早稻氮磷钾施肥类别归属的贝叶斯判别方法研究
2017-09-03章明清李娟许文江孔庆波姚宝全
章明清,李娟,许文江,孔庆波,姚宝全
(1福建省农业科学院土壤肥料研究所,福建福州350013;2福建省亚热带植物研究所,福建厦门361006;3福建省农田建设与土壤肥料技术推广总站,福建福州350003)
早稻氮磷钾施肥类别归属的贝叶斯判别方法研究
章明清1,李娟1,许文江2,孔庆波1,姚宝全3
(1福建省农业科学院土壤肥料研究所,福建福州350013;2福建省亚热带植物研究所,福建厦门361006;3福建省农田建设与土壤肥料技术推广总站,福建福州350003)
【目的】在测土配方施肥中,“测土”是实现合理施肥微观指导的关键技术手段。本研究针对高度分散经营的耕地代表性土样采集难、测试费用高、花费时间长等“测土”难题,探讨早稻氮磷钾施肥类别归属的统计模式识别技术。【方法】利用闽东南80个早稻氮磷钾田间肥效试验资料作为样本,采用欧氏距离–离差平方和法进行系统聚类分析,建立区域早稻施肥类别。在此基础上,根据田块氮磷钾施肥量及其产量结合地力信息等数量指标,应用贝叶斯判别准则探讨具体田块的施肥类别归属。【结果】在确保空白区产量和平衡施肥产量均值在两两施肥类别间具有统计显著差异的前提下,闽东南早稻最多可划分为6个氮磷钾施肥类别。多元统计检验表明,6个施肥类别的类内协方差矩阵差异不全相等,据此建立了各个施肥类别的贝叶斯判别函数。结果表明,原始试验数据标准化处理可大幅度提高判别准确性,监测样本的回代误判率和交叉误判率分别只有1.2%和1.3%,预留6个试验点的84个处理的氮、磷、钾施肥量和产量试验资料的施肥类别归属的判别正确率达到81.0%。【结论】统计模式识别原理及其贝叶斯判别准则可用于早稻氮磷钾施肥类别归属决策,判别准确性能够满足推荐施肥的精度要求。
早稻;氮磷钾;施肥类别;贝叶斯判别;类别归属
近10年来,我国在测土配方施肥技术推广应用过程中,利用“3414”设计开展了数以万计的作物氮磷钾田间肥效试验,数量之多和范围之广是罕见的。如何正确利用这些田间肥效试验结果来指导作物合理施肥是一个大问题。根据“3414”试验设计特点,一个试验点结果可分别建立三个一元肥效模型、三个二元肥效模型和一个三元肥效模型。肥效模型的优点是直观和计量准确,但其微观指导功能较弱。为了弥补肥效模型在应用上的不足,一些学者将土壤有效养分含量等地点变量引入到模型中[1,2],或者建立土测值与肥效模型推荐施肥量的回归关系式[3–5],从而实现了微观指导功能。显然,这种改进是建立在田间试验基础上,通过田间试验获取模型参数,在具体应用时都需要测土这一技术环节。但是,在广大农村的取土和测土过程中,常遇到代表性土样采集难、测试费用高和耽误农时等难题,制约了计量施肥技术的推广普及[6]。因此,在田间肥效试验结合测土的研究基础上,探讨高效和准确的推荐施肥技术具有重要的实用价值,可对测土配方施肥起到有益补充。
推荐施肥技术如何实现既高效快速又有较高准确度呢?统计模式识别原理和技术为我们提供了有益的启发。该技术已在生物技术[7–8]、作物品种鉴别[9]、土壤分类[10–13]、水土保持区划[14]等领域得到应用,但在作物施肥类别归属判别上的应用还鲜见报道。为此,本文利用闽东南地区近年来完成的86个早稻“3414”设计氮磷钾田间肥效试验资料,在建立早稻氮磷钾施肥类别基础上,探讨区域内具体田块氮磷钾施肥类别归属的贝叶斯判别方法及其可行性,以期为最大限度地发挥众多“3414”田间试验资料在指导合理施肥中的作用提供一种新途径。
1 材料与方法
1.1 早稻氮磷钾肥效试验资料的收集整理
在近年来的测土配方施肥工作中,福建在福州市、莆田市、泉州市和漳州市等闽东南沿海地区早稻上先后完成了86个“3414”设计的氮磷钾田间肥效试验。每个试验设14个处理,即:1)N0P0K0;2)N0P2K2;3)N1P2K2;4)N2P0K2;5)N2P1K2;6)N2P2K2;7)N2P3K2;8)N2P2K0;9)N2P2K1;10)N2P2K3;11)N3P2K2;12)N1P1K2;13)N1P2K1;14)N2P1K1。其中,“2”水平为试验前当地推荐施肥量,“0”水平表示不施肥,“1”水平和“3”水平的施肥量分别为“2”水平的50%和150%,具体试验施肥量设计和实施方案与李娟等[4]相同。
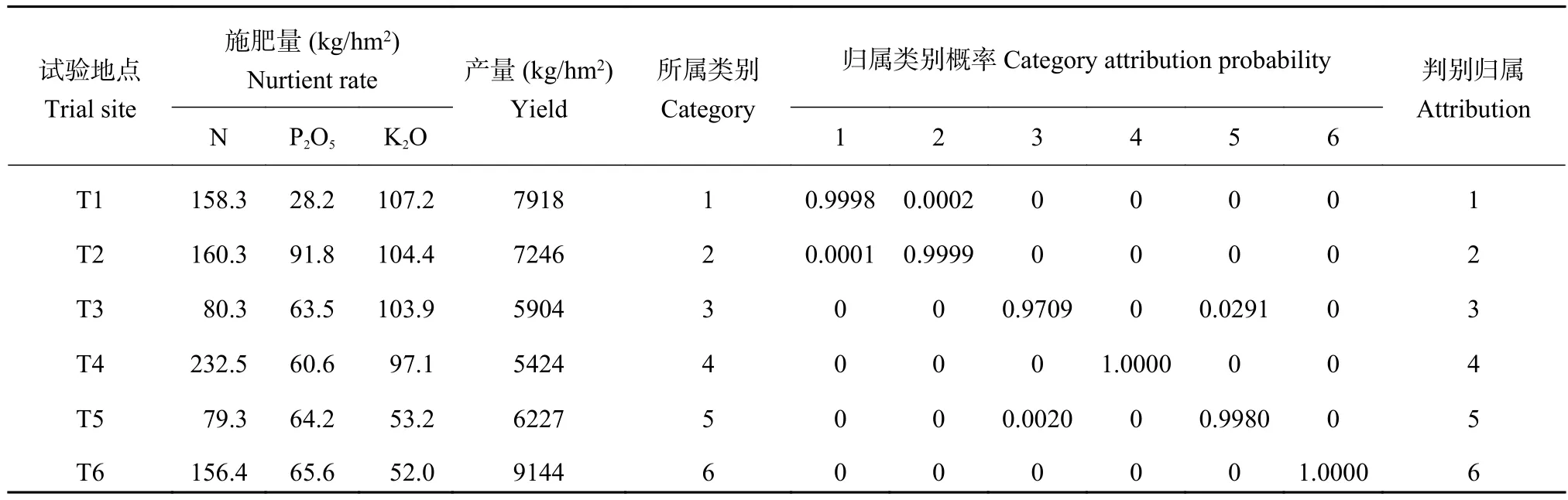
在86个试验资料中,取80个试验资料作为建立氮磷钾施肥类别的训练样本,按照不同地区预留6个试验点资料(表1)用于检验判别结果可靠性。这6个试验资料分别来自闽侯县灰泥田、闽清县黄泥田、仙游县灰泥田和灰沙田、龙海市灰泥田以及平和县灰沙田的试验结果。基础土样采用常规方法[15]测定土壤主要理化性状,其中,土壤pH为4.7±0.6,土壤有机质为22.7±1.0g/kg,土壤碱解氮、Olsen-P和速效钾含量分别为120.7±43.8mg/kg、33.9± 22.8mg/kg和69.3±32.7mg/kg。每个试验点都有14个处理的氮、磷、钾施肥量和产量数据,即有84个待判样本,其中,处理1)无肥区产量水平变化幅度为3315~7470kg/hm2,处理6)平衡施肥产量变化幅度为5355~10500kg/hm2,基本涵盖了该区域早稻产量水平的可能范围。
