KD-TSS:精确隐私空间分割方法*
2017-10-12金凯忠张啸剑彭慧丽
金凯忠,张啸剑+,彭慧丽,2
1.河南财经政法大学 计算机与信息工程学院,郑州 450046
2.河南广播电视大学,郑州 450008
KD-TSS:精确隐私空间分割方法*
金凯忠1,张啸剑1+,彭慧丽1,2
1.河南财经政法大学 计算机与信息工程学院,郑州 450046
2.河南广播电视大学,郑州 450008
Abstract:KD-Tree-based differentially private spatial decomposition has attracted considerable research attention in recent years.The trade-off between the size of spatial data and Laplace noise directly constrains the accuracy of decomposition.This paper proposes a straightforward method with differential privacy,called SKD-TS(samplingbased KD-Tree)to partition spatial data.To handle the large-scale spatial data,this method employs Bernoulli random sampling technology to obtain the samples.While SKD-Tree still relies on the height of KD-Tree to control the Laplace noise.However,the choice of the height is a serious subtitle:a large height makes excessive noise in the nodes,while a small height leads to the partition too coarse-grained.To remedy the deficiency of SKD-Tree,this paper proposes another method,called KD-TSS(KD-Tree with sampling and SVT)for spatial decomposition.The sparsevector technology(SVT)is used in KD-TSS to judge whether a node of KD-Tree should be split,without depending on the height.SKD-TS and KD-TSS methods are compared with existing methods such as KD-Stand,KD-Hybird on the large-scale real datasets.The experimental results show that the two algorithms outperform their competitors,achieve the accurate decomposition and results of range query.
Key words:differential privacy;KD-Tree;private spatial decomposition;Bernoulli random sampling;sparse vector technology
基于KD-树与差分隐私保护的空间数据分割得到了研究者的广泛关注,空间数据的大小与拉普拉斯噪音的多少直接制约着空间分割的精度。针对现有基于KD-树分割方法难以有效兼顾大规模空间数据与噪音量不足的问题,提出了一种满足差分隐私的KD-树分割方法SKD-Tree(sampling-based KD-Tree)。该方法利用满足差分隐私的伯努利随机抽样技术,抽取空间样本作为分割对象,然而却没有摆脱利用树高度控制拉普拉斯噪音。启发式设定合适的树高度非常困难,树高度过大,导致结点的噪音值过大;树高度过小,导致空间分割粒度太粗劣。为了弥补SKD-Tree方法的不足,提出了一种基于稀疏向量技术(sparse vector technology,SVT)的空间分割方法KD-TSS(KD-Tree with sampling and SVT)。该方法通过SVT判断树中结点是否继续分割,不再依赖KD-树高度来控制结点中的噪音值。SKD-Tree、KD-TSS与KD-Stand、KD-Hybrid在真实的大规模空间数据集上实验结果表明,其分割精度以及响应范围查询效果优于同类算法。
差分隐私;KD-树;隐私空间划分;伯努利随机抽样;稀疏向量技术
1 引言
