基于分层的微博话题传播模型研究
2017-10-16杜文才叶春杨
姜 帅,杜文才,叶春杨,2
(1.海南大学 信息科学技术学院,海南 海口 570228; 2.海南大学 南海海洋资源利用国家重点实验室,海南 海口 570228)
基于分层的微博话题传播模型研究
姜 帅1,杜文才1,叶春杨1,2
(1.海南大学 信息科学技术学院,海南 海口 570228; 2.海南大学 南海海洋资源利用国家重点实验室,海南 海口 570228)
通过对社交网络新浪微博的数据的统计分析,得知微博数据具有高度的聚集性,即一个流行微博的只被转发一次的转发数占总转发数量的50%以上.因此,提出了对信息级联分层的STIC模型,该模型的第一层级联和第二层级联分别使用SVM分类算法和基于主题的信息级联模型对话题传播进行预测.实验结果表明,STIC模型的预测结果优于基于主题的信息级联模型.
信息传播; 微博; 信息级联; 支持向量机
随着移动设备的快速发展,社交媒体迅速崛起,例如国外的Twitter,Facebook,国内的微信和微博.根据新浪微博发布的一份《2016年度用户发展报告》显示,新浪微博的月活跃用户达到了2.97亿.用户可以在任何时间任何地点分享自己的想法和观点.因此微博等社交媒体数据呈现爆发式的增长.信息在社交媒体的传播也一直成为了社交媒体计算的研究热点.
信息级联模型是常见的话题传播模型.Kempe等[1]描述问题作为一个离散型的优化问题并且利用2个基本的信息传播模型,IC(Independent Cascade)模型和LT(Linear Threshold)模型.Barbier等[2]提出了一个基于话题的IC模型TIC模型.TIC模型考虑了用户的话题分布和信息的主题分布. Wang Zhipeng等人[3]考虑了信息中包含的情感也影响了信息在网络中的传播,提出了基于情感的IC模型.研究者将信息中的包含的情感分为5类:生气,厌恶,喜欢,难过和害怕.Cheng J等[4]通过社交网络的连续的时序特征预测Facebook内容的级联.Sun A[5]和Tsur O[6]则通过给定一个固定的时间窗口预测信息的级联.Goyal等[7]在使用GTM模型时,增加了一个时间的延迟,考虑一个有影响力的用户和一个行为的影响倾向,并且可以用来预测用户是否执行或者何时执行某个操作.Lee等[8]认为IC模型中的行为是连续发生,而不是只发生一次,提出了时间受限的IC模型.Gomez S[9]和Sole-Ribalta A[10]考虑到社交网络的复杂性,使用简单图建立了多层连接模型.Granell C[11]考虑用户在对社交网络中的信息做出决定的时候,可能不只是受网络中社交信任的影响,还会受到一些其他的外界影响.Kwak等[12]研究了Twitter中的转发行为,发现网络中信息传播大多数只有一次转发,生命周期不超过1 d. Escolano D等[13]将社交网络中的信息比作热量或者气体,社交网络中的信息会像热量一样从一个高温区域传播到一个低温区.Hakim M A N[14]用支持向量机的分类算法预测社交网络中用户是否会做出某个行为.罗杰[15]使用支持向量机的方法对微博中的话题自适应跟踪.钟杰等[16]研究了社交网络中话题传播的社区结构.张跃伟[17]使用分类方法学习热门话题的预测.
以上的信息传播的模型做了很好的理论基础研究,不足之处在于没有考虑社交媒体中话题传播的特殊模式.根据笔者对新浪微博的数据统计分析发现,微博话题转发中50%以上是1次的转发,只有少部分话题才是多次转发.因此,微博话题的传播具有很高的聚集性,笔者提出了基于分层的信息级联模型—STIC模型,用于分析话题传播的预测分析 .
1 相关理论研究
1.1 IC模型IC模型认为在社交网络中,信息传播是通过网络中的用户逐级转发信息形成了社交网络中的信息传播.信息级联传播的模型时通常包含有以下假设:
1) 网络中个用户是有朋友关系的,比如新浪微博中用户的关注和关注此用户的粉丝.
