面向文摘的中药方剂与疾病关系抽取*
2017-10-26杨晓欢单娅辉李晓东
杨晓欢,单娅辉,解 丹**,李晓东
(1.湖北中医药大学信息工程学院 武汉 430065;2.湖北省中医院 武汉 430061)
面向文摘的中药方剂与疾病关系抽取*
杨晓欢1,单娅辉1,解 丹1**,李晓东2
(1.湖北中医药大学信息工程学院 武汉 430065;2.湖北省中医院 武汉 430061)
目的:利用机器学习的方法,从文献摘要数据入手,研究中药方剂与疾病的相关性。方法:在中国知网的“文献分类目录”中选取“医药卫生科技”—“中医学”类别,使用网络爬虫技术获取摘要数据,经过数据清洗、构建词典、分词等预处理步骤,使用自然语言处理技术对处理后的文本数据进行特征提取,并构建支持向量机(Support Vector Machine,SVM)分类模型,对中药方剂与疾病进行关系抽取。结果:共爬取1073581篇摘要,根据中药方剂与疾病词典筛选出同时包含中药方剂与疾病的语句共204780句,利用句法解析抽取的特征构建SVM分类模型,准确率达87%,将该SVM模型应用于筛选后的句子,最终得到中药方剂与疾病之间的关系三元组。结论:利用机器学习方法对中国知网中医学摘要文本数据进行关系抽取,得到的中药方剂与疾病的关系三元组,将对中药方剂治疗疾病研究起积极推动作用。
中药方剂与疾病关系抽取 抽取数据 中医药数据抽取 网络爬虫技术
1 引言
中医领域包含丰富的临床和文献数据资源,这些数据资源具有重要的理论研究和临床应用价值,对其分析利用是重要的研究问题,但目前中医临床数据和文献数据等仍以自然语言为主要记录方式,其数字信息载体主要是文本数据。如何从非结构化文本中提取出有用的医学信息或者知识,已逐渐成为人们关注的研究课题,如抽取基因与疾病之间关系的DTMiner框架,从网络论坛、社交媒体数据中发掘药物与副作用之间的关联等[1-3]。中医药是我国的国粹,有着几千年的发展历史,近代时期西医后来居上,如何让传统中医在数据时代重获新生是中医药现代化的重要内容[4]。利用计算机程序自动从文本数据中提取有用信息,能够将人们从繁重的科研工作中解放出来,提高科研工作效率。
本文选取中医药文献摘要数据作为中医药知识的文本来源,尝试对其中蕴含的中医方剂与疾病之间的关系进行提取。本文在第2节中介绍了中医药文本挖掘的相关研究;在第3节中详细介绍了数据处理与分析方法,包括文本数据获取、数据清洗,构建词典以及分词;在第4节中分别使用句法解析、依存解析对文摘数据进行特征提取,然后使用SVM算法模型对数据进行分类;在第5节中进行了实验,得到中药方剂与疾病的关系三元组。结果表明本文提出的中药方剂与疾病关系抽取的方法方便可行,分类准确度高,为后续数据挖掘工作奠定了重要基础。
2 相关研究
关系抽取是从一句包含两个或多个实体的文本中抽取出实体间的关系[5]。例如从句子“益气导溺汤治疗产后尿闭35例”中抽取出实体“益气导溺汤”与“尿闭”的关系。关系抽取最终将得到二元组或者三元组表示的关系形式,帮助用户查询或者作为其他系统的输入,如问答系统等[6,7]。关系抽取方法主要有以下两种:基于规则匹配的方法和基于机器学习的方法。基于规则匹配的关系抽取方法是定义了一组表达自然语言文本关系的模式规则,然后从文献中抽取与该模式相互匹配的关系。Yu-Ching Fang在PubMed语料的句子级别上,采用基于模式匹配的方法进行关系抽取,结合PharmGKB数据库,对中药,基因,疾病之间的关系进行探索研究[8]。规则匹配的方法,对语言学的要求较高,因而基于机器学习的方法较为常用[9]。基于机器学习的关系抽取方法一般是预先定义关系类型体系,然后使用分类、无向图模型等机器学习方法来进行关系抽取[10]。周雪忠在现代生物医学数据与中医药文献数据中利用Bubble-bootstrapping算法进行中医术语实体识别,然后在基于共现的方法上利用点互信息,进行关系权重计算,得到症状、疾病与基因之间的关系[11]。Huaiyu Wan在中国知网的文献摘要语料中,利用因子图模型,对中药、方剂、症状、疾病这四者之间的关系进行关系抽取,判断它们之间是否存在关联[12]。
