基于Hadoop的网络安全审计关键技术的研究
2017-08-29董海滑斌
董海,滑斌
(宁夏大学信息工程学院,宁夏银川750000)
基于Hadoop的网络安全审计关键技术的研究
董海,滑斌
(宁夏大学信息工程学院,宁夏银川750000)
该文主要针对研究企业内部分布式网络日志审计技术的相关问题,提高海量日志数据的分析效率。首先,该文介绍了网络安全审计系统的研究方向和需要解决的问题。其次,该文从日志安全审计、分布式平台日志审计相关技术、关联规则挖掘算法的改进及应用三个方面进行着重研究,对日志的提取和分析、安全审计的常用方法、Apriori算法并行化改进、分布式并行日志分析流程和阶段等几个点进行了分析。最后,根据建立的安全审计模型建立实验环境,描述了一个完整的系统构架,并进行了相应实现和验证。
网络安全;日志审计;Hadoop;管理规则;数据挖掘
大数据环境下的网络信息安全令人担忧,很多企业和单位也建立了内部的日志分析系统来对区域网络日志进行关联分析,有效弥补了其他安全技术防御的不足之处。20世纪80年代Anderson[1]就提出了对系统日志分析来对系统用户进行审计,随后各种日志审计模型层出不穷,被广泛地应用研究,数据的快速增长使得现阶段的大数据环境下的整个网络的环境审计能力却不足,现有的数据挖掘算法在处理并行分布式的数据问题时也需要更近一步的改进。多网络设备和终端的大量使用,导致了海量日志的异构性不断增加,现有的网络日志安全审计系统并不能满足海量日志分析。利用分布式的数据分析环境为数据进行有效合理的分配,并利用Hadoop和关联规则并行化数据处理平台和技术来优化传统的审计方法是如今的一个研究热点[2]。
本课题的意义具体表现在:研究现有的日志审计主要方法和技术,针对现有挖掘技术在实际应用中的不足,改进现有的Apriori并行算法,将其应用到网络安全审计模型中,提高日志分析的效率和准确率,在Hadoop平台下结合相关研究,最终设计实现出一个海量日志分析的网络安全审计系统模型,并对模型进行验证,为其他人员的深入研究提供借鉴。
1 日志审计相关技术研究
1.1 日志格式和日志获取
网络安全审计中需要对数据的格式进行分析并选定相应的获取手段。网络安全日志主要包括网络中安全防御设备的硬件信息、服务器中应用软件和系统软件产生的日志记录、主机信息、警报信息等,都记录着系统中特定事件的相关活动和用户信息。网络日志可以看作是一种无格式化的数据,它有数据量大、数据格式不统一,异构性强,容易被修改、破坏甚至伪造等特点。日志格式可以由三个元素来刻画:主体(Subject)、客体(Object)和行为(Action)。日志中的事件表示主体对客体进行的操作,其中用户是主体,受保护的系统资源是客体,行为是系统服务和上层的程序应用行为[3]。网络安全审计中需要对设备日志、操作系统日志、应用程序日志进行分析。
在设备日志中主要分为Syslog和Trafficlog和WELF[4],Sys⁃log主要是设备产生的基于RFC3164标准的基于事件的日志;TrafficLog是设备中流量信息日志,它由每一次网络设备访问结束后产生,专门记录设备流量信息;WELF是很多网络厂商普遍支持的日志格式,它上层的应用软件系统会自动记录支持此格式的设备日志到记录中。
日志的获取主要分为两种技术手段,分别为抓包捕获日志获取和网关日志分析获取[5]。抓包捕获日志获取主要是扫描网络上各个端口,对网络进行Sniffer扫描,来对硬件地址和IP地址转换过程中的广播数据帧进行保存,对数据包进行Sniffer并进行扫描。网关日志分析获取主要是和网关设备相关联的,这种日志主要来源于网络系统中的网络防火墙设备、网络数据包处理系统,包括流量信息、入侵信息,这些日志反映了当前网络的整体状况,是日志审计的重要数据源。