1.2 氮磷钾施肥类别归属的判别原理
根据统计模式识别原理[16],要进行未知施肥类别归属的判别分析,首先要在多点田间肥效试验基础上,构建研究区域的早稻施肥类别。这就要对该区域内的早稻肥效试验资料进行合理的定量分类。研究表明,对研究区域较小的作物氮磷钾肥效试验资料,欧氏距离–离差平方和法是最佳的系统聚类分析方法[17],因而采用该法建立闽东南早稻氮磷钾施肥类别及其类特征肥效方程,并据此提出各施肥类别的推荐施肥量。

表1 “3414”预留试验点的施肥量及其产量试验数据Table 1 Application rates of N, P and K fertilizers and the yields in the 14 treatments of six reserved experiments
早稻施肥类别归属判别是指在构建区域早稻施肥类别后,确定该区域内某个田块或几个相邻田块同种作物的施肥类别应属于这些已知类别中的哪一类。贝叶斯判别准则是统计模式识别中应用最广泛的模式归属判别方法,是根据待判样本属于各个类别的条件概率值大小,将其判归条件概率最大的那个类别。对多于2个以上类别的贝叶斯判别,当各施肥类别的协方差矩阵相等时,基于误判损失相等的贝叶斯判别函数[16,18]为:
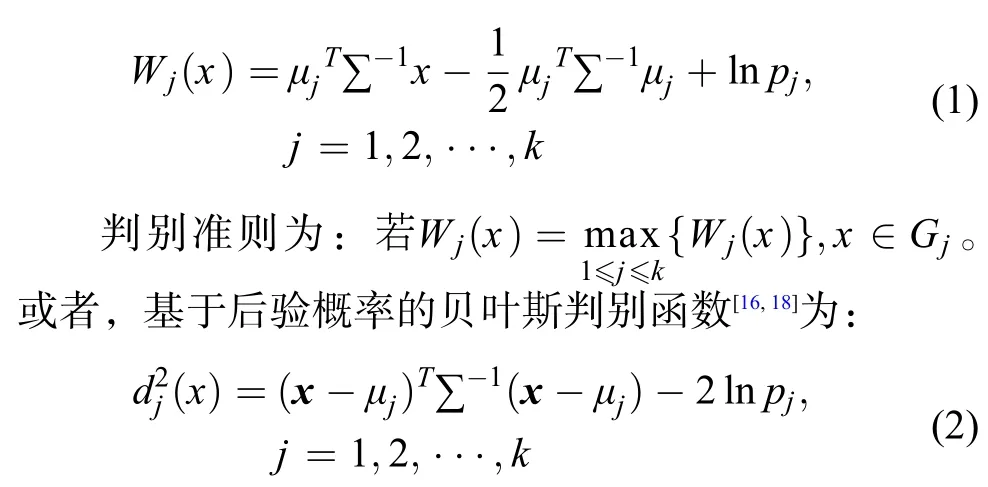
当各施肥类别的协方差矩阵不全相等时,基于后验概率的贝叶斯判别函数[16,18]则为:
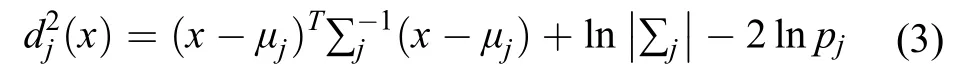
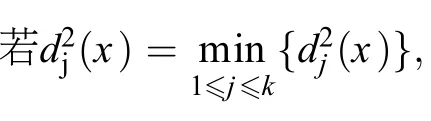
1.3 数据标准化和协方差矩阵差异显著性检验
在建立判别函数时要用到的均值和协方差矩阵,其数值大小受到数据量级和量纲的影响。因此,在建立各施肥类别的判别函数前,需对施肥量和产量原始数据进行标准化处理。计算公式为:

其中:x*表示x指标经标准化处理后的数值,x¹和s分别表示氮、磷、钾施肥量和产量各指标的平均值和标准差。
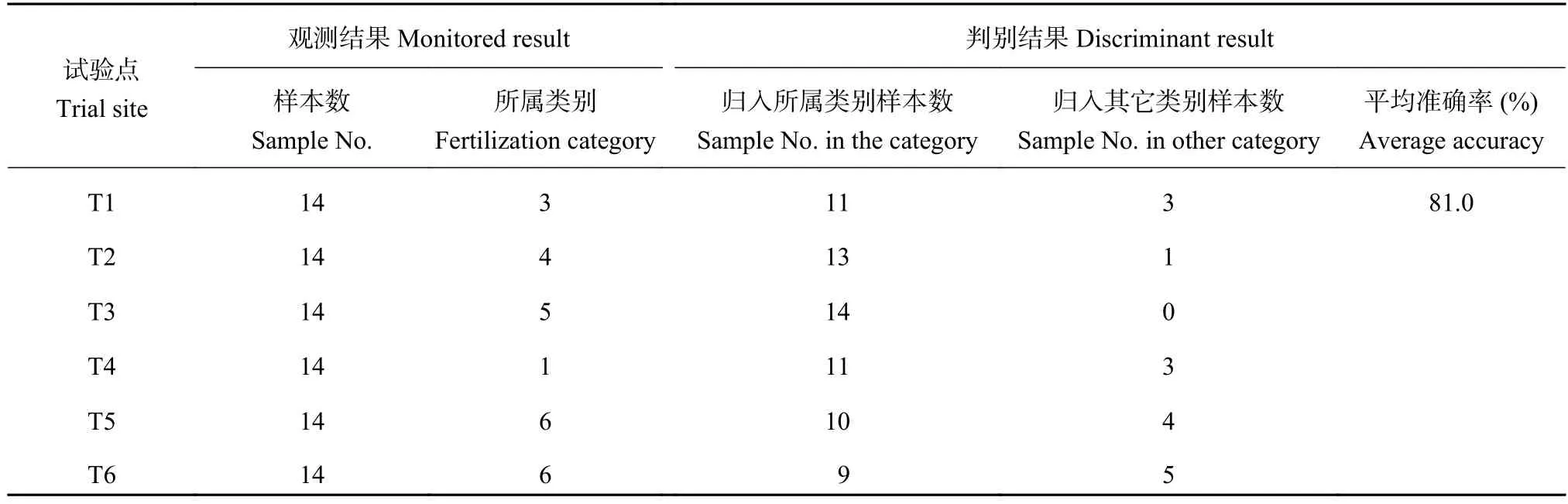
由于施肥类别间协方差矩阵相等或不全相等时的判别函数不同,因而需要对各施肥类别的协方差矩阵进行差异显著性检验。假设有氮、磷、钾施肥量和产量4个指标观测值的k个施肥类别Gi(i=1,2, 3,…,k),分别从中抽取样本容量为ni的k个样本,协方差矩阵分别为S1,S2,…,Sk。原假设为各施肥类别的协方差矩阵相等,则统计量[18–19]:样本总数n=n1+n2+….+nk。对给定的概率值a,计算概率p=P(»>Âa2(df)),若p 1.4 系统聚类分析和施肥类别归属判别的简洁方法 构建施肥类别的系统聚类分析和施肥类别归属的贝叶斯判别分析均涉及到深奥数学原理和复杂计算,不可能通过人工演算或计算器计算来完成。本文聚类分析的具体计算过程调用MATLAB软件的pdist、linkage和dendrogram等功能函数完成。贝叶斯判别分析采用MATLAB软件提供的功能强大的classify函数来进行相关计算,具体使用方法可参阅相关专著[19]。 考虑到现有参考文献大都未能准确地介绍classify函数的使用方法,根据本研究对此的学习和体会简要介绍如下,以供相关应用时参考。classify函数的调用格式为:[class,err,Poster]=classify(sample, training,group,type,prior)。其中,class给出待判样本归属的判别结果,err是训练样本回代误判率,Poster是待判样本归属的后验概率。sample是指待判样本,training是指已知类别归属的训练样本,group是对应训练样本的类别编号,type是指具体判别分析方法的选择项,包括linear、quadratic和mahal等,prior是指先验概率的可选项,用来指定各类别的先验概率值。应特别注意,type选项若选择linear或quadratic,classify函数将采用贝叶斯判别,若选用mahal(马氏距离)时则采用距离判别,此时Poster选项的输出项为空集,先验概率只能用来计算误判概率。上述相关输入和输出数据均以矩阵或向量的形式表达。MATLAB软件没有提供交叉误判率的计算程序,要使用必须自己编写计算程序。 对于试验数据标准化处理,本文采用MATLAB软件的zscore函数,其调用格式为[S,mu,sig]= zscore(X)。其中,X表示原始试验数据矩阵,S表示数据标准化处理结果,mu和sig分别表示原始数据各观测指标的平均值和标准差。 表2 早稻氮磷钾试验处理类别及类别间差异显著性分析 (P < 0.05)Table 2 Category of the fertilization treatments and the paired significance analysis of the categories 2.1 早稻氮磷钾施肥类别的构建 为建立闽东南地区早稻氮磷钾施肥类别,参照毛达如等[20]建立类特征肥效方程的思路,利用80个早稻“3414”设计的氮磷钾田间肥效试验资料,采用欧氏距离–离差平方和法对每个试验点的14个处理产量进行系统聚类分析,并对各施肥类别的处理1)空白区产量和处理6)平衡施肥产量进行均值差异显著性检验[18]。 