HDFS在智慧博物馆文件存储系统中的应用
2017-09-11张建光宋振源
赵 鑫,石 龙,张建光,刘 霞,宋振源
HDFS在智慧博物馆文件存储系统中的应用
赵 鑫a,石 龙b,张建光b,刘 霞b,宋振源a
(衡水学院 a. 科研处;b. 数学与计算机科学学院,河北 衡水 053000)
随着对智慧型博物馆的建设,各种文物藏品信息不断地丰富,形成的海量多媒体数据信息也越来越多,这对文物数据存储管理系统提出了更高要求.针对数字博物馆中海量多媒体下多维元小文件资源的特点,基于Hadoop File System(HDFS)分布式文件系统,将大量小文件合并成大文件,并对元数据的读写过程进行优化;根据不同海量小文件存储策略,从打包小文件、减少文件个数、集中缓存管理等方面优化存储效果.
智慧博物馆;海量存储;HDFS分布式系统;小文件存储
1 智慧博物馆现状
现如今伴随数据资源激增,数据应用模式已经从传统的互联网模式转变成云模式和云计算.其中智慧博物馆就是“云计算+文化遗产”在博物馆领域的应用.
传统博物馆的数据数量已经非常丰富,如今随着更多的文物被发掘,以及文化产业的更加深入发展,同时得益于虚拟现实技术、三维图形图像技术、特种视效技术、计算机网络技术、立体显示系统、互动娱乐技术等先进技术的进步,博物馆拥有了大量的数据资源.博物馆的数字藏品信息种类更加丰富多样,比如有图片、附属文字、影像视频、MP3音频、三维虚拟实体成像等.智慧型博物馆所蕴含的信息量以惊人的速度在增长,庞大的数据信息在丰富了博物馆的内容时,也给海量数据存储系统带来了很大难题.
因此人们近些年来不断研究如何提高博物馆管理水平并促进其发展,于是将海量博物馆数据资源整合成宏大的平台,搞好基础的数字典藏建设.
2 海量数据分布式存储
2.1 分布式存储技术
2003年谷歌公司设计了专门用于存储海量搜索数据的文件系统GFS.而后2006年适合运行在通用硬件上的Hadoop分布式文件系统(HDFS)被设计成功.分布式文件系统管理方式能够高效的解决存储海量数据的难题.其优势如下:使用低价机器来部署整个系统,很大程度上缩减了系统搭建成本及后期维护的费用;文件系统不限于一个服务器,系统由分布于世界各地任何一个地方并通过网络来传送数据、进行通讯的众多节点组成.系统可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样,不必了解数据的具体存放位置.此外这种分布式的存储可以均衡数据负载,并通过创建备份数据来防止数据丢失可能引起的系统瘫痪.另外因为分布式存储系统是建立在大量廉价的机器基础之上的,廉价就代表出错的可能性高,而用于海量存储的超大集群更是大大增加了出错的可能,所以HDFS本身需要有较强的容错性.
2.2 HDFS概述
尽管目前大数据技术还未形成统一标准,但Hadoop分布式系统已经成为云计算平台业界的宠儿.基于Hadoop关键技术的HDFS,原型参照谷歌公司的GFS文件系统,性能比较高效,是一个非常具有优势的海量数据存储系统,具有很高的服务可靠性、数据的高安全性、良好的易扩展性以及相对于其他分布式文件系统更加完善的生态环境,支持其他分布式系统,如HBase等.
HDFS采用Master/Slave结构,主节点NameNode包括fsimage、edits、fstime 3部分[1],其中fsimage为元数据镜像文件,用来存储某个时间段内的NameNode内存元数据信息;edits用于放置操作日志文件;fstime保存最后一次checkpoint时间.主节点既要维护文件系统目录结构,还要维护文件与block的直接关系,另外也要维护block与datanode之间关系.DataNode节点用于存储文件、将文件分割成block、复制副本的功能.Secondary NameNode从NameNode上下载元数据信息(fsimage、edits)并把它们合并起来,重新生成new fsimage保存在本地,然后将其推送到NameNode,然后对NameNode的edits重置.具体结构图如图1所示.

