基于某电商平台评论数据的文本挖掘分析
2017-09-05闫洲
闫洲
【摘 要】本文是对抓取到的6131条某电商平台上的某品牌面膜的消费者评论数据做文本挖掘分析。第一步是对抓取到的评论数据进行基本的数据预处理、中文分词;接下来通过建立语义网络和LDA主题模型等数据挖掘模型,实现对文本评论数据的情感倾向性分析以及对其所隐藏信息的挖掘分析,得到有价值的潜在内容;最后提出相应的可行性的建议。
【关键词】文本挖掘;电商平台
一、引言
随着中国互联网经济的发展,在“互联网+”的背景下,电子商务得到了快速发展,网上购物在中国越来越流行。人们在工作和生活之余对于网上购物的需求变得越来越多样化,这样的发展状况给天猫、京东等电商平台带来了很好的发展機遇,但是与此同时,多样化的需求也推动了更多电商平台的崛起,引发了更为激烈的竞争。在电商平台这样激烈竞争的大背景下,除了提高商品的质量、压低商品的价格和合适的营销手段外,了解更多消费者的心声、发现商品痛点对于电商平台来说也变得越来越有必要。而这其中最为有效的方式就是利用消费者的文本评论数据,进行潜在信息的一种数据挖掘分析工作,这对于电商平台以及产品都会有很大的意义。
二、研究目的与方法
本文选取了某电商平台上的某品牌面膜作为研究对象,抓取了2017年1月至2017年6月6个月共计6131条消费者评论数据做文本挖掘分析。预期得到的目标如下:(1)分析产品评论的用户情感倾向;(2)从评论文本数据中挖掘出该品牌的优点与不足。
本文的研究主要分为以下3个步骤:(1)对抓取的数据进行基本的操作处理,包括数据预处理、中文分词等操作;(2)文本评论数据经过处理后,运用多种手段对评论数据进行多方面的分析;(3)从对应结果的分析中获取文本评论数据中有价值的内容。
三、研究过程
(一)评论预处理
文本评论数据里面存在大量价值含量很低甚至没有价值含量的条目,如果将这些无价值的数据也进行分词、词频统计甚至情感分析,会对分析造成很大的影响,得到的分析结果也会存在问题。那么在利用这些文本评论数据之前就必须先进行文本预处理,把大量的诸如此类的无价值含量的评论数据去除。
对这些文本评论数据的预处理主要由三个部分组成:文本去重、机械压缩去词以及短句删除。
1.文本去重
本文采用一些相对简单的文本去重思路。由于相近的评论语句存在了不少是有用的评论,去除掉这类语句当然是不合适的。那么为了保存足够多的有用语料,就只能针对于完全重复的语句进行处理。因此,处理这样的完全重复的语句,直接采用最方便的比较删除法,即两两对比,如果完全相同就去除的方法。
2.机械压缩去词
机械压缩去词实际上要处理的语句就是评论语句中有连续累赘重复的部分,从一般的评论偏好角度来讲,一般人制造无意义的连续重复只会在开头和结果进行,如“为什么为什么为什么快递这么慢?!”和“效果很好很好很好”。因此我们只对评论文本开头和结尾的连续重复进行机械压缩去词的处理。
连续累赘重复的判断可通过建立两个存放国际字符的列表来完成,先放第一个列表,再放第二个列表,一个个读取国际字符,并按照不同情况,将其放入第一或第二个列表或触发压缩判断,若得出重复(及列表1与列表2有意义的部分完全一对一相同)则压缩去除,这样当然就要有相关的放置判断及压缩规则。在机械压缩去词处理的连续累赘重复的判断及压缩规则设定的时候,必然要考虑到词法结构的问题。
3.短句删除
完成机械压缩去词的操作后,需要进行短句删除。虽然精简的叙述在一些时候是一种很良好的习惯,但是由语言的特点可知,从根本上说,字数越少其所能够表达出的意义就会越少。想表达特定的意思就需要有相应数量的字数,太少的字数的评论语句必然是没有意义的评论。比如三个字,就只能表达诸如“质量差”、“很不错”等等。基于以上原因,我们需要删除掉这些过短且没有意义的文本评论。
显然,短句删除中最重要的环节就是保留评论的字数下限的确定。因为这个操作没有明确的固定标准,只能结合实际语句来确定。一般6到10个国际字符是较为合理的下限,本文我们设定下限为7个国际字符,即经过机械压缩去词之后得到的语句若小于等于6个国际字符,则将该语句删除。
(二)文本评论分词
