分层聚类在土地利用中的应用
2017-10-18赵国富
赵国富
(山东理工大学网络信息中心,淄博 255049)
分层聚类在土地利用中的应用
赵国富
(山东理工大学网络信息中心,淄博 255049)
通过分析分层聚类法理论基础,实现分层聚类算法。运用分层聚类算法研究土地利用变化,通过多次尝试、比较不同的距离变量,得到较好的结果,验证聚类结果的正确性,提高算法结果的有用性。
聚类分析;土地利用;分层聚类
0 引言
当前,土地科研工作者对于土地利用的研究不断采用更先进的技术方法,所得到的结果也越来越能反映陆地的表层(岩石、岩石的风化物和土壤)的实际情况。当前很多工作者选用聚类分析的策略,其中分层聚类算法是常用的一种技术方法。根据计算类别间距离的不同,构成了不同的分层聚类方法[1]。通过研究、比较分层聚类的类别间不同的距离,参照实际的土地状况,可以得到较好的结果,可以为进一步改善我国土地利用、保护土地资源提出更好的策略。
1 分层聚类方法理论基础
1.1 数据矩阵
分析数据,可以从原始数据开始,对原始数据对象展开调查、研究,分析有用的主要成分,形成所需要的有效数据,并将每一个有效数据对象作为矩阵的变量,置于相应的行列位置。所以,可用p个变量来表示n个对象,将这种数据结构看成如下n×p的数据矩阵[2]:

在这个数据矩阵中,往往因为各个变量可以选用不同的度量单位,而不同的度量值经常导致观测值有一定偏差,所以需要对度量值进行绝对值转换,以减小变量的不同带来的具体影响。
1.2 聚类统计量
在统计中,聚类具有不可替代的作用,通常选用群重心、群中心、群间距离中的一种作为聚类统计量进行统计。在聚类分析过程中,聚类统计量的选取较为关键。如果选取不尽合理,可能导致错误的结论。对于空间聚类,聚类统计量通常采用欧氏距离[2]。
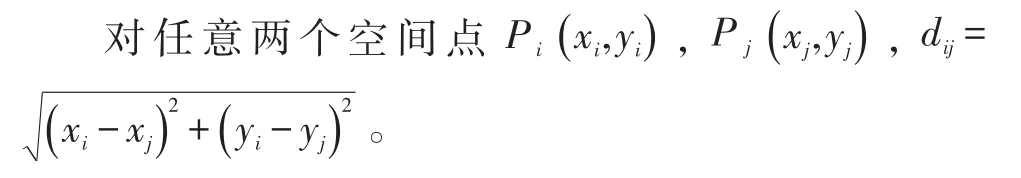
1.3 相异度矩阵

聚类算法一般是建立在相异度矩阵的基础上。将数据矩阵转化为相异度矩阵,表示对象与对象之间的关系紧密程度,即相似度或相异度,表现形式是一个n×n维的矩阵[2]:对象i和j越相似,d()i,j值就越接近0,所以相异度矩阵能够充分地表示出各分类对象间的相似度,作为基础数据用于进行聚类分析。为了确保各变量在分析中的作用相同,需要对分析数据进行中心化和标准化变换[3]
2 分层聚类方法的实现
顾名思义,分层聚类就是对给定的数据按层次进行划分,直到满足要求的条件结束。该方法可以是基于距离的或基于密度或连通性的,有“自底向上”和“自顶向下”两种。
通过分析具体数据,选择“自底向上”分层聚类法较为合理,其实现过程为[1]:
(1)将初始的n各数据对象分别作为一个类别,将原始数据矩阵做相应处理,生成一个距离矩阵;
(2)分析该距离矩阵,将距离最小的两个数据对象归并,生成了n-1个类别的新的距离矩阵;
(3)迭代第二步,直到所有的数据都满足条件,这时意味着生成一新的类别。
分层聚类法的计算主要是“起初聚类统计量的计算”和“统计量在类别合并过程中的刷新”[4]。
3 分层聚类方法的应用
为适应经济全球化的大趋势,依据《土地利用现状分类》(GB/T 21010-2007),要求各省(区、市)农业部门会同国土资源部门的土地工作者有效科学地规划土地,合理利用土地,对土地的管理达到最优,所以迫切需要一些切实可行的技术方法,为土地决策者提供有力的技术支持。算法以各省(区、市)的农用地的利用现状(2006)为基础数据。通过分析,在各因素中农用地(如牧草地、建筑用地、未利用土地等)因素分布变化较大,需合理选取农用地分析因素算法的变量,用于分层聚类方法生成符合需求的聚类。通过综合分析,算法选用幅员面积、农用地、建筑用地和未利用地四个方面进行处理[5]。
(1)数据处理
对原始数据对象进行中心化和标准化变换,生成的相异度矩阵,如表1所示。
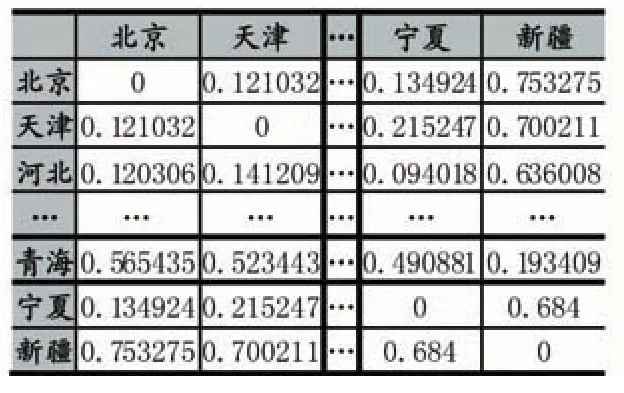
表1 相异度矩阵
(2)聚类分析过程
对土地利用进行的分层聚类算法的分类结果显示以离差平方和法较为合理[5],其聚类过程如表2所示。
