基于多分类AdaBoost改进算法的TEE标准切面分类
2017-10-21王莉莉付忠良
王莉莉,付忠良,陶 攀,朱 锴
(1.中国科学院 成都计算机应用研究所,成都 610041; 2.中国科学院大学,北京 100049)
(*通信作者电子邮箱wanglili8773@163.com)
基于多分类AdaBoost改进算法的TEE标准切面分类
王莉莉1,2*,付忠良1,2,陶 攀1,2,朱 锴1,2
(1.中国科学院 成都计算机应用研究所,成都 610041; 2.中国科学院大学,北京 100049)
(*通信作者电子邮箱wanglili8773@163.com)
针对超声图像样本冗余、不同标准切面因疾病导致的高度相似性、感兴趣区域定位不准确问题,提出一种结合特征袋(BOF)特征、主动学习方法和多分类AdaBoost改进算法的经食管超声心动图(TEE)标准切面分类方法。首先采用BOF方法对超声图像进行描述;然后采用主动学习方法选择对分类器最有价值的样本作为训练集;最后,在AdaBoost算法对弱分类器的迭代训练中,根据临时强分类器的分类情况调整样本更新规则,实现对多分类AdaBoost算法的改进和TEE标准切面的分类。在TEE数据集和三个UCI数据集上的实验表明,相比AdaBoost.SAMME算法、多分类支持向量机(SVM)算法、BP神经网络和AdaBoost.M2算法,所提算法在各个数据集上的G-mean指标、整体分类准确率和大多数类别分类准确率都有不同程度的提升,且比较难分的类别分类准确率提升最为显著。实验结果表明,在包含类间相似样本的数据集上,分类器的性能有显著提升。
多分类AdaBoost;主动学习;特征袋模型;标准切面分类;超声图像分类
0 引言
目前,经食管超声心动图(TransEsophageal Echocardiography, TEE)已被广泛应用于各种心脏疾病的诊断和术中监测中,不同的标准切面在疾病诊断中起着不同的作用。近年来,研究者们采用监督学习的方法对标准切面进行自动识别[1-4],文献[5]基于尺度不变特征转换(Scale Invariant Feature Transform, SIFT)特征和稀疏编码构造超声心动图视频词典,构建词袋(Bag of Words, BOW)模型,通过多类别支持向量机(Support Vector Machine, SVM)实现多个标准切面的自动识别。文献[6]把不同的标准切面看作不同的人脸目标,通过手动定位出左心室位置来调整数据,使用多分类Boosting算法提取Harr-like特征,实现了对二维超声心动图标准切面分类。文献[7]基于知识库方法,采用Probabilistic Boosting Tree (PBT) 检测器,使用Harr-like 特征,采取由粗到细策略实现标准切面的识别,进而实现三维超声心动图标准切面的自动检测。
不同病人心脏大小不同,不同疾病造成的心脏形状、腔室轮廓不同,且超声图像的对比度和分辨率较低,夹杂斑点噪声,这些都使得感兴趣区域(Region of Interest, ROI)的自动分割非常困难,也会影响全局特征的提取,并进一步影响到分类性能。特征袋(Bag of Features, BOF)[8-9]是一种高层语义特征,能够避免ROI定位不准确问题, BOF模型采用加速鲁棒特征(Speeded Up Robust Feature, SURF)[10]算法提取局部特征,与SIFT特征相比,SURF算法执行效率更高,在医疗领域中也取得了一些成果[11-12]。