在中文语句中,通过分界符只能对字、句和段落进行简单的划分,而对于“词”或者说“词组”来讲,它们之间的边界非常模糊,没有一个真正严格意义上的分界符,不容易划分。所以,在对文本评论数据进行挖掘分析时,要对这些文本数据进行分词,将连续的字序列按照一定的规范重新排列组合成一个词序列。
三、模型构建分析
(一)情感倾向性分析
为了分析消费者对一件产品的总体情感倾向,我们可以对该商品的评论数据集做情感倾向分析,以此得到对商品的总体印象。本文是基于词向量和深度学习方法对评论数据集做情感倾向性分析。
评论集子集的标注与映射。利用词向量构建的结果,我们进行评论集子集的人工标注,正面评论标为1,负面评论标记为2。然后我们将每条评论映射为一个向量,将分词后评论中的所有词语对应的词向量相加做平均,使得一条评论对应一个向量。由于数据量过大,纯人工标注需要耗费大量时间,所以这里我们仍然使用ROSTCM6软件情感分析的功能进行评论数据集的正负面标注。
(二)基于语义网络的评论分析
使用语义网络对评论进行进一步的分析,通过语言关系构建有利于滤取产品的独有优势、各产品抱怨点以及顾客购买原因等,并结合以上分析对品牌产品的改进提出建议。要进行语义网络分析,首先我们要分别对两大组重新进行分词处理,并提取出高频词。因为只有高频词之间的语义联系才是真正有意义的,个性化词语间关系不具代表性。然后在此基础上过滤掉显著的无意义的成分,减少分析干扰。最后再抽取行特征,处理完后便可进行两组的语义网络的构建。endprint
(三)基于LDA模型的主题分析
基于语义网络的评论分析进行初步数据感知后,我们从统计学的角度,对主题的特征词出现频率进行量化表示。本文使用机器标注来将文本分为正面和负面评论数据,仍然采用ROSTCM6中的情感分析做机器分类,生成“正面情感结果”、“负面情感结果”和“中性情感结果”,我們不处理“中性情感结果”,直接对“正面情感结果”和“负面情感结果”数据进行LDA主题分析。
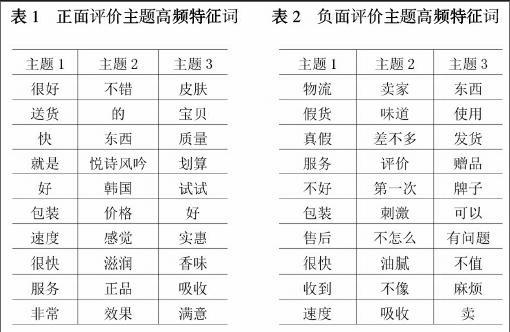
由ROSTCM6进行情感分析得到的数据还包含每条评论的评分前缀,因此,我们需要删除前缀评分。由于文本数据是用unicode进行编码,在处理前,需要另存为UTF-8编码再进行前缀评分删除。删除评分前缀后,要进行文本分词。在经过LDA主题分析后,评论被分为三个主题,每个主题下生成10个最有可能出现的词语,下表表示了正面评论文本的潜在主题和负面评论文本的潜在主题。
根据正面评价潜在主题的特征词提取结果,主题1中的高频特征词,即很好,送货、快、就是、好、包装、速度等,主要反映了该电商平台送货快、服务非常好;主题2中的高频特征词主要反映了产品的效果,是正品;主题3中的高频特征词主要是产品是否划算、是否值得购买。
根据负面评价潜在主题的特征词提取结果,主题1中的高频特征词,即物流,假货、真假、服务、不好、包装、售后等,主要反映了产品包装不好、客服售后态度不好;主题2中的高频特征词主要反映了产品的使用效果不好;主题3中的高频特征词主要是产品是否为正品。
四、结论
综合以上的分析可以看出,该品牌面膜的优势集中在:效果好、价格实惠;该电商平台的优势集中在:服务好、快递效率高。而用户抱怨的集中点主要是个别使用效果不好、客服态度以及售后服务上。为此我们提出以下建议:
(一)由于该电商平台物流的特殊性,在一二线城市的分布比较完整,覆盖面广,但是在三线城市以下,尤其是乡镇城市,商品配送的效率还有待提高。同时在物流运输环节,也要注意保存商品的完整性。
(二)提高客服及售后服务的规范性,客服的服务态度和商品售后服务的保障是影响消费者评价的重要因素。
【参考文献】
[1]阮光册.基于文本挖掘的网络新闻报道差异分析[J].情报科学,2012,30(1):105-109.
[2]陈江涛,张金隆,张亚军.在线商品评论有用性影响因素研究:基于文本语义视角[J].图书情报工作,2012,56(10):119-123.
[3]张志飞,苗夺谦,张亚军.基于LDA主题模型的短文本分类方法[J].计算机应用,2013,33(6):1587-1590.
[4]闫强,孟跃.在线评论的感知有用性影响因素——基于在线影评的实证研[J].中国管理科学,2013,21(S1):126-131.endprint
