基于关联语义融合的WebGIS数据库优化检索方法研究
2017-09-25李浩,李博
李 浩,李 博
(河南工程学院计算机学院,河南 新郑 451191)
基于关联语义融合的WebGIS数据库优化检索方法研究
李 浩,李 博
(河南工程学院计算机学院,河南 新郑 451191)
为提高在Web上发布的空间数据的检索能力,针对传统的WebGIS数据库模糊指向性聚类检索方法容易陷入局部收敛导致检索准确度不高的问题,提出一种基于关联语义融合聚类的WebGIS数据库优化检索方法。采用有向图模型构建WebGIS数据库检索节点分布结构模型,在WebGIS数据库存储数据信息流中进行关联语义特征信息挖掘,以挖掘的特征信息为数据库检索的指向性信息素,并采用分段融合模糊聚类方法进行关联语义融合聚类处理,在数据融合中心中求得数据库检索目标值的全局最优解,实现数据库优化检索和访问。仿真结果表明,采用该方法进行WebGIS数据库检索,对检索数据的查准率较高,抗干扰能力较强,检索过程的收敛性较好。
数据库;检索;WebGIS;语义;数据聚类
随着计算机网络技术和大数据信息处理技术的发展,采用网络Web信息处理技术进行空间地理信息存储和处理成为互联网环境下进行地理信息应用和处理的重要工具,在互联网上存储地理信息的数据库即为WebGIS数据库,WebGIS数据库建立在互联网平台上,客户端应用软件采用网络协议进行空间数据的共享和互操作。WebGIS数据库的客户端采用多主机、多数据库进行分布式部署,满足应用客户获得各种空间信息和应用的功能[1]。WebGIS数据库是一种级联分布式数据库,在对空间数据的共享操作中,需要进行地理信息的准确检索,研究WebGIS数据库优化检索方法是完善网络地理信息系统构建的关键技术,相关的检索算法研究受到相关领域专家的极大重视。目前,对WebGIS数据库检索及应用系统开发模式将数据源、业务逻辑和用户界面以及通讯协议绑定在一起,进行GIS信息的在线查询和业务处理,这种方法导致在空间数据发布、空间查询与检索中容易出现信息干扰,导致检索效率较低,误差较大。对此,需要一种智能的数据库检索方法,主要有空间信息点特征标注法、遗传进化检索方法、粒子群寻优检索方法等[2-3],上述方法主要通过对数据库中存储的数据进行信息特征提取和自适应寻优,采用向量量化编码等方法实现检索信息的关联数据挖掘[4],达到数据库检索的目的,取得了一定的研究成果。其中,林楠等[5]提出一种基于多层空间模糊减法聚类算法的Web数据库安全索引方法,通过数据库信息矢量构建成多层矢量自回归空间,采用遗传进化算法变尺度调整聚类中心向量,结合改进的粒子群算法进行Web数据安全索引,阻止了邻近数据点的干扰,提高了数据库检索的查准性。但是,该算法随着WebGIS数据库规模的增大,计算开销几何级增长,数据检索的实时性较差。陈志华等[6]提出在云计算下环境下的WebGIS大数据非结构的稳定性检索方法,采用属性相关度估计进行GIS空间信息点特征标注,结合关键词语义特征匹配方法进行大数据非结构稳定检索,提高了数据库检索的稳定性。但是该方法在受到较大的网络Web环境干扰下检索出现非法入侵和查询为空等情况,抗干扰能力不强。王跃飞等[7]提出的数据块索引方法利用 URL内容文本特征进行WebGIS数据库的内存扩展和检索语义的语义文本信息寻优,通过量化编码进行WebGIS空间数据信息编码,提高了检索过程中的安全性,但是该方法对数据库中的叠加文本的自动识别能力不高,导致检索精度受到限制。JIANG等[8]采用的模糊指向性聚类检索方法虽然有较快的检索实时性,但是容易陷入局部收敛,存在检索准确度不高的问题。针对上述问题,为了克服传统方法存在的弊端,本研究提出了一种基于关联语义聚类的WebGIS数据库优化检索方法。首先构建WebGIS数据库检索节点分布结构模型,在WebGIS数据库存储数据信息流中进行关联语义特征信息挖掘,然后采用分段融合模糊聚类方法进行关联语义融合聚类处理,在数据融合中心中求得数据库检索目标值的全局最优解,实现数据库优化检索和访问。最后进行仿真试验分析,得出有效性结论。
1 WebGIS数据库存储结构及数据特征分析
1.1原理分析与数据库检索节点分布结构
