基于Solr的混合介质存储在淘宝系统中的研究与应用
2017-09-03汪洋,崔炜
汪 洋,崔 炜
(1.烽火通信科技股份有限公司 南京研发部,江苏 南京 210019;2.武汉邮电科学研究院 湖北 武汉 430000)
基于Solr的混合介质存储在淘宝系统中的研究与应用
汪 洋1,崔 炜2
(1.烽火通信科技股份有限公司 南京研发部,江苏 南京 210019;2.武汉邮电科学研究院 湖北 武汉 430000)
DT时代已经来临,开源搜索引擎已经成为各大公司检索海量数据的主流,其中Solr以其支持多种格式索引,高效性,高灵活性,高可扩展性,深受广大爱好者以及各大公司青睐,本文基于提高Solr检索速度和对数据管理便捷性,提出了混合介质存储分盘管理查询并且设置优先级异步并发的改进方案,通过在淘宝用户评论检索中的研究与应用,证实了方案能够极大优化了性能并且提高检索速度。
Lucene;Solr;混合介质存储存储;数据的冷热;淘宝用户评论检索系统
信息的爆炸式增长和互联网技术的与日俱新催生了数据时代(DT时代)的来临,结构化数据和非结构化数据存储检索已经成为了各大公司的关注热点。Solr作为Apache Lucene项目的开源的全文检索框架,其主要功能有全文检索、命中标示、分面搜索、动态聚类、数据库集成、以及富文本的处理(例如Word、PDF),以其强大功能和开源性广受使用者追捧,但是Solr在存储数据时会没有利用好存储媒介,现在广泛是将Solr的数据存储在SATA盘中,因为SATA盘廉价适合海量存储成本低,但是这样存储检索的性能会随之降低,本文基于此提出SATA,SAS,SSD盘混合存储,根据业务需求,将数据分为“热数据”,“温数据”和“冷数据”,根据查询频率选择合适的盘进行存储,在解析并发查询后设置相对应的优先级加入缓存队列以此来提升并发查询效率。最后在淘宝用户检索系统这个实例中验证此方案的正确性和性能优越性。
1 技术综述
1.1 Lucene介绍
Lucene最初是由Doug Cutting编写的,是一款高性能,可扩展的信息检索工具库。它由JAVA实现,能够让你的应用程序不用了解复杂的索引和搜索实现的情况下,通过调用其简单的API实现从文本中解析出来的数据进行索引和搜素。并且Lucene不需要关心数据来源格式甚至不关心数据语种,只要把它转换为文本格式即可,同时Lucene可以用来索引存储在数据库中的数据。
1.2 Solr介绍
Solr是基于 Lucene的开源的全文检索框架,同样由Java实现,用户可以通过HTTP请求,向搜索引擎服务器提交XML文件,然后生成索引。也可以通过Http Get操作提出查询请求,并且得到XML格式的返回结果。
Solr是Lucene的扩展,并且提供了比Lucene更为丰富的查询语句,对异步并发查询进行优化。
1.3 SATA,SAS,SSD 盘的选择
SATA盘,SAS盘,SSD盘都是常用的磁盘,SATA盘价格便宜,是使用最广泛的磁盘,如今SOLR底层数据存储都依赖SATA盘接口,一块SATA盘1T到2T之间,价格每G才0.7元,价格极其低廉,非常适合存储海量数据,但是其并发查询性能差,高并发查询很能满足需求的响应速度。所以STAT盘用来存储“冷数据”比较合适,“冷数据”即为查询期间比较难用到的数据。
SAS盘是SATA盘的升级版,采用了串行技术以获取更高的传输速度,并且改善了存储性能,可用性和扩充性,同时完全兼容SATA盘。现阶段,SAS盘是机械硬盘中速度最快的了,比起传统机械硬盘速度显著提升,但是它同时有自身的不足,SAS盘同样一块是1T到2T大小,海量存储数据非常方便,但是它的价格比较贵,比SATA盘贵了一倍还多,但是鉴于它优秀的性能,存储数据,比较支持高并发的能力,SAS盘适合存储“温数据”,“温数据”即为查询频率比较频繁的数据。
SSD盘又名“固态硬盘”,它摒弃了传统的磁介质,采用了电子存储介质进行数据存储和读取,突破了传统的机械硬盘的瓶颈。拥有惊人的500MB/S的读写速度,I/0性能是SATA盘和SAS盘的40到60倍,同时具有低功率无噪音,工作温度范围大等优点,但是SSD盘成本非常高昂,是SAS盘的10倍以上,并且每块盘的存储容量很小,一般才100G到200 G左右,所以SSD盘自身优秀性能支持高并发查询,拥有极快的响应速度,但是它不适合用来存储海量数据,因此SSD盘用来存放“热数据”,“热数据”即为查询中频繁用到的数据。
1.4 区分冷数据,温数据,热数据,并且进行数据标记
