基于文献的地质实体关系抽取方法研究
2017-11-01吕鹏飞王春宁朱月琴
吕鹏飞,王春宁,朱月琴
(1.中国地质图书馆,北京 100083;2.中国科学院大学,北京 100049;3.中国地质调查局发展研究中心,北京 100037;4.国土资源部地质信息技术重点实验室,北京 100037)
基于文献的地质实体关系抽取方法研究
吕鹏飞1,2,王春宁1,朱月琴3,4
(1.中国地质图书馆,北京100083;2.中国科学院大学,北京100049;3.中国地质调查局发展研究中心,北京100037;4.国土资源部地质信息技术重点实验室,北京100037)
实体关系抽取是信息抽取的一项重要内容,通过实体关系的抽取能够发现文本中的有价值信息。本文在分析和比较了有监督、无监督、弱监督以及开放式等关系抽取方法的原理和特点的基础上,建立了基于文献的地质实体关系抽取模型:采用统计语言模型作为关系抽取方式、采用Bootstrapping算法作为关系扩展方式。最后据此进行了关联关系发现和关系扩展发现实验。
文献;关系抽取;统计语言模型;Bootstrapping
进入大数据时代,随着获取数据的规模、范围和深度在不断宽展和延伸,人们关注的重点开始从起初数据的积累,向挖掘数据的深层次价值、实现数据的“增值”转变。在成矿预测领域,同样面临这样的问题,地质调查工作的成果基本上是信息性的成果,地质调查工作者在百年的工作实践中,积累了海量的成果报告、勘查资料、文献等数据资源,这些数据资源中蕴含着丰富的地质信息,如何在成矿规律和预测的研究过程中充分利用这些数据?如何将数据转化为新的认识或知识,为地质找矿实践提供积极的数据支撑。本文论述了一套基于文献的地质实体关系抽取模型的研究方法,尝试通过建立地质实体的关联关系网络实现发现潜在知识的目的。
1 关系抽取综述
为了解决从文本数据中获取有价值的信息,信息抽取技术应运而生。信息抽取被定义为从非结构化信息中获取结构化数据的过程[1]。信息抽取一般包含两个任务:实体识别和关系抽取。实体识别是通过自然语言处理技术从文本中提取实体要素,而关系抽取是在实体识别的基础上结合语义环境提取出实体之间的关系[2]。Etzioni认为关系抽取是分析检查文本中的实体对,并判断它们之间是否存在关系[3]。通过实体识别获得的一个个离散的实体要素对于理解文本语义、发现有价值的知识点毫无帮助。有价值的信息往往是通过实体间的关系来体现的,比如在成矿预测研究中矿种和特定生物的关联关系、和岩石的伴生关系等。此外,关系抽取在很多领域具有应用价值。例如在检索系统中,传统的检索方式是基于关键词的匹配检索,而关系抽取技术则可以实现智能语义检索。比如输入“石墨烯”不光可以得到关键词里含有石墨烯的文本资料,还可以得到类似“前沿技术”、“知名学者”、“研究机构”等结果。此外,实体关系抽取在自动问答、自动标引、机器翻译方面具有重要的研究意义。
关系抽取技术路线经历了从模式、词典等简单方法到机器学习、基于本体的关系抽取等复杂方法,从基于分词、句法等匹配的浅表分析到基于语义的深层分析的发展过程[4]。基于模式和词典的方式准确率较高,但要求前期制定细致的规则和语料,而且跨领域移植很困难;本体是对信息资源进行语义化和有序化,理想化的本体包含实体及其关系,但由于本体构建需要投入巨大的工作量,目前仍然没有较为成熟的体系和应用。机器学习采用自然语言处理中的统计语言模型作为基础,实质上是一个源于数据的模型训练过程。机器学习的关系抽取方式是通过对大量文本数据进行抽取、转换、分析和模型化处理,从中自动分析获得规律,并利用规律对未知数据进行预测,从中提取出有助于关联分析的关键性数据。它的优势是入手简易、效率较高。采用机器学习的关系抽取方法按照对人工干预标注数据的依赖的程度可以分为:有监督关系抽取、远距离监督关系抽取、半监督关系抽取[5]。此外,近来随着大数据的理念和落地应用日趋成熟,开放式关系抽取方式开始兴起,下面分别做介绍。
1.1 有监督关系抽取
