基于k-means聚类分析的高校论文统计研究
2017-11-07,
,
(1.杭州科技职业技术学院信息工程学院,杭州 311402;2.浙江理工大学图书馆,杭州 310018)
基于k-means聚类分析的高校论文统计研究
查香云1,吕国良2
(1.杭州科技职业技术学院信息工程学院,杭州 311402;2.浙江理工大学图书馆,杭州 310018)
科研论文的质量能反映学者、学术机构和学术团队的科研水平。文章选取浙江理工大学、浙江工业大学、浙江师范大学等十所高校,提取各高校在2012—2016年所有被WOS核心合集中SCI数据库收录的论文,采用非监督的机器学习k-means算法对发文量、去自引被引频次、去自引施引文献及发文量权值等四个特征变量进行统计分析。结果表明:在这十所高校中,浙江工业大学和宁波大学属于第一等级,浙江理工大学、浙江师范大学和杭州师范大学属于第二等级,中国计量大学、杭州电子科技大学、温州大学、浙江农林大学和浙江工商大学属于第三等级。文章研究表明,利用k-means方法横向比较高校科研论文质量具有可行性。
k-means;中科院期刊分区;MATLAB;归一化;去自引被引频次
科研论文是科研成果的重要表现形式,论文的质量很大程度上反映了个人或机构的科研水平。科研论文的质量评价指标,无疑会对科学研究起到导向性的作用。相比于早期的易受主观因素影响的同行评议,目前人们更认可能体现客观性的论文质量评价指标——论文的被引频次和期刊影响因子。
虽然这两个指标在学术的研究和评价中带来了相当积极的影响,然而,在持续的文献计量的研究中,笔者也发现了其诸多弊端。第一,不同学科领域,受人们的关注的程度不同,会造成论文的被引频次的巨大差异,只用论文被引频次和基于论文被引频次计算的期刊影响因子来表征论文质量的优劣,不够全面。在不同的学科领域,这两个指标完全没有可比性[1]。第二,虽然SCI对期刊做了学科的分门别类,增加这两个指标的可比性,但是由于学科间的渗透融合,期刊的分类标准本身也是研究的一个主题,因此仅从这个层面来考量或研究科研论文的质量和水平,也显得困难重重。第三,基本科学指标(essential science indicators,ESI)作为一种衡量科研水平相对高低的指标,刚一出现,即受到广泛的关注和重视,具有很强的导向性作用。可是,ESI是在学科分类基础上,把论文的被引频次作为唯一指标来衡量论文的质量,这缺少合理性。此外,ESI只显示了达到基线指标的相关的学科、机构和论文等的信息,难以从中了解学术机构的更详实的水平,因此ESI指标在科研管理中也缺乏可操作性。在学术机构作为基本单位进行排序(如ESI的排名)的方法中,鉴于论文的被引频次作为计算指标的不足,本文采用论文的被引频次与其在“中科院期刊分区”(2016年版,以下所称“中科院期刊分区”即指该版本)中的论文权重并举的计算方法;同时,本文也认为,以学术机构作为排序的基本单位,其粒度过细,因此提出了以较粗粒度——学术机构的聚类,作为学术机构(本文以高校作为实证研究对象)排序的基本单位的方法。粗粒度较之于细粒度,其排序结果能够显现出较好的鲁棒性。
k-means是一种非监督机器学习算法,具有易收敛、操作性强的特点。k-means在生产实践[2-5]、商务旅游[6-8]、图像处理[9-10]和文本分类等领域都得到了有效应用。朱亮亮[11]把k-means应用在数据清洗中的人名的消歧,文献[12-14]研究了利用k-means在图书馆服务中实现文献自动推送。但这些研究,均着眼于单一的具体的研究对象内的数据聚类分析,未涉及多个对象的聚类的比较分析。