区分“冷数据”,“温数据”,“热数据”的具体方式是通过查询频率区分的,查询频繁的即为热数据,查询比较频繁即为温数据,查询频率小的即为冷数据,当然可以根据业务具体情况实际情况来区分3种数据,比如数据的重要性来区分3种数据,或者数据的新旧来区分3种数据,区分完数据后对3种数据打标,以便后面的数据迁移,数据迁移能妥善管理数据。
2 改进方案设计
2.1 改进方案设计图
改进后的整体设计框架如图1所示。

图1 改进后整体设计框架图
2.2 改进后查询流程图
改进后的查询请求流程如图2所示。

图2 改进后查询请求流程图
2.3 查询解析模块说明
将客户端发出的查询请求解析为对SATA盘查询指令,对SAS盘查询指令和对SSD盘查询指令,需要特别要说明的,查询指令如果不可分割,必须同时涉及到不同盘间混合查询即为混合盘查询指令。
2.4 数据迁移模块工具说明
随着业务需求或者客户查询需求的改变,“热数据”,“温数据”,“冷数据”3种数据也在动态变化。数据迁移模块很好的完成了3种数据的迁移转换。
2.5 改进方案总体流程说明
系统从各种关系型数据库(Mysql,ORACLE等)和非关系型数据库(Hbase,Mongodb 等),HDFS 文件系统,各种流式数据,本地磁盘上数据等途径导入数据。通过数据查询频率(或者业务需求)分为“冷数据”,“温数据”和 “热数据”并且依次存储在SATA盘,SAS盘和SSD盘。数据迁移模块能妥善的管理3种数据,数据迁移之前,对要迁移数据标记转换成迁移去的盘的统一标记,根据查询业务需求和数据现阶段冷热程度完成数据迁移转换。
客户端发出异步并发查询请求,查询解析模块将查询指令解析为对SATA盘查询,对SAS盘查询,对SSD盘查询和指令无法分割对多个盘混合查询4种模式。分别赋予优先级1,2,3,0。然后依次加入缓存队列,根据优先级大小先后执行查询请求并将结果返回给客户端。
3 淘宝用户评论检索中的应用
3.1 数据来源
数据来源于淘宝提供的资源数据。选取家电,化妆品,电子产品等资源数据约500万份。确保一条数据既有结构化数据又有非结构化数据,买家信息和商品信息构成结构化数据,买家评论和商品描述构成非结构化数据。检索词是电风扇,美白保湿,内存10G。分别在传统的全用SATA盘存储的Solr集群和改善后的Solr系统中测试。
3.2 实验应用步骤
STEP1:把500万份数据随机分为约300万份数据,180万份数据,20万份数据,然后通过查询频率分为“热数据”,“温数据”和“冷数据”(这里为了实验方便,根据数据时间,近期新数据为“热数据”,中等新的数据为“温数据”,老的数据为“冷数据”。具体分数据时候,也可以根据业务需求区分数据)。将3种数据分别存储到SSD盘,SAS盘,SATA盘中。选择3台配置相同的电脑作为集群(操作系统:64位Windows8;CPU:INTEL 酷睿 17-3537U,2.0 GHz;内存:4 GB)。
STEP2:每条原始数据包括结构化数据和非结构化数据,非结构化数据买家评论和商品描述在Solr中进行分词,然后建立统一的倒排索引,索引列选取商品型号,种类和价格和结构化数据一起索引到Solr中。
STEP3:在改进后的Solr存储系统中输入检索词电风扇,美白护肤,内存10G。得到测试结果。
STEP4:在原始的Solr系统和HBASE数据库中导入同样的数据和输入同样的检索词进而得到测试结果。
3.3 实验结果比较
根据表1,2,3可以得到实验结果:
改进后的Solr混合存储系统查询速度对比没改进的Solr和传统查询海量数据HBASE数据库查询速度优势明显。

表1 3034279份数据

表2 1809108份数据
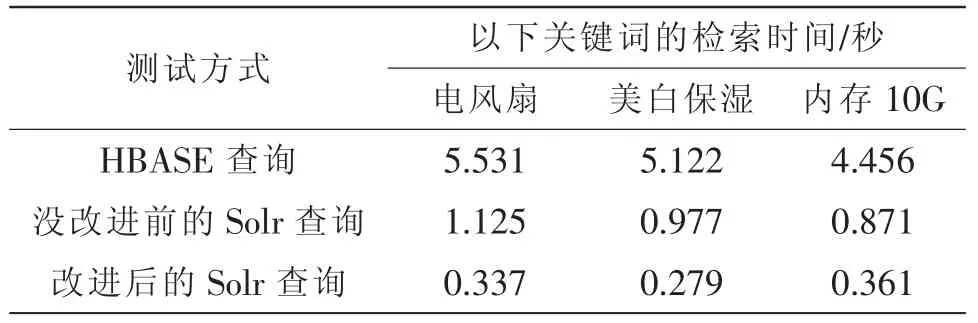
表3 213672份数据
数据量越大,这种优势表现的会越来越大。数据量10倍增加,改进后的Solr查询系统查询时间增加幅度较小,而传统的Solr和HBASE数据库查询时间增加幅度较大。
4 结论
文中提出了对Solr底层数据分盘存储的改善思路,并且设计并且优化了新的Solr底层存储方案。并在淘宝用户评论检索系统中对比传统的Solr查询和HBASE查询。验证了方案的可行性和查询性能的优越性。
[1]Rafal Kuc.Marek Rogozinski.Mastering Elastic Search[M].北京:机械工业出版社.
[2]赵凯,王敏.基于Solr企业级搜索引擎的设计[J].电子世界,2014(11):10-11.