超声图像容易出现大量的样本冗余问题,训练集样本的选择对分类器的分类性能影响很大。主动学习的思想最初是用来解决无标记样本数量大、且标记代价高的问题,其本质是有效的样本选择策略。文献[13]采用主动学习方法构造平衡的训练集,并提出了一种基于SVM的主动学习样本选择策略,能用较少的样本获得较高的分类性能;但是主动学习需要迭代多次选择最有价值的样本,进行多次模型训练,而SVM的非线性模型优化过程对计算和存储要求太高。AdaBoost (Adaptive Boosting)算法[14]是一种集成学习方法,可以将重心放在ROI特征上,避免背景区域特征影响分类器性能。因此可以考虑将BOF模型、主动学习方法和AdaBoost算法进行结合,实现图像描述、训练集样本选择和分类器模型构建。
标准切面自动识别问题属于典型的多分类问题,多分类问题的解决方法主要包括两种类型:一种是将多分类问题分解为多个二分类问题;另一种是直接修改算法,使之能适应多分类问题。多分类SVM算法[15]是采用分解法把多分类问题分解为二分类问题,将二分类SVM扩展到多类别分类问题中;AdaBoost.M2算法[16]采用一对一分解策略,将二分类AdaBoost扩展到多分类问题中;AdaBoost.SAMME算法[17]是采用CART、C4.5等能直接解决多分类问题的算法作为弱分类器,将二分类AdaBoost算法直接推广到多分类问题中。标准切面识别中,因疾病类型不同,类间样本存在一定的相似性,影响分类器性能。对于相似性高的标签给予不同的错分代价,可将标签相似问题转化为代价敏感问题解决。文献[18-19]在AdaBoost算法中引入标签相关性,对弱分类器构造方法和权重调整规则进行改进。本文在多分类AdaBoost算法对弱分类器的迭代训练中,综合已训练所得的临时强分类器的分类情况,动态调整样本的错分代价,对多分类 AdaBoost算法进行改进,能综合提高标准切面的分类性能。
1 TEE标准切面识别
在疾病诊断中最基本且最常用的三个标准切面是四腔心(four Chamber, 4C)、右室流入流出道(Right Ventricle Inflow-Outflow, RV IO)和左室长轴(Left ventricular long AXis, LAX),如图1所示。图像包括背景区域和ROI区域,为避免ROI定位不准确问题,本文采用BOF模型完成对超声图像的特征描述,最后采用多分类AdaBoost改进算法构建分类器对标准切面进行分类。

图1 疾病诊断中最基本的三个标准切面Fig. 1 The three most basic standard planes in disease diagnosis
1.1 图像预处理
仪器采集的超声图像的四周,包含仪器自身所标注的文字、图标等相关信息,为便于后续步骤中特征提取,采用形态学滤波方法提取出包含有效信息的超声子图。式(1)~(4)为自定义掩膜。
(1)
(2)
(3)
(4)
采用形态学掩膜mask1和mask2进行滤波,则在经食管超声图像左侧边缘处和右侧边缘处得到的结果最大;然后采用掩膜mask3和mask4进行滤波,则在两个直角边缘处得到结果最大。如图2(a)所示为四腔心切面原图,图2(b)所示是对图2(a)预处理后的结果。