本文从文献的四个特征出发,摈弃单纯的使用引文数量的分析方法,结合使用“中科院期刊分区”中论文质量的划分标准,实证研究了k-means算法在多个研究对象——十所高校中的聚类分析中的应用。
一、数据的获取和处理
本文分析的文献数据,来自WOS(web of science)的核心合集中的SCI数据库。时间区间:2012—2016年;检索数据库:web of science “core collection”(SCI);检索字段:organization-enhanced;文献类型:article,review。具体情况如表1所示。

表1 浙江省十所高校论文SCI论文特征值(2012—2016)
注:获取数据的时间为2017年5月25日。
文献计量分析中,论文属性的选择和处理是十分关键的一环,本文选择能反映论文价值的特征作为文献计量的属性,通过归一化等处理方式统一属性间的量度标准。本文所述论文抽取的特征属性如表2所示,具体表述如下:
a)属性a:“发文量”,即论文数量,是高校的科研规模和科研产出能力的表征;
b)属性b:“去自引被引频次”,显示了论文所承载的学术成果被他人所认可的程度;
c)属性c:“去自引施引文献”,一定程度上反映了学术成果的影响面;
d)属性d:“发文量权值”,依据中科院期刊分区原则赋予论文权重计算所得的论文的权值。
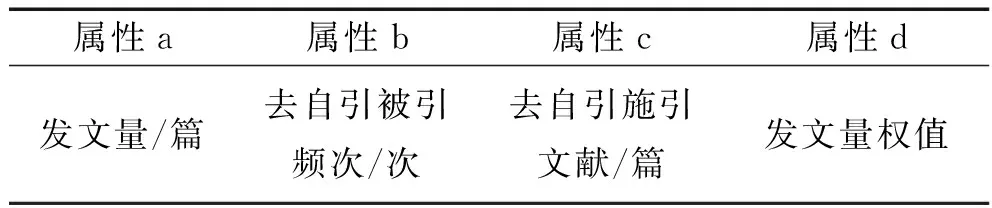
表2 文献属性一览
依据“中科院期刊分区”,本文把SCI期刊分为一区、二区、三区、四区及未收录五个类别。
“中科院期刊分区”的分区原则:将SCI期刊分为13个大类学科,在每个大类学科内,所有期刊按照学术影响力(3年平均IF)由高到低降序排列;依据该期刊排序,将期刊划分为一区、二区、三区和四区四个等级。“中科院期刊分区”的一区到四区的期刊数量不等,呈金字塔状分布。在大类学科中,取前5%(含5%)为一区、5%~20%(含20%)为二区、20%~50%(含50%)为三区,50%~100%(含100%)为四区[15-16]。不论领域,只要论文发表的刊物在同一个分区,就可以认为这些论文的质量是相当的[17]。依据这一原则,赋予每个分区的期刊论文的权重。“中科院期刊分区”论文的权重分配见表3。特别说明,表3中的“未收录”,是指未被“中科院期刊分区”收录的SCI期刊。由于这些期刊毕竟也属于WOS中的SCI期刊,所以本文赋予了较小的权重“0.5”。

表3 期刊分区论文的权重分配表
发文量权值计算公式:
Δ=∑μk*λk
(1)
其中:Δ表示发文量权值;k表示“中科院期刊分区”的五个类别,即一区、二区、三区、四区和未收录;μk表示分区类别k的文献量;λk表示分区类别k的权重。
根据“中科院期刊分区”统计各高校论文在期刊分区上的分布,并依据式(1)计算发文量权值,结果见表4。
表4续

序号高校名称一区/篇二区/篇三区/篇四区/篇未收录/篇总计/篇发文量权值5温州大学1254465575816317726456.506浙江农林大学903314576413815575029.007浙江工商大学1243843475673614585679.008浙江师范大学236756871974116295311274.009浙江理工大学1795737818754524538904.5010浙江工业大学342116713631913118490317373.00
对表1和表4作了汇总,结果见表5。
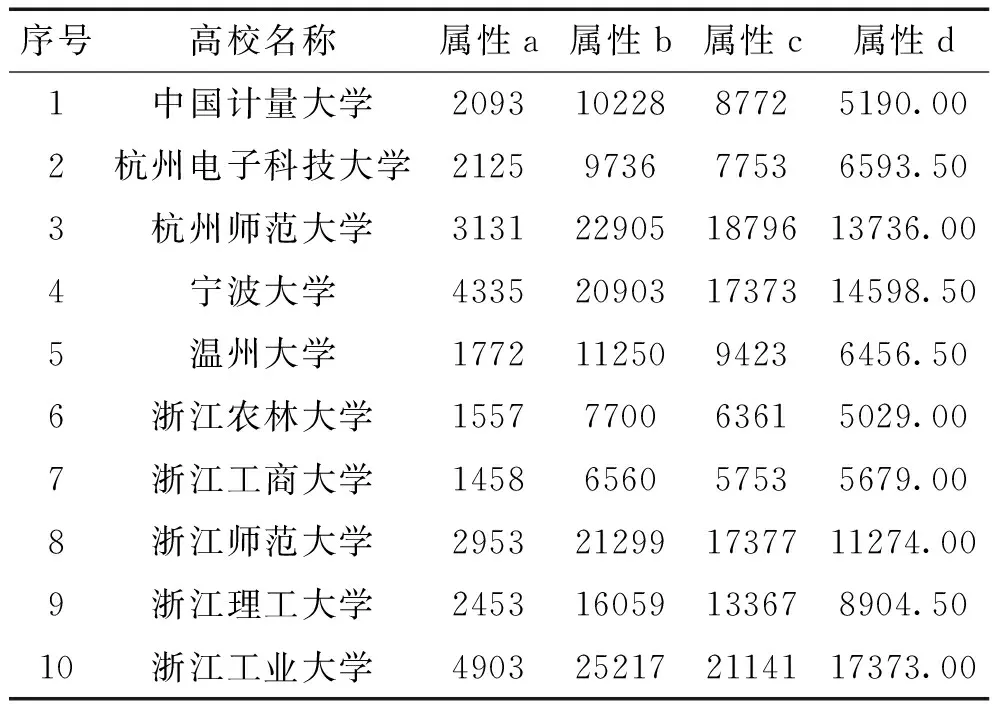
表5 四个特征属性值汇总
为避免特征属性的不同量纲对k-means的结果的影响,对四个特征属性的值进行线性归一化处理。归一化映射公式如下:
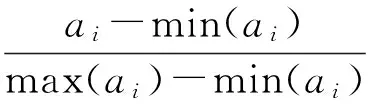
(2)
其中:ai为一组数据集中的第i个值;min(ai)为该数据集的最小值,max(ai)为该数据集的最大值;ai′为第i个数据的归一化处理后的值。
二、相似度和聚类的计算
本文采用欧氏距离来计算元素之间的相似度。两个元素的欧氏距离值越小,两者相似度越高。距离值越大,则相异度越高。
设有两元素X和Y,其都具有n个属性,则X、Y之间的欧氏距离D(X,Y)表示为:
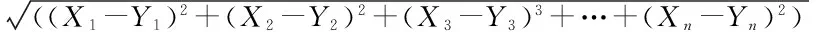
(3)
k-means算法,是指含有n个元素的集合D,D={X1,X2,X3,…,Xn},每个有可观察属性有m个,即X1有属性{X11,X12,X13,…,X1m},X2有属性{X21,X22,X23,…,X2m},…,Xn有属性{Xn1,Xn2,Xn3,…,Xnm}。假定要把这n个对象分成k个子集,即k个簇(k 依据表5中的四个特征属性作为可观察属性的项,计算欧氏距离。设定把10所高校分为三个层次,则在k-means聚类中,取k=3。 k-means算法的终止条件可以是以下中的任何一个: a)没有数据对象被重新分配到不同的聚类; b)聚类中心收敛; c)误差平方和局部最小。 根据式(2),在MATLAB软件下运行程序,结合表5,输出的归一化值如表6所示。 表6 四个特征属性归一化值 根据式(3)和表6,在MATLAB运行k-means程序,输出的结果为表征各个簇(即聚类)的代码。同一个簇,其代码数字是相同的。对应表6高校名称的排列顺序,程序运算结果见表7。表7中的簇代码,不表示大小或顺序,数字相同的数据对象位于同一个簇。 表7 簇代码与高校对应表 显见,三个簇的对象分别是:簇1:浙江工业大学和宁波大学;簇2:浙江理工大学、浙江师范大学和杭州师范大学;簇3:中国计量大学、杭州电子科技大学、温州大学、浙江农林大学和浙江工商大学。 综合分析表明,所统计的这四个指标属性中,浙江工业大学在10所高校中都处于榜首位置,无疑是这10所高校的领军者。宁波大学以四项相对比较均衡的指标值显示出其较强的科研能力,k-means算法聚类结果显示,它与浙江工业大学位居同一层次。 a)文献发文量显示了该统计区间(2012—2016年)高校的科研成果的产出。科学研究是需要投入的,科研投入与产出一般是正相关关系,因此文献的发文量与该高校获得科研经费的能力相关,这也是一种科研能力的体现。本文中,浙江工业大学以总量4903、占比18.31%占居首位;其次为宁波大学,总量4335,占比16.19%。杭州师范大学、浙江师范大学和浙江理工大学紧随其后。 b)文献数量只是评价科研能力的一个指标,科研能力还体现在文献的质量、学术影响的深度和广度上面。WOS平台为我们提供了现成的影响力指标——文献被引频次和文献的施引文献。本文选择更具有客观性的“去自引被引频次”和“去自引施引文献”两种指标。去自引被引频次,是文献被他人关注和认可的客观反映。去自引被引频次越高,表明文献所承载的研究成果越被他人所推崇和认可,影响也就越是深远;施引文献是被引文献的知识的发展面,揭示了知识流动的方向,也即原始文献所承载的研究成果的影响广度。表1显示,浙江工业大学以去自引被引频次25217次,去自引施引文献21141篇,独占鳌头,杭州师范大学则分别以22905次和18796篇位居其二。 c)根据“中科院期刊分区”加权获得的发文量权值反映了论文的整体质量,发文量权值越大,论文的总体质量越高。从表4可以看出,浙江工业大学、宁波大学和杭州师范大学位列三甲。 