SVM+模型中可用信息用作特权信息
2017-09-19董勇孙广玲刘志
董勇,孙广玲,刘志
(上海大学通信与信息工程学院,上海200444)
SVM+模型中可用信息用作特权信息
董勇,孙广玲,刘志
(上海大学通信与信息工程学院,上海200444)
在机器学习中,当测试阶段无法得到训练阶段拥有的特权信息时,特权学习(learning using privileged information,LUPI)是一个有效的解决框架.由于获取特权信息需要特殊的条件,或由于其他原因,往往不能获得全部训练样本的特权信息,因此提出了一种直观却有效的方法.对于缺失特权信息的这部分训练样本,将它们的可用信息同时用作特权信息,并将其纳入到支持向量机(support vectormachine+,SVM+)的模型中,引入了一种新的扩展SVM+(extended SVM+,eSVM+)模型.进一步地,对于不涉及特权信息的常规有监督学习问题,也将训练样本的特征(可用信息)同时用作特权信息,引出一种新的扩展SVM模型(eSVM),eSVM也可认为是SVM+的特例.在两个公开的人脸表情数据库BU-3DFE和Bosphorus上进行了实验,结果证实了将可用信息用作特权信息策略的有效性.
特权学习;可用信息;特权信息;支持向量机
利用特权信息的学习(learning using privileged information,LUPI)是机器学习领域发展较快的一个方向[1-2],其意图在于模仿人类“教”与“学”中的一个重要现象:在学生的学习阶段,一个好的教师除了提供实例,还要提供相关的其他信息,而这些信息是在非学习阶段(学生利用学习得来的知识独立解决问题而不再依赖于教师)不可获得的,因此称为特权信息.在学习阶段提供特权信息的意义是,相对于只提供实例,可以使学生获得更丰富的知识,从而提高其未来独立解决问题的能力.相应地,可以构建体现类似思想的机器学习模型,以使学习得来的模型拥有更强的泛化能力.
假设提供了m个训练样本,训练样本的特征和相应的类别标记构成的集合用
表示,其中xi表示第i个样本的特征,yi表示第i个样本的类别标记.在识别阶段可以得到测试样本的特征x,利用学习得来的模型,预测其类别标记y.这类学习的特点是在学习和测试中得到的信息是对称的.而对于特权学习,在学习阶段,除了xi和yi之外,还可以获得额外的特权信息,特权学习的训练样本集合是因此,特权学习在学习和测试中得到的信息是非对称的,属于非对称学习.但是非对称学习并不仅仅只有特权学习这一种方式,因为在测试阶段拥有比学习阶段更多信息的学习,也属于非对称学习[3].
在特权学习中,特权信息的作用是显著提高学习算法收敛于贝叶斯解的速度.本工作称特权学习中训练样本的特征x为可用信息.
1 相关工作
最早在LUPI框架下的模型是支持向量机(support vector machine+,SVM+)[2].自SVM+提出之后,无论是模型、算法还是应用方面,研究者们已在LUPI领域发表了很多研究成果.对比属于有监督学习的SVM+,文献[4]研究了利用特权信息的无监督聚类问题,并将其应用于金融领域的预测模型[5].文献[6]给出了特权经验风险最小化相对于常规经验风险最小化可获得更快收敛速度的理论分析.文献[7]提出了基于信息理论的度量学习(information-theoreticmetric learning+,ITML+),试图用特权信息修正可用信息空间中每一对训练样本的损失,并应用于RGBD(red,green,blue,depth,红、绿、蓝、深度)中的人脸认证和身份重认证.文献[8]提出了高斯过程分类(Gaussian process classification+,GPC+),特权信息被看作GPC隐函数中的噪声,从而能较好地用于评价可用信息空间中训练样本的可利用程度.文献[9]分析出SVM+的主要作用等效于在SVM的目标函数中,利用特权信息给出每个训练样本的权重.文献[10]提出基于结构SVM+(structural SVM+,SSVM+)的目标定位方法,对之前基于特权学习的模型仅用于分类的应用场景进行了扩展.类似地,文献[11]研究了利用特权信息的结构化输出条件回归森林算法,用于定位人脸的特征点.文献[12]强调有相对排序关系的属性可作为特权信息.文献[13]分析了特权信息学习属性排序对于提升分类器性能的作用,而这相对排序关系是基于一定的学习模型得到,恰好可与SVM+的模型一致,形成一个整体.
上述研究无一不在强调特权信息的作用,但更多的研究目的是比较训练样本在有无特权信息时,分类器性能的差异.然而存在另一方面的问题是,由于获取方法的特殊性,或者获取的成本较高,或者其他多种原因,在很多现实应用中,不仅测试样本无法得到特权信息,即使对于训练样本,也仅是部分才拥有特权信息.对于此种情况,已有研究仅仅是提供了相对简单的处理方法[2,7].同时,基于SVM+的框架,是否可将用于有监督学习的SVM扩展,从而在形式上与SVM+统一起来?本工作针对上述两个问题,提出将可用信息用作特权信息,从而有效提高仅有部分特权信息的SVM+和用于有监督学习的SVM的泛化能力.
2 SVM和SVM+
SVM在对偶空间中最大化的目标泛函为

