基于混合方法的医疗欺诈行为检测
2017-09-22潘松松张伟佳
潘松松,张伟佳
(华东师范大学,计算机科学与软件工程学院,上海200062)
基于混合方法的医疗欺诈行为检测
潘松松,张伟佳
(华东师范大学,计算机科学与软件工程学院,上海200062)
随着医保制度的不断完善,医保覆盖率的不断扩大,医保基金的正常运转已经与人民大众的切身利益密切相关.然而,频繁就医、分解住院和异常费用支出等欺诈行为的频繁发生,极大地威胁着医保基金的正常运转.本文先使用随机森林的方法分病种进行特征选择,然后通过基于Clustering-Based Local Outlier Factor(CBLOF)的方法以及改进的CBLOF方法检测异常的结算费用.同时通过基于规则的方法检测频繁就医和分解住院行为.通过在真实医保结算数据上进行实验,实验结果证明了方法的可行性和有效性.最后,本文给出了医保基金监督平台的系统框架,通过该平台对透视分析的结果进行可视化展示.
异常检测;局部异常因子;CBLOF;分解住院
0 引言
随着人民生活水平的不断提高,公民自身的社会保障意识得以不断提升.医疗保险制度以其不可或缺的重要性在我国社会保障体系中占据着重要的地位.该制度自实施以来,医保基金在解决人民大众就医看病方面起到了重要作用.医疗保险被认为是一个介于参保人员、医疗机构和医保机构三方之间博弈的过程,三方利益的驱动往往容易诱发欺诈行为的发生.从医院角度,往往通过过度诊疗、过度用药和分解住院等来达到增加医院收入的目的;从参保人员角度,冒名就医、频繁就诊和非法报销等行为成为减少个人医疗费用支出的手段;而至于医保机构方面,也时有发生医保结算数据审核力度不够的情况.在这种情况下,愈演愈烈的医疗欺诈行为使医保基金遭受着巨大的损失,威胁着医保基金的正常运转.因此,为了实现医保基金长期的正常运转,加大对医疗欺诈行为的检测至关重要.
目前,大部分对于医保违规行为的审核,主要还是靠人工去解决,工作量极大,效率低下,且不能很好地发现医保欺诈行为.随着数据挖掘和机器学习在医疗领域的广泛应用,利用数据挖掘等大数据技术来解决医疗欺诈行为的需求应运而生.部分学者开始把数据挖掘技术应用到医保欺诈行为的检测中,如Shi[1]综合利用半监督的Isomap方法和局部异常因子检测方法Local Outlier Factor(以下简称LOF)识别异常的费用,但是在特征选择时,并未考虑患者本身个体的差异;Xie[2]将信息熵和LOF方法结合用于基金费用异常检测,同样没有考虑患者本身的特征.鉴于目前大部分研究都是针对某一种欺诈行为展开,本文将基于聚类的检测方法和基于规则的检测方法相结合,提供多种欺诈行为的检测.本文主要贡献点包括以下3点:
(1)特征提取.加入患者的个人特征如年龄、性别等;同时,鉴于不同病种影响因素不同,采用分病种进行相应的特征选择,以减小特征差异对模型结果造成的影响.
(2)异常检测.本文选取指定的常见病种,应用基于Clustering-based Local Outlier Factor方法(以下简称CBLOF)和改进的CBLOF方法检测异常的费用支出,应用基于规则的异常检测方法对频繁就医、分解住院等行为进行检测,以帮助减轻异常审核的工作量.
(3)系统实现.利用Web开发框架开发了医保基金监督平台,支持从不同维度对以往费用数据和异常检测的结果进行查询和展示.
本文第1节介绍相关工作;第2节详细介绍医疗欺诈行为的检测方法;第3节介绍医保基金监督平台的系统框架;第4节进行实验结果展示与分析;第5节对本文工作进行总结与展望.
1 相关工作
医疗保险欺诈行为并不是某个国家所特有的问题,全世界实行医疗保险制度的国家都面临相应的问题.国内外对医疗欺诈行为的研究主要分为欺诈行为成因及其特点研究、如何反欺诈行为研究以及欺诈行为的识别3个方面.
在欺诈行为成因及其特点方面,Dionne[3]基于信息不对称的角度,对医疗欺诈行为的成因进行了相关解释;Skiba[4]借鉴长久以来反欺诈行为的经验,应用定性解释现象学对欺诈行为的成因进行了解释;Krause[5]通过对各种欺诈行为进行分析,构建了以患者为中心的分析模型;Lorenz[6]则详述了美国医保基金中存在的欺诈行为的分类和原因.
在如何反欺诈方面,李连友和李亮等人[7]从欺诈方的成本与收益的角度对欺诈行为进行分析,提出了欺诈行为的影响因子模型;王明慧[8]则从欺诈成因及其危害两个方面进行了深度分析,对如何反欺诈行为给出了相应的建议;夏宏和汪凯[9]从医保基金征缴、支付以及基金管理过程中的欺诈行为进行分析,并提出一系列反欺诈行为的措施.
