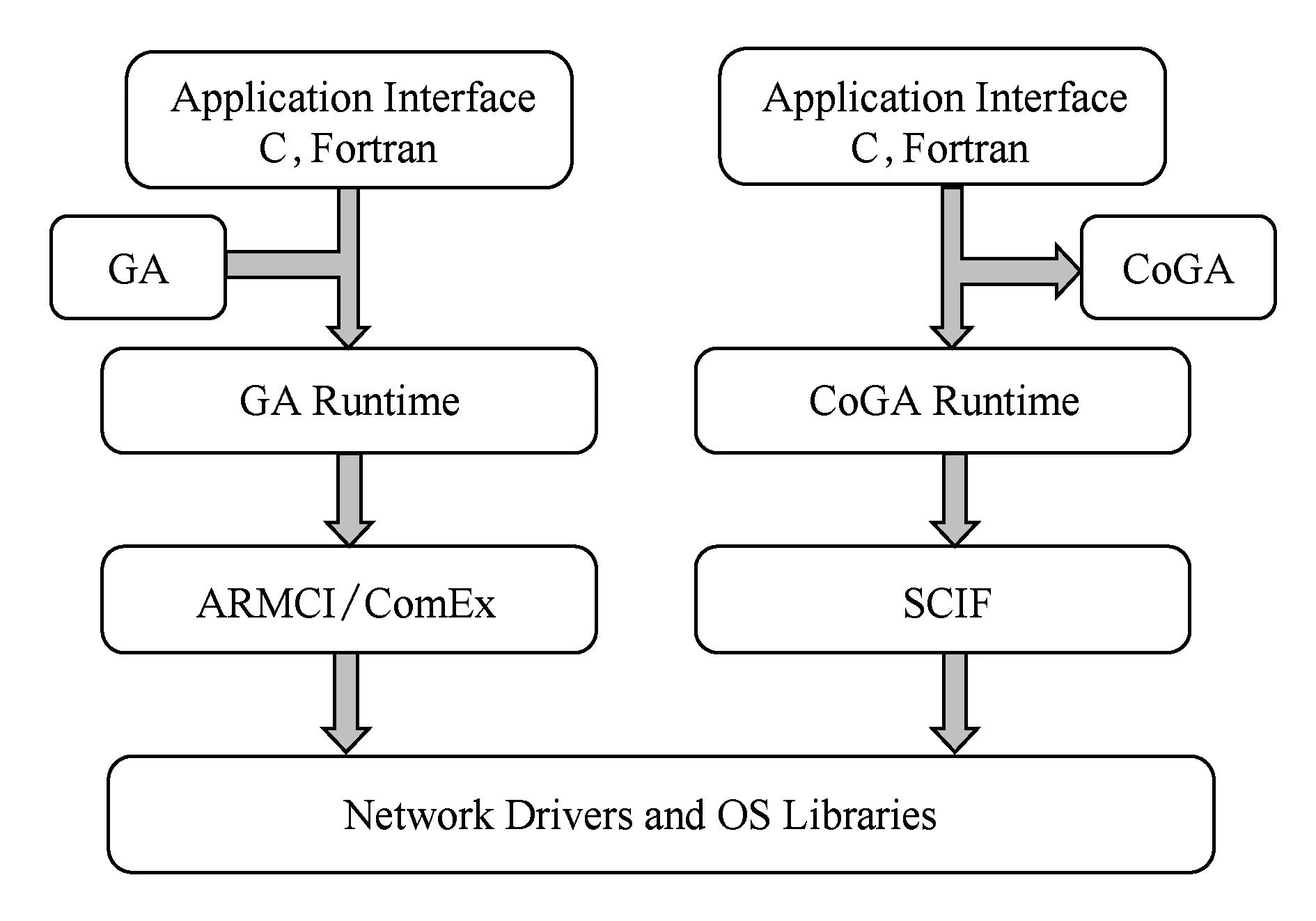
Fig. 2 Comparison between GA and CoGA图2 GA和CoGA软件层对比
表1总结了CoGA现有的API接口.其主要分为2大类,coGA_Initialize等接口是基于原本的GA接口进行的拓展,实现了CoGA库的初始化和终止、全局数组的创建与销毁、put和get单边通信等操作,这些接口在实现原有功能的同时还结合MIC结构与SCIF传输特点进行了优化;coGA_Reg等接口则是为了简化数组操作并优化数据传输所拓展的新接口,包括小数据的发送与接收、快速获取本地缓存指针等操作.通过这些接口,编程人员可以在异构系统中高效使用CoGA模型实现内存管理和数据传输,达到简化编程而不影响性能的目的.