日志数据源异构性和分布式特点日渐显现,Apache Flume是Hadoop中的一个用户数据采集的子项目,它是一个可靠性强、可用于分布式日志采集[6]。它利用FlumeNG通过主机从多个Agent系统上分布式的获取日志源,每个Agent系统处理通过安全通信链路对数据源进行数据包的存储,保存到系统的数据库中。Agent节点分布式的信息采集过程如图1所示。

图1 Agent节点分布式的信息采集过程
1.2 日志分析和关联规则
日志分析主要是对已获取的日志数据集进行数据挖掘,在网络日志数据源异构性、差异性比较大的情况下,对设备日志、操作系统日志、应用软件日志等日志进行分析的同时需要对主机和网络系统进行安全状况进行异常分析。日志分析主要有两个基本要求,第一是对来自于不同结点的异构数据源归一化后处理并进行数据集联系分析,需要对数据的相关性、数据的趋势、聚类分析和异常分析,由于联系分析中很多描述是不准确的,所以需要结合网络管理员和数据分析人员进行数据的预处理。第二个要求是利用现有的数据进行预测未来网络发展趋势,由于网络日志是整个网络状况的反映,利用现有的数据结合有效的数据预测算法可以对网络的整体状况进行预测。主要的日志挖掘模式类型有关联分析、聚类分析、演变分析和孤立点分析[7]。由于在数据挖掘中,关联分析是一个重要的研究方向,它通过频繁模式的关联来发现数据库中记录的潜在联系,本文中为了研究局域网中不同信息系统的数据集中记录的潜在联系,关联分析的方式有着良好的优势。
关联分析(Association Analysis)最初用来分析商业中购买记录中的潜在联系,它用来分析事物数据库中数据记录属性值在给定数据集中一起出现的条件[8].它最终的目的就是从数据集中提取相关性,它可以用类似X→Y的蕴涵表示形式,设X和Y是两个从事物数据库中提取的不想交的子集,X→Y可以看作是一个链表,X表示这个链表的前驱,Y可以看作这个链表的后继。对于X→Y可以看作是一个关系,也可以看作是一个硬链接,我们用支持度和置信度来表示这个硬链接的强度,即关系的可信程度。支持度代表规则在记录中出现的频繁程度,而置信度代表Y在包含A的记录中出现的频繁程度。用事务数据库中的一条日志记录作为参照,假设该项集包含字段(ID、UserName、Time、OpenSource、Traget、Item、Action、Result、Date⁃Time),假 设 该 项 集 记 录 Item(“ 注 册 表 ”)&Source (“202.201.128.2”)&Action(“修改DNS”)=>UserName(“root”),可以理解为IP地址为202.201.128.2的这个IP地址从注册表修改了DNS服务器指向,如果是root用户登录可以判断为是正常登录,其中Item(“注册表”)&Source(“202.201.128.2”)&Action(“修改DNS”)就是项集中的A,UserName(“root”)就是项集中的B,当不是用户root的时,这种强关联规则不成立,可以判断是异常操作。从这个例子中可以得到,支持度和置信度的数学表达分别可以抽象为:
Support(X→Y)=P(XY)
Confidence(X→Y)=P(Y|X)
其中置信度可以进一步表示为:
Confidence(X→Y)=Support(X→Y)/Support(X)
由此可以得到,支持度和置信度的因子可以影响关联分析的最终结果,合理的设置两个参数的值是进行高效的关联分析的重中之重。
根据数据挖掘中数据源的不同,关联规则中提供了很多分类方法,其中根据数据类型不同可以分为数值型规则和布尔规则类型,根据构成规则的维度可以分为单维和多维关联规则,根据抽象层次不同可以分为单层和多层关联规则等。每一种模式都有其具体的应用场景,应当根据数据源的不同可以选取不同的关联规则进行有效的数据关联。要注意的是,由关联规则做出的推论并不必然蕴涵因果关系。它只表示规则前件和后件中的项会明显地同时出现。
2 Hadoop平台及相关技术研究
2.1 Hadoop平台及构成
