一种基于决策森林的单调分类方法
2017-08-12王文剑任丽芳
许 行 王文剑,2 任丽芳,3
1(山西大学计算机与信息技术学院 太原 030006)2(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)3 (山西财经大学应用数学学院 太原 030006)
一种基于决策森林的单调分类方法
许 行1王文剑1,2任丽芳1,3
1(山西大学计算机与信息技术学院 太原 030006)2(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)3(山西财经大学应用数学学院 太原 030006)
(xuh102@126.com)
单调分类问题是特征与类别之间带有单调性约束的有序分类问题.对于符号数据的单调分类问题已有较好的方法,但对于数值数据,现有的方法分类精度和运行效率有限.提出一种基于决策森林的单调分类方法(monotonic classification method based on decision forest, MCDF),设计采样策略来构造决策树,可以保持数据子集与原数据集分布一致,并通过样本权重避免非单调数据的影响,在保持较高分类精度的同时有效提高了运行效率,同时这种策略可以自动确定决策森林中决策树的个数.在决策森林进行分类时,给出了决策冲突时的解决方法.提出的方法既可以处理符号数据,也可以处理数值数据.在人造数据集、UCI及真实数据集上的实验数据表明:该方法可以提高单调分类性能和运行效率,缩短分类规则的长度,解决数据集规模较大的单调分类问题.
单调分类;决策树;单调一致性;决策森林;集成学习
单调分类是一种特殊的分类问题,广泛存在于实际生活中,如大学综合水平的评定问题,其中“科研水平”、“师资队伍”、“教学质量”是3个重要指标,其得分很显然就是一种序关系,大学综合水平的“评定等级”若为“高、中、低”,则它们之间也具有优劣次序,这一问题的特征(科研水平、师资队伍、教学质量)与类别(评定等级)之间存在以下单调性约束:当一所学校在科研水平、师资队伍、教学质量这3个特征上的分数都不比另一所学校低时,它的评定等级就一定不会比另一所学校低.此外,还有诸如决策风险分析、企业绩效考核、消费者满意度评价等问题都具有同样的特点,这类问题就是单调分类问题.与一般分类问题不同,单调分类问题的特征与类别上的取值都存在序的关系,且2者之间满足单调性约束.
对于一般的分类问题,已经有很多分类方法,如决策树、神经网络、支持向量机等,这些方法一般不考虑特征与类别上的序关系,所以不能得到单调一致的分类规则.目前对于单调分类问题已有一些研究,如以粗糙集为理论框架的模型解决单调分类问题[1-6],但这些方法获得的单调一致的分类规则数量有限,且只能用于符号数据.对于数值数据的单调分类问题,我国学者Hu等人[7-10]提出的单调决策树是目前较好的方法,他们在一定程度上解决了单调性和泛化能力之间的冲突,还将序的关系引入经典Shannon熵,提出有序信息熵概念,并在此基础上设计了基于有序信息熵的决策树算法(rank entropy based monotonic decision tree, REMT).这种方法能够产生结构简单、易于理解的规则集,但得到的精度相对有限,且存在过度拟合问题.
决策森林源于随机森林[11],是以决策树为基础分类器的集成算法,可以有效避免过度拟合,且能够提高分类精度,因而受到了研究者的广泛关注.但决策森林目前只用于解决一般的分类问题,对于单调分类问题,构造决策森林时面临3种困难:1)单个决策树的构造需要在不同的训练子集上进行,如何保证子集的单调性;2)如何确定决策森林的规模;3)集成规则出现冲突时如何解决.
本文提出一种用于解决单调分类问题的基于决策森林的单调分类方法,设计采样策略来构造决策树,该策略考虑数据集单调一致的特点,可避免非单调数据的噪声影响,同时这种策略可以自动确定决策森林中决策树的个数.在决策森林进行分类时,本文还提出叶子节点上的规则支持度的概念,从而给出决策冲突时的解决方法.本文提出的方法既可以处理符号数据,也可以处理数值数据.