信息时代的飞速发展,空间数据的获取与收集变得尤为容易,例如移动用户位置、GPS位置、家庭住址等数据。通过对空间数据的分析,使得交通监控、位置推荐等应用能够提高自身的服务质量。然而,空间数据蕴含着丰富的个人敏感信息,在提供给第三方应用的同时,个人的敏感信息有可能被泄露。因此,如何在隐私保护的前提下,发布空间数据是当前基于位置服务的主要挑战问题。匿名化[1]与差分隐私[2-4]是常用的隐私保护模型。然而,匿名模型由于对攻击背景知识与攻击模型给出过多特定假设,而不适合真实的位置服务。例如,文献[5]指出针对150万条匿名后的用户位置数据,在无任何背景假设情况下,随机给出2个时空点,能够甄别出50%用户的敏感位置,随机给出4个时空点,能够甄别出97%用户的敏感位置。不同于传统的匿名化模型,差分隐私模型要求数据库中任何一个用户的存在都不应显著地改变任何查询的结果,从而保证了每个用户加入该数据库不会对其隐私造成危险。
近年来,出现了几种满足差分隐私的KD-树空间划分方法。HKD-Tree(hierarchical KD-tree)[6]是此类方法的早期代表。该方法利用部分隐私代价对原始空间数据进行网格划分,然后基于网格的每个划分单元构建KD-树。然而,该方法没有从数据相关(data dependent)的角度考虑空间数据的实际分布与大小,KD-树仅起到索引作用。文献[7]是最早从数据相关角度分割空间数据的,并给出KD-Stand与KD-Hybrid两种方法。KD-Stand方法利用指数机制[8]寻找每次分割的中位数(例如图1中的a点),KD-Hybrid结合四分树与KD-树达到比较理想的分割效果。上述几种方法均采用KD-树对空间数据进行分割,然而这些方法存在以下问题。
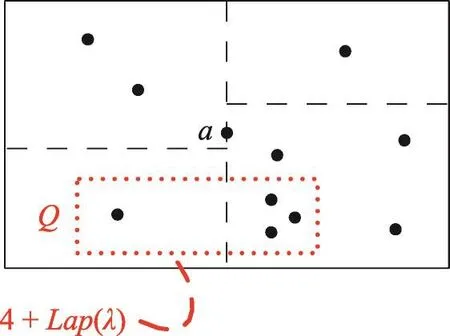
Fig.1 Spatial decomposition with KD-Tree图1 基于KD-树的空间分割
问题1 HKD-Tree、KD-Stand以及KD-Hybrid方法仅仅在小的空间数据上进行分割,支持相应的范围查询。然而,当数据点达到百万级别时,这些方法的分割与响应查询精度很低。
问题2 HKD-Tree、KD-Stand以及KD-Hybrid方法通常逐层分配隐私代价(例如ε/h,h为KD-树的高度),然后利用结点中的噪音值判断该结点是否继续分割(例如判断图1中Q查询的结果4+Lap(λ)≥θ是否成立,其中θ为分割阈值,λ≥ε/h)。然而,当h很大时,KD-树的分割精度会急剧降低。
总而言之,目前还没有一个行之有效的方法同时克服上述两种差分隐私下KD-树分割空间数据的不足。为此,本文提出了两种融合抽样与稀疏向量技术(sparse vector technology,SVT)的KD-树分割方法,在满足差分隐私的情况下,采用伯努利抽样技术对大规模原始空间数据进行抽样,在构建KD-树分割过程中,利用稀疏向量技术判断结点是否继续分割,实现高质量的空间数据发布。
本文主要贡献如下:
(1)为了解决问题1,提出了SKD-Tree(samplingbased KD-Tree)方法,该方法利用伯努利抽样技术对海量空间数据进行抽样,不但满足差分隐私需求,而且能够比较精确地响应范围查询。
(2)为了有效解决问题2,提出了KD-TSS(KDTree with sampling and SVT)方法,该方法利用抽样与稀疏向量技术对KD-树中结点进行分割判断,不再按照KD-树的高度逐层分配隐私代价,进而减少结点分割误差,提升了叶子结点中计数值的发布精度。
(3)理论分析了SKD-Tree与KD-TSS方法满足ε-差分隐私,通过真实数据集上的实验分析展示了两种方法在兼顾高可用性和准确性的同时,优于同类方法。
2 相关工作
差分隐私拥有极强的保护能力,并依赖严谨的统计模型,这些特点使其得到广泛研究和应用。当前学术界的应用着重关注差分隐私保护下的直方图发布[9]、高维数据发布[10-11]等。鉴于空间数据在分析应用中的重要性,研究者已经提出了多种基于差分隐私的空间数据分割方法。HKD-Tree[6]是空间数据分割的早期代表,该方法利用网格分割原始数据,并为每个网格单元添加噪音,利用KD-树进行索引,其只有在数据均匀分布的前提下才有效。Quad-post[7]利用四分树与后置处理技术发布空间数据,该方法同样没有考虑原始数据分布,仅对叶子结点中计数添加相应的噪音。HKD-Tree与Quad-post通常利用树的高度控制噪音大小,然而PrivTree[12]在添加噪音时,不依赖于树高度,该方法利用一个噪音常量来判断某个结点是否分割。网格也是空间数据分割常用的数据结构。UG(uniform grid)[13]采用均匀网格划分二维空间数据,并为每个划分单元添加噪音,然而该方法无法顾及原始数据分布的偏斜问题。针对UG方法的不足,AG(adaptive grid)[13]根据高层划分单元的粒度不同,自适应地自顶向下划分,然而该方法同样没有考虑原始数据的实际分布。
