基于近红外光谱技术的抹茶掺伪定性判别研究
2017-09-21,,,,
,, , ,
(安徽农业大学茶树生物学与资源利用国家重点实验室,安徽合肥 230036)
基于近红外光谱技术的抹茶掺伪定性判别研究
赵开飞,王敬涵,张惠,黄萧,刘政权*
(安徽农业大学茶树生物学与资源利用国家重点实验室,安徽合肥 230036)
本实验采用近红外光谱技术与主成分分析法结合线性判别分析法(PCA-LDA)和K最邻近法,对抹茶中添加白砂糖、麦芽糊精、桑叶粉、大麦苗粉的现象进行定性判别分析。结果显示,PCA-LDA的定性判别结果优于K最邻近法,纯抹茶与掺伪抹茶、纯抹茶与掺糖抹茶、纯抹茶与掺糊精抹茶、纯抹茶与掺桑叶粉抹茶、纯抹茶与掺大麦苗粉抹茶、4种掺伪抹茶的定性分析模型的校正集识别率为98.3%、100%、91.7%、100%、100%、100%;预测集识别率为96.5%、100%、87.5%、95.8%、90.3%、95.3%。由此可知,通过PCA-LDA建立的定性判别模型准确度和识别率都很好,能够快速、准确的对抹茶中是否掺伪进行定性判别。
抹茶,近红外光谱,品质判别,主成分分析,线性判别分析,K最邻近法
抹茶,即采用覆盖栽培的茶树鲜叶经蒸汽(或热风)杀青后、干燥制成的叶片为原料,经研磨工艺加工而成的微粉状茶产品[1-2]。因而它最大限度地保持了绿茶原有的天然绿色以及营养、药理成分,有很强的表面吸附力及亲和力、固香性及良好的悬浮稳定性等特性,特别容易被肠胃消化吸收,并广泛应用于奶制品、冷食、烘焙、豆制品、饮料、保健食品、日化产品等诸多行业[3-5]。近年来,随着哈根达斯、星巴克、伊利等知名企业在中国推出了抹茶口味的冰激凌、抹茶星冰乐、抹茶拿铁、抹茶巧克力等食品,抹茶逐渐在市场上流行起来[6]。因抹茶具有良好的经济效益,而致使市场上的抹茶产品良莠不齐,出现了往抹茶中添加非茶成分,或以次充好的现象,其中市场上抹茶中常见的添加物有白砂糖、麦芽糊精、桑叶粉、大麦苗粉、小球藻等。这不仅损害了消费者的权益,也扰乱了中国抹茶市场秩序。因此,这就需要寻找一种快速有效的方式来辨别抹茶掺伪,为规范中国抹茶市场秩序提供一种有效手段。
近红外光谱技术是近年来发展较快的一种绿色、无污染、快速、无损检测技术,其广泛应用于农产品、食品领域和茶叶的品质检测分析[7-8]。近红外光是指波长在780~2526 nm(波数在12500~4000 cm-1)范围内的电磁波,主要反映含氢基团振动的倍频和组合频吸收,几乎涵盖了有机物中所有含氢的信息[9-10]。近红外光谱技术在食品真伪掺假判别上得到广泛应用[11],至今,其已被广泛用在肉类[12-13]、植物油[14-15]、牛奶[16-17]、蜂蜜[18-19]、奶粉[20-21]等食品的掺伪鉴别。
