基于词袋模型的分布式拒绝服务攻击检测
2017-09-03马林进马绍菊易辉凡
马林进,万 良,马绍菊,杨 婷,易辉凡
(1.贵州大学 计算机科学与技术学院,贵阳 550025; 2.贵州大学 计算机软件与理论研究所, 贵阳 550025)
基于词袋模型的分布式拒绝服务攻击检测
马林进1,2,万 良1,2*,马绍菊1,杨 婷1,易辉凡1
(1.贵州大学 计算机科学与技术学院,贵阳 550025; 2.贵州大学 计算机软件与理论研究所, 贵阳 550025)
(*通信作者电子邮箱lwan@gzu.edu.cn)
针对分布式拒绝服务(DDoS) 攻击有效荷载快速变化,人工干预需要依赖经验设定预警阈值以及异常流量特征码更新不及时等问题,提出一种基于二进制流量关键点词袋(BSP-BoW)模型的DDoS攻击检测算法。该算法可以自动从当前网络的流量数据中训练得到流量关键点(SP),针对不同拓扑网络进行自适应异常检测,减少频繁更新特征集带来的人工成本。首先,对已有的攻击流量和正常流量进行均值聚类,寻找网络流量中的SP;然后,将原有的流量转化映射到相应SP上使用直方图进行形式化表达;最后,通过欧氏距离进行DDoS攻击的分类检测。在公开数据库DARPALLDOS1.0上的实验结果表明,所提算法的异常网络流量识别率优于现有的局部加权学习(LWL)、支持向量机(SVM)、随机树(RandomTree)、logistic回归分析(logistic)、贝叶斯(NB)等方法。所提的基于词袋聚类模型算法在拒绝服务攻击的异常流量识别中有很好的识别效果和泛化能力,适合部署在中小企业(SME)网络流量设备上。
词袋;机器学习;聚类;分布式拒绝服务攻击;异常流量识别;流量关键点
0 引言
随着互联网规模的飞速发展,网络流量迅速增加,充斥各种协议的异构网络变得越来越复杂。网络异常流量的防御与检测在网络管理中至关重要,而分布式拒绝服务攻击门槛低、危害巨大、难以抵御等特点成为企业需要长期面临的严峻挑战。在大量涌入的流量中迅速、准确地识别和检测网络流量中的异常行为,减少异常攻击流量对相关平台业务以及网络应用的危害,保证机房网络的有效运行,对提高网络的可靠性和可用性非常重要,同时也是学术界和工业界共同关注的前沿领域之一。
分布式拒绝服务(Distributed Denial of Service, DDoS)攻击检测方式通常也可分为三种: 基于统计的检测、基于数据挖掘的检测和基于机器学习的异常检测。Sun等[1]提出利用Bloom Filter来统计握手数据包和确认数据包的配对情况,用累积算法检测时间序列的异常变化检测攻击。Yu等[2]针对大规模洪泛分布式拒绝服务攻击进行研究,通过模拟僵尸网络发现了并发流特征规避现有检测手段的问题,提出计算流之间的相似度来检测分布式拒绝服务异常流量。顾晓清等[3]通过拟合IP请求熵(IP Service Request Entropy, SRE)时间序列的自适应回归模型,来获得描述当前用户访问行为特征的多维参数向量,通过支持向量机(Support Vector Machine, SVM)对参数向量进行分类能够准确识别攻击流量。Hurst指数和Holder指数分别用于描述网络流量的自相似性和多重分型特征,广泛应用于检测DDoS攻击引起的网络流量异常。Lu等[4]基于现有空间降维算法(Isomap)扩大Hurst指数差异增加灵敏性,使用小波分析方法计算网络流量的自相似性数据来进行实时检测。许晓东等[5]从流量的全局标度指数和局部标度指数出发分析流量异常的分形参数,利用多分形奇异谱和Lipschitz正则性分布进行异常检测。冶晓隆等[6]利用主成分分析(Principal Component Analysis, PCA)对高维特征进行降维,结合决策树(C4.5),提出了一种半监督的学习方法对异常流量进行实时检测。Lee等[7]利用DDoS攻击数据源IP地址分布特性,提出了一种基于流量矩阵的 DDoS 检测方法,通过优化流量矩阵参数的方法,实现了对 DDoS流量的实时监测。Yasami等[8]利用隐马尔可夫模型提出一种基于主机地址解析协议(Address Resolution Protocol, ARP)的异常检测算法,检测精度达到90%以上。王宇等[9]提出基于决策树(C4.5)的有监督络流量分类方法,讨论特征选择和boosting增强方法两种改进策略,文中实验结果表明,决策树(C4.5)分类器的训练复杂度适中,准确率高且分类速度快。胡石等[10]基于(Back Propagation, BP)神经网络模型和线性神经网络模型,分别提出了两种无线传感器网络异常数据检测方法,此类方法结合系统网络中的流量特征信息,设计不同的自动学习算法,根据网络的流量总体情况自动构建不同的检测模型,以此来分析系统网络的异常行为情况。