玉米籽粒淀粉含量主基因+多基因混合遗传模型分析
2017-10-27栗亚静进茜宁李静
栗亚静 进茜宁 李静


摘要:以3个玉米组合济533/PH6WC(组合Ⅰ)、济533/H5818(组合Ⅱ)、2394/PH6WC(组合Ⅲ)的P1、P2、F1、F2、B1、B2 6世代群体为材料,利用植物数量性状主基因+多基因混合遗传模型,对玉米淀粉含量进行6世代联合遗传分析。结果表明,组合Ⅰ和组合Ⅲ淀粉含量均为E-1模型(2对加性-显性-上位性主基因+加性-显性多基因混合遗传模型),2个组合均表现为以主基因遗传为主,均在F2代主基因+多基因遗传率较高;组合Ⅱ淀粉含量为D-2模型(1对加性主基因+加性-显性多基因模型),在B1世代没有检测到多基因,B2和F2代以多基因遗传为主,在F2代主基因+多基因遗传率较高。
关键词:玉米;淀粉;主基因+多基因;六世代联合遗传分析
中图分类号: S513032文献标志码:
文章编号:1002-1302(2017)16-0060-04
收稿日期:2016-04-21
基金项目:河南省新乡市科技创新平台建设项目(编号:CP1502)。
作者简介:栗亚静(1990—),女,河南焦作人,硕士研究生,主要从事玉米遗传育种的研究。E-mail:1379816806@qqcom。
通信作者:陈士林,教授,硕士生导师,主要从事玉米遗传育种教学与科研工作。E-mail:chenshilin63@126com。
随着我国经济的迅速发展,玉米由以食用和饲用为主,逐渐发展了工业原料应用和深加工等方面的用途。淀粉是玉米籽粒的主要成分,集中分布在胚乳中,淀粉含量对玉米品质和深加工方面有着重要影响。国外玉米深加工产品已由过去单纯的淀粉产品发展到淀粉糖、各种发酵产品、变性淀粉、玉米油和蛋白饲料等多门类的产品体系。
到目前为止,植物数量性状的主基因+多基因混合遗传模型在玉米株型性状[2-4]、穗部性状[5-6]及产量性状等方面已有大量的研究,玉米品质方面也有相关研究[8-10]。Wassom等研究了IHO和B73的回交群体(BC1S1)及BC1S1与Mo17的测交群体(TCs),在BC1S1群体定位到的QTLs中,有7个与油分含量相关,12个与蛋白质相关,14个与淀粉相关;TCs群体中有3个QTLs与油分相关,5个与蛋白质相关,6个与淀粉相关[11-12]。
本试验是在前人研究工作的基础上,用XDS型近红外光谱谷物分析仪测定构建好的3个组合的6世代玉米籽粒淀粉含量,进行多世代联合分析,估算其遗传参数,进一步分析玉米籽粒淀粉含量的遗传规律,从而更准确地认识该性状的遗传特征,为玉米品质育种提供理论参考。
1材料与方法
11试验材料
本试验选用4个优良玉米自交系,济533(济源市农业科学院选育)、PH6WC(美国先鋒玉米杂交种先玉335的母本)、H5818(河南科技学院自育的玉米自交系)、2394(山东省农业科学院选育出的自交系)组配3个组合济533/PH6WC(组合Ⅰ)、济533/H5818(组合Ⅱ)和2394/PH6WC(组合Ⅲ)。2012年6月10日在河南科技学院玉米育种试验田种组合Ⅰ、组合Ⅱ和组合Ⅲ的亲本,并组配F1代。收获后于2012年冬在河南科技学院海南三亚育种基地播种3个组合的F1代及亲本,并组配2个组合的B1、B2、F2代。2013年6月在河南科技学院试验田播种组合Ⅰ、组合Ⅱ和组合Ⅲ的P1、P2、F1、F2、B1、B2 6个世代材料。
12试验方法
