基于元数据的分布式通用查询系统研究与实现
2017-08-30王战英王占宏
王战英, 王占宏
(上海众恒信息产业股份有限公司,上海 200042)
基于元数据的分布式通用查询系统研究与实现
王战英, 王占宏
(上海众恒信息产业股份有限公司,上海 200042)
信息查询是所有信息系统中的基础功能,不同的业务有不同的查询要求和结果展示要求。传统的解决方法是由程序员根据不同的业务要求定制开发不同的查询模块,造成了很多的重复工作,既降低了开发效率,又增加了开发成本。另一方面,传统的查询模块大多是和业务系统共用一个数据库,少部分有独立的查询、分析数据库,基本都是集中式的关系型数据库,随着业务数据的快速增长,系统的性能就往往有明显的下降,很难满足用户的实时性需求。针对这两方面的问题,在长期实践的基础上,提出了基于元数据的分布式通用查询系统研究,一方面使用模板引擎解析不同的元数据,自动适应不同的业务查询需求,提高查询的通用性;另一方面,基于分布式搜索引擎技术,利用全索引和并行计算提高系统的查询性能。通过多个系统的开发实践,该成果不仅能够满足不同行业、不同类型系统90%以上的查询需求,且响应时间基本都在毫秒级,取得了较好的应用效果。
通用查询; 元数据; 分布式搜索
0 引言
随着信息化的快速,各领域都逐步建设了符合自己业务需求的信息化系统,这些系统都自成体系。伴随信息化的深入发展,人们发现将一定范围中的相关数据整合到一起,统一组织、开发、利用,才能使这些信息资源发挥更大的价值,实施这项工作的早期技术就是人们比较熟悉的数据仓库技术,按应用主题把相关数据组织存储在统一的数据库中,既可以在各自的主题中快速查询分析,也可以在主题之间关联分析,消除了数据之间彼此隔离的障碍,使人们可以在更大范围中充分发掘这些数据中蕴含的信息,为日常的辅助决策提供有力的数据支撑[1]。数据集中存储、统一管理后,面对的最直接需求就是对这些数据进行检索、查询,以展示数据本来的面貌和数据之间的关联关系。通常系统中的检索、查询功能都是根据不同的业务需求,针对不同的数据表定制开发,面对大型数据仓库中的成千上万的数据表,这种开发方式的工作量相当大,且也缺乏适应性、灵活性。因此,研发一套与业务无关但又能体现不同业务特点的检索、查询系统成为应对这个问题的关键。另一方面,随着大数据时代的到来,数据呈爆炸式增长,人们很快发现,关系型、集中式数据仓库技术面对大规模、超大规模数据的检索请求,不仅响应速度慢,且经常因资源消耗大而造成宕机。因此,急需探索新的技术来应对大数据的挑战。所以分布式存储、分布式计算应运而生,分布式技术的核心思路是把超大规模的数据集分割成多个较小规模的数据集,这些较小规模的数据集分别存储在不同的机器中,计算请求也被分发到相关的机器上,大量机器并行地在自己管理的小规模数据中快速的完成计算,最后把各自的结果汇总到客户端形成最终结果[2]。针对以上两方面问题,本文讨论了采用分布式技术,以元数据为核心,通过灵活配置,以适应不同业务需求查询功能的设计思路与实现方法。
1 查询功能分析
1.1 查询功能的内容
