Web数据库top-k多样性关键字查询推荐方法
2017-08-12孟祥福毕崇春张霄雁唐晓亮唐延欢
孟祥福 毕崇春 张霄雁 唐晓亮 唐延欢
1(辽宁工程技术大学电子与信息工程学院 辽宁葫芦岛 125105)2 (辽宁工程技术大学软件学院 辽宁葫芦岛 125105)
Web数据库top-k多样性关键字查询推荐方法
孟祥福1毕崇春1张霄雁1唐晓亮2唐延欢1
1(辽宁工程技术大学电子与信息工程学院 辽宁葫芦岛 125105)2(辽宁工程技术大学软件学院 辽宁葫芦岛 125105)
(marxi@126.com)
Web数据库用户通常使用他们熟知的关键字表达查询意图,这可能导致获取的结果不能很好满足其查询需求,因此为他们提供top-k个与初始查询语义相关且多样化的候选查询有助于用户扩展知识范围,从而更准确完善地表达其查询意图.提出一种top-k多样性关键字查询推荐方法.1)利用不同关键字在查询历史中的同现频率和关联关系评估关键字之间的内耦合和间耦合关系;2)根据关键字之间的耦合关系构建语义矩阵,进而利用语义矩阵和核函数方法评估不同关键字查询之间的语义相关度.为了快速返回top-k个与初始查询相关且多样性的候选查询,根据查询之间的语义相关度,利用概率密度函数分析查询的典型程度,并利用近似算法从查询历史中找出典型查询.对于所有的典型查询,从中选出少数代表性查询,根据其他典型查询与代表性查询之间的语义相关度,为每个代表性查询构建相应的查询序列;当一个新的查询到来时,评估其与代表性查询之间的语义相关度,然后利用阈值算法(threshold algorithm, TA)在预先创建的查询序列上快速选出top-k个与给定查询语义相关的多样性候选查询.实验结果和分析表明:提出的关键字之间耦合关系计算和查询之间的语义相关度评估方法具有较高准确性,top-k多样性选取方法具有较好效果和较高执行效率.
Web数据库;多样性推荐;耦合关系;典型化分析;top-k选取
关键字查询无需用户了解Web数据库的结构和内容,而是类似于谷歌和百度等搜索引擎一样仅使用少数几个关键字表达查询意图.近年来,关系数据库上关键字查询的代表性研究工作主要是基于模式图(schema graph, SG)[1-3]和候选网(candidate networks, CNs)[4-6]的全文匹配方法.然而,上述方法通常假定用户能够使用关键字明确表达自己的查询意图,进而主要关注关键字的形式化匹配及查询效率,没有考虑查询关键字与查询结果的语义相关性.实际上,用户的查询意图通常是模糊或不明确的,并且用户通常使用自己熟知的关键字表达查询意图,因此提出的关键字查询也并非能够有效表达出用户的查询需求.此外,如果查询关键字的选择性过强,还将会导致空或少量查询结果问题.这种情况下,为用户提供一些与初始查询语义相关的多样性候选查询,有助于扩展用户的查询思路,进一步完善其查询需求的表达.例如当科研人员通过DBLP网站进行文献检索时,他们所提的查询关键字通常是某个研究领域的特殊专业词汇,有时匹配的结果会很少,此时他们希望看到与查询关键字语义相关的文献.举例假设某位科研人员希望了解信息检索领域有关查询排序的技术方法,则他很可能输入的查询关键字是“information retrieval,ranking,top-k”,这种情况下如果系统能够为其提供“vector space model”,“latent semantic analysis”,“relevance ranking”等与信息检索和排序函数相关的查询(或查询关键字),则对于不了解信息检索领域的初学者来说非常重要.由此可见,top-k关键字查询推荐技术的关键在于分析关键字之间的语义相关关系,进而找到与给定查询语义相关的多样性候选查询.近年来,从耦合关系角度分析关键字之间的语义相关性逐渐兴起,文献[7-9]将耦合关系分析思想引入到文档分析、聚类和分类中,有效提高了算法的准确性.作者以前的研究工作[10]提出了基于语义相似度的top-k关键字查询推荐方法,但在实际应用中该方法返回的top-k个候选查询之间通常非常相似,不能有效拓展用户知识和查询视野.针对这一问题,本文在此基础上进一步研究Web数据库top-k多样性关键字查询推荐方法,目的是为普通用户提供少量语义相关且彼此具有一定差异的多样性候选查询,以便扩展用户的知识范围的查询视野.因此,本文工作对于目前关键字查询技术的改善具有重要意义.
1 相关工作
关键字查询的研究最早始于信息检索领域(主要针对无结构化的文本数据),后来逐渐扩展到结构化、半结构化以及空间数据.
近年来,有关结构化数据上的关键字查询匹配方法大致可分成4类:1)基于模式图SG的方法,该类方法(如BANKS等)[1-3]把关系数据库看成一个模式图,图中的节点代表元组,边代表元组之间的主外键约束关系.对于一个给定的关键字查询,从图中找出包含全部或部分查询关键字的最小子图作为查询结果.2)基于候选网的方法(如DBXplorer,DISCOVER,IR-Style,SPARK等)[4-6],该类方法首先在每个关系表中找出包含全部或部分给定查询关键字的匹配元组,然后每个关系表中的匹配元组通过主外键约束关系构建多个候选网CNs,在此基础上找出具有最小连接代价的候选网(minimal total joining network of tuples, MTJNT).上述2类方法在理论上都被证明为NP-hard问题,因此需要采用近似方法解决.3)基于元组单元(tuple unit)[11-12]和虚拟文档(virtual document)[13]的方法.基于元组单元的方法首先利用关系之间主外键约束关系构建视图,视图中具有相同主属性值的记录集合视为一个元组单元,元组单元是关键字查询结果的逻辑单位,关键字查询结果就是显式包含查询关键字的多个元组单元集合.虚拟文档与元组单元方法的基本思想类似,都是按主属性值进行元组聚合,区别在于后者使用图模型表示虚拟文档.4)根据查询关键字与元数据之间的对应关系将关键字查询转换成标准的SQL结构化查询[14-16],该类方法首先对数据进行抽样,然后分析查询关键字与元数据以及抽样数据之间的对应关系,据此定义关键字查询转换规则,从而将关键字查询转换成符合用户查询意图的结构化查询语句.
有关XML数据上的关键字查询方法,其基本思想是基于最低公共祖先(lowest common ancestor, LCA)及其扩展方法(如(exclusive LCA, ELCA)[17],(smallest LCA, SLCA)[18],(MLCA-Meaningful LCA)[19]等),该类方法先对XML数据树中的节点进行编码并构建索引,然后查找出XML数据树中显式包含全部(或部分)查询关键字的节点并鉴别出这些节点的LCA,最后将以LCA为根的子树作为结果.关于空间数据的关键字查询,代表性工作如文献[20-21],基本思想是在多维空间中综合考虑兴趣点(point of interests, POI)的位置信息和描述信息与查询点的距离和与查询关键字的相关程度.
现有方法通常在形式上进行查询关键字的全文匹配,而实际上一个查询中的关键字之间具有很强的语义相关性,一个关键字表达的含义会受到其他关键字表达含义的影响,它们合在一起共同表达了用户的查询意图;另一方面,数据库中有些记录虽然没有显式包含查询关键字,但其在内容上可能与查询十分相关,上述查询技术无法检索到这些信息.特别是当用户提出的查询关键字非常具有选择性或它们之间存在矛盾时,很有可能导致空或少量查询结果问题,此时用户希望系统能为其推荐语义相关的候选查询或返回语义相关的近似查询结果.
2 基本概念和解决方案
2.1 基本概念
令D是一个Web数据库,其后台数据库为关系数据库,包含关系表(R1,R2,…,Rn),每个关系表包含ni条元组(t1,t2,…,tni),在此基础上定义关键字查询、查询历史及相关概念.
定义1. 关键字查询.Web数据库D上的关键字查询Q,是一个包含n个查询关键字的序列,即Q=[k1,k2,…,kn],其中每个ki(i∈1,2,…,n)是一个查询关键字,这些关键字的组合表达了用户的查询意图.
查询Q中的每个关键字可以是一个单词或一个短语,取决于如何对关键字查询进行分解.
定义2. 查询历史.Web数据库D上的查询历史表示为W={(U1,Q1,K1),(U2,Q2,K2),…,(Un,Qn,Kn)},其中Ui代表Session ID(一个Session是从用户连接Web数据库开始到断开连接为止,这段期间用户可能会提交多个关键字查询),Qi代表查询ID,Ki代表查询中包含的查询关键字.
为了提高查询历史的数据质量,本文采用如下策略修剪查询历史:1)去除查询结果为空的关键字查询,因为导致空查询结果的查询没有意义;2)由于用户的查询习惯通常是由宽泛到具体,用户通过观察查询结果,逐步改善查询条件,直到返回有意义的查询结果为止,在逐步细化的过程中,最后一个查询通常是最有实际意义的查询,因此保留Session中最后一个查询;3)利用文本分析工具(如AlchemyAPI[22]和Wikipedia[23])对关键字查询进行分解和规范化处理.表1给出了基于DBLP数据集的修剪后的关键字查询集合的例子.
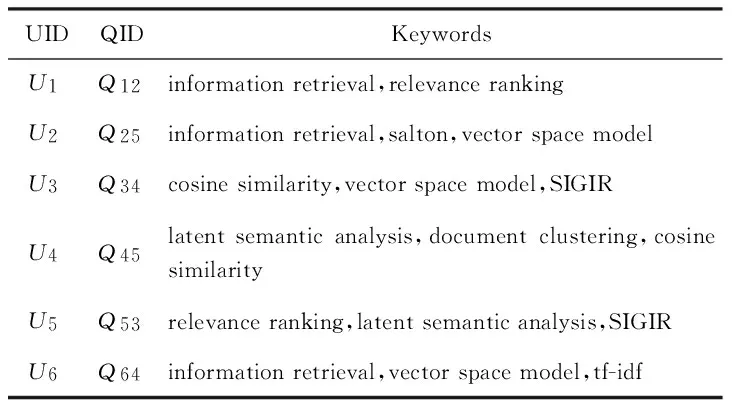
Table 1 An Instance of Pruned Keyword Query表1 DBLP数据集上修剪后的关键字查询集合例子
2.2 解决方案
本文提出的Web数据库top-k多样性关键字查询推荐方法分成2个处理阶段,系统框架如图1所示.