图1 HDFS结构
HDFS使用过程中存在很多优点:
1) 超大文件的处理,这里的超大文件通常是指100 MB、100 TB大小的文件.目前在实际应用中,HDFS已经能用来存储管理PB级的数据了.
2) 流式的访问数据,HDFS的设计建立在更多地响应“一次写入、多次读写”任务的基础上.这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求.在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效.
3) 廉价的硬件配置要求,hadoop设计对硬件需求比较低,无需昂贵的高可用性机器上.
在建设智慧博物馆的过程中,海量多媒体小文件的高效存储有待提高.然而,如今流行的HDFS等分布式文件系统在高效存储大文件上虽有出色的表现,但是在存储海量小文件时,却不尽人意.海量的小文件如果直接应用HDFS系统会存在无法高效存储的问题:因为文件系统的元数据放置在Namenod内存中,所以系统中容放的文件数目和Namenode的内存大小息息相关.当读取的文件越多所需的内存也随之增大,对于巨大的内存要求,以当前的硬件水平无法达到.同时,数量庞大的小文件频繁地与元数据节点进行交互时产生的DateNode节点文件块报告检测也同样需要占用NameNode节点资源.在用户访问小文件时,因为文件内容小,所以真正传输文件需要的时间非常少,而因为发送请求而产生的交互反而占用了系统的较大开销,从而导致数据的访问效率低下.
3 HDFS小文件存储解决方案
3.1 HAR(Hadoop Archive)
Mackey等[2]最早采用Hadoop Archive技术,并被Hadoop 0.18.0版本引入.它是一个能高效地将小文件放入HDFS块中的文件存档文件格式,具体样式如图2 HAR文档结构.它能够将多个小文件打包成一个后缀为.har文件,这样减少了文件个数(但是文件总体大小并没有减少,无压缩),随之降低了namenode内存的使用,并且仍然支持访问文件透明化.打包后不影响原文件的Map-reduce操作,打包后的文件包括索引(原目录、文件状态)和存储两部分.

图2 HAR文档结构
另外HAR有自己的几个特性:
1) 文件夹模糊匹配:在使用hadoop命令查看文件夹的时候hdsf系统是精确匹配文件夹的,但是在har文件系统中是模糊匹配的.
2) pig读har文件系统只能指定到具体文件,不能指定到文件夹.
3) hive只能读到文件夹,读不到具体的文件.
而且HAR中创建Archive文件要消耗和原文件一样多的硬盘空间,并且Archive文件不支持压缩,一旦Archive文件创建了就无法改变.如果要修改Archive文件的内容,就需要重新创建Archive文件.所以HAR会因为频繁地创建海量小文件的归档文件而占用大量的机器资源[3],从而严重影响集群系统性能.
还需要注意的是:因为archive的开源性,所以其他的fsshell命令也可以在archive上运行,这将对系统的安全性造成影响.
3.2 基于SequenceFile的小文件合并
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)[4].由一系列的二进制key/value组成,key为filename,value为file contents,可以将大批小文件合并成一个大文件.序列文件如图3所示:

KeyvalueKeyvalue……Keyvalue
SequenceFile中虽然是按文件名(或其他任何值)为键,文件内容为值来存储的.但SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序存储的,并且读取时,键值还是会被读到文件的首行.
进入到SequenceFile的所有记录,都需要根据一定的hash规则确定一个HashKey.相对而言,记录块是比较简单的,每个记录块中仅包含块的大小以及该块的数据;元数据就相对而言比较复杂,其中Metadata size是总体的记录数,每个HashKey均可以直接定位到记录的位置(offset, length, number记载着这些信息).其中需要注意的是,记录是严格有序的,写文件需要按照HashKey的顺序进行写入,也就是说,不能向该文件中append一条HashKey在当前Key之前的数据,一旦文件写完成,可能不能再更改.