近红外光谱的定性分析主要是利用已知样或标准样来判定未知样品的归属,即定性模型可以用来判断研究对象的真假、等级、产地以及类别等[22]。其中定性分析方法根据实际情况应用过程有所差别,但其一般步骤可分为标准(参考)样品光谱集的建立、光谱的预处理及校正、光谱特征提取、定性判别模型的建立和验证、未知样品定性分析[23]。本实验以玉露碎为研究对象,掺入不同比例的白砂糖、麦芽糊精、桑叶粉、大麦苗粉,探索了采用近红外光谱分析方法结合主成分分析与线性判别分析和K最近邻法判别抹茶添加非茶成分的可行性。
1 材料与方法
1.1材料
玉露碎、桑叶粉、大麦苗粉 浙江绍兴御茶村茶叶有限公司;白砂糖 购于合肥家乐福超市;麦芽糊精 上海南季生物有限公司。
1.2仪器设备
行星式球磨机 湖南长沙米淇仪器设备有限公司;AR224CN分析天平 奥豪斯仪器(上海)有限公司;MPA型傅里叶变换近红外光谱仪 德国Bruker光谱仪器公司,扫描范围为12500~4000 cm-1,分辨率4 cm-1,扫描次数为32次;OPUS 6.5光谱采集分析软件和Matlab2014数据处理软件。
1.3实验方法
1.3.1 样品制备 在添加两种非茶成分白砂糖和麦芽糊精时,按1%的梯度添加到玉露碎茶叶中,添加范围在0~30%之间,并使用行星式球磨机制备成掺伪抹茶。将制备好的茶粉样品分别装入小塑料自封袋中封口,从每种样品中称取10 g茶粉放入样品杯中,每种比例做3个平行,分别获得添加白砂糖和麦芽糊精抹茶样品93个,共计186个样品。
在添加桑叶粉时,其添加量为0~10%,以1%的梯度添加,12%~50%,以2%的梯度添加,55%~100%,以5%的梯度添加至玉露碎茶叶中制备成掺伪抹茶,每个梯度样品做3个平行,共计123个样品。
在添加大麦苗粉时,其添加量为0~10%,以1%的梯度添加,12%~50%,以2%的梯度添加,52.5%~100%,以2.5%的梯度添加至玉露碎茶叶中制备成掺伪抹茶,每个梯度样品做3个平行,共计153个样品。
由玉露碎制备的纯抹茶样品30个并扫描光谱和4组掺伪抹茶中0%的抹茶样品12个,共计42个纯抹茶样品。
1.3.2 样品光谱采集 利用MPA型傅里叶变换近红外光谱仪对样品进行光谱扫描,样品以称取10 g为准放入样品杯,以保证实验数据的稳定可靠。样品杯以0°、120°和240°旋转3次扫描光谱,然后利用以光谱以配套的OPUS 6.5光谱采集分析软件对扫描的光谱取平均值,作为该样品的原始光谱。
1.3.3 调用光谱 从原始近红外光谱库中导出42条原抹茶近红外光谱,150条掺伪抹茶近红外光谱(依次将每种浓度梯度的掺伪抹茶平均光谱得到),实验样品分布见表1,其近红外光谱图如图1。将192个样本分为校正集和验证集,分组结果见表2,其中校正集128个样本用于原料肉和掺假肉两类判别模型的建立,验证集64个样本则用来评价模型的有效性。