图2 图像预处理结果Fig. 2 Image preprocessing results
1.2 BOF模型构建
BOF的基本思想是将图像看作相互独立的图像块的集合,为每个图像块提取描述向量;对训练集的特征向量进行聚类,生成一个包含视觉单词的词典;根据词典对图像中的描述向量进行加权统计,生成特征直方图向量,该向量即代表整个图像,完成对图像的特征表达。
BOF构建过程主要涉及以下步骤:
1)检测图像块并生成描述向量。检测图像块的常见方法有密集采样法、随机采样法和网格划分法等,本文使用网格划分法。常见的描述算子有SIFT、PCA-SIFT (Principal Components Analysis-Scale Invariant Feature Transform)和SURF等,本文使用SURF描述算子。
2)应用聚类算法将图像块描述算子聚类为视觉词汇,常见的聚类算法有K-means等。
3)使用一种加权策略,如TF-IDF(Term Frequency-Inverse Document Frequency)加权技术,将图像的描述算子映射到视觉词汇中,然后进行步加权、归一化。
1.3 基于主动学习方法的训练集选择
TEE标准切面存在大量的冗余样本,采用主动学习方法进行样本选择。对于AdaBoost算法采用基于Margin策略的不确定性来选择训练集样本,如式(5)所示:

(5)
基于Margin策略的训练集样本选择流程:
输入 有标注样本集X={(x1,y1),(x2,y2),…,(xm,ym)},其中yi∈{1,2,…,K},初始训练集L1,非训练集U1=XL1;
Fork=1,2,…,iter
1)
在训练集Lk上训练多分类AdaBoost分类器f;
2)
用分类器f对非训练集Uk中样本预测,如果分类模型满足停止条件,循环终止;
3)
对Uk中每个样本计算f(x,l1)-f(x,l2),l1和l2分别是最具有最大和第二大值的置信度输出值,选择最小的N个样本,记为S;
4)
更新Lk+1=Lk∪S,Uk+1=UkS;
End
输出 训练集L。
2 多分类AdaBoost改进算法
2.1 多分类AdaBoost改进算法原理
训练样本集L={(x1,y1),(x2,y2),…,(xn,yn)},其中yi∈{1,2,…,K},集成学习算法通常指通过某种方式得到T个弱分类器ht(x):X×Y→[0,1]和弱分类器权重αt,然后进行组合得到强分类器,即:
(6)
强分类器的输出为:
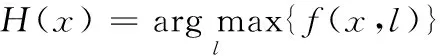
(7)
训练到第t个弱分类器时,可以得到临时强分类器:
(8)
调用ft临时强分类器对训练样本集X进行分类,若标签yi被错分为标签l的概率Pt(yi,l)>thresh(阈值),则可以认为标签l是标签yi的相似标签,此时令St(yi,l)=1,否则St(yi,l)=0,如此可得标签相似性矩阵St。如果标签l是标签yi的相似标签,令ct(yi,l)=c2,否则令ct(yi,l)=c1,如此可得动态代价矩阵Ct。
分类算法总是希望平均错分代价最小,即希望式(9)最小:
(9)
