基于深度学习的胎儿颜面部超声标准切面自动识别
2017-09-08吴凌云陈思平李胜利汪天富雷柏英
余 镇 吴凌云 倪 东 陈思平 李胜利 汪天富* 雷柏英*
1(深圳大学生物医学工程学院,广东省生物医学信息检测和超声成像重点实验室, 广东 深圳 518060)2(深圳妇幼保健院超声科,南方医科大学附属医院,广东 深圳 518060)
基于深度学习的胎儿颜面部超声标准切面自动识别
余 镇1吴凌云1倪 东1陈思平1李胜利2汪天富1*雷柏英1*
1(深圳大学生物医学工程学院,广东省生物医学信息检测和超声成像重点实验室, 广东 深圳 518060)2(深圳妇幼保健院超声科,南方医科大学附属医院,广东 深圳 518060)
在常规胎儿超声诊断过程中,精确识别出胎儿颜面部超声标准切面(FFSP)至关重要。传统方法是由医生进行主观评估,这种人工评判的方式不仅耗费时间精力,而且严重依赖操作者经验,所以结果往往不可靠。因此,临床超声诊断亟需一种FFSP自动识别方法。提出使用深度卷积网络识别FFSP,同时还分析不同深度的网络对于FFSP的识别性能。对于这些网络模型,采用不同的训练方式:随机初始化网络参数和基于ImageNet预训练基础网络的迁移学习。在研究中,数据采集的是孕周20~36周胎儿颜面部超声图像。训练集包括1 037张标准切面图像(轴状切面375张,冠状切面257张,矢状切面405张)以及3 812张非标准切面图像,共计4 849张;测试集包括792张标准切面图像和1 626张非标准切面图像,共计2 418张。最后测试集实验结果显示,迁移学习的方法使得网络识别结果增加9.29%, 同时当网络结构由8层增加至16层时,分类结果提升3.17%,深度网络对于FFSP分类最高正确率为94.5%,相比之前研究方法的最好结果提升3.66%,表明深度卷积网络能够有效地检测出FFSP,为临床自动FFSP检测方法打下研究基础。
胎儿颜面部标准切面识别;超声图像;深度卷积网络;迁移学习
引言
在胎儿疾病的常规检查中,超声检查已经成为最受欢迎的影像诊断技术[1- 7]。胎儿颜面部标准切面(FFSP)的获取对于超声精确诊断和测量至关重要[1,3- 4]。临床上,胎儿超声检查需要操作者具有完备的知识储备,以及大量的经验实践。经验丰富的医生可以高效地利用超声进行诊断,而在欠发达地区,缺少有经验的专家以及先进的超声成像设备。在这种情况下,自动识别胎儿超声颜面部标准切面的方法可以有效地弥补专家等医疗资源的不足,同时减少医生诊断时间[8]。因此,研究自动识别技术对临床诊断意义重大。
临床上,传统检测FFSP的方法是基于医生对于获取的胎儿超声图像进行主观评估。但是,这种人工评估的方法除了比较耗时外,其评估结果往往具有很大的主观性,不同的医生可能会得到不同的诊断结果。而利用计算机技术,也就是图像分析与机器学习的方法,可以自动检测出医生所需的异常或标准面图像,从而方便医生诊断流程,同时改善诊断结果。这种计算机辅助诊断技术往往需要大量的标注数据,然而在临床应用上,数据采集与处理过程极具挑战且相当耗时。与此同时,在超声图像中,由于大量伪影和噪声的存在,使得图像类间差异小而类内差异大。如图1所示,胎儿颜面部超声标准切面FFSP与其他非标准切面之间差异并不明显。所以,精确识别FFSP具有相当大的挑战。为了解决这些困难,很多研究者提出了不同的方法,其中最常见的是利用低层特征(即SIFT、Haar和HoG特征)作为图像表述中介来表达图像。随后,对这些低层特征进一步编码来改善识别的结果,常见的编码方法有视觉词袋(bag of visual words, BoVW)、局部特征聚合描述符(vector of locally aggregated descriptors, VLAD),以及Fisher向量(Fisher vector, FV)[1,4- 5]。然而,这些从连续二维超声图像中提取的手工特征,最后得到的FFSP识别结果并不能令人满意。

图1 胎儿超声颜面部切面。(a)非标准切面;(b)轴向标准切面;(c)冠状标准切面;(d)矢状标准切面Fig.1 Original samples of FFSP. (a) Others (non- FFSP); (b) Axial plane; (c) Coronal plane; (d) Sagittal plane