1 背景知识
1.1 单调分类问题
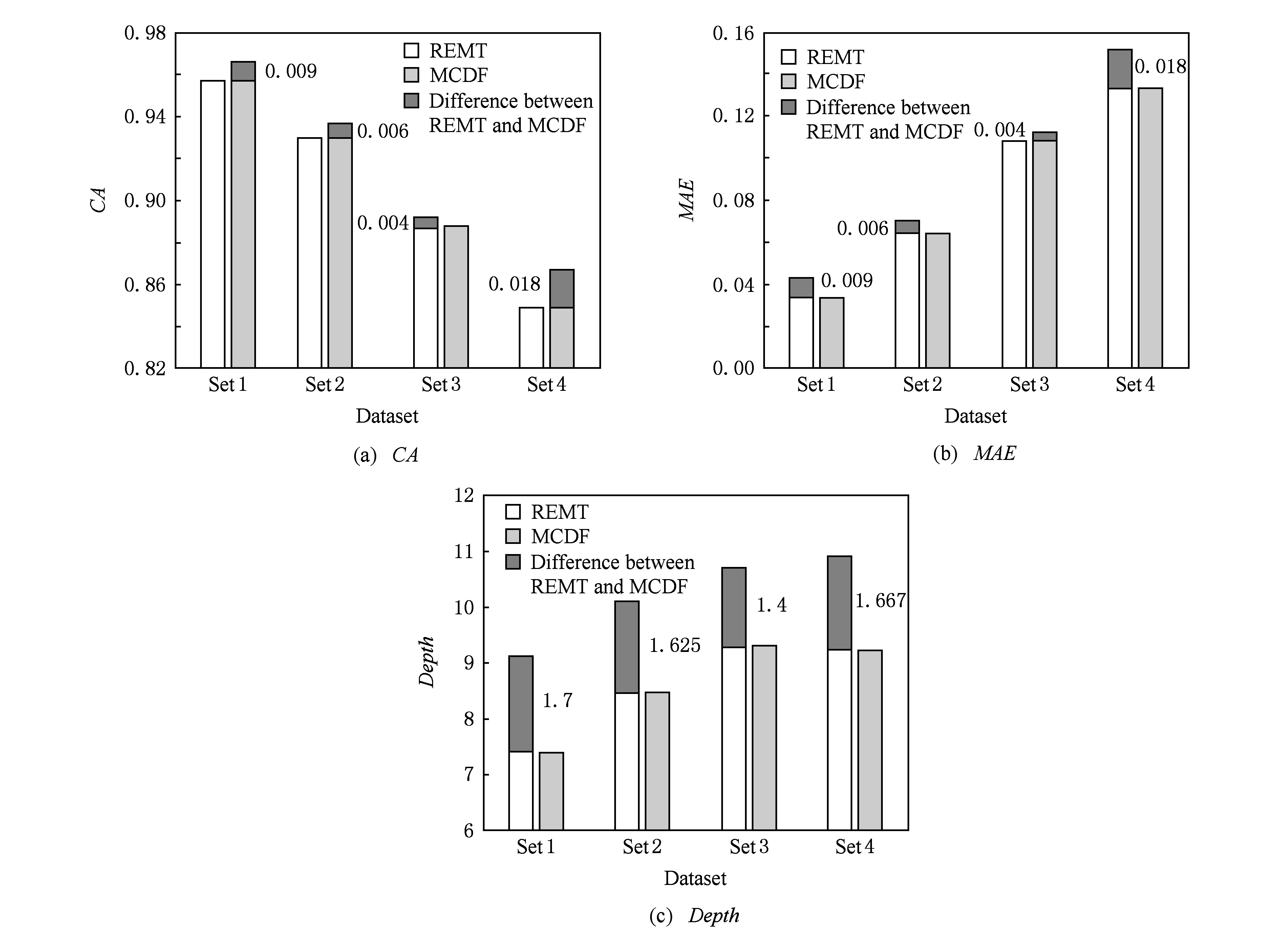
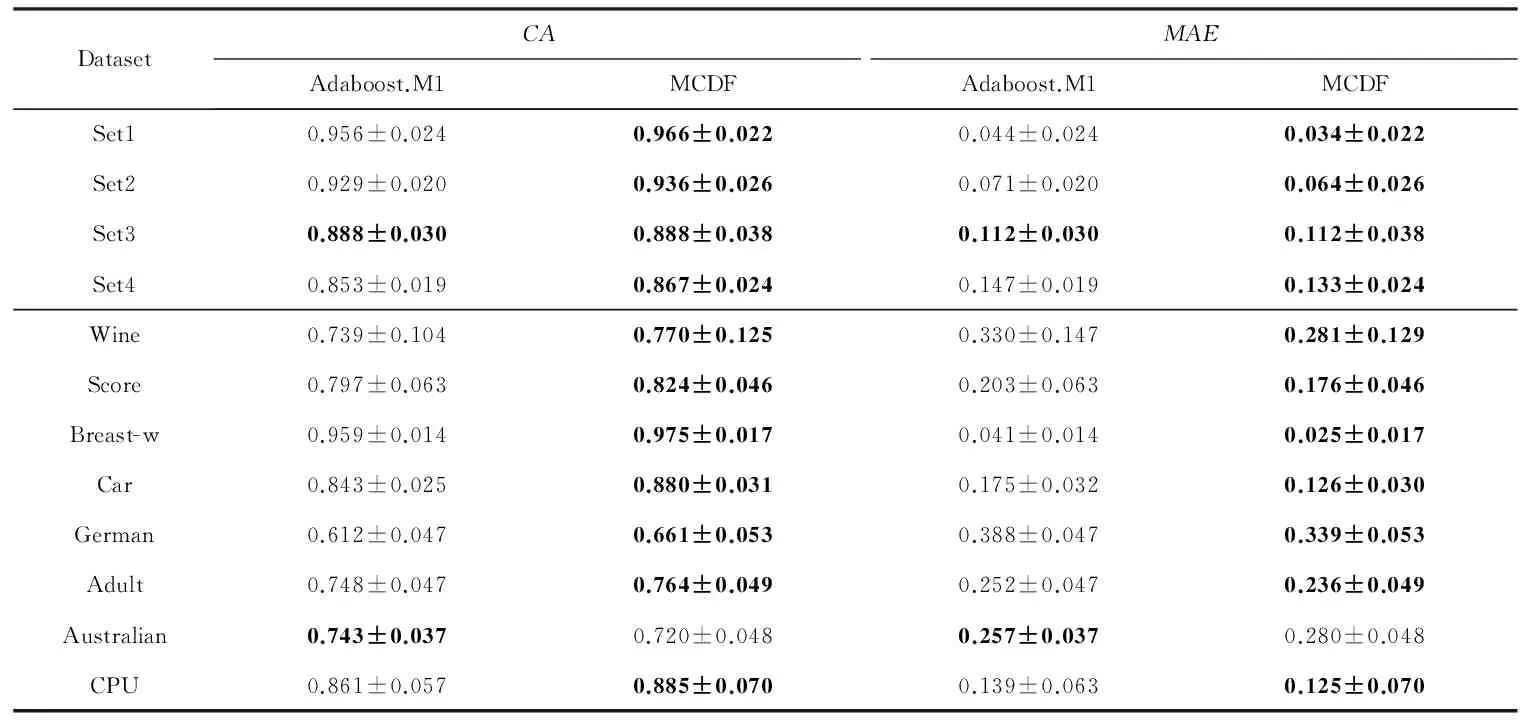
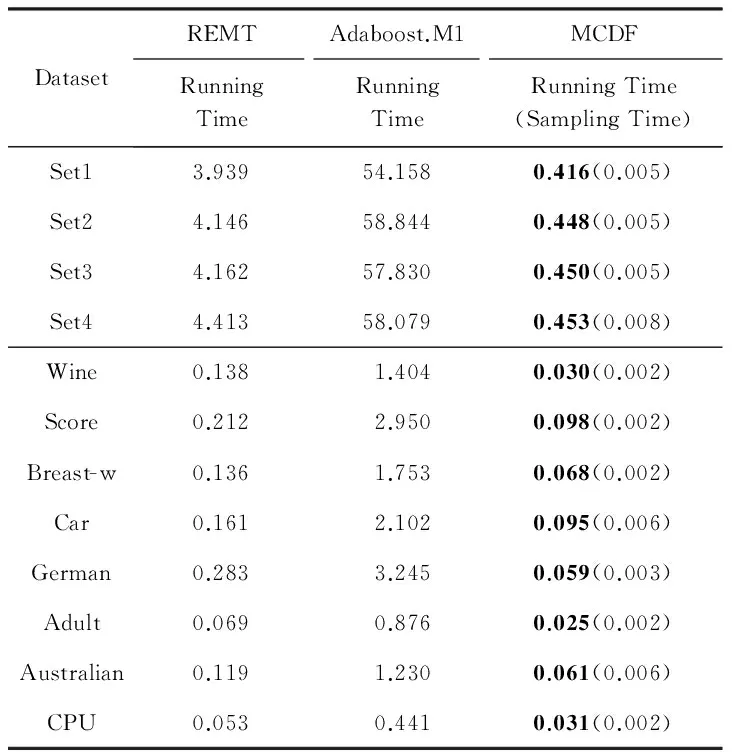
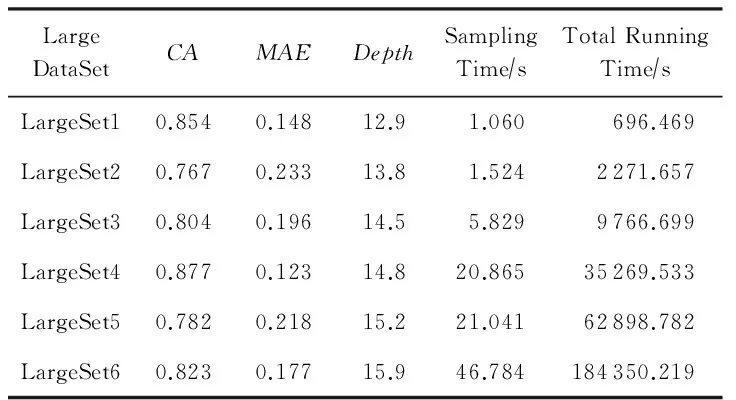
令U={x1,x2,…,xn}为数据集,A={a1,a2,…,am}是描述数据的特征集,xi在特征a上的值记为a(xi),xi的类标签记为y(xi).如果y(xi)的值域{c1,c2,…,cs}上存在序关系c1 对于一个有序分类问题,如果∀xi,xj∈U在每一个特征ak∈A上都满足若ak(xi)≤ak(xj),则y(xi)≤y(xj),那么该问题为单调分类问题[12]. 给定xi∈U,若特征集B⊆A,则在特征集B上xi的优势类和劣势类分别定义为 (1) (2) 1.2 决策森林 决策森林是由多个单棵决策树组成集成分类器的集成学习方法,可表示为{h(x,θk),k=1,2,…},其中,x是输入样本,θk是独立同分布的随机变量,h(x,θk)表示一棵决策树.对于输入样本x,每棵决策树判断其类别后投票给与其判断结果相符的类,得票最多的一类为最终分类结果.构建决策森林的方式主要有基于数据集的构造方式和基于特征集的构造方式. 构建决策森林模型时主要考虑4方面: 1) 当采用基于数据集的构造方式构造决策森林时,训练数据子集如何构成; 2) 当采用基于特征集的构造方式构造决策森林时,特征子集如何构成; 3) 决策树的数目如何确定; 4) 生成的所有决策树如何集成为决策森林模型. 2.1 单棵决策树的构造 决策森林的预测能力与每棵决策树相关,为用较少的决策树构造出精度较高的决策森林,决策树必须要有一定的差异性.本文采用基于数据集的构造方式构造决策森林,通过为每个决策树构造有差异性的训练子集来获得决策树之间的差异性.构造单棵决策树的训练子集时,不能采用经典的随机采样、bagging[13]、boosting[14]等方法,因为随机采样和bagging方法都不考虑数据的分布情况,boosting方法对噪声的敏感性使其更易于产生过拟合现象[15],并且这些方法也没有考虑数据的单调性.Liang等人[16]提出一种较好的重采样方法,使得采样得到的子集间有一定的差异度又能较大程度地覆盖原始数据集,且与原数据集分布相同,但该方法不考虑数据的序关系,且只能用于符号数据的处理. 本文借鉴文献[16],将以上方法引入单调分类问题,可以同时处理符号数据和数值数据.在构造单棵决策树时,为保持单调分布的一致性,为每个样本加权,在多次采样时权值不是固定不变的,而是随着已有决策树的错误率和错分样本的单调一致性进行调整,在调整中去掉不一致的样本.另外,本文中训练子集的规模不是由用户指定的固定值,而是根据数据集的特征自动确定的. 1) 训练子集规模的确定 对于数据集U,文献[16]给出的训练子集规模M为 (3) 其中,Z为置信水平下的Z-统计值,可以计算得出,E为可以接受的误差,由用户指定,这2个变量取值已知,因此计算M的关键在于数据集上的标准差σ的计算.文献[16]给出了符号数据上σ的计算方法. 为同时处理符号数据和数值数据,本文设计的标准差σ为 (4) 对于数值型特征,先统一各个特征的取值范围,将所有样本的特征取值归一化: (5) 其中,akmin(x)和akmax(x)分别表示所有样本在特征ak上的最小值和最大值,然后计算该特征的特征标准差: 对于符号型特征,与文献[16]不同,本文采用单个特征的不相似度而不是基于所有特征上的不相似度来计算特征标准差σak. (7) 一般地,为保证学习器的训练效率,训练子集的规模M不宜太大,若M与样本总数N超过一定比率θ(如θ=5%),需要调整训练子集的规模,调整方法为 (8) 确定训练子集样本的规模算法总结如下. 算法1. 确定训练子集样本的规模算法. 输入: 单调数据集U、参数Z,E,θ; 输出: 训练子集的规模M. Step1. 按式(4)计算数据集的标准差:若特征为数值型,则按式(5)将所有样本在该特征上的取值归一化,然后按式(6)计算其特征标准差;若特征为符号型,则按式(7)计算其特征标准差; Step2. 按式(3)计算训练子集的规模M; Step4. 返回M. 2) 训练子集的采样 采样训练子集前,先计算原始训练集U中每个类别的样本占所有样本的比例pl: (9) 其中,l=1,2,…,s,Cl={xi∈U|y(xi)=cl},i=1,2,…,n.采样时要确保各个类别的样本数在原训练集与采样出的训练子集中的比例相同.之后通过迭代采样训练子集,每次迭代产生1个训练子集.迭代过程如下: 初始状态下,原训练集U中所有样本的权重相等,即每个样本的初始权重为 (10) 其中,n为原训练集中样本的数量. 