其中:当条件π满足时,δ(π)为1,否则为0;c(yi,l)表示标签为yi的样本xi错分为l的代价。假设权重更新参数αt>0,结合动态代价矩阵得到改进的多分类AdaBoost算法如下:
输入 训练样本集L={(x1,y1),(x2,y2),…,(xn,yn)},样本权重D,弱分类器h:X×Y→R,迭代次数T;
初始化: D1(i)=1/n,其中i=1,2,…,n;
Fort=1,2,…,T
1)
根据样本分布Dt,训练弱分类器ht:X×Y→R。
2)
根据临时强分类器:
计算动态标签相似性矩阵St,若t=1,则令S1=I(K×K),I(K×K)为K阶单位矩阵。
3)
对动态代价矩阵Ct赋值:若l≠yi,且St(yi,l)=1,则令ct(yi,l)=c2,否则ct(yi,l)=c1,其中c1,c2>0。
4)
计算弱分类器权重αt。
5)
更新权重:
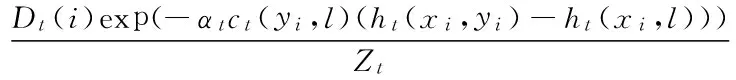
其中:

2.2 训练误差有界性验证
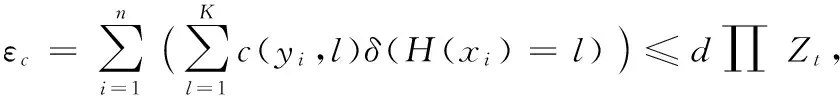
证明 根据权值更新公式可得:
DT(i)=
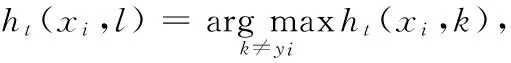


故有:
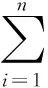
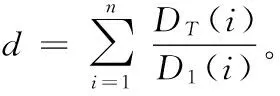
2.3 计算弱分类器权重αt
假设ht:X×Y→R,根据文献[15]的证明,由于:

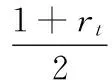

2.4 错分代价动态性
本文算法根据临时强分类器的分类情况,可以获得动态的标签相似矩阵,在权值更新中,需要根据标签相似矩阵和c1,c2>0的值对错分代价矩阵Ct进行动态赋值。
3 实验结果与分析
3.1 实验数据集
本文实验使用TEE标准切面数据集和三个UCI数据集。其中,TEE数据集中所有图像来自华西医院麻醉科,大多数均是患有疾病的超声图像,图像采集数据以视频格式存在,选取视频中能包含一个心动周期的连续6~7帧图像作为图像样本集,为避免重叠,测试集和训练集分别来自不同的视频。实验数据详细情况如表1所示。
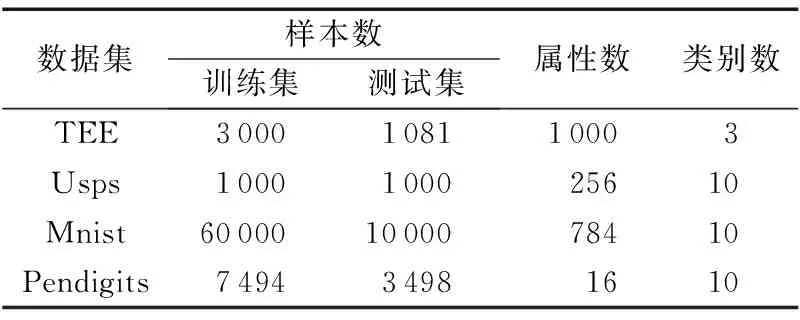
表1 实验数据集Tab. 1 Experimental data sets
3.2 在TEE数据集上的实验结果与分析
3.2.1 训练集选择
初始训练集L1的选择:在全部训练集上训练多分类AdaBoost分类器f,然后调用分类器f对训练集中全部样本进行预测,对每个样本计算f(x,l1)-f(x,l2),其中l1和l2分别是最具有最大和第二大值的置信度输出值,对每个类别选择f(x,l1)-f(x,l2)值最小的100个样本,共得到300个样本作为初始训练集。
训练集选择过程:每次迭代选择20个最有价值的样本加入训练集,共迭代50次,或满足停止条件。
4C、RV IO和LAX的原始训练集样本数均为1 000,新的训练集样本数分别为300、320和340。
3.2.2 实验设置