中医药文本挖掘以及关系抽取方面的研究成果较多。本文采用自然语言处理的方式,将文摘划分为句子,然后对句子进行分词、解析,抽取特征,建立模型。自然语言处理任务耗时较长,本文在单台机器上搭建了Spark伪分布式环境,验证了在Spark平台环境中执行自然语言处理任务的可行性。
3 数据处理与分析方法
3.1 文献摘要数据获取
中国知网作为学术文献、学位论文、报纸、会议等各类资源统一检索的数据库,包含的中医药文章与摘要资源丰富,本文将中国知网上的中医药类型文献摘要数据作为语料库。
使用Web爬虫,同时借助于支持JavaScript脚本的WebKit浏览器引擎PhantomJS,可以比较方便地全自动获取到中国知网网络期刊数据库中的文章标题以及摘要数据[13]。在中国知网的“文献分类目录”中选取“医药卫生科技”—“中医学”类别,本文爬取从1950年10月到2016年12月,共计66年所有该分类的摘要数据,一共爬取到1073581篇摘要。将所有标题、摘要数据合并为一个整体文件,方便后续的处理分析。
3.2 数据清洗
网页常用HTML标签对文本进行修饰,在提取正文信息时,需要删除这些HTML标签。本文使用正则表达式、Beautiful Soup库,对网页中的正文信息进行提取。中国知网上的摘要数据,有少量摘要数据的最后一句话不完整,特别是年代较早的摘要,如六七十年代的摘要。对于这些摘要,通过下载全文可以观察到,这些文章的排版不一样,而且是扫描版的文件,由图片构成,使用OCR进行图像识别得到的结果较差,不便于自动化处理,只能使用手工的方式才能对不完整的摘要进行补全,从效率上考虑,最终舍弃了摘要中最后不完整的语句。中国知网上的摘要数据,有中文简体字,也有中文繁体字,使用Open Chinese Convert(Open CC)开源中文简繁转换软件对文本全部转为中文简体文字格式。然后对字符集进行格式转换,全部转为UTF-8格式,避免后续的处理步骤因为字符集缘故而出错。在摘要中经常出现以“目的:”、“方法:”、“结果:”、“结论:”、“<正>”等标志字符开头的句子,这些词语对后续关系抽取无实际意义,清洗时删除了这类词语。
3.3 构建词典
中医药博大精深,名词术语包含了症状、疾病、证、中药方剂等。为了提高分词的准确性,需要建立中医药专业词典。中华人民共和国国家标准GB/T15657-1995《中医病证分类与代码》包含了“证”、“疾病”类专业名词。中华人民共和国国家标准GB/T 31773-2015《中药方剂编码规则及编码》包含了“方剂”类专业名词。另外,分别从国际疾病分类(ICD-10)、《秦伯未医学名著全书》中摘录疾病与方剂专业名词。词典中词的数量越多,对分词效果越好。为了进一步扩充中医药专业词典,从中国知网的中草药知识库、疾病诊疗知识库、中药方剂知识库,寻医问药网等获取信息,利用Web爬虫技术以及Heritrix开源网络爬虫项目获取所需名词术语数据,然后进行数据清洗,获取疾病、方剂、症状专业名词。对症状、疾病、证、中药方剂专业名词,在去重处理后,构成中医药专业词典。在分词阶段,为了提高分词精确度,还使用搜狗词库中的症状、名老中医姓名、医学穴位词典,将这些scel文件格式词典进行解析转换为普通文本文件txt。