与此同时,由于大规模数据集(ImageNet)[9]的出现,以及具有极强表达能力的深度卷积网络的发展,深度网络在图像识别领域取得了巨大成功[10-12]。受此启发,在本研究中,用深度卷积网络模型去检测FFSP。由于深度网络往往需要大量的训练样本,而临床采集数据又相当困难,往往会导致网络训练出现过拟合现象,最后无法得到预期结果。对此,本研究采用迁移学习策略,结合数据增强技术,以改善深度网络识别FFSP结果。此外,还研究了不同深度的网络结构的FFSP识别性能。据了解,这是首次使用深度网络来自动识别FFSP的方法,对于常规超声检查和产前诊断具有巨大的应用前景。
1 方法
本研究的主要目标是从胎儿超声图像中精确识别出颜面部标准切面,创新性地提出了利用深度学习结合特殊数据预处理的方法,以及引入迁移学习方法来自动识别胎儿颜面部标准切面。下面将会对整个研究所用到的方法进行介绍,包括卷积神经网络原理、CNN网络结构、数据增强方法以及迁移学习策略。
1.1 卷积神经网络
受到生物神经系统的启发,卷积神经网络(convolutional neural network,CNN)在物体识别和检测领域已经获得了巨大成功。不同于传统的神经网络,卷积神经网络结合了局部连接和权值共享策略,因此使得卷积神经网络的参数大大减少,从而使构建更深层数的卷积网络成为可能。CNN结合了特征提取和特征分类两个过程,相比传统的手工特征表达分类方式,它可以根据给定的训练样本自动地学习特征。CNN一般由多个带参数的学习层构成,每个学习层都能学习一定特征,使得整个网络可以从输入图像中自动提取特征并不断组合、抽象化迭代,形成具有极强表达能力的高层级特征,并在最后进行分类输出。
CNN的主要组成成分是卷积层(convolutional layer, Conv),卷积层包含许多神经元,每个神经元带有一组可学习的权值和一个偏置项。这些权值会在网络训练的过程中不断改变。每个神经元对于前一层的局部区域进行感知,即将该局部区域作为其输入。假定xlj是第l层卷积层的第j个神经元的输出,且x(l-1)m(m=1,…,M)是第l-1层的神经元输出,M表示当前神经元的局部输入大小,那么xlj可以表示为
(1)

池化层(pooling layer, pool,本研究采用最大池化,因此在下面表示为max- pool)和全连接层是CNN的另一主要成分。在本研究中,将分类层softmax层作为全连接层的附属层。一般而言,在卷积层之间会加入池化层,池化层本身不带参数,其作用是减少卷积层的输出尺寸大小,从而大大减少整个网络的参数数量,同时增强卷积层输出特征的空间稳定性。因此,池化层在一定程度上可以避免网络出现过拟合的情况。全连接层(fully- connected layer,FC)类似于卷积层,同样是由许多神经元组成,但这里的神经元与前一层输入之间是全连接的方式,即每个神经元与前一层所有输入进行作用。
Softmax层是CNN网络的最后一层结构,其功能是对网络提取的特征进行分类。为了评价网络预测输出与输入图像真实标签之间的一致性,这里用到了损失函数。具体而言,假定Ii(i=1,…,N)为输入图像,Ti∈{0,1,…,K}是其对应的真实标签,则损失函数可以表示为
(2)
(3)
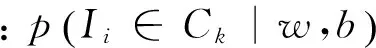
CNN训练的目的就是获取合适的权值参数,使整个网络能够针对目标数据自动学习合适的特征表达,从而让未知样本得到比较好的预测结果。
1.2 CNN结构设置
本课题主要研究了两种深度的CNN结构,其中16层的深度网络是基于VGGNet改进而来,作为对比,另一深度较浅的8层CNN网络是以AlexNet为设计基础的。对于这两个网络结构,在下文中分别称为CNN- 8和CNN- 16。针对CNN- 8,本研究分别采用随机初始化网络参数和迁移学习的方式来进行训练,训练的结果分别称为CNN- 8- RI和CNN- 8- TR。对于像CNN- 16这种深度的网络,在直接随机初始参数的情况下训练会出现收敛速度极慢的情况,在反向传播更新参数过程中会出现梯度消失的情况[13- 15],因此这里直接采用迁移学习的方式来初始化设置网络,相应结果表示为CNN- 16- TR。本实验中CNN的具体结构细节如表1所示。
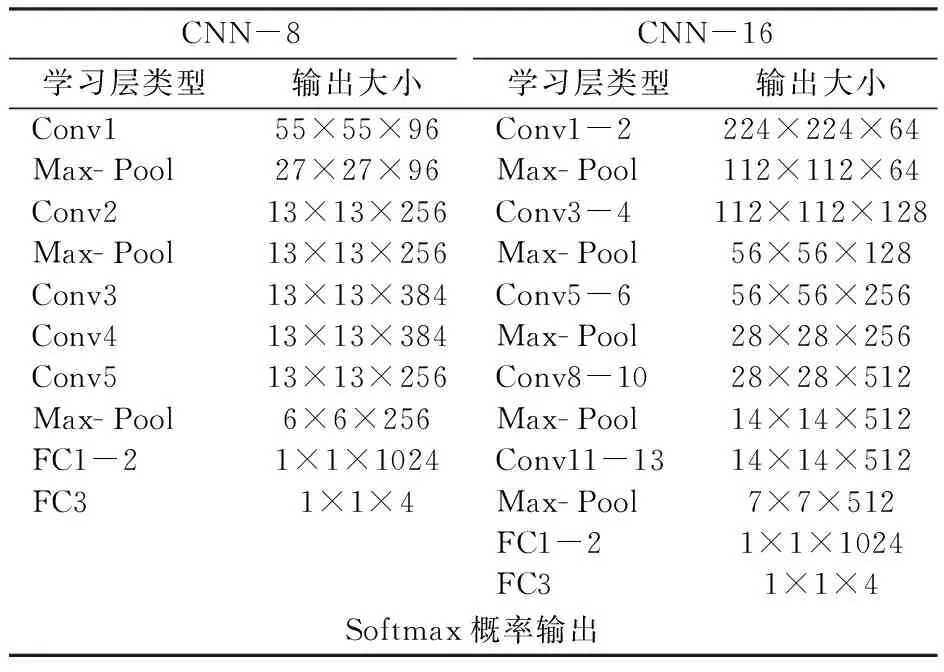
表1 CNN模型结构Tab.1 Architecture of our CNN models.