在高校内部的科研管理中,使用该方法统计分析各学科、各学术团队或各学术机构如研究所和学院的科研论文,利用k-means对他们的学术发展水平做一个统一的聚类分析和评估,简单方便,操作性强。本文中的不足之处在于:a)本文只统计了SCI的论文,其聚类排名只限于在理工科方面的学术水平的展现;b)未考虑作者在具体的论文中的排名,而致在合作发表的论文中对各高校的学术贡献程度的揭示不够充分。 [1] 丁佐奇,郑晓南.期刊影响因子、论文被引证次数与学术质量评价的矛盾分析[J].中国科技期刊研究,2009(2):286-288. [2] 边振兴,杨子娇,钱凤魁,等.基于LESA体系的高标准基本农田建设时序研究[J].自然资源学报,2016(3):436-446. [3] 刘艳秋,武佩,张丽娜,等.母羊产前行为特征分析与识别:基于可穿戴检测装置构架[J].农机化研究,2017(9):163-168. [4] 常亮,郭垚嘉,贾炯,等.利用聚类算法分析河北省地震分布状况[J].高原地震,2017(2):12-16. [5] 刘仕兵,葛俊祥.基于K-means聚类法的牵引供电隔离开关故障状态监测[J].华东交通大学学报,2017(3):109-117. [6] 陈钢华,黄远水.旅游者重游决策的影响因素实证研究:基于网络调查[J].旅游学刊,2008(11):69-74. [7] 陈晓艳,黄震方,胡小海,等.事件旅游城市居民分类及影响因素研究:以常州花博会为例[J].南京师大学报(自然科学版),2016(1):108-116. [8] 丛丽,吴必虎,张玉钧,等.野生动物旅游场所涉入实证分析:以澳大利亚班布里海豚探索中心为例[J].北京大学学报(自然科学版),2017(4):1-6. [9] 蔡志华.基于K均值聚类的彩色图像快速分割方法[J].计算机与数字工程,2013(8):1328-1330. [10] 李文博,强少卫.基于BMP位图的簇绒机花型图像处理技术初探[J].纺织科技进展,2017(6):9-11. [11] 朱亮亮.利用改进的K-means算法实现文献著者人名消歧[J].软件导刊,2013(5):63-66. [12] 常盛.k-means聚类算法在提高图书馆数字文献服务效能中的应用[J].电子技术与软件工程,2016(23):163-164. [13] 吉雍慧.数字图书馆中的检索结果聚类和关联推荐研究[J].现代图书情报技术,2008(2):69-75. [14] 张宏,王新玲,张丽.基于读者文献推送需求分析的医院图书馆精准服务实践[J].中华医学图书情报杂志,2016(4):74-77. [15] 中科院网站.JCR期刊分区数据在线平台[EB/OL].(2016-10-15)[2017-06-15]. http://www.fenqubiao.com. [16] 刘芳,朱沙.学术期刊主要评价体系差异性研究[J].高等教育研究学报,2015(1):33-38. [17] 李秋实,刘红玉.基于文献计量的期刊分区与论文学术评价量化实证研究[J].图书馆工作与研究,2015(4):60-66. StatisticalResearchofUniversityPapersBasedonK-meansClusterAnalysis ZHAXiangyun1,LÜGuoliang2 (1.School of Info Engineering, Hangzhou Polytechnic, Hangzhou 311402, China; 2.Library, Zhejiang Sci-Tech University, Hangzhou 310018, China) The quality of