表1 实验样品分布Table 1 Distribution of test samples

表2 校正集与预测集样品分布Table 2 Sample distribution of calibration set and prediction set
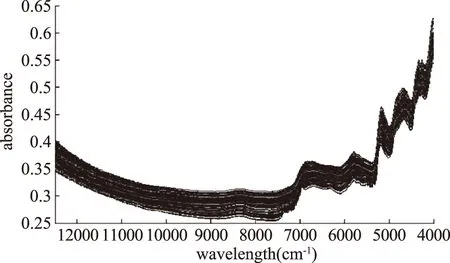
图1 192个样品光谱原始图Fig.1 The original spectra of 192 samples
2 结果与分析
纯抹茶与掺伪抹茶判别模型的建立由于实验采集的光谱(42条原抹茶光谱和150条掺伪抹茶光谱)在4000~12500 cm-1波数范围内共有2202个数据点,包含的信息量大,其中还有很多无用信息,与样品的组分和性质缺乏相关性,分析量大。因而需要利用Matlab2014软件对庞大的信息数据用主成分分析进行降维,特征提取。然后利用提取的有效特征参数进行线性判别分析。经过分析,各组掺伪抹茶的前三主成分的累积贡献率达到0.9以上,当主成分的累积贡献率达到0.85以上就能代表原始信息的绝大部分信息,因而其能够满足建模需求[24]。
图2为192个样品前3主成分在三维空间经过视觉旋转后得分分布情况图,从图中可以看出,通过主成分分析法就能够较好的把纯抹茶和掺伪抹茶区分开来,掺伪抹茶主要分布在Z轴上以-0.1为横轴的上半部分,纯抹茶主要集中在其下半部分,并主要分布在Y轴的负半轴。模型的识别率如表5所示,校正集为98.3%,预测集为96.5%,这说明主成分分析结合线性判别分析(PCA-LDA)能够较好的对抹茶的掺伪进行判别。此外,纯抹茶与掺伪抹茶进行两两判别和抹茶掺伪种类间的区分结果表明,PCA-LDA能够较好的实现抹茶掺伪的定性判别。

图2 192个样本前三主成分三维得分图Fig.2 192 samples of the first three principal components of the three-dimensional score chart
图3是经过视觉转换后的四种掺假抹茶前两个(PC1,PC2)主成分分布图,从图中可以看出,添加白砂糖、麦芽糊精、桑叶粉、大麦苗粉的4种抹茶通过主成分分析法能够将它们区别出来,进一步采用线性判别分析分析建立识别模型,模型的校正集和预测集识别率分别为100%、95.3%,由此可以得出,PCA-LDA能够实现4种掺伪抹茶的识别。
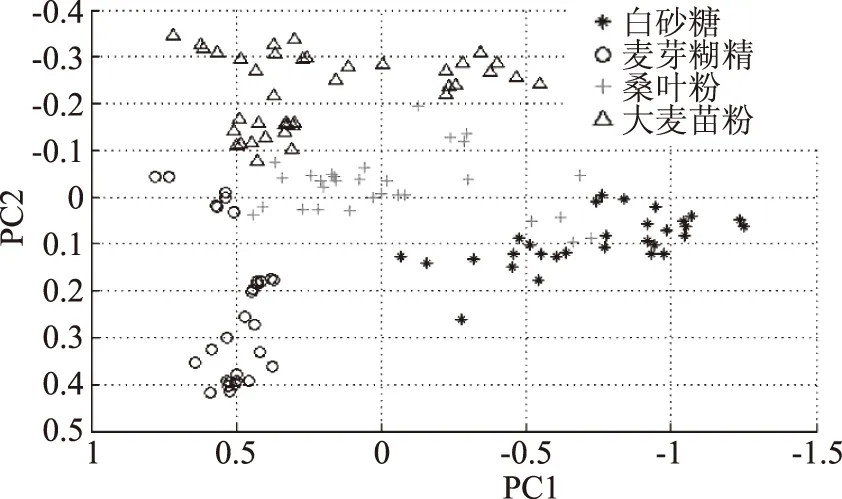
图3 4种掺伪抹茶前两个主成分得分图Fig.3 First two principal component score plot of 4 kinds of adulteration of matcha