为了实现WebGIS数据库的优化检索,采用分段融合模糊聚类方法进行特征分析。首先,建立WebGIS数据库检索的节点分布结构模型,本文设计的WebGIS数据库检索模型首先在WebGIS数据库客户端发布空间数据,从Web的任意一个节点进行原始数据提取和语义特征分析,采用数据融合和关联语义特征提取进行WebGIS数据库检索的关联信息分析。然后,通过检索接口返回到数据库中进行检索条件编码,对检索条件进行信息处理和反馈,利用因特网来进行客户端和服务器之间的信息交换,进行WebGIS数据库中的空间数据发布、空间数据信息查询与检索。最后,在用户端显示数据库检索结果[9-12]。根据上述设计原理,设计的WebGIS数据库的优化检索流程如图1所示。
结合图1所示的数据库检索流程,进行数据库检索节点分布结构分析,采用假设Gc表示WebGIS数据库的语义特征分布有向图G1和G2的交集,在有向图G1和G2的语义节点中,WebGIS数据库的邻域空间A,B和C具有共同节点,且同时属于G1和G2。计算有向图G1、G2语义关系相似度Sr,通过语义编辑和概率推理把SC和Sr组成统一的语义相似度S,得到WebGIS数据库检索节点分布的相似度SC的计算公式为:

(1)
式中:n(D1)和n(D2)分别表示WebGIS数据库分布有向图G1和G2中的检索节点数目,n(D1∩D2)表示公共结点数目。
根据上述结算结果,形成WebGIS数据特征分布的语义相似度S:
S=SC*(a+b*Sr)
(2)

图1 WebGIS数据库的优化检索设计流程Fig.1 Optimized retrieval design flow of WebGIS database
式中:当Sr=0时,相似度S取决于SC*a。系数a表示检索通道在G1、G2中的连接度:

(3)
式中:n(GC)表示Gc中语义检索主题词表个数,mGC(G1)+mGC(G2)表示G1、G2中与Gc相关的关系弧数目。
1.2WebGIS数据库检索数据信息流模型
在WebGIS数据库存储结构模型中进行检索数据信息流模型构建[13],采用标量时间序列表示一组WebGIS数据信息流模型为:
(4)
对上述标量时间序列进行WebGIS数据库属性集的向量量化处理[14],得到检索语义特征属性集的向量量化特征分解函数为:
(5)
式中:k表示分布式WebGIS数据库的特征融合中心,采用小波变换对数据信息流从时域转换到频域空间,为:
(6)
式中:f(t)为WebGIS数据库分布数据信息的频域特征值,ρ(a,b)为时频联合分布,a为小波变换的尺度参数,b为加窗时间延迟。在特征分布状态空间中WebGIS数据信息流x(t)的特征匹配输出向量为:
=min{D(xi,Aj(L))}
(7)
式中:xi∈Rn为数据库中检索数据的模糊度点集,ui∈Rm为数据信息流的相空间主频特征分量。根据上述对WebGIS数据库检索数据信息流模型构建,为进行数据库检索提供准确的数据输入基础。
2 数据库检索算法优化设计
2.1关联语义特征信息挖掘
在上述进行了WebGIS数据库存储结构分析和信息模型构建的基础上,进行数据库检索优化设计,本文提出一种基于关联语义聚类的WebGIS数据库优化检索方法。在上述构建的WebGIS数据库存储数据信息流中进行关联语义特征信息挖掘,通过数据匹配检测,得到WebGIS数据库检索数据信息流的包络幅值为:
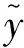
(8)
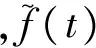

(9)
式中:N(z)是关联语义特征分辨率,它的零点在z=e±jω0处频域的分辨率下降,D(z)为模糊属性集的聚类尺度因子,由此可得WebGIS数据库中隐蔽数据信息流的交叉项[15],对隐蔽数据进行抗干扰抑制,实现关联语义特征信息挖掘,得到挖掘输出为:

(10)
式中:语义相似度属性的模糊度点集满足UT=U-1,VT=V-1,D∈Rm×M,且D=[∑ 0]。以上述挖掘的WebGIS数据特征信息为数据库检索的指向性信息素,进行数据库检索的优化设计。
2.2分段融合模糊聚类及数据库检索实现
采用分段融合模糊聚类方法进行关联语义融合聚类处理,假设WebGIS数据库中的待检索信息流时间序列x(n),〈x(n)〉代表对x(n)取分段融合均值:

(11)
通过对数据信息流进行动态副本自适应分簇匹配[16],得到WebGIS数据库中的融合数据的语义属性自相关特征状态为:
xn=x(t0+nΔt)=h[z(t0+nΔt)]+ωn
(12)
式中:h(.)为多元数量值函数;z(t)是数据库检索模型在时刻n或t的状态向量;ωn为观测或测量误差。在相空间中挖掘数据库检索信息的几何不变量,得到WebGIS数据库的数据类群多样性分类属性状态函数表示为:
z(t)=s(t)+js(t)⊗h(t)=s(t)+
(13)
式中:s(t)为WebGIS数据模糊隶属函数,称为复信息流z(t)的瞬时幅度。
以挖掘的特征信息为数据库检索的指向性信息素,得到有限个WebGIS数据库的信息素集:
X={x1,x2,…,xn}⊂Rs
(14)
把数据库中的信息素集X分为c类,其中1 V={viji=1,2,…,c,j=1,2,…,s} (15) 其中,Vi为WebGIS数据库聚类中心的第i个矢量,选择一定的基函数对冗余数据归集合并,得到聚类目标函数: (16) 式中,μik为WebGIS数据库检索的延迟映射;m为检索目标数据的高阶谱特征分量;(dik)2为关联语义融合聚类中心xk与Vi的欧式距离表示,为: (17) 且 (18) 在检索通道链路层中进行WebGIS数据关联语义信息模板匹配[17-19],结合模糊指向性控制的约束条件,在数据融合中心中求得数据库检索目标值的全局最优解为: (19) (20) 在聚类中心初始值已经给定的情况下,根据上述求得的全局最优解实现待检索数据的准确定位和识别,实现WebGIS数据库检索优化。 为了测试本文算法在实现WebGIS数据库优化检索中的性能,进行仿真实验。实验采用C++和Matlab 7混合编程进行数据库检索算法处理和数据分析,Web服务器使用Tomcat4.1,数据库服务器使用MySQL,服务器端代码用Java实现,WebGIS数据库中进行检索的时间间隔为1.45 s,WebGIS库中采样数据集的训练数据长度为10 000,语义关联特征空间的时间窗口系数τ为0.43,数据库的分层列数为20,语义特征尺度参数a0=1.03,关联语义特征分解的带宽B=10 kHz,仿真实验的持续时间T=100 s,分段融合聚类的迭代次数设定其1 000次,根据上述仿真环境和参数设定,进行WebGIS数据库的优化检索仿真实验。首先,对WebGIS数据库中存储的大数据进行信息采样,形成海量数据集合作为测试样本集,得到测试样本数据的时频域散点分布图如图2所示。 图2 测试样本数据的时频域散点分布Fig.2 Scatter plot of time and frequency in test sample data 从图2的数据分布空间状态可见,原始测试数据在WebGIS数据库中受到大量信息的相互干扰作用,难以有效实现准确的数据检索和提取,采用本文方法进行关联语义特征信息挖掘,实现对待检索数据的分段融合模糊聚类,得到融合聚类结果如图3所示。为了对比,图4给出了采用文献[5]提出的模糊减法聚类Web数据库安全索引方法进行数据检索的输出结果,模糊聚类方法采用减法聚类的模糊推理构建索引函数,变尺度调整聚类中心向量,阻止了邻近数据点非法侵入和非法聚类,有效排除了非法数据输出,实现Web数据库安全索引,然而该方法存在收敛性不好和容易陷入局部最优解的问题。 图3 本文方法进行分段融合聚类后的数据检索输出Fig.3 Data retrieval output after segmentation and clustering with new method 图4 传统模糊聚类检索输出Fig.4 Traditional fuzzy clustering retrieval output 由图3和图4可知,采用本文方法进行数据库检索,相比传统方法能有效滤除冗余数据的干扰,避免陷入局部最优解,提高了数据库检索的聚类中心指向性能力,检索的精度较高。为了定量分析算法性能,采用本文方法和传统方法进行WebGIS数据库检索,得到查准率对比结果如图5所示。 由图5可知,采用本文方法进行数据库检索的查准率能快速收敛到100%,计算时间开销较小,精度优越传统方法。 图5 查准率对比结果Fig.5 Precision contrast results 本文研究了WebGIS数据库的优化检索问题,提出一种基于关联语义融合聚类的WebGIS数据库优化检索方法,采用有向图模型构建WebGIS数据库检索节点分布结构模型,在WebGIS数据库存储数据信息流中进行关联语义特征信息挖掘,在检索通道链路层中进行WebGIS数据关联语义信息模板匹配,采用分段融合模糊聚类方法进行关联语义融合聚类处理,求得数据库检索目标值的全局最优解,实现待检索数据的准确定位和识别,完成数据库优化检索和访问。