查询功能是根据用户输入的查询条件,查询出满足条件的数据记录。此功能包含3个部分的内容,查询条件的输入与构造,查询结果列表的展示,单条记录详细信息的展示以及关联信息展示。
1.2 查询功能的分类
查询功能根据条件、操作灵活性、查询结果的处理方式以及查询数据的格式具有不同的分类方法。
(1) 根据查询条件的匹配精度分
根据查询条件的匹配精度,可以把查询功能分为精确查询和模糊查询。精确查询指的是用户输入的每个查询字符串与数据库中的相应字段值完全匹配才算命中;模糊查询指的是用户输入的查询字符串与数据库中的相应字段值部分匹配就算命中;模糊查询又可根据匹配范围分为单字段模糊查询和多字段模糊查询。单字段模糊查询是指,对单个表的单个字段进行前缀匹配、后缀匹配、包含匹配。多字段模糊查询是指,对单个表的多个字段或多个表的多个字段进行前缀匹配、后缀匹配、包含匹配及相识度匹配。
(2) 根据查询操作的灵活程度分
根据查询操作的灵活程度,可以把查询功能分为简单固定条件查询、复杂自定义条件查询和全文检索。简单固定条件查询,指的是针对单个业务表,给用户提供几个常用字段进行查询,每个字段的条件一般为相等关系,也可以通过在输入字符串中添加通配符实现模糊查询,多个字段间一般为逻辑并的关系;复杂自定义条件查询,指的是针对单个业务表,把表中可能需要查询的所有字段都提供给用户,由用户在其中自己选择用哪几个字段来组合查询条件,每个条件根据字段值的类型可以支持相等、不相等、大于、大于等于、小于、小于等于、包含、为空、不为空等比较运算,多个条件之间可以由用户选择逻辑并或者逻辑或关系,多个条件也可以通过添加括号来支持条件分组嵌套;全文检索,指的是只给用户提供一个条件输入框,用户可以在其中输入用空格分隔的多个字符串,查询是相对于整个库的所有表的所有字段进行模糊匹配,也可以让用户选择查询范围。
(3) 根据查询结果的处理方式分
根据查询结果的处理方式,可以把查询功能分为简单定位查询和多级关联查询。简单定位查询,是指根据查询条件得到单条或多条满足条件的结果记录,然后简单地查看每条记录本身的信息而不关注额外信息;多级关联查询,指的是除过查看满足条件的记录本身的信息外,也给用户提供这条记录其他的关联信息,使用户对结果了解地更清楚,并且用户也能够通过交互导航到其他相关信息。比如:对人口信息的查询,先查询到满足条件的一个或多个人的信息,然后选中一个人进一步查看此人的更详细的信息,在详细信息中除过展示人的基本信息外,同时展示这个人的家庭成员、工作履历等关联信息,用户也可以进一步查看此人的某个家庭成员而导航到另一个相关的目标,这种关联查询可以使用户对查询结果有更全面的理解。
(4) 根据查询数据的形式分
根据查询数据的形式,可以把查询功能分为结构化数据查询和非结构化数据查询。结构化数据查询,是指对关系型数据库中,或来自其他数据源中可以用二维表格表达的数据进行查询,这种查询一般都是字段级的精确查询;非结构化数查询,指的是对网页、文本文件、word、excel、ppt、pdf等文本型数据进行查询,这种查询一般都是文档级的全文检索。
1.3 通用查询功能分析
(1) 通用查询功能
通用查询是指能够满足上述所分析的各类查询功能要求。即能够对各个行业的相关数据,进行满足其业务特点的查询要求。
