基于C4.5算法和Hadoop云计算平台的购物意愿分析方法
2017-09-08褚治广
褚治广,颜 飞,张 兴,李 畅
基于C4.5算法和Hadoop云计算平台的购物意愿分析方法
褚治广,颜 飞,张 兴,李 畅
(辽宁工业大学 计算中心,辽宁 锦州 121001)
为适应大数据背景下的计算需求,首先根据C4.5算法计算原理的特点,对C4.5进行数据处理并行化改进。然后根据Hadoop云平台的特点,对数据处理流程进行简要说明。最后,通过搭建Hadoop云平台环境,使用随机生成的测试数据集对算法进行验证。分析消费者可能购买的商品,实现数据的利用率最大化、提高交易成交率和挖掘潜在交易。通过实验分析得出,基于C4.5算法和Hadoop云计算平台的购物意愿分析方法可以应用到大型电商平台对消费者的购物意愿进行分析中。
C4.5;Hadoop;计算集群;购物意愿;数据挖掘
互联网是人类历史上最成功的科技成果之一,互联网在人们生活中的应用,极大地改变了人们的生活方式[1]。近年来,基于Internet的电商平台快速发展,网上购物为生活提供了诸多便利。每天电商平台都将会产生来自各行各业的海量交易数据和浏览记录。如何有效地对海量交易数据进行分析和挖掘其潜在价值,对电商企业来说是具有重要意义。数据的潜在价值是企业发展的重要经济资产。
在海量的交易数据和浏览记录中,隐藏了消费者的购物习惯、未来消费意愿等潜在信息。对消费者的历史消费记录进行分析可以有效地推测出消费者购物意愿,以及分析出对购物成功与否产生重要影响的因素。而且可用于企业较深入地挖掘、获取数据潜在价值,提高交易成交率、库存规划、优化市场结构等。毋庸置疑,大数据的研究提供了挖掘巨大潜在价值的手段[2]。因此,使用大数据分析方法可成为探测数据价值的重要手段,具有极其重要的作用[3]。
为此,本文搭建了一个基于Hadoop的云平台,利用C4.5算法对购物者的一些信息进行分析,比如性别、年龄、所属地区、物品类属等。可用于数据分析的众多方法中,比较适合于消费者行为分析的、而且较为有效的方法是使用决策树方法来进行信息分类。本文应用到了C4.5算法[4-5]对消费者行为进行分析并构建出决策树,从而进一步分析出消费者购物意愿。
1 研究现状