从通过视觉旋转后的图4~图7中可以看出,主成分分析法能够把各掺伪抹茶与纯抹茶很好的区分开来,进一步的模式识别即通过线性判别分析(LDA)建立识别模型,其中校正集和预测集的识别率如表4所示表明,通过PCA-LDA建立识别模型可以有效的对掺伪抹茶进行识别。
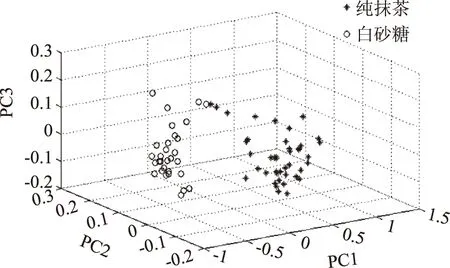
图4 纯抹茶与掺白砂糖抹茶前三主成分三维得分图Fig.4 First three principal component score plot 3D of pure and mixed matcha

图5 纯抹茶与掺麦芽糊精抹茶前三主成分三维得分图Fig.5 First three principal component score plot 3D of pure and addition of maltodextrin matcha
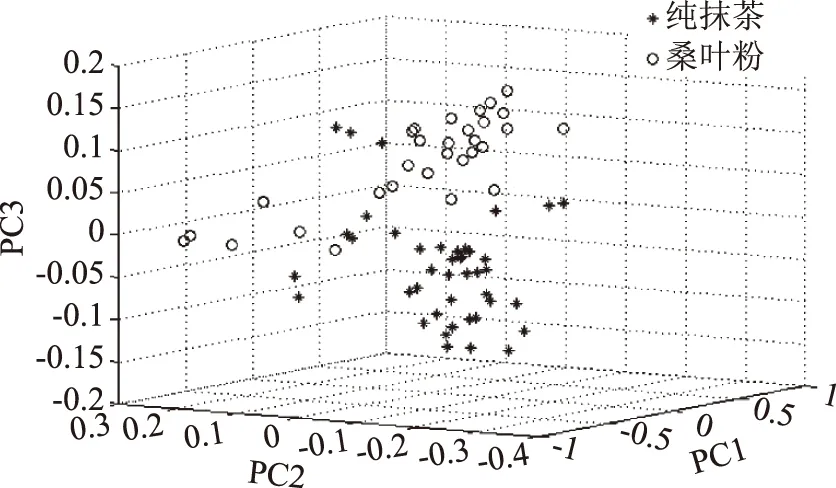
图6 纯抹茶与掺桑叶粉抹茶前三主成分三维得分图Fig.6 First three principal component score plot 3D of pure and addition of mixing ratio of mulberry leaf powder matcha
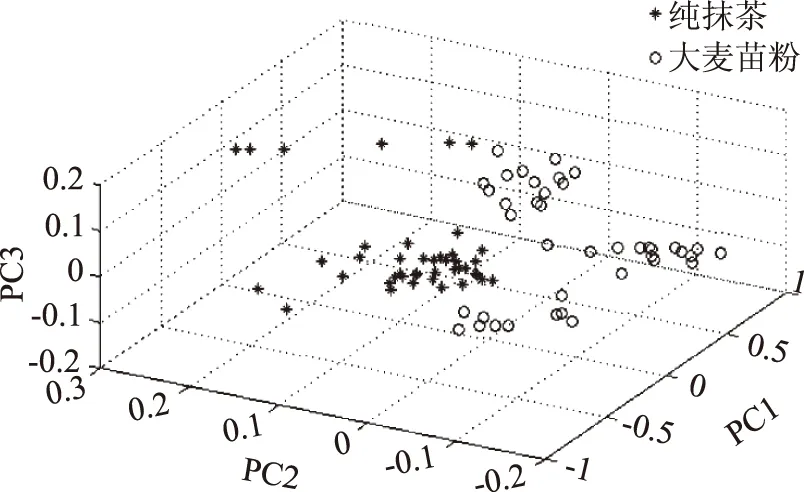
图7 纯抹茶与掺大麦苗粉抹茶前三主成分三维得分图Fig.7 First three principal component score plot 3D of pure and addition of mixed ratio of barley seedling powder matcha
在对抹茶掺伪的定性判别分析研究中,本实验主要采用主成分分析法结合线性判别分析法(PCA-LDA)和K最邻近法。在使用K最邻近法进行判别时,选取的主成分数对模型的判别结果有很大影响,需对其作优化处理。此外,样本间的距离K的选取也会对模型的判别结果有影响,也要作优化处理,因而实验中选取了前10个主成分数和10个K值,K值以奇数选取,同时对KNN模型进行优化,优化以校正集和预测集的识别率为判断标准[25],优化后的实验结果如表3所示。
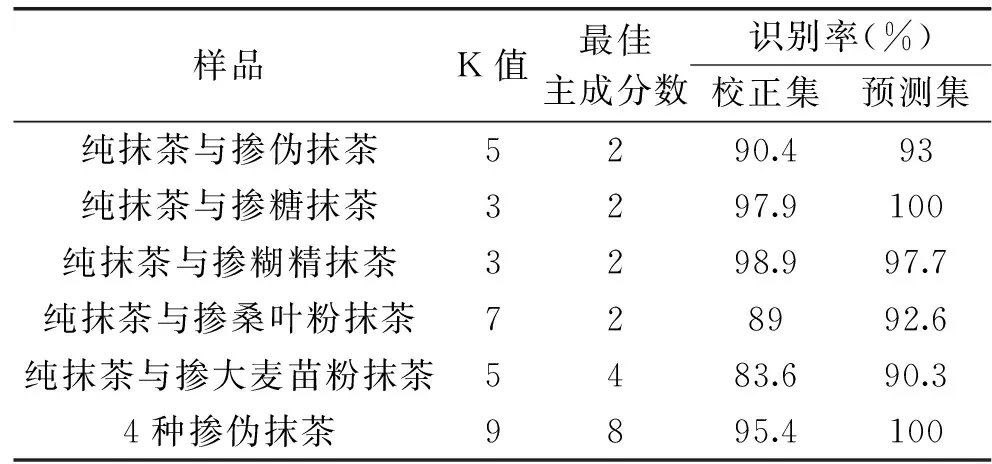
表3 K-NN模型识别抹茶掺伪结果Table 3 K-NN model to identify the adulteration of the matcha
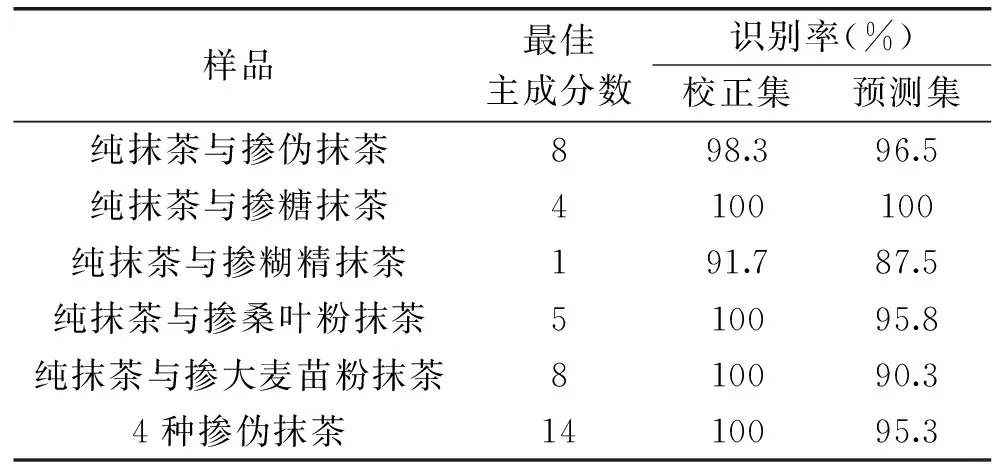
表4 PCA-LDA模型识别抹茶掺伪结果Table 4 PCA-LDA model to identify the adulteration of the matcha