Table 1 Summary of GA and CoGA Function Call表1 GA与CoGA接口对比
3 内存管理
本节对原有GA模型内存管理方式进行简要分析,并针对CPU+MIC的异构系统提出CoGA模型的内存管理方式.
GA模型通过不同的函数调用实现全局数组对象在对称多处理节点上的规则和不规则分布,动态分配大部分内存空间用于存储新创建的全局数组数据或者作为其他操作的临时缓存,并在程序运行结束后释放.在提供共享内存的系统上,内存空间由ARMCI动态库管理,其首先从操作系统中划分大段共享内存空间,之后再根据GA操作分配或释放内存.在程序终止之前,ARMCI库所管理的大段内存空间不会被释放.
然而,由于MIC设备的时钟频率低于CPU,分配同样大小的内存空间时,MIC上的内存分配开销比CPU的内存分配开销更大.为了减少内存分配次数进而降低整体开销,CoGA通过函数coGA_Create为全局数组分配固定内存空间,一旦全局数组创建,该数组就可以被用于存储不同数据直至数组被销毁.
函数coGA_Create的语义与其他标准内存分配调用的语义类似,参与计算的每个进程都必须执行该函数,并根据参数分配相应的内存空间.参数type表示全局数组的数据类型,如整型、浮点型等;参数size表示全局数组的整体长度;参数dis[n]则表示数据的分布情况.编程人员可以通过dis[n]参数直观地控制数据如何分布在CPU和MIC上.图3说明了函数coGA_Create对内存的分配和注册.CPU端和MIC端都执行该函数,并为全局数组分布本地内存空间.CPU的进程号为0,CPU所分配的内存大小为dis[0]-0;MIC的进程号为1,则MIC上分配的内存大小为dis[1]-dis[0].