决策树是应用在数据挖掘中最简单、最直接、最有效的分类算法[6-7]。其中应用比较广泛的一种是C4.5算法,它对ID3算法进行大量的改进,C4.5算法是以信息增益率作为选择分裂属性的标准。解决了测试数据属性值缺失的问题;在决策树生成前进行修剪[8-9];能够对离散的属性和连续的属性值进行处理等。然而,随着云计算的发展以及海量数据的产生。在海量数据集处理过程中,C4.5算法需要花费大量的计算时间,时间效率低下。其次,在传统的决策树构造过程中,需要将数据集全部装入内存,导致在内存上算法具有比较差的伸缩性。为满足大数据背景下的海量数据处理,C4.5算法在处理海量数据过程中需要并行化处理。
比如海量嘈杂数据进行决策树算法中[10],在Hadoop平台下,通过将C4.5算法以文件分裂的方式进行MapReduce并行化程序设计,增强了处理海量数据的能力。而且由实验结果可得,在训练集数据是嘈杂的情况下,C4.5算法的准确率相对更高。并且基于Hadoop的并行化的C4.5算法具有处理海量数据的能力。在对C4.5算法并行化方法中,可将C4.5的并行化应用到海量医疗数据挖掘中[11],对算法中可并行的部分进行并行化设计。融合Bagging改进C4.5算法和基于MapReduce的并行化C4.5算法进行验证,对比算法性能。文献[12]利用MATLAB实现串行的C4.5决策树,并对构成该决策树的子函数进行运行时间分析,确定信息增益率计算的复杂性,纵向划分数据,构建了并行的C4.5决策树。
由于在决策树的构建过程中,连续属性的端点计算和数据扫描会花费决策树算法时间,因此研究人员通过对连续属性离散化实现属性分割。将需要统计的数据分到不同的机器上面进行统计,然后汇总。除此之外,可以对决策树的构建过程做一些处理[13]:首先,在数据的预处理中,主要是对与挖掘任务不相关的数据内容进行清洗处理,以减少数据样本量,有效地缩短决策树构建时间开销。其次,在决策树算法中对数据进行了重新构造,建立属性表,构造新的数据类型能够更方便快速地构造决策树,实现C4.5算法在大数据处理中的应用。
2 Hadoop平台的C4.5算法的并行化
本方法在对大量的购物者行为数据进行分析的基础上构建决策树,从而对消费者潜在的购物意愿进行预测。出于对大数据背景的考虑,消费者信息往往是基于Hadoop平台来存储的。因此,数据往往分布式存储在不同场地。在决策树的构建过程中,需要从分布式的场地中提取出来数据,那么就需要借助于Hadoop平台来对数据的存储策略、存储场地、数据处理等进行操作。而传统决策树算法无法很好地满足大数据背景下分布式数据处理的需求。