在欺诈行为识别方面,传统的医疗欺诈行为检测方法,主要是基于专家制定的规则[10],一旦就医记录中违反了给定的规则,则判断为欺诈行为,方法的有效性受到规则正确性的约束.随着大数据技术在医疗领域的广泛应用,数据挖掘技术开始被应用到医疗欺诈行为的检测中.早在1999年,Biafore[11]指出数据挖掘技术发现数据中潜在的数据模式,从而为科学决策提供依据;Milley[12]则介绍了数据挖掘技术在医疗欺诈行为检测中的成功案例.高臻耀和张敬谊等[13]从医保基金风险防控的角度,把数据挖掘与机器学习技术应用到模型库与方法库的构建当中.数据挖掘技术把医疗欺诈行为视为异常行为,则医疗欺诈行为检测问题转化为经典的异常检测问题.传统的异常检测方法主要分为基于分类的异常检测方法、基于距离的异常检测方法、基于统计的异常检测方法以及基于聚类的异常检测方法4种.
基于分类的异常检测方法[14],将数据分为正常和异常两种,使用标注好的数据进行训练,把异常检测问题转化为二分类问题.基于距离的异常检测方法基本思想是基于数据点之间的距离,异常点会极大不同于它的邻居,而正常点会和自己邻近的点非常接近.不同的方法会使用不同的距离或者相似度度量方式.如何衡量异常点和其邻近点的距离,主要有两种方式,一种是计算各个数据点与其邻近点集合的距离,然后通过距离来判断异常.另一种计算数据中各区域的密度,把处于低密度区域的数据视为异常.Breunig[15]给每个数据点定义了一个局部异常因子,局部异常因子值越大越可能是异常点.基于统计的异常检测方法[16-17]假定正常的数据是由某一统计模型产生,不符合该模型分布规律的则视为异常数据,这种方法高度依赖数据的模型假定.基于聚类的异常检测方法[18-20]认为正常点必然属于包含数据点较多的簇,而异常点则属于包含数据点较少的簇或者不属于任何一个簇.该方法先聚成簇,再根据簇的大小来判定是否为异常数据点.
目前,异常检测方法应用到医疗欺诈行为检测方面的研究相对较少.Roberts[14]应用神经网络分类模型来检测医药诊断中数据的异常数据;Xie[2]将信息熵和LOF方法结合基金异常检测,信息熵主要用来计算两条记录之间的距离,通过不同属性的信息熵,给予不同属性相应的权重,最后根据局部异常因子的大小判定异常程度;Sun[21]提出了一种混合的异常检测方法,将患者的就医记录表示成一个序列,通过比较子序列的模式,判断异常的就医行为类别和就医行为频次;Moyano[22]使用IBM Bluemix平台和开放云平台搭建了一个医疗报销数据分析和展示平台,他把患者和医生之间的一次诊疗过程用图来进行描述,患者和医生是不同的结点,而一次诊疗过程被视为一条边,从而可以分析患者与医生之间的联系; Bauder[23]则对患者按照疾病进行分组,对每个分组使用不同的回归模型去拟合医疗费用,对每个分组选择具有最高R2或者最小RMSE的模型,把拟合的结果作为基准费用标准,从而判断异常的异常费用;Shi[1]综合应用半监督的Isomap方法和LOF方法检测异常的费用支出,同时构建了一个医保索赔数据异常检测系统;关皓文[24]针对同一病种,提出基于SLOF方法检测异常的用药组合,同时,提出基于CODM的方法检测异常的临床路径.
2 医保欺诈行为检测方法
由于医保欺诈行为的频繁发生,极大地威胁着医保基金的正常运转,如何对欺诈行为进行检测成为普遍关注的问题.具有欺诈行为的记录可以视为数据集中的异常点,所以欺诈行为的检测,转化为经典的异常数据的检测问题.
2.1 基于CBLOF的检测方法
CBLOF方法是聚类算法和LOF方法思想的结合,利用聚类算法将数据集聚成簇,然后根据簇大小划分大簇和小簇,分别计算每个簇中数据的异常因子.该算法认为,大簇中的数据点异常因子会比较低,而小簇中数据点的异常因子相对较高.在同一个簇中,簇边缘的数据点更可能是异常点,而簇中心的点则更可能是正常点.本文中使用基于CBLOF算法检测异常的费用支出,对每条数据计算异常因子值,根据异常因子值的大小,最终选取其中的一小部分数据作为候选异常记录集.
2.1.1 问题定义
为了方便后续对于欺诈行为检测方法具体步骤的描述,本节中介绍了文章中使用的符号及其相关定义.
定义1医保数据库D有m条记录,每条记录t有n个属性,记为A1,A2,…,An,假设对数据集进行聚类后分为k个簇,记为c1,c2,…,ck,则c1∪c2∪…∪ck=D.
定义2假设聚类之后按簇的大小进行排序之后结果为|c1|>|c2|>|c3|…>|ck|,定义一个阈值α来区分大小簇,大簇记为L,小簇记为S.
