一种基于分层多尺度卷积特征提取的坦克装甲目标图像检测方法
2017-10-12孙皓泽常天庆王全东孔德鹏戴文君
孙皓泽, 常天庆, 王全东, 孔德鹏, 戴文君
(装甲兵工程学院 控制工程系, 北京 100072)
一种基于分层多尺度卷积特征提取的坦克装甲目标图像检测方法
孙皓泽, 常天庆, 王全东, 孔德鹏, 戴文君
(装甲兵工程学院 控制工程系, 北京 100072)
针对坦克装甲目标的图像检测任务,提出一种基于分层多尺度卷积特征提取的目标检测方法。采用迁移学习的设计思路,在VGG-16网络的基础上针对目标检测任务对网络的结构和参数进行修改和微调,结合建议区域提取网络和目标检测子网络来实现对目标的精确检测。对于建议区域提取网络,在多个不同分辨率的卷积特征图上分层提取多种尺度的建议区域,增强对弱小目标的检测能力;对于目标检测子网络,选用分辨率更高的卷积特征图来提取目标,并额外增加了一个上采样层来提升特征图的分辨率。通过结合多尺度训练、困难负样本挖掘等多种设计和训练方法,所提出的方法在构建的坦克装甲目标数据集上取得了优异的检测效果,目标检测的精度和速度均优于目前主流的检测方法。
兵器科学与技术; 目标探测与识别; 卷积神经网络; 坦克装甲目标; 目标检测
Abstract: A target detection method based on hierarchical multi-scale convolution feature extraction is proposed for the image detection of tank and armored targets. The idea of transfer learning is used to mo-dify and fine-tune the structure and parameters of VGG-16 network according to the target detection task, and the region proposal network and the detection sub-network are combined to realize the accurate detection of targets. For the region proposal network, the multi-scale proposals are extracted from the convolution feature maps of different resolutions to enhance the detection capability of small targets. For the object detection sub-network, the feature maps with high-resolution convolution are used to extract the targets, and an upsampling layer is added to enhance the resolution of the feature maps. With the help of multi-scale training and hard negative sample mining, the proposed method achieves the excellent results in the tank and armored target data set, and its detection accuracy and speed are better than the those of current mainstream detection methods.
Key words: ordnance science and technology; target detection and identification; convolutional neural network; tank and armored target; target detection
2.4 液化性坏死的处理与转归 2例患者术后消融区液化性坏死经口服抗炎药治疗后自行消散,局部未作处理(图3)。10例患者行手术切开放置皮片引流,14~26 d 后切口愈合,其中 3例行患侧甲状腺坏死组织清除术和负压引流,2例颈部皮肤留下明显瘢痕。6例采取超声引导下扩开穿刺窦道引流,任坏死物自然引流或轻压辅助引流,皮肤破溃处使用安尔碘消毒液擦洗,用无菌纱布覆盖并每天更换,10~20 d 愈合,颈部皮肤均无瘢痕形成。
0 引言
基于图像的目标检测技术是指利用计算机视觉等相关技术,将既定类别的物体自动从图像中检测出来,并对物体的类别、位置、大小以及置信度进行判断[1]。目前,该技术已在海防监视、精确制导、视频监控等方面得到广泛应用。然而,对于坦克装甲车辆而言,由于地面战场环境的复杂性以及相对较远的观测打击距离,在大视场内实现对敌方坦克装甲目标的自动检测识别和精确定位仍具有很大的难度。当前,坦克装甲车辆仍然是地面战场最主要的作战力量,因此开展针对坦克装甲目标自动检测识别方面的研究,通过结合我方无人机、地面侦察车以及坦克装甲车辆等多种观测平台的图像采集设备,实现对敌方的坦克装甲目标的自动检测识别,对提升坦克装甲车辆的智能化、信息化作战水平具有重要的意义[2]。
