分布式网络爬虫设计研究
2017-09-30孟军覃海奎刘洁甘宇健
孟军,覃海奎,刘洁,甘宇健
分布式网络爬虫设计研究
孟军1,覃海奎2,刘洁2,甘宇健1
(1.广西财经学院电子商务系,南宁 530000;2.广西财经学院计算机科学与技术系,南宁 530000)
随着大数据相关技术的不断发展,数据的重要性越来越大,如何低成本第获取大量数据是一个值得研究的问题。通过网络爬虫采集数据是一个方便且成本较低的网络数据获取手段,而为了获取更多的数据,单机运行网络爬虫显然是不够的。因此,研究分布式网络爬虫软件,提出一个可行且成本较低的实现方案。
网络爬虫;大数据;分布式
0 引言
网络爬虫又被称为网页蜘蛛、网络机器人,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本[2]。数据爬虫可以在网页之间不断的蠕动获取特定的需要的信息,并将它整理收集保存至用户指定的存储介质。传统垂直网页爬虫常常是单机版的,且操作复杂,需要编写爬虫脚本。而大多的企业更是自己开发爬虫程序,这就花费了大量的时间和资源。能力有限的个人用户更是无法完成独立完成爬虫程序的编写。经过大量的研究分析,编写一个易用的、高效的网络爬虫程序,使没有编程基础能力的普通用户可快速使用,使企业用户可快速使用或可深度定制使用的网络爬虫程序是符合当前市场需要的。
1 系统设计
1.1 系统功能设计
数据抓取是网络数据爬虫的基础也是核心功能,因此保证数据抓取的高效、可靠尤为重要。分布式是目前使用的较多的保证软件系统高效可靠运行的系统架构之一。软件的目标实现当用户安装部署好分布式爬虫系统后,只需编写简单的逻辑脚本①脚本是使用一种特定的描述性语言,依据一定的格式编写的可执行文件,又称作宏或批处理文件。代码即可完成数据抓取工作。对于拥有现成脚本的用户,只需要通过客户端运行脚本即可,客户端会自动将脚本上传到主服务器,由主服务器自动完成任务调度。因此用户可以专注于数据抓取脚本的逻辑实现而分布式、数据库操作等都由爬虫系统完成。
1.2 数据抓取功能
数据抓取功能可以帮助用户抓取用户所需的数据,例如抓取某一个或者多个网站的新闻数据、抓取博客网站数据等[3]。在这个模块下,抓取数据需要用户自行编写简单的爬虫脚本代码以适应不同的网站数据格式。用户脚本代码使用Python语言编写,系统提供自动编码功能(即用户通过点击菜单输入需要的数据便可完成简单脚本代码)。用户定义好抓取规则后,由系统完成数据的抓取、解析、存储等任务。
1.3 分布式运行功能
在处理大数据时,分布式运行往往都能比单机运行快,对数据抓取操作也一样。为了更高效抓取数据,系统需要提供分布式功能。但是,分布式的程序也比单机程序要复杂很多。为了简单易用且高效数据抓取,系统实现不需要用户“操心”的分布式运行功能;用户完成抓取脚本后,系统自动将脚本中的任务拆分,让多台电脑同时进行数据抓取工作。
1.4 系统关键模块设计
爬虫系统使用了C#加Python的两种语言完成。C#语言强项是编写Windows桌面应用程序,系统使用C#语言完成界面、网络通信、分布式、数据库操作等功能模块。Python拥有多个开源且免费的关于数据抓取的开源程序,利用这些程序库开源很方便实现复杂的数据抓取模块。此外Python常被称为胶水语言,能够把用其他语言制作的各种模块联结在一起,这为与C#结合提供了便利。系统关键模块共有三个,分别为任务调度模块、爬虫模块和用户脚本模块,其中系统模块结构如图1所示。

图1 关键模块结构图
(1)任务调度器
任务调度器只运行在Server主机,由管理器、队列维护器和数据同步器三个组件组成。
管理器是Server主机管理Client主机的组件。管理器负责启动、暂停、关闭Client主机的任务。当用户使用管理器管理任务时,任务管理器会向Client主机发送相应指令,通过远程过程调用协议管理Client主机任务,让用户管理Client主机任务就像管理本地任务一样轻松便捷。当任务全部执行完毕后,自动暂停所有Client主机。此外,这个组件还提供定时管理、多用户脚本管理等功能。