全局数组的总大小为dis[1]-0.在异构系统上创建全局数组后,为便于CoGA接口通过SCIF接口实现远程内存访问,函数coGA_Create内部调用接口scif_register将各进程所分配的全局数组本地内存空间注册为远程访问地址空间,并建立注册地址空间与物理页面的固定映射关系,从而允许远端进程直接对该部分地址空间进行读写操作.
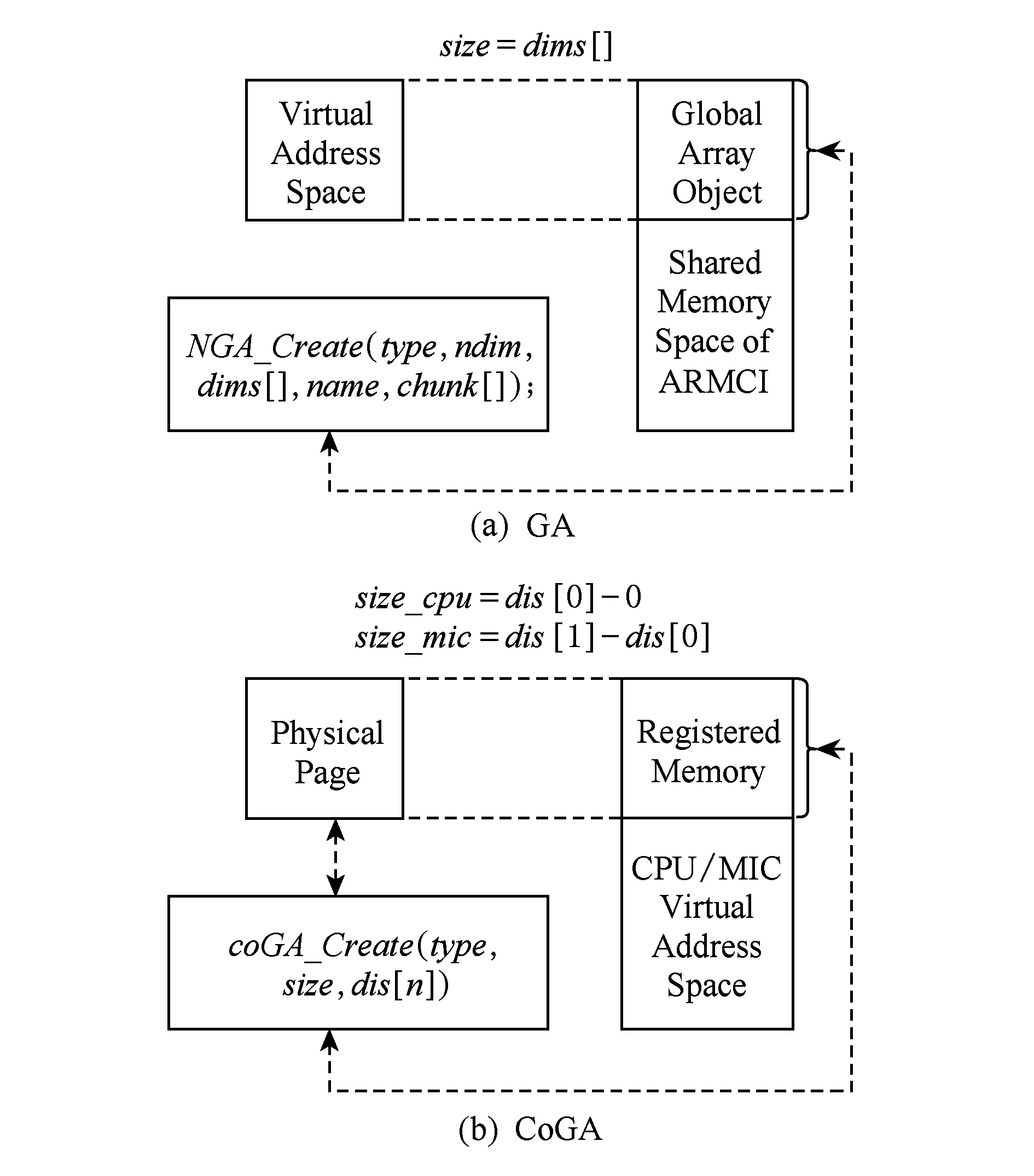
Fig. 3 Memory allocation of GA and CoGA图3 GA和CoGA内存分配对比
4 远程通信设计与实现
4.1 CPU与MIC连接
为了保证CoGA库一旦初始化就可以实现对CPU和MIC的内存管理并进行远端通信,我们使用函数coGA_Initialize负责初始化CoGA库并通过SCIF接口建立CPU与MIC的连接:CPU和MIC各自创建新的端口并将地址绑到其本地节点;CPU端的端口作为监听端接收MIC端所发送的连接请求,请求响应后CPU与MIC可成功建立连接.在SCIF实现中,每个建立连接的端口称为端点,每个计算节点可与多个不同节点建立多个连接,而且每个连接都通过其各自的端点完成,即一个节点上可以拥有多个端点,各个端点负责与其连接的对应端点间通信.
4.2 远程内存访问
CoGA的核心思想是隐藏数据传输细节的同时为CPU和MIC提供对等的API接口.图4说明了CoGA模型的数据传输方式.MIC设备在CoGA库初始化时通过SCIF接口直接建立连接,进而允许用户调用CoGA函数实现数据在MIC间的直接传输.