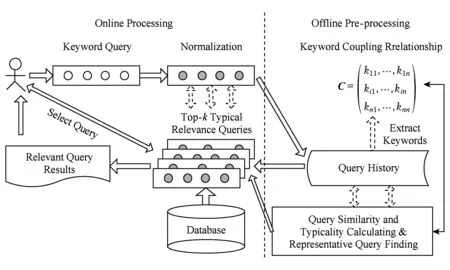
Fig. 1 Framework of top-k diverse keyword query suggestion system图1 top-k多样性关键字查询推荐系统框架
1) 离线阶段.首先在修剪后的查询历史中抽取出所有不同的关键字;然后在查询历史上利用同现频率和关联关系分析方法计算不同关键字之间的耦合关系;根据关键字之间的耦合关系构建语义矩阵,再利用核函数和语义矩阵对查询历史中所有不同的关键字查询进行语义相关度评估.根据查询之间的语义相关度,利用概率密度估计方法分析查询的典型程度,然后使用近似算法获取查询历史中具有较高典型程度的查询,形成典型查询集合.为了提高top-k候选查询选取效率,从典型查询集合中选出少数代表性查询,并为每个代表性查询构建一个序列(序列中的元素是查询历史中除该关键字查询之外的所有典型查询,按其对代表性查询的语义相关度降序排列).
2) 在线处理阶段.当一个关键字查询到来时,先计算该关键字查询与代表性查询之间的语义相似度,然后使用阈值算法(threshold algorithm, TA)在离线阶段创建的序列上快速选取前k个与当前查询语义相关且彼此具有一定差异的查询提供给用户,其中当前查询与代表性查询之间的相似度作为评分函数的一个权重,也就是当前查询与某个代表性查询越接近,那么该代表性查询对应的序列对结果的影响就越大.
3 关键字之间的耦合关系评估
本文结合信息检索领域文献[24]提出的文档-词条相似度评估思想,利用查询历史分析关键字之间的耦合关系,它包括内耦合和间耦合关系.
3.1 关键字之间的内耦合关系评估
在信息检索中,如果2个词条(term)经常共现在相同文档中,则说明这2个词条在一定程度上语义相关.类似地,在本文环境下,每个关键字查询可看成是一个文档(document),查询历史看成是文档集合,查询中的每个关键字看成是一个词条(term),那么如果2个关键字经常在查询历史的相同查询中共同出现,则说明这2个关键字在一定程度上语义相关.因此,给定一对关键字(ki,kj),根据它们在查询历史中的共现频率,其语义相关性可由Jaccard系数[25]进行评估:
J(ki,kj)=
(1)
其中,W(ki)和W(kj)分别代表查询历史中包含关键字ki和kj的查询集合,c是给定阈值.基于式(1),关键字之间的内耦合关系可定义如下:
定义3. 关键字的内耦合关系.如果2个关键字至少在查询历史W的某个查询中共同出现,则它们具有内耦合关系,内耦合关系计算方法如下:
δIaR(ki,kj|W)=J(ki,kj),
(2)
其中,J(ki,kj)如式(1)所定义.
由于ki和kj还可能与其他关键字共现,因此需要对ki和kj之间的内耦合关系进行归一化处理.也就是说对于关键字ki,(ki,kj)的内耦合关系在ki与所有其他关键字内耦合关系中所占的比例.所以,关键字(ki,kj)之间的内耦合关系最终按式(3)计算:
(3)
其中,n代表查询历史W中所有不同关键字的个数.
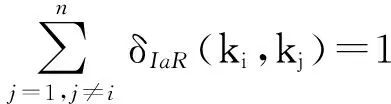
算法1. 关键字内耦合关系评估算法.
输入: 查询历史、关键字集合K、关键字个数n;
输出: 内耦合关系矩阵IaRMatrix.
①IaRMatrix=∅;
② fori=1 ton-1 do
③ fork=i+1 tondo
④IaRMatrix[i][k]=J(K[i],K[k]);
⑤IaRMatrix[k][i]=IaRMatrix[i][k];
⑥ end for
⑦ form=1 tondo
⑧ if (m≠i) then
⑨Sum=Sum+IaRMatrix[i][m];
⑩ end if
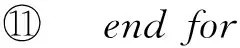



关键字的内耦合关系反映了在查询历史中共现关键字之间的关联关系.除此之外,2个关键字即便没有共现,但是它们之间仍然可能存在间接关联关系.例如,表1中“information retrieval”和“cosine similarity”没有共现,但它们通过共同关键字“vector space model”间接相关,本文将关键字之间的这种关联关系称为间耦合关系.
3.2 关键字之间的间耦合关系评估
给定2个关键字ki和kj,它们在查询历史中没有共现过,但如果与ki和kj同现的关键字集合之间存在交集,则这2个关键字存在间耦合关系.
给定一个关键字ki,所有与其共现的关键字可看做是ki的语义相关词语集合,因此ki和kj的间耦合关系可以通过二者的语义相关词语集合的重合度来评估.例如对于表1中的关键字“vector space model”,其语义相关词语集合包括关键字“information retrieval,salton,cosine similarity,SIGIR”;对于关键字“relevance ranking”,其语义相关词语集合包括“information retrieval,latent semantic analysis,SIGIR”,由此可见,“vector space model”和“relevance ranking”的语义相关词语集合中重叠的关键字为“information retrieval”和“SIGIR”,本文称其为“共同关键字(common keywords)”.在此基础上,ki和kj通过共同关键字kc产生的间耦合关系可定义如下.
定义4. 关键字的间耦合关系.如果在查询历史中至少存在一个关键字,使得δIaR(ki,kc)>0和δIaR(kj,kc)>0成立且ki和kj没有共现,则ki和kj具有间耦合关系,它们通过共同关键字kc产生的间耦合关系计算方法为
δIeR(ki,kj|kc)=min{δIaR(ki,kc),δIaR(kj,kc)},
(4)
其中,δIaR(ki,kc)和δIaR(kj,kc)分别代表ki和kc,kj和kc的内耦合关系.
需要指出的是,ki和kj之间通常会存在多个共同关键字,并且每个共同关键字在查询历史中会有不同重要性.因此,需要评估每个共同关键字的权重.权重评估的基本思想是在查询历史中出现次数越多的关键字具有越高权重,因为出现次数越多代表用户查询该关键字的次数越多,因此也就说明其越受用户关注.令QF(ki)代表关键字ki在查询历史中出现的次数,QFMax代表查询历史中最频繁出现的关键字的出现次数,关键字的权重:
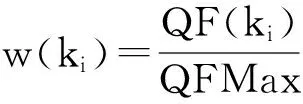
(5)
由于ki和kj的共同关键字可能有多个,令S代表ki和kj的共同关键字集合,即S={kc|(δIaR(ki,kc)>0(δIaR(kj,kc)>0)}.关键字ki和kj通过S中所有共同关键字产生的间耦合关系为
(6)
其中,w(kc)由式(5)计算,δIeR(ki,kj|kc)代表ki和kj通过共同关键字kc产生的间耦合关系.如果ki和kj的共同关键字多于一个,则式(6)表示的是取ki和kj通过这些共同关键字产生的间耦合关系的平均值.如果S=∅,则δIeR(ki,kj)=0.关键字耦合关系评估算法如算法2所示.
算法2. 关键字间耦合关系评估算法.
输入: 关键字集合K、K中的关键字个数n、内耦合关系矩阵IaRMatrix、关键字权重;
输出: 间耦合关系矩阵IeRMatrix.
①IeRMatrix=∅;
② fori=1 ton-1 do
③ forj=1 tondo
④S←K[i]和K[j]的所有共同关键字;
⑤m=|S|;
⑥ if (S=∅) then
⑦IeRMatrix[i][j]=0;
⑧ else
⑨ fork=1 tomdo
⑩minvalue=min{δIaR(K[i],S[k]),δIaR(K[j],S[k])};
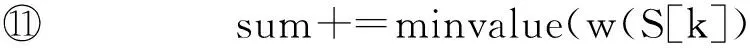

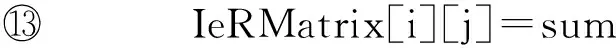
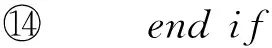
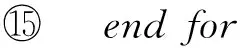

3.3 关键字之间的耦合关系评估
给定2个关键字ki和kj,它们之间的耦合关系是内耦合关系和间耦合关系的结合,计算方法如下:
(7)
其中,α∈[0,1]是一个参数,用来调节内耦合关系和间耦合关系在耦合关系计算中所起的作用.耦合关系值越大,说明2个关键字之间的语义相关性越强.需要说明的是,如果α=0,则式(7)将转化成内耦合关系;如果α=1,则式(7)将转化成间耦合关系.
图2给出了从表1中抽取出的所有不同关键字的耦合关系度.这里将式(7)中设定α=0.5,表示内耦合关系和间耦合关系在关键字耦合关系评估中起同等作用.