表2的结果显示,当80个试验资料分成9类或10类时,总有两类或两类以上的均值差异不显著,导致定量分类结果无效;分成7类或7类以上时,总有一类的试验点数只有一个,导致该类别因试验点过少而缺乏代表性。因此,有效分类数最多为6个施肥类别,此时每一个施肥类别至少有7个代表性试验点,同时确保了类与类之间的空白区产量均值和平衡施肥产量均值的差异达到统计显著水平。结果表明,依据空白区产量和平衡施肥产量水平,6个施肥类别可分别命名为“超高产田”、“高产田” “中高产田”、“中产田”、“中低产田”和“低产田”等六种稻田施肥类型(表3)。 根据各施肥类别对应试验点的试验结果,分别建立氮磷钾三元二次多项式肥效模型(略)。统计表明,6个施肥类别的三元肥效模型的F值均达显著水平,而且模型参数正负号满足水稻营养特性,均为典型肥效模型[21]。因此,以每公斤N4.3元、P2O55元、K2O6元和稻谷2元的当地市场均价为依据,用边际产量导数法计算各施肥类别的推荐施肥量(表3)。但在指导该区域早稻合理施肥时,用户的具体田块的推荐施肥该归属于哪个施肥类别呢?以往常用的方法是根据用户常年空白区产量或者预期施肥目标产量,对照表3的结果进行推荐。但是,在广大农村中空白区产量或施肥目标产量等指标难以准确获取,在应用上尚存在困难,模式识别技术可使表3结果的实际应用更为简便和可靠。 表3 供试地块基础产量、目标产量及其推荐施肥量 (kg/hm2)Table 3 Paddy field yield levels, blank yields and the recommended fertilizer rates for the target yields in different categories of N, P and K fertilization recommendation for early rice 表4 各施肥类别的训练样本的氮、磷、钾施肥量和产量均值 (kg/hm2)Table 4 Average N, P and K fertilizer rates and early rice yields in the selected training samples from the six fertilization categories 2.2 早稻氮磷钾施肥类别的训练样本 根据统计模式识别原理[16],要对未知施肥类别的地块做出施肥决策,首先应根据各施肥类别的相关试验资料,提取各类别的特征样本作为训练样本。这样做的缘由是使后续建立决策准则更容易,结果更稳定和易于理解。因此,根据80个试验点在6个施肥类别中的归属,针对同一施肥类别内各试验点的14个处理,提取相同处理的氮、磷、钾施肥量及其对应产量均值,作为该类别的训练样本,结果见表4。 根据“3414”试验设计方案,表4的每个施肥类别有14个处理,每个处理含有4个指标,即:氮、磷、钾施肥量及其产量。从表中可以看到,施肥量数据在10的一次方和二次方量级之间,而产量数据在10的三次方量级,数值大小差异较大。为消除数据量级差异的影响,在建立判别函数前,需对80个试验资料的施肥量和产量原始数据根据(4)式进行标准化处理,然后利用处理后的数据分别建立6个施肥类别的判别函数。 2.3 早稻氮磷钾施肥类别归属的判别函数及其应用 将80个试验资料分成6个施肥类别时,根据(5)式的ζ统计量,各施肥类别的协方差矩阵差异显著性检验结果表明,自由度df等于50,统计量ζ等于376.97,大于临界值表明各施肥类别间协方差矩阵不全相等。因此,需采用基于(3)式的贝叶斯判别函数。 为得到(3)式判别函数的具体表达式,如上所述,第一步,对80个试验资料分别计算各处理氮、磷、钾施肥量及其对应试验产量的平均值和标准差。第二步,利用第一步得到的各处理氮、磷、钾施肥量及其产量的平均值和标准差,分别计算表4中6个施肥类别的对应试验点14个处理中各处理对应的氮、磷、钾施肥量和产量的标准化数值。第三步,在此基础上,分别计算各施肥类别的氮、磷、钾施肥量和产量的均值、协方差矩阵及其逆矩阵。第四步,取各施肥类别的试验点数除以试验总数(80个),所得数值作为其先验概率值。最后,将所得数值分别代入(3)式判别函数式,分别得到6个施肥类别的判别函数表达式。 为便于理解,对表4的各施肥类别分别随机抽取一个处理作为样本,即氮、磷、钾施肥量及其对应产量,利用MATLAB软件的classify功能函数计算其后验概率值(表5)。结果表明,来自第1、2、3、4、5、6个施肥类别的样本分别归属于原所属施肥类别的概率值为0.9998、0.9999、0.9709、1.0000、0.9980、1.0000,即,判别结果正确地归属于它们原来的所属类别。 2.4 氮磷钾施肥类别归属准确性评价 模式识别准确性评估常用训练样本的回代误判率和交叉误判率指标。根据表4的6个施肥类别80个试验点的氮、磷、钾施肥量和产量数据,应用MATLAB软件提供的classify函数计算回代误判率,同时自编程序计算交叉误判率。