有监督的关系抽取方法是最基本的机器学习方法,思路是在已标注的语料上建立机器学习模型,然后使用模型在目标文本里进关系识别。有监督的学习效率较高,但前期需要大量的工作量投入人工标注语料。这种方法的问题在于适用于训练语料丰富的领域,所以跨领域移植性较弱。其典型算法诸如决策树、人工神经网络和支持向量机等算法,已广泛用于机器学习及模式识别、人工智能等领域中[6]。
1.2 远距离监督关系抽取
远距离监督又叫弱监督或无监督,它不需要建立人工标注的关系模型,是以预先定义关系模式和关系实例作为种子,通过机器学习,发现新的关系模板和实例。实现过程首先根据实体对出现的上下文将相似度高的实体对聚为一类,然后选择具有代表性的词语来标记这种关系[7]。远距离监督关系抽取一般基于统计语言模型的关系抽取思想。远距离监督关系抽取方法克服了费时费力的人工语料标注环节,不需要或需要很少预先处理的语料支撑,能自动地提取文本中包含的实体关系。而且由于不依赖于特定的训练语料,该方法对各领域的适应性很高。相较于有监督的关系抽取方法,远距离监督关系抽取方法的缺点是准确率较低。
1.3 半监督关系抽取
顾名思义,人工干预标注程度基于有监督和无监督之间的方法我们称之为半监督的关系抽取方法,半监督实体关系抽取无需大规模标注语料,只需人工标注少量关系实例,适用于缺乏标注语料的实体关系抽取。最典型的实例是Bootstrapping算法。Bootstrapping源于“重抽样”的统计思想,即通过现有模式不断扩展出新的模式,属于启发式的方法[8]。
1.4 开放式关系抽取
传统的关系抽取方式是有“限定”作为先决条件的,限定的范围包括:目标数据的范围、实体的类型、限特点定的关系等。而在网络时代,我们面对的是大量的无规则、开放的数据,因而有学者提出了开放式关系抽取的思想,主要基于以下特点:目标数据开放,不再限定数据的领域范围和数量;抽取类型开放,不在限定抽取的实体、关系类型。自动识别、分析、抽取语义类型[9]。开放式关系抽取方法是顺应大数据时代要求的产物,一经提出引起了广泛的关注,但至今成熟应用的案例还不多。
1.5 关系抽取方法比较
以上的关系抽取方法各有优缺点,关系抽取方法的选择需要结合语料准备和应用需要具体问题具体分析,通过比较分析得出以下结论。
1) 由于地质领域缺乏较为齐整的人工标注的地质信息本体,因此排除有监督关系抽取的方法。
2) 传统开放域抽取的方法基本上都是基于语法分析,而中文的短语结构分析和依存关系分析的水平还未能达到应用的水平。故本项目考虑改进传统的开放域抽取方法,引入统计语言方法代替语法规则的方法。故采用基于统计语言模型的关系抽取方式。
3) 基于Bootstrapping的方法可以很好的结合人的先验知识和庞大语料带来的统计效果,而且便于人去使用和修改,此外结合领域当中的关系专业性较强的特点,借助Bootstrapping方法可以利用庞大的语料对于人为规定的实体关系进行扩展,从而快速实现信息的同种关系抽取。因此,选择基于Bootstrapping的方法进行关系扩展。
2 实体关系抽取模型研究
2.1 统计语言模型算法
2.1.1 统计语言模型算法研究
统计语言模型最早是由贾里尼克提出,他认为一个句子是否合理,就看它的可能性大小,这个可能性就是概率[10]。简单来说,统计语言模型就是可能出现的句子或其他语言学单位的一个概率分布。统计语言模型可以形式化统一表示为式(1)。
p(S)=p(w1,w2,…,wn)=
p(S)就是用来计算句子S概率的模型。那么,如何计算p(wi|w1,w2,…,wi-1),最简单的办法就是采用极大似然估计(Maximum Likelihood Estimate,MLE),见式(2)。
p(wi|w1,w2,…,wi-1)=

(2)
其中,count(w1,w2,…wi)表示词序(w1,w2,…,wi)在语料库中出现的频率。但由于数据稀疏和参数空间过大,导致实际中无法得到应用。所以,实际中通常采用N元语法模型(N-Gram),它采用马尔科夫假设:语言中每个单词只与其前面N-1的上下文有关。假设下一个词的出现只依赖它前面的一个词,即二元语法模型(BiGram),则有式(3)。
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)…