李向军等[11]利用相对领域信息熵重新定义离群度,提出一种基于直推式网络的异常检测算法相对领域熵基础上的直推式网络异常检测(Transductive Confidence Machines for Relative Neighborhood Entropy, TCM-RNE)算法,能有效降低网络噪声数据对检测的影响。Seliya等[12]将主动学习引入神经网络,建立一种异常检测模型,通过建立一个神经网络模型对剩余数据的相关变量进行预测,然后采用主动学习的方法将选中的实例加入训练集,该过程循环进行直到满足终止条件,从而能够以较小的标记代价获得较好的检测性能。
基于统计的异常检测方法通常需要确定阈值,阈值的设定有时还需要人工经验的介入,也有一些算法是基于自适应阈值进行设定的。为了提高识别率有时需要人为调低阈值设定,相应会提高误识别率。统计方法还需要假定该网络流量环境变化情况是一个似稳态的过程,还不能很好应对目前如分布式僵尸网络的精心构造的攻击流量。基于数据挖掘的检测算法如利用生成归纳规则、模糊逻辑、遗传算法、神经网络、深度学习等,往往需要离线进行迭代分析,无法实时进行流量处理。基于数据挖掘的检测算法训练期间还会分析大量访问日志、流量数据等,其产生的中间结果和偏差往往不可干预,前期模型训练一般较为复杂,实时处理时还需要占用服务器本身资源,对服务器本身有一定要求,不适用于小型机房检测。而基于机器学习的异常检测算法,依据机器学习算法进行分类、聚类特征训练,能对流量进行实时处理,算法本身比较灵活,具有较好的泛化识别能力和多种可选择的算法,适用于中小型企业服务器端部署。
网络异常流量中分布式拒绝服务攻击经常变换、伪装改变特征码以达到欺骗绕过等目的,有时甚至攻击流量来源于分布式网络、物联网(Internet of Things, IoT)等,通过模拟网络的随机突发性访问进行洪水式拒绝服务攻击,检测算法往往检测到了攻击,但无法识别是具体哪种攻击,或者算法本身具有较高的误识别率与低检测率。传统基于统计的异常检测方法需要依赖人工经验设定阈值,为了增加识别率往往通过人为调低阈值的方式达到,容易造成大量误报,统计方法也要求满足精确的统计分布,不是所有的异常情况都可以通过完全的统计方法表示,而且后期的维护中需要大量人工维护,不适用于攻击防御阶段的应对处理。本文改进了文本识别中的词袋(Bag of Words, BoW)模型,提出了一种基于二进制流量关键点的词袋模型(Binary Stream Point Bag of Word model, BSP-BoW),并将其应用到分布式拒绝服务攻击的检测中。实验结果表明,与传统异常流量检测算法相比,基于流量关键点词袋聚类的异常流量检测算法前期建模速度快于REPTree(一种决策树算法)、C4.5决策树、支持向量机(Support Vector Machine, SVM)、JRip(重复增量修枝方法,即RIPPER 算法)、Logistic(Logistic回归模型)、逻辑模型树(Logistic Model Tree, LMT)、MultilayerPerceptron(多层感知模型)等算法,平均识别率高于OneR(简单的1-R分类法)、贝叶斯分类器(Naive Bayes, NB)、RandomTree(随机树模型)、SVM等方法,能针对当前网络环境下的流量进行训练建模,对伪造的正常数据流量具有较好的识别率,适合于部署在中小企业网络流量设备上,具有很好的泛化识别能力,是较可行的分布式拒绝服务(DDoS)攻击检测方法。
1 词袋模型
词袋(BoW)模型是自然语言处理(Natural Language Processing, NLP)领域用于信息检索(Information Retrieval)和文本分类(Text Classification)的模型,也广泛应用于计算机视觉(Computer Vision)领域物体识别、人脸识别、场景分类[13]、特征描述(Bag of Features, BoF)[14-15]等方面。词袋模型假设关键点集合的特征描述可被看作是无序的特征集合,忽略语法甚至是特征的顺序。为了使用流量关键点词袋模型,首先要在训练阶段建立流量关键点的集合:在训练模型中,归一化所提取的流量特征,使用K-means算法对这些特征进行聚类,得到的结果是可以被视为当前网络拓扑结构下流量数据的普遍特征,称作流量关键点(Stream Point, SP)。将同一阶段的拒绝服务攻击流量映射到流量关键点上,形成流量关键点直方图,可以表示某一阶段拒绝服务攻击的特有特征。同理,对不同阶段异常流量进行训练建模,可以得到整个拒绝服务攻击的词袋模型的流量关键点直方图,将当前网络流量(测试集流量)映射到相应流量关键点中,与训练直方图进行比较,可以检测攻击流量以及攻击流量的阶段,为防御阶段的拦截提供依据。