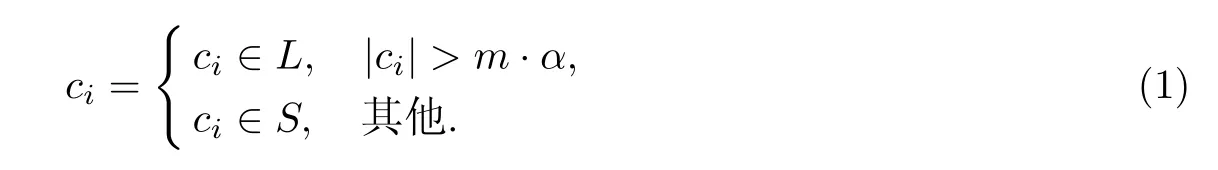
定义3局部异常因子(local outlier factor,以下简称lof),如果数据记录聚类后属于标记为L的簇,它的局部异常因子由所在簇大小和它到所在簇中心的距离决定;如果数据记录聚类后属于标记为S的簇,则由其所在簇大小及其它与最近的大簇中心的距离所决定.lof值的大小决定着数据记录的异常程度,lof值越大,则越可能是异常记录.

定义4 lof值的更新,当新记录进入时,若经过聚类属于标记为S的簇,则立即更新每条记录的lof值,若属于标记为L的簇,则设置计数器cnt,cnt计数加1,当cnt与当前簇大小的比例超过预先设定的阈值β,则更新每条记录对应的lof值.
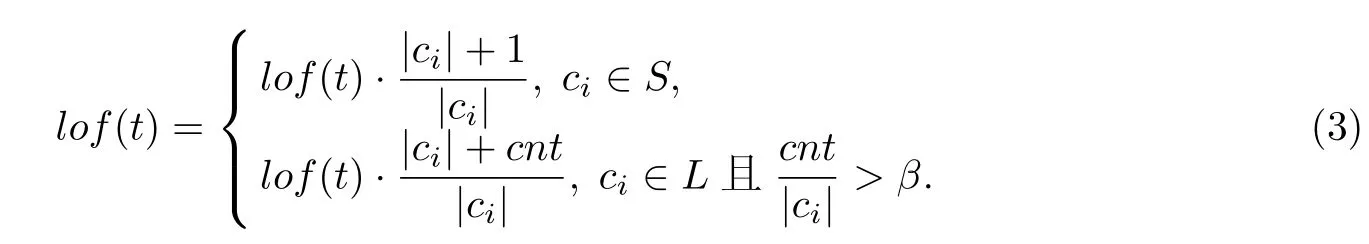
2.1.2 CBLOF算法
CBLOF方法先对数据集进行聚类分析,根据聚类的结果进行大簇和小簇的划分,然后再对每条记录计算lof值.考虑到Squeezer算法[25]不需要初始指定聚类结果中包含的簇的多少,所以能够给出更加自然的聚类效果.因此,本文中选用Squeezer方法进行聚类,它的主要思想是,对于第一条记录通过addNewCluster()创建一个新簇,对于后续每条记录,调用computeSimilarity()判断它与当前已有簇的相似度,找到最相似的簇索引index和最大相似度cur similarity.如果cur similarity超过预先设定的阈值max sim,则调用addToCluster()把该条记录加index对应的簇中,否则,调用addNewCluster()创建一个新簇.
聚类相关工作完成后,需要计算每个数据记录的局部异常因子.对于给定的阈值α,它是大小簇划分的依据.对于第一步聚类的结果,根据定义2进行大簇和小簇的划分,大簇标记为L,小簇标记为S.再次遍历数据集,对于每一条数据记录,根据定义3,如果该记录属于标记为L的簇,则调用computedLOF L()计算该记录的lof值;如果属于标记为S的簇,则调用computedLOF S()计算该记录的lof值,具体算法流程如算法1所示:

2.1.3 改进的CBLOF方法
鉴于本系统中会陆续有新的数据进入,如果利用上述的CBLOF方法可以进行欺诈行为检测,但是每次都需要重新训练模型,当数据量比较大时,开销很大.因此,这里采用改进的CBLOF算法,该算法的主要思想是:先针对已有的数据采用CBLOF法进行模型的训练,直到模型相对稳定.当有新的数据到来时,使用Squeezer算法进行聚类,对每条记录record进行判断,如果该记录属于标记为S的簇,调用addToCluster()把该记录添加到当前簇中,同时根据定义4,调用updateLOF S()更新当前簇内所有数据点的lof值;如果该记录属于标记为L的簇,设置计数器cnt,cnt计数加1,调用computeLOF L()计算该记录lof值,当且仅当计数器的大小超过当前簇大小相应的比例β时,调用updateLOF L()更新当前簇内所有数据点的lof值,可以极大地减少频繁更新lof值的开销.具体算法流程如算法2所示.