本文在实验过程中采用stump决策树作为弱分类器,共训练30个弱分类器。主要对以下两个方面进行实验: 1)参数thresh、c1和c2的选择; 2)本文算法与AdaBoost.M2算法(简写为Ada.M2)、多分类SVM算法、AdaBoost.SAMME算法(简写为Ada.SAMME)、BP神经网络(简写为BP-Net)算法进行比较。
在对参数thresh、c1和c2的最优选择实验时,在[0.01,0.3]区间内以步长0.01变化,动态错分代价矩阵中c1、c2值的确定通过征集10位医学专家的意见,得到了10个不同的c1、c2值,通过升序排列,形成一个[0.1,10]的错分类代价区间。在实验时认为对于任何属于[0.1,10]区间里的c1、c2都是可行的,步长设为0.1。
3.2.3 性能评价指标
本文采用G-mean指标、Accuracy和各类别的分类准确率评价分类器的性能。
令ni表示属于类别li的样本总数,K为类别个数,cm(li,lj)表示类别为li的样本被判断为类别lj的个数,则类别li的分类准确率可定义为:

G-mean定义为:
Accuracy定义为:
3.2.4 实验对比结果
通过实验可知,当thresh=0.03,c1=6.9,c2=1.3时总体识别性能最优,此时与Ada.M2算法、多分类SVM算法、AdaBoost.SAMME算法、BP-Net进行比较,每个类别的分类准确率和整体分类准确率如表2所示。
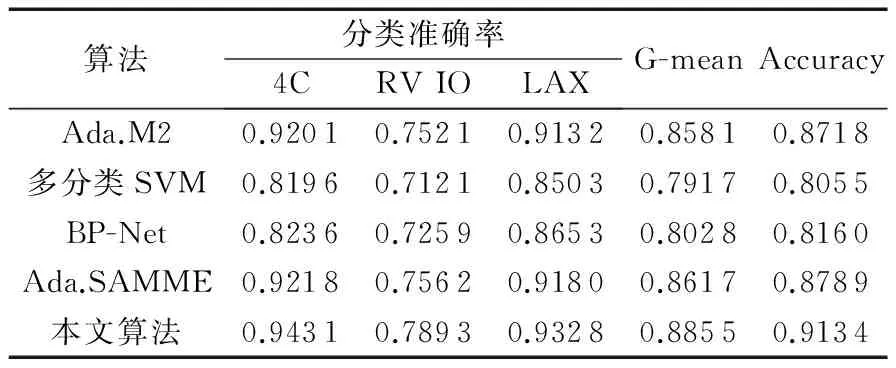
表2 分类性能对比Tab. 2 Comparison of classification performance
从表2可以看出,本文算法的各个类别分类准确率、G-mean指标和Accuracy都是最优的。多分类SVM和BP-Net算法性能较低,BP-Net算法稍好于多分类SVM算法。这是因为这两种算法的性能直接跟样本特征值相关,将超声图像的背景区域特征和ROI区域特征同等看待,而背景区域占据图像比例较大,影响了分类器的性能。AdaBoost.M2算法和Ada.SAMME算法在模型构建中会选择比较重要的特征,突出ROI区域特征、削弱背景区域特征对分类器的影响,两种算法性能不相上下,Ada.SAMME算法略胜一筹。相比Ada.SAMME算法,本文算法的Accuracy提升了3.93%,G-mean指标提升了2.76%,4C准确率提升了2.31%,RV IO准确率提升了4.38%,LAX准确率提升了1.61%;相比BP-Net算法,本文算法的Accuracy提升了11.94%,G-mean指标提升了10.3%,4C准确率提升了14.51%,RV IO准确率提升了8.73%,LAX准确率提升了7.8%。
3.3 在UCI数据集上的实验结果与分析
另外对本文算法在三个UCI数据集上进行实验,包括Usps数据集、Mnist数据集和Pendigits数据集,这三个数据集都是对手写数字0~9进行识别。如表3所示是本文算法与其他四个对比算法在三个数据集上的G-mean指标和Accuracy对比结果。可以看出本文算法在三个UCI数据集上的G-mean值和Accuracy均是最优的,而其他四个对比算法中Ada.M2算法性能较优。
相比Ada.M2算法,在Usps数据集上,本文算法的G-mean值提升了1.5%,Accuracy提升了1.18%;在Mnist数据集上,本文算法的G-mean值提升了1.67%,Accuracy提升了1.94%;在Pendigits数据集上,本文算法的G-mean值提升了2.17%,Accuracy提升了1.72%。