1.1K均值算法
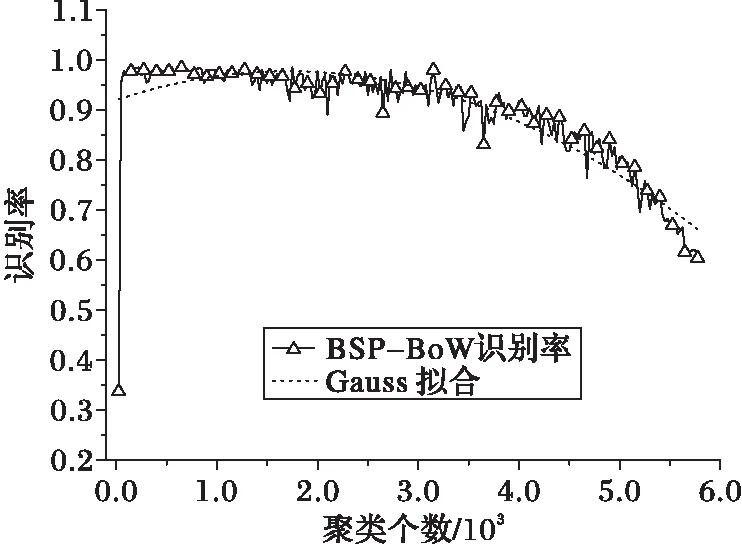
K均值算法以欧氏距离作为相似度测度,需要提前制定K值进行聚类,是改进提出的半监督聚类算法。K-means算法能迅速将输入数据集划分为k个集群,每个集群都由一个质心表示。其主要思想是:划分N个输入数据x1,x2,…,xN到k个不相交的子集Ci(i=1,2,…,k)中,对于每个ni数据集,0 (1) 其中:xt表示子集Ci中第t个数据;ci是Ci的几何中心;K-means算法旨在使得目标函数得到最小值minJMSE;‖xt-ci‖2表示xt与ci之间距离度量。 当数据集成员使得函数I(xt,i)为1时,K-means算法划分输入数据xt到第i个集群中。 (2) 其中,c1,c2,cj,…,ck(j=1,2,…,k)是聚类的中心,通过以下步骤得到: 步骤1 初始化k个随机指定的聚类中心c1,c2,…,ck。 步骤2 通过式(2)计算I(xt,i),决定第k集群最靠近哪个中心。 步骤3 对于k个聚类中心,计算ci,令ci为集群Ci的质量中心。 对于每个输入数据xt和k个集群,重复步骤2、3直到收敛。 对于给定一组观察值的序列x1,x2,…,xN,这里每一个观察值都是一个d维的实值向量。K均值聚类的目标是划分这N个训练数据到k个聚类中心,最后得到k个d维的训练聚类中心。 1.2 直方图表示法 直方图模型可用于K-means聚类结果表示,对于k个d维的训练聚类中心用生成的词频统计直方图进行表示,如式(3)所示: (3) 通常最终的结果用频率直方图进行表示: (4) 基于二进制流量关键点的词袋(BSP-BoW)模型算法,是在原有聚类模型的基础上进行改进,将其应用到分布式拒绝服务攻击的流量检测中,可以用于异常流量的类别检测、攻击流量实时在线检测以及流量分布式检测。基于二进制流量关键点的词袋模型面向实时的网络流量,对于单个网络数据包本身具有的结构可以被视为一种文档对象,且其符合特征描述无序性,故可以将词袋模型应用到流量检测中。因为各个流量数据包大小不一样,文中统一截取包括数据头在内的前面240个字节数据,并将其转化成[0,255]的整型数据。同一阶段的恶意攻击流量自身携带的特征可以被看作区别于正常流量的攻击流量特征向量,可以通过流量关键点直方图进行形式化描述。对于训练样本,使用训练得到的流量关键点模型进行表示,训练过程如图1~2所示。 2.1BSP-BoW训练过程 1)对于训练组数据流量,首先提取特征向量进行数据归约,[0,255]的整型数据可以转化为[0,1]的浮点数据,长度为120,对于训练集k个类别,每个类别有M个数据,共k*M个数据的训练集数据,为消除不同的特征数据度量对聚类造成影响,对网络流量进行如下变换: (5) 2)给定k值,依据文献[16]推荐k值选取在[2,134],选取如75作为k值,此值是较快达到识别率的数值,后续实验中还测试了选取[25,800]情况下识别率情况。对于步骤1)中归一化后的大小为N的训练数据S={S1,S2,…,SN},这里每一个观察值都是一个d维的特征向量。进行均值聚类后使得JMSE最小,得到k维的数据划分,即聚类中心。显然,K-means的结果是当前网络拓扑结构下流量数据的普遍特征,将这些聚类中心称为流量关键点。BSP-BoW建模得到流量关键点的训练过程如图1所示。 图1 BSP-BoW得到流量关键点过程 3)对于每一个训练集数据,重新计算与各个流量关键点SP的距离,可以得到与之最接近的SP上Tk,因此可以将该训练集映射到第k个SP上,如式(6)所示: (6) 对于每个分片,将其通过式(4)进行直方图表示,通过流量关键点直方图替换描述原始流量样本,即可得到训练组流量关键点直方图,总的训练过程如图2所示。 图2 BSP-BoW建模训练过程 2.2BSP-BoW测试样本处理过程 对于测试样本,同样经过转化为[0,1]再通过式(5)数据处理,得到测试集特征S={S1,S2,…,SN},将测试集通过式(6)映射到训练得到的流量关键点中。测试样本处理过程如图3所示。 图3BSP-BoW测试样本处理过程 Fig. 3TestsampleprocessingofBSP-BoW 对于测试集中不同类别的流量关键点特征向量,将同一类别的测试流量通过式(4)进行直方图处理,可以得到测试集流量关键点直方图。 