CNN-8结构主要以AlexNet为设计基础[11]。该网络在ImageNet等数据集上都取得了极大的成功,同时在2012 年大规模视觉识别挑战竞赛(Large Scale Visual Recognition Challenge, ILSVRC2012)中超过了其他各类深度学习模型,并取得了第一名的好成绩。因此,本研究的CNN- 8模型也由5层卷积层、3层池化层以及3层全连接层构成,不同的是,将第一层卷积层卷积核大小由11×11改为8×8[16],同时减少最后全连接层通道数,即由原来的4096-4096-1000减少至1024-1024-4。
CNN-16结构与VGGNet[12]类似,相对于其他CNN模型,VGGNet在深度上有了极大的提升,共有16与19层两个版本。在本研究中,CNN-16所有层的卷积核大小都为3×3,且卷积步长为1。一方面,小尺寸卷积核能够提取更为丰富的细节特征;另一方面,相对于5×5、7×7甚至11×11等较大尺寸的卷积核,使用3×3卷积核可以大大减少网络参数,从而防止潜在过拟合问题的出现。对于最后的全连接层,同样将其通道数从4096- 4096- 1000减少至1024- 1024- 4。
1.3 数据增强
CNN网络作为一种深度学习模型,对于训练数据量具有极大的要求。某种程度上,数据量的大小直接决定了网络的规模,以及网络的可训练性。临床上,收集大量且具有代表性的医学图像本身就相当困难,再加上这些数据还需要人工进行标注,因此构建高质量、大规模的医学图像数据集极具挑战。在保持图像本身标签不变的情况下,对图像数据进行多种变换来增大数据集的规模,是一种可行且有效的数据增强方式[11]。通过这种方式,可以扩大数据集规模,从而解决医学图像数据集因为数据量不足而无法训练CNN模型的情况。
在本研究中,同样采用了这种数据增强技术,即从原始FFSP数据集中,对每一张US图像在裁剪掉非数据区后进行采样,提取新的子图像。由于数据集的分布不均匀,标准切面与非标准切面的数量存在较大的差异,会导致带偏差的经验(biased prior)[17],这样的数据集训练网络会降低其最后分类性能。
为此,对胎儿颜面部超声非标准切面与标准切面图像分别提取不同数量的子图像,从而保持两者数量上的均衡。具体而言,对于初始的FFSP超声图像,其大小为768像素×576像素,首先裁掉周围的黑色区域(即非数据区),而后调整其尺寸至256像素×256像素,并从该图像下裁剪出5张224像素×224像素大小的子图像(左上、左下、右上、右下以及中心块),再水平翻转,从而每张初始图像最后总共得到10张子图像,如图2所示。
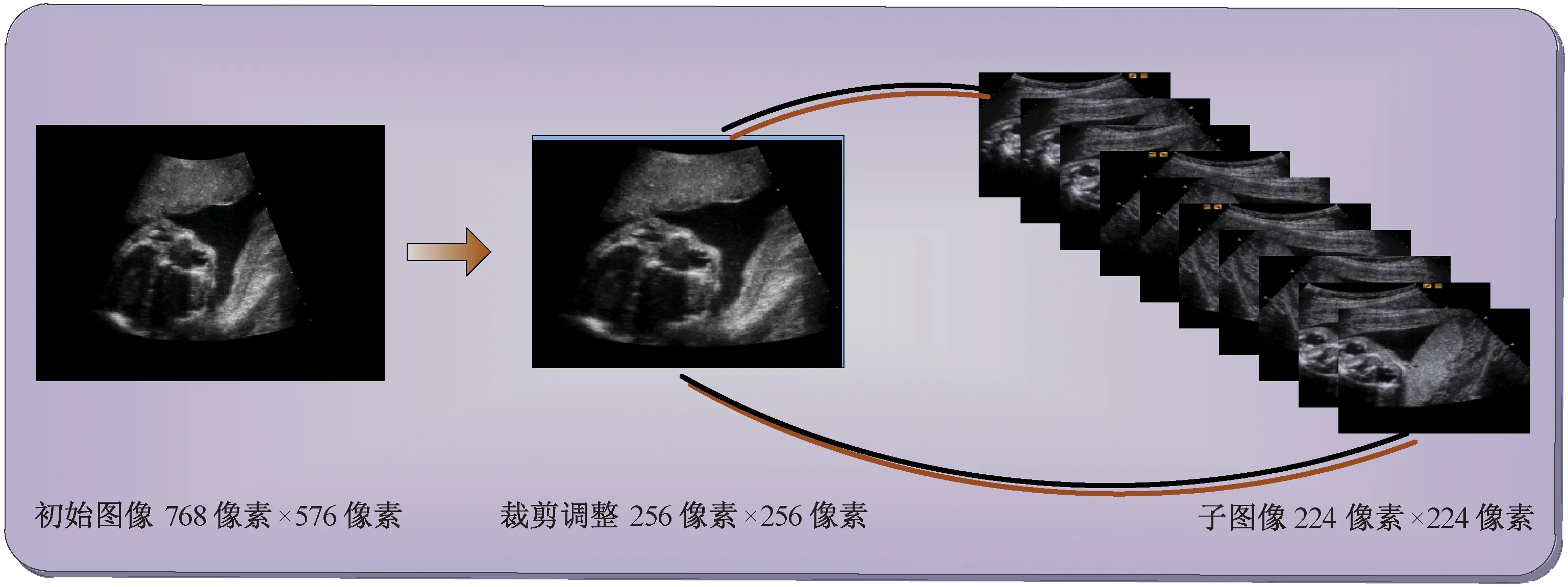
图2 数据增强Fig.2 Data augmentation
由于非标准切面的数量远远多于标准切面,因此,对于每张非标准切面,只提取其中间块子图像。相应地,在测试过程中,原始图像分类结果由其子图像类别分数综合决定。
1.4 迁移学习
即便CNN网络具有极强的特征表达能力,在很多医学图像上得到了成功应用,但训练的数据量依旧是最大的限制。因此,过拟合问题是有监督深度模型始终无法回避的一个话题。在这种情况下,先从大规模的数据集上预训练一个CNN网络,而后将该网络的参数复制到目标网络中,这是一个有效的网络初始化方式,可以大大加快网络训练速度,同时避免训练数据量过小而出现的过拟合现象。近来,有很多研究证明了该方法的有效性[18-20]。
这种迁移网络学习层参数的方法,其有效性在于网络提取的特征具有层级特性,不同层的学习层提取不同层次的特征信息。在网络的浅层部分,提取的特征是低层特征,即该类特征具有一般共性,相对于网络后面层所提取的特征而言,抽象度更低,表述的是目标颜色、轮廓等常见的基本特性,而且不同数据集得到的低层特征相似度很大。而在网络的后面层部分提取的高层特征则具有很大的特异性,即不同的数据集得到的高层特征往往差异很大。对此,在不同数据集训练的网络之间,可以通过迁移网络浅层学习层参数来共享低层特征。