相比多分类SVM算法,在Usps数据集上,本文算法的G-mean值提升了3.59%,Accuracy提升了3.28%;在Mnist数据集上,本文算法的G-mean值提升了3.66%,Accuracy提升了3.55%;在Pendigits数据集上,本文算法的G-mean值提升了3%,Accuracy提升了2.89%。
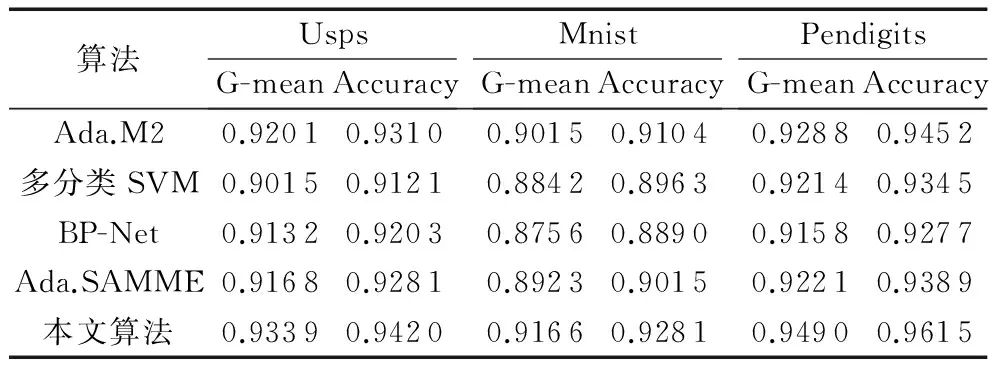
表3 在三个UCI数据集上的G-mean和Accuracy对比Tab. 3 Comparison of G-mean and Accuracy on three UCI data sets
本文算法与Ada.M2算法对各个类别的分类准确率对比结果如表4所示。
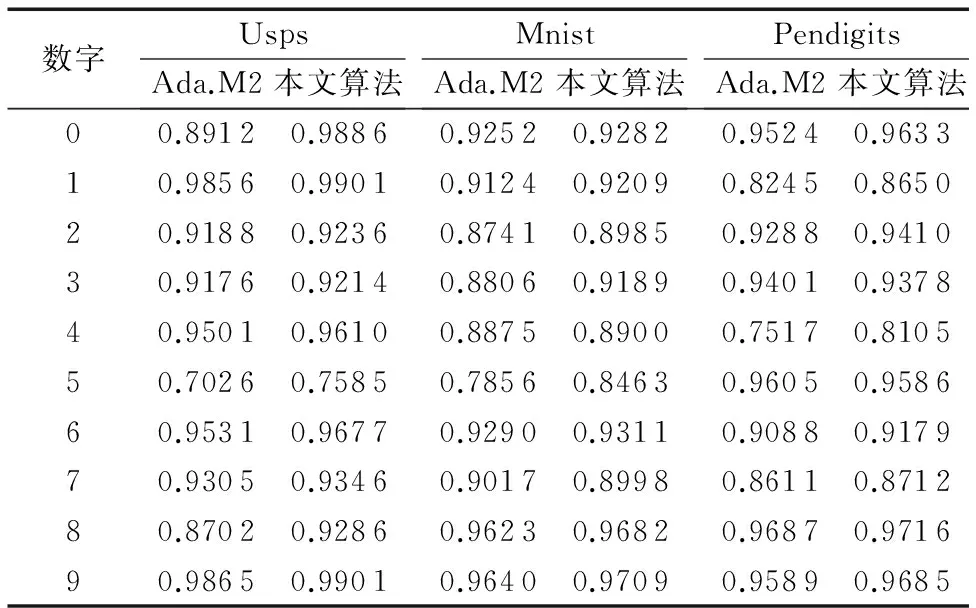
表4 本文算法与Ada.M2算法对各类别的分类准确率对比Tab. 4 Classification accuracy comparison of each class by using proposed algorithm and Ada.M2
表4数据表明,与Ada.M2算法相比,本文算法在三个UCI数据集上对各个类别的分类准确率都有一定程度的提升,其中较难分类的类别有显著的提升。Usps数据集中数字5的准确率提升了7.96%,数字8的准确率提升了6.71%左右;Mnist数据集中数字5提升了7.73%左右;Pendigits数据集中数字1提升了4.91%,数字4提升了7.82%。
4 结语
本文结合BOF模型、主动学习方法和动态错分代价矩阵对TEE标准切面进行分类。首先采用BOF模型完成超声图像的特征描述,BOF模型能突出ROI区域特征,削弱背景区域特征,避免ROI定位不准确问题;然后采用主动学习方法选择对分类器最有价值的样本作为训练集,消除样本冗余;最后对多分类AdaBoost算法进行改进。改进算法在每个弱分类器的训练中都会将已经训练得到的弱分类器集成为临时强分类器,根据临时强分类器的性能为不同类别的样本赋予不同的错分代价,调整权重更新规则,强迫正在训练的弱分类器“关注”错分代价较高的样本。在TEE标准切面数据集上的实验结果表明,本文算法的Accuracy、G-mean指标和各个类别的分类准确率均优于AdaBoost.SAMME算法及其他常用的多类别分类算法。在三个UCI数据集上的实验结果表明,本文算法在各个数据集上的Accuracy和G-mean指标均优于AdaBoost.M2算法,在易分错的类别上提升效果更显著。实验分析表明:在存在类间相似样本的数据集上,或者存在“难分”类别的数据集上,本文算法的提升效果最为显著。
References)
[1] EBADOLAHI S, CHANG S F, WU H. Automatic view recognition in echocardiogram videos using parts based representation [C]// CVPR 2004: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004, 2: 2-9.