2.3BSP-BoW识别过程 对于已经标记的k个类别,每个类别M个数据,共k*M个已经映射到流量关键点的训练集数据,给定一个聚类数目F如10,使得MmodF=0,可以将每一类别分为M/F个分片,训练集可以表示为C={C1,C2,…,Ck*M/F},同一类别的训练集划分到M/F个分片内,对每一个分片,统计每一分片内各个类别的流量关键点直方图特征,h(i)表示该分片中一个类别的直方图特征值,直方图特征H(k)={h(1),h(2),…,h(k)},计算式如下: (7) 对于训练集的每一个类别分片,都能得到相应的流量关键点直方图。训练集中得到的不同类别的频数直方图,还需要进行式(4)处理,使得不同训练集样本的个数能在同一尺度内进行识别。 总的训练识别过程如图4所示。 图4 BSP-BoW训练识别流程 最终的分类识别率通过分类器进行得到,本文采用的欧几里得(Euclid)公式进行检测识别,计算式如下: (8) 其中:n为Ci、Cj的维度。 3.1 数据集 数据来源是DARPA(DefenseAdvancedResearchProjectsAgency) 2000数据集(http://www.ll.mit.edu/ideval/data/2000data.html),该数据集是由美国国防部高级研究计划局(DefenseAdvancedResearchProjectsAgencyInformationTechnologyOffice,DARPAITO)和空军研究实验室(AirForceResearchLaboratory,AFRL)赞助,麻省理工学院Lincoln实验室收集和整理的用于攻击检测评估的权威数据集。其中,数据集的背景流量是美国麻省理工学院(MassachusettsInstituteofTechnology,MIT)的日常流量,攻击流量是由实际网络环境下的攻击实验所产生,包括两个攻击场景实例LLDOS1.0和LLDOS2.0.2,每个场景下都有Inside(内部网络)、Outside(外部网络)和隔离区(DeMilitarizedZone,DMZ)下的流量数据。 实验使用了第一个攻击场景下的Inside流量数据,其中Inside域中包括了近40台的主机以及防火墙,该数据集标记了PHASE1~5个不同攻击阶段的流量,总计649 787个数据包。数据集第5阶段包含73 924个数据,远大于第1~4阶段全部数据,为了更好显示不同阶级下的识别率,本文采集了1~4阶段的全部数据,以及部分第5阶段数据和部分背景流量下作为训练集和测试集,其中训练集数量基本为测试集的1/2,数据情况如表1所示。 表1 实验中使用的LLDOS数据集 3.2 实验环境 实验测试环境为Windows64位系统,Inteli5CPU,主频3.2GHz,内存4GB,现有机器识别方法在weka3.8.0实验平台下进行,词袋聚类方法在VS2015环境下编译实现。 3.3 实验结果 首先需要对网络流量进行归一化处理:截取包括数据头在内的前面120个字节数据,将每个字节转化成[0,255]的整型数据,再归一化为[0,1]数据,使用式(5)进行标准化。然后将流量数据分为训练集和测试集两类,对训练集进行特征提取与变换,将得到的特征向量进行均值聚类式(2),计算流量关键点式(6)。将训练集的每个类别进行分片,对于每10个分片,计算相应的流量关键点直方图式(7),最后通过式(4)得到流量关键点频率直方图。对于测试集提取的特征向量,与训练集得到的流量关键点进行比较映射,将映射后得到关键点替换原始特征向量,对于每个类别,按每10个分片大小统计测试集的流量关键点直方图,式(4)得到测试集的流量关键点频率直方图,最后的检测使用欧氏距离式(8)进行识别。总的训练识别过程如图5所示。 图5 BSP-BoW总的过程 为了比较BSP-BoW识别率,结果采用检测率(TruePositive,TP)和误报率(FalsePositive,FP)作为评价指标,使用准确率(Precision)进行表示,定义如下: presicion=NTP/(NTP+NFP)×100% (9) (10) 其中:Dj表示LLDOS第j数据组总数据大小;pi表示该算法在第i数据组上准确率。 图6 BSP-BoW在k=75下的准确率 使用OneR简单的1-R分类法、ZeroR、LWL、Naive Bayes(NB)分类器、RandomTree、AttributeSelectedClassifier、Jrip(规则学习方法)、C4.5决策树、FilteredClassifier 、Logistic(logistic回归模型)、SVM、REPTree 、LogitBoost(采用对数回归方法的弱学习器)、MultilayerPerceptron、LMT(组合树结构和Logistic回归模型)进行比较。由于不同的k值对识别率有一定影响,为了减少k值选取对本文方法所造成的影响,测试了k值选取在100~1 000,间距大小为25共计37组实验的全部实验结果,使用各组的平均值作为BSP-BoW平均效果,表2依据平均识别率对不同算法由高到低进行排序,最后一行为BSP-BoW算法结果。 