2.2 基于规则的欺诈行为检测方法
基于规则的异常检测方法是一种传统的医保数据异常检测手段,医疗专家根据经验进行规则的制定,如果就医行为违反了制定的规则,则视为欺诈.由于不合规行为的多变性以及疾病发生的不确定性,不同的医生可能会制定出不同的规则.虽然规则可能存在不同,但是依然存在一些通用的规则可以帮助我们发现其它检测方法无法捕获的异常.例如,基于CBLOF的异常检测方法,它给每条记录进行异常因子的计算,但是却没有考虑对于同一个患者,不同的就医记录之间存在的关系,如频繁就医、分解住院等行为.频繁就医,是指在一定的时间范围内,患者因为同一种疾病去医院就诊的次数过多的行为.分解住院,是指医院在患者尚未痊愈的情况下,为患者办理多次出院、再入院的行为.这些行为不能仅仅通过单条就医记录进行判断,但基于规则的方法却能够很快地进行检测.

基于规则的欺诈检测方法借助于医保知识库、医药知识库以及医疗专家的领域知识来制定相应的规则.医保知识库中包括《基本医疗保险、工伤保险和生育保险药品目录》、《医疗服务价格手册》和《城镇职工基本医疗保险实施办法》等数据来源,而医药知识库将包含《诊疗指南》、《药品说明书》和《临床路径》等数据来源.系统将知识库中包含的内容转化为相应的规则,一旦违背规则,则视为医疗欺诈行为.规则主要分为报销规则、临床规则和统计规则三大类.报销规则包括限性别审核、限儿童、超限定价格、支付比例异常审核、非基本医疗保险目录和限定医院级别等审核内容;临床规则,包括非常规诊疗用药、重复用药、重复诊疗和用药安全等审核内容;而统计规则包括不合理入院、超短期住院、分解住院、住院天数异常和频繁就医等审核内容.通过相应规则的制定,则可以真正实现事前监督,极大地杜绝医疗欺诈行为的发生.一旦在住院过程中,医生、医疗机构或者患者本身违反制定的规则,则视为医疗欺诈行为,不予报销医疗费用.与此同时,通过基于CBLOF和改进的CBLOF的方法对于异常费用支出的检测结果,可以分析其中的欺诈行为的聚集模式,从中学习新的规则,进一步更新系统中的规则库.
针对就医行为中的频繁就医和分解住院,本文制定以下规则进行检测.
(1)频繁就医.在一个月内,同一个患者因同一种病在同一家医院就诊次数超过3次,视为频繁就医行为.
(2)分解住院.同一个患者因同一种病,在同一家医院住院时,相邻两次住院记录,前一次出院时间等于后一次入院时间,则视为分解住院.分解住院示例如表1所示.

表1 分解住院示例Tab.1 Examples of hospitalization decomposition
3 医保基金监督平台的框架
本文选取了当前主流的Web开发框架Struts2+Mybatis和Mysql数据库开发了医保基金监督平台(Medical Insurance Fund Supervisory System,以下简称MIFS,如图1所示).MIFS系统可以帮助医疗保险机构从多个维度洞察费用的支出情况,同时可以将医保审核人员从大量医保数据异常审核的工作中解脱出来.该系统框架主要分为源数据层、数据仓库层、数据分析层和应用业务层4层.
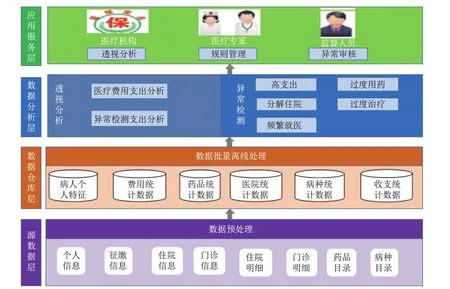
图1 医保基金监督平台框架图Fig.1 Framework of medical insurance fund supervisory system
源数据层主要来自于医保机构提供的参保人的个人信息、征缴信息、住院信息、门诊信息、住院明细、门诊明细、病种目录和药品目录等数据.
数据仓库层,对源数据层提供的数据进行数据抽取、清理.通过数据分析发现存在数据格式不一致以及很多无效数据.在住院数据中,有些疾病代码是按照ICD-10进行编码,而且存在小部分疾病编码混乱,在征缴信息中也存在缴费金额为负数的情况.同时,住院数据中也存在数据缺失问题,住院记录中有小部分患者入院病种和出院病种均为空,入院日期为空的记录也少量存在.因此,需要进行数据预处理之后,才能进行后续的数据分析工作.
数据分析层,主要分为以下两个子模块.
(1)异常检测模块,主要包含异常费用支出、分解住院、频繁就医、过度治疗和过度用药5种欺诈行为的检测.目前,系统主要完成了对前3种欺诈行为的检测.系统使用基于CBLOF方法和改进的CBLOF方法检测异常的结算费用;使用基于规则的方法检测频繁就医和分解住院行为.
(2)透视分析模块,包括对现有费用支出和欺诈行为检测结果的分析,对于费用支出,可以从参保人群、医院、病种和药品等多个维度进行分析,更好地了解费用支出的细节;对于欺诈行为检测结果的分析,可以了解具有欺诈行为的患者的年龄分布、医院的等级分布、病种分布以及药品分布情况,从中发掘异常聚集的特点,从而有效减少欺诈行为的发生.
同时,MIFS系统将借助Echarts强大的可视化功能对数据分析的结果进行展示,从而帮助用户对数据分析的结果有更加直观的了解.
