融合评分倾向度和双重预测的协同过滤推荐算法*
2017-10-12孙萍,李锵,关欣,吕杰
孙 萍,李 锵,关 欣,吕 杰
天津大学 电子信息工程学院,天津 300072
融合评分倾向度和双重预测的协同过滤推荐算法*
孙 萍,李 锵+,关 欣,吕 杰
天津大学 电子信息工程学院,天津 300072
Abstract:Collaborative filtering recommendation system suffers from series data sparsity problem.To solve the problem,this paper proposes a collaborative filtering recommendation method by combining rating preference and dual prediction.In the stage of calculating the nearest neighbors,to improve the calculation method of similarity,rating preference is introduced firstly.Then,in the stage of generating recommendation,a dual prediction method is proposed which is based on the user and the item nearest neighbors to predict the user preference more accurately.The experimental results on the MovieLens-1M data set indicate that the proposed method can relieve the influence of rating data sparsity on recommended results,significantly reduce the mean absolute error and effectively improve the recommendation precision.
Key words:recommendation system;collaborative filtering;user preference;rating prediction
协同过滤推荐算法面临着严重的数据稀疏性问题,提出一种融合评分倾向度和双重预测的协同过滤推荐算法以解决该问题。在选择最近邻阶段,引入评分倾向度来改进相似性度量方法,更加准确地得到最近邻居集;在推荐生成阶段,利用基于用户最近邻和基于项目最近邻的双重预测方法来进行评分预测,提高预测的准确度。通过在MovieLens-1M数据集上的实验结果表明:该算法能够缓解数据稀疏性对推荐结果的影响,有效降低平均绝对误差,提高推荐准确率。
推荐系统;协同过滤;用户偏好;评分预测
1 引言
伴随大数据时代的到来,信息过载问题日益严重,在面对众多可选项时,用户会感到困惑。在此背景下,推荐系统应运而生,它们可以有效地为在线用户处理信息过载问题,已成为电子商务的得力助手。
目前,推荐系统大致可以分为基于内容的推荐系统、协同过滤(collaborative filtering,CF)推荐系统和混合推荐系统3个主要类别[1]。基于内容的推荐算法,假设用户在过去和将来有相似的偏好,或者用户的偏好与个性相关。协同过滤推荐算法是目前发展最成熟和应用最广泛的推荐技术,主要包括基于内存的协同过滤和基于模型的协同过滤。其中基于内存的协同过滤又分为基于用户的协同过滤(user-based CF)和基于项目的协同过滤(item-based CF)[2]。推荐算法的模型包括聚类模型和贝叶斯网络模型。协同过滤算法假设过去具有相似偏好的用户未来也会有相似的偏好,通过挖掘用户过去的行为记录寻找相似的用户或项目,然后利用相似的用户或项目来预测当前用户的偏好,从而为用户推荐感兴趣的项目,亚马逊商城的推荐算法就是依此产生的[3]。基于内存的协同过滤无需分析信息资源的内容,可以发现用户潜在的兴趣,而且可解释性强,易实现,因此得到广泛的研究和应用,其也是本文的主要研究对象。混合推荐系统,即结合不同的协同过滤方法从而产生新的推荐算法。Liu等人[4]利用网络服务相似性计算模型,集成基于用户与基于项目的推荐算法,开发出混合协同过滤推荐技术。