2.1 C4.5算法的并行化
本文对C4.5算法并行化改进以适应Hadoop云平台来构建决策树。主要是对每个属性所拥有的信息增益以及信息增益率的计算过程进行并行化改进[14],改进后实现C4.5算法并行化。从而使得计算过程所花费的时间较大程度地缩短,提高数据处理效率,使其达到大数据背景下C4.5算法的应用需求[15]。
另外,无论是在实际应用中还是在模拟实验过程中,难免会出现脏数据。数据质量问题会对大数据的分析产生影响。为了保证实验的准确性,需要对测试数据集进行数据清洗。数据清洗是对数据集无效数据、空数据或冗余数据进行清洗,提高数据处理效率[16]。在Hadoop云平台上运行C4.5算法需要在C4.5算法中嵌入map函数和reduce函数,然后对其并行化处理,整个数据处理过程的主要步骤如图1所示。
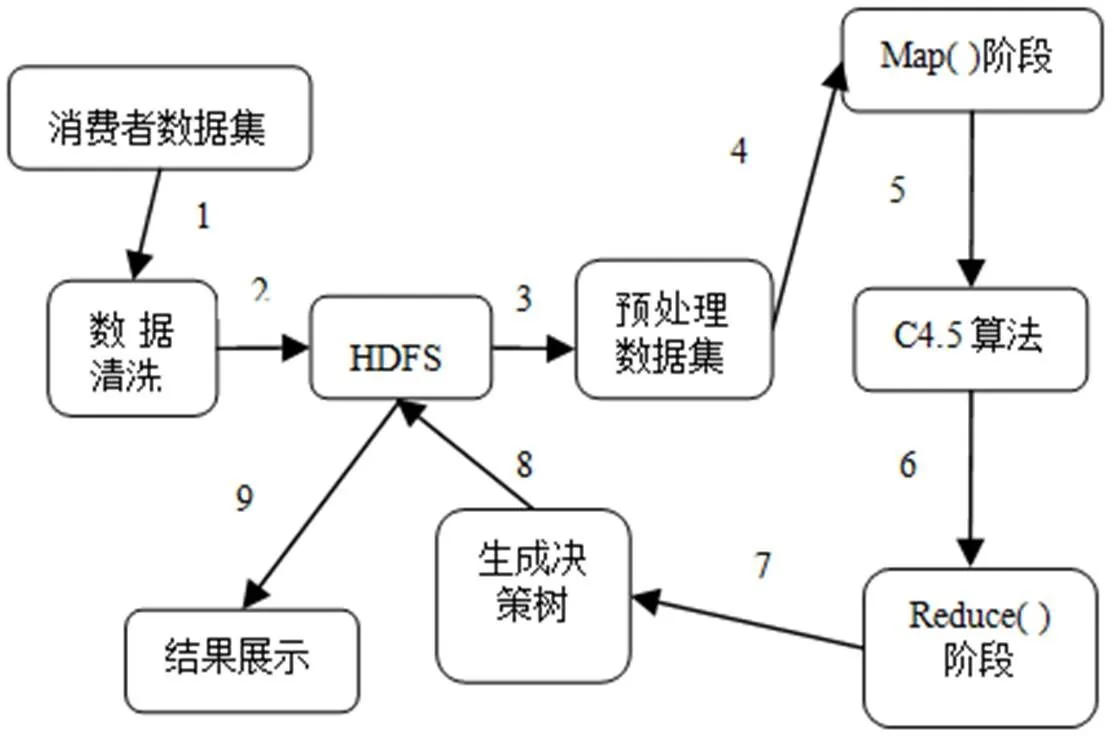
图1 数据流图
其映射和简化过程的说明[17]:开始执行Map动作前调用setup,在setup中预读取所有需要的Mapper数据。数据流经Map后,会将处理结果转至Reducer进行处理。而Reducer过程可将具有相同key值的数据集归约到一块。而后,所得到的处理数据将直接写入HDFS之中。
2.2 决策树的构建
在Hadoop云平台下生成决策树所需的判定依据来自C4.5算法对数据集属性的计算和判定,因此,结合图1对提出的C4.5算法[18]进行了改进,算法描述如下所示。
输入:数据集S,由离散值属性表示,节点T。
输出:一棵决策树。
(1)创建根节点T,如果数据集S中实例的属性相同或者实例仅有1例,则设置节点T作为叶节点;
(2)IF数据集S中实例的属性相同
(3)Then返回T为叶节点,标记其属性;
(4)IF数据集S中实例为空
(5)Then返回T为叶节点,将其标记为数据集S中最普通的类;
(6)否则,选择数据集S属性列表中信息增益率最高的属性作为属性;
(7)标记结点T为属性;
(8)将数据集S根据输出属性的不同划分成1,2,…,S子集,生成’节点的孩子节点1,2,…,T;
(9)对于每一组(S,T),递归生成子树T。
在C4.5算法构建决策树的过程中,引入了信息熵(Entropy)的概念,实现每个分类的构建都与其选择的目标分类相关[19-21]。利用信息增益来构造决策树是一种采用平均信息量处理属性不确定的信息的最佳方法,信息熵公式为:
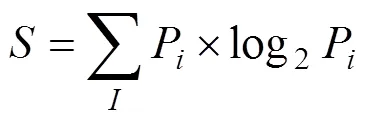
信息增益为信息熵的有效减少量,根据它就能够确定在不同的层次上选择相应的变量来分类。假设存在2个类P和N,并且记录集S中包括个属于类P的记录和个属于类N的记录。那么,用于确定记录集S中某个记录属于哪个类的所有信息量为:

假设以变量为树的根,将数据集S分成若干子类,其中每个中有条记录属于类P,和条记录属于类N。则信息量计算如下:
(3)
假设以变量为分类节点,则变量的信息增量为:
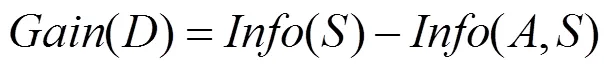
信息增益函数的定义为:
(5)
C4.5算法是以信息增益率来选择分类属性的。而信息增益率等于信息增益与分割信息量的比值,其中分割信息量计算公式为:
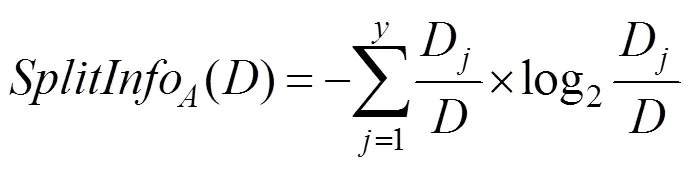
由上述公式可得,信息增益率是任意样本子集占总样本集的比例,即信息增益率为:
(7)
本方法在对大量的购物者行为数据进行分析的基础上构建一棵决策树,从而对消费者潜在的购物意愿进行预测。
3 实验与数据分析
3.1 实验环境
为了模拟电商平台,本文搭建了由20台普通计算机组成的一个小型的云平台。具体说明为:本文所搭建环境中,Hadoop集群由20台计算机组成,其中1台作为Master节点,其余为Slaver计算节点。每台PC硬件均为Intel Dual-core 2.6 GHz处理器,2 G内存,500 G硬盘,Ubuntu-12.10-server-i386系统,开发环境中的JDK版本为1.6.0_27,数据库采用Mysql 5.5版本,Hadoop-1.20.2。
3.2 实验数据分析
为了实现更客观的对消费者购物意愿的分析,本文采用了随机生成的方式,产生约100亿条没有倾向性的消费者购物记录,包括性别、年龄、所属区域、购物类型。将产生的数据首先存在Mysql数据库中,然后通过Hadoop平台将数据迁移到数据存储仓库Hive之中。在数据转存至Hive中时,对消费记录数据的描述进行了离散化处理,并按照将消费者性别分为男、女;地域为中国各个省份以及其他国家和地区;年龄分为青少年、中年、老年;类别为日用百货共15大项。
(1)计算分类属性的信息量
对于类别属性A(是否是男性)属于正例y和反例n的个数分别为321、179个,则()=321/500,()=179/500,分类属性的信息量为:
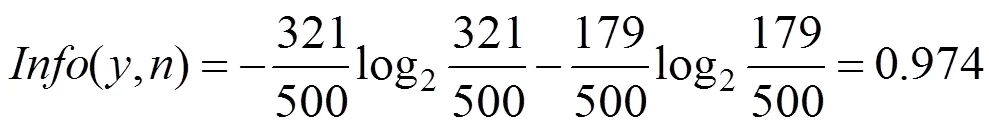
(2)计算测试属性的信息增益率
以属性“年龄”为例,取值为青少年、中年、老年,其实例数分别为202、226、72个。当取值为青少年时,正例为128个,反例为74个;当取值为中年时,正例为149个,反例为77个;当取值为老年时,正例为44个,反例为28个。则:
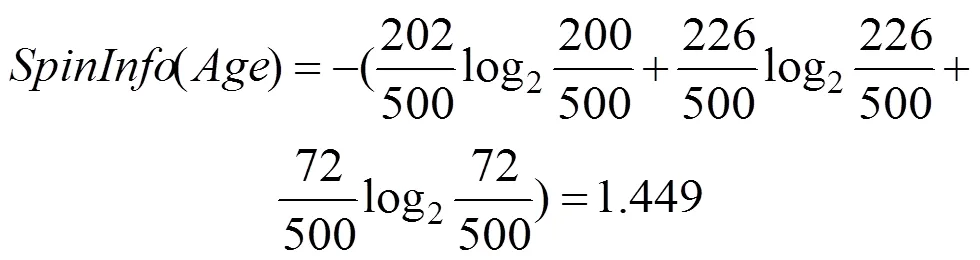
以属性“Area”为例,同age的原理一样:

以属性“Category”为例,同上述原理相同:
由上述计算结果可得:在本实验中,年龄的信息增益率最大,即年龄所含的信息对分类的帮助最大,因此选择“年龄”为测试属性。同理,可得出“地区”为决策树下一个节点的测试属性,以此类推最后是类目。依据测试属性集所生成的决策树即可分析出消费者可能需要购买的商品,从而挖掘出这些消费数据的潜在价值,实现数据的利用率最大化。
因此,此基于C4.5算法和Hadoop云计算平台的购物意愿分析方法可以应用到大型电商平台对消费者的购物意愿进行分析当中,从而挖掘出隐藏在消费记录中的潜在价值,提高交易成交率和挖掘潜在交易[22]。以京东618品质狂欢节第一单快递7 min送达为例,类似的交易可以利用购物意愿分析方法对购物者购物意愿进行预测,做到配送时间更短、签收速度更快,为消费者提供更高品质的购物体验。
3.2 MapReduce计算效率验证
本文还对基于C4.5算法的MapReduce在分布式并行环境下的计算效率进行评估扩展能力。主要从2个方面来进行评估:(1)节点数不同情况下的性能表现。(2)测试数据集大小不同时,计算性能表现。
本文实验所采用数据集分别为10、20、30 G,记录数据支持度为5%、10%、15% 3种情况下时,计算节点为5、10、15、20个运算节点的表现。
第一组实验为10G数据在5、10、15、20个运算节点上实际运行时的计算时间展示。10 G数据大概含有1亿条事务,测试结果如图2所示。
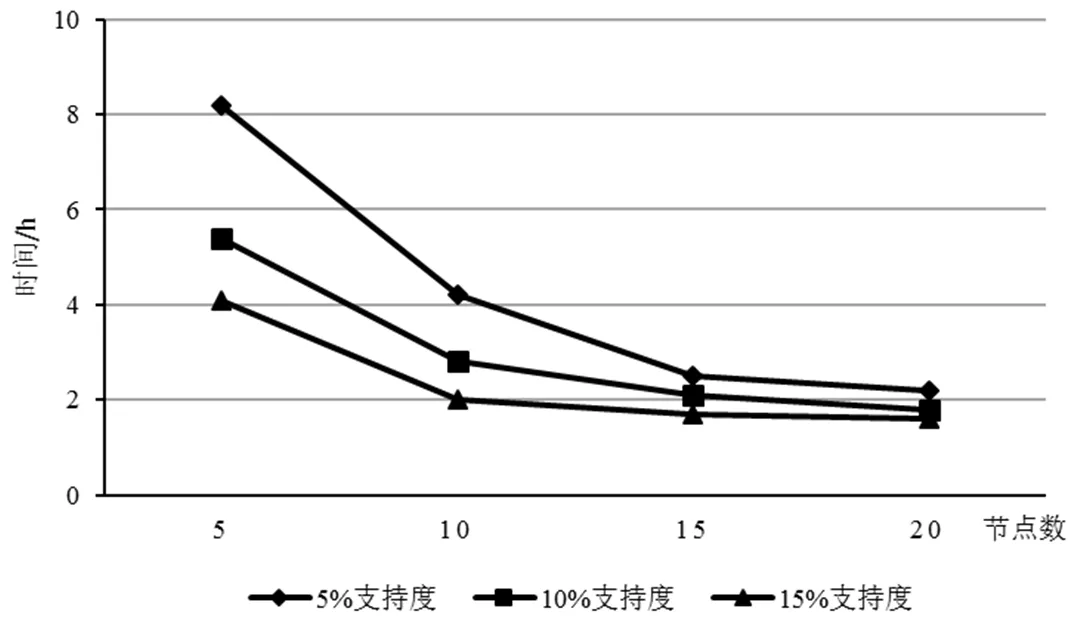
图2 10 G数据测试表现图
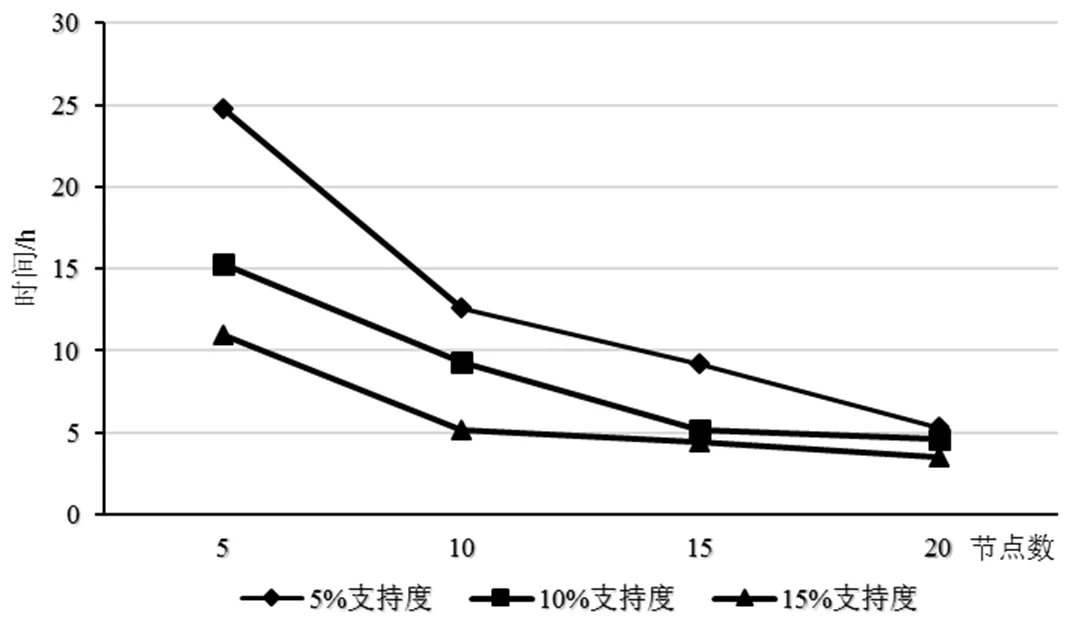
图3 20 G数据测试表现图