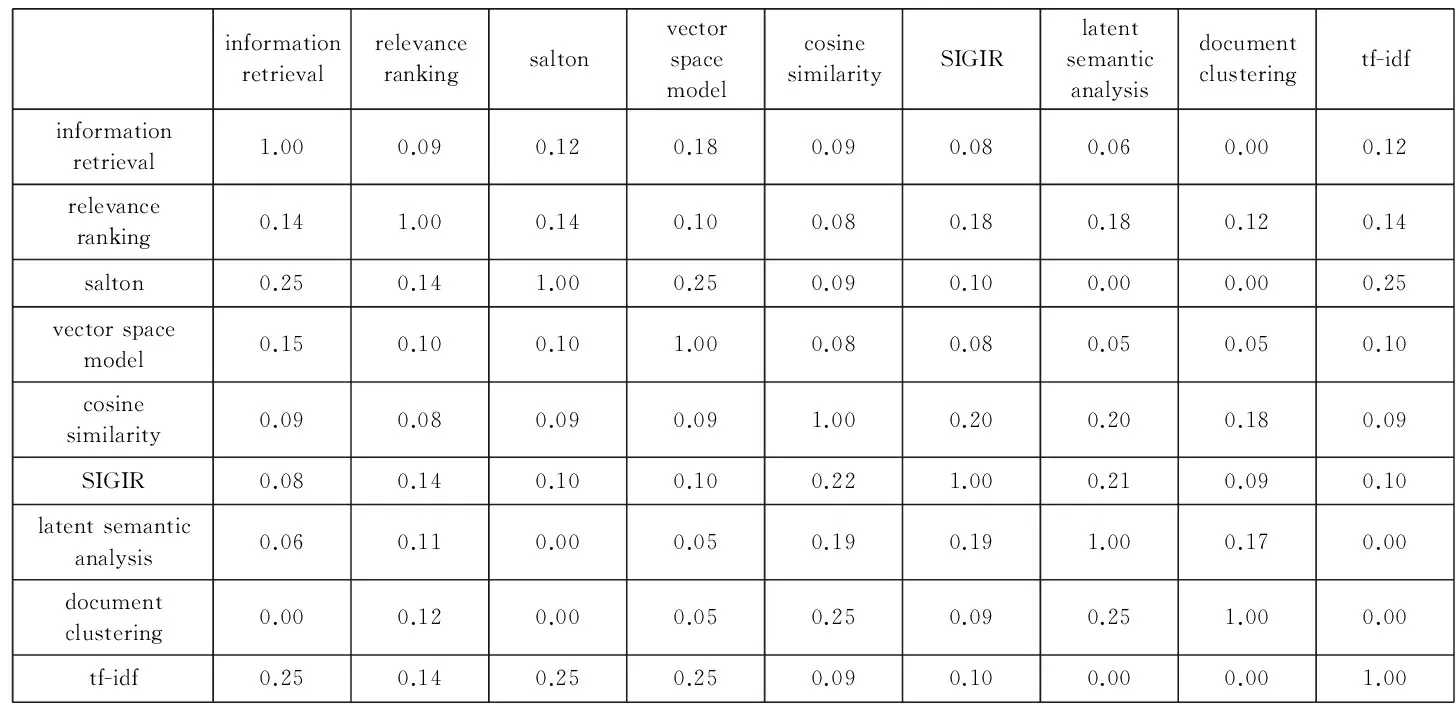
informationretrievalrelevancerankingsaltonvectorspacemodelcosinesimilaritySIGIRlatentsemanticanalysisdocumentclusteringtf-idfinformationretrieval1.000.090.120.180.090.080.060.000.12relevanceranking0.141.000.140.100.080.180.180.120.14salton0.250.141.000.250.090.100.000.000.25vectorspacemodel0.150.100.101.000.080.080.050.050.10cosinesimilarity0.090.080.090.091.000.200.200.180.09SIGIR0.080.140.100.100.221.000.210.090.10latentsemanticanalysis0.060.110.000.050.190.191.000.170.00documentclustering0.000.120.000.050.250.090.251.000.00tf-idf0.250.140.250.250.090.100.000.001.00

Fig. 2 Example of coupling relationship matrix of keywords
图2 关键字耦合关系矩阵实例
从图2可以看出,同时考虑内耦合关系和间耦合关系的关键字耦合关系更为合理.例如对于表1中的2个关键字“relevance ranking”和“cosine similarity”,如果仅考虑内耦合关系,这2个关键字之间的关系为0;但实际上,这2个关键字在语义上十分相关,这种相关性可由间耦合关系捕获到.因此,这2个关键字的耦合关系最终并不是0.本文将关键字之间的耦合关系存入耦合关系表中,表结构为{关键字1,关键字2,耦合关系度},并在(关键字1,关键字2)上构建索引,以便提高检索效率,进而缩短构建语义矩阵(将在4.1节描述)的时间.
4 语义相关度计算与典型程度分析
4.1 关键字查询之间的语义相关度计算
在信息检索领域,cosine相似度是基于向量空间模型(vector space model, VSM)的一种常用相似度评估方法.在本文中,查询历史可看成是文档集合,每个查询看成是一个文档每个关键字就是文档中的一个词条.因此,可以使用cosine相似度进行关键字查询之间的语义相关度计算.计算方法可分为3个步骤:
1) 将关键字查询转换成向量表示
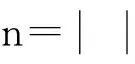
对于给定的一对关键字查询,其中每个关键字查询的向量表示都是一个包含n个元素的二元向量VQ,向量VQ中的第i个元素对应K中的关键字K[i].如果查询中存在一个关键字与K[i]对应,那么VQ[i]=1;否则VQ[i]=0.
例如给定表1中的一对关键字查询Q34和Q45,它们共包含5个不同的关键字.假设关键字的顺序为cosine similarity,vector space model,SIGIR,latent semantic analysis,document clustering.基于该顺序和上述构建向量空间模型的方法,查询Q34和Q45可以分别用向量[1 1 1 0 0]和[1 0 0 1 1]表示.
2) 构建语义矩阵
给定一对查询,假设K是这2个查询中的所有关键字集合,n为K中的关键字个数.根据关键字之间的耦合关系,K中所有关键字可以形成一个n×n阶的语义矩阵SK,每一个元素SK(i,j)代表关键字ki和kj的耦合关系,这些值可以从3.3节描述的关键字耦合关系表中快速检索到.
3) 计算关键字查询之间的语义相关度
在计算查询之间语义相关度过程中,为了保留住关键字之间的耦合关系,利用步骤2构建的语义矩阵将每个查询对应的向量转换成一个新的向量Q′=Q′SK,该向量体现了关键字之间的耦合关系信息.根据文献[26],2个转换后的向量所对应的核函数可以写成:
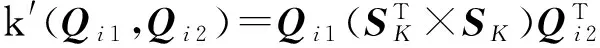
(8)
核方法的基本思想是将低维空间中的非线性可分问题映射到高维空间使其变的线性可分,并利用高维空间中映射函数的内积对低维空间的问题进行分类.其关键在于找到输入的低维空间到高维空间的映射方法.核函数的作用是接受2个低维空间的向量输入,无需寻找从低维空间到高维空间的具体映射,就能够计算出经过某个变换后在高维空间里的向量内积值[27].高维空间中的映射函数的内积反映了2个输入数据之间的距离,也就是相似(或相关)性.2个关键字查询的相似性问题是一个在低维空间中的非线性可分问题,因此本文首先将2个查询转换成相应的向量表示,作为核函数的输入,然后利用核函数来评估两查询之间的相似性,核函数中的语义矩阵SK保留了关键字之间的耦合关系.最后,根据cosine相似度评估思想,2个查询基于核函数的cosine相似度可定义为
δsim(Qi1,Qi2)=cosker(Qi1,Qi2)=
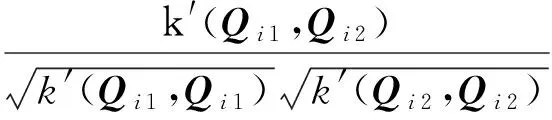
(9)
查询历史中所有不同查询之间的语义相关度都可以通过式(9)计算得到.使用基于VSM模型的cosine相似度(简称为V-COS)和基于核方法的cosine相似度(简称为K-COS)计算得到的不同查询之间的语义相关度分别如图3和图4所示:
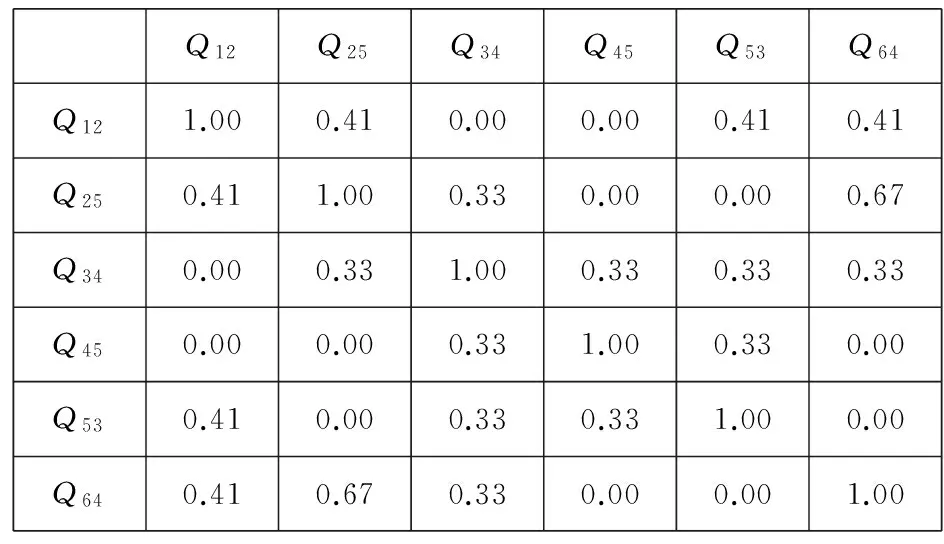
Q12Q25Q34Q45Q53Q64Q121.000.410.000.000.410.41Q250.411.000.330.000.000.67Q340.000.331.000.330.330.33Q450.000.000.331.000.330.00Q530.410.000.330.331.000.00Q640.410.670.330.000.001.00
Fig. 3 Matrix of query similarities obtained by V-COS
图3 V-COS方法得到的相关度矩阵
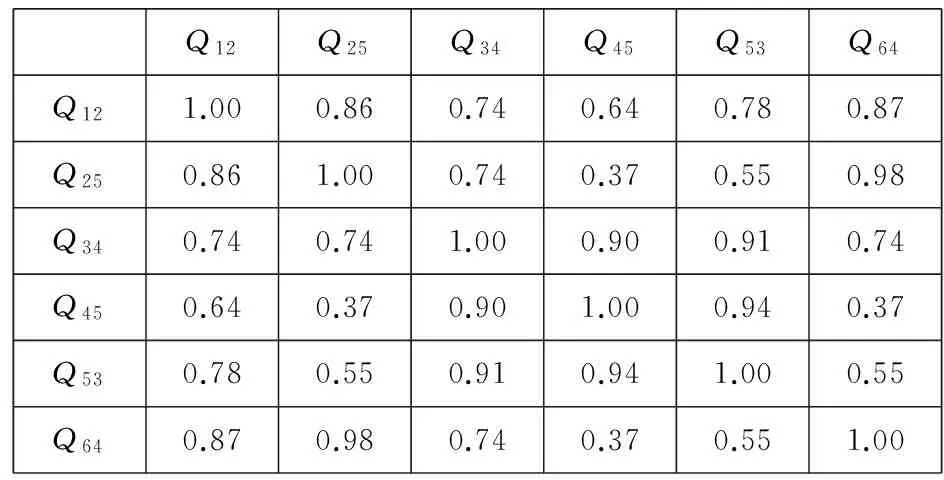
Q12Q25Q34Q45Q53Q64Q121.000.860.740.640.780.87Q250.861.000.740.370.550.98Q340.740.741.000.900.910.74Q450.640.370.901.000.940.37Q530.780.550.910.941.000.55Q640.870.980.740.370.551.00
Fig. 4 Matrix of query similarities obtained by K-COS
图4 K-COS方法得到的相关度矩阵
从图3和图4可以看出,由K-COS算法得到的查询之间的语义相关度的区分度明显优于V-COS算法.例如在图3中,查询Q12与Q25,Q53,Q64的相关度都是0.41,查询Q34与Q25,Q45,Q53的相关度都是0.33;而在图4中这些值都不相同,并且更贴近实际.