随着互联网科技的发展,推荐系统在电子商务、电影和视频网站、社交网络、互联网广告、个性化阅读、信息检索、移动应用、旅游、交通等众多领域[5-7]得到广泛应用。
尽管协同过滤推荐取得了很大成功,但面临着严重的数据稀疏性问题[2]。在实际应用中,用户和项目规模不断增加,数量巨大,但用户通常只会对少量项目进行关注或评分,造成用户-项目评分矩阵的维度不断增加,数据稀疏性问题愈发严重;常常出现由于用户间的共同评分项目过少,无法准确计算二者的相似性;在评分预测中,由于最近邻用户评分的缺失,难以准确预测评分。
本文针对上述问题,提出了一种融合评分倾向度和双重预测的协同过滤推荐算法。算法主要分为三步:首先计算融合了评分倾向度的用户相似性和项目相似性;然后确定最近邻用户集和最近邻项目集;最后动态选择基于最近邻用户集和最近邻项目集的双重预测方法进行评分预测。相比传统的userbased CF,本文算法具有以下优点:(1)引入评分倾向度,综合考虑了用户评分、用户间共同评分项目和评分差异对用户相似性的影响,能更真实地反映用户间的相似性。(2)综合考虑了用户最近邻和项目最近邻在评分预测中的作用,使评分预测更精确。在公开数据集MovieLens上的实验表明:本文算法有效改善了数据稀疏性问题,能够降低平均绝对误差,提高推荐准确率,并在一定程度上缓解了冷启动问题。
本文组织结构如下:第2章简要回顾传统协同过滤推荐算法并分析存在的问题;第3章提出了一种融合评分倾向度和双重预测的协同过滤推荐算法;第4章进行实验并分析实验结果;第5章总结全文。
2 基本理论
2.1 推荐模型
传统的基于用户的协同过滤算法主要分为3个阶段:用户偏好建模,选择最近邻居集,推荐生成。传统协同过滤算法中用户对项目评分表示用户的偏好,评分值一般为1~5之间的整数,评分值越大表示用户对项目越喜欢,评分值为空表示用户u未对项目i评分,评分值缺失,因此带来数据稀疏性问题。用户在项目空间上的偏好分布可以用一个m×n阶用户-项目的评分矩阵R表示,m表示用户的个数,n表示项目的个数,行向量R(u)为用户u的评分集合Iu,列向量R(i)为所有用户对项目i的评分集合Ui。
传统的协同过滤算法在评分矩阵R上计算用户(项目)间的相似性,然后选择相似性最大的用户(项目)作为最近邻用户(项目)集,常用的相似性度量方法有余弦相似性、Pearson相关性。设用户ua和ub之间的相似度为sim(ua,ub),则两种相似性的计算方法如式(1)、式(2)所示。
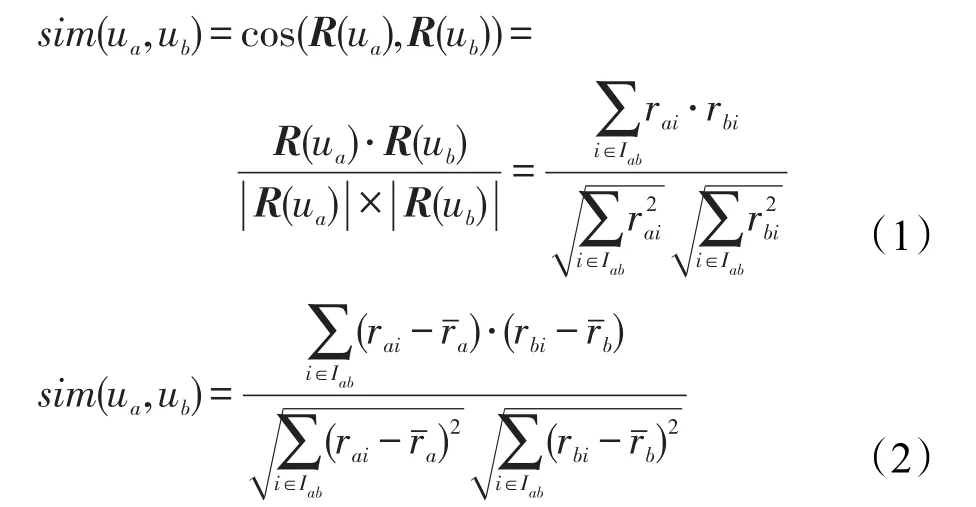
式中,Iab={i∈I|rai≠ ∅,rbi≠ ∅},表示用户a和用户b的共同评分项目集;rai和rbi分别表示用户ua和ub对项目i的评分值;和分别表示用户ua和ub的评分均值。如果求项目ia和ib之间的相似性,则公式修正如下:
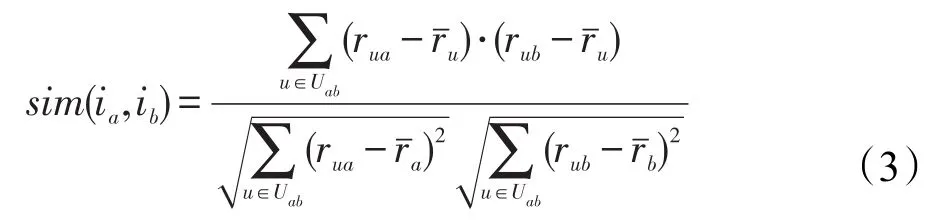
式中,Uab={u∈U|rua≠ ∅,rub≠ ∅},表示对项目a和项目b共同评分的用户集;表示用户的评分均值。
推荐生成过程的关键是评分预测,即通过利用最近邻居集来预测目标用户对当前项目的偏好,则评分预测计算方法表示如下:
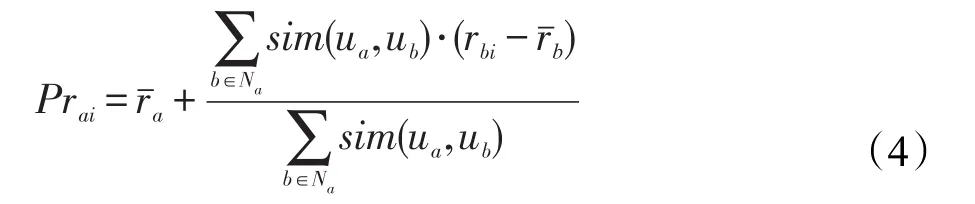
对于基于项目的协同过滤算法,公式修正如下:

2.2 传统协同过滤问题分析
