Logistic回归模型原理介绍及实例分析
2017-09-03姜阿丽
姜阿丽
(云南财经大学 云南 昆明 650000)
Logistic回归模型原理介绍及实例分析
姜阿丽
(云南财经大学 云南 昆明 650000)
我们知道,在日常处理的回归模型中,大多数都属于线性回归模型,然而有一些研究的问题中,其因变量是二分类变量,此时我们则需要用到logistic模型,本篇文章我们主要来介绍Logistic模型的原理以及其优缺点,并研究其适用的范围,然后我们利用高校就业去向的例子来加深对模型的理解,并根据模型的结果进行分析。
logistic模型;实例分析
一、Logistic回归模型理论
(一)Logistic回归模型原理
在我们的日常处理的回归模型中,大多数都属于线性回归模型,他们可以用线性表达式进行表达,y=βTx+b,但是,有些时候,我们接触的问题,它们的因变量为二分类变量,即因变量是非连续变量,这个时候我们就需要对模型进行一些简单的调整与变换,此时就要引出另一个概念:logistic回归模型。
logistic回归是通过函数Ln将因变量y来对应一个概率p,然后将其结果间接转化成一个连续变量。比如我们研究一些现象,其发生的概率为p,很明显它为概率值,有[0,1]的取值范围,我们就会很难去用线性模型描述概率p与自变量的关系,因此我们需要利用Logit变换来进行处理,我们通常的把出现某种结果的概率与不出现的概率之比作为比值,然后再把取值进行取对数处理,变换如下:
其中当p从0→1时,Logit(p)从-∞→+∞,另外从函数的变形可得如下等价的公式:
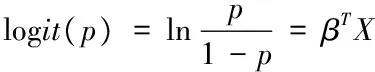
此时我们称满足上面条件的回归方程为Logistic线性回归。
(二)Logistic模型优缺点
对于logistic模型,我们也说到它可以解决一些普通线性回归模型解决不了的问题,存在一定的优点,例如:模型不需要样本数据作严格的假设条件并且可以对每个变量进行显著性检验,另外,logistic模型对于用来判别二分类变量问题有良好的效果,且使用该模型还可以显著降低犯第一类错误的概率。但是
Logistic模型也有一定的缺点,例如:它在采用极大似然法进行参数估计时要求样本的数量要足够,并且对中间区域判别敏感性较强,导致判别结果不稳定。而且当概率接近1或者0的时候还会出现低估的现象,因此我们仍然需要继续研究新的方法来对模型进行改进。
二、实例分析
我们对本科毕业生的去向做了一个调查,调查了40个学生,分析影响毕业去向的相关因素,我们自变量主要四个,分别为x1为专业课成绩,x2为英语成绩,x3为性别,x4为月生活费(单位:元),其中性别取值“1”=男生,“0”=女生。因变量为毕业去向,取值分别为0和1,“1”=工作,“0”=继续深造,
对于这种因变量为二分类变量的情况,我们选择用logistic回归来进行拟合,分析影响毕业去向的因素。
我们利用R3.3.3软件来建立logistic模型,因为我们的被解释变量为二分类变量,因此我们需要首先将其转化为因子,然后模型1中我们加入所有的解释变量来检验各解释变量的显著性,回归系数的显著性检验我们选用的统计量为Z统计量,结果显示:变量x1、x2、x3、x4检验的p值分别为0.01105、0.10839、0.95211、0.04368,因此可以看出在显著性水平α=0.05的水平下,解释变量x2、x3检验的结果是不显著的,因此我们选择将其剔除,重新对模型进行拟合,拟合结果如下表所示:
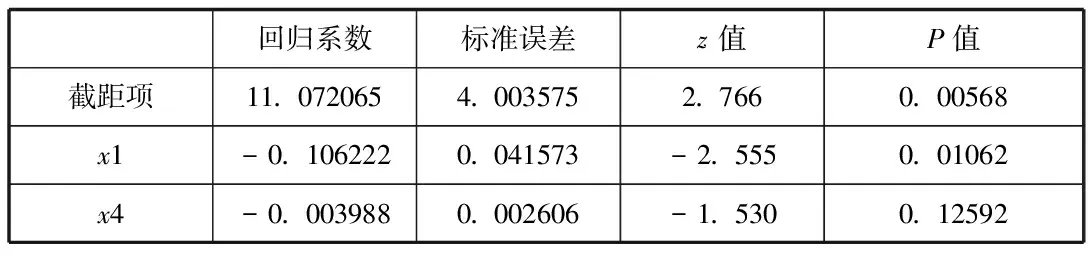
表1 回归系数
我们从表1可以看出,删除解释变量x2、x3之后,解释变量x1、x4检验的p值分别为0.01062、0.12592,在显著性水平α=0.05的条件下,勉强通过检验,我们又计算了比较全模型与剔除变量x2、x3后的模型的AIC值,分别为48.444、46.448,发现,剔除变量之后的模型较优,下面我们根据拟合结果写出模型表达式:
三、模型过散布诊断
所谓模型过散布,它是指观测到的响应变量的方差大于期望的二项分布的方差。过散布将会导致奇异的标准误检验以及不精准的显著性检验,检验过散布的一种方法是比较二项分布模型的残差偏差与残差自由度,即:
我们拟合出的模型进行过散布检验,发现在指定参数为family和binomial时,我们可以看到默认的散布系数φ为1,检验结果看出其φ的估计值明显小于1,因此我们能判定该模型没有出现过散布的情况。
四、结论
因此对于被解释变量为二分类变量,我们不能用到传统的回归模型解决时,我们可以选择logistic回归模型进行拟合,并且使用logistic模型预测还能够降低犯第一类错误的概率。我们利用logistic模型进行实例分析结果可以看出,影响毕业去向的主要因素为专业课成绩以及每月生活费的数量,且一个人专业课成绩每增加一分,则就业与继续深造的比值变为原来的exp(-0.106222)倍,约为0.899倍,说明了专业课成绩越好的人就业的可能性越小,继续深造的可能性越大。另外一个人每月的生活费每增加一分,则就业与继续深造的比值变为原来的exp(-0.003988)倍,约为0.996倍,说明了每月生活费越多的人就业的可能性越小,继续深造的可能性越大。
[1]刘小秦,林元,杨冬华,晁丽丽,李娟生.两水平logistic回归模型在高血压患病影响因素分析中的应用[J].中国卫生统计,2013,673-675.
[2]贾鹏芳.高职会计专业就业影响因素分析——基于Logistic回归的研究[J].价值工程,2015,228-230.
姜阿丽(1996-),女,汉族,安徽阜阳人,硕士研究生,云南财经大学,统计与数学学院学院,应用统计专业。