队列维护器全称任务URL②URL:对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址(Uniform Resource Lo⁃cator)队列维护器,是每一次数据爬取任务中需要从页面上爬取数据的网页URL队列,维护器负责对该URL队列的增删改查。在爬取数据过程中,维护器会将未爬URL发送给各个电脑上的爬虫完成数据爬取工作。当爬虫完成一个URL的任务后,会通知维护器并开始准备接受新的任务。
数据同步器是分布式高可靠的保障。为保障分布式系统的高可靠性,分布式系统在启动时,系统中的Server主机会随机从众多的Client主机中挑选一台备份Server主机(注:其原本的Client工作照常执行),同时启动其备份进程。数据同步器组件中有心跳机制,每次心跳都会与备份服务器同步数据。如果备份进程发现Server主机长时间没进行备份操作且无法联系上Server主机后,自己将变成Server主机,并通知其他Client,同时挑选新的备份Server。
(2)爬虫引擎
爬虫引擎采用Python语言编写,引用了三个开源的第三方软件:BeautifulSoup③Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库、Selenium④Selenium也是一个用于Web应用程序测试的工具,可直接运行在浏览器中,就像真正的用户在操作一样、Twisted⑤Twisted是一个用Python语言写的事件驱动的网络框架。通过这三个第三方软件可以很方便的编写需要的爬虫引擎,实现流程为Selenium负责操作浏览器和页面源码下载,BeautifulSoup负责源码解析和数据提取,Twisted则负责内部过程调度。Selenium可以很方便的访问网页,将页面源码下载下来,并且提供操作JavaScript和操作页面元素的功能。BeautifulSoup则可以很方便的解析网站源码,可以简便快捷的定位页面元素。Twist⁃ed是一个单线程事件驱动引擎,当用户运用selenium下载或操作页面元素时,twisted可以以单线程事件驱动模式调度selenium,而无需运用多线程加锁模式,从而减少系统资源占用。
(3)用户脚本模块
本模块由C#编写完成,提供一个人性化交互界面让用户完成数据爬取脚本。模块提供脚本的生成、编写、修改功能。由于用户脚本采用Python语言完成,对于不懂编程的用户,模块提供简单易操作的界面,使得用户可以很方便地生成脚本。例如,当用户需要循环运行时,只需要输入循环的开始和结束,系统就能自动生成循环代码。对于学习过Python的用户,软件提供良好的编码环境,如:语法着色、输入提示等功能。
当用户脚本完成后,模块会自动检查脚本正确性。当检查通过,用户便可运行脚本。运行脚本时,用户脚本会传递到爬虫引擎,爬虫引擎通过InronPython⑥InronPython是一种可以让C#中运行Python脚本的第三方.NET库库提供的函数运行用户的Python脚本,从而开始进行数据抓取。
(4)系统测试
分布式网络爬虫程序测试
软件测试环境如下:操作系统:Windows 10家庭版、CPU:E3-1231-v3 3.4Ghz、内存:16GB、网络带宽:100Mb。
在考虑了计算机的硬件配置和系统效率等因素后,测试分成:单机版,分布式(2、3台服务器)等不同情况进行,测试运行为对某电商网站数据进行爬取,测试结果如下:
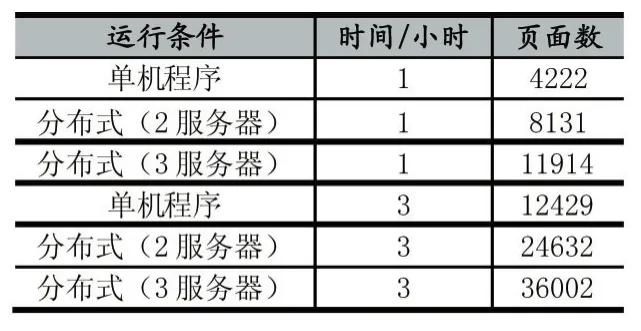
表1
由结果可以看出分布式爬虫的数据爬虫速度较高,可以在短时间内获取大量的页面数据,满足大多数场合应用需要。随着爬取服务器的增加,可以看到数据爬取速度的提升。
2 结果分析
网络爬虫的主要性能指标可以以页面采集速度评价。软件爬取效率提升计算公式如下:

本次测试分别测试运行1小时后,分布式(2服务器)采集效率为8131页面/小时,分布式(3服务器)采集效率为11914页面/小时,单机版采集效率为4222页面/小时。因此可以得出效率提升分别为2服务器效率