传统协同过滤算法中,由于评分数据的稀疏性问题,在利用传统相似性度量方法计算相似性时,无法真实反映用户间的相似性。例如:假设用户a和用户b分别对200个项目进行评分,但只有一个共同评分项目,且评分相同,按Pearson相关系数计算,二者相似度为1,显然这是不准确的。而且在评分预测阶段,由于数据稀疏性问题,导致缺失最近邻用户对当前项目的评分数据,难以充分利用最近邻用户进行评分预测。
针对以上问题,国内外学者提出了许多改进算法,主要分为基于内存的方法和基于模型的方法。Sarwar等人将信息检索领域的奇异值分解技术(singular value decomposition,SVD)引入到推荐系统[8-9],将高维的评分矩阵R拆分成低维的近似矩阵,利用数据中的潜在关系观察用户或项目间的相似信息。该方法在一定条件下,可以过滤掉数据中存在的噪声,提高推荐准确度,但该方法容易导致有用信息丢失,在某些情况下推荐质量较差。Hofmann等人将概率潜在语义分析(probabilistic latent semantic analysis,pLSA)引入推荐系统[10-11],该算法利用隐含变量发现用户社区和评分数据里隐藏的兴趣,并按照兴趣对用户进行划分,能获得比较高的准确率。Breese等人提出了一种矩阵填充技术[12-13],将缺失的评分数据填充为一个缺省值,以此来缓解数据稀疏性问题,但由于缺省值的设置存在误差,导致评分预测不准确,降低推荐准确率。为了有效利用评分数据之外的其他信息,避免评分数据稀疏性对用户相似度计算的影响,有学者提出将上下文信息、用户信任网络等引入到推荐系统中。文献[14]将用户附加信息,如性别、年龄等引入到推荐系统中,在一定程度上缓解了数据稀疏性问题。文献[15-16]进而提出了一种上下文感知推荐算法,将上下文信息融入到推荐系统中,包括用户上下文信息,如性别、年龄、职业、心情等;环境上下文信息,如位置、天气等时间上下文信息,社会化网络等。但该方法面临着获取上下文信息困难,而且带来更加严重的数据稀疏性等问题。Quan[17]提出加入用户个性改善用户模型的推荐算法,该算法可以在一定程度上缓解数据稀疏问题,但是加重了系统的计算负担。Gupta等人[18]提出协同过滤与人口统计学相结合的推荐算法,该算法可以有效解决数据稀疏、冷启动等问题,且算法的扩展性强,但是算法实现过程较复杂,计算量大,在实际应用中可能会受到限制。本文针对上述方法中存在的问题,引入评分倾向度改善相似度的计算,并利用动态选择基于用户最近邻和基于项目最近邻的双重预测方法来进行评分预测,提出一种融合评分倾向度和双重预测的协同过滤推荐算法。
3 融合评分倾向度和双重预测的协同过滤推荐算法
本文算法的主要思想是利用用户的评分倾向度更加准确地计算用户的相似性,并在评分预测阶段采用动态选择基于项目和基于用户的双重评分预测。本文将此算法命名为PDCF(collaborative filtering recommendation method combining rating preference and dual prediction)算法,下面详细介绍PDCF算法的主要内容。
3.1 基于评分倾向度的相似度
本文2.2节已经指出,由于数据的稀疏性,用户间的共同评分项目过少,在利用传统相似性度量方法计算用户或项目间相似性时,常常出现无法真实反映用户间相似性的问题。例如表1,显示了当前用户Alice和其他用户的评分数据。
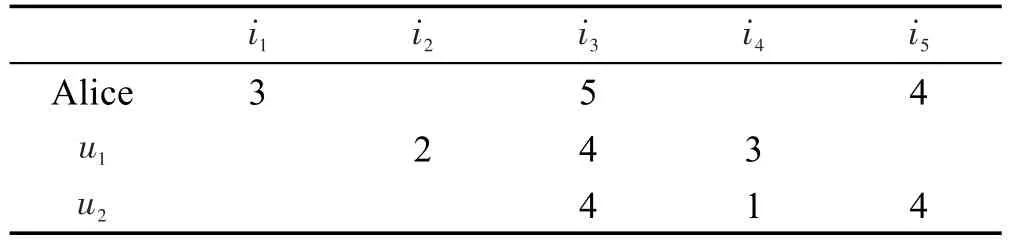
Table 1 User rating dataset表1 用户评分数据库
如果利用Pearson相关系数求当前用户Alice和用户u1和u2的相似性,则分别为sim(Alice,u1)=1,sim(Alice,u2)=0.707,即当前用户Alice和用户u2的相似性比和用户u1的相似性低。显然这是不正确的,因为当前用户Alice和用户u2有两个共同评分项,说明项目的关注倾向度更加趋于一致,而且共同评分差异小,综合起来说明二者评分倾向度更加一致,二者的相似度应该比和用户u1的相似度大。