SequenceFile文件可支持3种压缩类型:
1) NONE:对records不进行压缩;
2) 记录级别的压缩;
3) 块级别压缩.前两种以基于记录的格式保存(如图4所示),而第三种使用基于块的格式(如图5所示).

头部记录记录…同步记录…同步记录

头部记录块…同步块…同步块
另外如果采用并行的方式来创建一个一系列的SequenceFiles可以加快小文件的转换.
3.3 基于DataNode的元数据策略
HDFS中的集中化缓存管理是一个明确的缓存机制[5],它允许用户指定要缓存的HDFS路径.NameNode会和保存着所需块数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中.
HDFS集中化缓存管理具有许多重大优势:
1) 明确的锁定可以阻止频繁使用的数据被从内存中清除.当工作集的大小超过了主内存大小(这种情况对于许多HDFS负载都是司空见惯的)时,这一点尤为重要.
2) 由于DataNode缓存是由NameNode管理的,所以,在确定任务放置位置时,应用程序可以查询一组缓存块位置.把任务和缓存块副本放在一个位置上可以提高读操作的性能.
3) 当块已经被DataNode缓存时,客户端就可以使用一个新的更高效的零拷贝读操作API.因为缓存数据的checksum校验只需由DataNode执行一次,所以,使用这种新API时,客户端基本上不会有开销.
4) 集中缓存可以提高整个集群的内存使用率.当依赖于每个DataNode上操作系统的buffer缓存时,重复读取一个块数据会导致该块的N个副本全部被送入buffer缓存.使用集中化缓存管理,用户就能明确地只锁定这N个副本中的M个了,从而节省了N-M的内存量.
如图6缓存结构中[6],集群中所有DataNode的off-heap缓存通过NameNode负责协调.每个DataNode的缓存报告都会相隔固定时间发送至NameNode(包含描述缓存在给定DN中的所有块).NameNode通过借助DataNode心跳上的缓存和非缓存命令来管理DataNode缓存.
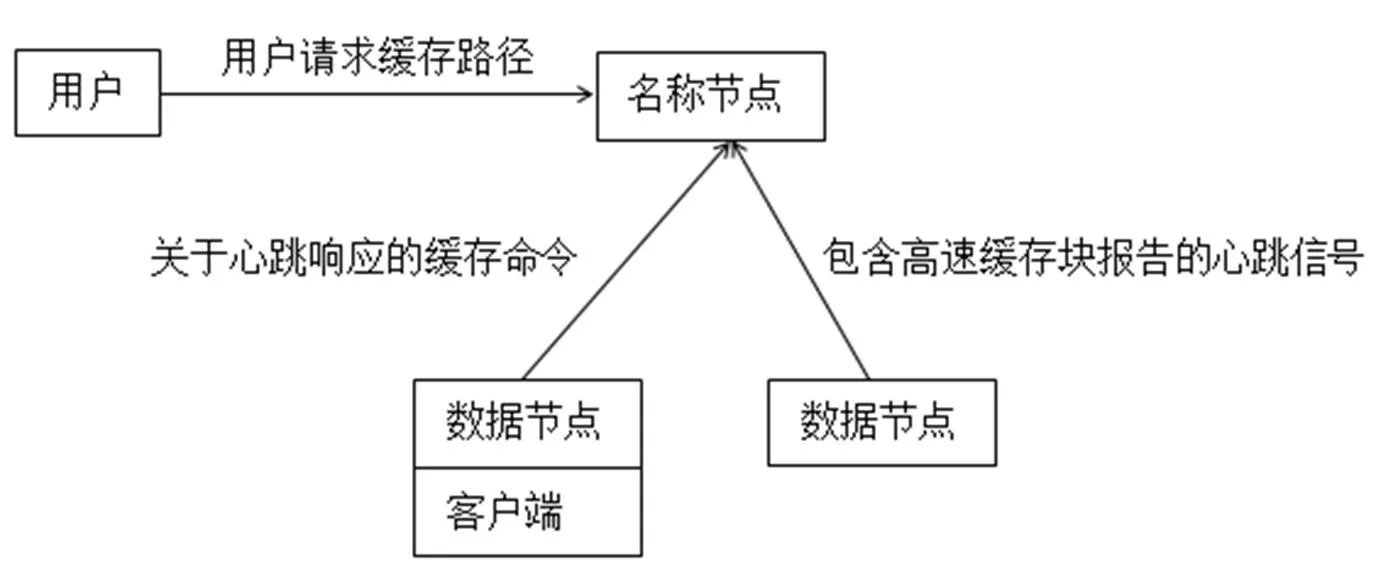
图6 缓存结构图
NameNode查询自身的缓存指令集来确定应该缓存那个路径.缓存指令永远存储在fsimage和edit日志中,而且可以通过Java和命令行API被添加、移除或修改.NameNode还存储了一组缓存池,它们是用于把资源管理类和强制权限类的缓存指令进行分组的管理实体.
