大数据流式计算环境下的阈值调控节能策略
2017-09-03蒲勇霖王跃飞侯冬雪
蒲勇霖,于 炯,,王跃飞,鲁 亮,廖 彬,侯冬雪
(1.新疆大学 软件学院,乌鲁木齐 830008; 2.新疆大学 信息科学与工程学院,乌鲁木齐 830046; 3.新疆财经大学 统计与信息学院,乌鲁木齐 830012)
大数据流式计算环境下的阈值调控节能策略
蒲勇霖1,于 炯1,2*,王跃飞2,鲁 亮2,廖 彬3,侯冬雪1
(1.新疆大学 软件学院,乌鲁木齐 830008; 2.新疆大学 信息科学与工程学院,乌鲁木齐 830046; 3.新疆财经大学 统计与信息学院,乌鲁木齐 830012)
(*通信作者电子邮箱yujiong@xju.edu.cn)
在大数据实时分析计算领域,流式计算的重要性不断提高,但是流式计算平台处理数据的能耗不断上升。针对这一问题,改变流式计算中节点对数据的处理方式,提出了一种阈值调控节能策略(ESTC)。首先,根据系统负载差异确定工作节点的阈值情况;其次,通过工作节点的阈值对系统数据流进行随机选择,确定不同数据处理情况调节系统的物理电压;最后,根据不同的物理电压确定系统功率。实验结果和理论分析表明,在20台普通PC机构成的流式计算集群中,实施ESTC的系统比原系统有效节能约35.2%;此外,ESTC下的性能与能耗的比值为0.080 3 tuple/(s·J),而原系统性能与能耗的比值为0.069 8 tuple/(s·J)。ESTC能够在不影响系统性能的前提下,有效降低了能耗。
流式计算;阈值;负载差异;随机选择;系统性能
0 引言
随着物联网、云计算、车联网、深度学习、量子通信、大数据等新兴技术的发展[1],且大规模的数据中心在全球范围内进行部署,其高费用、高污染、高能耗等问题也日益突出[2]。因此,如何更绿色更节能地处理新兴信息技术的能源问题,一直是世界广大研究者共同探讨的热点。根据美国纽约时报报道,全球数据中心每年总用电量超过3 000亿kW·h,相当于30座核电厂的总产电量,而巨大的能耗却只有6%~12%能耗被用于响应用户的请求[3]。特别是大数据时代的到来,更多的资源被用在海量数据的处理,给能耗高效益带来了巨大的挑战。因此,现阶段的关键性问题还是能源的利用率太低(特别是对大数据的处理),如何提升能源的利用率是解决问题的关键。
现阶段对数据的实时处理是大数据处理的一个重要方面,流式计算作为新的容错、分布式的大数据实时计算系统,存在着高能耗的问题,由于能够广泛部署在开源的系统平台上,其节能的策略还有待提高。无论从降低能耗、保护环境方面,还是从降低大数据的运营成本方面,研究流式计算的节能策略都有着广泛的应用前景。
流式计算内数据的处理,其本质是数据以流的形式在内存中运动,数据的处理方式为流式处理。流式处理的节能主要分为硬件节能[4]和软件节能两个方面,硬件方面的节能主要通过改变相应的物理结构单元,替换低能耗、高效率的物理元件。已有的软件节能主要体现为对系统框架的优化[5]与从虚拟化数据中心(Virtualized Networked Data Centers, VNetDCs)的角度出发,其中对系统框架优化研究的核心是提高资源利用率与减少数据处理的响应时间。大数据的处理具有无序性与突发性,无法预测下一秒数据量与传输路线,但是对系统框架的优化可以巩固关键路径上的节点,间接地预测数据处理的关键路径,使数据的传输更稳定,提高数据资源的利用率。但是,系统框架的优化难度较大,并且存在优化方案与系统不匹配的问题,容易造成不必要的资源浪费。针对虚拟化数据中心,文献[6]提出了云计算软件即服务(Software-as-a-Service, SaaS)计算模型下针对实时流式计算应用的最小化能耗调度策略。该研究充分考虑到大数据处理传输速率的不稳定、不可控,且大数据实时流数据量大等特性,在响应时间约束的前提下,最小化计算和网络传输总能耗。但是,该策略算法复杂度很高,导致执行策略时系统存在较高的延迟,会对系统性能造成影响,且虚拟环境与真实环境存在偏差,会对真实环境下系统造成影响。针对上述问题,本文提出了大数据流式计算环境下的阈值调控节能策略(Energy-efficient Strategy for Threshold Control, ESTC),其中心思想是对数据处理的当前节点设置阈值进行调控,根据数据处理的不同情况通过随机选择对系统的电压进行控制,其阈值根据当前节点处理的数据量与CPU使用率的负载情况确定。对比原系统,实施阈值调控策略的系统能够根据不同的数据处理情况进行能耗控制,更有效地节约系统因为无用功带来的能耗损失。此外,通过负载情况设计数据访问的阈值,本文系统可以更好地对数据的伸缩性进行控制,提高了系统的负载均衡能力。