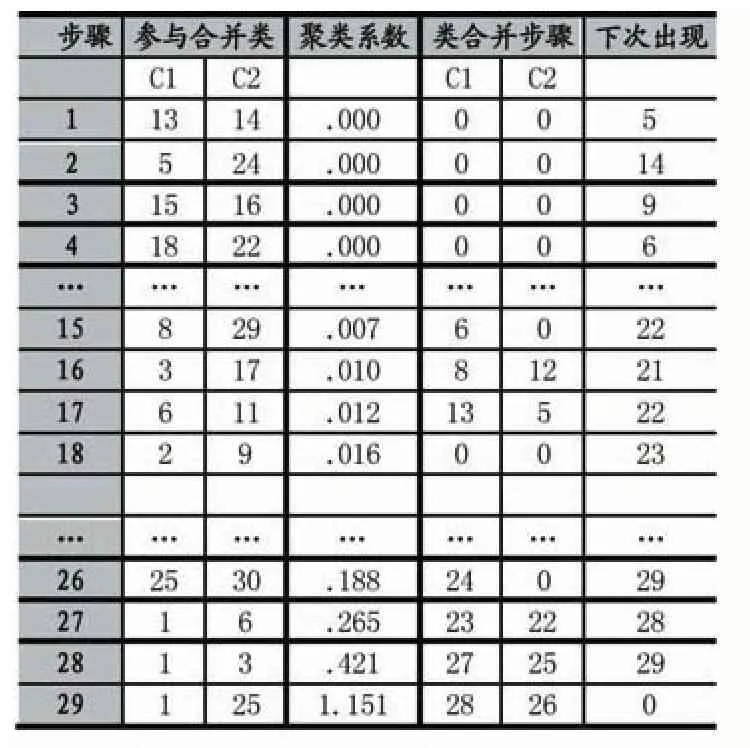
表2 聚类过程
由表2,第1列表示聚类过程的步骤号,第2列和第3列表示在某一步骤中参与合并的省市,第4列表示每一步聚类的聚类系数,第5列和第6列表示合并的省(市)初次出现在哪一步。在聚类过程中,一个记录代表的是一个类别,0代表该记录在聚类过程中第初次出现。根据聚类系数的变化,聚类过程共进行了29步。
(3)实验结果
根据我国土地资源的基本状况,聚类结果应满足各省(区、市)的农业发展规划和土地利用规划,尽可能反映各地实际情况,为土地工作者提供具有价值的聚类数据,以进一步对各省(区、市)的农业发展规划和土地利用规划提供决策,达到不断改进规划,更好的利用土地资源的目的。综合考虑30个省(市)土地资源的地方差异,将试验结果分为4类比较合理如下:
第一类:北京、天津、上海、江苏、安徽、山东、河南;
第二类:河北、山西、内蒙古、湖北、广东、广西、海南、贵州、云南、陕西;
第三类:辽宁、吉林、黑龙江、浙江、福建、江西、湖南、四川、宁夏;
第四类:西藏、甘肃、青海、新疆。
4 结语
通过上述分析,基于土地利用的分层聚类算法的结果符合各地农业发展规划和土地利用规划的要求,可以为改善我国土地利用状况,提供一定参考价值,较好地引导农业发展。算法还表明各部门的土地工作者需要对土地利用尽量优化,例如尽量利用荒山荒坡、滩涂等未利用土地。因此,通过我们的算法,在开展土地资源的调查研究和科学评价中,能够更好地对土地组成、利用现状进行综合的考虑,做到有计划有限制地开发土地资源,增加耕地面积,提高耕地质量,以达到对土地资源的更加科学的改造与治理的目标,保持土地的良性循环,土地利用可持续化,同时为社会发展、城市化进程不断推进、国民经济建设提供决策支持。
[1]张文彤,董伟.SPSS统计分析高级教程[M].北京:高等教育出版社,2004.
[2]Jiawei Han,Micheline Kambe著.数据挖掘概念与技术.范明,孟小峰译.机械工业出版社,223-262.
[3]邵峰晶,于忠清.数据挖掘原理与算法[M],北京:中国水利水电出版社,2003.
[4]郭仁忠.空间分析(第二版).北京:高等教育出版社,2001.
[5]赵国富.基于聚类的空间数据挖掘方法与应用研究[硕士学位论文]。山东:山东理工大学,2006.
Abstract:Analyzes the basic theories of the hierarchical cluster algorithm,and makes the algorithm come true.Applies the hierar⁃chical cluster algorithm into land use change,so attains a better result through many times of attempting,comparing some space regular clustering algorithm,validates the correctness of clustering gained,improves arithmetic serviceability.
Keywords:Cluster Analysis;Soil Utilization;Hierarchical Cluster
Application of the Hierarchical Cluster Algorithm in Soil Utilization
ZHAO Guo-fu
(Network Information Center,Shandong University of Technology,Zibo 255049)
山东省自然科学基金资助项目(No.2004ZX31)
1007-1423(2017)26-0033-03
10.3969/j.issn.1007-1423.2017.26.008
赵国富(1971-),男,山东潍坊人,硕士,高级工程师,研究方向为空间数据处理、计算机应用
2017-06-02
2017-08-30