首先采样第1个训练子集U1,在原训练集U中随机选择M个样本,并保证其中每个类别的样本数与M的比例为pl,l=1,2,…,s.采样下一个训练子集Ut时,先在前一个训练子集上生成决策树,计算该决策树的加权误差εt: (11) 根据错误率更新原训练集的样本权重:对于错分的样本,首先判断该样本的单调一致性,本文用包含度描述样本的单调一致性.定义xi在特征集A与类标签y上的包含度为 (12) D(xi)的值越大,表示样本xi在特征集与类别上取值的单调一致性越高.这里把满足D(xi)≥e的样本xi看作单调一致的样本,否则为非单调一致的样本,e为给定的参数. 对于错分的单调一致样本,增加其权重: (13) 对于错分的非单调一致样本,减小其权重:因为非单调一致的样本会影响分类器的精确度,故令其权重直接为0. 由于每次迭代产生1个训练子集,每个训练子集对应生成1棵决策树,因此迭代执行的次数就是决策森林中决策树的数目.当M确定后,每次从未抽取过的数据集中抽取的样本个数(1-α)M也随之确定,进而可以确定总迭代次数.也就是说,决策森林中决策树的数目可以通过确定每个训练子集的样本规模自动确定. 训练子集的采样算法总结如下. 算法2. 训练子集的采样算法. 输入: 单调数据集U、参数Z,E,θ,e,α; 输出:h个训练子集. Step1. 用算法1确定训练子集的样本规模M. Step2. 对于单调数据集U,按式(9)计算其中各个类别的比例pl; Step3. 按式(10)为训练集中每个样本的权重赋初值; Step4. 在U上随机选择训练子集U1,并保证其中各类别样本数占该训练子集中所有样本数的相应比例为pl; Step5. 按以下步骤,迭代生成决策树,直到训练集U上未被抽取的样本数小于M时结束循环,并记录迭代执行的次数h; Step5.1. 在上一训练子集上用REMT[9]方法生成决策树,并按式(11)计算决策树的加权误差; Step5.2. 对错分样本按式(12)计算其单调一致性,对给定参数e,若D(xi)≥e,则按式(13)更新xi的权重,否则权重为0; Step5.3. 在Ut-1上抽取αM个样本,在U上未被抽取的样本中抽取(1-α)M个样本,得到新的训练子集Ut,并保证其各类别的相应比例为pl; Step5.4. 对Ut中的样本权重归一化; Step6. 返回h个训练子集Ut(t=1,2,…,h). 在每个训练子集Ut上,采用适用于单调分类的REMT算法[9]可以生成单棵决策树Tt,t=1,2,…,h. 2.2 决策森林的生成算法 本文提出一种基于决策森林的单调分类算法(monotonic classification method based on decision forest, MCDF),通过计算每棵决策树的规则支持度,获得决策森林最终的分类结果. 对于每棵决策树,设叶子节点leafi中包含的样本集为Uleafi,这些样本来自不同的类c1,c2,…,定义分类规则在类别ck上的规则支持度为 (14) 其中,Uleafi k表示叶子节点leafi中的第k类样本集. 规则支持度Support(ck)记录在每棵决策树的每个叶子节点上,集成决策树时,根据每棵树的分类规则和规则支持度确定分类结果:当一个新的样本输入时,让每棵决策树根据自己的分类规则对其投票,即投票给它认为正确的类别,最后选择得票数最多的类作为该样本的最终分类结果.若有r个类别的得票数相等(r≥2),即决策冲突时,计算每棵决策树中用于判断该样本类别的叶子节点的规则支持度,将这h棵决策树在每种类别上的规则支持度加和,取规则支持度之和最大的类别作为该样本的最终分类结果,即该样本的分类结果为 (15) 本文提出的MCDF算法的主要步骤如下. 算法3. MCDF算法. 输入: 训练集UTrain、测试集UTest、参数Z,E,θ,e,α; 输出: 测试集UTest中所有样本的分类结果. Step1. 用算法2得到训练集UTrain的h个训练子集Ut,t=1,2,…,h; Step2. 在每个训练子集上用决策树算法REMT[9]生成决策树Tt,t=1,2,…,h,按式(14)计算每个叶子节点中各个类别上的规则支持度; Step3. 对测试集中的一个样本x,让h棵决策树对其分类并投票,得到多个分类结果ck,k=1,2,…; Step4. 比较每个类别ck的得票数,按以下步骤决定最终分类结果: Step4.1. 若具有最多票数的ck唯一,记为cmax,则cmax就是该样本的最终类别; Step4.2. 若同时具有最多票数的类别ck有r个(r≥2),则按式(15)计算这r个类中规则支持度之和最大的类别ck,作为该样本的最终类别; Step5. 对测试集UTest中的所有样本分类后返回分类结果. 2.3 时间复杂度分析 由于决策树数目可以提前计算,因此,MCDF方法构建决策森林的时间主要由采样时间和生成决策树的时间2部分构成. 