满足约束:

式(1)~(3)中,αi,i=1,2,···,n为Lagrange乘子,K为决策空间的核函数,C为正则参数, xi和yi分别表示第i个训练样本的特征和类别.
SVM+在对偶空间中最大化的目标泛函为

满足约束:

式(4)~(7)中,αi,βi,i=1,2,···,n为Lagrange乘子,K和K∗分别表示基于可用信息决策空间的核函数,以及用于预测松弛变量的基于特权信息的修正空间的核函数,γ和C为正则参数,和yi分别表示第i个训练样本的可用信息、特权信息和类别.目标泛函(1)和(4)可根据问题的规模,用二次规划优化(quadratic programming solver)算法或是Pechyony等[14]提出的快速算法求解.前者适用于小规模问题,后者适用于中等规模和大规模问题[15].
在求出式(1)和(4)最大的︿αi,i=1,2,···,n和最优偏移︿b之后,即可采用以下的决策函数预测只有可用信息的测试样本的类别:

3 可用信息用作特权信息的相关模型和算法
根据文献[2]的分析可知,基于一定的训练样本集,Oracle function可给出最小的经验风险对应的松弛变量.而一个合适的特权信息可基于一定的修正函数用于预测训练样本的松弛变量.该松弛变量能以较高的概率逼近用O racle function给出的松弛变量,因此松弛变量的求解结果是关键因素.但在有些现实场景中,只有部分训练样本提供了特权信息或是当面对常规的有监督学习问题时,以下问题随之而来:是否存在一定的策略可以有效地弥补缺失特权信息的作用;该策略获得的经验风险是否可以较高的概率获得至少低于在决策空间中求解松弛变量产生的经验风险.本工作提出了一种直观而有效的方法:对于无特权信息的样本,“求助于”自身,即将可用信息看作一类特殊的特权信息,并将其纳入到SVM+的模型中.
3.1 可用信息用作特权信息的扩展SVM模型
当特权信息是可用信息时,SVM+即是eSVM.此时,目标泛函(4)中的成为约束不变.这里将该情况下对偶空间的目标泛函及约束重写为

满足约束:

因为是用于常规的有监督学习问题,该模型也可认为是SVM的一种扩展.
3.2 可用信息用作特权信息的扩展SVM+模型
Vapnik等[2]曾提到部分训练样本特权信息缺失的SVM+.为了与其进行比较,这里先列出Vapnik模型,然后再列出本工作的模型.
3.2.1 部分训练样本特权信息缺失的Vapnik模型
部分训练样本特权信息缺失的Vapnik模型为

满足约束:

式中,m表示无特权信息的样本数.Vapnik模型实际类似于SVM,是直接求解无特权信息训练样本的松弛变量.
3.2.2 扩展SVM+(eSVM+)模型
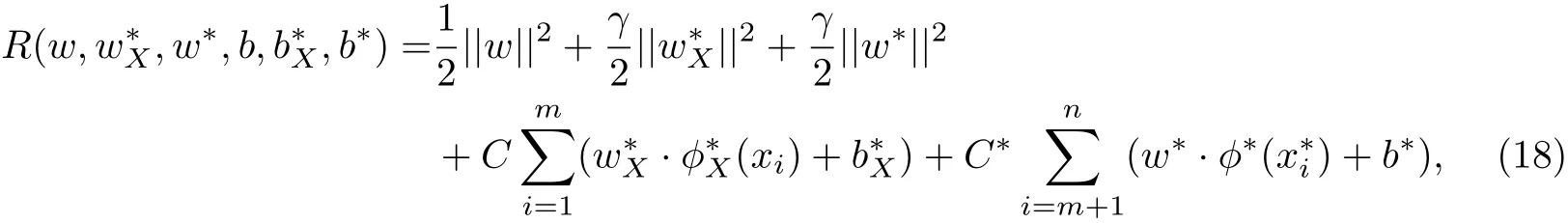
满足约束:

对偶空间中的目标泛函为

满足约束:
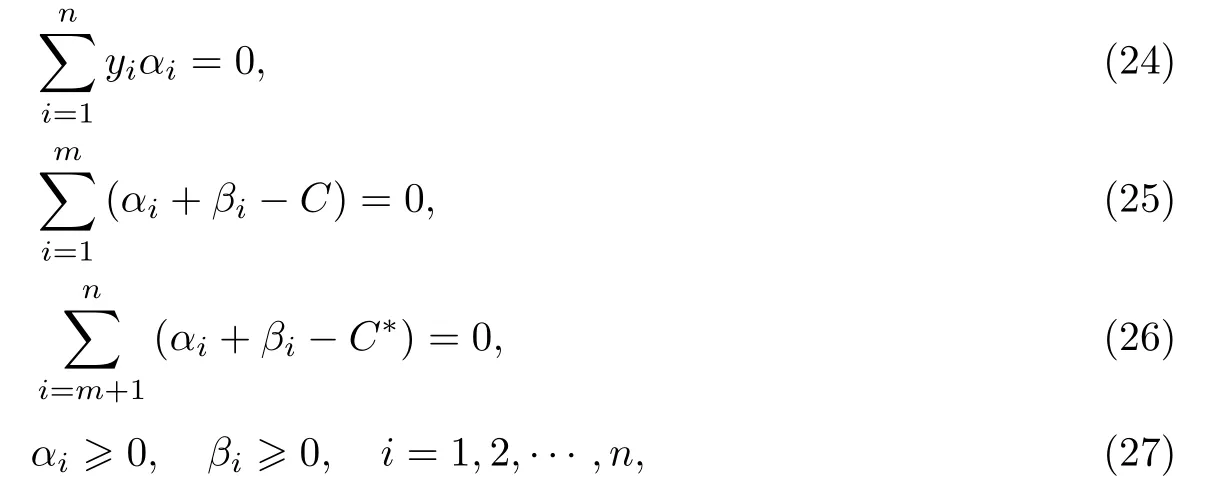
4 实验和分析
人脸面部表情识别是模式识别和计算机视觉中的经典问题,也是人机交互的重要方式之一[16].本工作结合该应用,对提出的方法进行实验和分析.值得指出的是,本工作并非关注提升表情识别的性能,而仅是表明将可用信息用作特权信息可获得的优势.
本工作利用了表情识别领域比较常用的两个公开数据库BU-3DFE和Bosphorus.图1和2分别是部分样本的示意图,其中第一行均为RGB图,第二行均为深度图,都包含了7种表情,依次为中性、愤怒、厌恶、恐惧、高兴、悲伤和惊讶,详细情况可参见文献[17-18].两个数据库的共同特点是,每个样本都有RGB和3D数据,因此可分别作为特权信息或可用信息.
碱洗过程控制液固比为10∶1,反应时间为1 h以上。碱洗完成后转化为黄色氧化铋,体积缩小,浆液变稀,Bi含量达到79.45%,可再进行酸化激活重复利用。