首先,如果用户间共同评分项目占二者所有评分过的项目比例越大,则二者对项目的关注倾向度越一致,二者的相似性也应该更大,因此引入Jaccard系数来计算用户对项目的关注倾向度Pi,具体计算方法如下:

式中,Ia和Ib分别表示用户a和b的评分项目集合。将Pi(ua,ub)乘以二者的Pearson相关系数,即sim2(ua,ub)=Pi(ua,ub)×sim(ua,ub),来改进上述缺陷,可以计算得到sim2(Alice,u1)=0.2,sim2(Alice,u2)=0.354。虽然sim2(Alice,u2)比原来的小,但当前用户Alice和用户u2的相似性比和用户u1的相似性提高了77%,显然这更符合实际情况。考虑用户对项目的关注倾向度虽然在一定程度上缓和了数据稀疏性,但也存在不足。因为即使两个用户对项目的关注倾向度相似,但如果评分存在较大不同,说明二者的偏好也不一致,所以对Jaccard系数进行改进,使得用户对项目的关注倾向度一致,而且评分也趋于相似时,二者的相似性才更大。
定义1(评分倾向度)用P(ua,ub)和P(ia,ib)分别表示两个用户间和两个项目间的评分倾向度,则计算公式如下:
将用户的评分倾向度融入到用户或项目的相似度计算过程,则得到基于评分倾向度的相似性度量方法,具体计算公式如下:

式中,P(ua,ub)表示用户间的评分倾向度;sim3(ua,ub)和sim3(ia,ib)表示分别利用式(2)和式(3)求得的用户间和项目间的皮尔森相关系数。
最后,利用式(9)再次计算当前用户Alice和用户u1和u2的相似性,分别为sim(Alice,u1)=0.16,sim(Alice,u2)=0.318。即虽然sim(Alice,u2)也有所减小,但当前用户和用户u2的相似性比和用户u1的相似性高98%,用此方法计算得到的最近邻用户更准确。
3.2 选择最近邻居集
3.1节详细介绍了基于用户间评分倾向度的相似性度量方法,在本文PDCF算法中,首先利用式(9)和式(10)计算用户相似度和项目相似度,然后选择相似度最大的作为最近邻居集。
3.3 评分预测
传统协同过滤推荐系统利用式(4)和式(5)进行评分预测,但由于数据的稀疏性,导致缺失最近邻用户对当前项目的评分,难以进行评分预测。为了充分利用最近邻用户集并提高评分预测的准确度,本文借鉴矩阵填充技术的思想,用预测值填充缺失的数据。同时为了缓解新填充数据带来新的误差,本文提出双重预测方法来进行评分预测。首先动态监测最近邻用户对当前项目的评分,当最近邻用户对当前项目的评分缺失时,利用基于项目的协同过滤方法确定当前项目的最近邻项目集,并预测最近邻用户对当前项目的评分,然后将此预测评分设置为最近邻用户对当前项目的评分。最后再利用基于用户的预测方法进行评分预测。
假设目标用户为ua,当前项目为i,目标用户的最近邻用户集为Na,用户b为最近邻用户集中的任一用户,则用户b对当前项目的评分rbi为:

式中,Na表示用户a的最近邻用户集;sim(ua,ub)为利用式(9)求得的用户间的相似度。
3.4 PDCF推荐算法描述
输入:用户-项目评分矩阵Rm×n。
输出:目标用户的top-N推荐列表。
步骤1计算基于评分倾向度的用户相似度。先利用式(7)确定用户间的评分倾向度矩阵Pu,然后利用式(9)确定基于评分倾向度的用户相似度矩阵Sp。
步骤2生成目标用户的K个最近邻用户。利用用户的相似度矩阵Sp,按照top-N最近邻选择策略为目标用户选择最近邻居集N。
步骤3扫描所有最近邻用户对当前项目的评分,如果评分为空值,则利用式(10)计算项目相似度,确定当前项目的最近项目集,然后将利用式(11)求得的预测值填充为最近邻用户对当前项目的评分。
步骤4计算目标用户对所有未评分项目的偏好。利用式(12)预测目标用户对当前项目的评分。
步骤5生成目标用户的推荐项目集Ir,根据目标用户对未评分项目的偏好,选择预测评分值前n个最大的项目作为top-N推荐列表推荐给目标用户。
4 实验及结果分析
4.1 数据集及实验环境