1 流式计算框架
在流式计算中,系统的构架由多个子系统共同组成,其子系统的组合方式是流式计算的核心技术。对于流式计算的框架集群,可以处理那些无需先存储、直接进行计算的数据与实时性要求严格,数据准确性要求略宽松的应用场景。数据以流的形式在内存中传输,硬盘不需为中间过程进行存储而仅在最后将数据备份,以Storm[7]为例,其整体结构构架如图1所示。
流式计算系统的系统结构框架[8]可分为有中心节点的主从式架构(如Storm、TimeStream[9]等系统)和无中心节点的对称式系统架构[10](如S4[11]、Puma[12]等系统)。主从系统架构的系统存在一个主节点和多个从节点,从节点的功能是负责接收来自主节点的任务,并通过计算后返回主节点。主节点通过传递任务、管理系统资源与接收来自从节点反馈的计算结果用来处理负载均衡等工作。对称式系统架构的系统各节点功能都是相同的,具有良好的可扩展性,但是由于没有中心节点,在系统容错、资源调度等方面需要分布式协议来完成,如通过Zookeeper来实现负载均衡等功能的S4系统。此外,各从节点之间不存在相互联系,整个系统完全依赖主节点的调控。

图1 Storm系统构架
流式计算平台不同于Hadoop[13]等批处理平台,Hadoop对于数据的处理通过MapReduce进行映射并对任务进行调度,且数据储存在分布式文件系统(Hadoop Distributed File System, HDFS)的磁盘上。流式计算平台数据的处理,通过对工作节点进行任务的部署,并计算各节点之间的数据关系,全程通过内存与CPU共同完成。流式计算平台主要的数据处理传输方式为主动推送方式与被动拉取方式[14]。
2 流式计算的结构及算法
在流式计算中,数据的计算处理方式用有向无环图表示,流入内存栈列区内的数据流根据有向无环图的拓扑结构,经工作节点的阈值进行调控,根据随机选择控制系统的物理电压。本章将从数据流计算时间的角度分析ESTC的能耗时间并建立数学模型。
2.1 流式计算的结构
流式计算系统的阈值调控策略处理数据时通过工作节点阈值对数据流进行随机选择,不仅减少了原系统在处理数据时因高电压而产生的无用功,而且增加了流式计算平台处理数据的延展性,提高了系统负载均衡的能力。由此,可建立有向无环图模型表示数据的传输处理状态。
定义1 有向无环图模型。流式计算系统处理传输数据需要通过有向无环图进行,因此建立有向无环图模型,以图2为例,工作节点为a1、a2、a3,子节点为b1、b2、b3、b4,工作节点a1传输的数据量a11、a12,父节点a2处理的数据量a21、a22、a23,则子节点b1为a11+a21→b1,以此类推,完成整个拓扑计算c1+c2→d,设在一段时间内原数据文件Fn由数据流[A1,A2,…,An]组成,存在数据流Ai满足Ai⊂Fn(i∈{1,2,…,n}),此外存在工作节点Ni满足Ni⊂[N1,N2,…,Nn](i∈{1,2,…,n}),其中:N1为初始源节点,Nn为有向无环图顶点。
有向无环图用来表示数据流的处理,其中:圆形为数据的计算节点,箭头为数据的流动方向。数据的计算路径如图2所示。

P=p(v,u)/p(v总,u总)
(1)
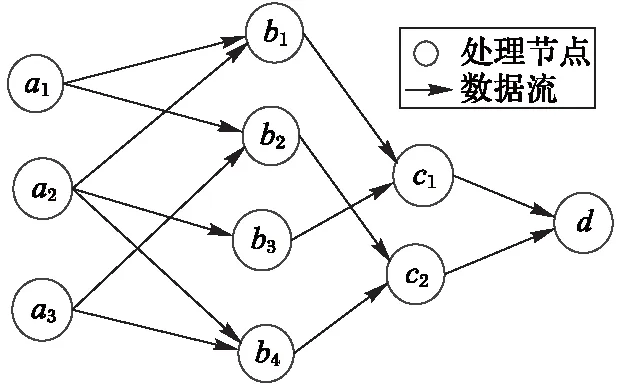
图2 数据计算路径
定理1 在大数据流式计算中,根据工作节点阈值模型可知存在四种随机选择方式,这四种选择的相应计算式为:
(2)
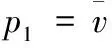
根据P=p(v阈,u阈)/p(v总,u总)可知:
(3)
根据定义1可知原数据文件Fn由数据流[A1,A2,…,An]组成,且存在数据流Ai满足Ai⊂[A1,A2,…,An](i∈{1,2,…,n}),则:
P(vu)=[(v/v总)(u/u总)]n
证毕。
定义3 数据处理模型。在确保性能不变的前提下,用计算关键路径来规定数据处理传输的情况。根据定义1有向无环图模型可知,数据流Ai最早传出数据的时间为Ae(i);表示数据流Ai从源点N1到顶点Nn走过的最长路径长度。数据流Ai最迟传出数据的时间为Al(i);表示数据流Ai在保证汇点Nn-1在Ae(n-1)时刻完成(即不影响整个系统性能的前提下),数据流Ai允许的最迟传出数据的时间。