3.4 分词
中文分词,是将中文文本划分为一个个的词语[14]。英文语言的词与词之间以空格作为标记,而中文的词与词之间没有分隔符,每句话中仅仅只有逗号、分号等作为分隔,中文中的这些分隔符不足以满足词语区分的要求。对于自然人而言,可以通过自己的理解知道语句中的单字、词语、短语、缩写等,而计算机不具备这样的能力,因此需要将语句进行分词处理。
改写Stanford Segmenter部分代码,获取自带词典的名词数量是423200个,加入自定义的中医药专业词典的名词共41110个,重新训练Chinese Segmenter,得到dict-chris6.ser.gz,对中国知网的摘要数据进行分词[15]。由于有的方剂长度较长,并且由几个中药名词组合加上“汤”、“丸”、“散”等组成,如“甘草知母鳖甲丸”由“甘草”、“知母”、“鳖甲”中药名加上“丸”构成,“茯苓桂枝甘草大枣汤”由“茯苓”、“桂枝”、“甘草”、“大枣”加上“汤”构成。使用Stanford Segmenter分词之后,这些由较短的中药名词组合而成的方剂名词,会被分为几个比较简短的中药名词。使用最大正向匹配的思想,对被误分的词进行重新合并,如图1所示,初始字符串s1表示经过Stanford Segmenter分词之后的语句。从方剂名词长度与中药名词长度考虑,对MaxLength设值为6,最长6个词一起合并,判断是否位于词典中,如果是则将它们重新合并,否则长度由6递减直至为1。
4 关系抽取
本文分别采用句法解析与依存解析两种方法进行特征提取,然后根据各自提取的特征构建SVM模型、决策树模型,根据对测试数据集的预测正确率,选取较高正确率的模型对未知数据进行划分,得到最终关系。
4.1 特征提取
中文文本词汇数量巨大,在抓取的全部摘要数据中,中文词汇的总数有近万条,如果特征空间直接由所有这些词汇组成,这样的特征空间偏大,不利于后续处理的效率与精度。为了提高分类的效率与精度,需要减小特征空间的维度。特征降维方法可以分为特征抽取(Feature Extraction)和特征提取(Feature Selection)。特征抽取将会产生新的特征,如主成分分析(Principal Component Analysis)等降维方法。特征提取是指依据某个标准从众多原始特征中选择少部分最能反映类别的特征集合,不会产生新的特征。这里分别使用句法解析与依赖解析的方法,进行特征提取,降低特征空间的维度。句法解析与依存解析,均需要通过标注的树库语料库建模产生,本文使用Stanford Parser开源工具进行句法解析与依存解析[16]。对语句进行句法解析或者依存解析之前,均需要对语句进行分词处理。
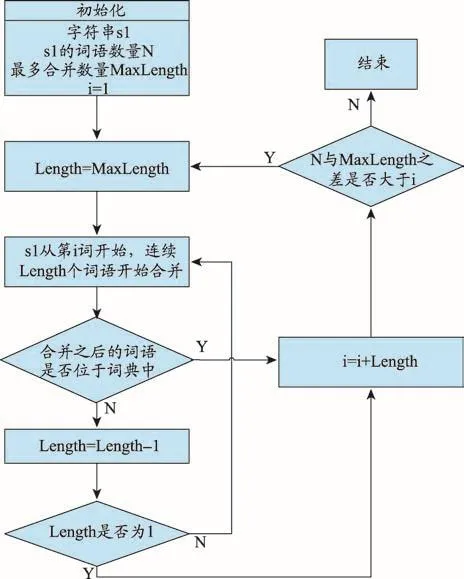
图1 基于Stanford Segmenter技术的分词流程图
4.1.1 句法解析
句法解析是指对句子中词语的词性进行解析[17]。例如,语句“笔者采用金水六君煎加味治疗慢性支气管炎31例,收到满意疗效,现报道如下。”进行句法解析的结果,如图2所示。
使用句法解析提取特征的步骤是:(1)提取出中药方剂与疾病之间的词语,以及与词语对应的词性;(2)中药方剂或者疾病后面是否有逗号,如果有,则提取出逗号后面紧接的短语中的词语,以及词语对应的词性;(3)去除停用词,如“的”,根据词语的词性,删除基数词、计量单位词等;(4)按照词语出现频率排序,删除出现频率较低的词语,并且对其他部分词语进行手工筛选;(5)罗列所有词语,若每句的特征中,出现对应的词语,则标注为1,否则标注为0。
4.1.2 依存解析