4.2 关键字查询的典型程度分析
为给用户提供多样性候选查询,需要分析查询历史中每条查询的典型程度,然后保留具有top-k个较高典型程度的查询作为多样性候选查询.
聚类分析与本文所提的典型程度分析具有一定相关性,聚类分析是将集合中的对象划分成若干类别,使同一类别中对象之间的相似度尽可能大,不同类别对象之间的相似度尽可能小[28].需要指出的是,典型化分析和聚类分析的目标不同,聚类分析是将对象划分到不同类别,而典型化分析是要找出代表性对象.一些研究工作把均值点(means)或中心点(medoids)作为一个聚类的代表[29],然而有时均值点或中心点可能并不是聚类中的代表.如图5所示,对象B和C分别是集合的均值点和中心点,但分布在A周围的对象要比B和C的多,因此A要比B和C更具有代表性.
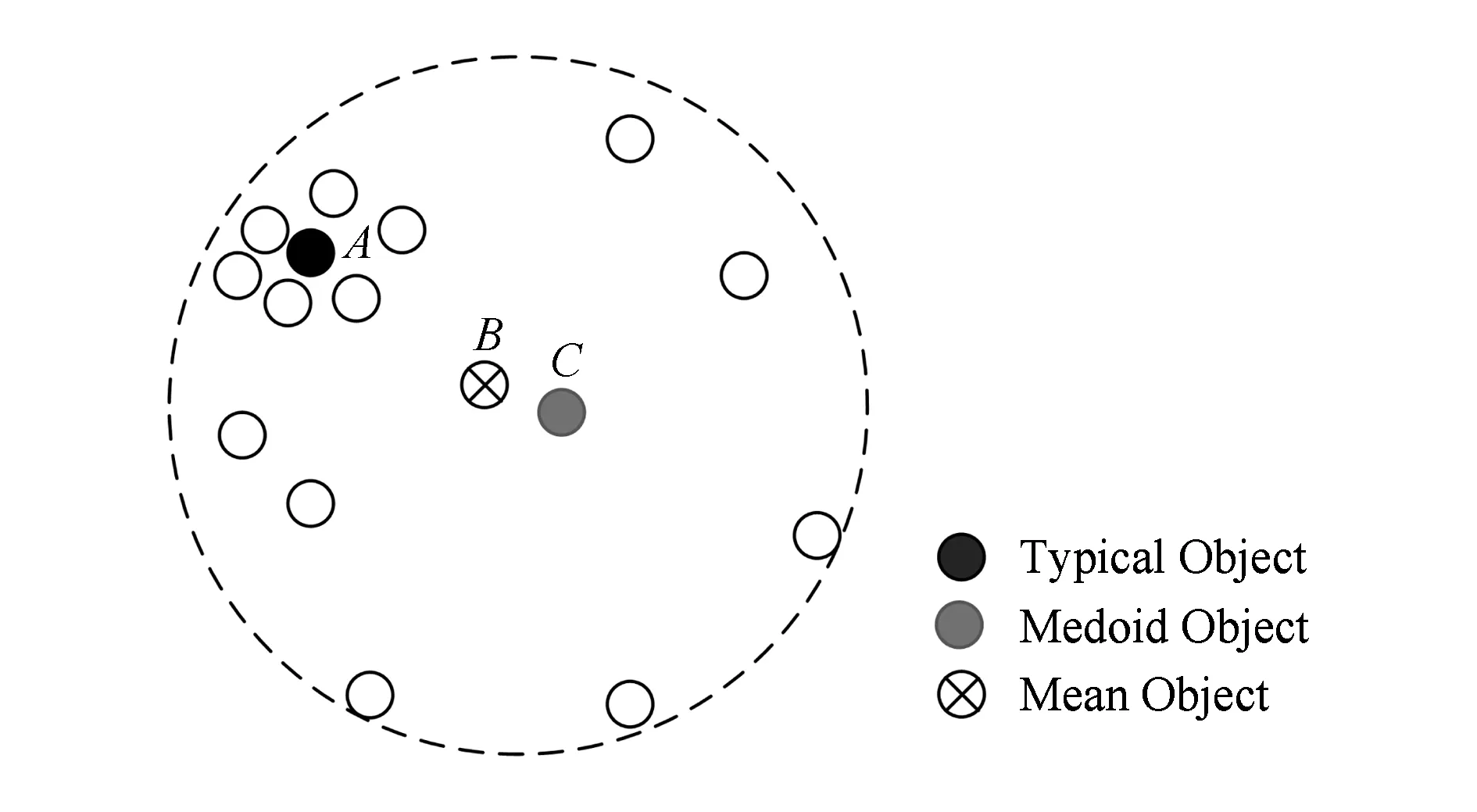
Fig. 5 Difference of medoids,means and typical object图5 中心点、均值点和典型点对象的区别
本文提出利用概率密度函数计算查询的典型程度,概率密度越大的查询典型程度越高,也说明其越具有代表性.概率密度是分析集合中某个对象典型程度的核心方法,其基本思想是,给定一个满足独立同分布的点集合S和其中一个点o,点o的典型程度与其他点在S中的分布情况有关,如果点o周围的点越密集,则o的概率密度越大,那么点o就越具有代表性.根据查询之间的语义相关度,可以将查询历史中的所有查询看成是一个空间中的点集合,其中每个点代表一个查询,点与点之间的直线距离代表一对查询之间的语义距离.这样就可以用概率密度估计方法来评估一个查询历史中查询的典型程.本文采用基于核函数的概率密度估计方法,核函数采用常用的高斯核函数,因为该方法能在数据分布未知情况下有效进行概率密度评估[30].
基于上述概率密度分析方法,对于查询历史W,其中一条查询q∈W的典型程度定义为
P(q,W)=f(q|W),
f(q|W)是W上的概率密度分布函数:
(10)
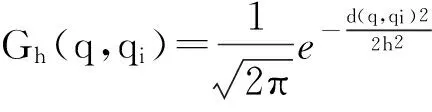
给定查询历史W(包含n条查询)和所有查询之间的语义距离,我们的目标是保留其中m(m≪n)条具有较高典型程度的查询.根据式(10),每计算一条查询的典型程度都需要遍历W中所有查询对其的贡献度,则该算法的时间复杂度为O(n2).当n很大时,算法需要耗费很多时间,因此需要考虑一种的近似解法,本文解决方法的基本思想是:先把查询历史W随机划分成若干小组,每个小组包含u条查询,这样可将W划分成nu个小组,然后计算每个小组内所有查询的典型程度并从中选取一个具有最高典型程度的查询,这些查询构成一个新的集合,最后从W中去除其他查询.对于得到的新集合,重复执行上述过程,直到集合W中只剩下一条查询为止,将该查询放入候选集中(上述过程记为一次选取过程).为了尽可能确保选取的准确性,将上述选取过程重复执行v次(记为一轮),这样候选集中最多存储v条查询,然后在最初的查询历史W上计算这v条查询的典型程度,最后输出一条具有最高典型程度的查询作为当前轮次的选取结果,并从W中去除该查询.上述整个过程重复m轮,这样就能找到m个近似于准确解的查询.
算法3. 典型查询的近似选取算法.
输入: 查询历史W、验证次数v、正整数m、小组大小u;
输出:m条典型查询.
① fori=1 tomdo
② fori=1 tovdo
③ repeat
④ 划分W成为若干小组g,每个小组有u条查询;
⑤ for each 小组gdo
⑥ 计算g中每个查询在g的典型程度;
⑦ 从g中选出最典型的查询,并将g中其他查询从W中移除;
⑧ end for
⑨ untilW中仅有一条查询
⑩ 把得到的最典型查询放入候选集合中;


算法3的复杂度分析:计算每个小组中所有查询典型程度的时间复杂度为O(u2),每次选取过程要进行l=logun次小组划分.假设n=ul,在每次选取过程中,第1次划分可得到nu个小组,第2次划分可得到(nu)u=nu2个小组,以此类推,这样每次选取过程总共划分的小组数将有个,所以每次选取过程找到最典型查询的复杂度是=O(un),又因为每次淘汰有v次验证,并且整个淘汰过程循环m次,因此该算法的时间复杂度是O(mvun),其中m,v,u都是比n小很多的正整数.由此可见,该近似选取算法的时间复杂度要明显低于准确选取算法.
5 候选查询的top-k多样性选取
令Q是一个关键字查询,T是典型查询集合.根据查询之间的语义相关度,从T中选取与给定查询语义相关的前k个多样性查询,该问题定义为
(11)
top-k候选查询选取方法可分成3个处理步骤:1)选择代表性查询;2)为代表性查询创建序列;3)在线计算当前关键字查询与代表性查询之间的语义相似度,利用TA算法在查询序列上选取前k个语义相关的典型查询.
5.1 选取代表性查询
算法4. 代表性查询选取算法.
输入: 典型查询集合T={Q1,Q2,…,Qm};
①Tl≠∅;
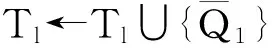
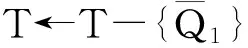
⑤ for alli=2 toldo
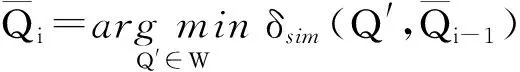
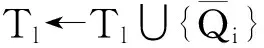
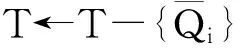
⑨ end for
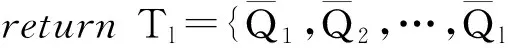
5.2 创建代表性序列
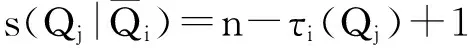
(12)
其中,τi(Qj)代表查询Qj在序列τi中的位置.