设数据ak传输的最早可能开始时间为ae(k),数据在节点上计算的时间为a(k),数据ak在弧〈N1,Nn〉上,则ae(k)+a(k)表示从N1源点到Nn顶点的最长路径长度。即:
ae(k)+a(k)=Ae(i)
(4)
设数据ak传输的最迟可能开始时间为al(k),数据在节点上的计算时间为a(k),在不会引起整个系统时间延误的前提下,该数据ak传输允许的最迟开始时间。即:
al(k)=Al(i)-dr〈1,n〉-a(k)
(5)
其中,dr〈1,n〉是完成数据ak传输需要的时间,从Ae(i)=0开始,向前推进。则:
Ae(i)=max{Ae(i)+a(k)+dr〈1,n〉}; 〈1,n〉∈S1,i=1,2,…,n-1
(6)
其中,S1是指向数据流Ai经过的有向边〈1,n〉的集合。
如果,从Al(n-1)=Ae(n-1)开始,反向推进。则:
Al(i)=min{Al(i)-a(k)-dr〈1,n〉}; 〈1,n〉∈S2,i=n-2,n-3,…,0
(7)
其中,S2是源自数据流Ai经过的有向边〈1,n〉的集合。
可能存在机动时间T,因此Ae(i)与Al(i)不一定相等。
定义4 性耗比模型。流式计算系统首先应该以不影响系统性能为前提,而流式计算的性能体现在数据的处理速率,即在不影响数据的处理速率的前提下进行。
设数据处理的总时间为t,开始处理的时间为t0,根据定义2可知,数据量M为单位时间内数据传输的tuple元组,其单位为tuple。数据处理的总能耗为E,则建立性耗比模型,单位时间内数据的处理速率与系统总能耗的商是性耗比R,其单位为(tuple/(s·J)),计算式为:
R=M/(tE)
(8)
定理2 在大数据流式计算中,对于单位时间内数据的处理速率与系统总能耗的性耗比R为:
(9)
证明 根据定义4可知单位时间内数据传输速率与能耗的比值为R=M/(tE),则1/R=tE/M。如果将总时间划分为[t0,t1,…,tn-1],则:
(10)
对式(10)进行积分得:
1/R=E(tn-1-t0)/M
(11)
因此:
R=M/[(tn-1-t0)E]
(12)
根据定义3可知,在不考虑数据处理的机动时间时,数据处理的最迟开始时间等于最早开始时间,因此数据的处理时间ti=max{Ae(i)+a(k)+dr〈1,n〉},当时间间隔被划分为n等份[t0,t1,…,tn-1]时,∀[ti](i∈{0,1,…,n-1}),则:
其中C是根据多次实验并验证到的性耗比误差参数,存在取值范围。
证毕。
2.2 阈值调控策略
流式计算根据2.1节考虑到流式计算数据流的传输情况,提出了ESTC,其中F表示为构造的数据文件流模型,定义的基本算法流程如下所示。
算法1 阈值判别算法。
输入 用户上传m个数据文件{F1,F2,…,Fm}到系统。
输出 系统的功率,根据工作节点的阈值判断系统的功率。
1)
{F1,F2,…,Fm}←getUpDatafile();
/*获得用户上传数据文件*/
2)
m←Datafiles.length();
/*数据文件的个数*/
3)
StackColumnfile←file[m];
/*数据文件存储到内存栈列区*/
4)
forj=0 tom-1 do
5)
DatafileInfo={F1,F2,…,Fm}.get(file[j]);
/*获得数据文件的信息*/
6)
forj=0 ton-1 do
7)
DataTaskInfo←{A1,A2,…,An};
/*获得数据流Ai的信息*/
8)
N1(v,u)←(M(v),CPU(u))i;
/*确定起始节点N1的阈值*/
9)
switchN1(v,u)←Ai
/*如果数据流Ai满足工作节点N1的阈值*/
10)
case1:
11)
P1←MP(v,u);
/*系统功率为P1*/
12)
break;
13)
case2:
14)
/*系统功率为P2*/
15)
break;
16)
case3:
17)
/*系统功率为P3*/
18)
break;
19)
case4:
20)
/*系统功率为P4*/
21)
break;
22)
endswitch
23)
endfor
24)
endfor
根据定义2数据流处理是否满足工作节点的阈值判断系统的功率,其中:如果完全满足工作节点的阈值,则系统功率为P1;不满足数据传输量M的阈值、满足CPU的阈值,则系统功率为P2;满足数据传输量M的阈值、不满足CPU的阈值,则系统功率为P3;不满足数据传输量M的阈值且不满足CPU的阈值,则系统功率为P4。判断后的数据流通过有向无环图处理数据,其主要的主要算法如下所示。