[2] RAHMATULLAH B, PAPAGEORGHIOU A, NOBLE J A. Automated selection of standardized planes from ultrasound volume [C]// MLMI 2011: Proceedings of the 2011 International Workshop on Machine Learning in Medical Imaging, LNCS 7009. Berlin: Springer-Verlag, 2011: 35-42.
[3] PARK J H, ZHOU S K, SIMOPOULOS C, et al. Automatic cardiac view classification of echocardiogram [C]// ICCV 2007: Proceedings of the 2007 11th IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2007: 1-8.
[4] 王勇,吕扬生.基于纹理特征的超声医学图像检索[J].天津大学学报,2005,38(1):57-60. (WANG Y, LYU Y S. Retrieval of medical ultrasound image based on texture feature [J]. Journal of Tianjin University, 2005, 38(1): 57-60.)
[5] QIAN Y, WANG L, WANG C, et al. The synergy of 3D SIFT and sparse codes for classification of viewpoints from echocardiogram videos [C]// MCBR-CDS 2012: Proceedings of the 2012 MICCAI International Workshop on Medical Content-Based Retrieval for Clinical Decision Support, LNCS 7723. Berlin: Springer-Verlag, 2012: 68-79.
[6] ZHOU S K, PARK J H, GEORGESCU B, et al. Image-based multiclass boosting and echocardiographic view classification [C]// CVPR 2006: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2006, 2: 1559-1565.
[7] LU X, GEORGESCU B, ZHENG Y, et al. AutoMPR: Automatic detection of standard planes in 3D echocardiography [C]// ISBI 2008: Proceedings of the 2008 5th International Symposium on Biomedical Imaging: From Nano to Macro. Piscataway, NJ: IEEE, 2008: 1279-1282.
[8] ZHOU L, ZHOU Z, HU D. Scene classification using a multi-resolution bag-of-features model [J]. Pattern Recognition, 2013, 46(1): 424-433.
[9] 梁晔,于剑,刘宏哲.基于BoF模型的图像表示方法研究[J].计算机科学,2014,41(2):36-44. (LIANG Y, YU J, LIU H Z. Study of BOF model based image representation [J]. Computer Science, 2014, 41(2): 36-44.)[10] LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories [C]// CVPR 2006: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2006, 2: 2169-2178.
[11] BAY H, TUYTELAARS T, GOOL L V. SURF: Speeded Up Robust Features [C]// ECCV 2006: Proceedings of the 2006 European Conference on Computer Vision, LNCS 3951. Berlin: Springer-Verlag, 2006: 404-417.
[12] SHEN L, LIN J, WU S, et al. HEp-2 image classification using intensity order pooling based features and bag of words [J]. Pattern Recognition, 2014, 47(7): 2419-2427.
[13] ERTEKIN S, HUANG J, GILES C L. Active learning for class imbalance problem [C]// SIGIR 2007: Proceedings of the 2007 30th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2007: 823-824.
[14] SCHAPIRE R E, SINGER Y. Improved boosting algorithms using confidence-rated predictions [J]. Machine Learning, 1999, 37(3): 297-336.
[15] WU T-F, LIN C-J, WENG R C. Probability estimates for multi-class classification by pairwise coupling [J]. Journal of Machine Learning Research, 2004, 5: 975-1005.