第二组实验是将20 G数据分别在5、10、15、20运算节点上实际运行。根据实验1所述,20 G数据大概含有2亿条事务。计算时间展示结果如图3所示。
第三组实验是将30 G数据分别在5、10、15、20个运算节点上实际运行。根据实验1所述,30 G数据大概含有3亿条事务。计算时间展示结果如图4所示。
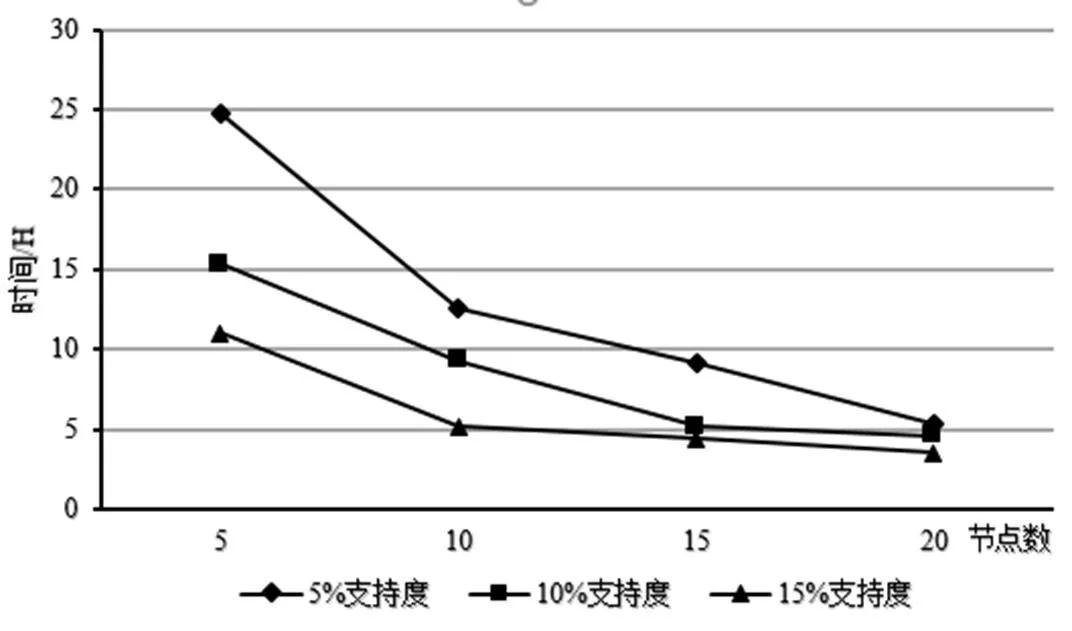
图4 30 G数据测试表现图
对比上述3组实验的运算时间结果可以看出,随着参与运算的节点数目的增加,数据处理耗费的时间呈递减趋势。这就说明参加运算的节点越多,C4.5算法运行的效率就越高。另一方面,运行时间还与训练集的大小有关。
由图2~图4的测试数据集大小不同的情况下运算性能表现可得:(1)数据集越庞大,系统运算时间越长。(2)参与运算的节点越多系统执行时间越少。(3)如果参与运算的的节点数足够多的话,即使测试数据集很大,其性能表现也会表现得最优。如图4所示,如果30 G的测试数据在20个节点下运行,其运行时间与20 G的测试数据时运行时间相差较小。总之,基于Hadoop平台的C4.5算法可以明显提高对海量数据的挖掘效率。
4 结束语
针对现在电商平台每时每刻都会产生来自各行各业的海量交易数据和浏览记录,提出了基于C4.5算法和Hadoop云计算平台的购物意愿分析方法。对海量交易数据进行分析和挖掘其潜在价值,对电商企业来说具有重要意义。而传统的单机系统无法胜任庞大数据的处理,因此本文搭建Hadoop集群模拟电商平台,生成数量庞大的测试数据集,通过C4.5决策树算法,对信息增益率进行推导计算,判断分类能力强的属性作为决策树节点。从而实现对消费者行为进行分析并根据购物行为推测出购物者的购物意愿的目的。因此,基于C4.5算法和Hadoop云计算平台的购物意愿分析方法可以应用到大型电商平台对消费者的购物意愿进行分析当中。最后,通过实验结果表明,利用MapReduce实现C4.5算法具有较好的挖掘效率。
[1] 尹浩, 乔波. 大数据驱动的网络信息平面[J]. 计算机学报, 2016, 39(1): 126-139.
[2] 赵国栋, 易欢欢, 糜万军, 等. 大数据时代的历史机遇: 产业变革与数据科学[M]. 北京: 清华出版社, 2013.
[3] 梁吉业, 冯晨娇, 宋鹏. 大数据相关研究综述[J]. 计算机学报, 2016, 2016, 39(1): 1-18.