将所有样品收获后自然状态风干,脱粒、粉碎备用。按照仪器操作要求,在XDS型近红外谷物分析仪(Foss公司生产)开机预热30 min并通过自检后,将9~10 g粉碎样品装入配套的样品池中并压实,用已校正的近红外漫反射光谱模型测定所有样品的淀粉含量,每个样本重复扫描2次,取其平均值,以干基含量(%)表示。3个组合亲本和F1代样品数均为30个;同一组合的B1、B2代样品数相同,3个组合样品数分别为180、179、160个;3个组合的F2代样品数分别为210、200、250个。[JP]
13数据的处理
试验数据使用Excel、SAS 80统计软件和南京农业大学章元明老师提供的主基因+多基因混合遗传模型6个世代联合分离分析软件进行分析。对3个组合6个世代的淀粉含量进行遗传模型分析。通过比较5大类24个遗传模型的赤池信息量准则(Akaikes information criterion,简称AIC)值选择1个或几个相对最适模型,之后根据适合性测验的结果[均匀性检验(U12、U22、U32)、Smirnov检验(nW2)和Kolmogorov检验(Dn)],确定最优模型,然后根据最优模型下的软件分析结果,计算出一阶遗传参数和二阶遗传参数。当多基因模型存在上位性效应时,其一阶遗传参数采用Gamble提出的6参数模式计算。
14遗传模型
P1、P2、F1、F2、B1、B2 6个世代联合分离分析的遗传模型共分5类24种模型,具体见表1。[FL)]
21玉米淀粉含量非分离世代的性状表现
3个组合亲本的淀粉含量及其差异性见表2和表3。对3个组合做t测验,结果表明,组合Ⅰ和组合Ⅲ的P1、P2差异均达到极显著水平(P<001),F1代平均淀粉含量均高于中亲值;组合Ⅱ的P1、P2差异达显著水平(P<005),F1代平均淀粉含量低于中亲值。
22玉米淀粉含量分离世代的性状表现
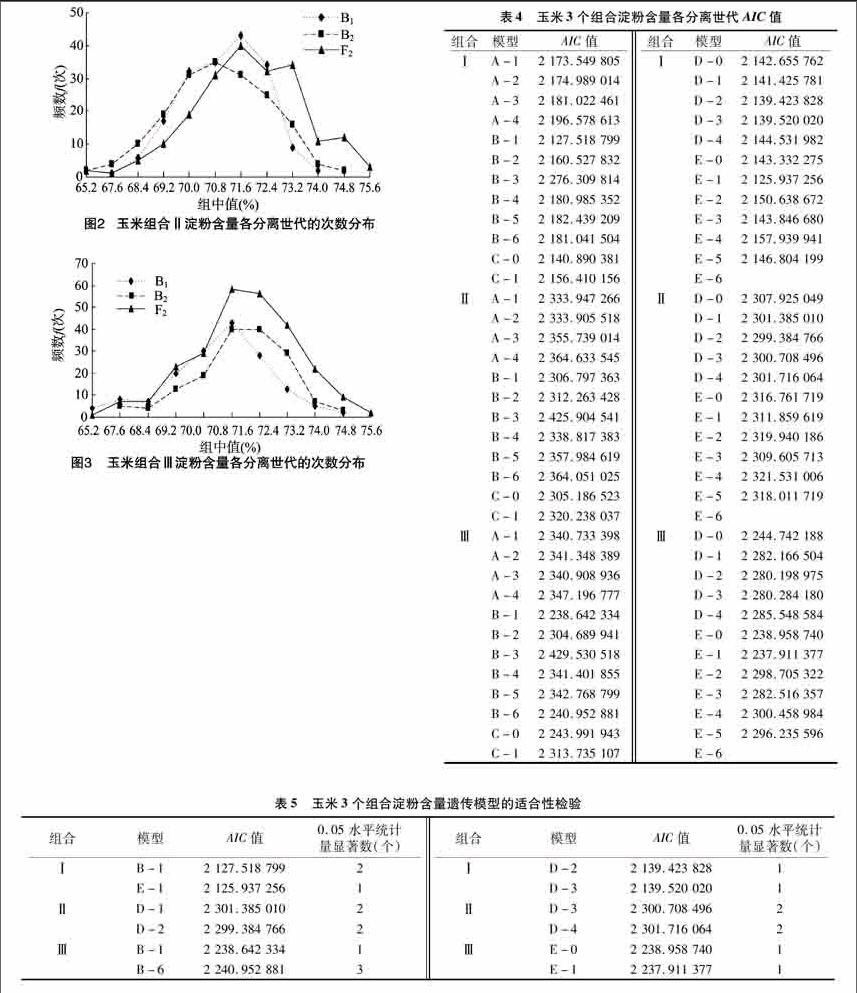
由图1至图3可知,组合Ⅰ中,各分离世代均表现为单偏峰分布,可能存在主基因;组合Ⅱ中,B1世代表现为单偏峰分布,B2世代表现为正态分布,F2世代表现为双峰分布,可能存在主基因和多基因;在组合Ⅲ中,各分离世代均表现为单偏峰
分布,可能存在主基因。
23玉米3个组合淀粉含量的主基因+多基因遗传模型分析
231玉米3个组合淀粉含量遗传模型的AIC值
由表4可知,组合Ⅰ中B-1、E-1、D-2和D-3模型的AIC值相对较低,以这4个模型为备选模型;组合Ⅱ中D-1、D-2、D-3和D-4模型的AIC值相对较低,以这4个模型为备选模型;组合Ⅲ中B-1、B-6、E-0、E-1模型的AIC值相对较低,以这4个模型为备选模型。
232玉米3个组合淀粉含量遗传模型的适合性检验
经适合性检验,组合Ⅰ中B-1模型的统计量显著数较多,E-1、D-2、D-3模型统计量显著数较少,而E-1模型的AIC值最低(表5),所以组合Ⅰ的淀粉含量最适模型为 E-1 模型。
组合Ⅱ中,备选模型有D-1、D-2、D-3和D-4模型。经[CM(25]适合性检验,D-2模型的AIC值最小,4个模型的统计量[CM)]
显著数相同,因此确定D-2模型为组合Ⅱ淀粉含量的最适模型。
组合Ⅲ中,备选模型有B-1、B-6、E-0、E-1模型。经适合性检验,B-6模型的统计量显著数较多,B-1、E-0、E-1模型的统计量显著数较少,E-1模型的AIC值最小。综合考虑确定E-1模型为组合Ⅲ淀粉含量的最适模型。
233玉米3个组合的淀粉含量最适模型及遗传参数估算