[16] GURUSWAMI V, SAHAI A. Multiclass learning, boosting, and error-correcting codes [C]// COLT 1999:Proceedings of the Twelfth Annual Conference on Computational Learning Theory. New York: ACM, 1999: 145-155.
[17] ZHU J, ZOU H, ROSSET S, et al. Multi-class Adaboost [J]. Statistics and Its Interface, 2009, 2(3): 349-360.
[18] FU Z, WANG L, ZHANG D. An improved multi-label classification ensemble learning algorithm [C]// CCPR 2014: Proceedings of the 2014 Chinese Conference on Pattern Recognition, CCIS 483. Berlin: Springer-Verlag, 2014: 243-252.
[19] 王莉莉,付忠良.基于标签相关性的多标签分类AdaBoost算法[J].四川大学学报(工程科学版),2016,48(5):91-97. (WANG L L, FU Z L. Multi-label AdaBoost algorithm based on label correlations [J]. Journal of Sichuan University (Engineering Science Edition), 2016, 48(5): 91-97.)
This work is partially supported by the Sichuan Science and Technology Support Project (2016JZ0035), the West Light Project of the Chinese Academy of Sciences.
WANGLili, born in 1987, Ph. D. candidate. Her research interests include machine learning, pattern recognition, data mining.
FUZhongliang, born in 1967, M. S., professor. His research interests include machine learning, pattern recognition.
TAOPan, born in 1988, Ph. D. candidate. His research interests include machine learning, data mining.
ZHUKai, born in 1991, Ph. D. candidate. His research interests include machine learning, data mining.
TEEstandardplaneclassificationbasedonimprovedmulti-classAdaBoostalgorithm
WANG Lili1,2*, FU Zhongliang1,2, TAO Pan1,2, ZHU Kai1,2
(1.ChengduInstituteofComputerApplication,ChineseAcademyofSciences,ChengduSichuan610041,China;2.UniversityofChineseAcademyofSciences,Beijing100049,China)
Due to redundancy of ultrasound image samples, high similarity between different planes caused by disease, and inaccurate positioning of region-of-interest, a classification method of TransEsophageal Echocardiography (TEE) standard plane was proposed by combining with Bag of Features (BOF) model, active learning and improved multi-class AdaBoost algorithm. Firstly, BOF model was constructed to describe ultrasound image. Secondly, active learning was adopted to select the most informative samples for classifiers as training data set. Lastly, improved multi-class AdaBoost algorithm was proposed, where the weight update rule of multi-class AdaBoost was modified according to the classfication results of temporary strong learner, and the TEE standard plane was classified by the improved multi-class AdaBoost algorithm. The experimental results on TEE data set and three UCI data sets showed that, compared with AdaBoost.SAMME, multi-class Support Vector Machine (SVM), BP neural network and AdaBoost.M2, the G-mean value, the total classification accuracy and the classification accuracy in most classes of the proposed method were improved in varying degrees, the classification accuracy of easily misclassified class was improved most significantly. The experimental results illustrate that the improved multi-class AdaBoost algorithm can significantly improve the G-mean value and accuracy of easily misclassified class in the datasets containing similar samples between classes.
multi-class AdaBoost; active learning; Bag of Features (BOF) model; standardized plane classification; ultrasound image classification
TP391.4; TP181
A
2017- 03- 01;
2017- 04- 12。
四川省科技支撑计划项目(2016JZ0035);中国科学院西部之光项目。
王莉莉(1987—),女,河南周口人,博士研究生,主要研究方向:机器学习、模式识别、数据挖掘; 付忠良(1967—),男,重庆合川人,教授,硕士,主要研究方向:机器学习、模式识别; 陶攀(1988—),男,河南安阳人,博士研究生,主要研究方向:机器学习、数据挖掘; 朱锴(1991—),男,贵州安顺人,博士研究生,主要研究方向:机器学习、数据挖掘。
1001- 9081(2017)08- 2253- 05
10.11772/j.issn.1001- 9081.2017.08.2253