图1 BU-3DFE数据库样本示例Fig.1 Samples of BU-3DFE database

图2 Bosphorus数据库样本示例Fig.2 Samples of Bosphorus database
本工作从RGB和3D数据中分别计算出灰度图和深度图,然后从两幅图中提取局部二元模式(local binary pattern,LBP)特征[19],采取的是LBP模式.将灰度图和深度图划分成8×8共64个子区域,统计每个子区域59维的直方图并连接起来,从而形成两个3 776维的分别描述灰度图和深度图的统计特征,用gLBP和dLBP表示.
4.1 实验设置
虽然BU-3DFE样本包含7种表情,但遵循大部分研究的实验设置,本工作只测试了6种表情.从中抽取60个人的所有4种表情强度作为实验数据,并进一步将60人身份无交叠地划分为训练集(45人)、验证集(9人)、测试集(6人)共3个集合,其中训练集用于学习分类器,验证集用于参数的寻优.对于Bosphorus数据库,只测试正面和无遮挡的情况,但测试全部7种表情.从中抽取65个人的表情作为实验数据,也是身份无交叠地划分为训练集(30人)、验证集(20人)、测试集(15人).实验中所有涉及识别率的结果都为交叉验证20次的平均数据.
4.2 SVM和eSVM比较实验
本工作利用dLBP特征,观察和比较了SVM和eSVM对于表情分类的性能,结果如图3所示,其中“综合”表示所有表情的总识别率.分类器学习采用1个类别对其他所有类别的方式.表1是SVM和eSVM中参数的设置情况,这些参数由多次划分的验证集寻优而得.由图3可见,除了BU-3DFE中的“愤怒”和“悲伤”两种表情识别率有很微弱的下降外,eSVM相较于SVM,可获得稳定的性能提升.

图3 利用dLBP特征的SVM和eSVM的表情识别率Fig.3 Expression recognition accuracy corresponding to SVMand eSVMusing d LBP

表1 SVM和eSVM的参数设置Tab le 1 Parameters in SVMand eSVM
4.3 Vapn ik和eSVM+模型比较实验
结合本工作的实验对象,理论上来说,3D数据和RGB二者中的任何一个都可以作为可用信息,另外一个就成为特权信息.不仅要为它们找到实际的应用场景,而且也要结合两种信息各自的特点和SVM+的本质,在理论或者依赖经验数据的层面上来分析3D数据和RGB如何分配“角色”,以利于最终提高分类能力.对于应用场景的问题,3D数据和RGB都有可能成为特权信息.首先,高质量的3D数据要依赖于价格昂贵的3D扫描仪或者特殊的获取环境才能得到,因此将其看作只在学习阶段可获取和利用的特权信息是合理的.其次,即使在识别阶段可获得3D数据,但要同步得到RGB也是不容易的.若在二者中选择了3D,那么RGB就成了特权信息.至于二者中究竟哪一个更适合作为特权信息,哪一个更适合作为可用信息,本工作试图从表2中得到初步的结论.