由表3可知,通过K最近邻法分别对纯抹茶与几种掺伪抹茶的判别结果表明:K最近邻法与主成分析法结合线性判别分析可以有效识别纯抹茶与掺伪抹茶、掺糖抹茶、掺糊精抹茶、掺桑叶粉抹茶、掺大麦苗粉抹茶以及识别掺伪的种类,其中掺糖和糊精的抹茶校正集和预测集的识别率要明显高于掺桑叶粉和大麦苗粉的,由表4主成分析法结合线性判别分析法也能够对纯抹茶与几种掺伪抹茶进行有效识别,其中主成分析法结合线性判别分析法对掺假、掺糖、桑叶粉、大麦苗粉的抹茶的校正集和预测集识别率要高于K最邻近法的识别,综合来看,PCA-LDA模型识别抹茶掺伪结果优于K最邻近法的结果。
3 结论
本实验采用近红外光谱技术结合主成分分析和线性判别分析(PCA-LDA)、K最近邻法对纯抹茶与掺伪抹茶建立定性判别分析来判别抹茶是否掺伪和掺伪类型,通过比较,在纯抹茶与掺伪抹茶、纯抹茶与掺糖抹茶、纯抹茶与掺桑叶粉抹茶、纯抹茶与掺大麦苗粉抹茶的定性分析模型中PCA-LDA的结果优于K最近邻法,而纯抹茶与掺麦芽糊精抹茶则是K最近邻法较好,综合而言,选取PCA-LDA作为抹茶掺伪的定性判别分析方法。纯抹茶与掺伪、掺糖、掺桑叶粉、掺大麦苗粉、4种掺伪抹茶、掺糊精抹茶的校正集识别率为98.3%、100%、100%、100%、91.7%;预测集识别率96.5%、100%、95.8%、90.3%、95.3%、87.5%。由此可知,通过PCA-LDA建立的定性判别模型准确度和识别率都很高,其能够快速、准确的对抹茶中是否掺伪进行定性判别。
[1]刘东娜,聂坤伦,杜晓,等. 抹茶品质的感官审评与成分分析[J]. 食品科学,2014,35(2):168-172.
[2]尹春英,刘乾刚. 抹茶溯源及其利用[J]. 茶叶科学技术,2008(2):13-15.
[3]李翔、许彦.抹茶制品开发研究进展[J].饮料工业,2013,16(6):13-15.
[4]徐睿瑶,李宏远. 日本抹茶的发展概况及其与中医茶疗的关系[J]. 世界中西医结合杂志,2016,11(9):1309-1310.
[5]李徽,李春方,任静,等. 遮阴时间对抹茶及其加工蛋糕品质的影响[J]. 上海师范大学学报:自然科学版,2014,43(6):573-577.
[6]张一洁.中国末茶文化研究[D].上海:华东师范大学,2014
[7]李雪明. 近红外光谱分析技术在农产品食品品质在线无损检测中的应用研究进展[J]. 科学与财富,2015(26):153-153.
[8]于英杰,孙威江. 近红外光谱及高光谱技术在茶叶上的应用[J]. 亚热带农业研究,2014,10(4):269-273.
[9]周小芬,叶阳,陈芃,等. 近红外光谱技术在茶叶品质评价中的研究与应用[J]. 食品工业科技,2012,33(5):413-417.
[10]王小燕,王锡昌,刘源,等. 近红外光谱技术在食品掺伪检测应用中的研究进展[J]. 食品科学,2011,32(1):265-269.