(2) 通用查询功能的特点
1) 与业务无关;各业务领域数据都能用此功能进行查询操作。
2) 能够体现不同业务的特点;根据不同业务的特点,支持不同的查询方式及展示方式。
3) 能够动态适应业务要求的变化;通过功能调整而非程序代码来快速响应用户需求的变化。
4) 能够高效地响应结果;查询一般都属于在线操作,响应时间应控制在毫秒级。
2 基于元数据的通用查询实现模型
元数据是“关于数据的数据”,它通过对信息资源的描述和限定,实现对资源的定位和管理,从而最终有助于实现对这种资源及相关数据的检索[3]。
通用查询功能既要与业务无关,又要体现不同业务的特点,从而动态适应其业务变化,必须对各种不同的物理数据表示给出相应抽象的逻辑表示,必须根据不同的描述信息对界面提供灵活的定制功能。要适应这些动态变化的要求,就要求程序逻辑不能固化,而要能够根据一些描述性信息作出不同的变化。所以,描述性信息是实现通用性的核心、基础,而描述性信息即元数据,描述数据的数据。通用查询功能中的元数据我们分为两类,描述数据结构的元数据和描述页面展示的元数据。
2.1 描述数据结构的元数据
此类元数据用来描述不同业务数据的物理结构、逻辑结构以及数据之间的关联关系。包括物理表、物理表字段、业务实体、业务实体属性、关联子实体、关联子实体属性六个方面的信息,他们之间的关系,如图1所示。
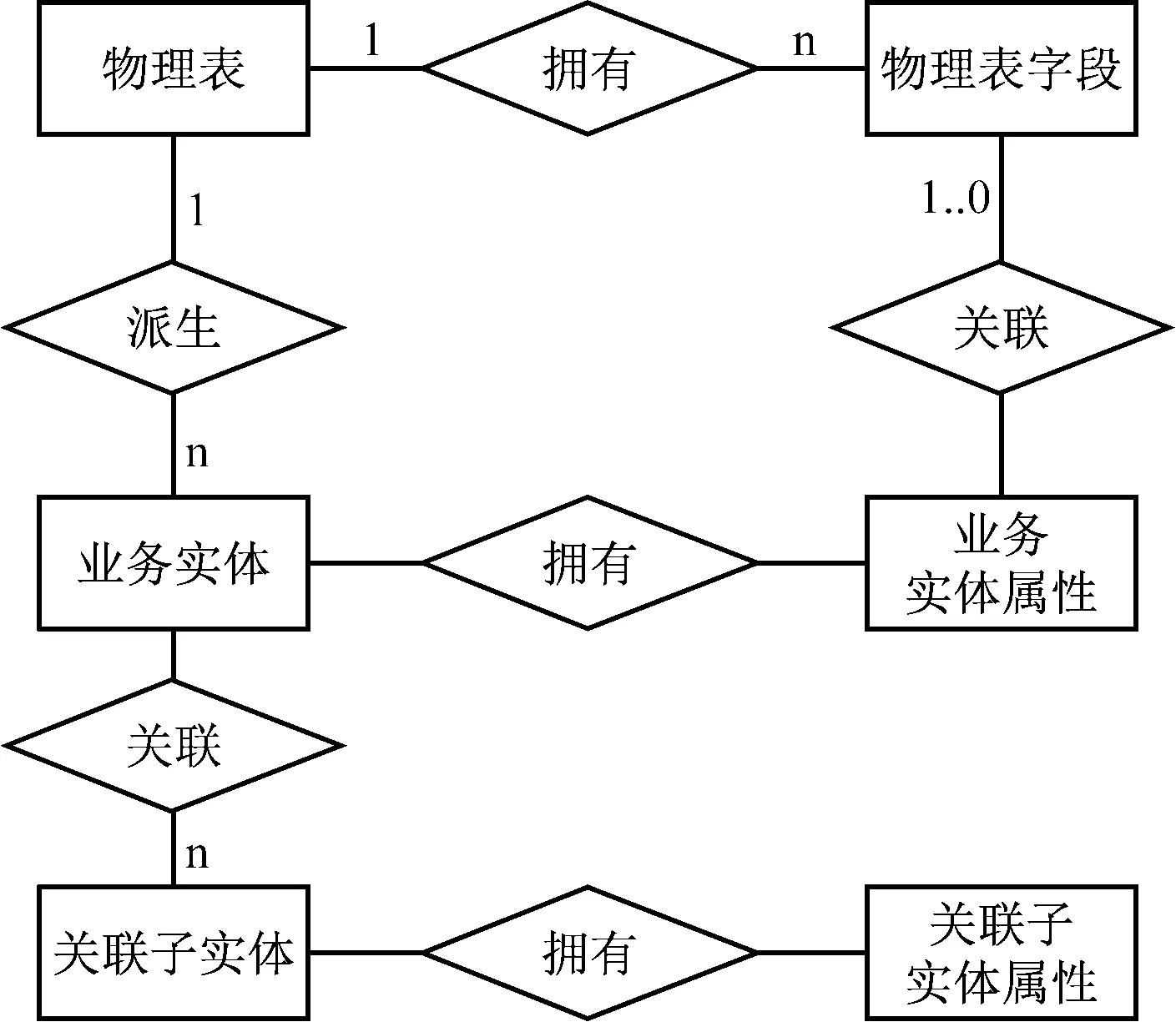
图1 通用查询元数据逻辑结构图
(1) 物理表
物理表描述系统中所有表,关键信息有表的存储名称、显示名称,还可以包含表的管理性信息,如表的类型(业务数据表、内部控制表等),表中数据的更新方式、更新周期等。
(2) 物理表字段
物理表字段描述构成物理表的字段信息,关键信息有字段的存储名称、字段的显示名称、字段的存储类型、字段长度、是否为主键、是否为外键、是否唯一、是否可为空等。
(3) 业务实体
业务实体是从业务的角度来描述系统中数据单元,大多数情况下一个物理表对应一个业务实体信息,也有物理表中的数据存储多个相似但不相同的业务逻辑的数据,比如,对一个城市的人口信息进行管理,所有的人信息都可以存储在一张物理表中,但从业务管理上,可以把人分成常住人口、外来人口和境外人口,三类人口信息的管理方式不一样,相关业务操作都有区别,如查询字段、展示字段都有差别。对业务实体和业务实体所拥有的属性描述是通用查询功能的核心内容。从数据结构方面看,业务实体包含的关键信息有业务标识名称、业务显示名称、业务所属类别。
(4) 业务实体属性
业务实体属性是描述一个业务具体信息项的元数据,是用户操作最多的数据项,也是业务差别最大的信息。因此,它是通用查询功能处理的重点。从数据结构方面看,业务实体属性包含的关键元数据有属性表示名称、属性显示名称、属性的类型、是否主键属性、是否外键等。通常,一个业务实体属性关联一个物理表字段,也有根据业务的需要,关联多个物理表字段,如地址信息,在物理表中可能会按城市、区县、街道、路名、号、室等多个字段存储,但查询展示的时候可能需要把这些字段合并成一个地址属性,这样的属性称为虚拟属性。