目前,最常见的迁移学习方法是:首先在其他数据集上预训练一个基础网络,然后将该网络的前层参数复制到目标网络对应层,而后目标网络余下层则随机初始化参数。根据训练的方式不同,迁移学习可以分为两种:一种是保持这些迁移过来的学习层参数固定,训练过程中只改变后面随机初始化的学习层参数;另一种则是在训练过程中微调这些迁移的学习层参数。根据文献[20]的研究结果,由于ImageNet数据集与FFSP数据集之间的图像差异巨大,因此迁移层数较多的情况下,采取前一种固定迁移参数的训练方式并不适用,因此在本研究中采取微调的迁移学习方式。
在本实验中,首先在ImageNet数据集上预训练AlexNet与VGGNet,分别作为CNN-8与CNN-16模型的基础网络,再分别复制AlexNet与VGGNet除最后3层全连接层外所有卷积层参数至CNN-8与CNN-16对应学习层。在训练过程中,对于迁移参数层与随机初始化参数学习层分别设置不同学习率。具体而言,CNN-8与CNN-16所有迁移参数的学习层学习率设置为0.001,并在训练过程中逐渐减小。随机初始化参数的学习层学习率设置为0.01,在训练过程中逐渐减小。图3是本实验中所采用的迁移学习方法的整个流程。
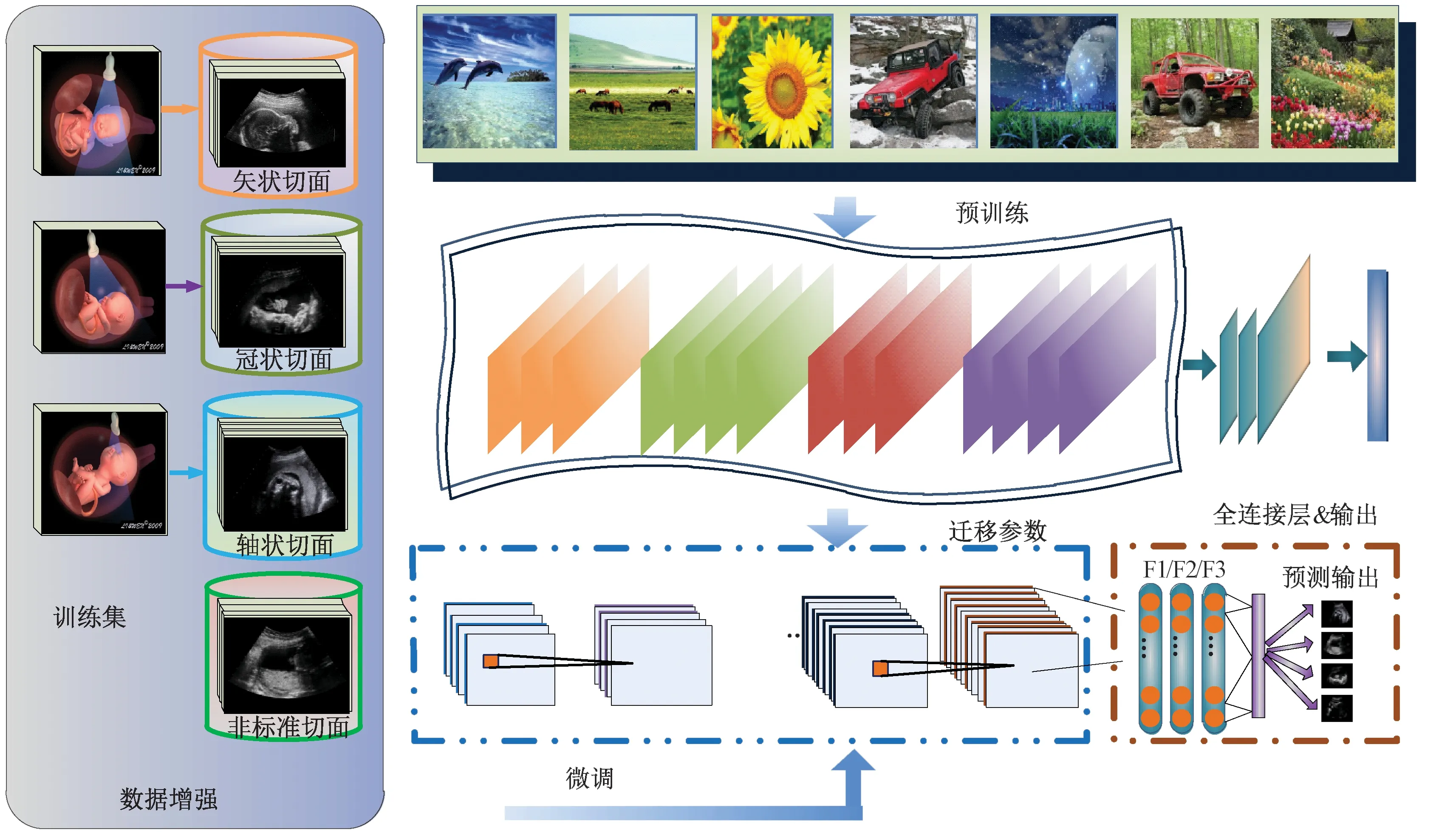
图3 迁移学习流程Fig. 3 Flowchart of our fine- tuning strategy
1.5 实验验证
本研究协议经本地协会伦理委员会批准与审核,相关课题均获许可通知。
1.5.1 实验数据集及系统设置
1)训练集:在本实验中,所有胎儿超声图像数据均由本项目组成员采集,原始超声数据由深圳妇幼保医院的专门超声医生扫描并标注,超声仪器型号为西门子Acuson Sequoia 512型,胎儿孕周为20~36周。数据集图像由超声原始格式数据分解成单帧位图,整个训练集包括375张轴状标准切面(axial plane)、257张冠状标准切面(coronal plane)、405张矢状标准切面(sagittal plane)以及3 812张非标准切面(others plane)。如本文第1.3节所述,本研究采用数据增强的方式,分别将轴状标准切面增至3 750张,冠状标准切面增至2 570张,矢状标准切面增至4 050张,非标准切面保持3 812张不变,故数据增强后整个FFSP数据集共包含14 182张图像。最后,对整个训练集提取均值,即每幅图像减去整个训练集图像均值。
近年来,重庆市各区县职业教育竞相发展、百花齐放。2017年,全市中职学校达182所,在校生39.8万人,校均学生数2884人。重庆市云阳县是人口大县、教育大县,在职业教育发展方面具有一定代表性。通过分析云阳县的情况,可对全市区县职业教育发展态势进行大致了解和把握。
2)测试集:在本研究中,测试集共包含2 418张图像(其中轴状切面axial plane 491张、冠状切面coronal plane 127张、矢状切面sagittal plane 174张、非标准切面others plane 1 626张)。在测试过程中,同样采用数据增强的方式,对每张测试图像裁剪出10张子图像,再综合训练好的网络对这10张子图像预测分数,得到原图像的预测结果(10- crop testing)[11]。
3)系统执行:本研究采用Matlab CNN工具包Matconvnet[21]进行CNN设计与测试,整个实验运行硬件环境为8核2.9 GHz CPU、128 GB内存计算机。训练整个CNN- 8网络耗时10 h,而训练CNN- 16网络耗时4 d。测试阶段则速度较快,加载完训练好的网络,单张图像只需要几秒钟就能得到预测结果。