上述方法大都属于数据无关(data independent)的方法,这类方法通常不考虑原始数据分布,其优势在于能够给出严谨的数据效用理论下限。但在实际数据上,这一系列方法均无法获得理想的数据可用性和效率,从而引出了数据相关方法的研究。所有空间数据相关的研究中最有希望的当属基于KD-树的分割方法。KD-Stand[7]利用指数机制分割中位数,以免泄露实际的数据点,并利用结点中的噪音计数与给定的阈值相比较,来判断该结点是否继续分割。不同于KD-Stand,KD-Hybrid[7]首先利用四分树分割部分原始数据,然后再利用KD-树分割剩余数据。然而,KD-Stand与KD-Hybrid两种方法具有相同的不足之处,二者均采用启发式设定树的高度来控制结点中的噪音量。而树的高度通常无法具体设定,树高度太小,导致空间数据分割粒度太粗劣;树高度太大,导致叶子结点中的噪音值过大,影响最终的范围查询精度。此外,KD-Stand与KD-Hybrid两种方法很难应对大规模空间数据。因此,本文针对上述数据相关方法的不足,提出了两种基于抽样的空间分割方法KD-TSS与SKD-Tree,其中KD-TSS方法不依赖于树高度来控制噪音的大小。针对大的空间数据集,KD-TSS与SKD-Tree能够比较精确地进行范围查询。
3 定义与问题
3.1 差分隐私
传统的隐私保护模型如k-匿名[1]通常对攻击背景知识与攻击模型给出特定的假设,而现实中这些假设并不成立。相比于传统保护模型,差分隐私保护模型具有两个显著的特点:(1)不依赖于攻击者的背景知识;(2)具有严谨的统计学模型,能够提供可量化的隐私保证。本文所关心的是在分割空间数据时,如何使得空间分割过程满足差分隐私。
定义1(近邻关系)设D={d1,d2,…,dn}为原始空间数据点,D′={d1,d2,…,dr-1,dr+1,…,dn},D与D′相差一个数据点,则二者互为近邻关系。
结合D与D′给出ε-差分隐私的形式化定义,如定义2所示。
定义2(ε-差分隐私)给定一个空间数据分割方法A,Range(A)为A的输出范围,若方法A在D与D′上任意分割结果T(T∈Range(A))满足下列不等式,则A满足ε-差分隐私:

其中,ε表示隐私预算,其值越小则方法A的隐私保护程度越高。
从定义2可以看出,ε-差分隐私限制了任意一个记录对方法A输出结果的影响。实现差分隐私保护需要噪音机制的介入,拉普拉斯与指数机制是实现差分隐私的主要技术。所需要的噪音大小与其响应查询函数f的全局敏感性密切相关。
定义3(全局敏感性)设f为某一个查询,且f:D→Rd,f的全局敏感性为:

其中,R为映射的实数空间;d为f的查询维度。
文献[2]提出的拉普拉斯机制可以取得差分隐私保护效果。该机制利用拉普拉斯分布产生噪音,进而使得发布方法满足ε-差异隐私,如定理1所示。
定理1[2]设f为某一个查询函数,且f:D→Rn,若方法A符合下列等式,则A满足ε-差异隐私:
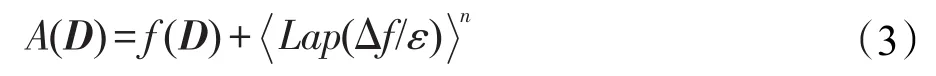
其中,Lap(Δf/ε)为相互独立的拉普拉斯噪音变量,噪音量大小与Δf成正比,与ε成反比。因此,查询f的全局敏感性越大,所需的噪音越多。
文献[8]提出的指数机制主要处理抽样算法的输出为非数值型的结果。该机制的关键技术是如何设计打分函数u(D,di)。设A为指数机制下的某个隐私方法,则A在打分函数作用下的输出结果为:

其中,Δu为打分函数u(D,di)的全局敏感性;Ω为采用算法的输出域。由该公式可知,di的打分函数越高,被选择输出的概率越大。
定理2[8]对于任意一个指数机制下的方法A,若A满足式(4),则A满足ε-差分隐私。
3.2 范围查询误差
给定一个原始二维空间数据集D={d1,d2,…,dn},每个di为一个二维数据点。基于D进行KD-树分割,得到满足差分隐私的分割结果T。本文的问题是如何针对T进行比较精确的范围查询。而在响应范围查询时,两种误差无法避免:一是采样本身带来的误差(sampling error,SE);二是结点中的拉普拉斯误差(Laplace error,LE)。给定一个范围查询Q,假设有q个数据点落入Q查询,则Q携带的误差如式(5)所示:
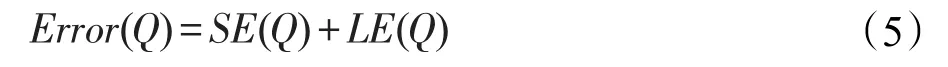
本文采用与文献[14]相同的方法,利用均方差来度量伯努利采样误差。设参数γ为抽样概率,则SE(Q)=q(1-γ)/γ。利用拉普拉斯分布的方差度量拉普拉斯噪音误差,则LE(Q)=2q(h/ε)2,其中h为KD-树的高度,进而使得Error(Q)=q(1-γ)/γ+2q(h/ε)2。
因此,如何使得Error(Q)尽量小是本文研究的重点。文献[6-7]采用启发式设置KD-树的高度h达到控制范围查询误差作用。而本文通过稀疏向量技术避免了拉普拉斯噪音对树高度h的依赖。
4 基于KD-树的空间分割方法
4.1 空间分割的原则
基于相关工作部分的分析,在设计新的基于KD-树空间分割方法时需要考虑如下原则:
原则1针对大规模空间数据问题,所设计的分割方法应在满足差分隐私条件下尽量抽取充足数据点作为分割对象。
原则2针对传统方法通过人工设置KD-树高度控制拉普拉斯噪音的缺陷,所设计的分割方法应尽量避免所添加噪音对树高度的依赖。