结果表明,如果原始数据未经标准化处理就建立判别函数,回代误判率和交叉误判率则分别达到34.5%和41.3%,判别准确性显然不能满足应用需要。但对原始数据进行标准化处理后建立判别函数,回代误判率和交叉误判率则分别下降到1.2%和1.3%,完全满足推荐施肥的精度要求,说明训练样本数据经过标准化处理可大幅度提高判别准确性。 回代误判率和交叉误判率作为评价指标的缺点是可能高估了模式识别系统的性能。为此,进一步利用预留的6个试验点资料(表1)作为待判样本来检验判别效果。首先参考当前多点试验资料汇总中土壤肥力等级划分的一般方法[4–5],根据空白处理和平衡施肥处理的产量水平,与表4中各施肥类别的相应处理产量水平的接近程度,确定这6个试验点的施肥类别归属。然后,利用已建立的贝叶斯判别函数检验其类别归属是否一致。一般认为,判别准确性达到80%左右时[18],该模式识别系统即可投入使用。表6结果表明,对包括氮、磷、钾施肥量和产量指标的84个处理的样本,平均判别准确率达到81.0%。可见,贝叶斯判别的准确率达到推荐施肥对精度的一般要求。 表5 基于后验概率的贝叶斯判别函数的施肥类别归属的判别结果Table 5 Recognition results of fertilization category attribution based on posterior probability of the Bayesian discriminant function 表6 预留6个试验点贝叶斯判别函数判别的施肥类别Table 6 Fertilization categories of the reserved six trial sites attributed by the Bayesian discriminant function 3.1 测土施肥技术的适用性 土壤测定与推荐施肥技术经过20世纪四十年代至六十年代这一段时间的发展,已奠定了良好的科学基础,并确立了一整套国际公认与通用的工作方法[22–23],在农业规模化生产的欧美发达国家无不行之有效。我国在测土配方施肥技术发展过程中,于1990年前后分别提出了“先测土后效应”和“先效应后测土”两大技术路线[24–25],要实现合理施肥的微观指导同样必须测土。毫无疑问,“测土”对于单个试验点的深入研究非常有效,能够让人们对耕地土壤肥力状况、作物需肥规律和推荐施肥三者间关系有深入的认识和掌握。然而,对面上的多点试验资料在推荐施肥中应用的深入探讨和规律总结则是其弱点,这也是为什么众多“3414”试验资料至今未能被很好地归纳总结的一个关键技术原因。 同时,在推广应用上,这种源自欧美发达国家规模化农业生产条件下的测土推荐施肥技术,面对我国耕地高度分散经营的农业生产实际时,在取土、测土过程中经常会遇到目前还难以克服的难题[6]。主要体现在两个方面:1)由于耕地高度分散经营和复种指数高,农户间栽培管理水平存在差异,造成土壤肥力空间变异大,代表性土样采集难;2)为了获得较高精度的推荐施肥量,必须加大土样采样密度,结果造成测土费用高、耗费时间长和常误农时等问题。实际上,这种状况就如同在火车站需要高效快速进行旅客身份识别,通过对旅客采集生物样品进行DNA测序来鉴别身份的技术,虽然结果准确和无异议,但在这种场合并不实用,而人脸模式识别技术则满足了准确和快速通关的客观需要。 因此,在推荐施肥技术领域,仅仅停留在通过“测土”技术手段深入研究和掌握土壤肥力状况、作物需肥规律和推荐施肥三者间关系是不够的,我们还需要在此基础上,应用高度发达的信息技术和计算机技术对研究结果进行深度总结和挖掘,提出普通用户就能使用的高效、快速和准确的肥效参数识别和推荐施肥新技术,才能满足广大农户的实际应用需要。 3.2 统计模式识别技术的应用 统计模式识别理论和技术的发展和成熟,为我们解决“测土”难题提供了一个新思路。在构建了区域作物施肥类别后,对于该区域内某个田块或几个临近田块的推荐施肥应属于哪个施肥类别呢?这就涉及到施肥类别归属的判别问题。根据统计模式识别理论[16],解决的办法是,先对区域内各个施肥类别的相关观测指标进行统计分析,确定每个施肥类别的统计特征,再把未知施肥类别田块的相关指标与这些已知施肥类别的统计特征进行比较,把它们归类到统计特征最相近的一个已知施肥类别中去,进而提出施肥建议。因此,可以采用具体地块上一年度或前2~3年的相同作物氮、磷、钾施肥量与产量,结合地块肥力信息等数量指标,作为施肥类别归属判别和推荐施肥的依据。 这一技术路线的准确性如何是人们最为关心的问题。本文初步研究表明,这个问题应从应用层面和技术层面两个方面来考虑。在应用层面,如果用户在施肥识别系统使用过程中逐渐养成记录田间资料档案的习惯,由此得到的数据质量将明显提高。在技术层面,在确保两两类别间的关键指标均值具有显著差异的前提下,将闽东南地区的早稻划分为6个施肥类别,训练样本的回代误判率和交叉误判率平均只有1%左右,预留的84个处理的氮、磷、钾施肥量及其产量试验资料的施肥类别归属的判别正确率达到81.0%。但是,如果原始数据未经标准化处理就建立判别函函数,回代误判率和交叉误判率则分别高达34.5%和41.3%。结果表明,数据标准化处理是提高判别正确率的重要手段。 