1.2.2.3 经济状况 采用主观经济状况自评问卷,即单条目问卷,“您在当地的富裕程度”,以“富裕、一般和不富裕”作为评判尺度,将“富裕”赋值为“3”,“一般”赋值为“2”,“不富裕”赋值为“1”,分数越高提示居民的主观自评经济水平越高。
近年来,基于图像的目标检测技术一直是计算机视觉领域研究的热点。传统的图像目标检测任务基本上遵循“设计手工特征(方向梯度直方图(HOG)特征、局部二值模式(LBP)特征、尺度不变特征变换(SIFT)等[3]+分类器(Boosting、支持向量机(SVM)等)[4-5]”的思路,采用人工设计的特征提取方法在原始输入图像中提取特征信息,并将其输入分类器中学习分类规则,最后利用训练完成的分类器实现对目标的检测。这种人工特征建模方法在人脸识别、行人检测等领域都取得了不错的效果,极大地推动了图像目标检测技术的发展。然而,由于人工特征建模方法只包含图像原始的像素特征和纹理梯度等信息,并不具备高层语义上的抽象能力,使得这种方法针对复杂场景下的目标检测效果并不理想。2012年,随着Hinton等[6]在ImageNet[7]图像分类竞赛中取得重大突破, 深度卷积神经网络(CNN)开始引起学术界和工业界的广泛关注,并相继在图像分类、目标检测、图像分割等多种图像处理任务中取得突破性进展。相比于传统手工设计的特征描述,深度卷积特征在语义抽象能力上有着颠覆性的提升。针对目标检测任务,国内外学者先后提出了多种基于深度CNN的检测方法:Girshick等[8]率先提出了区域卷积神经网络(R-CNN)检测方法,其主要思想是先采用选择性搜索方法[9],对输入图像中可能包含目标的位置提取若干个建议区域,接着采用深度CNN对建议区域提取卷积特征,随后采用线性SVM分类器对建议区域进行判别,最后对建议区域的边界框进行回归修正。该方法刷新了Pascal VOC[10]目标检测数据集的测试结果。然而,由于该方法需要对每一个建议区域计算一次卷积特征,计算效率较低;此外所有的建议区域均缩放到相同的尺度,在一定程度上造成了图像的畸变,影响最终的检测结果。针对R-CNN存在的问题,Girshick[11]随后又提出了加速区域卷积神经网络(Fast R-CNN)检测方法,该方法将建议区域的特征提取转移到最后一层的卷积特征图上进行,解决了R-CNN需要对同一张图片重复进行多次卷积计算的问题,同时将建议区域的判别和边界框回归整合到一个框架下进行,有效提高了目标检测的精度和效率。在不计入建议区域提取时间的情况下,Fast R-CNN的单张图片检测时间达到0.32 s,使得实时的目标检测成为可能。针对建议区域提取低效的问题,微软亚洲研究院何凯明等在Fast R-CNN的基础上,提出了Faster R-CNN[12]的检测方法。该方法设计了一种建议区域提取网络(RPN),并与目标检测子网络共享卷积特征,从而实现了在GPU上对整个输入图像的端到端的训练和测试。该方法在Pascal VOC[10]和MS COCO[13]数据集上都取得了优异的结果,在使用ZF-net[14]和VGG-16[15]预训练网络时检测速度分别达到了17帧/s和5帧/s. 除以上基于分类的目标检测方法,国内外学者还从回归的角度对目标检测方法进行了探索:Redmon等[16]提出了一种被称为YOLO的检测方法,其基本思路是直接在卷积特征图上对多个区域的类别和边界框进行回归,实现对输入图像的端到端的训练和测试。该方法大幅度提高了图像目标检测的速度,最快检测速率能够达到155 帧/s,真正实现了对目标的实时检测。然而由于舍弃了建议区域提取这一关键步骤,该方法的检测精度相比于Faster R-CNN有一定差距。Liu等[17]也采用基于回归的设计思路,提出了一种被称为SSD的检测方法。该方法通过在基础网络VGG-net上添加多个卷积层,并从多个卷积特征图上对多个区域的类别和边界框进行回归,较好地平衡了目标检测的精度和效率,当输入图像的分辨率为500×500时,检测速度能够达到23帧/s,同时平均检测精度也与Faster R-CNN基本持平。
1.2.2 困难负样本挖掘
现代战争的战场态势瞬息万变,需要在保持一定检测精度的同时,尽可能提高目标检测的速度。因此,本文针对坦克装甲目标图像检测任务的特点和要求,提出一种基于分层多尺度卷积特征提取的目标检测方法:首先,引入迁移学习[18-19]的设计思路,将在ImageNet数据集上预训练完成的VGG-16作为基础网络,针对目标检测任务对网络的结构和参数进行修改和微调;其次,沿用Faster R-CNN中的检测框架,结合建议区域提取网络和目标检测子网络来实现对目标的精确检测;对于建议区域提取网络,在多个不同分辨率的卷积特征图上提取不同尺度的建议区域,增强网络对弱小目标的检测能力;对于目标检测子网络,选用分辨率更高的卷积特征图(conv4-3)提取目标,并额外增加一个上采样层来提升特征图的分辨率,使其对弱小目标具有更强的表征能力。通过结合多尺度训练、困难负样本挖掘等多种设计和训练方法,本文提出的方法在构建的坦克装甲目标数据集取得了优异的检测效果,目标检测的精度和速度均优于目前主流的检测方法Faster R-CNN.