针对原则1,本文利用伯努利随机抽样技术抽样空间数据点,并且该抽样方法满足差分隐私。基于原则1,本文设计一种直接方法SKD-Tree。然而,SKD-Tree方法在添加拉普拉斯噪音时,没有脱离对KD-树高度的依赖。
针对原则2,本文利用满足差分隐私的稀疏向量技术判断KD-树结点是否继续分割。在分割结点时,判断条件不再依赖树的高度。基于原则1与原则2,本文设计一种高效方法KD-TSS来分割空间数据。
4.2 SKD-Tree算法实现
本节描述SKD-Tree算法的具体实现细节。
算法1 SKD-Tree算法
输入:D,隐私预算ε,分割阈值θ,树高度h。
输出:满足差分隐私的KD-树T。

该算法包括两个主要步骤:伯努利随机抽样(第1~2行)与KD-树分割(第4~11行)。在利用KD-树分割每个结点时,两种操作至关重要:判断每个结点中的噪音计数是否大于给定阈值θ(第7~8行)。对于可分割结点,利用指数机制选择其分割中位线(第9行)。接下来介绍如何利用指数机制选择中位线。
4.2.1 中位线选择方法EM
因为在树结点中选择中位数的过程,位于中位线上数据点的隐私有可能被泄露,所以该选择过程需满足差分隐私。本文利用指数机制实现该步骤。
设结点vi=<x1,x2,…,xl>的数据点属于区间[a,b],且x1≤x2≤…≤xl是按照升序排列。设xm是vi的真实中位数,任意取一个数值xi(xi∈[a,b]),则xi被选择的概率如式(6)所示:
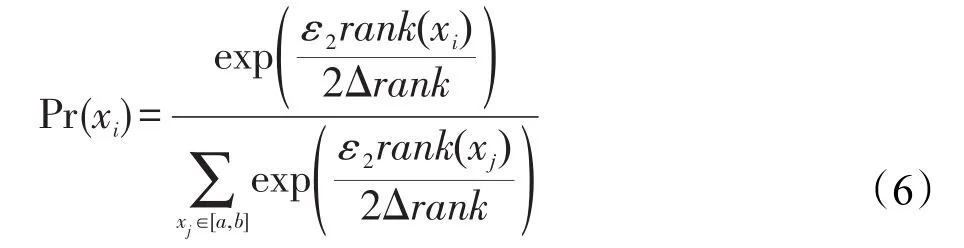
其中,rank(xi)表示xi在结点vi中的排名;Δrank表示排名函数的敏感性。在D中添加一个或者去掉一个数据点,rank函数的最大变化为1,因此Δrank=1。由式(6)可知,与真实中位数xm排名越接近的值,被选中的概率越大。
结合式(4)与式(6),算法SKD-Tree的第9行可表示为:
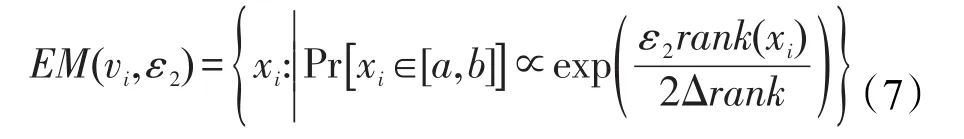
根据定理2可知,EM(vi,ε2)过程满足ε2-差分隐私,进而使得选择中位数的过程不会泄露该值的隐私。
4.2.2 伯努利随机抽样过程
SKD-Tree算法的另外一个重要步骤是伯努利随机抽样,该过程的操作细节如下:首先确定抽样概率γ,然后以γ对D做伯努利实验,如果实验成功,则获得空间样本,否则放弃该样本。最后,计算出整个空间分割所需的隐私代价εγ(SKD-Tree算法第2行所示)。该过程的关键在于如何使得抽样过程满足差分隐私。文献[15]给出的定理3说明该过程满足ln(1+γ(eε-1))-差分隐私。
定理3给定一个数据D,令方法A在D上满足ε-差分隐私。如果方法Aγ操作包括:以概率γ从D中抽取样本获得,然后A作用于,则Aγ满足ln(1+γ(eε-1))-差分隐私。
接下来要证明SKD-Tree算法如何满足ε-差分隐私。如定理4所示。
定理4 SKD-Tree算法满足ε-差分隐私。
证明 设A是SKD-Tree没有抽样操作的算法,即是算法SKD-Tree去掉第1行与第2行。Aγ表示SKD-Tree算法本身。首先证明A满足εγ-差分隐私。
算法A中只有第7行与第9行用到隐私代价。第7行为每个结点添加Lap(h/ε1)大小的噪音,其原因是在D中添加或去掉一个数据点时,最多影响h个结点的计数。结合差分隐私并行性质[16]与顺序性质[16],利用定理1可知,第7行满足ε1-差分隐私。结合定理2可知,第9行满足ε2-差分隐私。由于第7行与第9行是顺序执行,并且εγ=ε1+ε2,因此A满足εγ-差分隐私。
由于εγ=ln(eε-1+γ)-lnγ,结合定理3可知,算法Aγ满 足差分隐私。把εγ带入,则ln(1+γ(eln(eε-1+γ)-lnγ-1))=ε,因此可知算法Aγ满足ε-差分隐私,由于Aγ表示SKD-Tree算法本身,则SKD-Tree满足ε-差分隐私。
由上述的分析可知,SKD-Tree算法只是利用抽样技术克服了海量数据带来的分割困难。由式(5)可知,SKD-Tree算法的查询误差由树高度h控制。然而,启发式设定h非常困难,h过大或者过小均会造成范围查询的精度较低。为了同时满足原则1与原则2,本文设计一种更有效的算法KD-TSS。
4.3 KD-TSS算法实现
本节描述KD-TSS算法的具体实现细节。
算法2 KD-TSS算法
输入:D,隐私预算ε,分割阈值θ。
输出:满足差分隐私的KD-树T。


该算法的核心步骤包括稀疏向量技术SVT(第4~6行)与KD-树的重构技术Re-Gen-Tree(第10行)。利用SVT判断结点是否被分割(第6~8行),若满足条件,则利用EM函数分割该结点。结合所有的叶子结点噪音计数,利用Re-Gen-Tree重新构造KD-树。利用重构的KD-树来响应范围计数查询。在为结点添加噪音时,不再依赖于树高度h,其原因是KD-TSS算法并不实际保存中间结点的噪音计数。中间结点的噪音计数只是与SVT计算出的阈值进行比较,相当于一个“是/否”的应答。接下来介绍稀疏向量技术。
4.3.1 稀疏向量技术