判别分析的另一种常用方法是距离判别法[18],利用该法和本文的80个试验资料作为训练样本来检验表1预留资料的判别准确性,结果判别正确率只有69.0%,显示不同方法的判别准确性有较大差别。因此,选择合适的判别方法是提高判别准确性的另外一个重要途径。由于统计模式识别的具体数学方法很多[16],在将来的工作中,我们应根据不同区域的田间肥效试验资料,深入探讨不同方法的专业适用性和可行性。此外,提高判别准确率的另一个关键技术是正确建立作物施肥类别。 3.3 区域作物施肥类别的构建 统计模式识别技术在推荐施肥中应用的前提是正确地建立区域作物施肥类别。聚类分析是定量分类的最常用方法,但聚类结果的谱系图只给出了各个试验点的亲疏关系,本身并没有给出具体分类。本研究表明,闽东南地区早稻氮磷钾施肥类别的有效分类数为6个。这种以施肥量和早稻产量为指标依据的施肥类别划分方法具有简单实用的优点。但是,要了解不同施肥类别的土壤养分状况,还需要结合土壤测定。 区域作物施肥类别应该划分多少类?以往大都根据专业知识结合个人经验划分为3~6个类别,然后按照不同类别所属试验点的田间试验资料进行归纳总结[4–5]。显然,这种方法带有明显的人为因素的影响。本研究表明,施肥类别数取决于:1)类别的代表性,即某个类别的试验数不能太少;2)类别间的关键指标均值差异达到统计显著水平;3)预留样本类别归属的判别正确率达到80%以上[18]。这样,我们就能将区域作物施肥类别划分建立在严格的定量分类基础上,使每个施肥类别都具有鲜明的统计学意义,这是提高施肥类别归属判别准确性的一个关键点。 本研究所涉及的闽东南地区,在农业生产条件和早稻栽培管理水平等方面差异不大,因而在建立早稻施肥类别时仅考虑氮磷钾施肥量及其产量作为指标依据,就能达到81.0%的判别准确率。可以设想,如果研究所涉及的地理区域较大,导致生产条件和生产水平有明显差异时,为使判别准确率达到满意水平,在确定施肥类别时,土壤肥力信息、生态环境条件等地点变量就将变得很重要而不可忽略。 [1]杨卓亚,毛达如,黄金龙,卢志光.基于年景变化的施肥决策[J].北京农业大学学报,1995,21(Suppl.):19–22. Yang ZY,Mao DR,Huang JL,Lu ZG.Fertilization strategy for different crop yield year type[J].Acta Agriculturae Universitatis Pekinensis,1995,21(Suppl.):19–22. [2]耿兴元,毛达如,曹一平.土壤肥力模糊量化评价(判)系统的建立[J].北京农业大学学报,1995,21(Suppl.):23–28. Geng XY,Mao DR,Cao YP.A fuzzy system for quantitative evaluation of soil fertility[J].Acta Agriculturae Universitatis Pekinensis,1995,21(Suppl.):23–28. [3]金耀青,张中原.配方施肥方法及其应用[M].沈阳:辽宁科学技术出版社,1993:35–158. Jin YQ,Zhang ZY.The method of formula fertilization and its application[M].Shenyang:Liaoning Science and Technology Press, 1993:35–158. [4]李娟,章明清,孔庆波,等.福建早稻测土配方施肥指标体系研究[J].植物营养与肥料学报,2010,16(4):938–946. Li J,Zhang MQ,Kong QB,et al.Soil testing and formula fertilization index for early rice in Fujian Province[J].Plant Nutrition and Fertilizer Science,2010,16(4):938–946. [5]杨俐苹,白由路,王贺,等.测土配方施肥指标体系建立中“3414”试验方案应用探讨—以内蒙古海拉尔地区油菜“3414”试验为例[J].植物营养与肥料学报,2011,17(4):1018–1023. Yang LP,Bai YL,Wan H,et al.Application of“3414”field trial design for establishing soil testing and fertilizer recommendation index[J].Plant Nutrition and Fertilizer Science,2011,17(4): 1018–1023. [6]侯彦林,郭喆,任军.不测土条件下半定量施肥原理和模型评述[J].