5.3 候选查询的top-k选取
在代表性查询序列上,利用TA算法[31]选取前k个相关的典型查询.TA算法通过顺序访问方式发现每个序列中的某个查询的排序分数,然后利用随机访问方式从其他序列中发现该查询的排序分数,这些分数之和作为该查询在所有序列中的总分数(总分数是以该查询与与其对应的代表性查询之间的相似度作为权重系数,进行加权求和),定义为
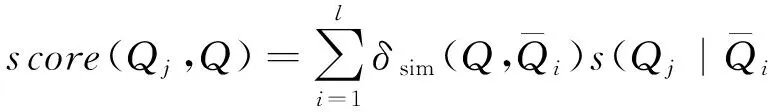
(13)
算法5. 候选查询的top-k选取算法.
输入: 代表性序列Tl={τ1,τ2,…,τl}、给定的关键字查询Q、top-k中的k值;
输出: top-k个候选查询.
① 令B={}是能存储k个关键字查询的内存空间;
② 令L是个一个大小为l的数组,它用于存储来自每个序列中的最近一次检索得到的分数;
③ repeat
④ for alli∈{1,2,…,l} do
⑤ 从τi中检索下一个Qj;
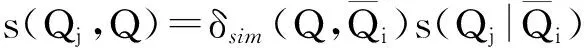
⑦ 用Qj在τi中的分数更新L;
⑧ 通过随机访问方式,获取Qj在其他序列中的分数;
⑩score(Qj,Q)←所有检索到的分数加权 求和;

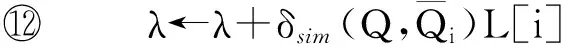

6 性能实验评价
本节描述实验环境,测试各算法性能并与相关算法进行比较,报告实验结果.
6.1 实验环境
实验测试机器配置为Intel PⅣ主频3.2 GHz处理器、内存8 GB.所有算法使用C#和SQL实现.实验数据使用2个测试数据集:
1) DBLP数据集.该数据集包含了4个关系表,分别是Authors,Papers,Write,Proceedings表.它们之间通过主外键约束关系相连接,数据库模式如图6所示:
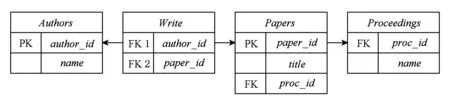
Fig. 6 The DBLP schema (PK refers to primary key and FK refers to foreign key)图6 DBLP数据集模式图(PK代表主键、FK代表外键)
本文构建了基于DBLP数据集的Web查询系统,用户可通过查询接口提交查询.利用该系统征集多个不同研究领域(数据库、数据挖掘、信息检索、机器学习、图形图像等)的研究人员提交关键字查询,通过观察查询历史可以发现,用户通常在一个Session中提交3~5个查询,并且查询条件逐步从宽泛到具体.总共收集5 000条用户查询,利用本文第3节提出的查询修剪策略,最终保留2 385条查询作为查询历史.查询关键字涉及Authors.name,Papers.title,Proceedings.name等属性.由于这些查询都是由具有专业背景的研究人员提出的查询,这些关键字大部分都具有较强的内耦合和间耦合关系,因此基于DBLP的查询历史非常适合关键字之间的耦合关系分析和关键字查询的语义相关度评估实验.
2) IMDB(Internet movie database):该数据集包含了5个关系表,分别是Actors,Roles,Movies,Movie_diretors,Directors表.它们之间通过主外键约束关系相连接,数据库模式如图7所示:
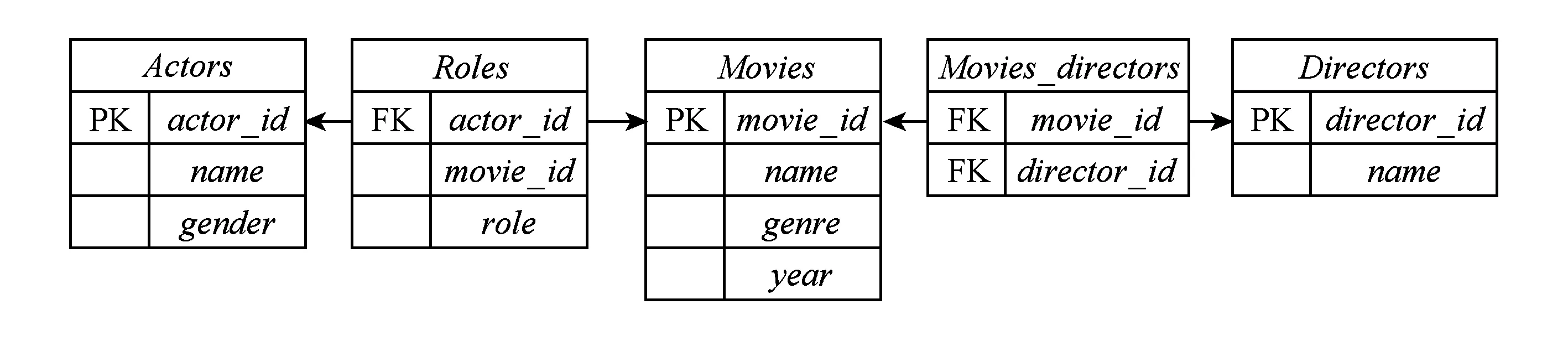
Fig. 7 The IMDB schema(PK refers to primary key and FK refers to foreign key)图7 IMDB模式图(PK代表主键、FK代表外键)
由于很难收集到该数据集上的真实查询历史,本文利用策略模拟查询历史:1)根据数据库模式构建视图,视图中的每条记录都是由具有主外键约束关系的元组连接构成;2)随机从视图中选取10 000条记录,并从每条记录的Movies.name,Actors.name,Movies.genre,Roles.role,Directors.name等属性中抽取关键字;3)从每条记录已抽取的关键字集合中随机抽取若干个关键字作为一个关键字查询.实质上,在该方法构建的查询历史上进行分析,得到的是IMDB数据库中所包含关键字之间的耦合关系.也就是说,当查询历史缺失情况下,可以通过从数据库中进行抽样分析得到关键字之间的耦合关系,进而实现关键字查询的相关推荐.
6.2 关键字耦合关系的准确性测试
为了测试提出的关键字之间耦合关系评估方法的准确性,本文在DBLP和IMDB的查询历史上分别随机选取10个关键字.对于每个关键字ki,利用式(7),将α值从0~1以0.1步长方法进行调节,取每个α值对应的前5个与当前关键字最为相关的关键字,将这些关键字合起来形成一个关键字集合Ki,即该集合中共有55个关键字(其中有一部分是重复的关键字).然后,统计集合Ki中出现频率最高的前5个关键字作为与ki语义上最为相关的关键字.因为在集合Ki中出现的频率越高,说明该关键字与给定关键字ki的相关程度越高.
本文使用查全率(Recall)和准确率(Precision)评价不同α值下关键字之间耦合关系的准确性.查全率是指检索到的相关关键字个数与相关关键字总数之比;准确率是指检索到的相关关键字个数与检索到的关键字总数之比.因为相关关键字个数和检索到的关键字个数都是5,因此查全率和准确率相等.图8给出了DBLP和IMDB数据集上不同α值所对应的关键字耦合关系的准确性(即查全率和准确率),这里取10个关键字对应准确性的平均值.本实验把式(1)中的阈值c设为2,因为该值能降低仅共现1次的词对对内耦合关系评估的影响.
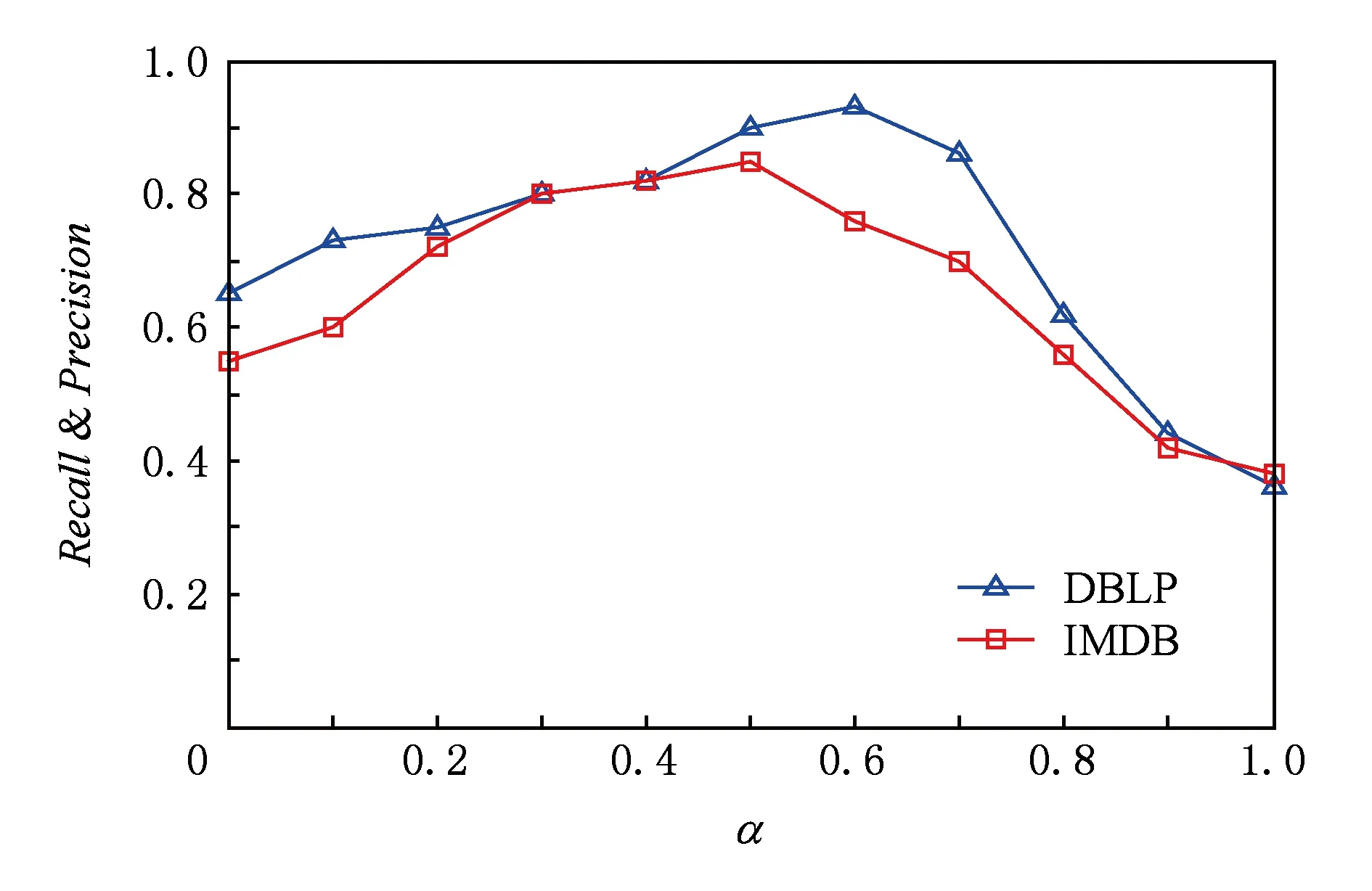
Fig. 8 Accuracy of answers for different values of α on DBLP and IMDB datasets图8 DBLP和IMDB上不同α值对应的准确性
从图8可以看出,当α分别取0.6和0.5时,DBLP和IMDB上的准确性达到了最高值,分别是0.93(DBLP)和0.85(IMDB).由于DBLP上的是真实查询历史,关键字之间具有较强的耦合关系,因此准确性较高;而IMDB的查询历史是从原始数据中抽样得到,关键字之间的耦合关系相对较弱,但是准确性也不低,因此本文方法也适用于原始数据中关键字之间的耦合关系评估.
