C4.5改进算法在研究生调剂中的应用
2017-08-29王浩
王浩
(阜新高等专科学校,辽宁阜新123000)
C4.5改进算法在研究生调剂中的应用
王浩
(阜新高等专科学校,辽宁阜新123000)
随着就业门槛的提高,越来越多的本科毕业生选择了考研,而且大部考生需要调剂才能读研。但由于招生的复杂性、多样性,考生很难从往年大量的调剂数据中分析出规律,选报合适的学校。在选报学校过程中,调剂的成功与否也是决定考生们能否顺利成读研的关键一步。该文针对此问题,将数据挖掘技术C4.5算法运用到调剂工作中,通过对学校的分类,有助于广大考生作出正确的选择,填报适合自己的学校。该方法实现过程简单,分类准确,可推广性强。
数据挖掘;考研调剂;c4.5算法;分类
近几年,我国就业压力增大,研究生报考人数增多,招生工作变的极为复杂。目前,我国研究生一直沿用考前填报志愿,很多考生在考试失误或其他原因而没被录取到所报考学校的但过了国家线想继续深造的都需要调剂[5]。而调剂可选择的高校很多,大部分同学对其中一些高校不甚了解而盲目填报,导致有些高校门庭若市,而部分高校却无人问津。本文通过研究运用数据挖掘算法,即c4.5算法,有针对性解决调剂问题。通过研究c4.5算法,发现运算过程中对数比较多,利用迈克劳林公式把对数函数转换为加减乘除运算,有效提高了运算效率。具体做法是根据学校其属性分类,采用基于决策树表现形式对学校数据记录挖掘出分类规则,并依据决策树的内部节点及每个分支代表属性取值的判断条件。
1 数据挖掘技术c4.5算法
Quinlan于1968年提出的ID3算法开创了决策树算法的先河。ID3算法不足是过于偏向于取值较多的属性,且这些属性又是无价值的,所以导致众多研究者开始研究其改进算法,在这些改进算法中,以C4.5算法最为著名。C4.5算法最主要的改进是用信息增益率来替换ID3算法中的信息熵,用信息增益率作为选择分支属性的标准,这种方法解决了ID3算法的缺点,提高了效率。
1.1 C4.5算法分析
C4.5算法用信息增益率代替信息增益来选择节点属性,其决策树节点属性的选择是使用信息论中熵的概念来完成的[2]。
C4.5的主要算法思想如下:
(1)数据预处理:如果某属性在数据集中为连续型属性,则必须进行离散化计算处理,才能计算全部属性的信息增益率,根据信息增益率最大原则,找出根节点。
①设数据分区D为标记类元组的训练集。假定类标号属性具有m个不同值,定义了m个不同的类Ci(i=1,···,m)。设Ci,D是D中Ci类元组的集合,|D|和|Ci,D|分别是D和Ci,D中元组的个数。对D中的元组分类所需要的期望信息由下式给出:

其中,pi是D中任意元组属于类Ci的非零概率,并用|Ci,D|/ |D|估计。Info(D)是识别D中元组的类标号所需要的平均信息量。又称为D的熵[1]。
②若根据非类别属性A划分D中的元组,将D分成集合D1,D2,···Dn,则确定D中一个元素类的信息量可通过Di的加权平均值来得到,即Info(Di)的加权平均值为:

InfoA(D)是基于按A划分对D的元组分类所需要的期望信息。需要的期望信息越小,分区的纯度越高。
③信息增益定义为原来的信息需求(仅基于类比例)与新的信息需求(对A划分后)之间的差。即

④增益率用“分裂信息(split information)”值将信息增益规范化。分裂信息类似于Info(D),其定义如下:

该值代表由训练数据集D划分成对应于属性A测试的v个输出的v个分区产生的信息。
⑤增益率定义为:

(2)选择具有最大增益率的属性作为分裂属性,即为当前节点的确定标准,对分支节点不断进行划分,直到所有的分支节点中的子集中的数据的类别相同,即叶节点中所有数据都属于统一类别。由此构造完成了一颗决策树。
(3)根据搭建的决策树获取决策规则。依据属性的取值大小来判定数据,进行分类的规则,使用决策规则可以对新的数据集中的数据进行分类预测[1]。
1.2 C4.5算法改进
1.2.1 公式的改进
虽然C4.5算法利用信息增益率度量很好地解决了偏袒具有较多值的属性,但由于步骤也随之增多,则可以从C4.5算法分析中看到其信息增益率的计算过程中对数函数的运算也随之增多,并且由于决策树的生成过程是一个递归循环的计算过程,经过了多次的重复计算导致产生很高的计算代价。如果能减少决策树的计算成本就可以节省决策树的生成时间[11]。因此,本文利用泰勒公式与麦克劳林公式,较大程度减少了计算量。
公式简化如下:
设根据非类别属性A划分D中的元组,将D分成集合D1,D2,···Dn,且Dij(j=1,2...,v)是子集Di(i=1,2...,n)中类Ci的样本数。则对于给定的子集Di,其信息量为:

则由A划分后的信息熵为:

设:

将对数换底可简化得到:


根据高等数学中的泰勒公式、迈克劳林公式的思想对信息熵进行简化依据等价无穷小原理,如果x很小,则可得:

因此:

同理:


1.2.2 改进前后的C4.5算法对比
从以上推导可看出,改进的C4.5算法计算公式中已经没有了对数运算,而是简单的四则混合运算,在计算机上实现速度很快,提高了运算效率[11]。
2 关于研究生调剂的C4.5算法
在每年研究招考阶段,高大高校基本都有需要研究生调剂的工作,但影响学校的因素多种多样,结构复杂,调剂工作也变得相对复杂、工作繁重。因此,必须要考虑学校的多种影响因素做好准备,考虑的调剂的因素主要有:院校社会影响程度,如985院校或211院校、重点院校还是普通院校、是否在发达地区或偏僻地区等。
本文将以计算机技术专业为例,把录取学校按学校类型、地理位置、师资、是否为重点专业等属性进行分类。如下表所示,采用部分学校样本进行分类,构建部分属性组成如下的基础表结构。

表1 学校综合属性
上表1共有20条记录,等级分别分为:一、二、三、四,且分别计数,则样本记为:D1=4;D2=4;D3=4;D4=8。
分别以学校类型、地域位置、师资情况以及是否为重点专业等为因素,计算信息增益情况:
(1)其中学校类型(A)为985且211的4个,211的4个,其他为否的12个。为一类院校的有4个,二、三、四类的都为0个。根据改进公式,可以计算相应的熵为:
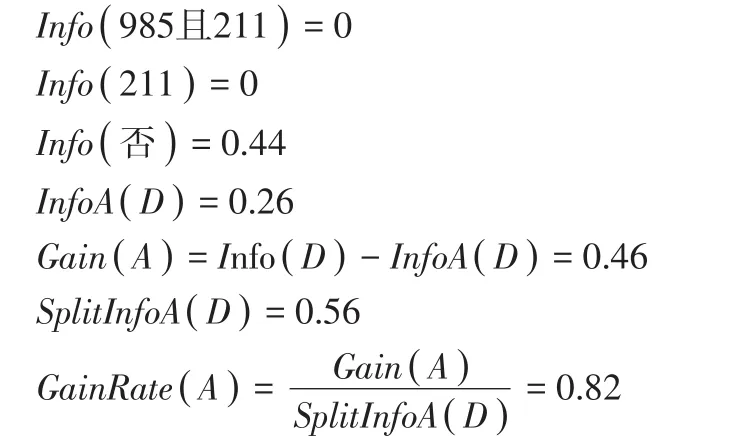
(2)以地理位置(B)为属性,9个为中部的学校,1个为西部学校,10个为东部的学校;信息熵额计算如下:

(3)以师资(C)为属性,其中有8个学校师资为“强”的,有8个学校师资为“中”的,有4个学校师资为“一般”的。
信息熵的计算如下:

(4)以计算机技术是否为其重点专业(E)为属性,其中有10个是其重点专业的学校,有10个不是重点专业的学校。
信息熵的计算如下:
根据以上的计算结果可发现,依据增益率的大小,首选学校的类型作为挖掘根节点,根据其属性取值的不同,我们可以引出3条分支,并依次取是否重点专业,师资,地理位置作为分支节点,构造出决策树。在此挖掘过程中应注意不要使决策树过于复杂,否则将难以理解,对应的规则也大量增加而造成冗余,所有规则必须通过适当的方式进行有效剪枝。如下图所示改进算法决策树:

图1 改进算法构造决策树
3 实验数据分析
3.1 实验数据
根据学校综合实力情况和以上对学校的归类可将学校分为四类,第一类即一些985且211的院校,如(清华大学、北京航空航天大学、复旦大学、东南大学等)。第二类即为一些不是985但是211的院校,如(辽宁大学、大连理工大学、南京理工大学、北京化工大学等)。第三类即那些既不是985也不是211的重点院校,如(辽宁工程技术大学、长沙理工大学、黑龙江大学、南京邮电大学等)。第四类即一般重点院校,如(中北大学、河南理工大学、河南师范大学、河北师范大学等)。表2是这四类学校调剂学生情况及实际调剂学生数占总学生数的比例。

表2 调剂学校及调剂学生比例情况
3.2 结果分析
通过C4.5改进算法对大量已知数据进行分类,将学校分为四个类别,然后分别对这四个类别往年的一些数据进行分析,即可对那些需要调剂的学生在面对大量学校而不知如何填写提供帮助,这样既有利于学校的招生也有利于学生的继续深造。
4 总结
C4.5算法是决策树分类算法中一种常用的数据挖掘方法,目前应用也较为广泛。本文主要采用其改进算法,完全不用对数运算,提高了运算效率。研究生招生调剂利用C4.5算法对系统学校的分类分析并构造出决策树,可以为大量需要调剂的同学指明方向,不盲目填写,具体情况具体分析,对学校对自己都能起到很大作用。目前,利用数据挖掘在这方面的研究还并不是很多,本文提出的对学校进行分类也只是调剂系统的一部分,要想完善此调剂系统,还得进一步对学生进行分析,每个学生的条件都不一样,所有这些都还需进一步的研究。
[1]魏现波,谢文阁,王长斌.改进的C4.5算法在绩效管理中的应用[J].计算机系统应用,2011,20(7).
[2]傅亚莉.数据挖掘技术C4.5算法在成绩分析中的应用[J].重庆理工大学学报:自然科学版,2013,27(11).
[3]陶双红,常炳国.一种改进的C4.5算法及在贫困生认定中的应用[J].计算机光盘软件与应用,2013(2).
[4]李孝伟,陈福才,李邵梅.基于分类规则的C4.5决策树改进算法[J].计算机工程与设计,2013,34(12).
[5]黄树成,曲亚辉.半监督学习在研究生调剂中的应用[J].计算机系统应用,2011,20(4).
[6]曲亚辉.数据挖掘在研究生调剂中的应用研究[D].江苏科技大学硕士学位论文,2011(4).
TP3
A
1009-3044(2017)21-0215-03
2017-06-15
王浩(1976—),男,河北迁安人,讲师,工程硕士,研究方向为计算机技术。