本文使用美国明尼苏达大学的Grouplens研究组提供的MovieLens-1M数据集。该数据集包含了6 040个用户对3 952部电影的1 000 209条评分记录,评分值为1~5的整数,1表示最不喜欢,5表示最喜欢;每个用户至少对20部电影进行评分,数据的稀疏度为95.81%。
为了验证推荐算法的推荐质量,本文采用5折交叉验证的方法,将数据集按照80%和20%的比例随机分为训练数据集和测试数据集。
本文实验环境为:Windows7 32位操作系统,2 GB内存,Intel®CoreTM2 Duo CPU E7500@2.93 GHz,实验程序基于python2.7开发。
4.2 评价指标
为了验证推荐算法的推荐质量,实验使用平均绝对误差(mean absolute error,MAE)和推荐准确率Pu作为评价指标。
MAE通过计算所有测试用户对测试项目的预测评分和实际评分的平均误差大小来衡量推荐系统的质量。MAE越小,推荐系统质量越好,MAE越大,推荐系统质量越差。计算方法如下:
式中,Tu表示测试用户集;Ti表示测试项目集,|表示测试项目的个数;prui表示用户对项目i的预测评分;rui表示用户对项目i的真实评分。
Pu是评价top-N推荐质量的重要指标,通过计算top-N推荐列表中的项目在用户top-N评分项目列表中的个数占所有推荐项目的比例来衡量推荐系统的质量。具体计算方法如下:

式中,Tu表示测试用户集;Ir表示用户的top-N推荐列表;表示用户的top-N评分列表。
4.3 实验结果及分析
本文共设计了4组实验,分别从基于用户上下文信息的相似度、基于用户评分倾向度的相似度、动态选择基于用户和基于项目的评分预测以及CPCF算法的有效性四方面来验证本文CPCF算法的性能。为了便于描述实验结果,本文采用表2中的缩写来表示对应的算法,采用k表示最近邻用户的个数。

Table 2 Method proposed in this paper and methods for comparison表2 本文算法和拟比较算法
4.3.1 评分倾向度的有效性
该实验主要验证基于用户评分倾向度的相似度计算方法对推荐质量的影响。实验结果如图1和图2所示。表3、表4分别表示基于评分倾向度的相似度计算方法与余弦相似性方法、Pearson方法相比,MAE降低比例和Pu提高比例。
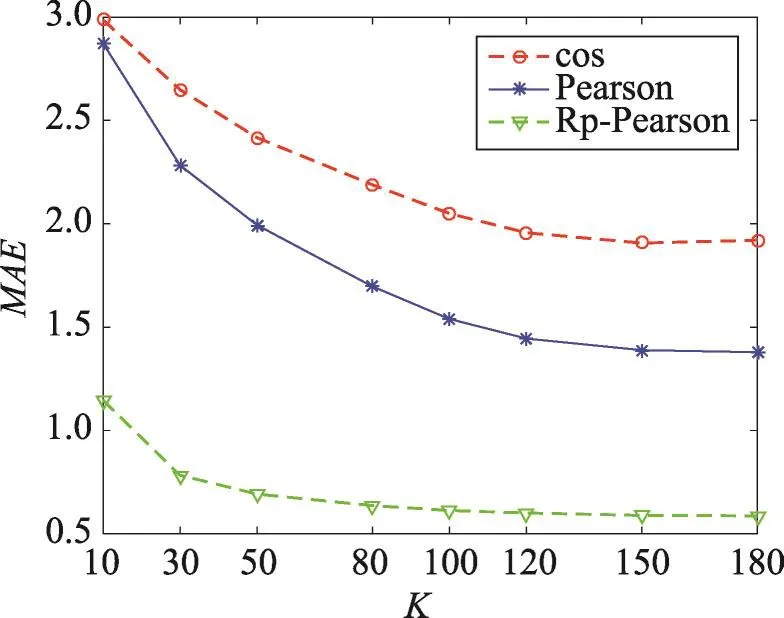
Fig.1MAEcomparison of collaborative filtering methods with cos,Pearson and Rp-Pearson图1 分别采用cos、Pearson和Rp-Pearson相似度的推荐算法MAE对比图
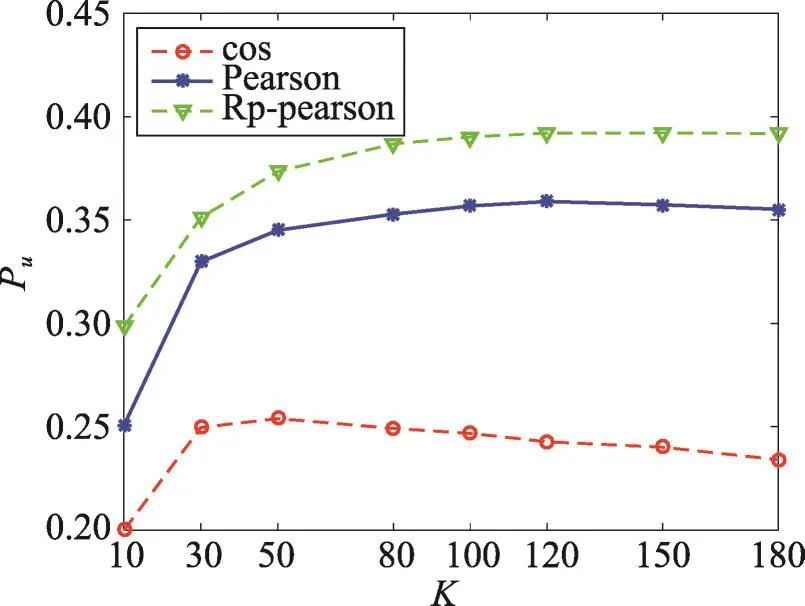
Fig.2Pucomparison of collaborative filtering methods with cos,Pearson and Rp-Pearson图2 分别采用cos、Pearson和Rp-Pearson相似度的推荐算法Pu对比图
如图1所示,在不同数量的最近邻用户的条件下,基于用户评分倾向度的相似性计算方法(Rp-Pearson)与余弦相似性方法和Pearson方法相比,MAE最小,且改善效果非常明显。当最近邻用户从10增加到30时,MAE急剧降低;当最近邻个数从30逐渐增加到150时,MAE逐渐降低,并趋于平缓。通过表3可以更加清晰地看出,与余弦相似性方法和Pearson方法相比,采用基于用户评分倾向度的方法MAE均明显降低,分别平均降低69.08%和60.85%。
如图2所示,确定top-N的个数为10的情况下,取不同数量的最近邻用户时,基于用户评分倾向度的推荐准确率最高,当最近邻个数从10增加到80时,推荐准确率逐渐升高,此后再增加最近邻个数,推荐准确率达到最大值。通过表4可以更加清晰地看出,与余弦相似性方法和Pearson方法相比,采用基于用户评分倾向度的方法Pu均明显提高,与余弦相似性方法和Pearson方法相比,推荐准确率平均分别提高42.56%和8.29%。由以上分析可知,基于用户评分倾向度的相似性算法与余弦方法和Pearson方法相比,可以有效缓解数据的稀疏性,降低平均绝对误差,提高推荐准确率。