Hadoop是由Goug Cutting和Mike Cafarella根据谷歌的分布式存储和运算论文而研发的一套软件生态系统[9]。Hadoop可以看做一个可靠的可伸缩的存储和分析平台,它将分布式思想应用在软件逻辑上,包括分布式的存储和分析,HDFS是Hadoop生态系统中一种分布式应用底层框架[10],它拥有高容错性、高可靠性、高可扩展性,为超大数据集(Large Data Set)的应用处理带来了很多便利,HDFS解决了海量数据的存放形式和位置、分布式处理过程中的安全性、分布式处理后的调用效率等多种问题,为海量网络日志分析提供了可能性。
Hadoop来自于Apache的lueene项目,对海量的数据进行运算分解,它基于本地化的运算原则,把运算节点放到各个节点上面[11]。从逻辑上来讲,Hadoop大致可以分为四层架构分别为底层、中间层、上层、顶层。底层是存储层,一般基于HBase的数据存储交互;中间层是用于资源管理和数据管理,有YARN以及Sentry作为支撑[12];上层包括一些常用的计算引擎来联通中间层和顶层用户的交互,有MapReduce、Impala、Spark等计算引擎;顶层是与用户直接交互的接口,它是基于MapRe⁃duce和Spark等计算引擎的高级封装,例如,Hive、Pig、Mahout等可视化工具[13]。
2.2 MapReduce处理模型
MapReduce是谷歌公司发明的一种面向大规模海量数据处理和高性能并行计算平台和软件编程框架。它是目前最成功和最易于使用的大规模海量数据并行处理技术[14]。MapRe⁃duce被广泛应用于搜索引擎(文档倒排索引、网页连接图分析与网页排序)、Web日志分析处理、机器学习、机器翻译等各种大规模数据并行计算应用领域[15]。由于MapReduce框架是基于Java平台的,由于Java的虚拟机技术的广泛应用,使得Ma⁃pReduce框架成为Apache Hadoop的一个重要的框架。MapRe⁃duce的基于YARN的资源调度系统,使得MapReduce在大数据集的并行处理方面有着独特的优势。如图2所示,MapReduce的处理模型可以分为高度并行的Map阶段和Reduce阶段。
Map阶段中需要对海量数据进行分片作为Map的输入,主要是从节点上反序列化数据,输入的数据被split为离散的块,可以被分别并行处理,在Map阶段中,通常执行输入格式解析、投影(选择相关的字段)和过滤(删除网关的记录)。
Reduce阶段主要是数据处理人员对输入的数据集合进行处理,利用相关算法对数据集合进行合并,可以看作是一个聚合或者汇总的阶段。在这个阶段里,Map阶段的输出被聚合以产生期望的结果,所有相关的record必须被集中在一起由一个单一的实例处理。

图2 MapReduce处理的两个阶段
3 关联规则算法的并行化及应用
3.1 Apriori算法及并行化
Apriori算法是Agrawal和Srikant提出的[16],它的主要原理是通过M的项集值逐层查找M+1的项集,它不断地利用已经查找到的项集和剩余的项集作为先验库来不断的迭代逐层查找候选集合极大项集。设S为一个事物数据集合,B={b1,b2,…,bn}代表N项集的集合,A={a1,a,…,an}代表候选N项集的集合,分别便利两个集合得出两个集合中最小支持度的项集,产生项为1的候选集B1,然后通过B1中超过最小支持度的所有候选集后成B1,这样可以由B1和B1进行自然链接形成B2,对于数据集和B2可以进行清洗后再对它进行扫描遍历,通过B2中超过最小支持度的所有候选集构成B2,由B2构造B3,以此类推,当Bn=φ时进行停止,不断地进行迭代直到找到最大频繁项数据集。
由上面的传统Apriori算法的基本步骤可以看出,它是通过从底到上不断的迭代进行求出最大频繁项数据集,其中的空间复杂度和时间复杂度比较高,每一次的迭代都需要去便利两个集合的项集,如果N是较大的值,在处理大数据的日志系统中是非常不利的,影响系统的效率。另一方面,传统的Apriori算法在两个项集遍历的时候都需要一一比较过去,在求解Bn时需要遍历N项子集不在An-1中,产生比较大的候选2项集,再产生很大的候选3项集,这样占据了非常大的空间复杂度,效率比较低。