其中:NB在D3、D4、D6上识别不佳;D6数据总数量有9 000组,识别率不高直接造成总体加权识别率下降,NB不能很好地泛化正常的流量。C4.5在D2、D3、D4上容易造成混淆,对类别的区分不是很敏感;但对于D5数据识别很好。SVM对于有些单类别识别的效率很高,对于D3、D4识别效果不佳。LogitBoost算法在D2、D5识别上优于BSP-BoW,但加权平均值低于BSP-BoW。BSP-BoW在D3、D6上识别率优于NB、C4.5;D6训练数较多,其识别率达到99%,总的加权平均值达到97.8%。表3为实验中所有算法的训练与测试所耗费时间的详细数据(以总耗费时间排序从小到大排序)。MultilayerPerceptron、LMT方法虽然加权识别上准确率较高,但是耗费时间较多。 表2 LLDOS数据集下不同算法的识别率 表3 LLDOS数据集训练测试时间 其中ZeroR训练与识别时间为0.23s,但其识别率平均为50.3%;LMT训练时间为60.44s,总的时间为61.02s;MultilayerPerceptron训练时间达到345s,总的时间345.89s,高于BSP-BoW的23.49s;而BSP-BoW比较的时间为平均时间,训练时间随着k的个数从100至1 000变化依次增加,从4.24s至43.57s,平均时间约为23.49s,准确率较高,能快速达到识别率要求。综上,考虑时间,BSP-BoW能在相等时间耗费的情况下迅速收敛,总体识别率为97.8%。 为了进一步测试词袋聚类算法的优劣性,本文在不同聚类中心大小下还作了进一步实验测试,得到BSP-BoW识别率如图7~8所示。 图7 不同聚类个数k下BSP-BoW 识别率(小范围) 图7所示为k值在100到1 000之间变化对应的BSP-BoW识别率,当聚类个数达到75左右,即达到90%以上识别率,其中聚类个数125的情况下识别率为98.7%,且随着聚类个数的增加,识别率稳定在97.8%左右。 继续增大聚类个数,随着聚类中心的增多,识别率突变上升,随后聚类中心开始影响最终识别率,呈现缓慢下降趋势,继续增大聚类个数,识别率下降更加明显,具体变化趋势如图8所示。通过高斯曲线拟合,得到曲线如图8中所示拟合曲线。总体来说,随着聚类中心的个数增加,前期识别率指数级增加,识别率维持在一定范围内。随着不断增加聚类个数,当进入一段区域(1 500~3 000)后,聚类中心会转化为噪声,影响识别率,识别率开始剧烈抖动。当大于3 000后,识别率开始下降。由图7~8可知,最优k值处于识别率稳定的阶段,如100~1 000,最优值与识别率稳定存在一定关联。 图8 不同聚类个数k下BSP-BoW识别率(大范围) 本文提出改进的基于二进制流量关键点的词袋模型(BSP-BoW),能对当前网络环境下异常流量进行分析,得到当前环境的流量关键点,适合中小型网络的异常流量的快速检测识别判断。实验结果表明,该方法相比现有的OneR、NB、RandomTree、SVM等方法迅速有效,适合部署于中小企业网络流量设备上,具有很好的泛化识别能力,是比较可行的DDoS攻击检测方法。下一步研究方向在于如何确定最优k值,是否存在规律,以及是否存在最优分片个数,使得识别率迅速收敛,达到最优。 ) [1]SUNCH,FANJD,LIUB.ArobustschemetodetectSYNfloodingattacks[C]//CHINACOM’07:Proceedingsofthe2007SecondInternationalConferenceonCommunicationsandNetworkinginChina.Piscataway,NJ:IEEE, 2007: 397-401. [2]YUS,GUOS,STOJMENOVICI.Canwebeatlegitimatecyberbehaviormimickingattacksfrombotnets? [C]//INFOCOM’12:Proceedingsofthe2012 31stAnnualIEEEInternationalConferenceonComputerCommunications.Piscataway,NJ:IEEE, 2012: 2851-2855. [3] 顾晓清,王洪元,倪彤光,等.基于时间序列分析的应用层DDoS攻击检测[J].计算机应用,2013,33(8):2228-2231.