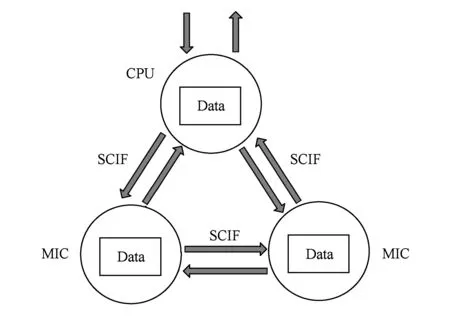
Fig. 4 Data transmission in CoGA图4 CoGA数据传输
CoGA的put和get操作包含完成单边通信的参数,如全局数组的句柄、数据的上下边界及本地数组的指针.在调用put和get操作后,进程首先对数据边界和全局数组分布情况进行对比,再根据数据在远程或本地选择不同传输方式.put和get操作定义2种不同的完成方式:本地传输和远程传输.本地传输是指数据在CPU或MIC内部传递,可通过函数memcpy实现;远端传输则意味着数据在CPU和MIC之间进行传输,可以通过SCIF RMA访问操作实现.SCIF提供2组接口完成RMA访问:scif_readfrom,scif_writeto和scif_vreadfrom,scif_vwriteto.接口scif_readfrom,scif_writeto在本地注册地址空间和远端注册地址空间之间完成数据的读写访问,而接口scif_vreadfrom和scif_vwriteto则将本地用户空间作为参数与远端注册地址空间进行数据传输操作,即数据可以直接从用户虚拟地址发送到远端数组对象而无需对该段虚拟地址进行注册.如果已知本地缓存将被使用多次作为RMA访问的源或者目的地,那么scif_readfrom,scif_writeto可提供更好的传输性能;反之,若本地缓存仅仅是源或一次传输的目的地,那么scif_vreadfrom,scif_vwriteto则能避免注册窗口、数据传输、释放窗口的复杂操作,减少注册开销.
为了保证传输性能的同时不影响简易性,我们同时提供这2种完成方式:在put和get操作中增加flag标志位,flag值默认为-1,若用户未注册本地临时缓存,则put和get操作自动调用scif_vwriteto,scif_vreadfrom在本地虚拟地址和远端注册地址之间完成数据传输;当用户使用函数coGA_Reg提前为本地临时缓存注册地址空间后,返回的flag值即为注册地址空间偏移,put或get操作自动调用scif_writeto或scif_readfrom,在注册地址空间之间进行数据传输.当需要进行远端数据传输时,CoGA函数直接将参数传递给SCIF接口,包括源地址、远端注册地址空间偏移和拷贝数据长度.
此外,CoGA还提供函数coGA_GetLocalBuffer允许进程获取共享数组的本地缓存指针,从而避免冗余的数据拷贝.
4.3 小数据通信优化
考虑到程序运行过程中,CPU和MIC可能需要频繁地进行小数据通信,而且MIC端计算完成后,MIC与MIC或者MIC与CPU之间的小数据通信无法避免.传统的offload模式下,编程人员必须通过编译指导命令来指明传输的数据,而且数据无论大小,传输的数据都是按照4 KB对齐,即使数据只有1 B,MIC端也会为该数据分配4 KB的内存空间.在需要进行频繁小数据通信的情况下,offload模式一方面会使得代码显得较为冗长;另一方面也会造成空间浪费,并且导致传输延迟增加.
在函数coGA_Put和coGA_Get实现过程中,由于数据必须先放入全局数组对象才能使用,对于小数据传递(通常小于4 KB),函数coGA_Put和coGA_Get可能显得过于复杂.为降低传输延迟,我们基于SCIF点对点通信实现了在CPU和MIC间直接传递短消息的函数:coGA_sendMsg和coGA_recvMsg.用户可以直接调用这2个函数在任意2个建立连接的端点之间进行通信.此外,相比于多个连接共享一个消息队列的情况,CoGA实现中每一对连接的端点都包含2个消息队列,每个消息队列负责一个通信方向,因此发送消息的进程不会被其他进程阻碍.coGA_sendMsg和coGA_recvMsg所构成的消息传递层主要针对小消息传递,而不是大块数据.尽管它能传递最大为(231-1)B的消息,由于消息队列较短,一条长消息会被转化为多个短消息进行传递,而且在传送过程中每个短消息都会产生延迟,因此传递长消息会使总体延迟急剧增大.