基于Hadoop平台可以对传统的Apriori算法进行并行化研究。可以利用Hadoop的并行优势对求数据块中所包含子集的个数进行优化,称作分治算法,在求频繁项的数据集中可以优化只遍历一次数据集。将S数据集合划分为N个数据块S={S1,S2,…,Sn},将每个数据块发送给Slave去处理,每个Slave只需要求出本机的数据项集个数,将每个Salve产生的键值进行合并求出最大频繁项集。Hadoop中每个Slave都会对Master发送的数据块进行计算,分别进行Map处理并按
3.2 Apriori算法的改进
在基于上一节提出的基于Hadoop平台的Apriori的分治算法,对算法的改进可以分为如下几个步骤:
步骤一:对源数据进行处理得数据集合S,Hadoop中Master节点和Slave节点的个数,对最小支持度SupportMin初始设定。
步骤二:将S数据集合划分为N个数据块S={S1,S2,…,Sn},其中S集合内为每一个不想交的数据块,将每个数据块发送给Slave去处理。
步骤三:在Slave计算通过Map计算每个Slave只需要求出本机的数据项集个数k,得到键值表<最大项集,个>。
步骤四:利用Hadoop中的Reduce对输入的键值表进行处理,利用相关算法对数据集合进行合并,键相同的情况下可以对值进行合并相加,在值大于SupportMin的情况下,继续执行步骤六,否则执行步骤五。
步骤五:令k=k-1,然后重新执行步骤三和四,求出每个Slave的最大项集。
步骤六:得到所有Slave节点给的最大项集,合并之后就是S的极大频繁项集。
3.3 算法应用分析
结合实验服务器采集的数据,利用Apriori算法并行化改进的模型,建立特征库对用户的异常行为进行分析和算法验证。首先对数据源的数据进行清洗,对时间属性离散化、对不同日志类型的数据进行区分。对系统操作进行研究,设一致化后的原始数据如表1所示。

表1 一致化后的原始数据表
对原始数据表进行离散规约后,为减少在Slave节点进行处理时从本地子集发现频繁项集发现过程中候选项集的数据,通过排除一样前缀的组合。对原始数据集进行频繁项发现后替换原有的数据表,设项为键,原始的编号序列作为value,垂直转换后可以得到如表2所示的事务数据库。
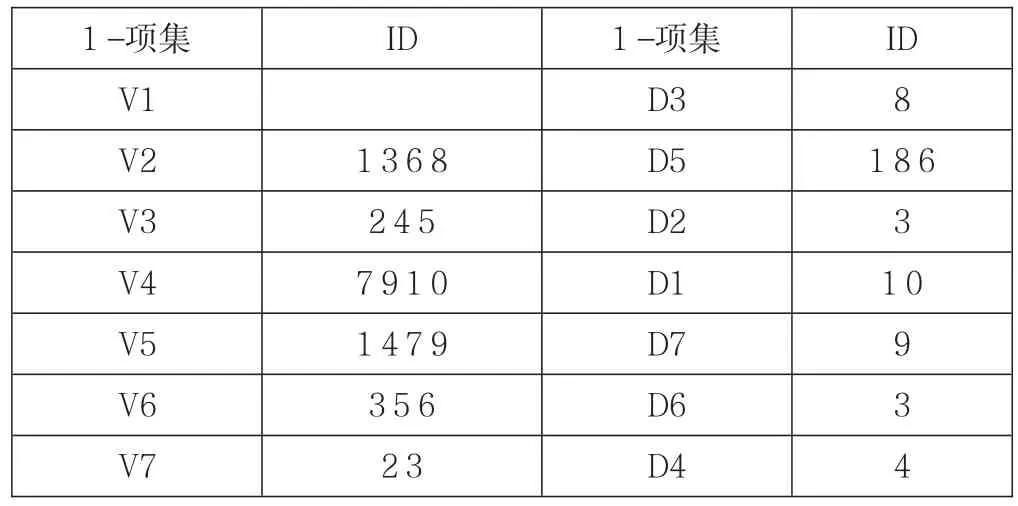
表2 垂直转换的事务数据库
4 实验分析
为检验Apriori并行化算法的效率和安全审计方法的审计效率,本文建立具体的实验环境并进行结果分析验证。实验中主要对日志分析时间、日志审计的准确率、系统自适应功能和鲁棒性进行验证。根据前面对日志审计做出的研究,确定支持度衡量关联规则的重要指标,通过改变支持度的阈值来对候选频繁项集进行调整,从而得到不同的日志分析时间、日志审计准确度和系统自适应功能。测试日志数据集的相关参数可以做如下表示:用|M|代表日志数据集的数目,用|L|日式数据集记录的平均长度,N表示事务数据库中项集的个数。设N=1200,|M|=12000,|L|=15,测试结果如下表3所示。如表3表示不同支持度下未经改进的Apriori算法和改进后的执行时间对比。可以说明,在本实验环境下改进优化算法是有效的。

表3 算法性能对比
5 结束语
本文研究了基于Hadoop平台的网络安全审计系统的关键技术,主要从网络安全审计的方法、Hadoop数据分析平台的研究现状、关联规则经典算法的并行化研究及其改进等三个方面,基于这些研究建立基于Hadoop平台的数据挖掘分析模型,并对模型进行了验证,比较了传统Apriori算法和改进后的Apriori算法的执行效率,该模型能较好地适应大数据环境下的网络日志分析,有比较好的普适性,为企业的海量日志分析提供了可以借鉴的思路。
[1]辛义忠.基于数据挖掘的网络安全审计技术的研究与实现[D].沈阳工业大学,2004.