依存解析就是分析句子中各个词语之间的依存关系[18]。例如,语句“笔者采用金水六君煎加味治疗慢性支气管炎31例,收到满意疗效,现报道如下。”进行依存解析的结果,使用Graphviz开源软件绘制后的图形,如图3所示。
使用依存解析提取特征的步骤是:(1)找到包含中药方剂与疾病所在的子树,提取子树上的词语;(2)中药方剂或者疾病后面是否有逗号,如果有,则提取出逗号后面的第一个子树上的词语;(3)按照词语出现频率排序,删除出现频率较低的词语,并且对其他部分词语进行手工筛选;(4)罗列所有词语,若每句的特征中,出现对应的词语,则标注为1,否则标注为0。
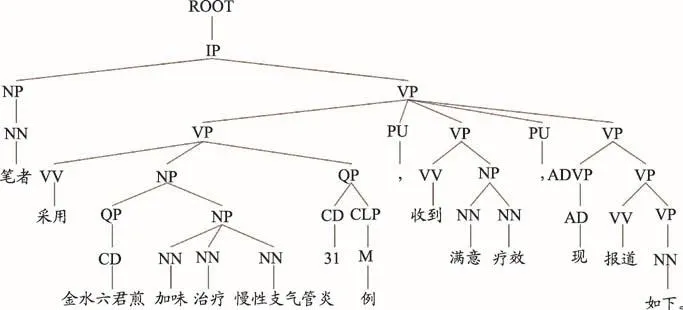
图2 句法解析结果

图3 依存解析结果
4.2 SVM模型
SVM(Support Vector Machine,支持向量机)是一个二分类器,是一种监督学习模型。监督学习是从标记样本中训练模型,然后再利用训练得到的模型对未标记样本进行映射,得到相应的输出。对摘要数据进行观察,分为三类,分别是:(1)因服用中药方剂导致副作用或者不良反应;(2)中药方剂可以治疗某些疾病;(3)中药方剂治疗某些疾病,并且收到了良好的治疗效果。由于SVM是二分类器,本实验数据有三类,这里使用一对一法,在任意两类样本之间设计一个SVM模型,所以最终一共有三个SVM模型。当对一个未知样本进行分类时候,得票最高的类别就是此样本的类别。这里使用开源的LIBSVM软件包训练SVM模型,只需将数据转换为LIBSVM所要求的格式[19]。
5 实验结果
利用中药方剂与疾病词典,筛选出同时包含方剂与疾病的语句,最终一共得到204780句。从这些语句中随机挑选一千多句,依据前面定义的类型,进行手工标注所属类别,分别用-1,0,1表示。然后按照特征提取中的步骤,分别使用句法解析与依存解析的特征提取方法,从标注数据中随机抽选80%数据集作为训练数据,20%数据集作为测试数据集,使用SVM模型进行训练,最终的结果如表1所示。

表1 SVM实验结果
采用类似的方法,对上述数据,使用决策树建立分类模型,与SVM模型作对比。这里采用WeKa数据挖掘软件进行实验,将数据转为WeKa要求的arff数据格式,并且对最终结果计算正确率,如表2所示。
从表1与表2中结果得知,使用句法解析与依存解析的方式进行特征提取,对最终训练的模型正确率有影响,且用句法解析得到的特征进行训练模型,正确率均较高。这里选用句法解析提取的特征与SVM分类模型对其他未知数据进行预测,最终得到的类别为-1、0、1 的三元组,去重后数量分别是 164,34265,25417。最终从中药方剂与疾病的关系中,能够发现如三黄片致血尿的过敏反应、复方丹参滴丸治疗冠心病、排石汤治疗泌尿系结石且效果良好。
本实验过程中,分词与特征提取步骤,均用到了Stanford NLP的相关工具,由于需要处理分析的文本内容较多,计算处理耗费的时间较长。搭建基于内存计算的Spark集群,能够加快处理速度,节省时间[20]。在本地单台机器上搭建Spark伪分布式环境,从Hadoop的HDFS读取文件,实现了Spark平台环境中运行Stanford CoreNLP。

表2 决策树实验结果
6 总结与展望