稀疏向量技术(SVT)[17-19]通常用来响应有限个大于某阈值的计数查询。该技术包含两个主要步骤:一是寻找合适的阈值θ,添加噪音后获得二是对每个查询结果c(v)添加噪音后获得,并与噪音阈值比较。比较结果有两种:一是若则输出;否则输出一个标识符号⊥。本文SVT技术的具体表示形式如式(8)所示:

不同于文献[5],本文在计算结点噪音值的过程中并不分割隐私代价ε1,其原因是在利用SVT分割结点时,被分割结点中的噪音值并没有实际保存到该结点中,与仅在形式上进行比较。例如,设定图2中的KD-树扇出为4,对v4结点进行判断是否继续分割。由于则v4结点被分割成4个结点。然而值6+Lap(2/ε1)却没有保存在v4结点中。由于v2、v3、v5结点中的噪音值小于则不再继续分割。对于v2、v3、v5这样的结点,具体的噪音值应保存在结点中(算法2中的第4行)。例如v2结点中的噪音计数为1+Lap(2/ε1)。
接下来一个关键问题是如何找到合适的阈值θ。为了找到恰当的θ,首先不考虑数据点隐私,结合空间数据点构建KD-树。然后记录所有叶子结点中的计数值{c(v1),c(v2),…,c(vi)},求出{c(v1),c(v2),…,c(vi)}的中值作为阈值θ。
当利用SVT对空间分割后,形成了相应的KD-树结构。树中所有的叶子结点记录相应的噪音值。由于在分割过程中,一些结点的噪音值没有被保存下来,如何恢复这些结点的噪音值是另一个关键问题。接下来介绍如何利用叶子结点计数值重构KD-树。
4.3.2 KD-树重构过程Re-Gen-Tree
满足差分隐私的KD-树空间分割,其最终目的是能够精确响应范围查询。给定一个范围查询Q,在遍历树过程中,Q与树中结点v交集存在几种情况:(1)Q完全包含v,此时v中的数据点全部落入Q中;(2)Q与v没有交集,此时抛弃结点v;(3)Q与v部分相交,此时利用相交部分响应Q。
在利用SVT与EM对结点进行分割时,一些结点的噪音值并没有被记录下来。如果只利用最终的叶子结点响应范围计数查询,查询精度与查询效率会非常低。例如,图2中给出范围查询Q,自顶向下遍历KD-树,得到响应结点v1、v4、v5、v9。然而,由于结点v4中的噪音值没有被记录,无法精确响应Q。
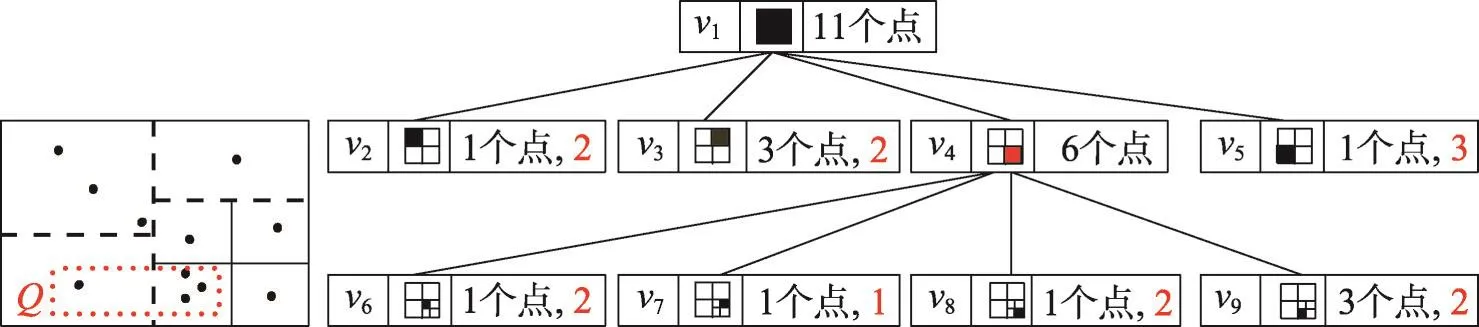
Fig.2 An example of KD-Tree decomposition图2 KD-树分割实例
为了能够比较精确地响应范围查询,本文设计了KD-树重构算法。
算法3 Re-Gen-Tree
输入:仅有叶子结点计数的KD-树T。
输出:各结点均有计数的树T。

算法Re-Gen-Tree主要包含两个过程top-downtravel(T)与bottom-up-travel(T,S)。其中top-down-travel(T)主要用来寻找那些被分割的结点,并存入S中(过程1的第7行),同时把叶子结点的噪音计数叠加到其父结点中(过程1的第4~5行)。bottom-up-travel(T,S)过程主要用来恢复那些被分割却没有噪音计数的结点(过程2的第2~5行)。
例如,图2结点中红色数字为噪音值,黑色数字为真实计数值。自顶向下遍历KD-树,结点v1与结点v4中没有实际的计数值。把结点v1与结点v4放入S中,把叠加到结点v1中,把叠加到结点v4中,得到。然后,自底向上遍历KD-树,叠加到结点v1中,得到。得到所有结点的噪音值后,即可应用重构后的KD-树响应范围查询。
接下来比较KD-TSS与SKD-Tree的范围查询误差。根据式(5),设ErrorKD-TSS(Q)表示KD-TSS的查询误差,ErrorSKD-Tree(Q)表示SKD-Tree的查询误差。
定理5在大规模空间数据环境中,KD-TSS与SKD-Tree的查询误差满足不等式ErrorKD-TSS(Q)<ErrorSKD-Tree(Q)。
证明 利用反证法进行证明。
假设ErrorKD-TSS(Q)>ErrorSKD-Tree(Q)。根据式(5)可知,ErrorSKD-Tree(Q)=q(1-γ)/γ+2q(h/ε)2,ErrorKD-TSS(Q)=q(1-γ)/γ+2q(2/ε1)2。假设 KD-TSS与SKD-Tree采用相同的抽样概率,落入Q查询中的数据点相同,则不等式ErrorKD-TSS(Q)>ErrorSKD-Tree(Q),使得如下不等式(2/ε1)2>(h/ε)2成立。进而使得h<2ε/ε1成立。由于ε1为KD-树中的叶子结点添加噪音,通常ε/ε1≤ 2,进而得到h≤4。由于KD-树通常表示成二叉树,则。而在数据点达到百万级别,h≤4不成立。因此,不等式ErrorKD-TSS(Q)<ErrorSKD-Tree(Q)成立。
4.4 KD-TSS算法隐私性分析
KD-TSS算法的隐私性主要从ε-差分隐私的概念和性质的角度来证明,论证KD-TSS算法是否满足ε-差分隐私。
定理6 KD-TSS算法满足ε-差分隐私。
证明 根据算法2可知,用到隐私代价的只有SVT技术(KD-TSS中第4~6行)与EM操作(KD-TSS中第7行)。根据定理2可知,EM操作满足ε2-差分隐私。因此,只要证明SVT技术满足ε1-差分隐私,即可推理出KD-TSS满足ε-差分隐私。