表2 gLBP和d LBP各自和互为特权信息的识别率Tab le 2 Expression recognition accuracy using gLBP and dLBP as independent and privileged features %
表2中黑体的数字说明,在4个组合中,以dLBP为可用特征、gLBP为特权特征的组合获得了最高的识别率,自然也都高于无gLBP特权特征的识别率,并且这个结果在两个数据库中是一致的.因此可以认为,由于深度图直方图相对于灰度直方图具有更明显的稀疏性,使dLBP更适合用于决策,而gLBP更适合用于预测松弛变量.出于观察数据多样性的考虑,本工作选择在BU-3DFE数据库中,以gLBP为可用特征,dLBP为特权特征;在Bosphorus数据库中,以dLBP为可用特征,gLBP为特权特征.
本工作测试了特权信息占全部训练样本25%,50%和75%3种比例情况下的结果.事实上,在部分训练样本具有特权信息的问题中,学习方式共存在3种选择:只利用有特权信息的样本、利用全部样本和Vapnik模型、利用全部样本和eSVM+模型.表3和4中分别用“SVM+”“Vapnik”和“eSVM+”表示这3种方式,并列出了3种比例和3种方式下的识别率.
图4显示了3种比例特权信息和3种方式下的全部类别表情总的识别率,以及全部样本都有特权信息(100%)的SVM+结果.各方式中模型的具体参数设置如表5所示.同样地,这些参数也由多次划分的验证集寻优而得.