4.4 同 步
CoGA使用了与GA类似的一致性模型:
1) 只有在访问全局数组相同或重叠区域时,函数coGA_Put和coGA_Get必须严格保证执行顺序;反之,访问区域不重叠或访问不同全局数组时,put和get操作允许以任意顺序完成.
2) CoGA模型的put操作可通过2种方式访问全局数组,即本地访问和远程访问.put操作在本地访问完成后立即返回,这也意味着此时数据已经从本地拷贝完毕但可能尚未到达远端.
CoGA提供2种同步函数:coGA_Fence是局部操作,用于等待函数调用端进程的操作完成;coGA_Sync则是集体操作,对所有进程进行同步并保证CPU和MIC端的CoGA操作完成.coGA_Fence操作基于SCIF RMA同步操作实现:首先通过接口scif_fence_mark()标记那些已经开始但尚未完成的RMA访问操作,并将返回的句柄传递给scif_fence_wait();之后再调用接口scif_fence_wait()等待被标记的RMA访问完成.
5 测 试
我们基于SCIF,一种类似socket、用于主机端和MIC之间传递数据的对称传输接口,在CPU+MIC的异构系统上实现CoGA.本节主要通过带宽测试、延迟测试和稀疏矩阵乘(sparse matrix vector multiply, SpMV)问题评估CoGA性能.
图5通过一个简单的例子说明CoGA编程与offload编程的差异.在offload模式中,同一节点内的MIC之间无法直接进行传输数据,因此数据必须
if(rank=1)*MIC0*
{
coGA_sendMsg(2,p,k);*sent message to MIC1*
}
if(rank=2)*MIC1*
{
coGA_recvMsg(1,p,k);*receive message from MIC0*
}
⋮
(a) CoGA
⋮
#pragma offload target (mic:0) in (p:length(i))
{
}
#pragma offload target (mic:0) out (p:length(i))
{
}
#pragma offload target (mic:1) in (p:length(i))
{
}
⋮
(b) offload
Fig. 5 Programming example
图5 编程对比
coGA_sendMsg
coGA_recvMsg
为了更好地了解CoGA的实用性和具体性能,我们测试了函数coGA_Put的数据传输带宽和coGA_sendMsg发送小消息的延迟,并测试了在同一节点内2个MIC之间进行传输传递时CoGA接口的实用性,最后通过稀疏矩阵乘问题测试其整体性能.测试工作在由2个CPU和4个MIC组成的异构系统上进行,其中CPU型号为Intel Xeon E5-2670,2.60 GHz;MIC型号为Xeon Phi 3100,1.1 GHz;MPI版本为MPICH-3.2b1,网络模式为SCIF;GA版本为GA-5-4b,网络模式为MPI双边通信.