在利用SVT技术判断KD-树的结点是否被分割时,相当于系列的“是/否”应答。因此,为了证明方便,采用二元向量v=<x1,x2,…,xt>记录结点是否分割。如果则xi=1,表示结点vi被分割;否则,xi=0,表示vi没被分割。此时vi为叶子结点。
给定两个近邻空间数据集D与D′,Pr1(v)与Pr2(v)分别表示SVT作用于D与D′输出v的概率。设x<i表示向量v中前i-1个响应记录。由条件概率定理可知:
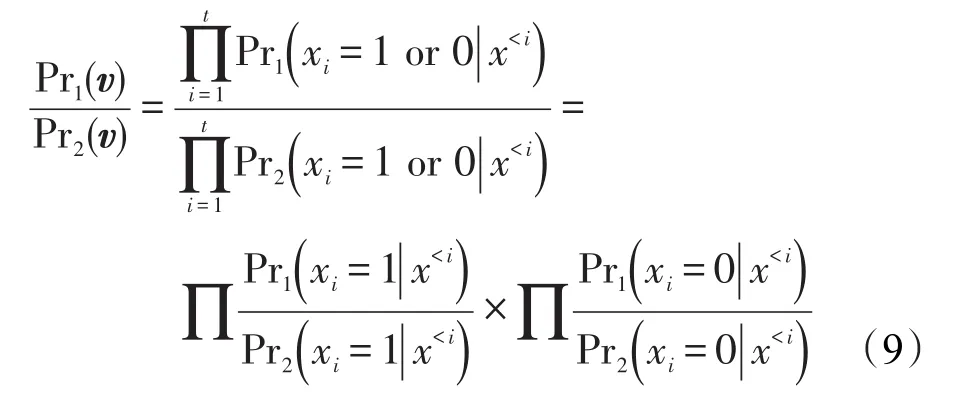
由式(9)可知,当x<i固定后,使得xi=1,使得xi=0。因此,与的分布仅仅是拉普拉斯分布。
假设x是D上某个分割阈值,设Hi(x)表示D上xi=1的概率,H′i(x)表示D′上xi=1的概率。因此,Hi(x)可以描述如下表达式:
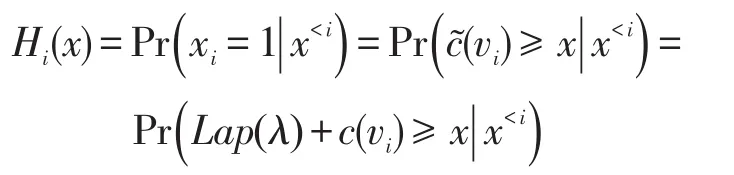
其中,Lap(λ)表示拉普拉斯分布产生的独立噪音。
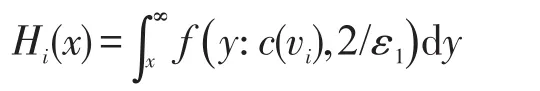
根据全局敏感性定义可知,计数c(v)的敏感性为1,即∆=1。设c(vi)与c′(vi)分别表示D与D′上结点vi的计数,c′(vi)=c(vi)+1,进而得μ=y+1。重写Hi(x),则Hi(x)可以表达成如下公式:
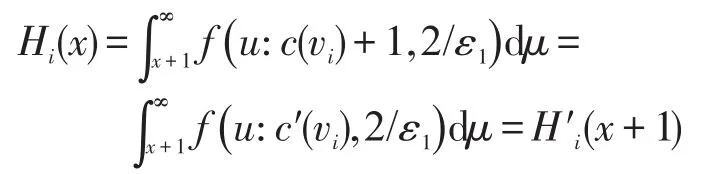
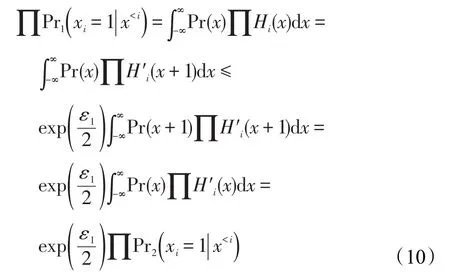
同理,可以获得如下不等式:
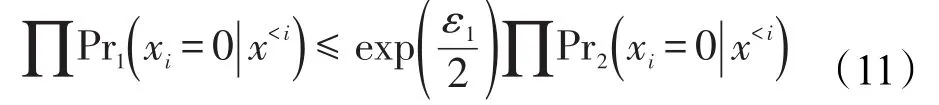
把式(10)与式(11)带入式(9)可知:
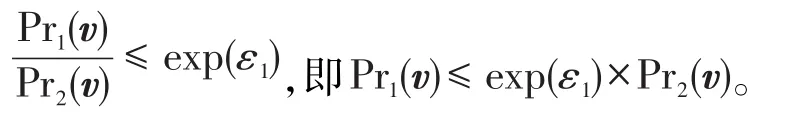
由定义1可知,SVT技术满足ε1-差分隐私。
由于εγ=ε1+ε2,并且εγ=ln(eε-1+γ)-lnγ,进而可以推理出。因此,KDTSS算法满足ε-差分隐私。
5 实验结果与分析
实验平台是4核Intel i7-4790 CPU(4 GHz),8 GB内存,Win7系统。所有算法均采用Python实现。实验采用两个数据集NYC(http://publish.illinois.edu/dbwork/open-data)与 Beijing(http://research.microsoft.com/apps/pubs/?id=152883),其中NYC数据集是整个2011年12个月内纽约市出租车的乘车和下车地理坐标数据,该数据集包含1 000万条信息;Beijing数据集是2011年北京市二月份某一周内10 357辆出租车的乘车和下车地理坐标数据,该数据集包含1 500万条信息。两种数据集具体细节与可视化结果分别如表1与图3、图4所示。

Table 1 Characteristics of datasets表1 数据集的属性
Fig.3 Visualization of NYC dataset图3 NYC数据集可视化结果

Fig.4 Visualization of Beijing dataset图4 Beijing数据集可视化结果
结合上述两种数据集,采用相对误差(relative error,RE)度量 SKD-Tree、KD-TSS、KD-Stand 以及KD-Hybrid算法的可用性。相对误差如式(12)所示:

其中,Q(D)表示D上真实的范围查询结果;表示D上范围查询的噪音结果;Δ为平滑因子,其值为实验数据集大小的0.1%。
本文设置伯努利随机抽样概率为1%,隐私预算参数ε的取值为0.1、0.5、1.0。实验中范围查询Q的查询范围分别覆盖NYC与Beijing两种数据集的[1%,1%]、[5%,5%]、[10%,10%],在每种查询范围内随机生成5 000次查询。
(1)基于NYC数据集的KD-TSS、SKD-Tree、KDStand以及KD-Hybrid算法RE值比较
通过改变隐私预算参数ε值来对比KD-TSS、SKD-Tree、KD-Stand以及KD-Hybrid算法响应固定范围查询的相对误差,进而对比4种算法的可用性。
图5表示NYC数据集范围查询结果。由图5(a)~(c)可以发现,当查询范围固定到[1%,1%]、[5%,5%]、[10%,10%]时,ε从0.1变化到1.0,KD-TSS算法所取得的查询精度是SKD-Tree算法的将近3倍,是KDStand与KD-Hybrid算法的将近10倍。特别是查询范围为[1%,1%]时,将近13倍。图5(d)~(f)显示,当查询范围从[1%,1%]变化到[10%,10%],ε分别固定为0.1、0.5、1.0时,KD-TSS算法取得的范围查询精度是SKD-Tree算法的将近2倍,是KD-Stand与KD-Hybrid算法的将近12倍。此外,从图5(a)~(f)可以看出,SKD-Tree算法同样优于KD-Stand与KD-Hybrid算法。其主要原因是NYC数据偏斜比较严重,而KD-TSS与SKD-Tree算法通过抽样技术能较好地避免偏斜问题。同时KD-TSS采用SVT技术避免了对隐私代价的多层次分割。