采样过程中,样本在特征集与类标签上的包含度可以在采样前提前计算,不需占用采样时间.而计算决策树的加权误差、更新样本权重和抽样过程都需要分别遍历1次M个样本,因此单棵决策树的采样过程的时间复杂度为O(M). 生成决策树时,需要分别考虑非叶子节点和叶子节点上的时间复杂度. 2) 在第j个叶子节点上,需要遍历该节点中的所有样本求其所包含的每个类别的支持度,故叶子节点上的时间复杂度为O(nj)≤O(M). 假设决策森林中的非叶子节点和叶子节点数分别为k1和k2,则生成决策树的时间复杂度为O(k1mvM2+k2M). 综上,设MCDF方法构建的决策森林中决策树数目为h个,那么MCDF方法的时间复杂度为O(hM+k1mvM2+k2M). 由以上分析可知,本方法中虽然增加了采样过程,但采样的时间复杂度仅为O(hM),而通过采样可以将时间复杂度中的样本数量M由原训练集的样本数量n减少为采样后的M,而M≪n. 3.1 实验数据集及评价指标 本文分别在4个人造数据集、7个UCI及1个真实数据集上进行实验.4个单调的人造数据集构造[8]为 (16) 其中,x1,x2∈[0,1]. 每个数据集都有1 000个样本、2个特征,类别数依次为2类、4类、6类和8类,其散点图如图1所示: Fig. 1 The artificial datasets图1 人造数据集 本文还使用表1所示的8个数据集验证算法,除Score为山西大学学生成绩的真实数据集外,剩下的7个为UCI数据集.其中Wine,Score为数值型数据集,Breast-w,Car为符号型数据集,其他4个为既包含符号型特征也包含数值型特征的数据集. Table 1 The Datasets Description表1 数据集描述 在每个数据集上进行十折交叉验证.使用分类准确率和平均绝对误差作为预测能力的评价标准. 分类准确率CA定义为 (17) 平均绝对误差MAE定义为 (18) 此外,用决策树的平均深度Depth作为分类规则长度的评价标准.实验设备是1台配置为3.60 GHz-4核CPU、8 GB内存的计算机,实验平台是MyEclipse 2015CI.相关参数设置如下:Z=1.96,E=1.2,θ=0.05,e=0.1,α=0.5. 3.2 MCDF与REMT算法的比较 Hu等人提出的REMT单调分类算法[9]是单调分类问题中较为经典的算法,因此本文首先比较MCDF与REMT单调分类算法的分类精度、平均绝对误差和决策树深度. 图2和图3分别为2种算法在人造数据集和UCI及真实数据集上的实验结果. 从图2和图3可以看出,除人造数据集Set3以外,MCDF方法在所有数据集上都比REMT算法的分类准确率高,平均绝对误差低;由于训练子集的规模比原训练集的规模小,所以在包括Set3在内的所有数据集上,MCDF方法都比REMT算法的决策树深度小. Fig. 2 The experimental result comparison of REMT and MCDF on the artificial datasets图2 人造数据集上REMT算法与MCDF方法的实验结果比较 在人造数据集Set3上,MCDF方法在CA和平均绝对误差MAE上比REMT算法低约0.4%.MCDF方法在生成多个决策树的迭代过程中,除了每次采样不同的训练样本外,还通过判断错分样本的单调一致程度来改变每棵决策树中训练样本的权重,以增加各个决策树之间的差异度,从而提高决策森林的分类精度.而由于构造的人造数据集具有较强的单调一致性,一方面单调一致的数据集中不会有权重为0的样本出现,另一方面,单棵决策树在单调一致的数据集上每次迭代得到的错分样本数量较少,即权重改变的样本数较少,造成了各个决策树之间的样本权重差异度不大,所以MCDF方法的优越性没有得到充分体现;而REMT算法由于使用了全部的训练对象,在人造数据集上具有较好的分类性能.实际上,在人造数据集上,2种方法的分类性能差别不大:在Set1,Set2,Set4上MCDF方法精度比REMT算法提高不多(分别为0.9%,0.6%和1.8%),在Set3上低于REMT算法的差距也很小(0.4%). 根据实验结果,在人造数据集和UCI及真实数据集上,MCDF方法比REMT算法的分类准确率分别平均提高了0.72%和4.14%,平均绝对误差分别平均降低了0.73%和4.21%,而且由于使用了较小规模的训练子集,MCDF方法得到的决策树深度在人造数据集和UCI及真实数据集上分别平均减少了1.6和3.21,因此本文提出的方法可以提高单调分类的性能,缩短分类规则的长度. Fig. 3 The experimental result comparison of REMT and MCDF on the UCI and real datasets图3 UCI及真实数据集上REMT算法与MCDF方法的实验结果比较 3.3 MCDF与Adaboost.M1算法的比较 MCDF与经典的集成学习方法Adaboost.M1算法[14]进行了比较,表2是2种方法在12个数据集上的准确率和平均绝对误差比较. 