(GUXQ,WANGHY,NITG,etalDetectionofapplication-layerDDoSattackbasedontimeseriesanalysis[J].JournalofComputerApplications, 2013, 33(8): 2228-2231.) [4]LULF,HUANGML,ORGUNMA,etal.AnimprovedwaveletanalysismethodfordetectingDDoSattacks[C]//NSS’10:Proceedingsofthe2010 4thInternationalConferenceonNetworkandSystemSecurity.Piscataway,NJ:IEEE, 2010: 318-322. [5] 许晓东,朱士瑞,孙亚民.基于分形特性的宏观网络流量异常分析[J].通信学报,2009,30(9):43-53.(XUXD,ZHUSY,SUNYM.Anomalydetectionalgorithmbasedonfractalcharacteristicsoflarge-scalenetworktraffic[J].JournalonCommunications, 2009, 30(9): 43-53.) [6] 冶晓隆,兰巨龙,郭通.基于主成分分析禁忌搜索和决策树分类的异常流量检测方法[J].计算机应用,2013,33(10):2846-2850.(YEXL,LANJL,GUOT.Networkanomalydetectionmethodbasedonprinciplecomponentanalysisandtabusearchanddecisiontreeclassification[J].JournalofComputerApplications, 2013, 33(10): 2846-2850.) [7]LEESM,KIMDS,LEEJH,etal.DetectionofDDoSattacksusingoptimizedtrafficmatrix[J].Computers&MathematicswithApplications, 2012, 63(2): 501-510. [8]YASAMIY,FARAHMANDM,ZARGARIV.AnARP-basedanomalydetectionalgorithmusinghiddenMarkovmodelinenterprisenetworks[C]//ICSNC2007:Proceedingsofthe2007SecondInternationalConferenceonSystemsandNetworksCommunications.Piscataway,NJ:IEEE, 2007: 69. [9] 王宇,余顺争.网络流量的决策树分类[J].小型微型计算机系统,2009,30(11):2150-2156.(WANGY,YUSZ.Internettrafficclassificationbasedondecisiontree[J].JournalofChineseComputerSystems, 2009, 30(11): 2150-2156.) [10] 胡石,李光辉,卢文伟,等.基于神经网络的无线传感器网络异常数据检测方法[J].计算机科学,2014,41(11A):208-211.(HUS,LIGH,LUWW,etal.Outlierdetectionmethodsbasedonneuralnetworkinwirelesssensornetworks[J].ComputerScience, 2014, 41(11A): 208-211.) [11] 李向军,张华薇,郑思维,等.基于相对邻域熵的直推式网络异常检测算法[J].计算机工程,2015,41(8):132-139.(LIXJ,ZHANGHW,ZHENGSW,etal.Transductivenetworkanomalydetectionalgorithmbasedonrelativeneighborhoodentropy[J].ComputerEngineering, 2015, 41(8): 132-139.) [12]SELIYAN,KHOSHGOFTAARTM.Activelearningwithneuralnetworksforintrusiondetection[C]//IRI2010:Proceedingsofthe2010IEEEInternationalConferenceonInformationReuseandIntegration.Piscataway,NJ:IEEE, 2010: 49-54. [13] 王宇新,郭禾,何昌钦,等.用于图像场景分类的空间视觉词袋模型[J].计算机科学,2011,38(8):265-268.