结合表3和4可以看到,在绝大多数情况下,基于eSVM+的方式都获得了最高的识别率.结合图4的结果,可进一步发现,随着特权信息比例的增加,3种方式呈现出不一样的规律:“SVM+”的识别率是稳定上升的,“Vapnik”的表现始终低迷,“eSVM+”的表现比较稳定,只是对于BU-3DFE数据库,在25%的比例时,其优势比较微弱;而对于Bosphorus数据库,3种比例的表现几乎没有变化.这或许与数据的特征分布有关.另外,这个实验结果也说明,其实并不需要全部的样本都拥有特权信息,借助于eSVM+模型,也可逼近甚至超越全部样本都拥有特权信息的分类能力(对应于图4中标注为100%比例的柱).显然,这个结果对于解决现实中不易获得特权信息的应用是非常有意义的.
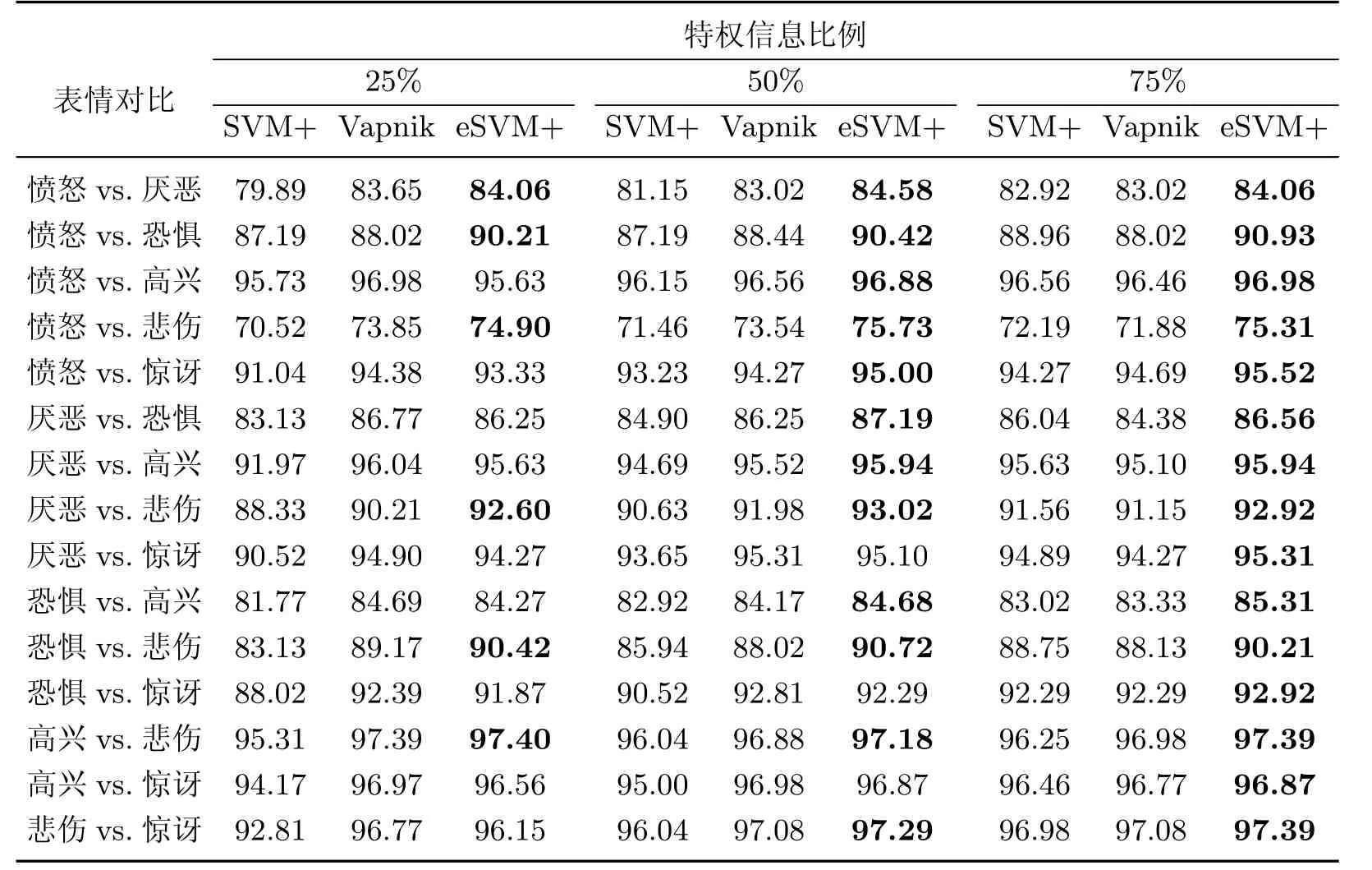
表3 BU-3DFE数据库中3种比例特权信息和3种方式表情识别率Tab le 3 Expression recognition accuracy corresponding to three ratios of privileged sample to total sample and threemethods for BU-3DFE database%