2) 用户通过观察邻居节点的决定而做决定.
当信息在社交网络中传播时,节点的状态分为2种.一种是活跃的节点,表示该节点已经采纳或者转发了信息.另一类是非活跃的节点,表示这个节点没有转发目标信息.当活跃的节点对非活跃的节点造成足够的影响时,受影响的非活跃的节点就会转变成活跃的节点,然后开始对其邻居节点造成影响,影响如此在网络中传递下去,直到整个网络没有新的非活跃节点的出现.
节点u对其所有的邻居节点的影响不是一个简单的随机过程[18],而是会受许多条件的影响.用概率来表示节点间的影响力.假设节点v和节点u是朋友关系,且节点u影响节点v,那么影响概率为puv.当概率puv大于节点v受影响的阈值时,节点v将会变成活跃节点,接纳或者转发这条信息.
(1)
其中,puv代表节点u对节点v的影响概率[19].
因此节点u对其邻居节点v在信息i的影响概率可以表示为
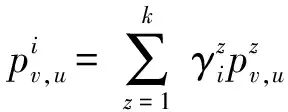
(2)
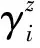
2 STIC模型
2.1话题数据集统计分析使用话题微博爬虫系统爬取了新浪微博中5个电影话题数据.为了获取话题下最全面的数据,依据上映的时间抓取上映一个月内的话题微博数据,共抓取微博6 032条,被转发267 482次,被评论282 462次,被点赞886 608次.
2.1.1 微博被转发的次数分布一条用户发布了一条微博后,会被感兴趣的邻居节点转发,邻居节点转发后又会被其他邻居节点继续转发.对5个电影话题微博进行统计结果如表1所示.
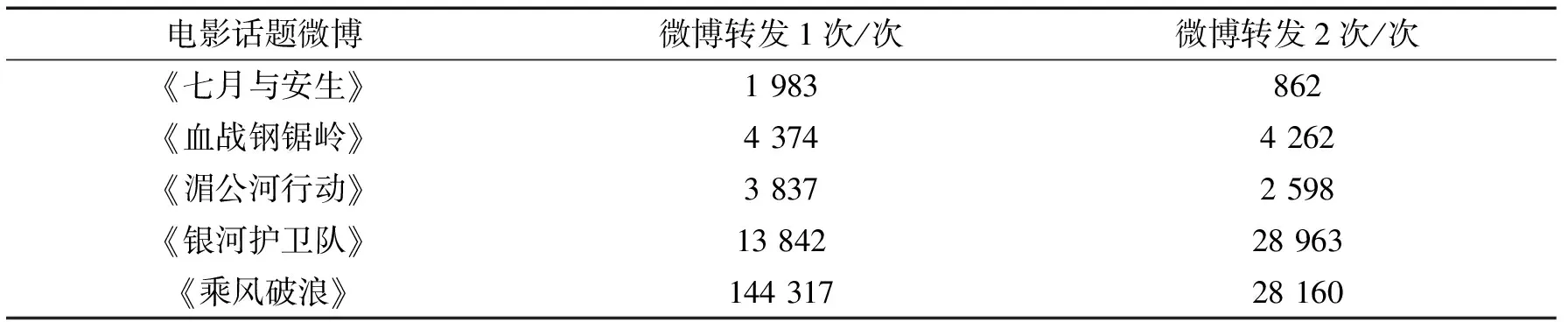
表1 电影话题微博转发次数分布
从表1中可以看出,50%以上的转发都是1次转发,对于某些话题2次转发以上的数量甚至不超过10%,说明话题微博的用户具有很高的聚集性和小世界效应.使用图1来简化表示社交网络中用户对某个话题的的分布情况.