(WANG Y X, GUO H, HE C Q, et al. Bag of spatial visual words model for scene classification [J]. Computer Science, 2011, 38(8): 265-268.) [14] QIU Q, CAO Q X, ADACHI M. Filtering out background features from BoF representation by generating fuzzy signatures [C]// iFUZZY 2014: Proceedings of the 2014 International Conference on Fuzzy Theory and Its Applications. Piscataway, NJ: IEEE, 2014: 14-18. [15] MA L J, WANG H J. A new method for wood recognition based on blocked HLAC [C]// ICNC 2012: Proceedings of the 2012 Eighth International Conference on Natural Computation. Piscataway, NJ: IEEE, 2012: 40-43. [16] 吴夙慧,成颖,郑彦宁,等.K-means 算法研究综述[J].现代图书情报技术,2011,27(5):28-35.(WU S H, CHENG Y, ZHENG Y N, et al. Survey onK-means algorithm [J]. New Technology of Library and Information Service, 2011, 27(5): 28-35.) This work is partially supported by the Guizhou Provincial Science Department Project (KEHE LH [2014]7634, KEHE J [2011]2328). MA Linjin, born in 1991, M. S. candidate. His research interests include information security, pattern recognition, anomaly traffic detection, distributed denial of service attack detection. WANG Liang, born in 1974, Ph. D., professor. His research interests include information security, formal method, machine learning, intelligent home. MA Shaoju, born in 1991, M. S. candidate. Her research interests include information security, App privacy protection. YANG Ting, born in 1992, M. S. candidate. Her research interests include information security, intelligent home. YI Huifan, born in 1993, M. S. candidate. His research interests include information security, formal method. Distributed denial of service attack recognition based on bag of words model MA Linjin1,2, WAN Liang1,2*, MA Shaoju1, YANG Ting1, YI Huifan1 (1.CollegeofComputerScienceandTechnology,GuizhouUniversity,GuiyangGuizhou550025,China; 2.InstituteofComputerSoftwareandTheory,GuizhouUniversity,GuiyangGuizhou550025,China) The payload of Distribute Denial of Service (DDoS) attack changes drastically, the manual intervention of setting warning