NameNode周期性地重复扫描命名空间和活跃的缓存指定以确定需要缓存或不缓存哪个块,并向DataNode分配缓存任务.重复扫描也可以由用户动作来触发,比如,添加或删除一条缓存指令,或者删除一个缓存池.
当用户缓存construction、corrupt下的块数据,或者别的不完整的块,比如一条缓存指令包含一个符号链接时,那么该符号链接目标不会被缓存.
目前,文件或目录级的缓存已经实现,块和子块缓存是未来的目标.
4 小结
目前基于 HDFS对小文件存储进行优化所提出的一些方案,有各自的优点和不足,通过分析比较发现,几种文件系统的应用方法虽然有所区别,可是都可以从增大cache命中率、降低元数据的磁盘访问量、缩减随机读写次数等方面来提高海量小文件的优化效果.
现实中的不同应用场景对海量数据存储有不同侧重点的需求,对于智慧博物馆海量数据的多维化特点,可通过多维索引进行进一步优化.
[1] 刘高军,王帝澳.基于Redis的海量小文件分布式存储方法研究[J].计算机工程与科学,2013,35(10):58-64.
[2] MACKEY G, SEHRISH S, WANG J. Improving metadata management for small files in HDFS [C]//Cluster Computing and Workshops, 2009. CLUSTER 09. IEEE International Conference on. New Orleans: IEEE, 2009:1-4.
[3] 洪旭升,林世平.基于MapFile的HDFS小文件存储效率问题[J].计算机系统应用,2012,21(11):179-182.
[4] 赵晓永,杨扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构研究[J].计算机应用,2012,32(6):1724-1726.
[5] 余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45(6):59-63.
[6] 江柳.HDFS下小文件存储优化相关技术研究[D].北京:北京邮电大学,2011:51-60.
Application of HDFS in the Construction of File Storage System of Smart Museum
ZHAO Xina, SHI Longb, ZHANG Jianguangb, LIU Xiab, SONG Zhenyuana
(a.Scientific Research Office, b. College of Mathematics and Computer Science, Hengshui University, Hengshui, Hebei 053000, China)
With the construction of the smart museum, various heritage collection information is increasing constantly, and more and more multimedia data information is formed. That demands a better system of heritage data storage and management. In view of the characteristics of small file resource in the massive multimedia data in the digital museum, based on the Hadoop File System ( HDFS ) distributed file system, a large number of small files are merged into big files, and the metadata reading and writing process are optimized. According to the strategy of storing mass different small files, the storage results should be optimized from the aspects of packing small files, reducing the number of files and centralizing cache management.
smart museum; mass storage; HDFS distributed system; small file storage
(责任编校:李建明 英文校对:李玉玲)
10.3969/j.issn.1673-2065.2017.04.002
TP333
A
1673-2065(2017)04-0006-05
2017-05-23
衡水市科技计划项目(2016011010Z);河北省高等学校科学技术研究青年基金项目(QN2017513)
赵 鑫(1984-),女,河北饶阳人,衡水学院科研处讲师,工程硕士; 石 龙(1988-),男,河北衡水人,衡水学院数学与计算机科学学院助教.