应用服务层,根据用户的需求,提供相应的服务,对于医保机构,系统将提供透视分析的结果,帮助他们更好地了解基金费用支出的细节;对于医疗专家,通过异常聚集特点的分析,可以帮助他们进行异常规则的制定;对于医疗审核人员,系统将提供候选异常,以供他们进行最后的判断.
4 实验
本节使用真实的医保结算数据进行相关实验,系统的开发基于Java语言实现,运行在处理器为Intel Core i5-4460 3.20GHz,内存16G,操作系统为Windows的PC机上;相关数据分析工作主要基于Python语言实现,运行在Hadoop集群服务器上.
4.1 数据集介绍
数据集来自某市医保局提供的该市城镇职工基本医疗保险数据,包括2006–2015年的职工缴费信息、职工个人信息(包括个人编号、性别、年龄和工作单位类型)、2010–2015年职工住院信息、门诊信息以及住院明细信息、门诊明细信息等,数据集的简单统计信息如下表2所示.

表2 数据集统计信息Tab.2 Statistics of datasets
4.2 实验结果分析
考虑到医保局提供的门诊数据中未包含入院病种、出院病种以及医疗机构代码字段,所以在欺诈行为检测部分,主要使用的是住院数据.通过对2015年分病种费用统计汇总,发现腰椎间盘突出总费用支出最高,所以本文主要是针对腰椎间盘突出患者的住院记录进行欺诈行为的检测.
4.2.1 基于病种进行特征选择
通过对患者个人信息、住院信息和住院明细信息进行特征抽取以及对原数据的统计分析工作,得到分病种的特征集包括患者年龄、性别、身份(在职、离退)、单位性质、年度工资、医院等级、住院天数、是否患有慢性病、起付线、报销比例、药品费、诊疗费、床位费、手术费、护理费、材料费和住院总费用等17个特征.一般基于聚类算法的医疗数据异常检测,不会分病种进行考虑,对所有病种住院费用异常的检测时都选用同样的特征.由于病种的不确定性对于住院费用的影响因素也不尽相同.因此,在进行聚类算法之前,本文先使用随机森林方法,分病种对医疗费用的影响因素进行分析,然后进行特征提取.图2是使用随机森林对腰椎间盘突出住院费用影响因素进行分析的结果,可以看出药品费、诊疗费以及年龄,对于一次住院费用的高低影响较大,而身份、医院等级的影响相对较小,所以特征选取将剔除性别、身份两个特征.在进行特征选取之后,对于特征的每一维,按照min-max标准化方法进行归一化处理.
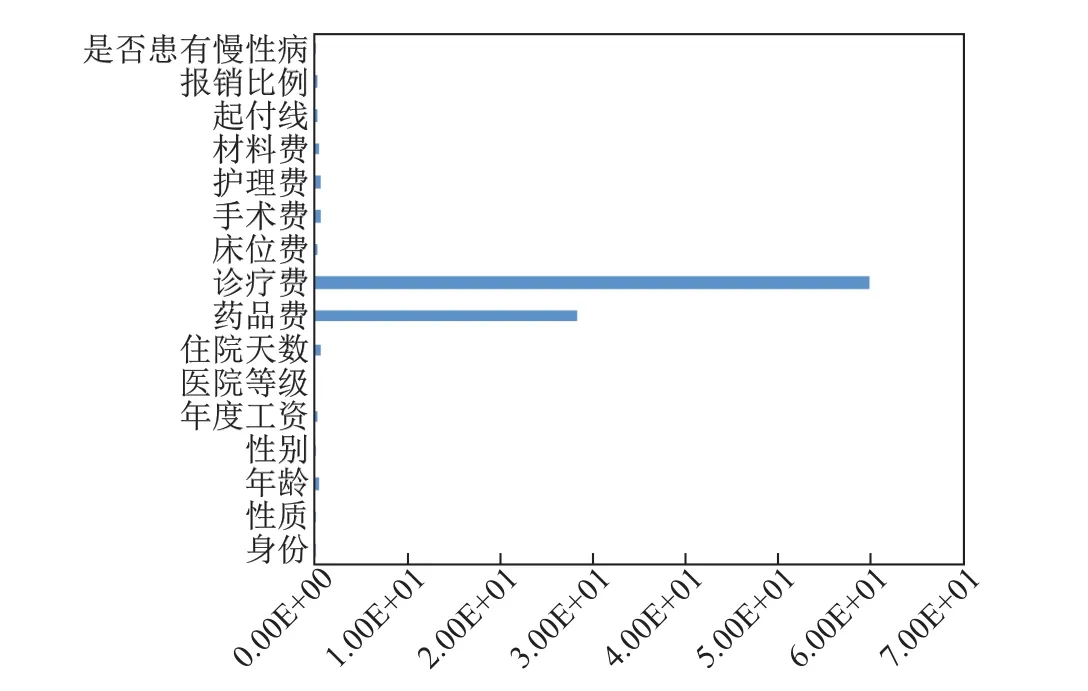
图2 腰椎间盘突出住院费用影响因素Fig.2 Factor of hospitalization fees of lumbar disc herniation
4.2.2 基于CBLOF和改进的CBLOF的异常检测方法
本文针对异常行为的检测的评价指标主要有异常检出率和时间效率两种.异常检出率(Coverage),是指在异常检测的结果中,检测出的异常点数量占所有异常点的比例.时间效率,则是关注程序运行的时间长短.