[3]MichaelMcCandless,ErikHatcher,OtisGospodnetic.lucene实战[M].北京:人民邮电出版社.
[4]李戴维,李宁.基于Solr的分布式全文检索系统的研究和实现.[J].计算机与现代化,2014(9):6-9,14.
[5]庄新妍.计算机中文粉刺技术的研究现场与困难[J].呼伦贝尔学报,2013(3):4-9,24.
[6]陈波.基于全文检索系统Solr的OPAC分面浏览[J].现代图书情报技术,2013(11):72-75.
[7]张建飞,黄艳飞.基于ElasticSearch的数字图书馆检索系统[D].长沙:中南大学,2015.
[8]邹敏昊.基于Lucene的HBase全文检索功能的设计和实现[D].南京:南京大学,2013.
[9]韩云辉.基于Lucene的数字版权资源库的构建和应用研究[D].北京:北方工业大学,2013.4
[10]王小森.基于Solr的搜索引擎的设计和实现[D].北京:北京邮电大学,2014.
[11]姚晓娜,祝忠明.基于分面搜索引擎的Solr的机构知识库访问统计[J].现代图书情报技术,2016(Z1):37-40.
[12]刘春江,刘丹军,文奕.基于Solr的专利在线分析系统的设计和实现 [J].现代图书情报技术,2013(2):89-92.
[13]张震,甘克勤.基于Solr的大规模标准文献可视化分析系统[J].计算机系统应用,2016(3):67-71.
[14]冯祥,邱志超.基于Solr的海量日志信息查询性能优化的研究[J].硅谷,2014(3):37-39.
[15]罗惠峰.基于Lucene的站内检索系统的设计与优化[D].杭州:浙江工业大学,2015.
Based on stored in Taobao Solr mixed media system in the research of application
WANG Yang1,CUI Wei2
(1.Ltd.Nanjing R&D,FiberHome Communications Science&Technology Development Co.,Nanjing 210019,China;2.Wuhan Research Institute of Posts and Telecommunications, Wuhan 430000,China)
DT times has come,open source search engine has become the mainstream of the major companies to retrieve massive data.Among them Solr to support a variety of formats index,high efficiency,high flexibility,high saclability,bythe majority of fans and the favor of major companies.In this paper,base on the improved Solr retrieval speed and convenience data management ,put forward the mixed media storage,query points disk management and setting priorities asynchronous concurrent impovements.Through research and application in taobao users comments retrieval system,confirmed the scheme to optimize performance and improve the retrieval speed.
Lucene; Solr; mixed media storage; hot and cold data; Taobao user review system
TN02
:A
:1674-6236(2017)15-0022-04
2016-06-20稿件编号:201606139
江苏省科技支撑计划(2015BAK20B01)
汪 洋(1978—),男,江苏南京人,硕士,高级工程师。研究方向:大数据,计算机网络。