本文对中药方剂与疾病之间的关系抽取做了探索研究,通过众多国家标准以及权威书籍,构建了疾病、中药方剂、证、症状词典,能够应用于其他中医药文本数据分析中。使用不同的特征提取方法,对手工标注的数据训练SVM模型,训练的模型准确率均较高,最终可以将此模型运行于其它未标注数据上。本文实验使用的数据集保存在https://github.com/XiaohuanIT/TCM。通过实验,我们验证了Stanford CoreNLP可以与Spark数据平台结合使用。在Spark集群环境中,可以加快文本处理的速度。后续希望将关系抽取得到的关系三元组保存在关系型数据库或者非关系型数据库中,然后利用后台编程语言Java,结合前端可视化技术D3.js,做成可查询的Web系统,方便中医药科研工作人员使用。同时,依据这些关系三元组,以及方剂的具体药物组成,通过其他数据挖掘或者排序算法,可以对药物的主要治疗作用进行探索性研究。
1 Xu D,Zhang M,Xie Y,et al.DTMiner:Identification of potential disease targets through biomedical literature mining.Bioinformatics,2016,32(23):3619-3626.
2 Sampathkumar H,Chen X,Luo B.Mining adverse drug reactions from online healthcare forums using hidden Markov model.Bmc Med Inform Decis Mak,2014,14(1):91.
3 Nikfarjam A,Sarker A,O'Connor K,et al.Pharmacovigilance from social media:mining adverse drug reaction mentions using sequence labeling with word embedding cluster features.J Am Med Inform Assoc,2015,22(3):671-681.
4 姚美村,袁月梅,艾路,等.数据挖掘及其在中医药现代化研究中的应用.北京中医药大学学报,2002,25(5):20-23.
5 段利国,徐庆,李爱萍,等.实体词语义信息对中文实体关系抽取的作用研究.计算机应用研究,2017,34(1):141-146.
6 Lin Y,Shen S,Liu Z,et al.Neural relation extraction with selective attention over instances,54th Annual Meeting of the Association for Computational Linguistics,ACL,2016.Stroudsburg:Association for Computational Linguistics,2016:2124-2133.
7 Zhou D,Zhong D,He Y.Biomedical Relation Extraction:From Binary to Complex.Comput Math Methods Med,2014,2014(1):298473.
8 Fang Y C,Huang H C,Chen H H,et al.TCMGeneDIT:a database for associated traditional Chinese medicine,gene and disease information using text mining.BMC complement Altern Med,2008,8(1):58.
9 徐健,张智雄,吴振新.实体关系抽取的技术方法综述.现代图书情报技术,2008,(8):18-23.
10秦兵,刘安安,刘挺.无指导的中文开放式实体关系抽取.计算机研究与发展,2015,52(5):1029-1035.