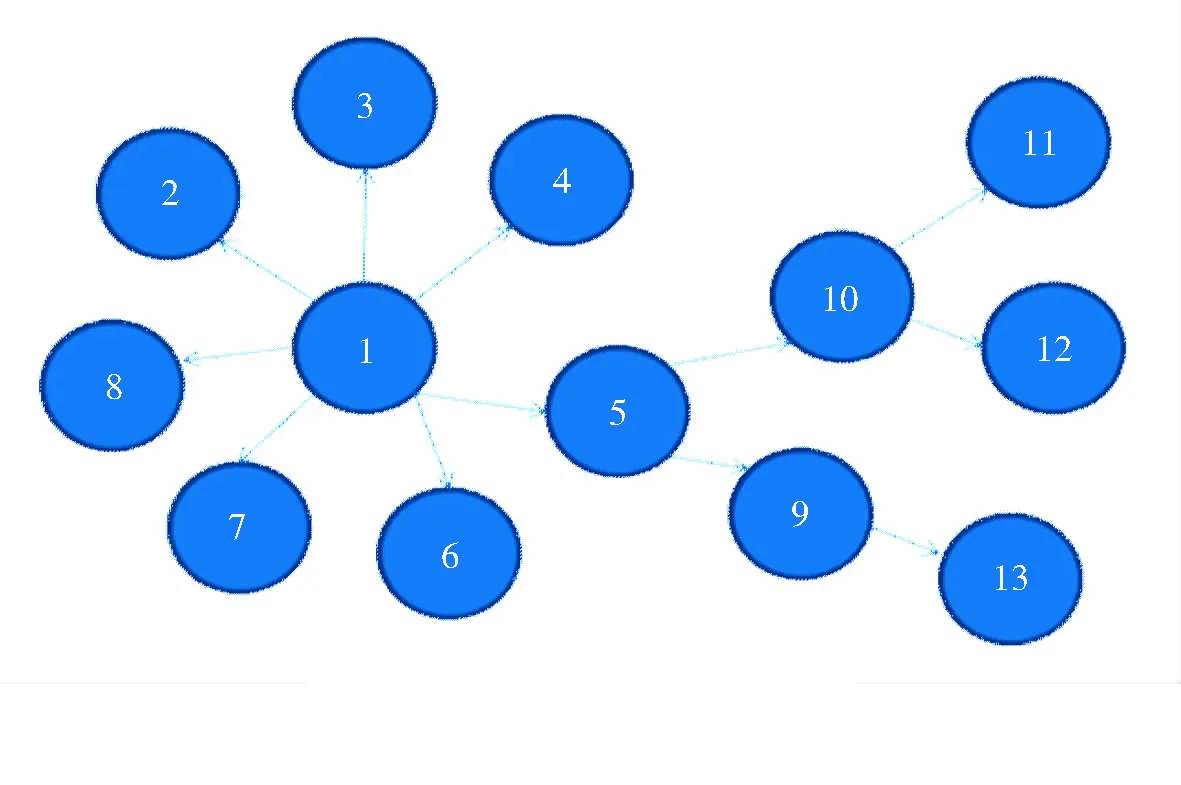
图1 话题微博转发层次示意图
2.1.2 微博转发的时间分析删除出话题被少量传播的微博,只选取被转发100次以上的热门微博进行转发时间的统计分析.5个电影话题数据共168 353次转发.统计24 h微博被用户转发的时间分布如图2所示.
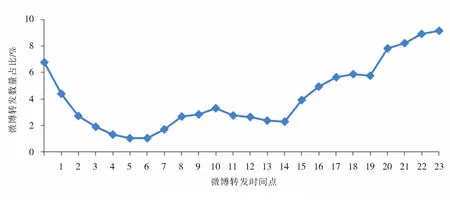
图2 24h 微博转发量随时间分布
从图2中可以看出,24 h微博的转发数量大约分为3个时间段.第一个时间段是2:00~6:00为转发量最少的时间段;第二个时间段是7:00~14:00,微博转发相对于第一个时间段增多;第三个时间段是15:00以后,转发数量逐渐增多.从图2中可以看出, 15:00~凌晨1:00是微博转发最集中的时候,换句话说,此时间段活跃用户最多,发布的微博更容易被转发.