可见分布式网络爬虫效率随着服务器增加呈现爬取速度呈现线性增长,满足预期设计要求。
3 结语
在信息爆炸的今天,互联网的发展速度就如同爆炸一般席卷全球。互联网中的信息正在以几何倍数激增,搜索引擎能够满足用户的信息查询需求,却不能满足用户的特殊需求,如:大量数据下载,特定格式数据抓取等[4]。文章提出了一种高效简单的分布式网络爬虫结构,该结构可以让用户只学习简单的脚本语言就能完成数据抓取工作。但是,这也意味着用户需要具有基本编程思维能力才能使用好本软件。在以后的工作中将继续朝着进一步简化用户工作简化用户脚本生成的方向努力改进。
[1]百度百科.大数据[EB/OL].http://baike.baidu.com/item/%E5%A4%A7%E6%95%B0%E6%8D%AE/1356941.2017.04.01.
[2]百度百科.网络爬虫[EB/OL].http://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB,2017.04.01.
[3]刘汉兴,刘财兴.主题爬虫的搜索策略研究[J].计算机工程与设计,2008(12).
[4]高凯.搜索引擎中信息动态采集策略的研究[J].电子学报,2007(10).
[5]蒋志刚,叶勇.Web搜索引擎.NET实现技术研究[J].计算机应用与软件,2007(10).
[6]丁烈云,赵刚.网络文化安全及其监管关键技术研究[J].信息网络安全,2007(10).
[7]崔晓波.无数据不AI,无人工不智能[EB/OL].http://techcrunch.cn/2016/10/26/big-data-and-ai/,2017.04.01.
Design and Research of Distributed Web Crawler
MENG Jun1,QIN Hai-kui2,LIU Jie2,GAN Yu-jian1
(1.Department of Electronic Commerce,Guangxi University of Finance and Economics,Nannig 530000;2.Department of Computer Science,Guangxi University of Finance and Economics,Nannig 530000)
With the sustainable development of big data's related technology,how to get large amount of data at low cost becomes a question worthy of study.It is a convenient and low-cost way to collect network data by web crawlers.However,it is obviously insufficient to get more data through standalone network crawler.Therefore,studies the distributed web crawler software and puts forward a feasible and low-cost action program.
Data Network Crawler;Big Data;Distributed
1007-1423(2017)24-0062-04
10.3969/j.issn.1007-1423.2017.24.015
孟军(1995-),男,广西桂林,本科,学生,研究方向为数据挖掘
覃海奎(1993-),男,广西宜州,本科,学生,研究方向为数据挖掘
刘洁(1997-),女,湖南娄底,本科,学生,研究方向为数据爬虫
甘宇健(1986-),男,广西玉林人,硕士研究生,讲师;研究方向为数据挖掘,Email:47237862@qq.com
2017-05-25
2017-08-15