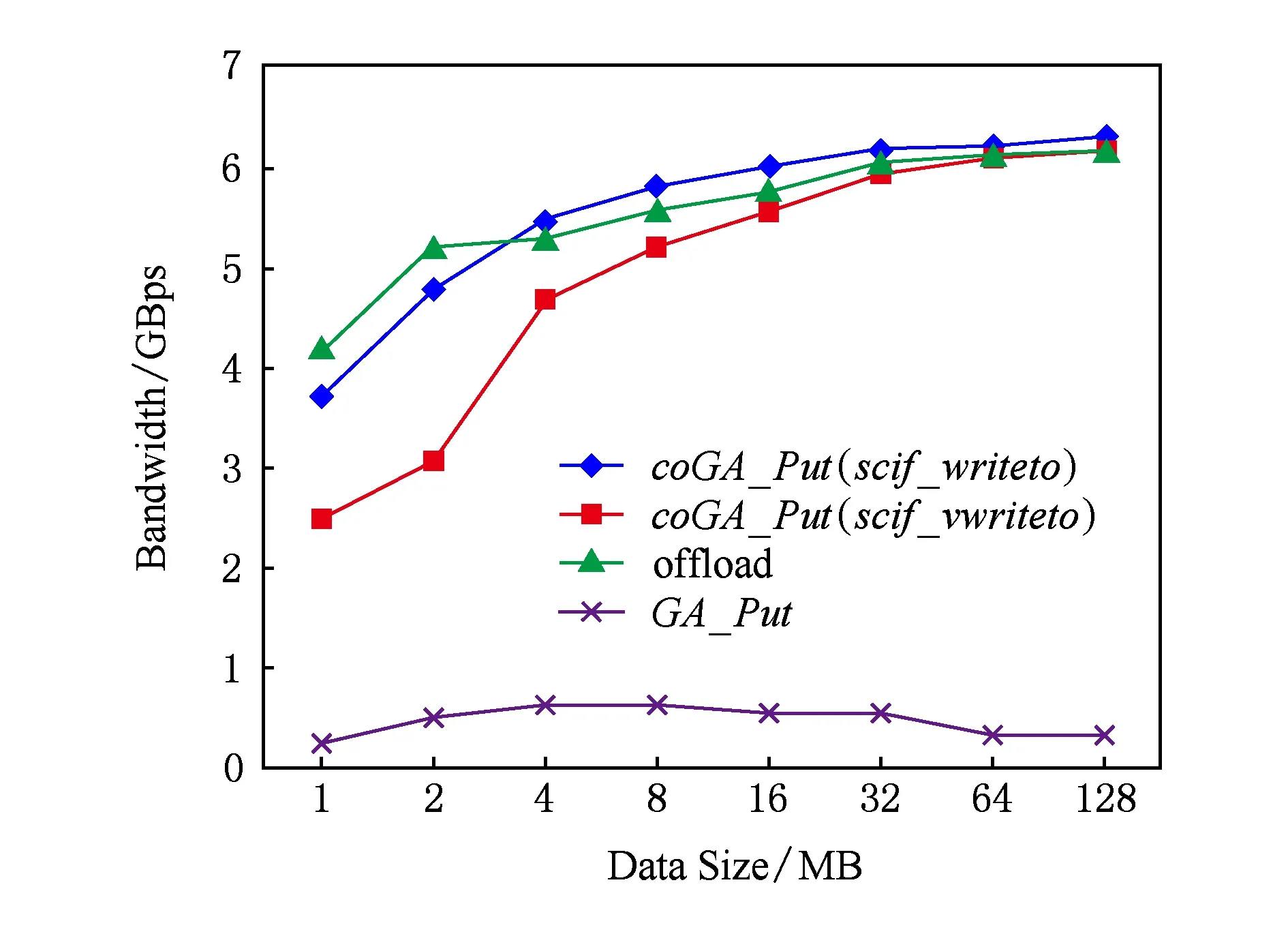
Fig. 6 Bandwidth test图6 带宽测试
首先,我们分别测试CoGA模型、GA模型和offload模式下从CPU传输数据至MIC端的数据传输带宽,其中coGA_Put包含2种远程数据传输方式,即scif_writeto和scif_vwriteto.测试结果如图6所示:GA_Put没有结合MIC上SCIF接口特点而是基于MPI双边通信实现,数据经过缓冲才发送至MIC端,因此带宽最低;函数coGA_Put(scif_writeto)实现过程中,数据从本地注册空间直接发送至远端注册空间,带宽性能优于coGA_Put(scif_vwriteto);coGA_Put(scif_writeto)在数据规模小于3.7 MB时,带宽低于offload模式带宽,这是因为put操作启动开销较大,需要比较数据传输范围并决定相应的数据传输方式,而当数据规模不断增加后,这部分开销所占的比例也不断减小,因此数据大于4 MB后coGA_Put带宽性能与offload带宽相当,甚至略高于offload模式.