此外,对于回归损失,[yi=1]指明了只有在样本标签为正时才被激活,否则将不产生作用。
1 基于分层多尺度卷积特征提取的目标检测方法
本文提出的目标检测方法的整体框架如图1所示。整个网络结构主要由3部分组成,即:VGG-16预训练网络、基于分层多尺度采样的建议区域提取网络以及目标检测子网络。
1.1 基于VGG-16预训练模型的迁移学习
多层级的深度CNN通常具有上百万甚至千万的模型参数需要进行学习训练,对训练样本的数量和硬件条件都有非常高的要求。目前,通用的做法是采用在大规模的图像数据集ImageNet上预训练好的网络模型,通过迁移学习的方式在特定数据集上对该模型参数进行修改和微调。常用的深度CNN模型包括Lenet-Net[20]、Alex[7]/ZF-Net[13]、VGG-Net[15]、Google-Net[21]等。通过对硬件条件和检测任务的综合考虑,本文选定预训练好的VGG-16网络模型作为基础网络,通过对VGG-16网络的修改和微调来实现目标检测任务。
1.2 基于分层多尺度特征提取的建议区域提取网络

图1 基于分层多尺度卷积特征提取的目标检测整体框架Fig.1 Framework of target detection based on hierarchical multi-scale convolution feature extraction
对于一副待检测的输入图像,建议区域提取网络主要用于对其提取若干个可能包含目标的矩形建议框,并对每个建议框赋予一个是否包含物体的置信度。Faster R-CNN采用了一种全卷积网络的实现方式,区域提取网络和目标检测子网络共享基础网络所有的卷积层,并在最后一层的卷积特征图上滑动小网络,实现对建议区域的提取。相比于目标检测方法,Faster R-CNN首次提出采用CNN来提取建议区域,实现了在GPU上对输入图像进行端到端的训练和测试,大幅度提升了目标检测的速度。然而,Faster R-CNN的建议区域由最后一个卷积层提取得到,由于该层上卷积特征图的分辨率不足,导致该方法对弱小目标的检测能力有限(对于一个输入图像中大小为32×32的目标,经过CNN的前向传递,在VGG-16最后一个卷积层上大小仅为2×2)。针对以上问题,本文采用一种多尺度的提取策略[22-23],将建议区域的提取对象扩展到VGG-16网络的多个卷积层(如图1),分别在卷积层conv3-3、conv4-3、conv5-3、pooling-5上滑动不同大小的窗口,将每一个滑动窗口覆盖的区域作为初始建议区域,判断其是否包含感兴趣的目标。随后,将每个滑动窗口区域映射到更低维的特征向量(512维),并将其输出到两个全连接层(分类层Scoring和边界框回归层Bbox reg),从而得到每个滑动窗口区域的置信度以及边界框回归向量。对于conv3-3而言,由于该层上的卷积特征图分辨率较高,相比于后两层对小目标的响应更强,主要用于对输入图像中小于30像素的弱小目标提取建议区域。考虑到对检测速度的要求,此处只采用一个大小为7×7的滑动窗口,并将滑动步长设置为2;对于conv4-3和conv5-3,分别采用两个大小为5×5和7×7的滑动窗口;对于pooling-5,考虑到实际情况中大于250像素的目标不能完全避免,除了两个大小为5×5和7×7的滑动窗口外,此处增设一个9×9的滑动窗口,用于实现对超大目标的检测。除conv3-3外,其余层上的滑动步长均设置为1. 需要指出的是,虽然在高分辨率的特征图上采取精细的建议区域提取方式能够在一定程度上提升检测精度,但是将导致检测速度的骤降,因此需要根据具体需求对其进行折中。实验结果表明,本文采用的建议区域提取方式对于坦克装甲目标保持着较高的召回率。
1.2.1 损失函数
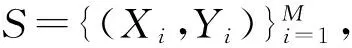
l(Xi,Yi|W)=Lc(p(Xi),yi)+λ[yi=1]Ll(bi,i),
(1)
式中:Lc(p(Xi),yi)表示样本集的分类损失函数,Ll(bi,i)表示样本集的回归损失函数,二者分别对应图1中的分类层和回归层,通过补偿因子λ进行加权平衡;W表示整个建议区域提取网络需要训练的参数。
分类层采用1个二分类的交叉熵分类函数,通过损失函数Lc(p(Xi),yi)=-lgpyi(Xi)输出样本在目标和背景间的概率分布,pyi(Xi)表示样本Xi属于yi类的概率。
对于回归层,主要用对样本边界框的坐标进行微调。由于预测的建议区域并不可能与真实目标的标注框完全重合,在其比较接近的情况下,可以通过线性的边界框回归对建议区域进行微调。参考文献[11]提出的边界框回归方法,定义回归损失函数Ll(bi,i)如下:
(2)
式中:smooth函数定义为
(3)
bi,x=(x-xa)/ωa,bi,y=(y-ya)/ha,
bi,w=lg (ω/ωa),bi,h=lg (h/ha),