[11]张玉华,孟一,张应龙,等. 近红外光谱技术在食品安全领域应用研究进展[J]. 食品科技,2012(10):283-286.
[12]Ding H B,Xu R J. Near-infrared spectroscopic technique for detection of beef hamburger adulteration.[J]. Journal of Agricultural & Food Chemistry,2000,48(6):2193-8.
[13]Mohanty B P,Barik S,Mahanty A. Food safety,labeling regulations and fish food authentication[J]. National Academy Science Letters,2013,36(3):253-258.
[14]彭星星,陈文敏,乔茜华,等. 近红外光谱技术鉴别核桃油中掺入菜籽油、大豆油及玉米油的研究[J]. 中国粮油学报,2015(12):106-113.
[15]张亦婷,刘翠玲,位立娜. 基于光谱技术的芝麻油掺假定性分析研究[J]. 食品科技,2016(9):257-261.
[16]金垚,杜斌,智秀娟. NIR技术快速鉴定牛奶品牌与掺假识别[J]. 食品研究与开发,2016,37(3):178-181.
[17]倪力军,钟霖,张鑫,等. 近红外光谱结合非线性模式识别方法进行牛奶中掺假物质的判别[J]. 光谱学与光谱分析,2014(10):2673-2678.
[18]Shui-Fang L I,Shan Y,Zhu X R,et al. Detection of honey adulteration by addition of maltose syrup using near-infrared transflectance spectroscopy[J]. Food Science & Technology,2010.
[19]Huang L,Liu H,Zhang B,et al. Application of electronic nose with multivariate analysis and sensor selection for botanical origin identification and quality determination of honey[J]. Food and Bioprocess Technology,2015,8(2):359-370.
[20]徐玲玲,李卫群,朱慧,等. 近红外光谱法检测奶粉掺假[J]. 食品安全质量检测学报,2016,7(8):3133-3137.
[21]王宁宁,申兵辉,关建军,等. 近红外光谱分析技术识别奶粉中淀粉掺假的研究[J]. 光谱学与光谱分析,2015(8):2141-2146.
[22]刘伟. 基于光谱信息的模型辨识方法研究[D]. 北京:北京化工大学,2014.
[23]严衍禄,陈斌,朱大洲.近红外光谱分析的原理、技术与应用[M].北京:中国轻工业出版社,2013.83-84.
[24]杨志敏. 应用近红外光谱技术快速检测原料肉新鲜度及掺假的研究[D]. 咸阳:西北农林科技大学,2011.
[25]赵杰文,林颢.食品、农产品检测中的数据处理和分析方法[M].北京:科学出版社,2012.164-165.
Qualitativediscriminationofadulterationinmatchabasedonnearinfraredspectroscopy
ZHAOKai-fei,WANGJing-han,ZHANGHui,HUANGXiao,LIUZheng-quan*
(State Key Laboratory of Tea Plant Biology and Utilization,Anhui Agricultural University,Hefei 230036,China)
In this experiment,near infrared spectroscopy and principal component analysis combined with linear discriminant analysis method and K-nearest neighbors was used to qualify the qualitative discriminant analysis on the phenomenon of matcha added sugar,maltodextrin,mulberry leaf powder,barley seedling powder.The results showed that the qualitative judgment of PCA-LDA was superior to K nearest neighbor method. Pure matcha and fake matcha,pure matcha and matcha adulterated white sugar,pure matcha and matcha adulterated maltodextrin,pure matcha and matcha adulterated mulberry leaf powder,pure match and matcha adulterated barley flour,four kinds of fake matcha,the calibration set recognition rate of qualitative analysis model were respectively 98.3%,100%,91.7%,100%,100%,100%,and the predictive set recognition rate were 96.5%,100%,87.5%,95.8%,90.3%,95.3%,respectively. It can be seen that the models had very good precision and stabilization and they could quickly and accurately discriminate whether matha was adulterated.
matcha;near infrared spectroscopy;quality identification;principal component analysis;linear discriminant analysis;K-nearest neighbors
2017-03-03
赵开飞(1990-),男,硕士研究生, 研究方向:茶叶资源综合利用,E-mail:461127635@qq.com。
*通讯作者:刘政权(1975-),男,硕士,副教授,研究方向:茶叶资源综合利用,E-mail:liuzq0312@163.com。
浙江省重大科技专项(2017C02037)项目资助;安徽特色农业发展项目(皖财农[2016]188号)。
TS207.3
:A
:1002-0306(2017)17-0241-05
10.13386/j.issn1002-0306.2017.17.046