因此,实际网络中用户的转发数量和用户的使用习惯是有关系的.对于商业推广作用非常明显,比如希望推广一个消息,可以在15:00~凌晨1:00发布,会被更多的人看到.
根据统计数据分析,可以了解到1次转发数量的占总转发的50%以上.因此,提高第一层数据的预测准确性,会相应的提高整体的预测的准确性.而1次转发作为信息级联的第一层,对于用户是否转发的行为预测可以方便的转化为常见的二元分类问题,可以添加更全面的影响因素作为特征值,提高算法预测的准确性.
2.2 STIC模型介绍

图4 社交网络有向图
除了社交图,还需要构建用户的行为日志D,D是用来保存用户在何时转发了某一信息i的记录.用元组(u,i,t,n)来表示D中的一条记录,其中u表示是用户,i指的用户转发的信息,这里用message_id标示,t是用户转发此消息的时间,n表示用户是第几层转发.
对文本的主题的挖掘一直是难点,目前最成功的文本挖掘算法是Latent Dirichlet Allocation,LDA算法[20].通过设定主题的个数k,分析信息的主题分布和用户已经发布的微博的内容分布.
根据对电影话题微博数据的统计分析结果,话题微博存在的明显的小世界效应和高度的聚集性,且微博的转发时间也跟用户使用社交媒体习惯有关系,24 h用户转发微博的热度是不一样的.此因素是以往信息级联模型尚未考虑到的.信息的转发是信息传播最直接的方法,针对转发具有明显的层次,提出STIC模型,根据转发具有2个层次将信息传播分为2层:第一层为微博只转发1次的情况;第二层为微博被转发2次以上的情况.
使用SVM分类算法学习第一层数据的预测问题.SVM分类算法相比IC模型可以加入更多的影响因素,例如用户转发的时间分布.SVM分类算法的输入是影响用户决定的3个因素:用户因素、微博主题因素以及社交关系因素.第二层转发2次以上的数据,信息以级联的方式在网络中传播.考虑到信息的主题和用户对信息主题的偏好对信息在社交网络中传播的影响,使用改进的IC模型—TIC模型学习第二层的信息传播.最后将SVM算法预测的信息转发中被1次转发的结果和TIC模型预测信息转发中被2次以上转发的预测结果进行线性整合,得到一个完整社交网络的预测结果.
2.2.1 SVM分类第一层级联特征值的选取对SVM分类结果是一个重要的影响因素.为了更好的得到SVM的学习结果,结合真实社交网络的情况,将SVM分类的特征值分为3类数据:用户属性、微博文本属性和社交属性,如表2所示.在用户属性中主要包括了目标用户的性别、年龄、用户关注的用户数量、用户粉丝数量、用户发布微博内容的主题倾向和用户发布微博的时间习惯.微博文本属性主要是微博的主题分布.社交属性指影响目标用户的邻居节点的影响力,主要通过该邻居节点的粉丝数、关注用户数以及是否是平台认证大V来标示.
在表2中特征值user_age,user_gender,user_follow和user_fans4个特征值,都可以通过爬虫程序,直接从网页获取,在处理的时候只需要转发成可计算的数值即可.
特征值 parent_fans,parent_follow,parent_V也可以通过爬虫程序,直接从网页上获取.但是对于一个用户是否是目标待测用户的关注用户,或者说和目标待测用户有朋友关系,则需要根据已知的社交图G(V,E)中的顶点集筛选.
特征值 user_interest,content_topic不能直接从数据获取,需通过使用LDA算法来提取用户内容和微博内容的主题分布.
特征值 time是用户的行为习惯,可根据用户的行为日志D归纳出用户活跃的时间段.
特征值follow_each_other表示用户和影响他的邻居节点是否是互相关注的关系,在社交网络中,互相关注代表着一种亲密的朋友关系.