此外,还可看到对于DBLP数据集,α值取从0到0.6时,准确性曲线逐渐上升,说明关键字的间耦合关系对于准确性的提高具有积极作用;而当α值取从0.6~1时,准确性曲线逐渐下降,说明关键字的间耦合关系对于准确性的提高起到了消极作用.表2给出了当α分别取值0,0.6(DBLP)0.5(IMDB),1时,在DBLP和IMDB上对于给定关键字“association rules”(DBLP)和“Hugh Jackman”(IMDB)的前5个语义相关关键字.

Table 2 top-5 Relevant Keywords for Different Given Keyword over DBLP and IMDB表2 DBLP和IMDB上与给定关键字相关的前5个关键字
6.3 关键字查询语义相关度的用户调查
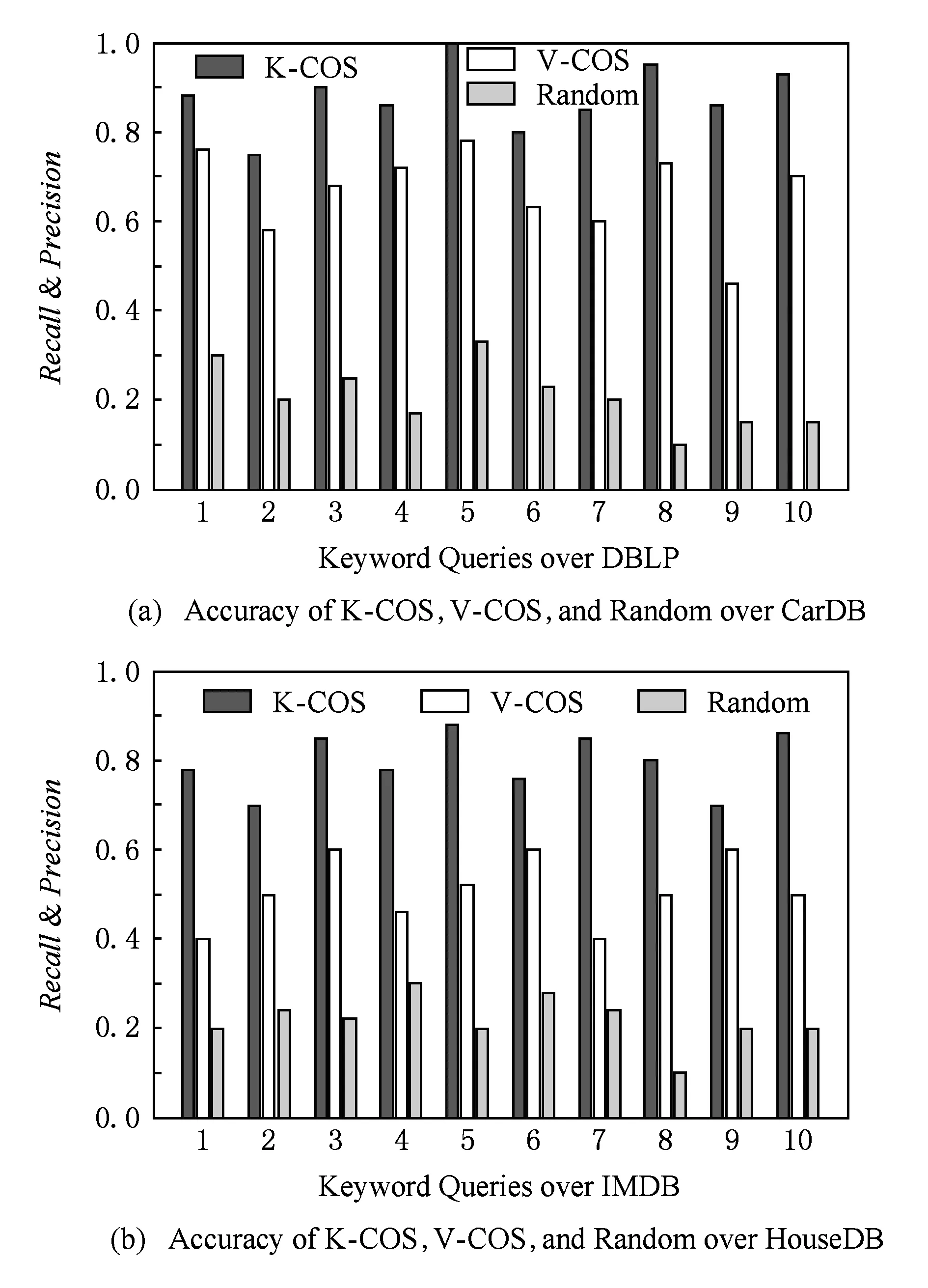
Fig. 9 Comparison of accuracy for K-COS,V-COS, and Random over DBLP and IMDB图9 DBLP和IMDB上K-COS,V-COS,Random方法的准确性对比
本文使用用户调查方法测试提出的关键字查询语义相关度评估方法的准确性.我们首先邀请了10个用户(博士研究生、硕士研究生和年轻教师)从DBLP和IMDB中各选取10个查询(每个用户在每个数据集上选取1个查询).对于每个选取的查询Qi,利用K-COS,V-COS,Random方法从查询历史中获得前10个相关查询,最终合成一个包含30个与给定查询Qi相关和不相关的查询集合Ki.K-COS和V-COS是本文第4节提到的方法,Random是随机选取方法(也就是从查询历史中随机选取10个查询,该方法作为效果对比的一个基线).在此基础上,我们把Ki和Qi提供给用户,由用户从Ki中标出前10个与Qi相关的查询,并且从2方面说明相关查询Q′与给定查询Q的相关性:
1) 查询Q′与Q中有部分重叠的查询关键字,则二者相关;
2) 查询Q′与Q包含的关键字之间没有重叠,但查询结果有重叠,则二者也可认为是相关的.例如,查询“cosine similarity,vector space model”与查询“latent semantic analysis,document clustering”的查询结果之间有部分重叠,说明二者具有语义相关性,但二者并不包含相同的关键字.
本文用检索到的相关查询个数与用户标注的相关查询总数之比来衡量不同关键字查询语义相关度评估算法的准确性.图9给出了在DBLP和IMDB上V-COS,K-COS,Random方法的准确性对比.
从图9可以看出,K-COS方法的准确性高于V-COS方法.K-COS在DBLP和IMDB上的平均准确性分别为0.88和0.79,而V-COS在DBLP和IMDB上的平均准确性分别为0.66和0.52.这是因为V-COS是在传统向量空间模型上计算相关度,仅考虑2个查询中形式上相同的关键字,没有考虑关键字之间的耦合关系;而K-COS同时考虑了查询之间形式上和语义上的相关性.因此,得到的语义相关度更为准确合理.