[2]高彩容.基于数据挖掘的网络安全审计技术研究[D].西安电子科技大学,2008.
[3]冯绿音.网络信息系统日志分析与审计技术研究[D].上海交通大学,2007.
[4]朱胜奎.基于日志数据挖掘的网络安全审计技术研究[D].山东师范大学,2009.
[5]付伟.基于Hadoop的Web日志的分析平台的设计与实现[D].北京邮电大学,2015.
[6]杨锋英,刘会超.基于Hadoop的在线网络日志分析系统研究[J].计算机应用与软件,2014(8):311-316.
[7]董妍妍.基于Hadoop的Teradata数据仓库日志分析系统的设计与实现[D].南京大学,2014.
[8]陈森博,陈张杰.基于Hadoop集群的日志分析系统的设计与实现[J].电脑知识与技术,2013(34):7647-7650+7655.
[9]李荣荣.基于Hadoop平台的日志分析系统[D].复旦大学, 2013.
[10]章伟星.基于Hadoop的海量广告日志分析系统的设计与实现[D].哈尔滨工业大学,2013.
[11]赵龙.基于hadoop的海量搜索日志分析平台的设计和实现[D].大连理工大学,2013.
[12]宋爱青.基于Hadoop的日志分析系统的设计与实现[D].中国地质大学(北京),2012.
[13]刘永增,张晓景,李先毅.基于Hadoop/Hive的web日志分析系统的设计[J].广西大学学报:自然科学版,2011(S1):314-317.
[14]陈文波,张秀娟,李林,唐钧.基于Hadoop的分布式日志分析系统[J].广西大学学报:自然科学版,2011(S1):339-342.
[15]胡光民,周亮,柯立新.基于Hadoop的网络日志分析系统研究[J].电脑知识与技术,2010(22):6163-6164+6185.
[16]王斌,李超,蒋秋华.基于Hadoop的自动售票日志分析系统设计[J].铁路计算机应用,2014(7):20-23.
Research on Key Technologies of Network Security Audit Based on Hadoop
DONG Hai,HUA Bin
(Scholl of Information Engineering,Ningxia University,Yinchuan 750000,China)
In this paper,we mainly study the related issues of the internal distributed network log audit technology,so as to im⁃prove the efficiency of the analysis of mass log data.First of all,this paper introduces the research direction of network security au⁃dit system and the problems that need to be solved.Secondly,this article from the log audit,distributed platform log audit tech⁃nology,association rules mining in three aspects of algorithm improvement and application focuses on the study of log extraction and analysis,security audit methods,Apriori algorithm improvement,distributed parallel log analysis process and stages are ana⁃lyzed.Finally,according to the established security audit model,the experimental environment is built,and a complete system framework is described,and the corresponding implementation and verification are carried out.
network security;log auditing;Hadoop;management rule;data mining
TP393
A
1009-3044(2017)21-0049-04
2017-06-20
董海(1989—),男,山东东营人,硕士研究生(在读),主要研究方向为计算机网络技术;通讯作者:滑斌(1975—),男,宁夏银川人,助理工程师,主要研究方向为物联网、信息安全。