Table 3MAEreduction percentage compared with different similarity methods表3 不同相似度计算方法的MAE降低比例

Table 4Puraise percentage compared with different similarity methods表4 不同相似度计算方法的Pu提高比例
4.3.2 双重预测的有效性
本实验主要验证在评分预测阶段双重预测的有效性,实验结果如图3~图5所示。其中图3为不同相似度计算方法在仅基于用户的评分预测和融合了双重预测的协同过滤推荐算法的MAE的对比图。由于图3中一部分曲线重合,故图4将动态选择基于用户和基于项目的评分预测方法的MAE对比图单独画出。表5、表6分别表示对于不同推荐算法,融合了双重预测的方法后,MAE降低比例和Pu提高比例。
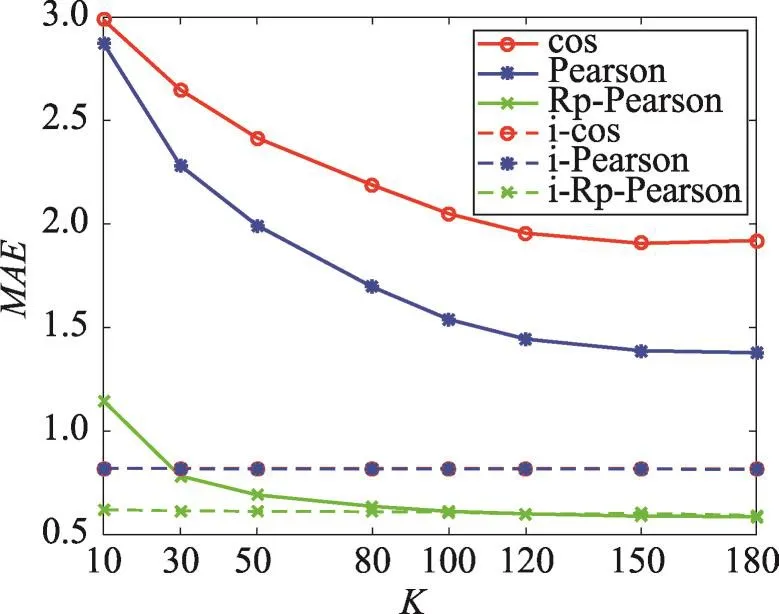
Fig.3MAEcomparison of collaborative filtering methods with different similarity图3 不同相似度的协同过滤算法的MAE对比图
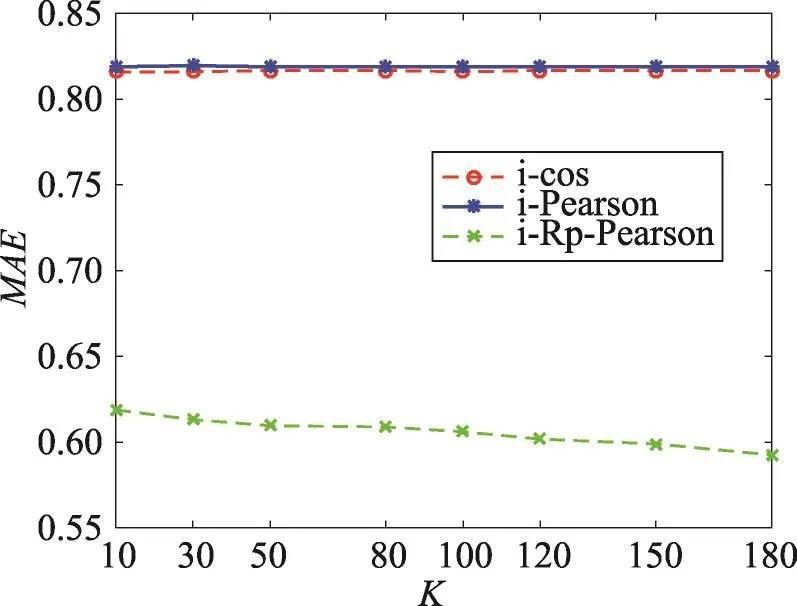
Fig.4MAEcomparison of different similarity methods after combining dynamic prediction图4 不同算法融合动态预测后的MAE对比图
由图3、图4和表5可以看出,对于余弦方法、Pearson方法,在不同数量的最近邻用户的条件下,融合了双重预测的协同过滤推荐算法MAE均最小,平均分别降低62.94%、52.09%,改善效果明显。对于基于用户评分倾向度的推荐方法,当最近邻个数K<60时,融合了双重预测的协同过滤推荐算法MAE较低,当K≥60时,MAE逐渐趋于一致,二者基本持平,平均降低了10.05%。由图5、表6可以看到,在top-10推荐中,对于余弦方法、Pearson方法和基于用户评分倾向度的协同过滤方法,在不同数量的最近邻用户的条件下,融合了双重预测的协同过滤方法的推荐准确率均最高,平均分别提高了13.07%、4.25%、3.02%。综合以上分析可以得知,动态选择基于用户和基于项目的方法,可以缓解数据的稀疏性,降低预测误差,提高预测准确率。

Fig.5Pucomparison of collaborative filtering methods with different similarity图5 不同相似度的协同过滤算法的Pu对比图

Table 5MAEreduction percentage of different similarity methods after combining dynamic prediction表5 融合双重预测后不同相似度计算方法的MAE降低比例

Table 6Puraise percentage of different similarity methods after combining dynamic prediction表6 融合双重预测后不同相似度计算方法的Pu提高比例
4.3.3 PDCF算法的有效性
通过上述两组实验,可以确定本文提出的基于评分倾向度的算法和双重预测方法均可以减低预测误差,提高推荐准确率。本实验主要验证融合了上述两种方法的PDCF算法效果,实验结果如图6和图7所示。表7、表8分别表示PDCF算法与余弦相似性方法、Pearson方法相比,MAE降低比例和Pu提高比例。