在计算的时把x5和x7乘在一起处理,也就是特征值user_interest和content_topic放在一起作为1个特征量,标示了用户和文本在主题上的相似度.

表2 输入特征值
假设每一个传播轨迹都是独立于其他的轨迹,则模型参数Θ的似然估计可以公式表示
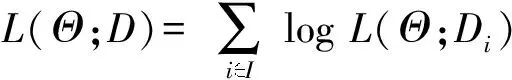
(3)
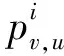
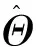

(4)


2.2.3 2层算法预测结果整合通过SVM分类算法得到的社交网络中用户是否会转发的结果,筛选出预测的会转发目标消息的用户,作为第一层对目标消息进行传播的用户.根据基于主题的TIC模型的学习得到的2次以上转发的信息级联的预测结果,筛选出预测的会转发目标消息的用户,作为第二层对目标消息进行传播的用户.将2层用户线性整合在一起,作为整个社交网络的预测结果.
3 实 验
实验数据将使用从新浪微博中获取的5个电影话题的微博数据,预测用户是否会转发微博,其实是个二元问题.因此最终对实验结果使用混淆矩阵的形式进行评估,混淆矩阵如表3所示.

表3 结果混淆矩阵分析
表3中TP表示被模型预测为正的正样本,FP表示被模型预测为正的负样本,FN表示被模型预测为负的正样本,TN表示被模型预测为负的负样本.
在使用模型对话题进行分析预测时,将在3个方面使对话题微博数据进行预测分析,第一个方面是同一个话题下的微博的预测(同一个主题标签下,对新发布的微博的预测);第二个方面是对新的话题下微博预测(不同主题标签的话题微博);第三个方面是影响力最大化,通过找出若干个种子节点,使得话题传播传播范围最广.
3.1同一个话题下微博预测分析在同一个话题下的微博,具有高度的主题相关性.目的是根据已有的话题微博的数据,对该话题下新发布的微博进行预测.实验室数据准备中将5个电影话题中的4个电影话题的微博根据发布时间按2:8的比例分为测试集和训练集,其中最后发布的微博占20%,作为测试集,其他作为训练集,然后分别使用STIC模型和TIC模型对微博数据进行预测,最后根据预测结果的混淆矩阵,分别计算2个模型下的准确率、召回率和F值.

表4 STIC模型下4个电影话题的预测结果

表5 TIC模型下4个话题的预测结果
从表4和表5中可以看出,在对同一个话题下的微博转发预测时,STIC模型比TIC模型有更好的准确率和召回率,因为STIC模型相比TIC模型在第一层使用SVM学习过程中,加入了更多的特征,丰富了学习的特征维度,而TIC模型则忽视了用户的一些基本特征,更注重社交网络中的社交关系.
3.2新话题的预测分析实验中,以《七月与安生》,《湄公河行动》,《银河护卫队》,《乘风破浪》4个电影话题为训练集,《血战钢锯岭》作为待预测的话题数据.对数据分别使用STIC模型和TIC模型进行预测,结果以混淆矩阵的形式评估,分别计算2个模型的真正率TPR和假正率FPR,画出2个模型的ROC曲线,如图5所示.

图5 STIC 模型和TIC 模型的ROC 曲线
从图5中可以看出,STIC模型有着更高的TPR,AUC值(曲线下的面积)更大,表明在对1个新的话题传播预测时,STIC模型的预测效果仍然好于TIC模型的预测效果,同时说明,STIC模型在泛化能力上的有效性.
综上所述,可以得出STIC模型在对话题传播模型建模与预测中,比TIC模型有更好的预测效果,更高的准确性.
3.3影响力最大化给定个新话题,如何筛选出若干初始用户使话题在社交网络上传播的最广泛,是对现实很多领域非常有作用的问题.根据提出的SITC预测模型,使用贪婪算法选择初始用户,使新话题可以在网络中传播的最广.