threshold relies on experience and the signature of abnormal traffic updates not timely, an improved DDoS attack detection algorithm based on Binary Stream Point Bag of Words (BSP-BoW) model was proposed. The Stream Point (SP) was extracted automatically from current network traffic data, the adaptive anomaly detection was carried out for different topology networks, and the labor cost was reduced by decreasing frequently updated feature set. Firstly, the mean clustering was carried out for the existing attack traffic and normal traffic to look for SP in the network traffic. Then, the original traffic was mapped to the corresponding SP for formalized expression by histogram. Finally, the DDoS was detected and classified by Euclidean distance. The experimental results on public database DARPA LLDOS1.0 show that, compared with Locally Weighted Learning (LWL), Support Vector Machine (SVM), Random Tree (RT), Logistic regression analysis (Logistic), Naive Bayes (NB), the proposed algorithm has higher recognition rate of abnormal network traffic. The proposed algorithm based on BoW model has the good recognition effect and generalization ability in abnormal network traffic recognition of denial of service attack, which is suitable for the deployment in the Small Medium Enterprise (SME) network traffic equipment. Bag of Words (BoW); machine learning; clustering; Distributed Denial of Service (DDoS) attack; anomaly traffic detection; Stream Point (SP) 2016- 11- 08; 2017- 01- 06。 贵州省科学基金资助项目(黔科合LH字[2014]7634号,黔科合J字[2011]2328号)。 马林进(1991—),男,浙江台州人,硕士研究生,主要研究方向:信息安全、模式识别、异常流量检测、分布式拒绝服务攻击检测;万良(1974—),男,贵州铜仁人,教授,博士,CCF会员,主要研究方向:信息安全、形式化方法、机器学习、智能家居; 马绍菊(1991—),女,贵州毕节人,硕士研究生,CCF会员,主要研究方向:信息安全、App隐私保护; 杨婷(1992—),女,贵州毕节人,硕士研究生,主要研究方向:信息安全、智能家居; 易辉凡(1993—),男,贵州安顺人,硕士研究生,CCF会员,主要研究方向:信息安全、形式化方法。 1001- 9081(2017)06- 1644- 06 10.11772/j.issn.1001- 9081.2017.06.1644 TP A

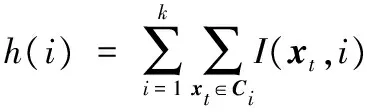


2 基于二进制流量关键点的词袋模型


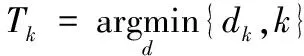





3 实验结果及分析






4 结语