由图6可以看出,PDCF算法与余弦相似性方法、Pearson方法相比,在不同数量最近邻用户的条件下,MAE均最小。由表7可以更加直观地看出,PDCF算法和余弦方法、Pearson方法相比,MAE均显著降低,整体分别平均降低了72.53%、64.61%。由图7可以看出,在top-10推荐中,DPCF算法和余弦相似性方法、Pearson方法的协同过滤推荐算法相比,在不同最近邻用户个数的情况下,推荐准确率均最高,推荐更加准确。通过表8可以看出,PDCF算法和余弦方法相比,Pu得到了很大提高,平均提高幅度为46.93%;PDCF算法和Pearson方法相比,Pu也得到不同程度的提高,平均改善率为11.57%。综合以上分析,CPCF算法可以有效缓解数据的稀疏性,降低预测误差,提高推荐准确率。
5 结论
协同过滤推荐技术是应用最广泛和最成功的推荐技术,但面临数据稀疏性和冷启动等问题的严峻挑战,导致推荐质量较差,不能满足企业和用户的需求。
本文针对传统协同过滤算法的不足,提出基于用户评分倾向度的相似性计算方法,与余弦、Pearson等相似度计算方法相比,能更加真实地计算用户间的相似性。为了进一步缓解数据稀疏性的影响,在评分预测阶段提出动态选择基于用户和基于项目的双重预测方法,进而提出一种融合用户上下文信息和双重预测的协同过滤算法(PDCF)。实验结果表明,PDCF算法可以有效缓解数据稀疏性,提高预测准确度和推荐准确度,改善推荐质量。
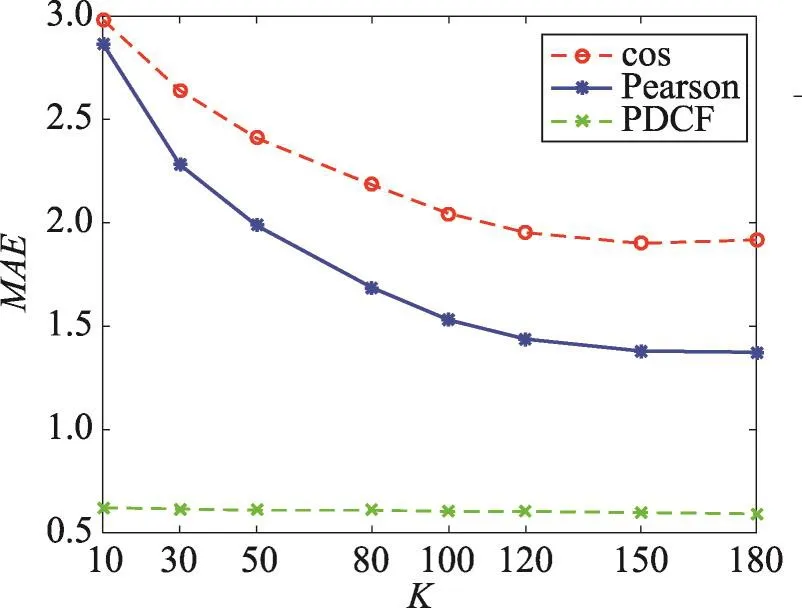
Fig.6MAEcomparison of collaborative filtering methods with cos,Pearson and PDCF图6 分别采用cos、Pearson and PDCF相似度的推荐算法MAE对比图
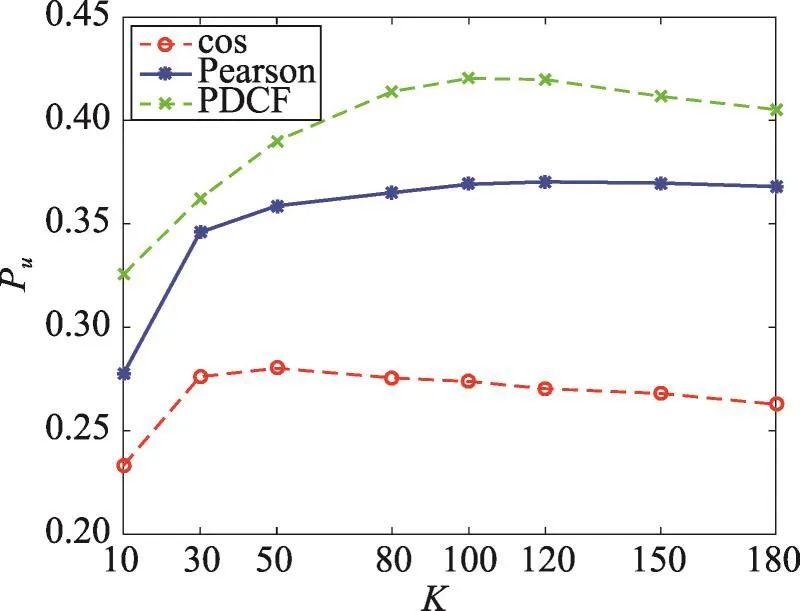
Fig.7Pucomparison of collaborative filtering methods with cos,Pearson and PDCF图7 分别采用cos、Pearson和PDCF相似度的推荐算法Pu对比图

Table 7MAEreduction percentage compared with different similarity methods表7 不同相似度计算方法的MAE降低比例

Table 8Puraise percentage compared with different similarity methods表8 不同相似度计算方法的Pu提高比例
[1]Revankar O S,Haribhakta Y V.Survey on collaborative filtering technique in recommendation system[J].International Journal ofApplication or Innovation in Engineering&Management,2015,3(4):85-91.
[2]Burke R,Felfernig A,Göker M H.Recommender systems:an overview[J].AI Magazine,2011,32(3):13-18.
[3]Linden G,Smith B,York J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[4]Jiang Yechun,Liu Jianxun,Tang Mingdong,et al.An effective Web service recommendation method based on personalized collaborative filtering[C]//Proceedings of the 2011 IEEE International Conference on Web Services,Washington,Jul 4-9,2011.Washington:IEEE Computer Society,2011:211-218.
