超分辨率重建结合正则化最小二乘的人脸识别方法
2017-08-30张春燕张莹
张春燕, 张莹
(新疆警察学院 信息安全工程系,乌鲁木齐 830000)
超分辨率重建结合正则化最小二乘的人脸识别方法
张春燕, 张莹
(新疆警察学院 信息安全工程系,乌鲁木齐 830000)
针对三维人脸重建模型精度和优化方法准确性问题,提出了一种基于单一图像的无约束姿态不变人脸识别方法。使用一个二维的正面图像来重建三维人脸。创建人脸的三重协同字典矩阵,利用凸集投影进行超分辨率重建。通过具有正则化最小二乘的协同表示完成分类。在LFW数据库和视频人脸数据库上处理姿态变化取得了预期的结果,与多种方法比较表明,提出的方法具有更高的识别率。
人脸识别; 协同表示; 超分辨率重建; 正则化最小二乘法
0 引言
无约束的姿态不变人脸识别是计算机视觉中最困难和最具有挑战性的任务之一[1]。人脸姿态会有各种变化,在约束条件下经典人脸识别方法效率较好[2,3]。然而,在有光照和表情变化的现实世界情况下进行姿态不变人脸识别是非常困难的。
许多学者已经提出一些关于姿态不变人脸识别方法。文献[4]提出了一个基于三维模型生成的姿态矩阵的联合动态稀疏表示分类的人脸识别的现实世界框架。文献[5]通过双数复小波变换(DT-CWT)和采用支持向量机中的迭代得分分类提取了用于姿态不变人脸识别的特征库矩阵。文献[6]通过局部二值模式和稀疏表示分类提出了用于姿态不变人脸识别的稀疏字典矩阵框架。然而,大多数现有的方法识别时间无法达到实时性且识别率有进一步提升空间。
提出了一种基于现实世界的人脸图像快速建立三维人脸模型来识别人脸姿态的方法,生成了测试集图像的三个角度协同字典矩阵(triplet collaborative dictionary matrix, TCDM)。最后,通过具有用于分类的规范化最小二乘(regularized least square, RLS)[7]的协同表示分类(collaborative representation classification, CRC)进行人脸识别。在LFW人脸数据库上进行试验,在视频数据库上进行实时试验。然后,在精度和速度方面与其他文献提出的方法进行对比。结果表明,提出的方法不仅更加准确,而且更加快速。主要创新点如下:(1) 通过采用协同表示生成基于每个主体中人脸姿态的三个角度的TCDM。(2)在TCDM框架上通过联合CRC和RLS进行分类。(3)该方法提高了识别率。
1 提出的方法
1.1 人脸表示
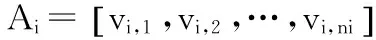
(1)
式中,αi,j∈R为标量,j=1,2,…,ni。因为测试样本的强度未知的,定义一个新的矩阵A,它是所有类的训练样本集合为式(2)。
(2)
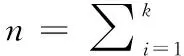
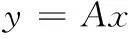
(3)
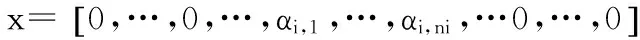
(4)
文献[8]提出了比稀疏表示更有效和更快速的协同表示,证明了CRC不仅比SRC更准确,而且也非常快速。在快速人脸识别方法中,通常情况下特征维度将不会太短会有一个很好的识别率[9]。可能不需要使用l1正则化来稀疏化x。因此,协同表示能够解决以下问题为式(5)。
(5)
其中,λ是正则化参数。正则化项的好处:(1)它使最小二乘解稳定,(2)它对解x引入了稀疏性的无限量,但这稀疏性是一个稍微弱于l1范数的大数。
式(5)中RLS的CR的解可以很容易地分析并推导出式(6)。
(6)
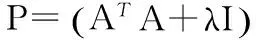
1.2 利用CR进行特征提取
通过协同表示(CR)进行特征提取[10,11]:
(1) 输入:来自主体i的输入图像。
(2) 对于主体i,通过FE-GEM(Facial Expression Generic Elastic Model)方法进行三维人脸重建。

(5) 输出:生成具有