图6 第一层SVM 和STIC 影响力最大化预测结果
实验数据是话题《星际迷航2:暗黑无界》为例,遍历社交网络中的节点,使用SVM算法预测第一层转发的数量,对转发数量进行排序.根据设定的种子节点k,根据转发数据排行榜,选择种子节点个数,然后使用IC模型的贪婪算法,对多次转发的情形进行预测,如图6所示.
由于IC模型的贪婪算法对影响力最大化的预测结果只有60%,并且由于话题的转发中50%以上是1次转发.因此STIC模型中第一层SVM预测结果对最后的准确率影响更大.从图6中可以看出,STIC模型通过SVM分类算法预测更多的传播用户,信息级联只需预测2次以上转发的少部分用户,从而提高了影响力最大化的准确性.
4 结束语
社交媒体的话题传播模型的研究在市场营销、舆情监测等领域发挥着越来越重要的作用.笔者根据真实社交数据的统计分析,提出了基于分层的STIC模型.STIC模型把信息传播的信息级联模型分为2层:第一层微博只被转发1次的情况;第二层是微博被转发2次以上的情况.分别使用SVM分类算法和基于主题的TIC模型预测2层的信息传播.实验结果表明,STIC模型的预测结果优于TIC模型的预测结果.但基于分层的STIC模型计算量大,计算速度不理想,如何优化概率的计算,减少迭代次数,提高收敛的效率是下一步工作研究的目标.
[1]KempeD,KleinbergJ,TardosE,etal.Maximizingthespreadofinfluencethroughasocialnetwork:proceedingsofKnowledgeDiscoveryandDataMining,Washington,D.C,August24 - 27, 2003[C].[S.l.]:IEEE, 2016.
[2]BarbieriN,BonchiF,MancoG.Topic-awaresocialinfluencepropagationmodels[J].KnowledgeandInformationSystems, 2013, 37(3):555-584.
[3]WangZ,ZhaoJ,XuK.Emotion-basedIndependentCascademodelforinformationpropagationinonlinesocialmedia:proceedingsofInternationalConferenceonServiceSystemsandServiceManagement,Kunming,June24-26,2016[C]. [S.l.]:IEEE, 2016.
[4]ChengJ,AdamicL,DowPA,etal.Cancascadesbepredicted?:proceedingsofInternationalWorldWideWebConferenceCommittee,Seoul,April7-11, 2014[C]. [S.l.]:IEEE, 2014.
[5]MaZ,SunA,CongG.OnpredictingthepopularityofnewlyemerginghashtagsinTwitter[J].JournaloftheAssociationforInformationScienceandTechnology, 2013, 64(7):1 399-1 410.
[6]TsurO,RappoportA.What′sinahashtag:contentbasedpredictionofthespreadofideasinmicrobloggingcommunities:proceedingsofInternationalConferenceonWebSearchandWebDataMining,Seattle,February8-12,2012[C].[S.l.]:IEEE, 2012.
[7]GoyalA,BonchiF,LakshmananLVS.Learninginfluenceprobabilitiesinsocialnetworks:proceedingsofInternationalConferenceonWebSearchandWebDataMining,NewYork,February4-6, 2010[C]. [S.l.]:IEEE, 2010.
[8]KimJ,LeeW,YuH.CT-IC:Continuouslyactivatedandtime-restrictedindependentCascademodelforviralmarketing[J].Knowledge-BasedSystems, 2014, 62(1):57-68.
[9]GómezS,DíazguileraA,GómezgardeesJ,etal.Diffusiondynamicsonmultiplexnetworks[EB/OL]. [2017-02-10].https:diposit.ub.edu/dspace/bitstream/2445/51663/1/620530.pdf.
[10]Solé-RibaltaA,DeDM,KouvarisNE,etal.SpectralpropertiesoftheLaplacianofmultiplexnetworks[EB/OL]. [2017-02-10].http://deim.urv.cat/~sergio.gomez/papers/Sole-Ribalta-Spectral_properties_of_the_Laplacian_of_multiplex_networks+suppl.pdf.