p(wn|w1,w2,…,wn-1)=
(3)
理论上讲,N值越大计算出来的值精确度越高。但是随着N值的增大,模型的复杂度也越大[7]。具体来说计算p(w1)、p(w2)很容易,但是当N=3时,计算p(w3|w1,w2)已经有些困难了,当N>3时,计算量将变的非常大。所以对于N的选择:理论上越大越好;经验上Trigram(三元模型)用的最多;原则上能有Bigram解决的,就不用Trigram。
2.1.2 构建基于统计语言模型的关系抽取模型
在实验中采用三元语法模型,满足二元马尔科夫假设。具体操作步骤如下所示。
1) 分词,对每个句子进行分词;过滤出名词、动词和介词。
2) 对关系词进行过滤,过滤出不及物动词(例如,奔跑)以及以人为主语的词(例如,看见)。
3) 获得关系三元组可能集合:句子中所有n-v/p-n结构的三元组,不考虑相邻关系。
并计算获得的所有三元组的联合概率作为该三元组的得分(用二元语法模型);获得关系三元组的候选集合:找出得分最高的n-v/p-n三元组作为候选的关系三元组。
4) 确定关系三元组:通过规则,对关系三元组的候选集合进行过滤,得到关系三元组,目前主要通过两条规则进行过滤:对于抽取出来的n1-(v/p)-n2结构,如果n1和n2之间距离超过5,我们认为这个关系较弱而舍弃;对于抽取出来的n1-(v/p)-n2结果,如果n2后面是一个动词,我们认为这个关系抽取的不完整故舍弃。例如:“我对他说,明天放假”,会抽取出来“我-对-他”的关系三元组,而这个关系不完整。
5) 关系三元组置信度计算:加入评分函数,计算抽取的关系三元组的置信度。评分函数利用统计语言模型统计关系对出现的次数,并参与联合概率计算:如式(3)所示,语言中每个单词只与其前面n-1的上下文有关。接下来的关键问题就是如何计算Pp(wn|wn-1)。现在有了大量机读文本后,这个问题变得很简单,只要数计算(wn,wn-1)在统计的文本中出现了多少次,以及wn-1本身在同样的文本中前后相邻出现了多少次,然后用两个数相除就可以了p(wn|wn-1)=p(wn,wn-1)/p(wn-1)。
关系抽取流程如图1所示。

图1 基于统计语言模型的关系抽取模型流程图
2.2 Bootstrapping算法
2.2.1 Bootstrapping算法研究
统计语言模型解决的是关系抽取的问题,而Bootstrapping解决的是关系扩展的问题。Bootstrapping首先利用少量已标记样本的特征及其结果度量建立初始学习模型,主要的思路是通过人工指定几个初始的种子,随后系统会寻找满足人工提供种子的句式模板,利用得到的模板找到新的种子不断的迭代下去,最终达到举一反三的目的。该方法的缺点是对初始关系种子的质量要求较高。比如我们现在知道“中国-北京”,“美国-华盛顿”两个国家-首都的关系,但是还想知道所有其他的国家-首都关系,那么就可以用Bootstrapping方法,以“中国-北京”,“美国-华盛顿”为基础,可以找到语料中几乎所有的国家-首都关系。
2.2.2 构建基于Bootstrapping算法的关系扩展模型
依据Bootstrapping算法的基本思想,设计算法流程共分为以下几个步骤:上下文构建阶段、模板抽取阶段、候选种子抽取阶段和候选种子评分阶段。
1) 上下文构建阶段。上下文构建阶段主要是利用一种前缀字典树的数据结构来存储种子的前后的文字,在抽取上下文的时候,只选择在同一个分句当中的内容即任何标点符号都作为边界处理。前缀字典树是一种压缩存储的数据结构,他的特征在于父节点是子节点的前缀。构造两个字典树,分别存储种子之前的文字和之后的文字。
2) 模板抽取阶段。模板抽取阶段主要是利用上下文构建得到的两个字典树,找到满足所有种子的最长的句式模板。
3) 候选种子抽取阶段。候选种子抽取阶段主要是利用找到的句式模板,在整个语料中找到满足句式句子并利用句式抽出去对应位置的种子,作为候选种子。