i,x=(-xa)/ωa,i,y=(-ya)/ha,
i,w=lg (/ωa),i,h=lg (/ha).
(4)
通过给正负样本的损失函数添加相应的权重系数,确保在正样本数量低于设定的比例时,通过权重系数来增加正样本在损失函数中的比重,使得损失函数中正负样本的权重保持均衡。
回来后,我苦闷了好久,到底要不要继续?如果要继续,就必须跟爸妈说,不说不行。如果不继续,就不再去他家了。老秦后来跟我说:“我看出来了,知道你来了一次就不想再来了。”
于是,对于所有被标注的M个样本,根据被选用的卷积层不同,可以得到一个总的损失函数:
3.2.1 建议区域提取网络测试评估
(5)
式中:N为参与建议区域提取的卷积层数量(此处取值为4);ωn对应每一个卷积层的样本权重;Sn对应从每一个卷积层提取的样本集合。在训练时,通过随机梯度下降法实现对损失函数的逐步优化。
以上所述方法曾先后在Pascal VOC[10]、MS COCO[13]等通用目标检测数据集上取得了不错的效果,有效推动了目标检测技术的发展。然而,针对复杂环境下坦克装甲目标的检测任务,直接移植以上方法的思路并不可行,这是因为目标在整幅图像中所占的尺寸比例有所不同。由于坦克装甲车辆的观测打击距离通常在几百米甚至1 000 m以上,使得目标在输入图像中所占尺寸的比例较小。以1 000 m的观测距离为例,当图像采集设备的观测视场角为20°时,敌方坦克装甲目标在1 024×768的输入图像中仅有20~30像素大小,目标尺寸比Pascal VOC等通用测试集中的大多数目标要小得多。目前主流的Faster R-CNN、SSD等检测方法主要是针对Pascal VOC等通用测试集设计完成的,以求在通用测试集上取得更高的平均检测精度,并未重点强调对小目标的检测效果。此外,Pascal VOC等通用目标检测数据集主要强调目标检测的精度,对检测的速度并没有硬性要求。
对于一副待检测图像,在经过样本标注后,由于目标在图像中所占的比例有限,负样本的数量通常会远远超过正样本,这种样本分布的不平衡可能会导致训练的不稳定。因此在训练时,需要对正负样本的数量和比例进行调整。对于一个样本集,本文将正负样本间的数量比例确定为|S-|/|S+|=α. 由于负样本数量众多且分布不均匀,不同的负样本存在难易程度的区别,对最终的检测精度影响很大,需要制定特殊的采样策略对负样本训练集进行挑选。文献[24]分别对随机采样、Bootstrapping采样和混合采样(随机采样+Bootstrapping采样)3种策略进行了分析和验证,结果表明Bootstrapping采样和混合采样的效果相当。因此,本文采用Bootstrapping采样方法,其基本思路是根据置信度值对所有的负样本进行排序,并从中挑选出得分最高的若干样本加入训练集。
在构建的坦克装甲目标数据集上,对所提出的建议区域提取网络网络进行测试评估。作为对比,同时对目前主流的目标检测方法Faster R-CNN进行相同的测试。遵循文献[27]提出的评估方法,将建议区域对目标的召回率作为其评估准则,并将建议区域的召回阈值设置为0.7,与真实标注框重合度超过70%的建议区域即认为是有效召回。

(6)
式中:变量x、xa、分别表示预测的边界框、建议区域边界框以及真实目标标注框。由此,在网络的训练阶段,算法以预测样本边界框内图像的卷积特征作为输入,通过梯度下降法对回归参数进行优化;在测试阶段,根据输入图像的卷积特征得到输出,经过反参数化后对边界框进行微调。
1.2.3 非极大值抑制
完善物流配送的法律投诉机制建设,健全物流配送体制。在加强外部管理的同时完善内部的监管,建立健全物流配送体制,相互制约促进其发展。针对网上购物配送中出现货物破损及退货、赔偿等种种问题,政府有关部门应该制定有针对性的法规和政策,以规范网上购物市场,增加广大消费者对网上购物的信任感。因此企业应尽快建立、健全电子商务法规与物流配送投诉机制,这样才可以妥善解决争端,使客户在消费后能维护自己的合法权益,也使商家能建立起较好的商业信誉,从而立于不败之地。
对于一副分辨率为1 024×768的输入图像,通过本文方法进行建议区域提取后,将得到大约30 000个初始建议区域。这些建议区域间将存在大量的重叠和冗余,严重影响检测的速度。因此,本文基于初始建议区域的分类得分,采用非极大值抑制的方法对其数量进行精简。在进行非极大值抑制时,将IoU的阈值设置为0.7,从而每张图像将只剩下大约2 000个建议区域。之后,从剩余的2 000个建议区域中挑选分类得分最高的100个作为最终的建议区域,并将其输入目标检测子网络。非极大值抑制不会对最终的检测精度造成影响,还能够大幅度提升检测效率。在后文的实验部分,本文对选取不同数量的建议区域进行了对比。
1.3 目标检测子网络