(5) 关联子实体
关联子实体是用来描述与一个实体有关联关系的实体元数据,用来描述两个业务实体之间的关系,关键信息有父实体ID、子实体ID、关联类型(一对一、一对多、多对多)、关联名称,如果关联类型为多对多,则还需要描述多对多关联实体ID、多对多目标实体属性、多对多关联实体属性。
(6) 关联子实体属性
关联子实体属性是用来描述两个实体之间关联条件的元数据,可以支持单条件关联和多条件关联,关键信息有子实体属性ID、父实体属性ID。
2.2 描述页面展示的元数据
查询功能是面向最终用户的,它的所有功能都是靠界面来体现,根据需求及使用场景不同,查询功能被分成很多种类,每一种都是通过不同的界面形式来表达。为了使实现的功能达到通用,就需要使用大量描述性元数据来定义页面的不同元素。界面反映的都是业务需求,所以页面展示的元数据都与描述数据结构元数据中的业务实体元数据和业务实体属性元数据对应,都是对这两个元数据的扩充。
(1) 查询功能页面结构分析
常用的查询功能由输入查询条件界面、展示结果列表界面和展示单条结果详细信息界面组成。
1) 输入查询条件界面
该界面需要考虑哪些业务属性用作查询条件;根据重要性及常用性,这些属性的排列顺序如何;根据界面大小,一行最多能够摆放几个查询属性;每一个查询属性的比较运算符是固定的还是可变化的;多个查询条件之间的逻辑关系是固定的还是可变化的;每个查询条件值的输入方式如何适应不同属性类型的变化。
2) 展示结果列表界面
该界面要考虑哪些业务属性需要展示在结果列表中;这些属性的排列顺序如何;根据属性值的可能长短如何控制不同属性在列表中的宽度大小;表头是否支持排序;每一行的哪个属性值支持超链接关联查询。
3) 展示单条结果详细信息界面
该界面要考虑哪些业务属性需要展示在详细信息界面中;这些属性的排列顺序如何;一般这个界面都是以表格方式进行排列,需要控制一行最多摆放几个属性,哪个属性需要进行跨多列、跨多行摆放;哪个属性需要支持超链接关联查询;哪些属性应该归为同一组,使展示更清楚;同时,此界面也会展示出当前业务的关联信息,要考虑如何摆放这些关联信息。
(2) 描述页面展示的元数据
综合考虑查询功能的不同页面要求,分别给业务实体和业务实体属性扩充相关元数据。
业务实体包括查询页面列数、详细页面列数、查询页面模板、列表页面模板、详细页面模板。
业务实体属性包括查询页面序号、列表页面序号、详细页面序号、输入类型(单行文本、多行文本、单选下拉列表、多选下拉列表、选项字典、日期、日期时间、树形单选、树形多选)、页面出现位置(查询条件页面、列表页面、详细页面、自定义查询页面)、查询页面跨列数、详细页面跨列数、详细页面跨行数、列表显示宽度、列表对齐方式(左对齐、右对齐、居中对齐)、默认查询符号(等于、大于、小于、大于等于、小于等于、不等于、为空、不为空、模糊、包含、不包含、前缀、后缀)、属性分组名称、日期时间格式、超链接地址。
2.3 元数据解析模型