research papers can reflect scientific research level of scholars, academic institutions and academic team. Ten universities such as Zhejiang Sci-Tech University, Zhejiang University of Technology and Zhejiang Normal University were chosen, and their articles’ data downloaded from SCI database of “core collection” in WOS(Web of Science, WOS) during five years(2012—2016) were extracted in this paper.K-means, an unsupervised algorithm, was employed for statistical analysis of four characteristic variables including quantity of publications, citation frequency without self-citation, citing articles without self-citation and weight of publications. The results showed that among these ten universities, Zhejiang University of Technology and Ningbo University are clustered to the first level; Zhejiang Sci-Tech University, Zhejiang Normal University and Hangzhou Normal University fall into the 2ndlevel and the other five universities (China Jiliang University, Hangzhou Dianzi University, Wenzhou University, Zhejiang A & F University and Zhejiang Gongshang University) belong to the 3rdlevel. The study showed that it is feasible to applyk-means for horizontal comparison of the quality of universality papers. k-means; CAS Journal Section; MATLAB; normalization; citation frequency without self-citation TP311 A 1673- 3851 (2017) 05- 0478- 05 (责任编辑任中峰) 10.3969/j.issn.1673-3851.2017.10.015 2017-06-21 网络出版日期: 2017-09-27 查香云(1972-),女,安徽安庆人,讲师,本科,主要从事信息安全、多媒体等方面的研究。 吕国良,E-mail:lvgl@zstu.edu.cn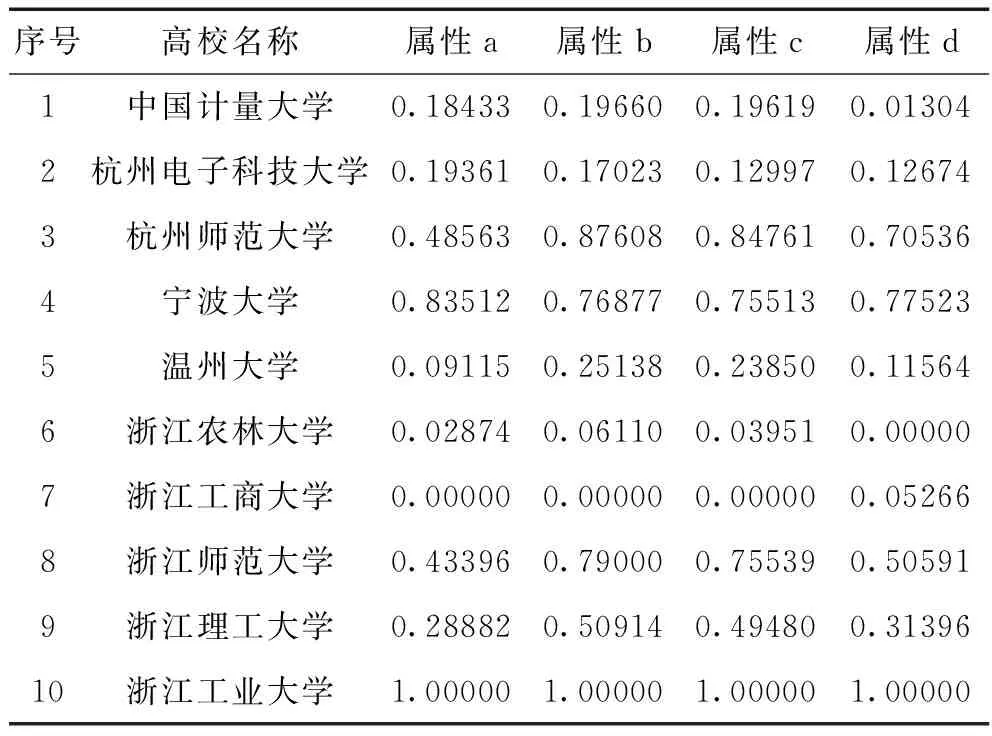

三、结 语