尽管单独使用建议区域提取网络能实现目标检测的功能,文献[16-17]也采用这种检测框架设计完成,但实验结果表明,这种设计思路相比于先提取建议区域再进行目标检测的方法,检测的速度有明显提高,但同时也牺牲了一定的检测精度,小目标检测更是效果欠佳。因此,本文在建议区域提取网络之后单独设计了目标检测子网络。整个网络的结构如图1所示。首先,为了增强对小目标的检测能力,不同于R-CNN系列的检测方法在最后一个卷积层上提取目标,本文在分辨率更高的第4个卷积层(conv4-3)上执行该操作。此外,为了进一步增大卷积特征图的分辨率,本文引入了文献[25]的设计思路,在conv4-3层上执行反卷积操作,通过双线性插值的上采样方式来增大卷积特征图的分辨率。反卷积层的加入有效提升了系统对小目标的感知能力,本文将在实验部分对其效果进行评价。随后,在增大后的卷积特征图上对建议区域所对应的部分进行固定尺度的池化采样。本文沿用了文献[11]中的ROI(感兴趣区域)采样方法,将建议区域对应的卷积特征转化为7×7×512维的特征向量。之后,依次连接全连接层和输出层。对于全连接层,考虑到VGG-16网络中两个4 096维的全连接层计算起来比较耗时,用一个2 048维的全连接层对其进行替换。对于输出层,与建议区域提取网络一样,由并行连接的分类层和回归层组成,并采用多任务模式对其进行联合优化。
这样,对于整个网络的损失函数,可在(5)式的基础上扩展得到:
“法治”是当今社会的主旋律,必须在“依法治国”的背景下建立和落实国家机关“谁执法谁普法”责任制,以确保其拥有稳固的制度根基[1]。一般来讲,该责任制的建立和实施必须有以下依据:
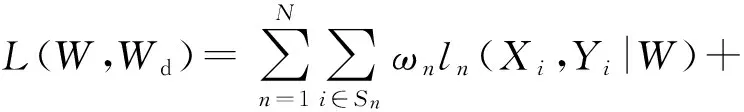
(7)
式中:ln+1表示检测子网络的损失函数;Sn+1表示检测子网络的训练样本。由于目标检测子网络与建议区域提取网络共享基础网络VGG-16的部分卷积层,此处考虑将两个子网络的参数W和Wd进行联合优化,即:
(1)振捣混凝土采用机械振捣,柱混凝土采用振捣棒振捣。分层浇筑的混凝土,振捣棒插入下层5 cm左右,以消除两层之间的接缝。

(8)
与建议区域提取网络一样,在训练时通过随机梯度下降法对其进行优化。对于目标检测子网络的输出结果,同样采用非极大值抑制方法对其进行优化。此处的IoU阈值设置为0.3. 最后,从简化结果中挑选出置信度得分大于阈值的区域作为最终的目标区域。对于坦克装甲目标的检测而言,可以容忍一定程度的误检率,但对于漏检却需要极力避免,因此为了尽可能检测出所有目标,此处设置了相对较小的置信度阈值(阈值为0.5),旨在发现更多的可疑目标,但也会造成误检率的提升。本文将在实验部分对此进行讨论。
2 训练与测试的实现细节
整个目标检测网络通过反向传播和随机梯度下降法对网络进行端到端的训练。文献[11-12]在训练和测试过程中对输入图像进行了多尺度变换,这种方式在一定程度上能够提高检测的准确性,但检测速度有所损失。本文采取一种折中方式:在训练时,对输入图像进行随机缩放,在保持原有长宽比例的条件下使其短边为400、600、1 000等多个像素尺寸;在测试时,直接使用输入图像的原始尺寸(1 024×768)。
整个目标检测网络的训练在VGG-16网络的基础上进行,该网络在Imagenet数据集上初始化训练完成。对于所有的新增层,遵循文献[12]的方法,采用零均值、标准差为0.01的高斯分布进行随机初始化完成。遵循文献[11]的训练规则,只对VGG-16网络conv3及其之后的层进行调节。由于采用多任务损失函数和bootstrapping采样可能导致训练早期的不稳定,故采用一种两步训练策略:1)对建议区域提取网络进行初始化,采用较小的平衡因子(λ=0.05),以0.000 1的学习率对建议区域提取网络进行10 000次迭代训练;2)将平衡因子和学习率分别增大为1和0.001,对整个网络进行20 000次迭代训练;随后将学习率缩小至0.000 1,继续进行10 000次迭代训练。整个训练过程均采用bootstrapping采样方式,每个批量包含256个训练样本,正负样本数量比例设置为1∶3(α=3),分别从两副输入图像中采样得到。当正样本数量不满足比例时,选用负样本对该批量进行补充。此外,动量因子设置为0.9,权重衰减因子设置为0.000 5. 对于各卷积层的权重因子,本文将第3和第4个卷积层的权重因子分别设置为0.8和0.9(ωconv3=0.8,ωconv4=0.9),将第5个卷积层以及池化层的权重因子均设置为1(ωconv5=1,ωpooling5=1)。实验结果表明,采用这种两步训练方式能够使整个网络快速趋于稳定。
3 实验及结果分析
为了验证本文所提方法的性能,针对坦克装甲目标构建专用的测试数据集,在该数据集上对提出的方法以及目前主流的目标检测方法Faster R-CNN进行训练和测试。此外,还在通用目标检测数据集Pascal VOC2007上对所提方法进行了测试分析。所有的测试评估均在核心配置为CPU:E5-2650Lv3/GPU:GTX-TITIAN-X的图形工作站上进行。整个目标检测网络在Ubuntu 14.04/Matlab 2014a上构建完成,在构建过程中使用了Caffe[26]框架。
3.1 构建针对坦克装甲目标的测试数据集