图4 t- SNE可视化实验结果。(a) 训练集初始数据;(b) CNN- 16- TR训练集特征;(c) CNN- 8- TR训练集特征;(d) CNN- 8- RI训练集特征;(e) 测试集初始数据;(f) CNN- 16- TR测试集特征;(g) CNN- 8- TR测试集特征;(h) CNN- 8- RI测试集特征Fig. 4 t- SNE visualizations of experimental results. (a) Raw training data; (b) CNN- 16- TR features of training data; (c) CNN- 8- TR features of training data; (d) CNN- 8- RI features of training data; (e) raw testing data; (f) CNN- 16- TR features of testing data; (g) CNN- 8- TR features of testing data; (h) CNN- 8- RI features of testing data
1.5.2 定性与定量方法说明
为了更好地分析比对不同CNN模型分类性能,本研究从定性和定量两个角度进行结果讨论。首先,通过可视化CNN网络提取的高层特征,直观展示CNN分类结果;其次,通过分析通用分类参数指标,具体评价CNN网络识别FFSP性能。
定性评价即对数据特征进行可视化,数据可视化是显示高维特征向量常用的方法,可以很直观地表示特征的分布。在本研究中,采用t- SNE方法[22],分别对训练集初始数据、测试集初始数据以及由CNN提取的训练集与测试集高层特征进行可视化。对于初始图像数据(像素数据),首先将其转换成一维行向量,即每张图像得到一个行向量,再将所有图像向量拼接成二维矩阵,最后将这些行向量连同图像本身标签一同输入至t- SNE函数。对于特征的可视化,则先提取CNN倒数第二层(即第二层全连接层)输出,得到的1024维向量即为特征向量,再按照之前可视化图像像素数据的方法,将所有图像特征及相应标签输入至t- SNE函数。
在定量评价过程中,采用国际通用分类评价参数:准确率(precision)、精确率(accuracy)、召回率(recall)、F1分数(F1- score)。为了更好地评估本研究方法的优势,除了对CNN模型分类结果进行定量的分析,同时还加入了与通用人工特征分类方法的对比。目前,这些主流的分类识别技术主要基于人工特征,同时结合通用分类器进行分类识别,该类方法的基本思想是先从图像中提取特征,同时对特征进行编码,再训练分类器进行分类识别,如基于DSIFT特征的编码方式识别,包括直方图编码BoVW模型、局部特征聚合描述符VLAD编码以及FV向量编码。笔者先前的研究工作就是利用这些方法进行FFSP的自动识别[1,4- 5],对比结果见本文第2.2节所述。
2 结果
2.1 定性分析结果
2.2 定量分析结果
表2给出了不同CNN模型以及人工特征结合分类器方法识别FFSP的结果。DSIFT人工特征方法与先前的研究工作[4- 5]类似,BoVW模型中聚类中心为1 024,单张图像采用空间金字塔模型,总共划分7个区域(2×2, 3×1)来进行特征提取,最后特征维度为7 168。VLAD模型中聚类中心为64,最后特征维度44 800。FV模型中高斯元素个数为64,最后特征维度71 680。
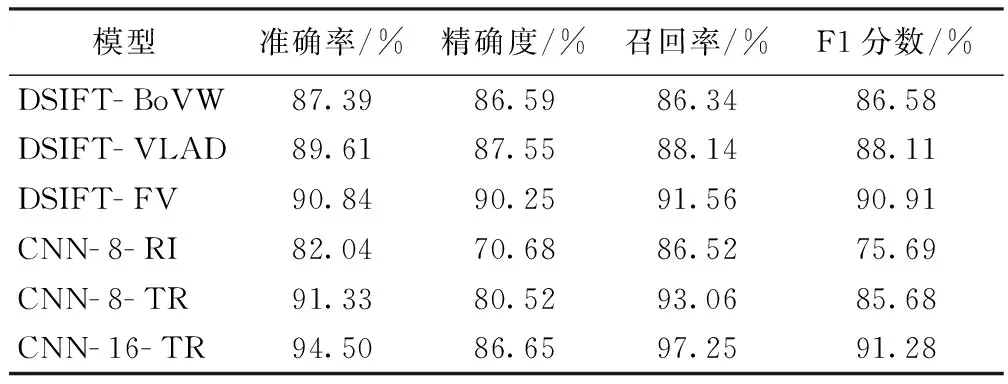
表2 CNN识别结果Tab.2 Recognition results.