(2)基于 Beijing数据集的 KD-TSS、SKD-Tree、KD-Stand以及KD-Hybrid算法RE值比较
由图6(a)~(c)可以看出,变化ε时,KD-TSS算法所取得的查询精度稍微好于SKD-Tree算法,是KDStand与KD-Hybrid算法的3倍多。图6(e)~(f)显示,查询范围从[5%,5%]变化到[10%,10%],ε固定时,KD-TSS算法取得的范围查询精度是SKD-Tree算法的将近2倍。查询范围从[1%,1%]变化到[10%,10%]时,KD-TSS算法取得的查询精度是KD-Stand与KDHybrid算法的将近4倍。其原因是Beijing数据的偏斜度不是很大(参考图4),由于KD-TSS算法同时采用了抽样与SVT技术,其查询精度优于同类算法。
6 结束语
针对差分隐私保护下基于KD-树空间数据分割存在的问题,本文首先对现有方法进行分析,并在此基础上提出了基于伯努利随机抽样技术的算法SKDTree。由于SKD-Tree依赖KD-树高度添加拉普拉斯噪音,重新提出了另外一种基于抽样与稀疏向量技术的算法KD-TSS。从理论角度进行分析的结果显示,SKD-Tree与KD-TSS算法分别满足差分隐私。最后,在真实数据集上的实验结果表明SKD-Tree与KD-TSS算法能够输出比较精确的范围查询结果。未来工作考虑高维度空间数据的分割问题。
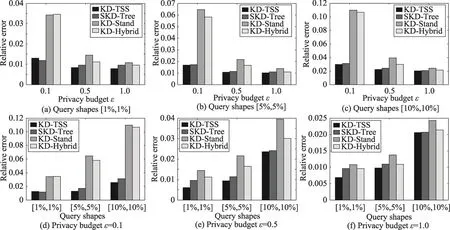
Fig.6 Results of range queries on Beijing dataset图6 Beijing数据集范围查询结果
[1]Sweeney L.K-anonymity:a model for protecting privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):557-570.
[2]Dwork C,McSherry F,Nissim K,et al.Calibrating noise to sensitivity in private data analysis[C]//LNCS 3876:Proceedings of the 3rd Theory of Cryptography Conference,New York,Mar 4-7,2006.Berlin,Heidelberg:Springer,2006:265-284.
[3]Dwork C.Differential privacy[C]//LNCS 4052:Proceedings of the 33rd International Colloquium on Automata,Languages and Programming,Venice,Italy,Jul 10-14,2006.Berlin,Heidelberg:Springer,2006:1-12.
[4]Dwork C,Lei J.Differential privacy and robust statistics[C]//Proceedings of the 41st Annual ACM Symposium on Theory of Computing,Bethesda,USA,May 31-Jun 2,2009.New York:ACM,2009:371-380.
[5]de Montjoye Y A,Hidalgo C A,Verleysen M,et al.Unique in the crowd:the privacy bounds of human mobility[J].Scientific Reports,2013,3(6):1376.
[6]Xiao Yonghui,Xiong Li,Yuan Chun.Differentially private data release through multidimensional partitioning[C]//LNCS 6358:Proceedings of the 7th VLDB Workshop on Secure Data Management,Singapore,Sep 17,2010.Berlin,Heidelberg:Springer,2010:150-168.
[7]Cormode G,Procopiuc C,Srivastava D,et al.Differentially private spatial decompositions[C]//Proceedings of the 28th International Conference on Data Engineering,Washington,Apr 1-5,2012.Washington:IEEE Computer Society,2012:20-31.