从多个场景拍摄图像中挑选出2 000张图像,构建一个小型坦克装甲目标样本库。如图2所示,该样本库拍摄于多种野外环境,包含多种车型的多个视角,并考虑遮挡、烟雾等多种复杂情况。随后,将样本图像的像素尺寸统一缩放为1 024×768,并采用LabelImg工具包对样本图像进行标注,对图像中目标的位置、大小和种类分别进行标定,使其满足Pascal VOC数据集的格式,以便后期对样本库进行学习训练。按照惯例,将样本库中的图像随机分为两组,其中1 400张用于训练,剩下600张用于测试,分别共包含3 159和1 344个坦克装甲目标。目前该数据集中的样本数量和类型还不够丰富,后续工作中还将对其进行完善。

图2 坦克装甲目标测试集中的部分样本图像Fig.2 Examples of tank and armored target test set
3.2 在坦克装甲目标测试数据集上的实验
根据馆藏《麦华三小楷书黎畅九李铁夫生轶事并跋》内容,文中提到的李铁夫的9幅水彩画作品现均藏我馆。②这组水彩作品材质均为宣纸,但构图和用色方式与其它水彩画一致。此外,归入水彩的藏品中还有2幅也确认是在宣纸上用水彩完成。
1.4 统计学分析 运用SPSS 18.0软件对数据进行统计学分析,数据均符合正态分布,计量资料以表示,数据比较采用独立样本t检验,计数资料以例(%)表示,数据比较采用χ2检验,P<0.05为差异有统计学意义。
由于CNN每一层的特征图对应不同大小的感知区域,每一个参与提取建议区域的卷积层负责提取不同尺度的建议区域。例如,第3个卷积层(conv3-3)负责提取最小尺度的目标,第5个池化层用来提取最大尺度的目标。这种提取方式可能导致在某一个卷积层上正样本数量的不足,即|S-|≫α|S+|,将导致训练的不稳定。因此,本文对分类损失函数的权重进行了修改:
表1展示了各卷积层提取的初始建议区域对目标的有效召回率。从表1可以看出,尽管各层所提取的初始建议区域只对相应尺寸的目标具有较高的召回率,但通过对各卷积层的结合使用,对所有尺寸的目标总的召回率达到了92.9%,从而证明了这种建议区域提取方法的有效性。
图3比较了本文的建议区域提取方法与Faster R-CNN所采用的RPN提取方法使用不同数量建议区域时的召回率。由图3可知,在使用相同数量的建议区域时,本文提取方法相比于RPN拥有更高的召回率(数量超过500个时两种方法的召回率持平)。本文的提取方法只需使用得分前100的建议区域,即可达到较高的召回率(92.9%),RPN则需要使用超过500个建议区域才能达到同等水平。使用较少的建议区域将有利于检测速度的提升,因此本文的提取方法更高效。图4比较了使用100个建议区域时,两种方法在不同IoU阈值时对应的召回率。由图4可以看出:当阈值被设定为0.5时,RPN和本文的方法均取得了较高的召回率;当设定的阈值超过0.7时,RPN对应的召回率下降幅度明显超过本文方法。从而表明了本文方法生成的建议区域相比于RPN更加精确,其主要原因在于RPN在最后一个卷积层上提取建议区域,由于分辨率不足,导致其对小目标的感知能力有限。本文在多个卷积特征图上提取不同尺度的建议区域,针对各种尺度的目标设计了相应大小的提取窗口,因此提取的建议区域更为精确。

表1 初始建议区域对目标的召回率
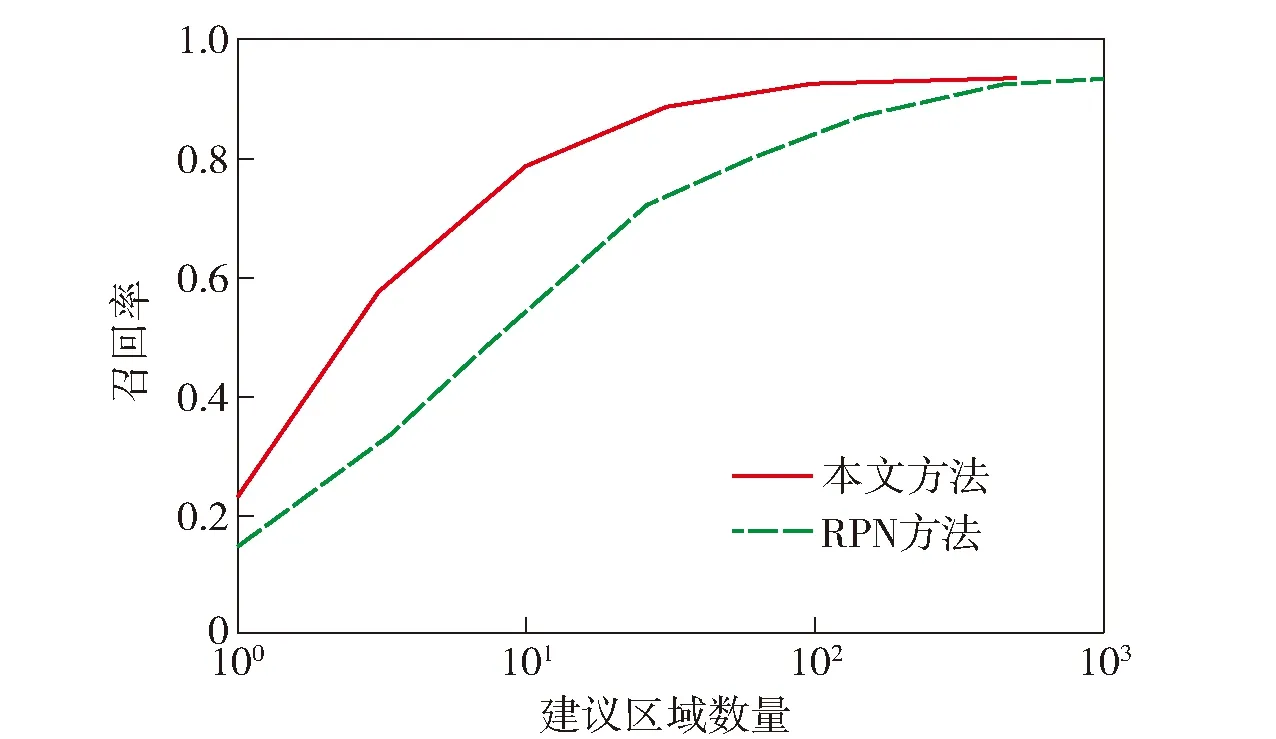
图3 不同数量建议区域对应的召回率(IoU=0.7)Fig.3 Recall rates corresponding to different number of region proposals (IoU=0.7)
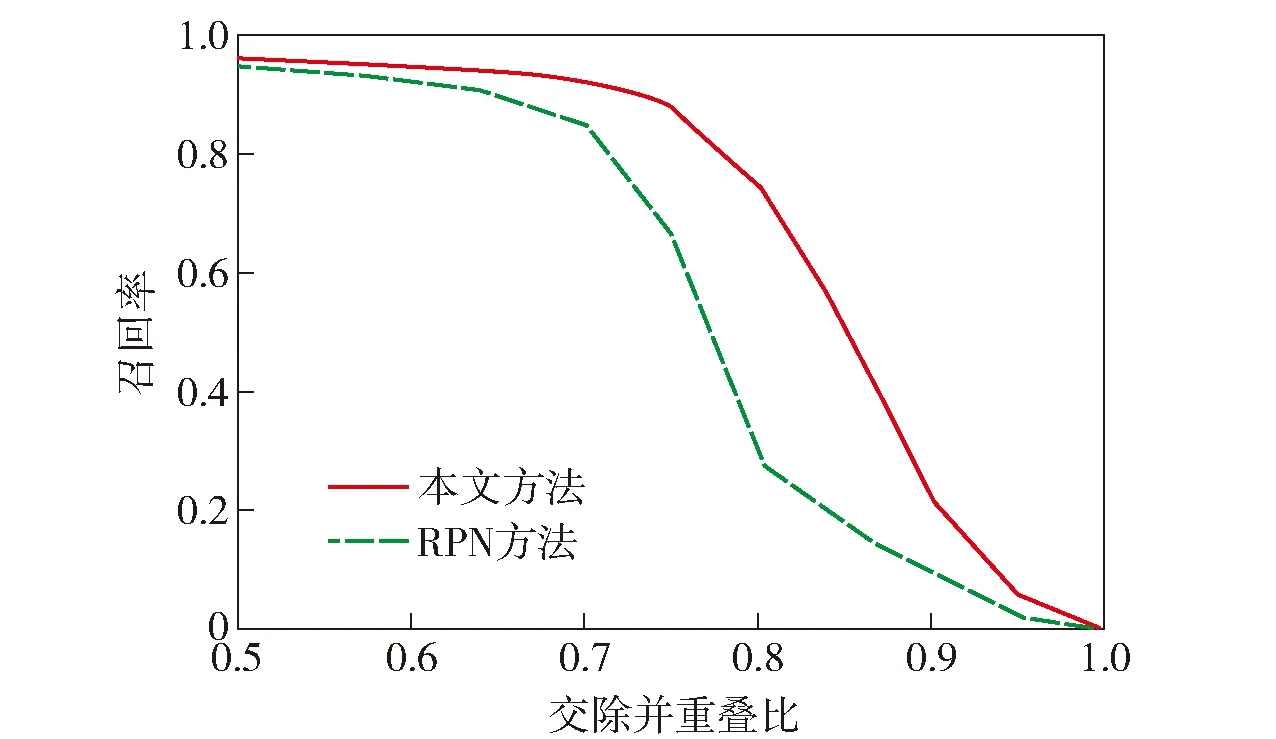
图4 不同交除并重叠比对应的召回率Fig.4 Recall rates corresponding to different IoUs
3.2.2 检测精度和速度分析
表2比较了本文方法以及Faster R-CNN在坦克装甲目标数据集上的检测精度与速度等性能指标。从总的检测精度来看,本文方法相比于 Faster R-CNN有7.4%的提升。从目标的大小尺度进行分析,尽管本文方法在大目标(≥100像素)上相对于Faster R-CNN检测率并无优势,但对于小于50像素的小目标,相比Faster R-CNN有10%~20%的提升,印证了本文方法在小目标检测上的优势。从检测速度来看,由于简化了全连接层,同时使用了更少的建议区域,对于1 024×768的输入图像,本文方法的检测速度达到10帧/s,略快于Faster R-CNN. 此外,由于本文方法旨在检测出更多的可疑目标,在提取最终目标时设置了相对宽松的置信度阈值,导致本文方法的误检率达到4.2%,比Faster R-CNN高出1.3%. 图5展示了本文方法在坦克装甲目标(tank)测试集上对部分样本的检测结果,其中红形矩形区域为正确检测到的目标,圆形实线区域为漏检的目标,圆形虚线区域表示误检。
3.2.3 模型分解实验
第三,中美意识形态的根本分歧。中国并未按照美国在过去数十年一直抱有的期望发展,即随着逐步融入美国和西方主导的国际体系,朝着西方期待的方向发展。20世纪初,美国为更多的占据中国的市场份额,打入中国市场,给予中国最惠国待遇,帮助中国加入世界贸易组织。美国希望随着中国经济市场化改革的深入,如东欧国家一样,改旗易帜,走上资本主义道路。但由于中国开辟了中国特色社会主义道路,经济社会发展稳步前进,不断突破,严重威胁了美国资本主义社会的经济霸主地位,导致其不得不转变对华贸易政策,通过打压社会主义中国的经济,维护其资本主义自身的利益。