从表2可以看出,FV分类结果在各项参数上均高于BoVW以及VLAD。同时,在未使用迁移学习的情况下,基于DSIFT特征的3类模型结果均好于深度网络CNN- 8- RI。其中,最大原因在于深度网络优化严重依赖于大量训练数据,而在本研究中的4类切面总共只有14 182张图像,数据规模相对较小。然而,利用大规模自然图像数据预训练网络,再利用目标数据(超声图像)对网络微调(迁移学习),可以有效改善深度网络因训练数据不足而导致的性能下降问题。在表2中,微调后的网络CNN- 8- TR结果相对于CNN- 8- RI有显著改善,其中准确率提升约8%,精确度提升约10%。另外,网络结构深度对于分类结果也有较大影响,更深层网络表达能力要更强,在同样使用迁移学习条件下,CNN- 16- TR较CNN- 8- TR在准确率上有约3%的提高,准确度提升约6%。因此,加深CNN模型的深度能够很好地改善最后的分类效果。
图5是各个CNN网络的分类性能ROC曲线和混淆矩阵(见下页)。对于4类切面,识别率相对低的是非标准切面,原因在于非标准切面数据中含有大量与其他3类切面差异较小的图像,这对于识别有较大影响。总体而言,所有CNN模型识别结果都表现良好,尤其是在使用微调策略以后,性能都优于人工特征分类结果。虽然CNN具有极强的分类性能,但在实验结果中也观察到了一些值得注意的细节:首先,在测试阶段,每张图像综合其10张子图像的预测结果,这种10- crop testing比直接测试单张图像的结果提升了3%左右;其次,采用迁移学习策略时,网络训练收敛的速度大大加快,比随机初始化参数的网络收敛时间快50%以上。
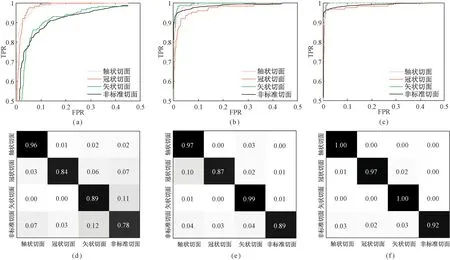
图5 CNN模型分类ROC曲线与混淆矩阵。(a) CNN- 8- RI ROC曲线;(b) CNN- 8- TR ROC曲线; (c) CNN- 16- TR ROC曲线;(d) CNN- 8- RI混淆矩阵;(e)CNN- 8- TR混淆矩阵;(f) CNN- 16- TR混淆矩阵Fig.5 ROC curves and confusion matrixes for our CNN models. (a) ROC curve of CNN- 8- RI;(b) ROC curve of CNN- 8- TR;(c) ROC curve of CNN- 16- TR;(d) Confusion matrix of CNN- 8- RI;(e) Confusion matrix of CNN- 8- TR;(f) Confusion matrix of CNN- 16- TR
3 讨论
深度网络作为一种表达学习方法[23],通过组合迭代不同层次的特征,最后形成高层抽象特征,这种特征相对于传统的人工特征(SIFT,HoG)而言,在概念表达方面更具鲁棒性或者说更具不变性。而且,深度网络可以根据给定的数据,学习到对应的特征,因此,其泛化能力更强,可以推广应用到不同的图像领域。近年来,由于计算机的发展以及数据集规模的扩大,深度学习模型在图像分类检测领域内取得了广泛应用。然而,深度学习模型普遍要求足够多的训练数据量,否则网络训练会出现过拟合问题。在不同的图像领域,显然数据采集的难度不尽相同,且自然图像数据集的规模往往远大于医学类图像数据。因此,医学图像领域内,深度网络应用的最大困难在于数据集规模的限制。
利用自然图像数据集训练基础网络,再进行迁移学习,是解决当前不同图像领域应用深度网络数据量不足的有效方式。因此,本研究结合了迁移学习与数据增强的方式来综合提升深度网络分类性能。最后的结果分析也表明,其FFSP分类性能要远远好于笔者之前的研究,即采用人工特征结合分类器分类的方法。
然而,本研究依然存在一些不足之处。首先,测试集数量有限,只有2 418张测试图像,虽然在一定程度上可以反映CNN模型的分类性能,但更大量的数据才能更具说明性,这也是以后所需改进的方向之一。其次,在测试结果方面,依然存在提升的空间,不少接近FFSP的非标准切面被识别为标准切面,这跟图像本身的噪声以及差异度小有极大的关系。在未来的研究中,可以通过给训练集图像随机添加噪声来增加网络识别的稳定性。另外,临床医生在寻找FFSP过程中,会考虑前后帧图像的上下文信息,因此在网络训练过程中加入当前图像上下文信息,可以消除FFSP与非FFSP类内差异小所带来的干扰。
4 结论