算法2 数据处理算法。
输入 数据流{A1,A2,…,An},表示判断后的数据流经过有向无环图模型进行处理;
输出 全局变量区,处理后的数据进入内存全局变量区。
1)
N1←{A1,A2,…,An};
/*经工作节点N1判断后获取数据流Ai的信息*/
2)
Ae(i)←DataTaskInfo.getStreamFirTime();
/*获得数据流Ai的最早开始时间*/
3)
Al(i)←DataTaskInfo.getStreamFinTime();
/*获得数据流Ai的最迟开始时间*/
4)
fork=0 ton-1 do
5)
DataInfo←{a1,a2,…,an};
/*获得数据ak的信息*/
6)
ae(k)←Ae(k)-a(k);
/*数据ak的最早开始时间*/
7)
al(k)←Al(i)-a(k)-dr〈1,n〉;
/*数据ak的最迟开始时间*/
8)
T←ae(k)-al(k);
/*数据ak的机动时间*/
9)
ifT=0;
/*数据ak的传输存在关键路径*/
10)
thenE=P(max{Ae(i)+dr〈1,n〉+a(k)});
/*不存在关键路径时系统总能耗*/
11)
else
12)
thenE=P(min{Al(i)-a(k)-dr〈1,n〉});
/*不存在关键路径时系统总能耗*/
13)
end if
14)
(Fn)k←createMatrixF(ak);
/*构造数据流模型*/
15)
streamk←getcreateMatrix(Fn)k;
/*获得数据文件中的一条数据流*/
16)
GlobalVariableStream←StackColumnStream;
/*内存栈列区推进为内存全局变量区*/
17)
end for
流式计算的ESTC通过对工作节点进行阈值调控降低了不必要的功耗损失,此外工作节点可以通过数据流的处理情况对其路径进行预测与计算,提高系统的负载均衡能力,因此完全符合流式计算的思想。单位时间内通过工作节点的数据量为M,其阈值为v,CPU使用率的阈值为u,定义在T1、T2时间段内数据处理情况与时间的比值为负载均衡率L,则系统负载均衡率为:
L=(M(v),CPU(u))/(T2-T1)
(13)
其中:负载均衡率L表示当前系统节点处理数据的相对负载状况;V为负载容量,表示当前系统节点数据处理可以容纳多少负载量的一个量度,V越大数据处理的负载能力越强,表示当前系统节点还可以处理更多的数据。定义在单位时间内数据量M与负载均衡率L的乘积为数据处理负载容量V,其单位为tuple,计算式为:
V=M(M(v),CPU(u))/(T2-T1)
(14)
3 流式计算能耗模型及节能策略
3.1 能耗模型
功耗和能耗都是对系统能量消耗的量度,但其意义不同。ESTC为单位时间内计算系统的能耗,功率P是系统单位时间内的功耗,其单位为W。功率P与系统运行时间内的乘积是能耗E,其单位为J。能耗E[15]计算式如下:
(15)
由此可见,式(15)反映了一段时间内系统总的能耗问题。由于系统能耗的降低可能会引起系统性能的下降,从而对整个系统造成影响,因此不能一味地降低系统的能耗。本节从能耗的角度考虑节能问题,并以节点作为主要的研究对象,是节点级的节能策略。系统工作节点主要存在内存的栈列区内,内存由金手指、内存芯片、电路板等部分组成,其主要划分为四个区域:I/O读写区、栈列区、全局变量区与代码区。以Storm系统的动态随机存取器(DynamicRandomAccessMemory,DRAM)为例,ESTC作用于内存栈列区,其主要工作流程如图3所示。

图3 ESTC工作流程
数据流通过I/O读/写入内存的栈列区,内存能量状态升高,内存芯片的工作电压最大,数据流在内存中不断运动,其通过节点的数据逐渐增减,由此可见,内存栈列区的能耗最大。当I/O读/写区不再作用这段位于内存中的数据流,内存能量减少,内存芯片工作电压下降,数据流动速度降低,此时存在这段数据流的内存从栈列区推进到全局变量区。 因此,原系统的内存能耗EOce为:
EOec=ESC+EGV+ECS+ECPU+EIO
(16)
其中:ESC、ECS、EGV为内存栈列区、代码区与全局变量区的能耗;ECPU为数据流经CPU计算后的能耗;EIO为数据读/写的能耗。
3.2ESTC