(1)异常检出率
鉴于医保局提供的数据并未进行异常数据的标注,所以本文借助于UCI数据库中的Wisconsin breast cancer数据集来验证算法的异常检出率情况.该数据集包含699条记录,每条记录包含细胞厚度、细胞大小均匀性、细胞形状均匀性、边际粘附、单个上皮细胞大小裸核、Bland染色质、正常核和有丝分裂9个属性,每条记录标记为良性或者恶性.去除包含缺失数据的记录,保留所有的良性记录和六分之一的恶性记录,总共482条记录,包含39条恶性记录,且把恶性记录作为异常.
分别使用CLOF和改进的CLOF方法进行检测,给每条记录一个lof值,然后按照lof值大小降序排序,选择lof值较高的作为异常值的候选项,表3是使用CBLOF和改进的CBLOF算法异常检出率的比较,表格第一列“数据量”,括号内的数字N表示选择前Top N的lof值来评估,如表3第一行表示,lof排名前4的记录中,使用CBLOF方法,有2条异常被选出来,占总异常数目的5%,使用改进的CBLOF方法,有4条异常记录被挑选出来,占总异常数目的10%.从表3可以看出,CBLOF方法在前15%的数据中,能检测出所有异常;而改进的CBLOF方法可以在前14%的数据中,检测出所有异常.
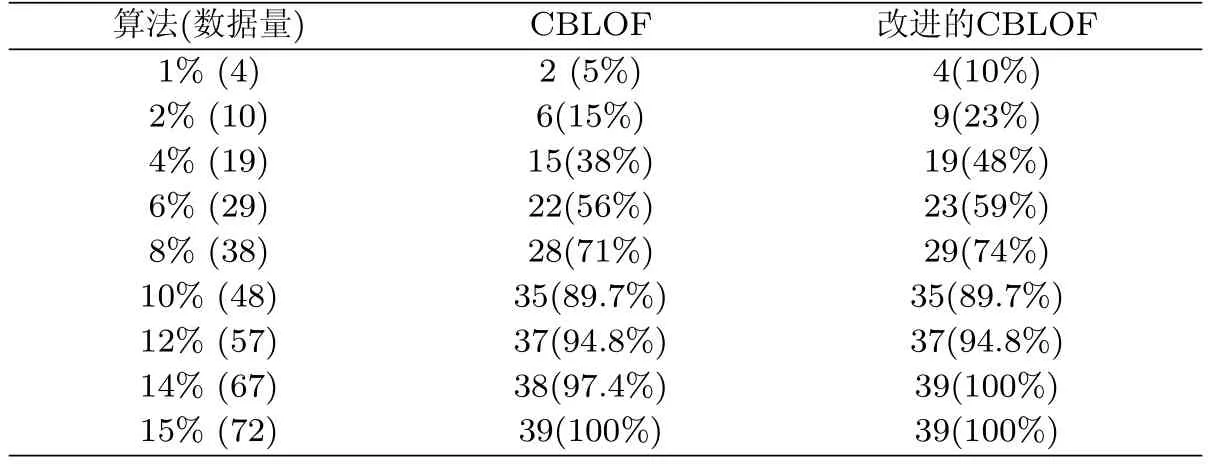
表3 检出率比较Tab.3 Comparison of coverage
(2)时间效率
对于医保数据异常检测,主要使用腰椎间盘突出患者的住院数据,数据量4 170条,选取最终lof值前5%~10%的数据作为候选异常项.鉴于数据没有标签,所以主要比较两种算法的时间效率,结果如图3所示.
从图3中可以看出,在数据记录较少的情况下,CBLOF方法的时间效率略高于改进的CBLOF方法,但是数据集的增大,改进的CBLOF方法的性能得以体现.改进的CBLOF方法,在使用原有数据集训练模型达到稳定的情况下,新记录到来,不需要重新训练模型,直接判断新记录所属的簇,减少了重新训练模型的开销,同时,只有当记录属于标记为S的簇,才立即更新该簇所有记录的lof值,若是属于标记为L的簇,则达到指定阈值,才进行更新,也极大地减小了更新lof值的开销.