使用元数据的目的是使查询功能能够随元数据的变化而变化,从而适应不同的业务需求,实现查询功能的通用性,不同的查询功能是通过不同的界面来体现的,界面是由元数据、业务数据、页面布局和控件联合生成,页面布局也称为页面模板。因此,本文利用模板引擎来解析元数据,动态生成不同的查询功能界面,如图2所示。

图2 通用查询元数据解析模型图
系统预先设计一组常用的、实现不同功能的页面模板,并实现元数据的配置功能。针对不同的业务数据及查询功能要求,通过选择适当的页面模板,配置不同的元数据,自动生成不同的查询页面,从而实现不同业务需求的通用查询功能。
3 分布式搜索引擎
3.1 集中式关系型数据库特点及局限性
传统查询功能都是基于集中式的关系型数据库实现的,特别是对于结构化、有关联关系的数据,关系型数据库提供了很好的存储支撑和标准的SQL查询语言,可以很方便、高效地实现特定的查询功能。对于特定条件的查询,关系型数据库可以通过对特定字段建立索引或对多个字段建立联合索引来满足高性能的查询需求。另外,对于一定规模的数据的查询,关系型数据库也可以通过对数据提供分区存储的技术,在一定程度上提高查询效率,满足应用要求。
但是,针对通用查询,关系型数据库遇到了难以克服的挑战。首先,通用查询会针对一个业务表的任何字段进行查询,而关系型数据库中当一张表中的数据达到千万记录时,如果对没有创建索引的字段执行查询时,响应时间是不可接受的。所以,为了面对任意字段查询,就需要对每个字段都创建索引。关系型数据库中的索引,分单列索引和多列复合索引,单列索引相对单条件查询,多列复合索引相对多条件查询,而且多列复合索引的顺序也是固定的(与业务相关)。通用查询既要查询单列又要查询多列,所以关系型数据库中的索引机制是受限制的,不能满足通用查询的业务无关性要求。其次,通用查询既要能够针对小规模数据量查询,也要能够满足一定的大规模数据量的查询性能要求,关系型数据库可以通过存储分区的技术有限地解决特定场景的大数据查询问题,它的分区是根据业务字段进行分区,如果查询条件相对一个分区,查询将是很高效的,但是有些查询也是要求跨分区,那么查询效率会受很大影响,也即这种分区技术是与业务相关的,满足不了通用查询的要求。受关系型数据库这两方面的限制,本文采用分布式搜索引擎作为通用查询
功能的技术支撑。
3.2 分布式搜索引擎的优势
分布式并行计算技术是当前解决大规模数据应用的最佳方案。分布式并行计算技术的核心思想是,把超大规模的数据集分片成多个较小规模的数据集,这些较小规模的数据集分别存储在不同的物理机器中,计算请求被分发到相关的机器上,大量机器并行地在自己管理的小规模数据中快速的完成计算,最后把各自的结果汇总而形成最终结果。这里的数据分片对应关系型数据库中的数据分区,但分布式计算中的数据分片是不与业务相关的,而是由分布式框架自动来管理,也自动实现跨分片计算,所以,不受业务限制,可以满足通用查询功能对业务无关性的要求。
其次,分布式技术通过为数据自动管理副本来提高数据的安全性和负载均衡,这可以解决通用查询功能的可用性和高效性。最后,分布式技术也能够自动对分布式集群中的计算节点进行管理,当数据规模不大,用户并发不高的情况下,可以使用较小的集群来满足查询要求,随着数据量的增大及并发量的提高,可以动态增加机器来提高计算能力来满足查询要求,这种能力可以满足通用查询对不同数据量、不同使用场景的应用要求。