数据流通过I/O读/写入内存栈列区后,根据内存寻址将内存中的数据提交到CPU内的工作节点进行阈值判断,而后进行处理计算,并经过内存实现数据的传输,此外,数据处理的阈值通过系统工作节点的负载情况确定。根据数据流处理传输的随机选择情况确定对系统物理电压的调控,从而确定系统相对的功率,此过程在内存堆栈区完成。经计算后的数据通过CPU进行内存传输,把数据传输到内存全局变量区,该过程会对数据进行存取且会产生延迟时间。此时,系统的能耗EEc为:
EEc=(ESC+ECPU)change+EGV+ECS+EIO
(17)

(18)
将式(6)与(7)代入式(18),存在机动时间T,此时最早开始时间与最迟开始时间并不相等,由此可见,可分两种情况计算系统节约的能耗,如(19)所示:
ESave=
(19)
其中:式(19)的参数与式(6)、(7)、(18)相同,式(19)为数据流经内存后得到的总的内存能耗。
4 实验结果及评价
实验以Storm系统为例进行,且Storm框架支持多种语言窗口,内存节能策略使用Java语言实现Storm的计算处理程序。
搭建的集群有1个主控节点Nimbus、4个工作节点Supervisor与1个协调节点Zookeeper,且整个集群在无其他任务运行的条件下进行该实验。
本文实验主要目的是测试流式计算的能耗优化与处理性能,主要的测试标准有数据的吞吐量、能耗情况、数据的处理响应时间等。定义每秒传输10~50个tuple元组,实验算法采用WordCount、RollingCount[18]与Sol进行基准用例测试,最后进行实验的结果分析。
4.1 实验环境
为了验证基于流式计算系统ESTC的有效性,实验需要注意以下两点:1)不同的数据变化会带来不同的能耗;2)不同的数据访问频率下的节点级存储计算结构变化。该实验的Storm环境是在普通的PC机下完成的,内存为4GB。根据不同节点的运行情况,Storm集群节点及数据处理环境的配置参数如表1所示。
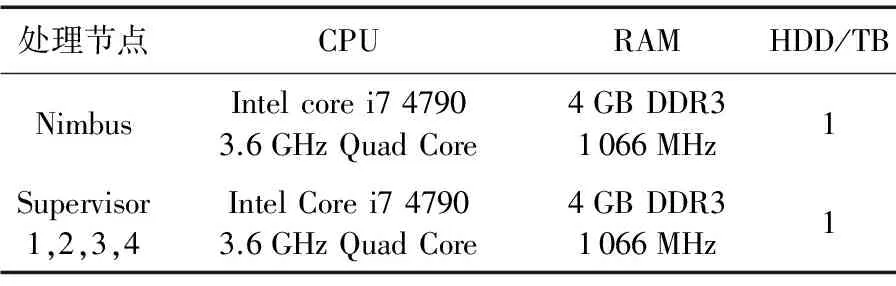
表1 Storm环境配置参数
其中,控制台节点进程UI、协调节点进程Zookeeper与主控节点进程Nimbus运行在同一台物理机上,故其硬件配置相同。工作节点进程Supervisor1、2、3、4分别部署在4台不同的PC机上。除此之外,各节点其他参数配置相同,现每台PC机内传输1GB数据集群配置参数如表2所示。

表2 Storm集群配置参数
为全面测试ESTC的有效性,实验选取3种不同基准测试用例对该策略进行测试,分别是CPU敏感型(CPU-Sensitive)的WordCount,Storm真实场景下的应用RollingCount以及网络带宽敏感型(Network-Sensitive)的Sol,各基准测试运行时工作进程(worker)的数量与当前所需的工作节点数量保持一致,其余参数保留其默认配置。
此外,当额定电压为1.5V,且在5min内不停传输数据时,不同内存状态下的能耗情况如表3所示。

表3 DDR3 1066内存能耗的数据测量值
4.2ESTC的结果及分析
根据4.1节环境设置完成以下实验:由于流式计算为节点级计算,因此在节能的同时需要保持较高的计算效率,不能影响系统的性能。为便于实验观测,根据三种基准测试用例设置metrics.poll的值为60 000ms,metrics.time的值为300 000ms,即每组实验每30s刷新一次数据,共统计5min。现有20台PC根据表1~2中的环境组成集群进行4组实验,且每组实验5台PC,通过ESTC的不同阈值情况完成实验,并通过对比进行分析。该实验利用计算数据产生的工作节点情况,根据数据单位时间处理量与CPU使用率的负载情况确定相对合适的阈值情况,实验结果如图4所示。

图4 阈值调控策略的负载变化
从图4可以看出,随着节点阈值的不断改变,数据负载均衡容量V也在不断发生变化。图4中:实验组test0为原系统不改变节点阈值的负载均衡容量,数据处理从0s开始逐步稳定在90s左右,系统负载容量V逐步稳定在1 100tuple;实验组test1表示系统阈值为CPU使用率65%,数据处理量为20tuple/s,数据稳定时间基本相同但系统负载容量V逐步稳定在1 300tuple;实验组test2表示系统阈值为CPU使用率65%,数据处理量为30tuple/s,同理可知系统负载容量V逐步稳定在1 600tuple;而实验组test3表示系统阈值为CPU使用率70%,数据处理量为30tuple/s,同理可知系统负载容量V逐步稳定在1 500tuple。从实验组test0到test3的结果对比可以看出,根据不同的节点阈值情况,系统负载均衡容量V不同,且实施节能策略后获得的系统负载容量比原系统显著增加。根据上述测试,系统阈值为CPU使用率65%,数据处理量为30tuple/s的情况时节能效果最好,因此后面的实验阈值以此为准。