[4] Wei D, Wei J. A MapReduce Implementation of C4.5 Decision Tree Algorithm[J]. International Journal of Database Theory & Application, 2014, 7(1): 46-60.
[5] Quinlan J R. Improved use of continuous attributes in C4.5. AI Access Foundation, 1996, 4(1): 77-90.
[6] Witten I H, Frank E. Data mining: practical machine learning tools and techniques[J]. Biomedical Engineering Online, 2011, 51(1): 95-97.
[7] Berry M J A, Linoff G S. Data Mining Techniques: For Marketing, Sales, and Customer Support[C]. John Wiley & Sons Publishing, 1997, 43(1): 1-8.
[8] Ventura D, Martinez T R. An empirical comparison of discretization methods[J]. Computer and Information Sciences, 1995, 10(2): 443-450.
[9] 李会, 胡笑梅. 决策树中ID3算法与C4.5算法分析与比较[J]. 水电能源科学, 2008, 26(2): 129-132.
[10] 刘亚秋, 李海涛, 景维鹏. 基于Hadoop的海量嘈杂数据决策树算法的实现[J]. 计算机应用, 2015, 35(4): 1143-1147.
[11] 王宁. ID3决策树算法分析与改进[D]. 北京: 北京邮电大学, 2013.
[12] 张莹, 毕卓. 基于SPMD的C4.5并行决策树加速分析[J]. 计算机技术与发展, 2015, 25(1): 29-32.
[13] 龙志勇. 基于并行化的决策树算法优化及应用研究[D]. 杭州: 浙江大学, 2015.
[14] 孙媛, 黄刚. 基于Hadoop平台的C4.5算法的分析与研究[J]. 计算机技术与发展, 2014(11): 83-86.
[15] Nari S G, Adbulla N, Gazzali Z A M, et al. Measure customer behaviour using C4.5 decision tree mapreduce implementation in big data analytics and data visualization[J]. International Journal for Innovative Research in Science & Technology, 2015, 1(10): 228-235.
[16] 杨东华, 李宁宁, 王宏志, 等. 基于任务合并的并行大数据清洗过程优化[J]. 计算机学报, 2016, 39(1): 97-108.
[17] Amogh Pramod Kullkarni, Mahesh Khandewal. Survey on hadoop and introduction to YARN[J]. International Journal of Emerging Technology and Advanced Engineering, 2014, 4(5): 82-87.
[18] Wu G, Li H, Hu X, et al. MReC4.5: C4.5 Ensemble Classification with MapReduce[C]// Chinagrid Conference, 2009. Fourth IEEE, 2009: 249-255.
[19] Dunham M H. Data mining: Introductory and Advanced topics[M]. 北京: 清华大学出版社, 2003.
[20] 黄世反, 沈勇, 王瑞芳, 等. 决策树C4.5算法属性取值优化研究[J]. 计算机科学与应用, 2015, 5(5): 171-178.
[21] 张睿. ID3决策树算法分析与改进[D]. 兰州: 兰州大学, 2010.
[22] Arasanal R M, Rumani D U. Improving MapReduce Performance through Complexity and Performance Based Data Placement in Heterogeneous Hadoop Clusters[C]// International Conference on Distributed Computing and Internet Technology. Springer Berlin Heidelberg, 2013: 115-125.
责任编校:孙 林
Analytic Method of Customers’ Shopping Intention Based on C4.5 Algorithm and Hadoop Platform
CHU Zhi-guang, YAN Fei, ZHANG Xing, LI Chang
(Computer Center, Liaoning University of Technology, Jinzhou 121001, China)
To meet the demand of big data computing, firstly, according to the characteristics of the C4.5 algorithm calculation principle, data processing was carried out on the C4.5 parallelization improvement. Then, considering the features of Hadoop platform, the data processing is explained briefly in this paper. Finally, the experiment used the randomly generated test data sets to verify the algorithm in the Hadoop cloud platform. The method not only helps us to identify customers’ willingness of shopping and realize maximum use of data, it also provides an approach to improve the trade rates and excavate potential deals. According to experimental analysis, the method can be applied to large electric business platform to analyze consumers’ willingness of shopping.
C4.5; Hadoop; computing cluster; purchasing intention; data mining
10.15916/j.issn1674-3261.2017.04.004
TP391.1
A
1674-3261(2017)04-0225-05
2017-02-26
褚治广(1980-),男,辽宁锦州人,讲师,硕士。