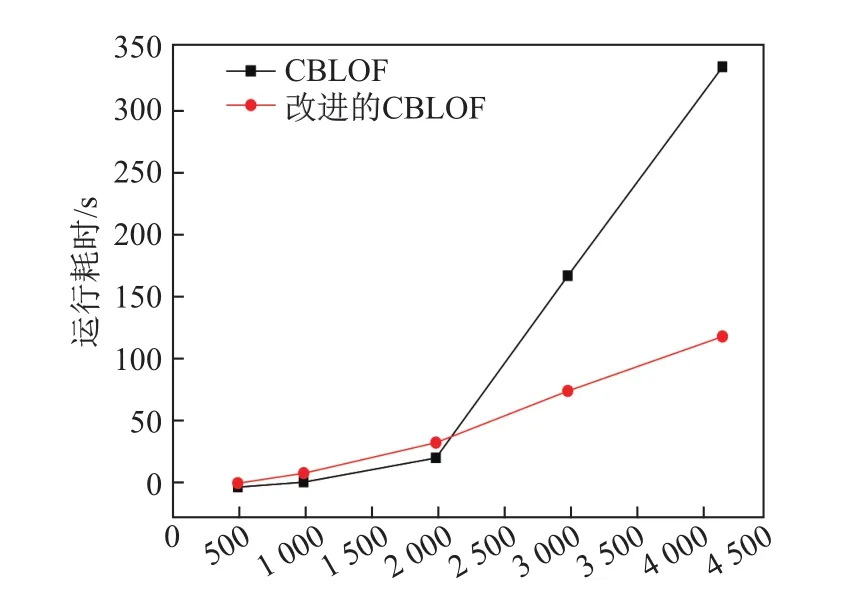
图3 时间消耗对比图Fig.3 Comparison of time cost
4.2.3 基于规则的异常检测方法
对同一个患者在一个月内的就诊记录进行分析,总共得到663 499条记录,其中在一个月内住院次数超过3次的总共有675条;对同一个患者在同一家医院的住院记录进行分析,总共得到402 018条记录,其中住院分解记录有621条.这些违反规则的记录,将提交给审核人员进行最后的筛选.住院记录中存在的频繁就医和分解住院两种情况检测的结果如表4所示.

表4 频繁就医和分解住院检测结果Tab.4 Results of frequent hospitalization and hospitalization decomposition detection
对分解住院记录汇总分析可得,检测到分解住院的行为有4 273例,其中存在患者在同一家医院就诊时,分解住院行为总次数高达33次.同时,通过分析发现,分解住院的行为发生在三级医院和二级医院的情况相对较多.这也不难理解,一般在三级、二级医院住院费用相对较高,分解住院行为自然成为医院回避超额医保费用的手段.表5展示了出现分解住院行为次数最多的医院,如医疗机构编号为8C78D9FC2943A和医疗机构编号为018FF7841008E的医院分解住院次数分别高达1 287次和1 261次,分别占所有分解住院行为的30.19%和29.5%,可见这两个医院分解行为的发生非常频繁,需要加大对这两个医院的监督力度.

表5 分解住院行为检测Tab.5 Results of hospitalization decomposition detection
4.3 系统界面展示
本节中对MIFS系统界面进行展示,主要分为透视分析和欺诈行为检测两个模块.图4给出了腰椎间盘突出患者住院记录中,可能存在欺诈行为的记录的详细信息,以供医保审核人员进行审查,对是否具有欺诈行为进行最终的判断.

图4 费用支出异常模块系统界面Fig.4 The interface of the details of abnormal fees
4.4 透视分析
透视分析是excel中比较常见的数据分析方法,对于一张二维表,根据业务需求,对表中相应的字段进行分类汇总的过程,被形象地称为透视分析.本系统中,主要进行两方面透视分析工作.①费用支出的透视分析,包括从区县、医院、病种和药品等不同维度对医保费用的支出情况进行细节的分析.②异常检测结果的透视分析,得出异常聚集的特点,从而可以有效地减少欺诈行为的发生.本系统中基于透视分析的结果,通过目前比较流行的Echarts来进行结果的展示.
从基于CBLOF和改进的CBLOF方法对腰椎间盘突出患者住院记录异常检测的结果中提取前10%的记录,异常记录属于各个等级医院的分布情况如图5所示,从图5可以看出,异常记录属于社区医院的记录数最多.鉴于社区医院的统筹支付报销起付线低,且报销比例较高,与此同时,对于社区医院的监督制度相对于三级医院来说,尚未完善,所以欺诈行为更容易发生.为了加强反欺诈行为的发生,加强对社区医院的管理必不可少.
5 总结与展望
本文基于对医保行为进行监督,减少医疗欺诈行为发生的需求,提出了医保基金监督平台MIFS.MIFS对医保机构提供的2006–2015年的费用支出数据进行透视分析,同时使用基于CBLOF和改进的CBLOF方法,对医保数据中的异常费用支出进行检测;使用基于规则的异常检测方法对于频繁就医以及分解住院进行检测.未来的工作包括以下两个方面:

图5 各个等级医院异常费用检测频次分布情况Fig.5 Frequency distribution of abnormal fees of di ff erent hospital level
[1]SHI Y,SUN C,LI Q,et al.A fraud resilient medical insurance claim system[C]//Thirtieth AAAI Conference on Artif i cial Intelligence.USA:AAAI Press,2016:4393-4394.
[2]XIE Z P,LI X Y,WU W Y,et al.An improved outlier detection algorithm to medical insurance[J].IDEAL, 2016:436-444.
[3]DIONNE G,GAGN´e R.Replacement cost endorsement and opportunistic fraud in automobile insurance[J]. Journal of Risk&Uncertainty,2002,24(3):213-230.