4) 候选种子评分阶段。候选种子评分阶段主要是利用随机游走的方法从图中进行迭代直到到达图中的任何一点的概率收敛。在这里的图的结构如下:共有三种类型的节点,分别为文档、句式和候选种子,文档和句式之间的关系是包含,句式和种子之间的关系是抽取,文档和种子的关系是含有。具体如图2所示。
在具体算法的实施过程中,首先由人工给出2~3个种子,每次迭代的过程中,从已有的种子集合中抽取三个种子并加上上一次迭代得到的分数最高的种子作为本次迭代的初始种子,利用上述的四个阶段提取种子,每次仅选取最高的一个加入到种子集合当中。具体抽取流程如图3所示。
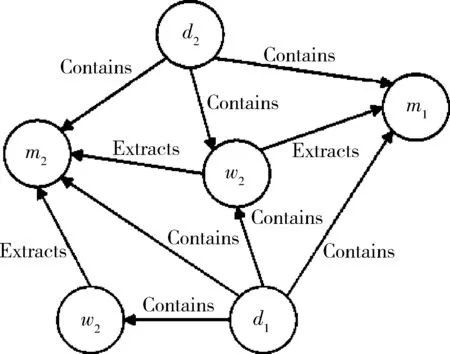
图2 种子评分所采用的随机游走方法结构图

图3 基于Bootstrapping算法的关系扩展模型流程图
3 关系抽取实验
实验的目的是从文献数据中发现潜在的关联关系,建立实体间的关联网络,为成矿预测工作提供未被发现的、有价值的新知识点。根据前期需求调研,本次实验将围绕发现并验证“金矿”和“生物”两个领域间的关系展开。
3.1 数据源准备
目标数据源主要有两类:第一类为生物和金矿会议文献,生物会议文献约44 640篇,金矿会议文献约1 647篇,大小共约457 M;第二类为生物和金矿期刊文献,生物期刊文献约387 660篇,金矿期刊文献约28 740篇,大小共约9.54 G。文献类型为txt类型。
3.2 实验环境
1) 服务器配置:CPU:Intel Xeon E5-2609 V3,内存:24 GB。
2) 操作系统:RedHat 4.4.7-4(Linux内核版本2.6.32) 64位。
3) 数据库:MySQL 5.6。
4) 分布式搜索引擎:ElasticSearch2.3.4。
5) 开发环境:MyEclipse 2015、Java版本:1.8.0.131。
3.3 关联关系发现实验
3.3.1 实验描述
发现“金矿”与“微生物”领域关键词之间的关联关系。
3.3.2 实验步骤
1) 获得候选关系对集合,在词典里提取金矿和微生物词表,并进行两两配对。
2) 获得可能关系对集合,挑选出语料中关系对至少同现10次的关系对和所有同现的语句。
3) 确定关系,采用统计语言模型的方法在关系对同现的语句中抽取关系词,用来表达关系对的关系。每个同现语句至多抽取一个关系,每个关系对可能有多个关系词,这些词统统保留(因为是关系发现,没有足够的证据表明哪个关系词是错误的)。
4) 关系过滤,对于句子中关系对距离过远的关系丢弃。
3.3.3 实验结果
实验结果如图4、图5所示。

图4 “金矿”与“微生物”关联关系发现结果

图5 “金矿”与“微生物”关联关系发现结果改进
在随后的实验中,考虑到此次研究的目的是新知识发现,限定关系对至少出现10次以上并不能很好的发现新知识(出现频次高的一般不是新知识),故在实验中取消了至少出现10词的过滤规则。
3.3.4 实验分析
本次实验的目的是发现分析“金矿”和“微生物”间的关系,验证并完善基于统计语言模型的关系抽取模型。下一步改进方向包括以下两方面。
1) 无用关系去除。可以通过不断完善停用词表来实现。
2) 关系的归类分析。在目前的统计语言模型中没有考虑关系的归类,遍历出的关系维度很大,考虑引入基于业务专家指导的关系聚类技术,提高模型的实用性。
3.4 关系扩展发现实验
3.4.1 实验描述
验证基于Bootstrapping算法的关系扩展模型,主思路如下:提供两对关系对(种子),模型将会自动扩展这两对关系对,并根据提交的关系对(种子)进行搜索,查询到由此生成的句式模板和候选集合(候选关系)。根据筛选得到的候选集合(候选关系)进行判定。
3.4.2 实验步骤
1) 关系对(种子)提交。人工提交一个关系对(种子),模型自动识别判断交的关系对(种子)关系。
2) 定义抽取模板。根据关系对(种子)抽取一个模板,再根据这个模板抽取其对应的候选关系,如发现新关系在进行种子提交和定义新抽取模板,如此循环,直到再也无法抽取出模板为止。