使用的是一个测试集的单一图形和测试集的单一图像。因为对于生成字典A,协同表示需要学习多个样本,使用27个由子训练矩阵产生的TCDM的每个阵列的样本。因此,通过合成子训练矩阵的姿态图像选择CRC需要的多个样本,且不需要多个图像用于训练。因为CRC方法需要多个样本用于生成字典A,生成子训练矩阵用于特定的姿态和来使用来自这些矩阵的27个合成图像生成字典A以形成LFW数据库的一个测试集图像。因此,对于每个特定姿态生成的字典A保留在TCDM的每个姿态中,考虑到所有姿态重复这个过程最终生成TCDM。
1.3 超分辨率重建

1.4 识别
这一节介绍所提出的姿态不变人脸识别系统。需要每个对象两张图像,一个测试集图像和一个测试图像。所提出的系统运行在离线和在线两个阶段。在离线训练阶段,注册一个来自可用二维数据库中每个人的单一正面人脸图像。然后,对于每个注册的图像,通过GE-GEM进行三维人脸重建, 接着进行特征提取并为每个人创建TCDM。

算法1 CRC-RLS算法
2 实验
为了验证提出方法的性能,在LFW数据库和视频人脸数据库上分别进行实验。
2.1 LFW数据库上的人脸识别
LFW数据库是人脸识别中最具有挑战性的数据库之一,严格包括了现实世界场景中将表情、光照、姿态等等因素在内的人脸图像的所有变化。LFW包括不同性别、不同年龄等5 749种不同主体的13 233张人脸图像。LFW数据库准备了两个不相交的集合:分别用于测试集和用于测试。因此,为了评估所提出的方法在现实世界场景中姿态不变人脸识别的性能,利用LFW数据库除了姿态之外的无约束环境。
LFW数据库上该方法的识别率如表1所示。

表1 LFW数据库上不同方法的识别率和平均延迟时间
所提出的方法具有更好的性能。
2.2 视频数据库上的实验
为了评估所提出的方法,利用视频数据库的30个人的30个视频进行重复测试评估。在每个视频中,主体存在超过1 000帧,视频中头部姿态俯仰方向覆盖了±60度和偏向方向±75度。使用提出的方法进行人脸识别,并与不同方法进行对比评估性能。
由式(7)和式(9)得到TCFG和TSFG稀疏表示中最小表示误差值,并分别跟踪每帧所有渲染的姿态。30视频中所有帧(超过25K帧)上整体识别率结果和平均延迟时间,如表2所示。
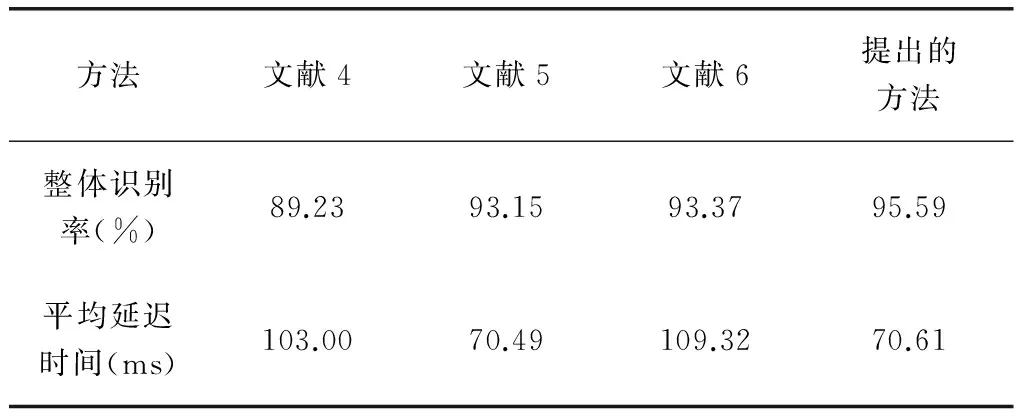
表2 视频数据库上整体识别率和平均延迟时间的对比
从表2可以看出,提出的方法的识别率和平均延迟时间优于比较的其他方法。正则化项的益处在于:(1)它是最小二乘解稳定;(2)它对解x引入了一个无限量。CRC中较弱的稀疏性不仅没有更糟糕的结果,而且可能稍微改善了结果。CRC中正则化项使得实验结果更稳定,它可以产生一个有限量的稀疏性来做出决定。因此,不仅有最稀疏性解,而且它通过计算表示误差具有有限和稳定的表示用于做出最终决定。提出的的方法正是由于加入了CRC,所以不仅降低了延迟时间而且还通过生成最稀疏的解做出决定而提高了识别率。
2.3 实验结果的讨论和分析
提出的方法执行速度较快,接近实时,且在处理现实世界场景中连续姿态和表情变化时是完全自动的。所提出的方法优于引言中描述的四类方法:(1)原因之一是CRC方法生成最稀疏和稳定解的精度。(2)主要原因是TCDM方法的人脸识别不像以前的方法,执行人脸识别系统的主要过程即特征提取,并在离线阶段保存在TCDM中,选择特征库并与在线过程中的测试特征进行对比。因此,所提出的方法对姿态不变人脸识别是有效的,而以往的方法试图合成测试集人脸图像,并用测试图像同时提取特征向量。因此,以往方法的缺点是速度问题,为了匹配一个人脸图像需要几分钟。这些方法的性能非常依赖于三维重建模型和优化方法的准确性。为此,提出一个姿态不变人脸识别系统,它不仅非常快,而且不依赖三维重建模型的精度。
3 总结
该文提出了一种用于测试单一图像的无约束姿态不变人脸识别的新方法。首先从正面人脸图像中重建一个三维模型。然后,基于所提出的框架创建TCDMs。最后,通过CRC-RLS方法进行人脸识别。在LFW和视频数据库上评估所提出的方法以实现姿态不变人脸识别,在处理现实世界场景的人脸姿态识别上取得了令人满意的结果。未来会将提出的人脸识别方法扩展到约束人脸识别。
[1] 初晓, 冷泽, 王艳玲,等. 基于多尺度MRF结合超级耦合变换的姿态变化人脸识别[J]. 计算机应用研究, 2016, 33(8): 2519-2523.