全文搜索引擎[4]是通过专门的索引结构来实现高效率的文本查询功能的技术。搜索引擎由索引引擎和查询引擎组成,索引引擎对需要查询的文本内容进行适当的分词切割,使长文本变成多个可能被用户用来检索的词语,把这些词语按一定的索引结构存储起来,以便高效检索查询。查询引擎对用户输入的查询关键字也是先进行分词,然后用这些短的词语通过高效的匹配算法在索引中查找,最终定位到索引所指向的原始数据,从而返回最终结果给用户。因此全文搜索引擎是通过对所有数据建立索引来提高查询效率,这一特点正好与通用查询功能中可能对所有字段进行查询的要求匹配,是用来提高通用查询效率的最佳技术路线。
3.3 ElasticSearch搜索引擎
弹性搜索(ElasticSearch,简称ES),是一个基于Lucene构建的分布式搜索引擎,能够实现实时、稳定、可靠的搜索功能[5]。(1)它是基于分布式架构的,包含分布式架构中的关键概念,集群、分片、副本、数据重新分配。(2)它是基于高效、通用的全文搜索库Lucene构建的,Lucene是当前最受欢迎的开源Java信息检索程序库,提供灵活、高效的搜索能力。(3)它的内部是以Json格式来组织数据,因此可以存储各种结构的文本数据,并且数据结构可以动态变化,这一点可以很好地满足通用查询业务无关性的要求。(4)它提供了简单、一致的restfull Api接口,既可以用来创建索引,也可以用来检索查询,可以很好地兼容各种语言的开发需要。它既支持全文本检索,也支持按字段精确或模糊查询,也就是说它既支持非结构化文本内容的检索,也支持结构化内容的查询。所以,此工具是理想的实现通用查询功能的技术支撑。
4 设计实现
基于上述分析的各项理论及技术,本人主导,基于JAVA语言、JAVAEE架构、SPRING框架实现了一套完整的通用查询功能,整体架构,如图3所示。
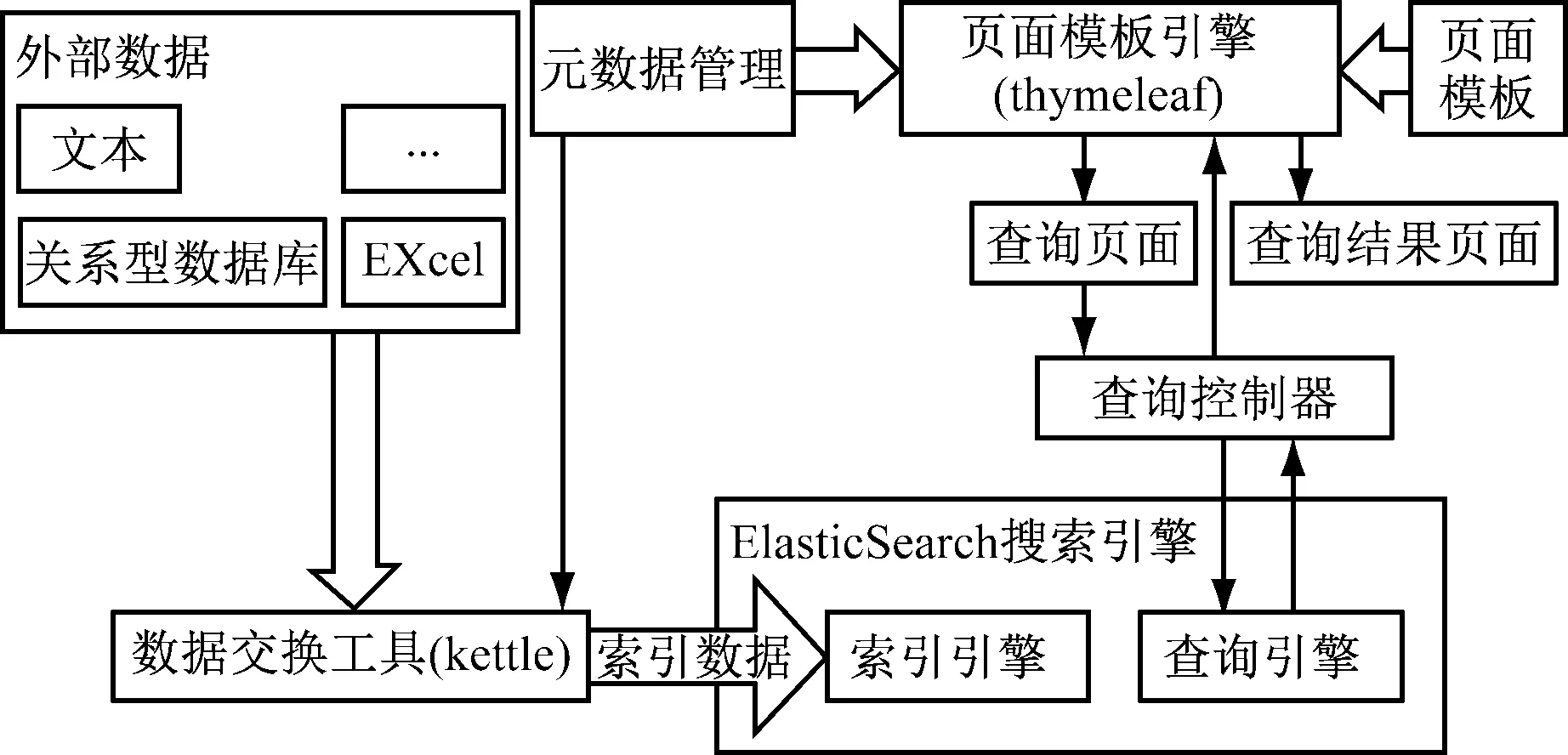
图3 通用查询参考实现架构图
外部不同形式的数据通过ETL工具,根据元数据中的标识信息,形成需要搜索的数据输入索引引擎,进而建立索引存储在索引库中。用户请求特定业务的查询功能,模板引擎解析相应业务的查询页面模板生成查询页面,用户在查询页面中输入查询条件后执行查询,由查询控制器构造查询语句提交到查询引擎,返回命中的结果给查询控制器,查询控制器再根据查询业务所配置的结果页面模板由页面模板引擎结合元数据生成查询结果页面展示给用户。
4.1 简单固定条件查询页面
如图4所示。
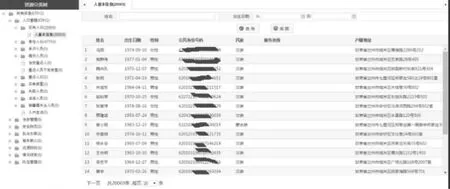
图4 简单固定条件查询页面参考图
每个业务实体都会归属到一个特定的资源目录条目中,左边为所有需要查询的业务的目录分类树,用户选择一个业务,右边展示出查询条件的页面和查询结果的页面,这两部分都是根据配置的元数据自动生成。
4.2 复杂自定义条件查询页面
如图5所示。
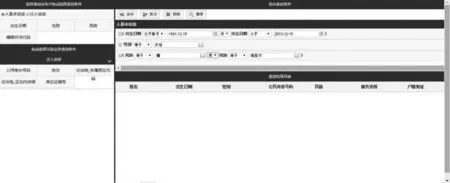
图5 复杂自定义条件查询页面参考图