从表2可以看出,除Australian以外的其他11个数据集上,MCDF比Adaboost.M1的分类准确率高、平均绝对误差低.因为Adaboost.M1算法是根据基分类器的错误率改变错分的训练样本的权重,进而构造不同的训练子集,生成决策树,而对于单调分类问题,由于训练集中存在非单调一致的样本,在Adaboost.M1算法的迭代过程中,这些样本的权重逐渐增大,降低了基分类器的准确率,使得Adaboost.M1算法的集成结果较差.而本文算法中根据D(xi)判断样本xi的单调一致性,避免采样非单调一致的样本,同时提高采样得到的训练子集的差异性,所以取得了较好的集成效果. 在数据集Australian上,MCDF方法在CA和平均绝对误差MAE上都比Adaboost.M1算法低2.3%,其原因首先与数据集Australian本身的特点有关.根据文献[12]中有序数据集上特征对类别的依赖度的定义可以求得:数据集Australian上的特征依赖度为0.998,接近于1,也就是说几乎所有样本都可以被一致地分配类别,这与人造数据集上的情况相似.其次,MCDF方法在数据集Australian上的迭代过程中较少出现权重改变较大的样本,降低了MCDF方法创建的决策森林中各个决策树之间的差异度,使得MCDF方法的性能受到影响;而数据集Australian中噪声较少的特点恰好避开了Adaboost.M1算法对噪声比较敏感的弱点,使其分类效果不受影响.另外,数据集Australian的类别数为2,也使得MCDF方法针对多类别之间的有序关系上的优势难以得到体现,而Adaboost.M1每次都使用了全部训练样本生成决策树,具有相对较好的分类性能.以上3个因素共同造成了MCDF在Australian上的分类性能略差于Adaboost.M1算法.但是与Set3一样,虽然MCDF方法的分类精度比Adaboost.M1略有下降,但其运行效率比Adaboost.M1算法高. Table 2 The CA and MAE Result Comparison of Adaboost.M1 and MCDF on the Datasets表2 Adaboost.M1算法与MCDF方法的准确率和误差比较 3.4 REMT,Adaboost.M1与MCDF的运行时间 REMT,Adaboost.M1与MCDF方法在运行时间上进行了比较,表3是3种方法在12个数据集上的实验结果. Table 3 The Running Time Comparison of REMT, Adaboost.M1 and MCDF表3 REMT,Adaboost.M1与MCDF方法的运行 时间比较 s 从表3可以看出,运行效率上,MCDF方法的执行时间比REMT算法、Adaboost.M1算法都有很大提高,尤其在数值型数据集上,如Set1~Set4,效果非常显著.按照2.3节中的分析可知,生成每棵决策树的时间复杂度为O(k1mvM2+k2M),由于Set1~Set4为数值型数据集,所以其特征的值域取值有ni种,即v=ni,以根节点为例,数值型数据集根节点上的时间复杂度就为O(mM3),那么与REMT和Adaboost.M1算法每次都使用训练集中的所有对象生成单棵决策树相比,如果MCDF方法的样本量减少为原来的20%,根节点上的运行时间就可以减少为原来的1500,同理,其他节点上的运行时间也都有不同程度的降低,而采样过程所增加的时间花销却很小.因此,尽管REMT算法只训练1棵决策树,但其时间复杂度为2n),而M≪n,所以其运行速度仍然比MCDF方法慢,而Adaboost.M1算法所需时间为REMT的hA倍(hA为Adaboost.M1算法构造的基分类器数量),运行速度更慢.由实验结果可知,在数值型的人造数据集上,MCDF方法的平均时间花销分别约为REMT和Adaboost.M1算法的19和1130;在UCI及真实数据集上,MCDF方法的平均时间花销提高最多的是German数据集,分别约为REMT和Adaboost.M1的15和155,即使在提高最少的CPU数据集上,MCDF方法的时间花销也仅约为REMT和Adaboost.M1的12和114.因此,本文提出的方法有效地提高了运行效率. 3.5 MCDF在较大规模数据集上的有效性 由于UCI中单调数据集的规模较小,为了验证MCDF在较大规模数据集上的有效性,用以下函数构造单调数据集: f(x1,x2,…,xm)= (19) Table 4 The Large Dataset Description表4 大规模数据集描述 在该数据集上,MCDF方法的实验结果如表5所示.