其次,我们测试了在CPU与MIC之间进行数据通信时,函数coGA_sendMsg发送短消息的延迟,并与原本GA模型和offload模式进行对比.在发送短消息(小于4 KB)时,数据所需的内存空间通常由系统自动分配,因此在测试时我们也采用系统自动分配内存空间的方式进行.offload模式下,从源进程发送到目标进程的数据至少是4 KB对齐的,这也导致了其发送小消息效率低下.而coGA_sendMsg和GA_Put根据变量大小分配合适空间,因此延迟较低.测试结果如图7所示:当数据小于4 KB时,coGA_sendMsg和GA_Put的延迟要远小于offload模式;而coGA_sendMsg通过SCIF消息传递层传递小消息,没有数据缓冲开销,因此延迟也低于GA_Put;但当数据不断增加大于4 KB后,GA_Put带宽低于offload模式,且SCIF消息传递层只适合发送小消息,因此coGA_sendMsg和GA_Put延迟急剧增加.
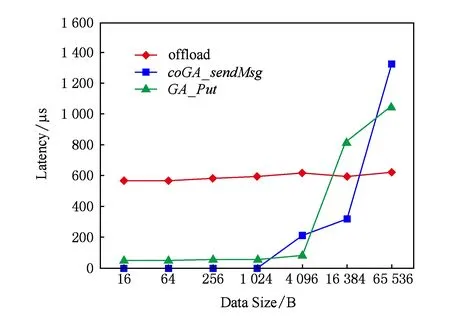
Fig. 7 Latency test图7 延迟测试
此外,我们还测试了在MIC之间进行数据通信时offload模式与CoGA接口的延迟表现.由于传输数据较大,此时我们提前为传输数据分配内存空间.测试结果如图8所示:随着数据规模增加,offload模式与coGA_Put延迟也不断增加,而且coGA_Put延迟整体小于offload模式延迟.由于此时事先分配好内存空间,因此offload模式下MIC间的传输延迟相对于未提前分配内存情况下offload模式的传输延迟减小.但是offload延迟包含MIC0传输至CPU加上CPU传输至MIC1的时间,因此总延迟较大;相比之下,coGA_Put允许数据直接从MIC0传输至MIC1,因此延迟较低.
