基于Weka的应用型本科数据挖掘课程实验设计
2017-08-29黄岚周娟
黄岚,周娟
(长江大学计算机科学学院,湖北荆州434023)
基于Weka的应用型本科数据挖掘课程实验设计
黄岚,周娟
(长江大学计算机科学学院,湖北荆州434023)
培养实践应用能力是数据挖掘课程教学的重要目标。针对此目标,该文以开源数据挖掘软件Weka为实践平台,重点探讨了面向应用型本科开设数据挖掘课程中的上机实验设计。通过四次上机实验,掌握分类、回归、聚类和关联规则挖掘四类经典数据挖掘任务的一般过程,理解不同任务中学习生成模型的评测方法和性能指标,了解数据挖掘过程中的常见陷阱。通过紧密结合课堂理论教学和上机实验教学,完成教学闭环。
数据挖掘;教学探索;实践教学
数据挖掘是从海量数据中发现隐藏的、前所未知的、有价值的规律的过程。随着大数据和人工智能技术的快速发展和广泛应用,数据挖掘课程已成为计算机科学与技术等信息技术类人才培养方案中的重要组成部分。数据挖掘是一门实践性非常强的学科,因此培养实践能力是数据挖掘教学的重要目标,而上机实验是培养实践技能的重要教学环节。因此本文在前期对数据挖掘实践资源建设研究的基础上[1],重点探讨针对应用型本科数据挖掘类课程的上机实验设计。
1 Weka简介
目前,被用于数据挖掘类课程实践教学的软件工具有R[2]、SPSS[3]、Matlab[4]等。本文选择使用Weka开源软件[5]。Weka ['wekɑ](Waikato Environment for Knowledge Analysis)是由新西兰怀卡托大学计算机系机器学习小组开发的数据挖掘平台。2005年,由于Weka的广泛应用,该机器学习小组被ACM SIG⁃KDD授予知识挖掘与知识发现服务奖,得到了广泛认可。Weka用Java语言开发,源代码公开(GPL许可),实现了许多有代表性的数据挖掘算法。提供了适用于不同场景的多种界面:面向初学者和简单数据挖掘任务的Explorer界面、面向数据挖掘流程构建和商业智能的KnowledgeFlow界面、面向算法研究的Experimenter界面、面向命令式调用的CLI界面。除传统的离线集中式数据处理方式之外,还支持数据流挖掘和分布式大数据挖掘。Weka 3.7.2版本引入了包管理模式,将学习算法封装成独立的资源包,安装新的学习算法只需通过包管理器下载相应的资源包即可,无需更新Weka主程序。
Weka支持两种输入数据格式:Weka自定义的文本型数据格式ARFF格式和经典的CSV格式。Weka安装包中自带了16个ARFF格式的标准数据集,可以直接加载到Weka平台中。表1对数据集进行了梳理,分析了数据集的常见适用任务,这些数据集也是本文设计上机实验的主要资源。
2 基于Weka的数据挖掘实验设计
在应用型计算机专业本科课程教学中,数据挖掘课程实验应紧密结合基础知识进行设计,以增强对数据挖掘核心概念、基本方法、基础流程的理解和掌握。紧扣基础算法和典型应用,我们设计了以下四次课内上机实验。

表1 Weka 3.8自带数据集及其适用的数据挖掘任务

2 86 2 4 2 09 1 0 4 6(7)标称标称数值8 9 1 00 0 7 68 2 14 3 77 2 3 51 1 50 5 7 3 0 3 4 2(4) 1 6 2 0标称字符串、标称标称标称标称标称标称标称标称标称标称数值数值、标称数值数值数值、标称数值数值数值、标称1 9 1 6 04, 1554, 604, 1554 breast-cancer contact-lenses cpu(cpu.with. vendor) credit-g diabetes glass hypothyroid ionosphere iris(iris.2D) labor Reuters(ReutersCorntest,ReutersCorn-train, ReutersGraintest,Reuters-Grain-train) segment(segment-chal -lenge, segment-test) soybean supermarket unbalanced vote weather (weather.nominal,weather. numeric) 1 50 0,810 2 3 1 2 2 7 4 2 3 2 2 7标称5 6 83 4 62 7 8 56 4 35 3 5 2 17 3 2 1 6 1 9标称标称标称标称标称标称数值标称标称(标称、数值) 1 4 2 2 2 2标称√√ √√√√√√√ √ √ √√√√ √√√√√√√√√√√√ √ √ √√√√ √√√数值√√√ √
(1)Weka平台使用与线性模型构建
预测数值型数据是经典的数据挖掘应用,因此将线性回归模型作为第一次上机实验的内容。主要操作包括装载数据集并审查数据,构建线性模型,解读线性模型的评测指标,将预测错误可视化,并应用模型对新实例做出预测。
在Weka 3.8版本自带的数据集中,CPU数据集的类别属性为数值型,可用于构建回归模型。该数据集的另一个版本(cpu. with.vendor.arff)中附带供货商信息,并以标称型属性存储。打开该版本的CPU数据集,观察数值型属性和标称型属性的不同描述方式。数值型属性的描述指标为最小值、最大值、均值和标准方差。标称型属性则会显示其可能取值,以及每种取值在数据集中的出现频次。