11 Zhou X,Liu B,Wu Z,et al.Integrative mining of traditional Chinese medicine literature and MEDLINE for functional gene networks.Artif Intell Med,2007,41(2):87-104.
12 Wan H,Moens M F,Luyten W,et al.Extracting relations from traditional Chinese medicine literature via heterogeneous entity networks.J Am Med Inform Assn,2016,23(2):356-365.
13 Wong C I,Wong K Y,Ng K,et al.Design of a crawler for online social networks analysis.Wseas Trans Commun,2014,3:264-274.
14宗成庆.统计自然语言处理(第2版).北京:清华大学出版社,2013.
15 Chang P C,Galley M,Manning C D.Optimizing Chinese word segmentation for machine translation performance,Proceedings of the third workshop on statistical machine translation.Acl,2008:224-232.
16 Chen,Danqi,Christopher D.Manning.A Fast and Accurate Dependency Parser using Neural Networks,2014 Conference on Empirical Methods in Natural Language Processing.Acl,2014:740-750.
17 Pinter Y,Reichart R,Szpektor I.Syntactic parsing of web queries with question intent,15th Conference of the North American Chapter of the Association for Computational Linguistics:Human Language chnologies.A C L,2016:670-680.
18 McDonald R T,Pereira F.Online Learning of Approximate Dependency Parsing Algorithms,11th Conference of the European Chapter of the Association for Computational Linguistics.ACL,2006:81-88.
19 Chang C C.and Lin C J.LIBSVM:a library for support vector machines.Acm Tist,2011,2(3),27:1-27.
20王亚玲,刘越,洪建光,等.基于Spark/Shark的电力用采大数据OLAP分析系统.中国科学技术大学学报,2016,46(1):66-75.
Relation Extraction of Traditional Chinese Medicine Prescription and Disease Based on LiteratureAbstracts Data
Yang Xiaohuan1,Shan Yahui1,Xie Dan1,Li Xiaodong2
(1.College of Information Engineering,Hubei University of Chinese Medicine,Wuhan 430065,China;2.Hubei Province Chinese Medicine Hospital,Wuhan 430061,China)
This paper studied the correlation between traditional Chinese medicine(TCM)prescription and disease based on machine learning.This paper selected TCM literature abstract data in the TCM category of the China National Knowledge Infrastructure(CNKI)database by crawler technology.After data cleaning,lexicon building,word segmentation and other related basic pre-treatment work,it uses natural language processing technique to extract the feature of the web text data,constructs the Support Vector Machine(SVM)classification model,and extracts the relation between TCM prescription and disease.The results showed that among 1073581 abstracts,204780 sentences,which included both TCM prescription and the disease according to dictionaries,were filtered.The SVM classification model whose feature is constructed by constituency parser is in a better accuracy,which achieved 87%.Applying the SVM model in filtered sentences,this study obtained the relation triples between TCM prescription and the disease.It was concluded that by using the method of machine learning to extract relation on abstract data from the CNKI database,the extracted relation triples of TCM prescription and disease will take a positive effect on the research of disease treatment by TCM prescription.
Relation extraction of traditional Chinese medicine prescription and disease Relation extraction of traditional Chinese medicine prescription and disease,data extraction,traditional Chinese medicine data extraction,web crawler technology
10.11842/wst.2017.07.012
R-33
A
2017-03-12
修回日期:2017-07-11
* 老年病中药新产品湖北省协同创新中心项目(No.201506):湖北省中医老年病数据资源管理平台构建研究,负责人:解丹;国家中医药管理局中医临床研究基地业余建设科研专项课题(No.JDZX2012051):中医治疗慢性乙型肝炎真实世界效果比较研究,负责人:李晓东。
** 通讯作者:解丹,副教授,硕士生导师,主要研究方向:医学数据挖掘。
(责任编辑:韩馥蔓,责任译审:王 晶)