6.4 多样性选取的准确性与合理性测试
该实验目的是测试本文提出的候选查询top-k选取方法的准确性与合理性.为了从查询历史中获取前k个与给定关键字查询最为相关的典型查询,最准确的方法是计算给定查询与典型查询集合中所有查询之间的语义相关度,然后再按语义相关度大小选取出top-k个候选查询.由于本文在选取代表性查询基础上提出了一种快速top-k选取方法,因此需要验证仅在代表性查询排列基础上选出的top-k个候选查询与上述方法选取的top-k个候选查询之间的重叠程度.这里用R(All,k)表示通过计算给定查询与典型查询集合中所有查询之间的相关度之后选出的top-k个相关查询;R(Rep,k)表示利用TA算法在代表性查询序列上获取的top-k个相关查询.这2个集合之间的重叠程度用Jaccard系数评估:
J(R(Rep,k),R(All,k))=
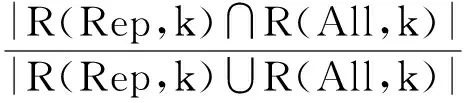
(14)
Jaccard系数的值在[0,1]之间,该值越高,表明重叠程度越高,则top-k选取算法的准确性也就越高.在该实验中,使用3个参数描述测试数据集:m,l,k,其中,m是指每个代表性查询序列中的查询个数(为了能够进行准确性评价,本文把数据集中的所有查询看作是典型查询,因此对于DBLP数据集设置m=2 385,对于IMDB数据集设置m=10 000),l是代表性查询序列个数,k为选取的k个相关查询个数.图10给出了在DBLP和IMDB数据集上不同
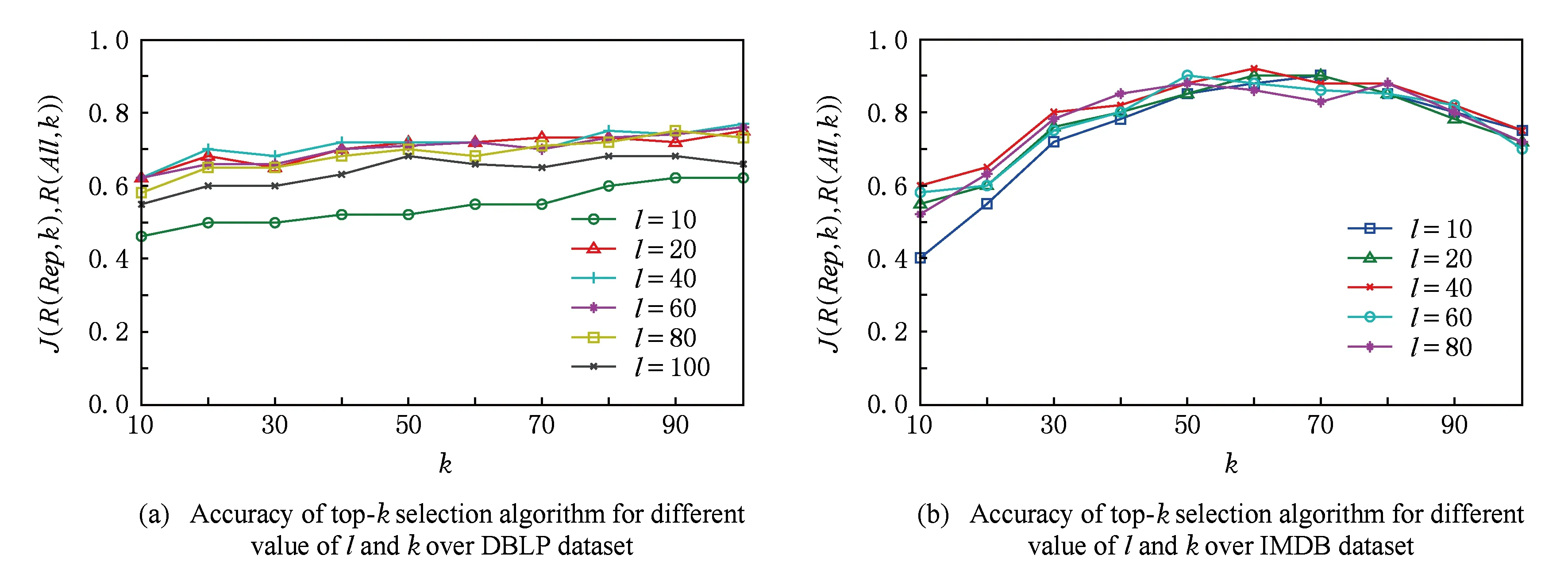
Fig. 10 Accuracy of top-k selection algorithm for different value of l and k图10 不同l和k值下top-k选取算法的准确性
l和k值下top-k选取算法的准确性,其中l={10,20,40,60,80},k={10,20,30,40,50,60,70,80,90,100}.
从图10可以看出,在相同数据集的不同l值下,top-k选取算法的准确性相差不大(除IMDB的l=10以外),这说明仅在少数代表性查询序列上选取top-k个候选查询,其信息丢失程度也很少.同时,还可以看出在DBLP和IMDB上,当代表性查询个数l≥20时,算法准确性趋于稳定,因此这也为代表性查询个数l值的选取提供了依据.此外还可看出,在不同k值下,top-k选取算法的准确性随着k值增大而有所提高,但即便在k值很小的情况下,top-k选取算法准确性也并不低.k值选取方法可以根据用户个人需求而定,系统默认值为k=10,也就是默认为用户提供前10个最为相似的推荐查询.
下面的实例说明了本文提出的候选查询top-k多样性选取方法的合理性.对于给定的查询,分别利用文献[10]提出的基于相似度的top-k选取方法(similarity-based top-kselection)和本文提出的top-k多样性选取方法(top-kdiverse selection)获取前k个相关查询,然后观察这些查询之间的语义相关性和差异性.对于给定查询,表3给出了2种方法返回的结果对比.可以看出,基于相似度的top-k选取方法返回的结果彼此之间非常相似,查询之间的关键词重叠度比较高;而本文提出的top-k多样性选取方法得到的结果既与给定查询语义相关,但彼此之间又有一定差异,从而能够有效扩展用户的知识范围和查询视野.
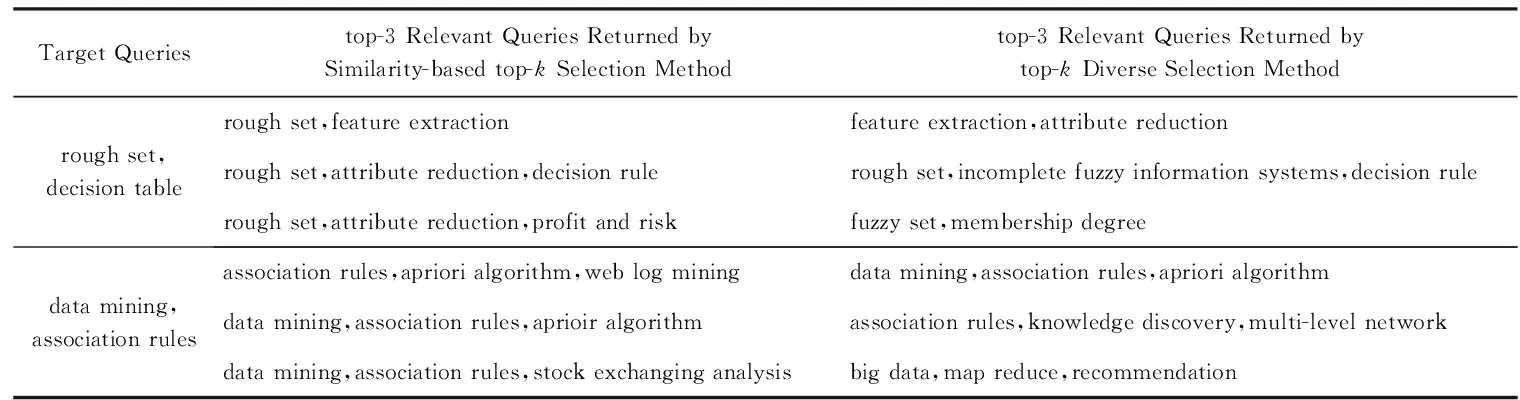
Table 3 The Comparison of top-3 Relevant Queries Obtained by Different Methods表3 由不同方法获得的top-3个相关查询对比
6.5 top-k选取算法的响应时间测试
该实验目的是测试本文提出的top-k选取算法的响应时间.在该实验中,将代表性排列的个数l值分别固定为10,20,40,60,80,然后测试不同k值下top-k选取算法的响应时间,如图11所示.
从图11可以看出,top-k选取算法的响应时间很快,如果仅返回前10个候选查询(在实际应用中,返回前10个候选查询基本能满足用户需求),代表性排列数l为20时(文献[10]已经验证了当代表性排列数不低于20时,top-k选取方法就能具有较高的准确性),所需时间不会超过5 s.本文还测试了计算给定查询与典型查询集合中所有查询之间相关度的时间,该时间在DBLP和IMDB数据集上分别为50 s和300 s左右,也就是说不用本文提出的top-k选取方法,获取前k个查询需要的时间会很长.因此,本文方法在响应时间上具有明显优势.此外,从图中还可以看出算法的响应时间随着l和k值的增加而逐渐增长,其原因是当l和k值增加后,算法需处理的查询个数增多,因此导致响应时间增加.
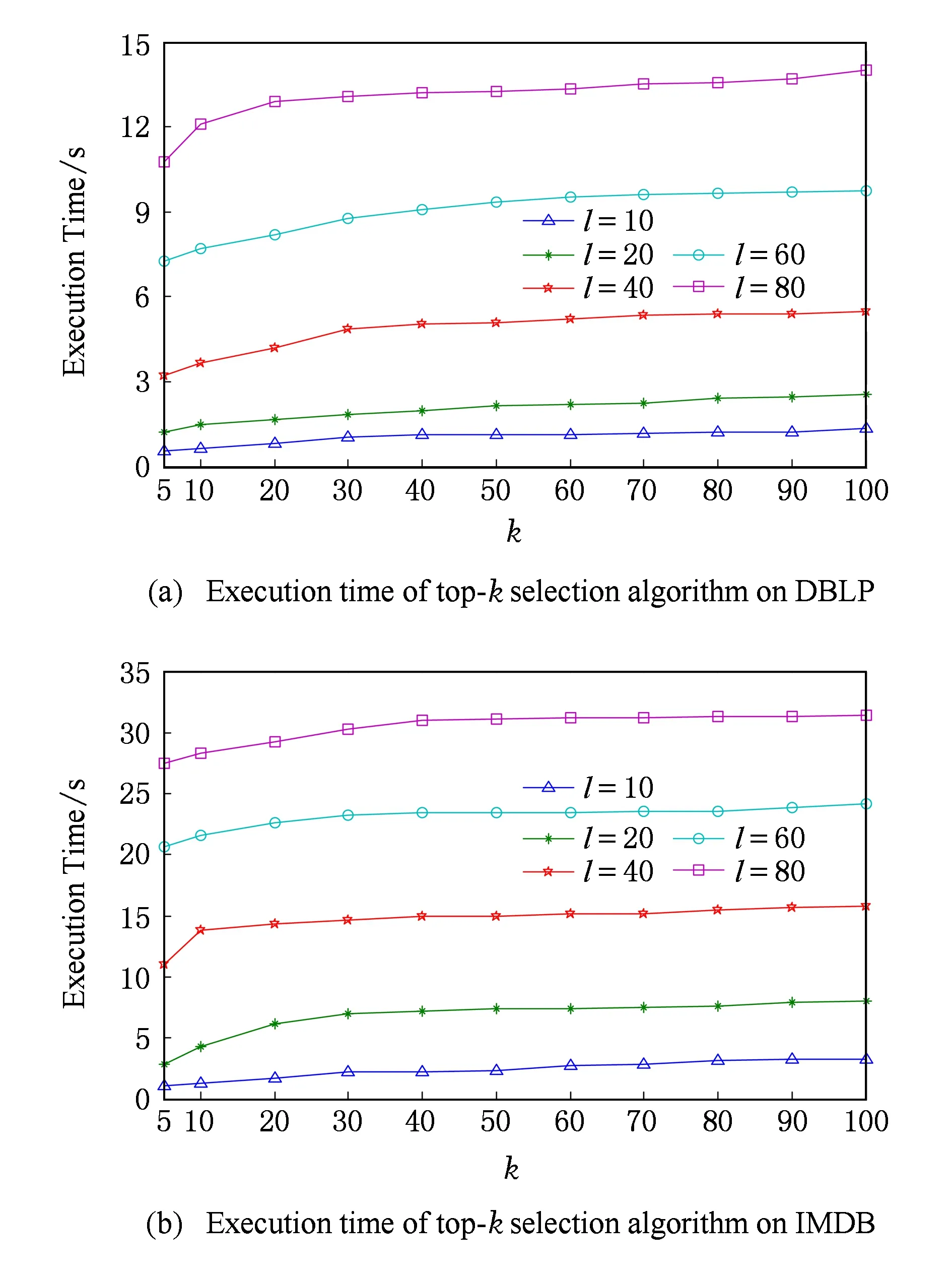
Fig. 11 Execution time of top-k selection algorithm for different value of l and k over DBLP and IMDB datasets图11 DBLP和IMDB上不同l和k值下top-k查询选取算法的响应时间
7 总 结
本文提出了一种基于关键字之间耦合关系的Web数据库top-k多样性关键字查询推荐技术.该方法的基本思想是从查询历史中选取与给定查询语义相关且多样性的查询返回给用户,用户根据返回的top-k个多样性候选查询,1)可以重新修改初始查询,使其更加完善;2)可以直接执行候选查询查看相关结果.