3) 句式模板抽取。根据模板中的两个关系实体通过Elastic Search(IK分词器的Elastic Search搜索引擎,下同)来搜索文献中包含这两个实体的句子。只要输入的关系实体之间有相关关系,则这两个关系实体可以抽出至少一个模板。当两对关系都被抽取过模板之后,需要对模板集合中的对应字段进行检索,仅保留对应于两个种子的模板。最后利用得到的模板进行候选集合(候选关系)的抽取工作
4) 候选关系对抽取。根据待抽取模板在Elastic Search中查找包含该模板的句子。再利用模板的类型和内容决定需要过滤的部分,过滤掉多余的字符串,只保留生成的关系。
5) 关系判定。然后对生成的关系进行清理,除去不完整的关系对(如关系实体残缺、关系实体有标点)。
3.4.3 实验结果
输入“矿石-黄铁矿”、“矿石-黄铜矿”关系对作为种子。实验结果如图6所示。
图6 输入关系对(种子)表的关系对
3.4.4 实验分析
1) 实验验证了在给定的关系对(种子)在适当的关系条件下,可以根据其定义抽取模板,进而抽取新的候选关系对的过程。抽取的关系和模板保存在数据库中的“cgl_seed_relation”表中, rel_template字段记录了抽取出的关系,而rel_ent1和rel_ent1分别对应了关系中的arg0和arg1。
2) 候选集合(候选关系对)中某个关系对出现的频率远高于其它的关系对,这种高频结果可能是前人已经总结过的成果,可以直接利用起来。相应的如果某个关系对在一些高频模板中出现的频率很低,这样的关系对可能还没有被挖掘出价值,因此可以作为新的研究的重点。
3) 在实验中我们发现抽取出的模板和候选关系对有一些在语义上不连贯。产生该情况的原因一部分是中文乱码,另一部分是由于生成的模板中只有虚词(模板中只有介词的情况多见)。在下一阶段中我们需要进一步使用NLP相关算法对生成的结果加以限制。
4 结 论
地质文献是地质调查工作的成果的重要载体和呈现方式,很多研究发现都是通过对地质文献研究分析而诞生的。本文通过建立地质实体关系抽取模型的方式自动发现分析地质文献中实体间的关系并进行了实验验证。关系抽取模型包括了关系抽取模型和关系扩展模型两部分:关系抽取模型采用了极大似然估计的三元统计语言模型收取出候选关系集合,并通过制定过滤规则和评分函数进行关系的过滤和排序;关系扩展模型采用了Bootstrapping算法,在试验中将人工定义的种子模板通过检索Elastic Search来发现扩展新的关系模板。在后续的工作中,需要加入不同领域、体裁、规模的文本扩充试验,以验证方法的可移植性和实用性;同时需要进一步优化算法模型,研究关系分析过滤以及关系归类算法,提升实验精度。最终的目的是通过统计语言模型发现成矿预测领域有价值的关系,再通过关系扩展模型进行关系扩展,实现发现新知识,为成矿预测提供积极数据支持的目的。
[1] Jurafsky D,Martin J H.Speech and Language Processing.An Introduction to Natural Language Processing,Computational Linguistics and Speech Recognition (Draft)[C]∥Prentice Hall PTR.1999:638-641.
[2] 冯志伟.当前自然语言处理发展的几个特点[J].华文教学与研究,2006(1):34-40.
[3] A Culotta,A McCallum,J Betz.Integrating probabilistic extraction models and data mining to discover relations and patterns in text[C]∥In:Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics,Association for Computational Linguistics,New York.2006.
[4] 徐健,张智雄.典型关系抽取系统的技术方法解析[J].数字图书馆论坛,2008(9):13-18.
[5] 刘方驰,钟志农,雷霖,吴烨.基于机器学习的实体关系抽取方法[J].兵工自动化,2013,32(9):57-62.