阈值调控策略通过不同阈值情况调节系统不同电压,根据不同的基准测试进行判断,以验证实验的真实性与应用性。通过传输速率为10~50tuple/s的系统能耗,对系统进行三种不同基准测试用例,分别为CPU敏感型的WordCount,Storm真实场景下的应用RollingCount以及网络带宽敏感型的Sol,其中基准测试WordCount与Sol为理想状态下系统的能耗情况,RollingCount为真实环境下系统的能耗情况。测试结果如图5所示。

图5 在10~50 tuple/s传输速率下系统不同测试的能耗情况
通过不同基准测试可以看出,随着时间的增加,系统的能耗不断上升,且进行阈值调控策略的系统能耗上升小于原系统。根据图5分析得,真实环境下还存在着电压不稳等物理因素影响系统的能耗。根据不同的感知策略对系统的能耗进行测试,其测量结果如图6所示,0~60s为10tuple/s的传输速率,60~120s为20tuple/s的传输速率,120~180s为30tuple/s的传输速率,180~240s为40tuple/s的传输速率,240~300s为50tuple/s的传输速率;SR=1表示系统只存在内存休眠状态,PRE=0表示系统不存在内存空闲状态。
从图6可以看出,不同感知策略对于系统能耗的影响不同,实验组test0表示原系统不进行任何感知策略,实验组test1为内存休眠节能策略系统产生的能耗,实验组test2为ESTC系统产生的能耗,实验组test3为实行Re-Stream[5]调度策略系统产生的能耗。实验组test0能耗基本不受系统数据处理带来的影响。实验组test1表示计算后数据进行休眠策略后的能耗效果,在240s前实验组test1节能效果要差于实验组test2与test3两种感知策略,在240s后逐渐与实验组test3接近,且节能效果优于实验组test2。实验组test2在30tuple/s前满足阈值策略,其能耗与实验组test3接近,数据传输速率超过30tuple/s,能耗增加明显,在50tuple/s的传输速率时超过实验组test1。实验组test3为Re-Stream策略,改变系统的结构框架,其节能效果最好,但是,Re-Stream策略存在框架改变复杂性与系统不匹配的问题。从实验组test0与test2的对比可以看出,通过使用ESTC将原系统的能耗降低了35.2%,综上所述,ESTC具有显著的效果。

图6 在10~50 tuple/s传输速率下系统不同策略的能耗情况
ESTC应该以性能为出发点,策略对流式计算性能存在影响,则ESTC是失败的,对于流式计算性能的判断标准应该从数据处理速率出发,不影响单位时间内数据处理速率的能耗策略才是成功的,用数据处理速率与能耗的比值关系性耗比来判断ESTC是否有效,内存节能策略的性耗比关系如图7所示。
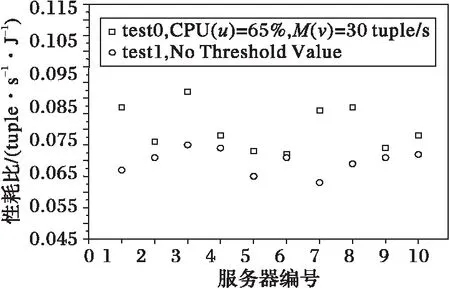
图7 ESTC的性耗比
根据图7的实验结果可以看出,ESTC并不影响流式计算系统的性耗比,但是能耗与数据处理速率之间的比值存在误差,每组实验不同服务器之间的性耗比并不相同,经实验反复测得实验存在误差C的范围为[0.7,1.3]。实验组test1为原系统5台PC的性耗比,其平均性耗比为0.069 8tuple/(s·J)。实验组test0为系统进行ESTC后5台PC机的性耗比,其平均性耗比为0.080 3tuple/(s·J)。由此可见,ESTC的性能优于原系统,因此ESTC是完全可行的。
5 结语
随着数据的不断增长,大数据技术不断发展,各种流式计算系统和平台不断增加,流式计算系统节能已经成为了一个不容忽视的问题。流式计算响应了时代的需求,其处理数据的本质为工作节点对数据流的处理。针对能耗问题,本文提出了大数据流式计算环境下的阈值调控节能策略(ESTC),即通过工作节点阈值对数据流进行随机选择,从而物理调控系统电压,减少了系统不必要的能耗损失,同时有效提高系统的负载均衡能力。经实验论证可知,ESTC不仅有效地提高了流式计算的能量利用率,并且提高了系统数据的延展性,为构建低能耗IT环境提供了帮助。
下一步的研究工作内容包括以下几点:1)从流式计算的性能考虑,以不改变甚至提高系统性能为前提,实现流式计算的节能。可通过提高系统的计算速率实现节能,如将部分CPU替换成图形处理器(GraphicsProcessingUnit,GPU)进行数据的处理计算。2)可以增大流式计算系统的网络带宽,带宽越大,数据量传输速率越快,数据处理的时间变短,从而提高系统的节能效果。因此,可以考虑网络带宽的节能策略,以更好地解决流式计算的能耗问题。