实验结果和分析表明,提出的关键字耦合关系和关键字查询语义相关度评估方法具有较高的准确性,提出的top-k多样性查询选取方法能够有效扩展用户知识范围和查询视野,并且在响应时间方面具有绝对优势,特别适用于大规模数据的检索.本文所提方法既可以作为应用层独立运行,又可以集成在现有关键字查询系统中提供语义近似查询服务.如何根据推荐的top-k个多样性候选查询获得更为细致的查询结果是未来研究工作.
[1]Aditya B, Bhalotia G, Chakrabarti S, et al. Banks: Browsing and keyword searching in relational databases[C]Proc of the 28th Int Conf on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann, 2002: 1083-1086
[2]Tata S, Lohman G M. SQAK: Doing more with keywords[C]Proc of the 2008 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2008: 889-902
[3]Ding Bolin, Yu J, Wang Shan, et al. Finding top-kmin-cost connected trees in databases[C]Proc of the 23rd Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2007: 468-477
[4]Agrawal S, Chaudhuri S, Das G. Dbxplorer: A system for keyword-based search over relational databases[C]Proc of the 18th Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2002: 5-16
[5]Hristidis V, Papakonstantinou Y. Discover: Keyword search in relational databases[C]Proc of the 28th Int Conf on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann, 2002: 670-681
[6]Hristidis V, Gravano L, Papakonstantinou Y. Efficient IR-style keyword search over relational databases[C]Proc of the 29th Int Conf on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann, 2003: 850-861
[7]Wang Can, Cao Longbing, Wang Mingchun, et al. Coupled nominal similarity in unsupervised learning[C]Proc of the 20th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2011: 973-978
[8]Wang Can, She Zhong, Cao Longbing. Coupled clustering ensemble: Incorporating coupling relationships both between base clustering and objects[C]Proc of the 29th Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2013: 374-385
[9]Wang Xin, Sukthankar G. Multi-label relational neighbor classification using social context features[C]Proc of the 19th ACM SIGKDD Conf on Knowledge Discovery and Data Mining. New York: ACM, 2013: 464-472
[10]Meng Xiangfu, Cao Longbing, Shao Jingyu. Semantic approximate keyword query based on keyword and query coupling relationship analysis[C]Proc of the 23rd ACM Int Conf on Information and Knowledge Management. New York: ACM, 2014: 529-538
[11]Li Guoliang, Feng Jianhua, Zhou Lizhu. Retune: Retrieving and materializing tuple units for effective keyword search over relational databases[C]Proc of the 27th Int Conf on Conceptual Modeling. Berlin: Springer, 2008: 469-483
[12]Feng Jianhua, Li Guoliang, Wang Jianyong. Finding top-kanswers in keyword search over relational databases using tuple units[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(12): 1781-1794
[13]Lopez-Veyna J I, Sosa-Sosa V J, Lopez-Arevalo I. Kesosd: Keyword search over structured data[C]Proc of the 2012 Int Conf on KEYS. New York: ACM, 2012: 23-31
[14]Sarkas N, Bansal N, Das G. Measure-driven keyword query expansion[J]. The VLDB Journal, 2009, 2(1): 121-132
[15]Bergamaschi S, Domnori E, Guerra F. Keyword search over relational databases: A metadata approach[C]Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 565-576
[16]Yao Junjie, Cui Bin, Hua Liansheng, et al. Keyword query reformulation on structured data[C]Proc of the 28th Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2012: 953-964
[17]Zhou Rui, Liu Chengfei, Li Jianxin. Fast ELCA computation for keyword queries on XML data[C]Proc of the 13th Int Conf on Extending Database Technology. New York: ACM, 2010: 549-560
[18]Bao Zhifeng, Lu Jiaheng, Ling T W. XReal: An interactive XML keyword searching[C]Proc of the 19th Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2010: 1933-1934
[19]Kong Linbo, Gilleron R, Lemay A. Retrieving meaningful relaxed tightest fragments for XML keyword search[C]Proc of the 12th Int Conf on Extending Database Technology. New York: ACM, 2009: 815-826
[20]Zheng Kai, Su Han, Zheng Bolong, et al. Interactive top-kspatial keyword queries[C]Proc of the 31st Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2015: 423-434
[21]Chen Lisi, Cong Gao, Jensen C S, et al. Spatial keyword query processing: An experimental evaluation[C]Proc of the 39th Int Conf on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann, 2013: 217-228
[22]IBM. AlchemyAPI documentation[EBOL]. 2005 [2015-05-10]. http:www.alchemyapi.com
[23]Huang A, Milne D, Frank E, et al. Clustering documents using a wikipedia-based concept representation[C]Proc of the 13th Pacific-Asia Conf on Knowledge Discovery and Data Mining. New York: ACM, 2009: 628-636
[24]Cheng Xin, Miao Duoqian, Wang Can, et al. Coupled term-term relation analysis for document clustering[C]Proc of the 2013 Int Joint Conf on Neural Networks. Los Alamitos, CA: IEEE Computer Society, 2013: 1-8
[25]Bollegala D, Matsuo Y, Ishizuka M. Measuring semantic similarity between words using Web search engines[C]Proc of the 16th Int Conf on World Wide Web. New York: ACM, 2007: 757-786
[26]AlSumait L, Domeniconi C. Text clustering with local semantic kernels[G]Survey of Text Mining Ⅱ. Berlin: Springer, 2008: 87-105
[27]Wang Xiuhong, Ju Shiguang. Novel kernel function for computing the similarity of text[J]. Journal on Communications, 2012, 33(12): 43-48 (in Chinese)(王秀红, 鞠时光. 用于文本相似度计算的新核函数[J]. 通信学报, 2012, 33(12): 43-48)
[28]Gan Guojun, Ma Chaoqun, Wu Jianhong. Data Clustering: Theory, Algorithms, and Applications[M]. Philadelphia, PA: Society for Industrial and Applied Mathematics, 2007
[29]Bouveyron C, Brunet-Saumard C. Model-based clustering of high-dimensional data: A review[J]. Computational Statistics and Data Analysis, 2014, 71(3): 52-78
[30]Hua M, Pei J, Fu A W C. Top-ktypicality queries and efficient query answering methods on large databases[J]. The VLDB Journal, 2009, 32(18): 809-835
[31]Fagin R, Lotem A, Naor M. Optimal aggregation algorithms for middleware[C]Proc of the 2001 Int Symp on Principles of Database Systems. New York: ACM, 2001: 102-113

Meng Xiangfu, born in 1981. PhD, associate professor, PhD supervisor. His main research interests include user behavior analysis, Web databases top-kquery, non-iidness learning and spatial data management.

Bi Chongchun, born in 1992. Master candidate. His main research interests include spatial data keyword query and spatial data analysis.

Zhang Xiaoyan, born in 1983. PhD candidate, engineer. Her main research interests include top-kranking, spatial data mining.

Tang Xiaoliang, born in 1980. PhD, lecturer. His main research interests include non-iidness learning and remote sensing image processing.

Tang Yanhuan, born in 1992. Master candidate. His main research interests include recommendation system and spatial data mining.
Web Database top-kDiverse Keyword Query Suggestion Approach
Meng Xiangfu1, Bi Chongchun1, Zhang Xiaoyan1, Tang Xiaoliang2, and Tang Yanhuan1
1(SchoolofElectronicandInformationEngineering,LiaoningTechnicalUniversity,Huludao,Liaoning125105)2(SchoolofSoftware,LiaoningTechnicalUniversity,Huludao,Liaoning125105)
Web database users often use the keywords that are familiar to them for expressing their query intentions and this may lead to unsatisfactory results due to the limitation of the users’ knowledge. Providing top-kdiverse and relevant queries can broaden user knowledge scope and thus can help them to formulate more efficient queries. To address this problem, this paper proposes a top-kdiverse keyword query suggestion approach. It first leverages frequency of co-occurrence and correlations between different keywords in query history to measure the intra-and inter-keyword couplings. And then, a semantic matrix, which reserves the coupling relationships between keywords, is generated. Based on the semantic matrix, the semantic similarities between keyword queries can be measured by using a kernel function. To quickly provide the top-kdiverse and semantically related queries, this approach first finds the typical queries from query history by using the probabilistic density estimation method. After this, it finds the representative queries from the set of typical queries and then creates the orders for each representative query according to the similarities of remaining queries in the set of typical queries to the representative query. When a new query coming, the similarities between the given query and representative queries are computed, and then the top-kdiverse and semantically related queries can be selected by using threshold algorithm (TA) over the orders of representative queries. The experimental results demonstrate that both the keyword coupling relationship and query semantic similarity measuring methods can achieve the high accuracy, and the effectiveness of top-kdiverse query selection method is also demonstrated.
Web database; diverse suggestion; coupling relationship; typicality analysis; top-kselection
2016-01-02;
2016-11-04
国家自然科学基金青年科学基金项目(61401185);辽宁省自然科学基金项目(20170540418);辽宁省教育厅科学技术研究项目(LJYL018) This work was supported by the National Natural Science Foundation of China for Young Scientists (61401185), the Natural Science Foundation of Liaoning Province (20170540418), and the Scientific and Technical Research Fund of Liaoning Provincial Education Department (LJYL018).
TP311.13