[5]West J D,Wesley-Smith I,Bergstrom C T.A recommendation system based on hierarchical clustering of an articlelevel citation network[J].IEEE Transactions on Big Data,2016,2(2):113-123.
[6]He Yaobin,Zhang Fan,Li Ye,et al.Multiple routes recommendation system on massive taxi trajectories[J].Tsinghua Science and Technology,2016,21(5):510-520.
[7]Jiang Shuhui,Qian Xueming,Mei Tao,et al.Personalized travel sequence recommendation on multi-source big socialmedia[J].IEEE Transactions on Big Data,2016,2(1):43-56.
[8]Sarwar B,Karypis G,Konstan J,et al.Application of dimensionality reduction in recommender system—a case study[R].Minneapolis,USA:University of Minnesota,2000.
[9]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[10]Hofmann T,Puzicha J.Latent class models for collaborative filtering[C]//Proceedings of the 16th International Joint Conference on Artificial Intelligence,Stockholm,Sweden,Jul 31-Aug 6,1999.San Francisco,USA:Morgan Kaufmann Publishers Inc,1999:688-693.
[11]Hofmann T.Latent semantic models for collaborative filtering[J].ACM Transactions on Information Systems,2004,22(1):89-115.
[12]Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,Madison,USA,Jul 24-26,1998.San Francisco,USA:Morgan Kaufmann Publishers Inc,1998:43-52.
[13]Degemmis M,Lops P,Semeraro G.A content-collaborative recommender that exploits WordNet-based user profiles for neighborhood formation[J].User Modeling and User-Adapted Interaction,2007,17(3):217-255.
[14]Pazzani M J.A framework for collaborative,content-based and demographic filtering[J].Artificial Intelligence Review,1999,13(5/6):393-408.
[15]Adomavicius G,Sankaranarayanan R,Sen S,et al.Incorporating contextual information in recommender systems using a multidimensional approach[J].ACM Transactions on Information Systems,2005,23(1):103-145.
[16]Adomavicius G,Tuzhilin A.Context-aware recommender systems[M]//Recommender Systems Handbook.Secaucus,USA:Springer-Verlag New York,Inc,2011:217-253.
[17]Quan Zhichao.Collaborative filtering recommendation based on user personality[C]//Proceedings of the 6th International Conference on Information Management,Innovation Management and Industrial Engineering,Xi'an,China,Nov 23-24,2013.Piscataway,USA:IEEE,2013:307-310.
[18]Gupta J,Gadge J.A framework for a recommendation system based on collaborative filtering and demographics[C]//Proceedings of the 2014 International Conference on Circuits,Systems,Communication and Information Technology Applications,Mumbai,India,Apr 4-5,2014.Piscataway,USA:IEEE,2014:300-304.
Collaborative Filtering Recommendation Method Combining Rating Preference and Dual Prediction*
SUN Ping,LI Qiang+,GUAN Xin,LV Jie
School of Electronic Information Engineering,Tianjin University,Tianjin 300072,China




A
TN911.7
+Corresponding author:E-mail:liqiang@tju.edu.cn
SUN Ping,LI Qiang,GUAN Xin,et al.Collaborative filtering recommendation method combining rating preference and dual prediction.Journal of Frontiers of Computer Science and Technology,2017,11(10):1642-1651.
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2017/11(10)-1642-10
10.3778/j.issn.1673-9418.1608002
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
*The National Natural Science Foundation of China under Grant No.61401307(国家自然科学基金);the Postdoctoral Science Foundation of China under Grant No.2014M561184(中国博士后科学基金);the Application Infrastructure and Cutting-Edge Technology Research Projects of Tianjin under Grant No.15JCYBJC17100(天津市应用基础与尖端技术研究项目).
Received 2016-08,Accepted 2016-12.
CNKI网络优先出版:2016-12-21,http://www.cnki.net/kcms/detail/11.5602.TP.20161221.1128.002.html
SUN Ping was born in 1990.She is an M.S.candidate at Tianjin University.Her research interests include recommending system and machine learning,etc.
孙萍(1990—),女,河北三河人,天津大学人工智能实验室硕士研究生,主要研究领域为推荐系统,机器学习等。
LI Qiang was born in 1974.He received the Ph.D.degree in signal and information processing from Tianjin University in 2003.Now he is a professor and Ph.D.supervisor at Tianjin University.His research interests include intelligence information processing,filter design,digital system and micro-system design,etc.
李锵(1974—),男,山西太原人,2003年于天津大学获得博士学位,现为天津大学教授、博士生导师,主要研究领域为智能信息处理,滤波器设计,数字系统和微系统设计等。
GUAN Xin was born in 1977.She received the Ph.D.degree from Tianjin University in 2009.Now she is a lecturer at School of Electronic Information Engineering,Tianjin University.Her research interests include music information retrieval,statistical learning and convex optimization,etc.
关欣(1977—),女,河北石家庄人,2009年于天津大学获得博士学位,现为天津大学讲师,主要研究领域为音乐信号检索,统计学习,凸优化等。
LV Jie was born in 1991.He is an M.S.candidate at Tianjin University.His research interests include recommending system and machine learning,etc.
吕杰(1991—),男,河南驻马店人,天津大学硕士研究生,主要研究领域为推荐系统,机器学习等。