而REMT和Adaboost.M1算法在数据集LargeSet1,LargeSet2上用MCDF方法的10倍运行时间仍无法得到结果;在LargeSet3~LargeSet6这4个数据集上,也无法在可接受的时间内得到结果. Table 5 The Experimental Result on the Large Dataset表5 大规模数据集实验结果 本文提出的MCDF方法针对单调的数据集,用基于数据集的构造方式构建决策森林,解决单调分类问题.该方法既可处理符号型数据,又可处理数值型数据以及包含符号型和数值型的混合数据;设计的采样策略,在保持较高分类精度的同时大大提高了运行效率;提出的规则支持度有效地保证了单调分类的性能;此外,该方法还可以解决大规模数据集上的单调分类问题.本文通过数据集各个特征上的取值来自动确定决策树的数目,可以避免人工干预,但需要遍历所有样本来获得对决策树的评价,对算法效率有一定影响.能否根据决策树本身的结构选择部分决策树来构成决策森林还需要进一步研究. [1]Greco S, Matarazzo B, Slowinski R. Rough approximation by dominance relations[J]. International Journal of Intelligent Systems, 2002, 17(2): 153-171 [2]Sai Ying, Yao Yiyu, Zhong Ning. Data analysis and mining in ordered information tables[C]Proc of IEEE ICDM’01. Los Alamitos, CA: IEEE Computer Society, 2001: 497-504 [3]Kotlowski W, Dembczynski K, Greco S, et al. Stochastic dominance based rough set model for ordinal classification[J]. Information Sciences, 2008, 178(21): 4019-4037 [4]Hu Qinghua, Yu Daren, Guo Maozu. Fuzzy preference based rough sets[J]. Information Sciences, 2010, 180(10): 2003-2022 [5]Qian Yuhua, Dang Chuangyin, Liang Jiye, et al. Set-valued ordered information systems[J]. Information Sciences, 2009, 179(16): 2809-2832 [6]Ben-David A. Automatic generation of symbolic multiattribute ordinal knowledge-based DSSs: Methodology and applications[J]. Decision Sciences, 1992, 23(6): 1357-1372 [7]Hu Qinghua, Guo Maozu, Yu Daren, et al. Information entropy for ordinal classification[J]. Science China: Information Sciences, 2010, 53(6): 1188-1200 [8]Hu Qinghua, Pan Weiwei, Zhang Lei, et al. Feature selection for monotonic classification[J]. IEEE Trans on Fuzzy Systems, 2012, 20(1): 69-81 [9]Hu Qinghua, Che Xunjian, Zhang Lei, et al. Rank entropy based decision trees for monotonic classification[J]. IEEE Trans on Knowledge and Data Engineering, 2012, 24(11): 2052-2064 [10]Che Xunjian. Ordinal decision tree based fault level detection[D]. Harbin: Harbin Institute of Technology, 2011 (in Chinese)(车勋建. 基于有序决策树的故障程度诊断研究[D]. 哈尔滨: 哈尔滨工业大学, 2011) [11]Breiman L. Random forest[J]. Machine Learning, 2001, 45(1): 5-32 [12]Hu Qinghua, Yu Daren. Applied Rough Computing[M]. Beijing: Science Press, 2012 (in Chinese)(胡清华, 于达仁. 