[2] 唐守军, 吴洪武. 基于Snake模型和协作表示分类的鲁棒人脸识别方法[J]. 湘潭大学学报(自然科学版), 2016, 38(2): 104-108.
[3] Moeini A, Faez K, Moeini H. Unconstrained pose-invariant face recognition by a triplet collaborative dictionary matrix [J]. Pattern Recognition Letters, 2015, 68(3): 83-89.
[4] 张佳宇, 彭力. 基于联合动态稀疏表示方法的多图像人脸识别算法[J]. 江南大学学报(自然科学版), 2014, 13(3): 287-291.
[5] 练秋生, 尚燕, 陈书贞,等. Texture classification algorithm based on DT-CWT and SVM [J]. 光电工程, 2016, 34(4):109-113.
[6] 唐恒亮, 孙艳丰, 朱杰,等. 融合LBP和局部稀疏表示的人脸表情识别[J]. 计算机工程与应用, 2014, 50(15): 34-37.
[7] 刘春茂, 郝倩, 张云岗. 基于PSO-LSSVM的网络流量预测[J]. 微型电脑应用, 2016, 32(5): 27-30.
[8] Jing X Y, Wu F, Zhu X, et al. Multi-spectral low-rank structured dictionary learning for face recognition [J]. Pattern Recognition, 2016, 59(4): 14-25.
[9] 孙新领, 谭志伟, 杨观赐. 字典学习优化结合HMAX模型的鲁棒人脸识别[J]. 现代电子技术, 2016, 39(15): 53-57.
[10] Cheng Y, Jin Z, Gao T, et al. An improved collaborative representation based classification with regularized least square (CRC-RLS) method for robust face recognition [J]. Neurocomputing, 2016, 34(2): 250-259.
[11] Lei Y, Guo Y, Hayat M, et al. A Two-Phase Weighted Collaborative Representation for 3D partial face recognition with single sample [J]. Pattern Recognition, 2016, 52(4): 218-237.
A Face Recognition Method Based on Super-resolution Reconstruction with Regularized Least Square Method
Zhang Chunyan, Zhang Ying
(Department of Information Security Engineering, Xinjiang Police College, Urumqi 830000, China)
In this paper, a novel method is proposed for unconstrained pose-invariant face recognition from only an image in a gallery. Firstly, a 3D face is initially reconstructed using only a 2D frontal image. Then, a triplet collaborative dictionary matrix is created, and projection onto convex sets is used to do super-resolution reconstruction. Finally, the classification is performed by collaborative representation classification with regularized least square method. Promising results are acquired to handle pose changes on the LFW and video face databases compared with state-of-the-art methods in pose-invariant face recognition.
Face recognition; Collaborative representation; Super-resolution reconstruction; Regularized least square method
2016年新疆维吾尔自治区高校科研计划项目青年教师科研培育基金(自然科学类)(No. XJEDU2016S090)
张春燕(1979-),女(汉),江苏丰县人,讲师,硕士,研究领域:图像处理等。 张莹(1988-),女(汉),山东梁山人,讲师,硕士,研究领域:图像处理、计算机应用等。
1007-757X(2017)08-0024-03
TP391
A
2017.03.08)