生态学杂志,2002,21(4):31–35. Hou YL,Guo Z,Ren J.Summarization of principles and models for semi-quantitative fertilization without soil testing[J].Chinese Journal of Ecology,2002,21(4):31–35. [7]Kim JW,Ahn YJ,Lee KC,et al.A classification approach for genotyping viral sequences based on multidimensional scaling and linear discriminant analysis[J].BMC Bioinformatics,2010,11:434. [8]Zhao XJ,Pei ZY,Liu J,et al.Prediction of nucleosome DNA formation potential and nucleosome positioning using increment of diversity combined with quadratic discriminant analysis[J]. Chromosome Research,2010,18:777–785. [9]Li XL,Yi SL,He SL.Identification of pummelo cultivars by using Vis/NIR spectra and pattern recognition methods[J].Precision Agriculture,2016,17:365–374. [10]罗汝英.江西省低山区杉林土壤障碍性条件的判别分析[J].土壤学报,1980,17(2):145–155. Luo RY.Discriminant analysis of inhibiting soil conditions of Chinese fir stands in low mountain district of Jiangxi Province[J]. Acta Pedologica Sinica,1980,17(2):145–155. [11]熊国炎.两组线性判别分析在土壤分类中的应用[J].土壤,1980,(5):177–181. Xiong GL.Two groups of linear discriminant analysis applied for the soil classification[J].Soils,1980(5):177–181. [12]Brus DJ,Bogaert P,Heuvelink GB.Bayesian maximum entropy prediction of soil categories using atraditional soil map as soft information[J].European Journal of Soil Science,2008,59(2): 166–177. [13]邱琳,李安波,赵玉国.基于Fisher判别分析的数字土壤制图研究[J].土壤通报,2012,43(6):1281–1286. Qiu L,Li AB,Zhao YG.Digital soil mapping based on Fisher discriminant analysis[J].Chinese Journal of Soil Science,2012, 43(6):1281–1286. [14]吴海波,赵晓慎,王治国,张超.基于Bayes判别分析模型的水土保持区划[J].水土保持科学,2012,10(2):88–91. Wu HB,Zhao XZ,Wan ZG,Zhang C.Regional division for soil and water conservation based on Bayes discriminant analysis model[J].Science of Soil and Water Conservation,2012,10(2): 88–91. [15]鲁如坤.土壤农业化学分析方法[M].北京:中国农业科技出版社, 2000:146–196. Lu RK.Soil agricultural chemical analysis method[M].Beijing: China Agricultural Science and Technology Press,2000:146–196. [16]Andrew RW,Keith DC(王萍译).统计模式识别(第三版)[M].北京:电子工业出版社,2015:163–201. Andrew RW,Keith DC(Translated by Wang P).Statistical pattern recognition(3rd ed.)[M].Beijing:Electronic Industry Press,2015: 163–201. [17]李娟,章明清,孔庆波,等.构建县域早稻氮磷钾施肥的系统聚类方法研究[J].植物营养与肥料学报,2017,23(2):531–538. Li J,Zhang MQ,Kong QB,et al.Building fertilization categories of N,P and Kfertilization for early rice using systematic clustering method in county territory[J].Journal of Plant Nutrition and Fertilizer,2017,23(2):531–538. [18]袁志发,宋世德.