由表6可知,玉米淀粉含量组合Ⅰ符合E-1模型(2对加性-显性-上位性主基因+加性-显性多基因模型),检测到2对主基因。2对主基因的加性效应1正1负,显性效应1正1负,2对主基因的显性度的绝对值均大于1,表现为正向超显性。多基因的加性效应为正向,显性效应为负向。上[CM(25]位性效应中,加性×加性的效应值较大,为正向效应。加[CM)]
性×显性效应和显性×加性效应均为负向效应,显性×显性的效应值较大,为负值,上位性效应累计为负向效应。[h]/[d] 势能比小于-1,表现为负向超显性。3个分离世代的主基因遗传率分别为4397%、3901%、5466%,多基因遗传率分别为 2393%、2152%、2281%。主基因+多基因遗传率分别为6790%、6053%、7747%。可见组合Ⅰ以主基因遗传为主,在F2代选择时效率较高。
由表6还可以看出,组合Ⅱ淀粉含量符合D-2模型(1对加性主基因+加性-显性多基因模型)。主基因的加性效应为正向,多基因的加性效应为正向,显性效应为负向。3个分离世代的主基因遗传率分别为3242%、525%、2432%,多基因遗传率分别为000%、5422%、3881%。主基因+多基因遗传率分别为3242%、5947%、6313%。可见组合Ⅱ以主基因+多基因遗传为主,在F2代选择时效率较高。
注:m为群体平均数;a和b代表2对主基因的序列号;d为主基因加性效应;h为主基因的显性效应;[d]为多基因加性效应;[h]为多基因显性效应;i、jab、jba和l分别代表主基因间的加×加互作、加×显互作、显×加互作和显×显互作;σ2为方差;h2mg主基因遗传率;h2pg多基因遗传率。[HT][FK)]
由表6还可以看出,组合Ⅲ淀粉含量符合E-1模型,2对主基因的加性效应均为正向,显性效应1正1负(1对主基因表现为正向超显性,另1对主基因表现为负向超显性),上位性效应累计为负
向,多基因的加性效应和显性效应均为负向。3个分离世代主基因的遗传率分别为4736%、4468%、5821%,多基因遗传率分别为2750%、2418%、1674%。主基因+多基因遗传率分别为7486%、6886%、7495%。可见组合Ⅲ以主基因遗传为主,在F2代选择时效率较高。
3讨论与结论
利用植物数量性状主基因+多基因混合遗传模型不但能检测到主基因的存在,而且能计算主基因的遗传率,该研究方法对育种工作具有非常重要的意义。如果1个数量性状由少数主基因控制,则一般采用主基因的育种方法,通过杂交、回交转移主基因;如果1个数量性状由主基因和多基因共同控制,则需明确是主基因为主,还是多基因为主,以便采用相应的育种方法[14]
本研究采用主基因+多基因混合遗传模型多世代联合分析方法,对玉米3个组合6个世代的淀粉含量进行遗传分析。结果表明,玉米淀粉含量组合Ⅰ和组合Ⅲ均检测到2对主基因,都符合E-1模型,即2对加性-显性-上位性主基因+加性-显性多基因模型,组合Ⅱ淀粉含量符合D-2模型,即1对加性主基因+加性-显性多基因模型。魏良明等用10个玉米自交系,通过10×10完全双列杂交试验显示,淀粉含量的遗传符合加性-显性模型,不存在上位性效应[15]。本研究结果中组合Ⅱ淀粉含量遗传与其一致。而祁新等采用不完全双列杂交法,把10个自交系配成24个组合,结果表明,淀粉含量符合加性-显性-上位性模型,遗传方式以加性效应为主[16]。本试验中玉米淀粉含量组合Ⅰ和组合Ⅲ遗传与其结果相符,可见材料不同其淀粉含量遺传模式不同。也有研究认为,[JP3]淀粉含量的狭义遗传力与广义遗传力差异较小,主要受基因加性效应影响,所以可以在早期世代进行表型混合选择。[JP]