表4 Bosphorus数据库中3种比例特权信息和3种方式的表情识别率Tab le 4 Expression recognition accuracy corresponding to three ratios of privileged sample to total sample and threemethods for Bosphorus database%
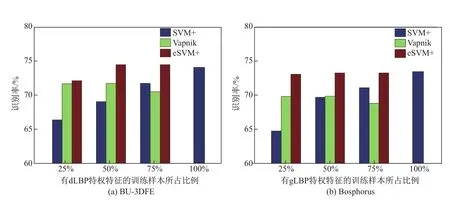
图4 3种比例特权信息和3种方式整体表情识别率F ig.4 Expression recognition accuracy corresponding to three ratios of privileged sample and threemethods

表5 3种方式中的模型参数设置Tab le 5 Parameters in threemethods
5 结束语
本工作研究了在SVM+的背景下,部分训练样本缺失特权信息或者面对常规的有监督学习,进一步提高分类模型泛化能力的问题,提出将无特权信息样本的可用信息同时用作特权信息.这分别称为eSVM+模型和eSVM模型,前者扩展了SVM+,后者扩展了SVM.在BU-3DFE和Bosphorus表情数据库中的实验结果说明了本模型是有效的.
[1]V ApNIK V,V ASHIST A,P AVLOVITCH N.Learning using hidden information(learning with teacher)[C]//International Joint Conference on Neural Networks.2009.
[2]V ApNIK V,V ASHIST A.Anew learning paradigm:learning using privileged information[J]. Neural Networks,2009,22(5/6):544-557.
[3]C HRISTOpH L.Learning with asymmetric information[EB/OL].[2015-09-01].http://pub. ist.ac.at/~chl/talks/lampert-us2014.pd f.
[4]J AN F,U WE A.Privileged information for data clustering[J].Information Sciences,2012,194: 4-23.
[5]R IBEIRO B,S ILVAC,V IEIRAA,et al.Financial distressmodel prediction using SVM+[C]// International Joint Conference on Neural Networks.2010:1-7.
[6]P ECHYONY D,V ApNIK V.On the theory of learning with privileged in formation[C]//NIPS. 2010:1894-1902.
[7]X U X X,L I W,X U D.D istancemetric learning using privileged information for face verifi cation and person re-identification[J].IEEE Transactions on Neural Networks and Learning Systems, 2015,26(12):3150-3162.
[8]H ERNANDEZ-L OBATO D,S HARMANSKAV,K ERSTING K,et al.Mind the nuisance:Gaussian process classifi cation using privileged noise[J].Advances in Neural Information Processing Systems, 2014(1):837-845.
[9]L ApIN M,H EIN M,S CHIELE B.Learning using privileged information:SVM+and weighted SVM[J].Neural Networks,2014,53:95-108.
[10]F EYEREISL J,K WAK S,S ON J,et al.Ob ject localization based on structural SVMusing privileged information[J].Advances in Neural In formation Processing Systems,2014(1):208-216.
[11]Y ANG H,P ATRAS I.Privileged information based conditional structured output regression forest for facial point detection[J].IEEE Transactions on Circuits and Systems for V ideo Technology, 2015,25(9):1507-1520.
[12]V IKTORIIAS,N OVI Q,C HRISTOpH H,et al.Learning to rank using privileged information[C]// ICCV.2013:825-832.
[13]W ANG S Z,T AO D C,Y ANG J.Relative attribute SVM+learning for age estimation[J].IEEE Transactions on Cybernetics,2016,46(3):827-839.
[14]P ECHYONY D,V ApNIK V.Fast optimization algorithms for solving SVM+[EB/OL].[2015-09-05].http://www.cs.technion.ac.il/~pechyony/book chapter.pd f.
[15]V IKTORIIAS,N OVI Q,C HRISTOpH L.Learning to transfer privileged information[J].Computer Science,2014,arXiv:1410.0389v1.
[16]V ALSTAR M,G IRARD J,ALMAEV T,et al.Fera 2015-second facial expression recognition and analysis challenge[C]//IEEE International Conference on Automatic Face and Gesture Recognition.2015:1-18.
[17]Y IN L,W EI X,W ANG J,et al.A3D facial expression database for facial behavior research[C]//IEEE InternationalConference on Automatic Face and Gesture Recognition.2006: 211-216.
[18]S AVRAN A.Bosphorus database for 3D face analysis[C]//Proc COST WorkshopBiometrics Identity Manag.2008:47-56.
[19]AHONEN T,H ADID A,P IETIKAINEN M.Face description with local binary patterns:application to face recognition[J].IEEE T-PAMI,2006,28(12):2037-2041.
U sing availab le in formation as privileged in formation in SVM+
DONG Yong,SUN Guangling,LIU Zhi
(School of Communication and In formation Engineering,Shanghai University,Shanghai 200444,China)
In machine learning,some in formation is only available during learning phase. Learning using privileged information(LUPI)can provide an eff ective solution to the problem.Such information is called privileged in formation.To deal with the issue that only partial privileged in formation of training data is available,this paper presents an intuitive but eff ective strategy called extended support vectormachine+(eSVM+).Specifi cally,for data without privileged information,available information is used as privileged information simultaneously and further cooperate it into the SVM+formu lation.In addition,for a regular supervised learning paradigm,a similar idea is adopted that all training data are both available and privileged.Naturally,it is extended SVM(eSVM),and also a special aspect of SVM+.Experimental resu lts show that the proposed strategy can boost generalization performance of the classifier on two benchmark expression databases,BU-3DFE and Bosphorus.
learning using privilegend in formation(LUPI);available in formation;privileged in formation;support vector machine+(SVM+)
TP 391.41
A
1007-2861(2017)04-0524-11
DO I:10.12066/j.issn.1007-2861.1675
2015-09-10
教育部科学技术研究重点资助项目(212053);上海市自然科学基金资助项目(16ZR 1411100)
孙广玲(1973—),女,副教授,博士,研究方向为模式识别、机器学习等.
E-mail:sunguangling@shu.edu.cn