以实际的WebGIS数据库进行检索试验分析,并传统的模糊减法聚类检索方法进行对比分析,研究得出,采用本文方法进行WebGIS数据库检索,对干扰数据的抑制能力较好,经散点图分布得知,本文的检索方法把大量的冗余数据排除在外,由于本文方法采用分段融合方法进行语义特征聚类处理,避免了数据库检索过程中陷入局部优化解,具有较好的收敛性和鲁棒性。对比检索结果得知,本文方法进行WebGIS数据库检索的查准率较高,在较短的测试时间使得查准率收敛到100%,表现出了较好的自适应寻优能力,在WebGIS数据库检索和访问等领域具有较高的应用价值。 [1] 邢淑凝, 刘方爱, 赵晓晖. 基于聚类划分的高效用模式并行挖掘算法[J]. 计算机应用, 2016, 36(8): 2202-2206. [2] ZIHAYAT M, AN A.Mining top-k high utility patterns over data streams[J].Information Sciences,2014,285:138-161. [3] YUN U,RYANG H,RYU K H. High utility itemset mining with techniques for reducing overestimated utilities and pruning candidates[J].Expert Systems with Applications,2014,41(8):3861-3878. [4] 冶忠林, 杨燕, 贾真, 等. 基于语义扩展的短问题分类[J]. 计算机应用, 2015, 35(3): 792-796. [5] 林楠,史苇杭.基于多层空间模糊减法聚类算法的Web数据库安全索引[J].计算机科学,2014,41(10):216-219. [6] 陈志华,刘晓勇. 云计算下大数据非结构的稳定性检索方法[J].现代电子技术,2016,39(6):58-61. [7] 王跃飞, 于炯, 鲁亮. 面向内存云的数据块索引方法[J]. 计算机应用, 2016, 36(5): 1222-1227. [8] JIANG Y Z, CHUNG F L, WANG S T, et al. Collaborative fuzzy clustering from multiple weighted views[J]. IEEE Transactions on Cybernetics, 2015, 45(4): 688-701. [9] PAO W, LOU W, CHEN Y, et al. Resource allocation for multiple input multiple output-orthogonal frequency division multiplexing-based space division multiple access systems [J]. IET Communications, 2014, 8(18):3424-3434. [10] 姜仁贵, 解建仓, 李建勋, 贺挺. 基于数字地球的WebGIS开发及其应用[J]. 计算机工程, 2011, 37(6): 225-227. [11] EISAYED A M A, ELSAID A, NOUR H M, et al. Dynamical behavior, chaos control and synchronization[J]. Communication in Nonlinear Science and Numerical Simulation, 2013, 18(1): 148-170. [12] 冯登国, 张敏, 李昊.大数据安全与隐私保护[J]. 计算机学报, 2014, 37(1):246-258. [13] 潘颖,元昌安,李文敬,等. 一种支持更新操作的数据空间访问控制方法[J]. 电子与信息学报, 2016, 38(8): 1935-1941. [14] 郭明强, 黄颖, 谢忠. 一种多核环境下的WebGIS模型优化策略[J]. 计算机工程, 2013, 39(8): 15-19. [15] 王映辉,冯德民.基于版本控制策略的WebGIS缓存实现机制研究[J].计算机科学,2003,30(12):89-91. [16] 潘颖, 汤庸, 刘海. 基于关系数据库的极松散结构数据模型的访问控制研究[J]. 电子学报, 2012, 40(3): 600-606. [17] 王天宝, 卢浩, 钟耳顺. 客户端视角下的WebGIS开发框架研究[J]. 