多元统计分析(第二版)[M].北京:科学出版社, 2009:278–293. Yuan ZF,Song SD,Multivariate statistical analysis(2nd ed.)[M]. Beijing:Science Press,2009:278–293. [19]李柏年,吴礼斌.MATLAB数据分析方法[M].北京:机械工业出版社,2015:81–104. Li PN,Wu LB.MATLAB data analysis method[M].Beijing: Mechanical Industry Press,2015:81–104. [20]毛达如,张承东.多点肥料效应函数的动态聚类方法[J].北京农业大学学报,1991,17(2):49–54. Mao DR,Zhang CD.Dynamic clustering method of multipoint fertilizer response function[J].Acta Agriculturae Universitatis Pekinensis,1991,17(2):49–54. [21]章明清,林仁埙,林代炎,姜永.极值判别分析在三元肥效模型推荐施肥中的作用[J].福建农业学报,1995,10(2):54–59. Zhang MQ,Lin RX,Lin DY,Jiang Y.Function of distinguish analysis on extreme value in recommendatory fertilization for threefertilizer efficiency model[J].Fujian Journal of Agricultural Sciences, 1995,10(2):54–59. [22]周鸣铮.测土施肥的科学基础[J].土壤通报,1984,15(4):156–160. Zhou MZ.Scientific foundation of soil testing and recommendation fertilization[J].Chinese Journal of Soil Science,1984,15(4): 156–160. [23]周鸣铮.中国的测土施肥[J].土壤通报,1987,18(1):7–13. Zhou MZ.Soil testing and recommendation fertilization in China[J]. Chinese Journal of Soil Science,1987,18(1):7–13. [24]金耀青.配方施肥的方法及其功能—对我国配方施肥工作的述评[J].土壤通报,1989,20(1):46–49. Jin YQ.Formula fertilization methods and its functions-review of formula fertilization work in China[J].Chinese Journal of Soil Science,1989,20(1):46–49. [25]陆允甫,吕晓男.中国测土施肥工作的进展与展望[J].土壤学报, 1995,32(3):241–251. Lu YP,LüX N.Progress and prospect in fertilizer recommendation based on soil testing in China[J].Acta Pedologica Sinica,1995, 32(3):241–251. Bayesian discriminating analysis on category attribution of nitrogen, phosphorus and potassium fertilization for early rice ZHANG Ming-qing1,LI Juan1,XU Wen-jiang2,KONG Qing-bo1,YAO Bao-quan3 【Objectives】In soil testing and formulated fertilization,soil testing is the key to realize rational fertilization through practical guidance.However,collection of representative soil samples is often difficult because of highly decentralized farmland management,and soil sample analysis is cost and time-consuming. Therefore,statistical pattern recognition techniques were studied in this paper to explore category attribution of nitrogen(N),phosphorus(P)and potassium(K)fertilization without soil testing for early rice.