五、学习贯彻十七大,围绕贴近基层服务,在深入调研上下功夫。随着改革的深化,大量劳动关系中的矛盾发生的基层,因此,工会的组织工作重心也必须“下移”。师团工会工作要围绕“三贴近”——贴近实际、贴近群众、贴近生活,有针对性地指导工作,夯实基础。今后,师团工会要进一步转变工作作风,深入基层、深入职工群众,大兴调查研究之风,做好职工热点、疑点、焦点问题化解,尤其要对带倾向性、典型性的问题进行调研,为工会组织积极投入新型团场建设,提供理论指导及对策。□
为了进一步验证本文方法的性能,在坦克装甲目标数据集上进行模型分解实验,分析文中使用的多种设计和训练方法对检测结果的影响。测试使用的输入图像采用与上文相同的尺度(1 024×768),表3展示了模型分解实验的结果。由表3可以看出,本文使用的多种设计和训练方法均对检测精度有一定的提升:使用分辨率更大的conv3-3卷积层来提取建议区域,增强对弱小目标的感知能力;不使用conv3-3卷积层时检测精度将下降2.5%;使用反卷积层增加了检测子网络特征图的分辨率,使最终的检测精度提升了2.8%;使用bootstrapping采样方式增强了对困难负样本的挖掘能力,能够将检测精度提升1.9%;在训练时对输入图像进行多尺度的缩放,使检测精度提升了2.3%。需要指出的是,这些方法并未对检测速度造成较大的影响。本文尝试了在测试时对输入图像进行多尺度缩放,这种处理方式能够将检测精度提升1.7%,但检测的速度也将大幅下降,因此并未被使用。
这时,牛皮糖就拨开众人,冲到前面,手舞足蹈的和肉仔吵起来。大家都不再买肉,停在那里看。受不了吵闹的老人就走开到远点的肉摊上去了。

表2 在坦克装甲目标数据集上的测试结果
3.3 在VOC2007数据集上的测试结果
除了在坦克装甲目标数据集上进行测试外,本文还在更通用的VOC2007数据集上对提出的方法进行了测试,并将测试结果与Faster R-CNN进行比较。为了公平比较,训练样本集均由VOC2007-trainval和VOC2012-trainval构成,测试样本集为VOC2007-test。由于VOC2007和VOC2012中样本图像的像素大小约为500×375,本文沿用Faster R-CNN对输入图像的处理方式,在保持原有长宽比例的条件下将其短边缩放为600像素,在单一尺度下对样本进行训练和测试。此处采用的数据集相比于坦克装甲目标数据集有更多的样本,因此训练时需要迭代更多的次数:第一步训练,以0.000 1的学习率对建议区域提取网络进行40 000次迭代训练;第二步训练,将学习率增大至0.001,对整个网络进行80 000次迭代训练;随后将学习率缩小至0.000 1,继续进行40 000次迭代训练。表4展示了两种方法在VOC2007数据集上的测试结果。从总的检测精度看,由于VOC2007数据集中包含了大量尺寸超过300像素的超大目标,本文方法相比于Faster R-CNN基本持平。从不同种类的检测结果进行分析:对于公交车、飞机、火车、马等大物体种类,Faster R-CNN比本文方法的检测精度更高;对于猫、小轿车、桌子、电视机等中等尺度的物体种类,本文方法和Faster R-CNN在检测精度上基本持平;对于鸟、瓶子、植物等小物体种类,本文方法相比于Faster R-CNN有5%~10%的优势。这一结果与预期相符,由于本文方法的设计初衷是主要针对小于200像素的中小物体检测,提取建议区域的最大滑动窗口大小仅为288×288,相比于Faster R-CNN中最大为768×437的锚点生成区域,对公交车和飞机等超大物体的检测能力有一定的差距。然而,由于坦克装甲车辆的观测打击距离较远,这种超大目标在实际情况中很难出现。

图5 坦克装甲目标测试集上部分样本检测结果Fig.5 Example detection results of tank and armored target test set

项目结果conv3-3✕√√√√√反卷积层√✕√√√√bootstrapping√√✕√√√输入多尺度缩放(训练)√√√✕√√输入多尺度缩放(测试)✕✕✕✕✕√检测精度/%66.766.467.366.969.270.9
注:“√”代表使用,“×”代表不使用。

表4 在VOC2007数据集上的测试结果
4 结论
本文针对坦克装甲目标图像检测任务,提出了一种基于深度CNN的多尺度目标检测方法。采用迁移学习的设计思路,在VGG-16网络的基础上针对目标检测任务对网络的结构和参数进行修改和微调,结合建议区域提取网络和目标检测子网络,实现对目标的精确检测。针对小目标在深层卷积特征图上分辨率不足的问题,在多个不同分辨率的卷积特征图上提取不同尺度的建议区域,并在分辨率更高的卷积特征图中提取目标,同时通过上采样方式进一步提升特征图的分辨率。通过结合多尺度训练、困难负样本挖掘等多种设计和训练方法,本文方法在构建的坦克装甲目标数据集取得了优异的检测效果,目标检测的精度和速度均优于目前主流的检测方法Faster R-CNN.