应用粗糙计算[M]. 北京: 科学出版社, 2012) [13]Breiman L. Bagging predictors[J]. Machine Learning, 1996, 24(2): 123-140 [14]Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139 [15]Wang Wenjian, Men Changqian. Support Vector Machine Modeling and Application[M]. Beijing: Science Press, 2014 (in Chinese)(王文剑, 门昌骞. 支持向量机建模及应用[M]. 北京: 科学出版社, 2014) [16]Liang Jiye, Wang Feng, Dang Chuangyin, et al. An efficient rough feature selection algorithm with a multi-granulation view[J]. International Journal of Approximate Reasoning, 2012, 53(6): 912-926 Xu Hang, born in 1987. PhD candidate. Her main research interests include machine learning and service computing. Wang Wenjian, born in 1968. PhD. Professor, PhD supervisor. Senior member of CCF. Her main research interests include neural networks, support vector machine, machine learning and intelligent computing. Ren Lifang, born in 1976. PhD candidate. Lecturer. Her main research interests include machine learning and service computing. A Method for Monotonic Classification Based on Decision Forest Xu Hang1, Wang Wenjian1,2, and Ren Lifang1,3 1(SchoolofComputerandInformationTechnology,ShanxiUniversity,Taiyuan030006)2(KeyLaboratoryofComputationalIntelligenceandChineseInformationProcessing(ShanxiUniversity),MinistryofEducation,Taiyuan030006)3(SchoolofAppliedMathematics,ShanxiUniversityofFinanceandEconomics,Taiyuan030006) Monotonic classification is an ordinal classification problem in which the monotonic constraint exists between features and class. There have been some methods which can deal with the monotonic classification problem on the nominal datasets well. But for the monotonic classification problems on the numeric datasets, the classification accuracies and running efficiencies of the existing methods are limited. In this paper, a monotonic classification method based on decision forest (MCDF) is proposed. A sampling strategy is designed to generate decision trees, which can make the sampled training data subsets having a consistent