[4]SKIBA J M.A phenomenological study of the challenges and barriers facing insurance fraud investigators[J]. Journal of Insurance Regulation,2013:131-136.
[5]KRAUSE J H.A patient-centered approach to health care fraud recovery[J].Journal of Criminal Law&Criminology,2006,96(2):579-619.
[6]LORENZ F A.Healthcare fraud in the United States:Assessing current policy and its role in fraud prevention[J]. California State University Northridge,2013:221-227.
[7]李亮.基于成本-收益理论的社会医疗保险欺诈问题研究[D].长沙:湖南大学,2011.
[8]王明慧,陶四海.我国大病医疗保险实施的影响因素分析[J].经营管理者,2013,21:298-298.
[9]夏宏,汪凯,张守春.医疗保险中的欺诈与反欺诈问题[J].现代预防医学,2007,34(20):3907-3908.
[10]COHEN W W.Fast ef f ective rule induction[J].Machine Learning Proceedings,1995,46(2):115-123.
[11]BIAFORE S.Predictive solutions bring more power to decision makers[J].Health Management Technology,1999, 20(10):12.
[12]MARCUSNEWHALL A,HALPERN D,TAN S J.Healthcare and data mining[J].Health Management Technology,2000.
[13]高臻耀,张敬谊,林志杰,等.一个医保基金风险防控平台中的数据挖掘技术[J].计算机应用与软件,2011,28(8):120-122.
[14]ROBERTS S J,PENNY W,PILLOT D.Novelty,conf i dence and errors in connectionist systems[C]//Intelligent Sensors.[S.l.]:IET,1996:10/1-10/6.
[15]BREUNIG M M,KRIEGEL H P,NG R T,et al.OPTICS-OF:Identifying local outliers[J].Lecture Notes in Computer Science,1999,1704:262-270.
[16]黄洪宇,林甲祥,陈崇成,等.离群数据挖掘综述[J].计算机应用研究,2006,23(8):8-13.
[17]LIU B,YIN J,XIAO Y,et al.Exploiting local data uncertainty to boost global outlier detection[C]//IEEE International Conference on Data Mining.[S.l.]:IEEE Computer Society,2010:304-313.
[18]ESTER M,KRIEGEL H P,XU X.A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]//International Conference on Knowledge Discovery and Data Mining.USA:AAAI Press,1996:226-231.
[19]NG R T,HAN J.Effi cient and ef f ective clustering methods for spatial data mining[C]//International Conference on Very Large Data Bases.San Francisco:Margan Kaufmann,1994:144-155.
[20]ZHANG T,RAMAKRISHNAN R,LIVNY M.BIRCH:An effi cient data clustering method for very large databases[J].ACM SIGMOD Record,1999,25(2):103-114.
[21]SUN C F,SHI Y L,LI Q I,et al.A hybrid approach for detecting fraudulent medical insurance claims:(Extended abstract)[C]//Proceedings of the 2016 Interational Conference on Autonomous)Agents&Multiagent Systems. Singapore:IFAAMS,2016:1287-1288.
[22]MOYANO L G,APPEL A P,SANTANA V F D,et al.GraPhys:Understanding health care insurance data through graph analytics[C]//International Conference Companion on World Wide Web.[S.l.]:International World Wide Web Conferences Steering Committee,2016:227-230.
[23]BAUDER R A,KHOSHGOFTAAR T M.A novel method for fraudulent medicare claims detection from expected payment deviations(Application Paper)[C]//IEEE,International Conference on Information Reuse and Integration.[S.l.]:IEEE,2016:11-19.
[24]关皓文.基于离群点检测方法的医保异常发现[D].济南:山东大学,2016.
[25]HE Z,XU X,DENG S.Squeezer:An effi cient algorithm for clustering categorical data[J].Journal of Computer Science and Technology,2002,17(5):611-624.
(责任编辑:张晶)
Fraudulent medical behavior detection based on hybrid approach
PAN Song-song,ZHANG Wei-jia
(School of Computer Science and Software Engineering,East China Normal University, Shanghai 200062,China)
With continuous improvement of medical insurance system,coverage of medical insurance continues to expand.The normal operation of medical insurance funds has been closely related with the vital interests of the people.However,frequent occurrence of fraudulent behaviors such as frequent hospitalization,hospitalization decomposition, abnormal fees threaten the normal operation of funds.This paper f i rstly used random forest method to select dif f erent features according to dif f erent diseases.Then the paper applied CBLOF-based and improved CBLOF methods to detect abnormal fees.What’s more,we utilized rule-based method to identity frequent hospitalization and hospitalization decomposition.Extensive experiments on real medical claim datasets demonstrate the ef f ectiveness and effi ciency of our proposal.Finally,this paper proposed a medical insurance fund supervisory system,which can display results of pivot analysis with the help of Echarts.
outlier detection;local outlier factor;CBLOF;hospitalization decomposition
TP311
A
10.3969/j.issn.1000-5641.2017.05.012
1000-5641(2017)05-0125-13
2017-06-20
国家重点研发计划(2016YFB1000904)
潘松松,女,硕士研究生,研究方向为数据挖掘.E-mail:pss ahnu@163.com.