在本研究中,提出了用深度卷积网络的方式来识别胎儿颜面部的超声图像,同时分析研究了不同深度结构的CNN模型对于FFSP分类的结果。为了防止由于训练数据集数量不足而引发网络训练出现过拟合问题,采用了数据增强(data augmentation)结合迁移学习的方式来改善网络分类结果。最后的结果表明,深度网络可以有效地识别FFSP标准切面,同时更深层的深度网络能够带来更好的分类性能。因此,深度网络与迁移学习的结合在临床应用方面具有极大的前景,值得进一步探索和研究。
[1] Lei Baiying, Zhuo Liu, Chen Siping, et al. Automatic recognition of fetal standard plane in ultrasound image [C]//International Symposium on Biomedical Imaging. Beijing: IEEE, 2014:85- 88.
[2] Chen Hao, Dou Qi, Ni Dong, et al. Automatic fetal ultrasound standard plane detection using knowledge transferred recurrent neural networks [C] // Medical Image Computing and Computer- Assisted Intervention. Munich:Springer International Publishing, 2015: 507- 514.
[3] Chen Hao, Ni Dong, Qin Jing, et al. Standard plane localization in fetal ultrasound via domain transferred deep neural networks[J]. IEEE J Biomed Health Inf, 2015. 19(5): 1627- 1636.
[4] Lei Baiying, Tan Eeleng, Chen Siping, et al. Automatic recognition of fetal facial standard plane in ultrasound image via fisher vector[J]. PLoS ONE, 2015, 10(5): e0121838.
[5] Lei Baiying, Yao Yuan, Chen Siping, et al. Discriminative learning for automatic staging of placental maturity via multi- layer fisher vector[J]. Scientific Reports, 2015. 5: 12818.
[6] Rahmatullah B, Papageorghiou A, Noble J. Automated selection of standardized planes from ultrasound volume[C] //Machine Learning in Medical Imaging.Toronto: Springer Berlin Heidelberg, 2011: 35-42.
[7] Zhang Ling, Chen Siping, Chin CT, et al. Intelligent scanning: automated standard plane selection and biometric measurement of early gestational sac in routine ultrasound examination[J]. Medical Physics, 2012. 39(8): 5015- 5027.