distribution with the original training dataset, and the influence of non-monotonic noise data is avoided by the sample weights. It can effectively improve the running efficiency while maintaining the high classification performance. In addition, this strategy can also determine the number of trees in decision forest automatically. A solution for the classification conflicts of different trees is also provided when the decision forest determines the class of a sample. The proposed method can deal with not only the nominal data, but also the numeric data. The experimental results on artificial, UCI and real datasets demonstrate that the proposed method can improve the monotonic classification performance and running efficiency, and reduce the length of classification rules and solve the monotonic classification problem on large datasets. monotonic classification; decision tree; monotonic consistency; decision forest; ensemble learning 2016-03-11; 2016-08-08 国家自然科学基金项目(61673249,61503229);山西省回国留学人员科研基金项目(2016-004);山西省研究生教育创新项目(2016BY003) This work was supported by the National Natural Science Foundation of China (61673249, 61503229), the Scientific Research Foundation for Returned Scholars of Shanxi Province (2016-004), and the Innovation Project of Shanxi Graduate Education (2016BY003). 王文剑(wjwang@sxu.edu.cn) TP181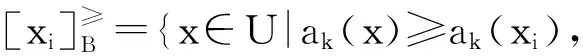

2 决策森林单调分类方法
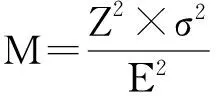

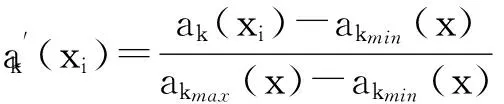
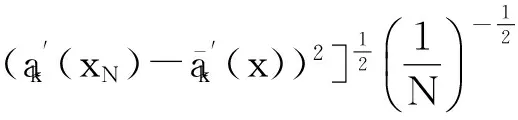
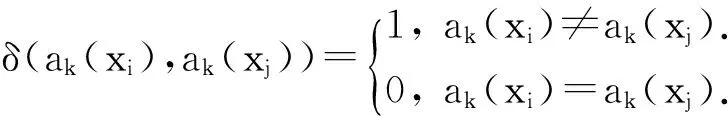
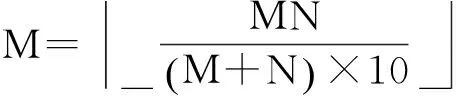
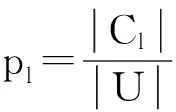
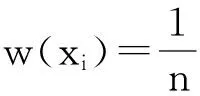
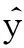
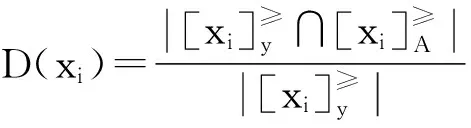

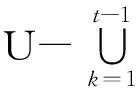
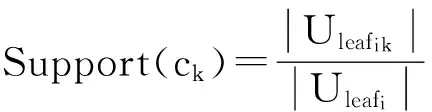
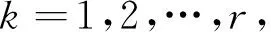
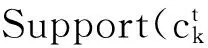

3 实验结果及分析
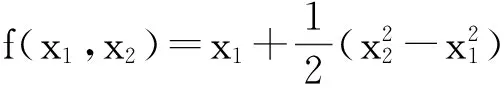


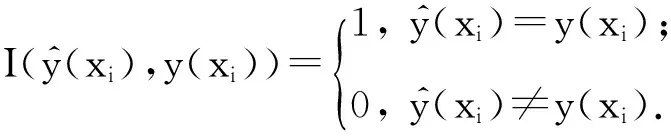


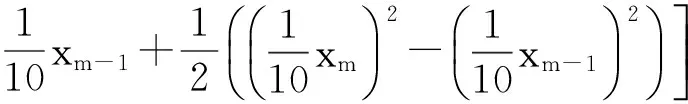



4 结束语