【Methods】Data from eighty field experiments in southeast of Fujian Province,China,were used in this study.Based on the response of early rice to N,P and Kfertilizers,the paddy fields were divided into regional fertilization categories, using clustering analysis method of Euclideana distance-sum of squares of deviations.Then the NPK fertilization category for afield was calculated based on the statistical pattern recognition principle,the application rates of N, P and Kfertilizers and the outputs.【Results】On condition of ensuring that the average yield of the blank area and that of balanced fertilization had statistical significant differences between any two fertilization categories,the 80paddy fields were divided clearly into six fertilization categories.Multivariate statistics showed that the differences of covariance matrix of six categories were not all equal,and the Bayesian discrimination function of each category was established based on that.The standardization of the original data greatly improved the discrimination accuracy,with the back substitution misjudgment rate and cross misjudgment rate of trainingsamples of only1.2%and1.3%respectively,and the category discrimination accuracy of the84treatments in the 6reserved experimental sites reached81.0%.【Conclusions】Statistical pattern recognition principle and its Bayesian discriminate analysis method may provide an effective technical approach for the attribution decisions of N,P and Kfertilization category of early rice without soil testing,and its results could meet the accuracy requirements of fertilizer recommendation. early rice;nitrogen;phosphorus;potassium;fertilization category;Bayesian discrimination; category attribution 2016–08–29接受日期:2017–03–20 国家自然科学基金项目(31572203);福建省农业科学院PI项目(2016PI-31);农业部测土配方施肥(2011~2015)资助。 章明清(1963—),福建永春人,博士,研究员,主要从事作物施肥原理与技术研究。E-mail:Zhangmq2001@163.com

2 结果与分析


3 结论与讨论
(1 Soil and Fertilizer Institute, Fujian Academy of Agricultural Sciences, Fuzhou 350013, China; 2 Fujian Institute of Subtropical Plants, Xiamen 36000, China; 3 Fujian Cropland Construction and Soil and Fertilizer Station, Fuzhou 350003, China)