[8] Ni Dong, Li Tianmei, Yang Xin, et al. Selective search and sequential detection for standard plane localization in ultrasound[C] //Medical Image Computing and Computer- Assisted Intervention. Nagoya: Springer Berlin Heidelberg, 2013: 203- 211.
[9] Deng Jia, Dong Wei, Socher R, et al. Imagenet: A large- scale hierarchical image database[C]//Computer Vision and Pattern Recognition. Anchorage: IEEE, 2009: 248- 255.
[10] Szegedy C, Liu Wei, Jia Yangqing, et al.Going deeper with convolutions[C]//Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1- 9.
[11] Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks[C]//Neural Information Processing Systems. Lake Tahoe: Nips Foundation, 2012: 1097- 1105.
[12] Simonyan K, Zisserman A. Very deep convolutional networks for large scale image recognition[J]. Computer Science, 2014.
[13] Bengio Y, Simard P, Frasconi P. Learning long- term dependencies with gradient descent is difficult[J]. IEEE Trans Neural Netw, 1994, 5(2): 157- 166.
[14] Hochreiter S. The vanishing gradient problem during learning recurrent neural nets and problem solutions[J]. International Journal of Uncertainty, Fuzziness and Knowledge- Based Systems, 1998. 6(02): 107- 116.
[15] Hinton G, Osindero S, The Y. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527- 1554.
[16] Zeiler M, Fergus R. Visualizing and understanding convolutional networks[C]//Computer Vision-ECCV. Zürich: Springer International Publishing, 2014: 818- 833.
[17] Shin H, Roth H, Gao Mingchen, et al. Deep convolutional neural networks for computer- aided detection: CNN architectures, dataset characteristics and transfer learning[J]. IEEE Trans on Medl Imaging, 2016, 35(5): 1285- 1298.
[18] Donahue J, Jia Yangqing, Vinyals O, et al. Decaf: A deep convolutional activation feature for generic visual recognition[C]//International Conference on Machine Learning. JMLR.org, 2014: 1-647.
[19] Razavian A, Azizpour H, Sullivan J, et al. CNN features off- the- shelf: an astounding baseline for recognition[C]//Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 806- 813.
[20] Yosinski J, Clune J, Bengio Y, et al. How transferable are features in deep neural networks?[C]//Neural Information Processing Systems. Montréal: Nips Foundation, 2014: 3320- 3328.
[21] Vedaldi A, Lenc K. MatConvNet: Convolutional neural networks for matlab[C]//The ACM International Conference. ACM, 2015:689-692.
[22] Maaten L, Hinton G. Visualizing data using t- SNE[J]. J Mach Learn Res, 2008. 9: 2579-2605.
[23] Yann LC, Yoshua B. Geoffrey H. Deep learning[J]. Nature, 2015. 521(7553):436- 444.
Fetal Facial Standard Plane Recognition via Deep Convolutional Neural Networks
Yu Zhen1Wu Lingyun1Ni Dong1Chen Siping1Li Shengli2Wang Tianfu1*Lei Baiying1*
1(Schoolof Biomedical Engineering, Shenzhen University, National- Regional Key Technology Engineering Laboratory for Medical Ultrasound, Guangdong Key Laboratory for Biomedical Measurements and Ultrasound Imaging, Shenzhen 518060, Guangdong, China)2(Department of Ultrasound, Affiliated Shenzhen Maternal and Child Healthcare, Hospital of Nanfang Medical University, Shenzhen 518060, Guangdong, China)
The accurate recognition of fetal facial standard plane (FFSP) (i.e., axial, coronal and sagittal plane) from ultrasound (US) images is quite essential for routine US examination. Since the labor- intensive and subjective measurement is too time- consuming and unreliable, the development of the automatic FFSP recognition method is highly desirable. In this paper, we proposed to recognize FFSP using different depth CNN architectures (e.g., 8- layer and 16- layer). Specifically, we trained these models varied from depth to depth and mainly utilize two training strategy: 1) training the “CNN from scratch” with random initialization; 2) performing transfer learning strategy by fine- tuning ImageNet pre- trained CNN on our FFSP dataset. In our experiments, fetal gestational ages ranged typically from 20 to 36 weeks. Our training dataset contains 4849 images (i.e., 375 axial plane images, 257 coronal plane images, 405 sagittal plane images and 3812 non- FFSP images). Our testing dataset contained 2 418 images (i.e., 491 axial plane images, 127 coronal plane images, 174 sagittal plane images, and 1626 non- FFSP images). The experiment indicated that the strategy of transfer learning combined with CNN improving recognition accuracy by 9.29%. When CNN depth changes from 8 layer to 16 layer, it improves the recognition accuracy by 3.17%. The best recognition accuracy of our CNN model was 94.5%, which was 3.66% higher than our previous study. The effectiveness of deep CNN and transfer learning for FFSP recognition shows promising application for clinical diagnosis.
fetal facial standard plane recognition; ultrasound image; deep convolutional network; transfer learning
10.3969/j.issn.0258- 8021. 2017. 03.002
2016-06-08, 录用日期:2016-09-09
广东省科技创新重点项目(2014KXM052)
R318
A
0258- 8021(2017) 03- 0267- 09
*通信作者(Corresponding author),E- mail: tfwang@szu.edu.cn, leiby@szu.edu.cn