图1 线性回归模型及其测评结果
在分类面板中选择线性回归,构建线性回归模型,如图1所示。数值预测模型的主要评测指标包括相关系数(correla⁃tion coefficient)、平均绝对误差(mean absolute error)、均方误差(root mean squared error)、相对绝对误差(relative absolute error)、相对平方误差(root relative squared error)。结合CPU数据集上的测评值,讲解各个测评指标。Weka提供了分类错误可视化的分析功能。在该数据集上可以得到如图2所示的可视化效果,其中预测值与实际值偏差越大,在可视化中越明显。右键单击单个数据点,将显示该数据点的详细信息,包括实际类别值和预测值,如图2所示。

图2 预测偏差可视化
(2)分类器构建与评测
本次实验的主要内容包括采用10折交叉验证的测评方式,构建并评测决策树分类器,分析各项性能指标,将决策树模型可视化,并应用模型对新实例做出预测。然后利用同一数据集分别构建k近邻分类器和朴素贝叶斯分类器,在同一数据集上比较多个分类器的分类性能。通过本次实验,重点落实以下几个知识点。第一,各种分类器的重要参数及其对模型的影响;第二,各种测评方式及其适用范围;第三,各种分类性能指标的解读。
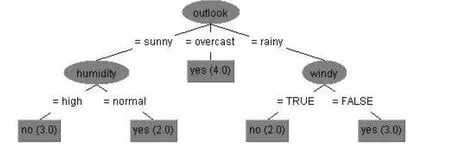
图3 在天气数据集上生成的决策树
过拟合是数据挖掘中的一个重要概念。过拟合的模型在训练数据上准确度非常高,但并不能有效预测未见新数据,因此实践中要避免过拟合。本次实验通过比较各种测评方式,加深学生对过拟合问题的理解。Weka提供了四种模型测评方式:基于全部训练数据、提供测试数据集、十折交叉验证和百分比分割。每种方式的适用场景不同,其中特别需要注意的有两点,第一,基于全部训练数据的方式仅适用于生成待部署的模型,即在各类参数确定后生成完整的待部署应用的模型,而并不适用于评估模型;第二,十折交叉验证应为缺省的评估方法。为了加深理解,实验中要求构建k近邻分类器,并将缺省的交叉验证方法改为基于训练数据的方式,此时将得到100%的准确率,但是该准确率并不意味着模型在未见新数据上的准确率也是100%。将模型保存,再加载新的数据集,应用所保存的数据集,得到的准确率却并不高。
在各种测评指标中,重点掌握混淆矩阵的解读方法。混淆矩阵是计算准确率、召回率等指标的基础,且提供了更多的细节,比如彼此间比较容易混淆的类别是哪些。针对此,实验中要求学生首先回答理想状态下的混淆矩阵,再和实验所得的混淆矩阵进行对比,并通过比较分析模型的错误率和错误类型。