参考文献:[HJ165mm]
[ZK(#]张晖,姚惠源,王立 国外玉米深加工业现状和发展趋势[J] 粮食与饲料工业,2004(9):24-26
王铁固,马娟,张怀胜,等 玉米穗位高的主基因+多基因的遗传模型分析[J] 贵州农业科学,2012,40(4):10-13
[3]马娟,王铁固,张怀胜,等 玉米叶夹角、叶向值主基因十多基因遗传模型分析[J] 河南农业科学,2012,41(5):15-19
[4]王铁固,马娟,张怀胜,等 玉米株高主基因+多基因遗传模型分析[J] 玉米科学,2012,20(4):45-49
[5]张怀胜,陈士林,王铁固,等 玉米穗长和穗粗的主基因-多基因混合遗传模型分析[J] 广东农业科学,2012,39(19):6-9
[6]包和平,毕成龙,李颖,等 爆裂玉米百粒重性状的主基因+多基因混合遗传分析[J] 华北农学报,2011,26(3):199-203
[7]赵刚,张亚平,席世丽,等 微胚乳超高油玉米产量性状的主基因+多基因遗传分析[J] 玉米科学,2009,17(2):7-11
[8]姜敏,周艳明,刘祥久,等 不同玉米自交系品质性状的遗传特性[J] 沈阳农业大学学报,2004,35(3):170-172
[9]兰海,谭登峰,高世斌,等 普通玉米主要营养品质性状的遗传效应分析[J] 作物学报,2006,32(5):716-722
[10][ZK(#]魏良明,戴景瑞,刘占先,等 普通玉米蛋白质、淀粉和油分含量的遗传效应分析[J] 中国农业科学,2008,41(11):3845-3850
[11]Wassom J J,Mikkelineni V,Bohn M O,et al QTL for fatty acid composition of maize kernel oil in Illinois high oil×B73 backcross-derived lines[J] Crop Science,2008,48(1):69-78
[12]Wassom J J,Wong J C,Martinez E,et al QTL associated with maize kernel oil,protein,and starch concentrations;kernel mass;and grain yield in Illinois high oil×B73 backcross-derived lines[J] Crop Science,2008,48(1):243-252
[13]Gamble E E Gene effects in corn (Zea mays L) I Separation and relative importance of gene effects for yield[J] Plant Science,1962,42(2):339-348
[14]蓋钧镒,章元明,王健康 植物数量性状遗传体系[M] 北京:科学出版社,2003:19-25
[15]魏良明,戴景瑞,张义荣,等 玉米淀粉含量的杂种优势与基因效应分析[J] 作物学报,2005,31(7):833-837
[16]祁新,赵颖君,李鹏志,等 玉米品质性状的遗传模型分析[J] 吉林农业科学,2001,26(3):32-35