计算机工程, 2012, 38(9): 255-257. [18] MAHBOUBI H, MOEZZI K, AGHDAM A G, et al. Distributed deployment algorithms for improved coverage in a network of wireless mobile sensors[J]. IEEE Transactions on Industrial Informatics, 2014, 10(1): 163-174. [19] MAHBOUBI H. Distributed deployment algorithms for efficient coverage in a network of mobile sensors with nonidentical sensing capabilities[J]. IEEE Transactions on Vehicular Technology, 2014, 63(8): 3998-4016. (责任编辑:蒋国良) ResearchonWebGISdatabaseoptimizationretrievalmethodbasedonassociationsemanticfusion LI Hao, LI Bo (College of Computer Science, Henan University of Engineering, Xinzheng 451191,China) By using the traditional fuzzy clustering method to WebGIS database retrieval, the suggested answer would probably fall into local convergence condition,which would result in low retrieval accuracy. In this paper, an optimized method of WebGIS database retrieval based on semantic clustering is proposed for the problem, which improves the retrieval capability of spatial datareleased on Web. Firstly, a digraph is used to construct the distribution model of retrieval node in WebGIS database. Secondly, the data in the information flow of WebGIS database is mined by association semantic character. The mined feature information will be used as a information clue in retrieval. Finally, a global optimal solution of database retrieval in the clustering center is found by using the associated semantic clustering which is achieved by adopting piecewise fusion fuzzy clustering methods. The simulation results show that the proposed method has a high accuracy, strong anti-interference ability and good convergence performance in the WebGIS database retrieval process. database; retrieval; WebGIS; semantic; data clustering TP391 :A 2016-10-12 国家自然科学基金资助项目(61501174) 李浩(1974-),男,河南洛阳人,副教授,硕士,从事计算机网络方面的研究工作。 1000-2340(2017)03-0396-06
3 仿真实验与分析
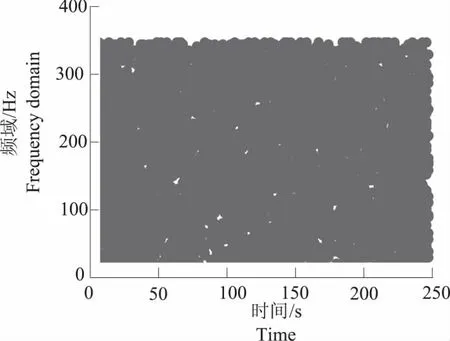



4 结论