)
[1]GAIKK,QIUMK,ZHAOH,etal.Dynamicenergy-awarecloudlet-basedmobilecloudcomputingmodelforgreencomputing[J].JournalofNetworkandComputerApplications, 2016, 59(C): 46-54.
[2] 邓维,刘方明,金海,等.云计算数据中心的新能源应用: 研究现状与趋势[J].计算机学报,2013,36(3):582-598.(DENGW,LIUFM,JINH,etal.Leveragingrenewableenergyincloudcomputingdatacenters:stateoftheartandfutureresearch[J].ChineseJournalofComputers, 2013, 36(3): 582-598.)
[3] 国冰磊,于炯,廖彬,等.结构化查询语言动态功耗解析及建模[J].计算机应用,2015,35(12):3362-3367.(GUOBL,YUJ,LIAOB,etal.Dynamicpowerconsumptionprofilingandmodelingbystructuredquerylanguage[J].JournalofComputerApplications, 2015, 35(12): 3362-3367.)
[4] 于炯, 廖彬, 张陶,等.云存储系统节能研究综述[J].计算机科学与探索,2014,8(9):1025-1040.(YUJ,LIAOB,ZHANGT,etal.Asurveyonenergy-efficientcloudstoragesystem[J].JournalofFrontiersofComputerScienceandTechnology, 2014, 8(9): 1025-1040.)
[5]SUNDW,ZHANGGY,YANGSL,etal.Re-Stream:real-timeandenergy-efficientresourceschedulinginbigdatastreamcomputingenvironments[J].InformationSciences, 2015, 319: 92-112.
[6]CORDESCHIN,SHOJAFARM,AMENDOLAD,etal.Energy-efficientadaptivenetworkeddatacentersfortheQoSsupportofreal-timeapplications[J].TheJournalofSupercomputing, 2015, 71(2): 448-478
[7]Apache.Storm[EB/OL]. [2016- 11- 13].http://storm-project.net.
[8]SCALOSUBG,MARBACHP,LIEBEHERRJ.Buffermanagementforaggregatedstreamingdatawithpacketdependencies[C]//INFOCOM’10:Proceedingsofthe29thConferenceonInformationCommunications.Piscataway,NJ:IEEE, 2010: 241-245.
[9] QIAN Z P, HE Y, SU C Z, et al. TimeStream: reliable stream computation in the cloud [C]// EuroSys’13: Proceedings of the 8th ACM European Conference on Computer Systems. New York: ACM, 2013: 1-14.
[10] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.(SUN D W, ZHANG G Y, ZHENG W M. Big data stream computing: technologies and instances [J]. Journal of Software, 2014, 25(4): 839-862.)