图4 理想状态的混淆矩阵与实际混淆矩阵对比
(3)聚类算法与聚类结果评估
本次实验的主要内容包括通过数据集可视化观察不同属性对数据集的区分度,分别构建层级式聚类和k均值聚类两种经典聚类模型,对聚类过程进行可视化,学习聚类模型的主要测评方法。
实验采用的是鸢尾花(Iris)数据集。需要特别注意的是该数据集自身是带有类别标签的,如果直接运行聚类算法,将得到完美的聚类结果,即聚簇与原始类别完全重合。因此,必须在聚类过程中排除类别属性,观察并比较前后的聚类效果,理解类别属性对聚类过程造成的影响。
聚类结果评估主要有两种方式:主观评估和基于参照类别的评估。第一种方式可以通过可视化完成。第二种方式通过选择Weka中的Classes to clusters evaluation测评方式完成。当选择这种评估方式时,聚类过程会自动忽略所选择的类别属性,而只在评估时使用类别信息。
对层级式聚类结果进行可视化,生成代表聚类过程的树状结构(即dendrogram),
理解层次聚类只需一次聚类即可得到任意聚簇数目的特点。掌握不同的类间距离计算方法对聚类结果的影响。
(4)关联规则挖掘与评估
本次实验的主要内容是以超市数据集(supermarket.arff)为基础,运行关联规则挖掘算法,对得到的关联规则进行评估。重点在于理解多种关联规则的筛选指标,掌握关联规则挖掘的评估方法。
Weka中Apriori算法的实现提供了四种筛选关联规则的指标:confidence、lift、leverage和conviction。分别以这四种指标为标准,从数据集中生成关联规则,从算法运行效率和所得到的规则两方面比较各个指标的有效性,理解评估关联规则过程中的主观性。
关联规则挖掘过程容易受频繁属性的影响。比如本次实验得到的关联规则中,大多数都包含面包和蛋糕(bread and cake)这个属性,体现出数据集所反映的购物行为模式。接下来,在预处理面板中删除该属性,再次运行Apriori算法,将得到的关联规则与之前的规则进行比较。通过该处理,理解关联规则挖掘以及数据挖掘往往需要多次迭代的特点。
除了上述四次基本上机之外,还设计了若干综合性上机实验,包括文本处理和分类、图像处理和分类以及音频处理和分类。部分学生的编程实践能力较强,通过综合型上机实验,利用数据挖掘算法解决小型应用,完成数据采集、特征设计、预处理、应用算法、测试、评价、模型解释和呈现,实现比较完整的数据挖掘过程。
3 总结
培养实践能力是数据挖掘教学的重要目标,而上机实验是实现这一教学目标的重要教学环节。本文介绍了面向应用型本科的数据挖掘课程上机实验的设计,以Weka数据挖掘软件为工具,针对四类经典数据挖掘任务,通过应用经典算法,完成数据挖掘的一般过程,有效增强学生对课题理论教学内容的理解,提升学生的实践能力。
[1]黄岚.数据挖掘课程实践教学资源库建设[J].计算机教育, 2014(12):89-92.
[2]岳强,胡中玉,文瑾,赵卿.基于R语言的数据挖掘课程实验设计[J].微型电脑应用,2016,32(5):31-37.
[3]张晓芳,黄晓涛,王芬.大数据时代的本科数据挖掘课程建设[J].计算机时代,2016(9):76-79.
[4]鞠训光,宋农村,张三友,姜英姿.基于C#和MATLAB Server的数据挖掘Web教学演示系统[J].徐州工程学院学报:自然科学版,2010(4):72-76.
[5]Witten,I.H.,Frank,E.,Hall,M.A.,Pal,C.J.Data Mining:Practical Machine Learning Tools and Techniques(Fourth Edi⁃tion)[M].Morgan Kaufmann,2016.
Designing Lab Tutorials using Weka for the Data Mining Course
HUANG Lan,ZHOU Juan
(College of Computer Science,Yangtze University,Jingzhou 434023,China)
Improving students’capability in solving practical problems is a crucial teaching objective of the data mining course. This paper discusses our design of course lab tutorials for achieving this goal.We used Weka as the main tool and designed four tutorials,covering classification,regression,clustering and association rule learning.Through these tutorials,students can learn the general process of classic data mining tasks,understand different testing methods and performance measures,and know the com⁃mon pitfalls in data mining processes.These tutorials effectively enhance students’understanding of course contents.
data mining;teaching practices;practical teaching

图5 层级式聚类树结构
G642
A
1009-3044(2017)21-0007-03
2017-06-28
该文为长江大学教学研究项目(编号JY2014032)研究成果
黄岚,博士,长江大学计算机科学与技术系,研究领域为数据挖掘技术与应用;周娟,长江大学软件工程专业硕士研究生。