[8]McSherry F,Talwar K.Mechanism design via differential privacy[C]//Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science,Providence,USA,Oct 21-23,2007.Washington:IEEE Computer Society,2007:94-103.
[9]Xu Jia,Zhang Zhenjie,Xiao Xiaokui,et al.Differential private histogram publication[J].International Journal of Very Large Database,2013,22(6):797-822.
[10]Zhang Jun,Cormode G,Procopiuc C M,et al.PrivBayes:private data release via Bayesian networks[C]//Proceedings of the 2014 International Conference on Management of Data,Snowbird,USA,Jun 22-27,2014.New York:ACM,2014:1423-1434.
[11]Su Sen,Tang Peng,Cheng Xiang,et al.Differentially private multi-party high-dimensional data publishing[C]//Proceedings of the 32nd International Conference on Data Engineering,Helsinki,Finland,May 16-20,2016.Washington:IEEE Computer Society,2016:205-216.
[12]Zhang Jun,Xiao Xiaokui,Xie Xing.PrivTree:a differentially private algorithm for hierarchical decompositions[C]//Proceedings of the 2016 ACM SIGMOD International Conference on Management of Data,San Francisco,USA,Jun 26-Jul 1,2016.New York:ACM,2016:155-170.
[13]Qardaji W H,Yang Weining,Li Ninghui.Differentially private grids for geospatial data[C]//Proceedings of the 29th International Conference on Data Engineering,Brisbane,Australia,Apr 8-12,2013.Washington:IEEE Computer Society,2013:757-768.
[14]Chen Rui,Shen Yilin,Jin Hongxia.Private analysis of infinite data streams via retroactive grouping[C]//Proceedings of the 24th International Conference on Information and Knowledge Management,Melbourne,Australia,Oct 19-23,2015.New York:ACM,2015:1061-1070.
[15]Li Ninghui,Qardaji W H,Su Dong.On sampling,anonymization,and differential privacy or,k-anonymization meets differential privacy[C]//Proceedings of the 7th ACM Symposium on Information,Computer and Communications Security,Seoul,May 2-4,2012.New York:ACM,2012:32-33.
[16]McSherry F.Privacy integrated queries:an extensible platform for privacy-preserving data analysis[C]//Proceedings of the 2009 International Conference on Management of Data,Providence,USA,Jun 29-Jul 2,2009.New York:ACM,2009:19-30.
[17]Hardt M A W.A study of privacy and fairness in sensitive data analysis[D].Princeton:Princeton University,2011.
[18]Lee J,Clifton C W.Top-kfrequent itemsets via differentially private FP-trees[C]//Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,Aug 24-27,2014.New York:ACM,2014:931-940.
[19]Chen Rui,Xiao Qiao,Zhang Yu,et al.Differentially private high-dimensional data publication via sampling-based inference[C]//Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Sydney,Australia,Aug 10-13,2015.New York:ACM,2015:129-138.
KD-TSS:Accurate Method for Private Spatial Decomposition*
JIN Kaizhong1,ZHANG Xiaojian1+,PENG Huili1,2
1.College of Computer and Information Engineering,Henan University of Economics and Law,Zhengzhou 450046,China
2.Henan Radio&Television University,Zhengzhou 450008,China



A
TP392
+Corresponding author:E-mail:xjzhagn82@ruc.edu.cn
JIN Kaizhong,ZHANG Xiaojian,PENG Huili.KD-TSS:accurate method for private spatial decomposition.Journal of Frontiers of Computer Science and Technology,2017,11(10):1579-1590.
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2017/11(10)-1579-12
10.3778/j.issn.1673-9418.1608040
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
*The National Natural Science Foundation of China under Grant No.61502146(国家自然科学基金);the Key Technologies Research and Development Program of Henan Province under Grant No.162102310411(河南省科技攻关项目);the Research Program of Higher Education of Henan Educational Committee under Grant No.16A520002(河南省教育厅高等学校重点科研项目);the Youth Backbone Teacher Program of Higher Education of Henan Province under Grant No.2013GGJS-098(河南省高等学校青年骨干教师项目);the Young Talents Fund of Henan University of Economics and Law(河南财经政法大学青年拔尖人才资助计划);the Technology Bureau Project of Zhengzhou under Grant No.153PKJGG115(郑州市科技局普通科技攻关项目).
Received 2016-08,Accepted 2016-11.
CNKI网络优先出版:2016-11-29,http://www.cnki.net/kcms/detail/11.5602.TP.20161129.1454.002.html
JIN Kaizhong was born in 1991.He is an M.S.candidate at College of Computer and Information Engineering,Henan University of Economics and Law,and the student member of CCF.His research interests include differential privacy and database,etc.
金凯忠(1991—),男,河南开封人,河南财经政法大学计算机与信息工程学院硕士研究生,CCF学生会员,主要研究领域为差分隐私,数据库等。
ZHANG Xiaojian was born in 1980.He received the Ph.D.degree from School of Information,Renmin University of China in 2014.Now he is an associate professor at Henan University of Economics and Law,and the member of CCF.His research interests include differential privacy and database,etc.
张啸剑(1980—),男,河南周口人,2014年于中国人民大学信息学院获得博士学位,现为河南财经政法大学计算机与信息工程学院副教授,CCF会员,主要研究领域为差分隐私,数据库等。
PENG Huili was born in 1981.She received the M.S.degree from School of Information,Yanshan University in 2007.Now she is a lecturer at Henan Radio&Television University.Her research interests include database and privacy protection,etc.
彭慧丽(1981—),女,河南周口人,2007年于燕山大学信息学院获得硕士学位,现为河南广播电视大学讲师,主要研究领域为数据库,隐私保护等。