[11] SIMONCELLI D, DUSI M, GRINGOLI F, et al. Scaling out the performance of service monitoring applications with BlockMon [C]// Proceedings of the 2013 International Conference on Passive and Active Network Measurement. Berlin: Springer, 2013: 253-255.
[12] SEGULJA C, ABDELRAHMAN T S. Architectural support for synchronization-free deterministic parallel programming [C]// Proceedings of the 2012 IEEE 18th International Symposium on High-Performance Computer Architecture. Piscataway, NJ: IEEE, 2012: 1-12.
[13] WHITE T, CUTTING D. Hadoop: The Definitive Guide [M]. Sebastopol, CA: O’Reilly Media Inc, 2010: 1-4.
[14] LIM L, MISRA A, MO T. Adaptive data acquisition strategies for energy-efficient, smartphone-based, continuous processing of sensor streams [J]. Distributed and Parallel Databases, 2013, 31(2): 321-351.
[15] 林闯,田源,姚敏.绿色网络和绿色评价:节能机制、模型和评价[J].计算机学报,2011,34(4):593-612.(LIN C, TIAN Y, YAO M. Green network and green evaluation: mechanism, modeling and evaluation [J]. Chinese Journal of Computers, 2011, 34(4): 593-612.)
This work is partially supported by the National Natural Science Foundation of China (61462079,61562086,61562078), the Research Innovation Project of Graduate Student in Autonomous Region (XJGRI2016028).
PU Yonglin, born in 1991, M. S. candidate. His research interests include green computing, distributed computing.
YU Jiong, born in 1964, Ph. D., professor. His research interests include grid computing, green computing, distributed computing.
WANG Yuefei, born in 1991, Ph. D. candidate. His research interests include distributed computing, grid computing.
LU Liang, born in 1990, Ph. D. candidate. His research interests include distributed computing, green computing, in-memory computing.
LIAO Bin, born in 1986, Ph. D., associate professor. His research interests include green computing, database technology.
HOU Dongxue, born in 1992, M. S. candidate. His research interests include recommended algorithm.
Energy-efficient strategy for threshold control in big data stream computing environment
PU Yonglin1, YU Jiong1,2*, WANG Yuefei2, LU Liang2, LIAO Bin3, HOU Dongxue1
(1.SchoolofSoftware,XinjiangUniversity,UrumqiXinjiang830008,China; 2.SchoolofInformationScienceandEngineering,XinjiangUniversity,UrumqiXinjiang830046,China; 3.SchoolofStatisticsandInformation,XinjiangUniversityofFinanceandEconomics,UrumqiXinjiang830012,China)
In the field of big data real-time analysis and computing, the importance of stream computing is constantly improved while the energy consumption of dealing with data on stream computing platform rises constantly. In order to solve the problems, an Energy-efficient Strategy for Threshold Control (ESTC) was proposed by changing the processing mode of node to data in stream computing. First of all, according to system load difference, the threshold of the work node was determined. Secondly, according to the threshold of the work node, the system data stream was randomly selected to determine the physical voltage of the adjustment system in different data processing situation. Finally, the system power was determined according to the different physical voltage. The experimental results and theoretical analysis show that in stream computing cluster consisting of 20 normal PCs, the system based on ESTC saves about 35.2% more energy than the original system. In addition, the ratio of performance and energy consumption under ESTC is 0.080 3 tuple/(s·J), while the original system is 0.069 8 tuple/(s·J). Therefore, the proposed ESTC can effectively reduce the energy consumption without affecting the system performance.
stream computing; threshold; load difference; random selection; system performance
2016- 11- 30;
2017- 01- 17。
国家自然科学基金资助项目(61462079,61562086,61562078);自治区研究生科研创新项目(XJGRI2016028)。
蒲勇霖(1991—),男,山东淄博人,硕士研究生,CCF会员,主要研究方向:绿色计算、分布式计算; 于炯(1964—),男,新疆乌鲁木齐人,教授,博士,CCF会员,主要研究方向:网格计算,绿色计算、分布式计算; 王跃飞(1991—),男,新疆乌鲁木齐人,博士研究生,主要研究方向:分布式计算、网格计算; 鲁亮(1990—),男,新疆乌鲁木齐人,博士研究生,CCF会员,主要研究方向:分布式计算、绿色计算、内存计算;廖彬(1986—),男,新疆乌鲁木齐人,CCF会员,副教授,博士,主要研究方向:绿色计算、数据库技术; 侯冬雪(1992—),女,新疆昌吉人,硕士研究生,主要研究方向:推荐算法。
1001- 9081(2017)06- 1580- 07
10.11772/j.issn.1001- 9081.2017.06.1580
TP311.1
A