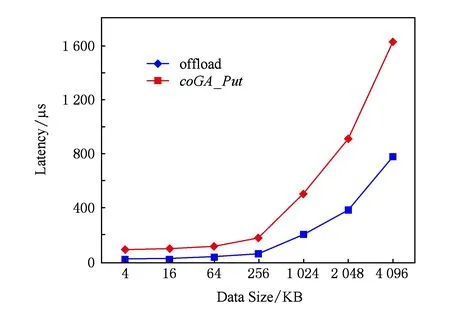
Fig. 8 Latency test between MICs图8 MIC间延迟测试
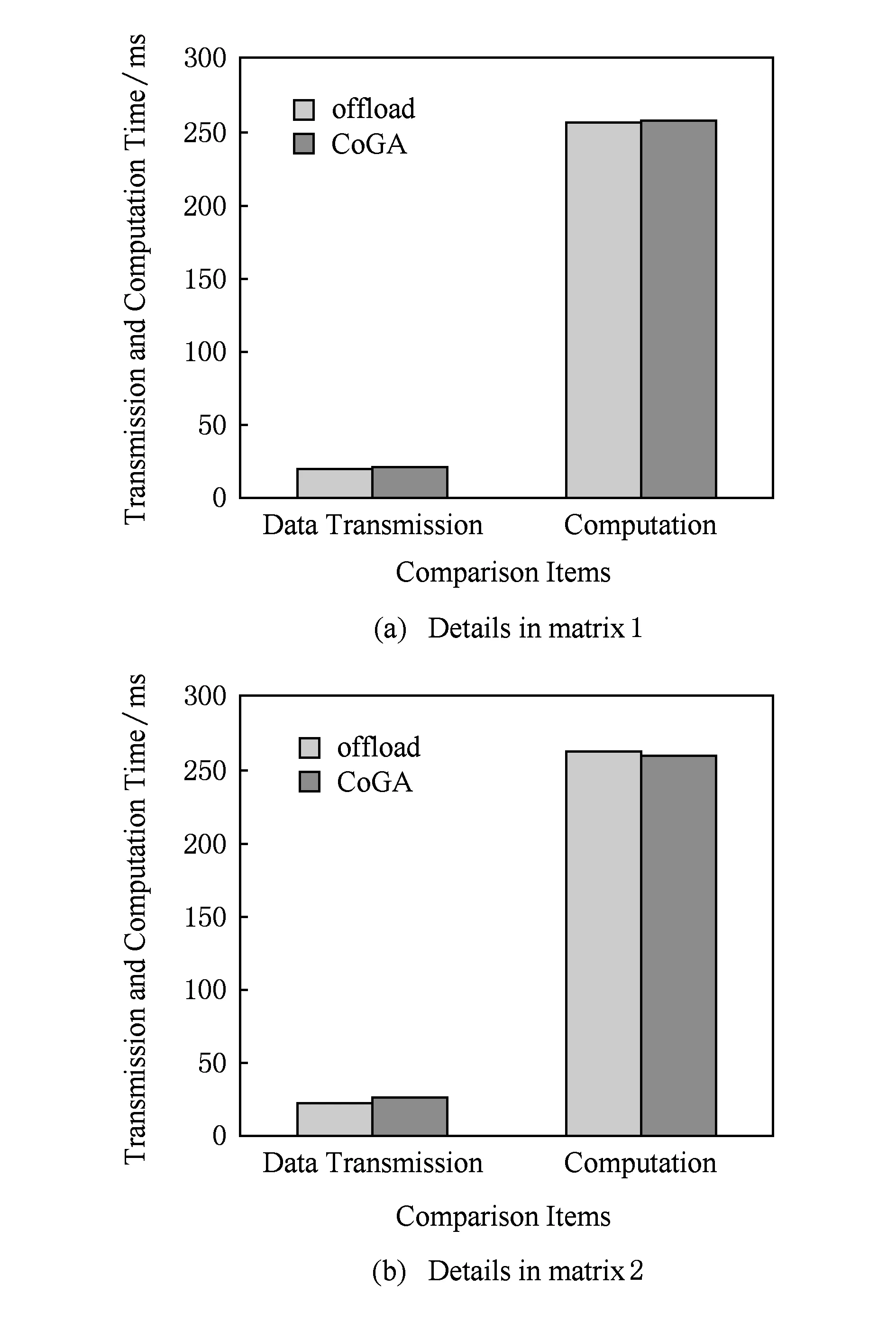
Fig. 9 SpMV performance comparison图9 稀疏矩阵乘性能测试
最后,我们通过稀疏矩阵乘问题评估CoGA整体性能.矩阵1的规模为116 158×116 158,包含8 516 500个非零点;矩阵2的规模为259 156×259 156,包含4 429 042个非零点.这2个矩阵都存储为CSR格式,CPU和MIC各自负责处理一半的数据.CoGA和offload模式下测试结果如图9所示:CoGA和offload模式的数据传输开销基本相同,说明了CoGA通过SCIF进行传输数据的性能与offload性能相当;与预测相符,计算开销也基本相同.
6 总 结
我们面向异构系统对GA进行拓展,结合MIC上的SCIF接口实现了CoGA,从而在CPU和MIC之间实现共享数据结构.CoGA提供的API接口隐藏数据传输细节并允许编程人员忽略数据的具体位置而直观操作共享数据,实现了MIC之间直接的数据通信,进而简化了编程难度.此外,CoGA基于库实现的特点也保证了其与OpenMP和MPI等并行编程模型的兼容性.我们定义了2种数据传输方式:本地访问通过函数memcpy实现,远端访问通过SCIF RMA接口实现.我们对CoGA的传输带宽的测试也表明了CoGA的实际性能远高于原本GA模型;此外,我们还通过函数coGA_sendMsg和coGA_recvMsg优化小数据发送,降低通信延迟.CoGA在具有简单和高效特点的同时也存在不足,如现在API接口不够丰富并只能应用于CPU+MIC的异构系统.在下一步工作中,我们将继续完善CoGA库特性并尝试将其拓展至GPU.