[6] Natalia K.Review of Relation Extraction Methods:What is New Out There?[J].Communications in Computer & Information Science,2014,436(1):15-28.
[7] 王晶.无监督的中文实体关系抽取研究[D].上海:华东师范大学,2012.
[8] 刘珍,王若愚,刘琼.基于Bootstrapping的因特网流量分类方法[J].北京邮电大学学报,2014(5):66-70.
[9] 秦兵,刘安安,刘挺.无指导的中文开放式实体关系抽取[J].计算机研究与发展,2015(5):1029-1035.
[10] 吴军.数学之美[M].北京:人民邮电出版社,2015:28.
Studyongeologicentityrelationextractionmethodbasedonliterature
LYU Pengfei1,2,WANG Chunning1,ZHU Yueqin3,4
(1.National Geological Library of China,Beijing 100083,China;2.University of Chinese Academy of Sciences,Beijing 100049,China;3.Development and Research Center,China Geological Survey,Beijing 100037,China;4.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing 100037,China)
Relation extraction is an important section of information extraction,which play an crucial role in valuable information discovering.On the ground of analyzing and comparing,including supervised methods,unsupervised methods,self-supervise methods and open information extraction methods,this essay has built a Geologic Entity Relation Extraction Model,using statistical language models for relation extraction and bootstrapping models for relation extension.Finally,according to the above analysis,the experiment of incidence relation discovery and relation extension discovery were carried out.
literature;relation extraction;metallogenic prognosis;statistical language model;bootstrapping model
P208
A
1004-4051(2017)10-0167-06
2017-06-27责任编辑赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079);国家重点研发计划“基于‘地质云’平台的深部找矿知识挖掘”资助(编号:2016YFC0600510)
吕鹏飞(1978-),男,硕士研究生,高级工程师,主要从事地质文献数据分析与挖掘方面的研究工作,E-mail:23690271@qq.com。
朱月琴(1975-),女,博士,高级工程师,主要从事地质大数据、地图综合与可视化研究工作,E-mail:yueqinzhu@163.com。