笔者所设计的民族综合信息大数据平台资源库管理系统,可实现内蒙古民族信息的统一管理和资源整合。随着信息技术的发展,资源库管理系统将进一步推进大数据平台的发展,民族信息的管理体系也将随之完善。
下一步工作将对所构建的坦克装甲目标数据集进行进一步完善,同时将尝试在深度CNN的基础上采用循环神经网络对视频图像的时序信息进行处理,将单帧图像的信息与帧和帧之间的变化信息进行融合,从而对视频图像进行更高效的目标检测。
References)
[1] 尹宏鹏, 陈波, 柴毅, 等. 基于视觉的目标检测与跟踪综述[J]. 自动化学报, 2016,42(10): 1466-1489. YIN Hong-peng, CHEN Bo, CHAI Yi, et al. Vision-based object detection and tracking[J]. Acta Automatica Sinica, 2016,42(10): 1466-1489. (in Chinese)
[2] 王铁虎, 焦爱泉, 冯连仲, 等. 精确打击作战与装甲装备未来发展[J]. 兵工学报, 2010,31(增刊2): 59-65. WANG Tie-hu, JIAO Ai-quan, FENG Lian-zhong, et al. Future development of armored equipment and precise attack operation [J]. Acta Armamentarii, 2010,31(S2): 59-65. (in Chinese)
[3] 郭明玮, 赵宇宙, 项俊平, 等. 基于支持向量机的目标检测算法综述[J]. 控制与决策, 2014, 29(2): 193-200. GUO Ming-wei, ZHAO Yu-zhou, XIANG Jun-ping, et al. Review of object detection methods based on SVM[J]. Control and Decision, 2014, 29(2): 193-200. (in Chinese)
[4] Felzenszwalb P, Girshick R, Allester D M, et al. Object detection with discriminatively trained part based models [J]. IEEE Tran-sactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[5] 吴青青,许廷发,闫辉, 等. 复杂背景下的颜色分离背景差分目标检测方法[J]. 兵工学报, 2013, 34(4): 501-506. WU Qing-qing, XU Ting-fa, YAN Hui, et al. An improved color separation method for object detection in complex background [J]. Acta Armamentarii, 2013, 34(4): 501-506. (in Chinese)
[6] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]∥Proceedings of the 2012 Advances in Neural Information Processing Systems. Cambridge, MA, US: The MIT Press, 2012: 1097-1105.
[7] Deng J, Dong W, Socher R, et al. ImageNet: a large-scale hierarchical image database[C]∥Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL ,US: IEEE, 2009: 248-255.
[8] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]∥Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH,US: IEEE, 2014: 580-587.
[9] Uijlings J R, Sande V D, Gevers K E, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171.
[10] Everingham M, Van G L, Williams C K, et al. The Pascal visual object classes (VOC) challenge [J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[11] Girshick R. Fast R-CNN[C]∥Proceedings of the IEEE 14th International Conference on Computer Vision. Chile: IEEE, 2015: 1440-1448.
[12] Ren S Q, He K M, Girshick R B, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]∥Proceedings of the 2015 Advances in Neural Information Processing Systems. Cambridge, MA, US: MIT Press, 2015: 91-99.
[13] Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context [C]∥Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014: 740-755.
[14] Zeiler M D, Fergus R. Visualizing and understanding convolutional neural networks [C]∥Proceedings of the 13rd European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014: 818-833.
[15] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10) [2016-11-15]. http:∥arxiv.orb/abs/1409.1556.
[16] Redmon J, Divvala S K, Girshick R B, et al. You only look once: unified, real-time object detection [EB/OL]. (2016-05-09) [2016-11-14]. http:∥arxiv.orb/abs/1506.02640.
[17] Liu W, Anguelov D, Erhan D, et al. SSD: single shot multi box detector [EB/OL]. (2016-03-30) [2016-11-15]. http:∥arxiv.orb/abs/1512.02325.
[18] Oquab M, Bottou L, Laptev I, et al. Learning and transferring mid-level image representations using convolutional neural networks[C]∥Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH,US: IEEE, 2014: 1717-1724.
[19] 石祥滨, 房雪键, 张德园, 等. 基于深度学习混合模型迁移学习的图像分类[J]. 系统仿真学报, 2016,28(1): 167-174. SHI Xiang-bin, FANG Xue-jian, ZHANG De-yuan, et al. Image classification based on mixed deep learning model transfer learning[J]. Journal of System Simulation, 2016, 28(1): 167-174. (in Chinese)
[20] LeCun Y, Boser B, Denker J, et al. Back propagation applied to hand written zip code recognition[J]. Neural Computation, 1989, 1(4): 541-551.
[21] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]∥Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, US: IEEE, 2015:1-9.
[22] Kong T, Yao A B, Chen Y, et al. HyperNet: towards accurate region proposal generation and joint object detection [EB/OL]. (2016-04-03) [2016-11-14]. http:∥arxiv.orb/abs/1604.00600.
[23] Bell S, Zitnick C L, Bala K, et al. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks [EB/OL]. (2015-12-14) [2016-11-14]. http:∥arxiv.orb/abs/1512.04143.
[24] Cai Z, Fan Q, Feris R, et al. A unified multi-scale deep convolutional neural network for fast object detection [EB/OL]. (2016-07-25) [2016-11-14]. http:∥arxiv.orb/abs/1607.07155.
[25] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]∥Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA,US: IEEE, 2015: 3431-3440.
[26] Jia Y. Caffe: an open source convolutional architecture for fast feature embedding [EB/OL]. [2016-10-15]. http:∥caffe.berkeleyvision.org/2013.
[27] Hosang J, Benenson R, Dollar P, et al. What makes for effective detection proposals? [EB/OL]. (2015-08-01) [2016-11-14]. http:∥arxiv.orb/abs/1502. 05082.
ImageDetectionMethodforTankandArmoredTargetsBasedonHierarchicalMulti-scaleConvolutionFeatureExtraction
SUN Hao-ze, CHANG Tian-qing, WANG Quan-dong, KONG De-peng, DAI Wen-jun
(Department of Control Engineering, Academy of Armored Force Engineering, Beijing 100072, China)
TP391.413
A
1000-1093(2017)09-1681-11
10.3969/j.issn.1000-1093.2017.09.003
2016-11-14
总装备部院校科技创新工程项目(ZXY14060014)
孙皓泽(1989—), 男, 博士研究生。E-mail: sunhz1989@163.com
常天庆(1963—), 教授, 博士生导师。 E-mail: changtianqing@263.net