左边摆放的是一个业务的所有可能需要查询的字段,可以通过拖动的方式把想要用来构造查询条件的字段放到右边的上半部分,对每个条件可以选择不同的比较运算符,多个条件可以通过添加括号合并,可以选择合并的逻辑符号,构造好查询条件后执行查询,在右边的下半部分展示匹配到的查询结果。
4.3 全文检索页面
如图6所示。
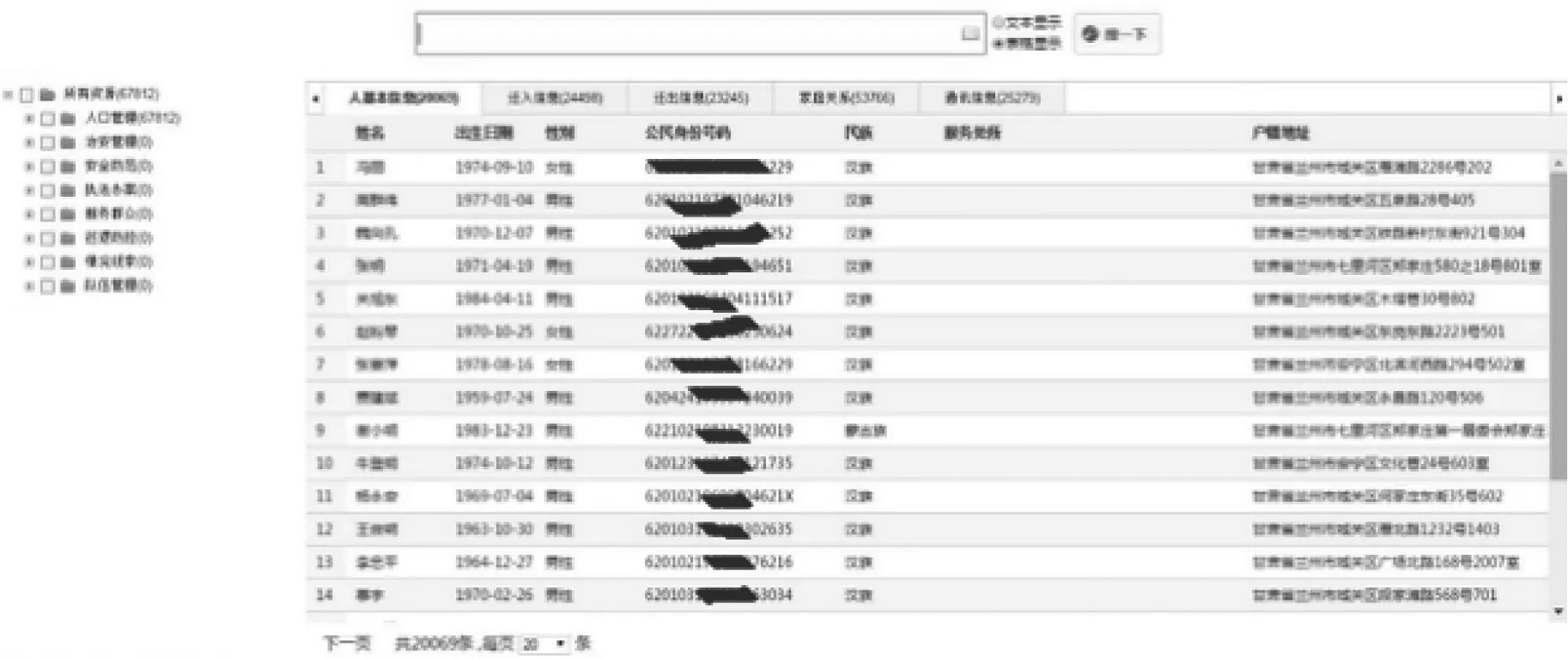
图6 全文检索页面参考图
页面上面为一个查询框,在其中输入检索关键词,多个关键词用空格分隔,执行检索,页面下面的左边展示的是所有匹配到的记录在相应资源分类中的记录数,通过选择相应的业务资源,在右边展示每个业务匹配到的具体记录信息。
4.4 元数据配置页面
如图7所示。
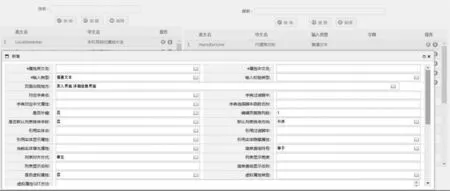
图7 元数据配置页面参考图
主要的元数据配置是业务实体元数据和业务实体属性元数据,左边维护业务实体列表,右边是每个业务实体的属性列表,业务实体属性的描述元数据是配置的主要内容。
5 总结
本文对查询功能做了详细而全面的研究分析后,提出基于元数据的分布式通用查询解决方案,既解决了查询功能的多样性、复杂性问题,也满足了大规模数据下的查询性能问题。
基于此方案开发了一套完整的通用查询系统,并在多个行业的不同项目中得到了成功的应用,极大地节约了项目的开发、维护成本,系统的功能、性能也得到了使用者的一致好评。
[1] 王志海. 数据仓库[M]. 北京:机械工业出版社, 2003.
[2] 刘丽,米振强,熊曾刚. 深入理解云计算:基本原理和应用程序编程技术[M]. 北京:机械工业出版社, 2015.
[3] 尹文燕. 元数据发展现状及存在问题研究[D]. 北京:中国科学技术信息研究所, 2003. 1.
[4] 李永春,丁华福. Lucene的全文检索的研究与应用[J]. 计算机技术与发展, 2010, 20(2): 12-15.
[5] 王占宏, 王战英, 顾国强, 等. 分布式弹性搜索研究与实践[J]. 微型电脑应用, 2014, 30(7): 9-12.
Research and Implementation of Distributed General Query System Based on Metadata
Wang Zhanying,Wang Zhanhong
(Shanghai Triman Information & Technology Co.,Ltd., Shanghai 200042)
Information query is a basic function of information systems. Different businesses have different requests of query and result presenting. A typical approach is to require that the programmer custom-develop query modules based on different business requirements. It causes a lot of duplicating efforts, reduces development efficiency and increases development cost. On the other hand, a typical query module and business systems share a same database. Few of them has independent query and analysis database, which basically is centralized relational database. With the rapid growth of business data, system performance decreases significantly, it is hardly to meet real-time requirement of users. In response to these two issues, after a long-term practice, this paper proposes a distributed general- query-system research, which is based on metadata. On one hand, different metadata are analyzed by using template engine. The system can automatically adapt to different business query needs, and improves the versatility. On the other hand, based on distributed search engine technique, it utilizes full index and parallel computing to improve query performance. Through multiple systems development practice, this achievement can meet more than 90% query needs of different industries and different types of systems, the response time is basically in the millisecond level, and it achieves good application effect.
General-query; Metadata; Distributed-search
王战英(1978-),工程师,学士,研究方向:电子政务规划。 王占宏(1975-),教授级高工,博士,研究方向:电子政务规划,数据仓库与数据挖掘。
1007-757X(2017)08-0046-05
TP311
A
2017.03.10)