[11]GranellC,GómezS,ArenasA.Competingspreadingprocessesonmultiplexnetworks:awarenessandepidemics[EB/OL]. [2017-02-10].http://deim.urv.cat/~sergio.gomez/papers/Granell-Competing_spreading_processes_on_multiplex_networks_awareness_and_epidemics.pdf
[12]BakshyE,HofmanJM,MasonWA,etal.Everyone’saninfluencer:quantifyinginfluenceontwitter:proceedingsof4thInternationalConferenceonWebSearchandWebDataMining,HongKong,February9-12,2011[C].[S.l.]:IEEE,2011.
[13]EscolanoF,HancockER,LozanoMA.Heatdiffusion:thermodynamicdepthcomplexityofnetworks[EB/OL].[2017-02-10] .https://rua.ua.es/dspace/bitstream/10045/35865/1/2012_Escolano_etal_PhysRevE.pdf.
[14]ManANH,KhodraML.PredictinginformationcascadeonTwitterusingsupportvectorregression:proceedingsofInternationalConferenceonDataandSoftwareEngineering,Yogyakarta,Novermber26-28,2015[C]. [S.l.]:IEEE, 2015.
[15] 罗杰. 基于SVM的微博话题跟踪方法及其应用[D].北京:北京理工大学, 2015.
[16] 钟杰, 王海舟, 王文贤. 基于话题的微博信息传播拓扑结构研究[J].信息网络安全, 2016(3):64-70.
[17] 张跃伟. 基于微博客话题的热点预测及传播溯源[D]. 北京:北京邮电大学, 2014.
[18]DooM,LiuL.Probabilisticdiffusionofsocialinfluencewithincentives[J].IEEETransactionsonServicesComputing, 2014, 7(7):387-400.
[19]BarbieriN,BonchiF,MancoG.Topic-awaresocialinfluencepropagationmodels[J].KnowledgeandInformationSystems, 2013, 37(3):555-584.
[20]WengJ,LimEP,JiangJ,etal.TwitterRank:findingtopic-sensitiveinfluentialtwitterers:proceedingsofWebSearchandDataMining,NewYork,February4 - 6, 2010[C]. [S.l.]:IEEE, 2010.
[21]DempsterAP,LairdNM,RubinDB.MaximumlikelihoodfromincompletedataviatheEMalgorithm[J].JournaloftheRoyalStatisticalSociety:SeriesB(Methodological), 1977, 39(1):1-38.
Abstract:In the report, the statistical analysis of social network data from Sina Microblog was performed. The analysis data suggested that the aggregation of data from microblog was high, and the number of on time forwarding was above 50% of the total number of forwarding. So, a hierarchical model, namely STIC, was proposed, and in which the information cascade was divided into two layers. The first layer was applied to describe the situations where messages are forwarded only one time. The second layer was applied to describe the other forwarding patterns. In the first layer, SVM was used to predict the information diffusion; In the second layer, Independent Cascade Model was used to predict the information diffusion. The results showed that the performance of STIC was superior to that of TIC in terms of accuracy of information diffusion.
Keywords:Information diffusion; microblog; information cascade; support vector machine
MircroblogDiffusionModelBasedonHierarchical
Jiang Shuai, Du Wencai, Ye Chunyang
(College of Information Science and Technology, Hainan University, Haikou 570228, China)
TP 309
A DOl:10.15886/j.cnki.hdxbzkb.2017.0036
2017-03-19
国家自然科学基金(61562019,61379047);海南省重点研发计划(ZDYF2017010);海南省自然科学基金(20156223);海南省高等学校教育教改重点(hnjg2017ZD-1)
姜帅(1989-),男,山东济宁人,海南大学2014级硕士研究生,研究方向:数据挖掘,E-mail:wxfx131813@outlook.com
叶春杨(1976-),男,海南琼海人,博士,教授,研究方向:软件工程,E-mail:cyye@ustc.edu
1004-1729(2017)03-0219-09
