云计算中基于多种群蚁群算法的虚拟机整合
2017-08-12王亚宁苑春苗孙学梅
王亚宁 苑春苗 孙学梅
(天津工业大学计算机科学与软件学院 天津 300387)
云计算中基于多种群蚁群算法的虚拟机整合
王亚宁 苑春苗*孙学梅
(天津工业大学计算机科学与软件学院 天津 300387)
在云计算的发展研究中,数据中心的高能耗问题得到了广泛的关注,而虚拟机整合是解决数据中心高能耗问题的手段之一。其思想是通过将一些物理机上的虚拟机迁移到其他活跃的物理机上使得一些物理机切换到低能耗模式或睡眠模式,从而降低云数据中心的能耗。首次将多种群蚁群算法应用于虚拟机整合,提出基于多种群蚁群算法的虚拟机整合算法。该算法通过特定的目标函数寻找一个近似最优解。通过仿真实验验证了该算法在降低能量消耗和减少虚拟机迁移次数方面优于现存的两种较优的虚拟机整合算法。
数据中心 能量消耗 虚拟机整合 多种群蚁群
0 引 言
云计算作为近来计算机工业领域的一大重要变革,其发展迅速,为用户提供几乎无限的虚拟的计算、存储和网络等资源。为了满足日益增长的用户需求,云数据中心的大小和能量消耗在不断增加[1],如美国能源部报告[2]指出,一个典型的数据中心的能耗占全美所有能耗的1.5%,并且仍以12%的速度增长。高能耗不仅转化为高的运行成本,还导致高的碳排放。因此,数据中心的能量消耗问题已成为一个急需解决的问题。
近年来,已有一些尝试来减少数据中心的能耗[3-4],一种有效且常用的方法是虚拟机整合。虚拟机整合是指根据虚拟机的资源需求,通过虚拟机迁移将其放置到更少的服务器上,进而将部分服务器关闭或处于低功耗状态,从而减小数据中心的能源开销。目前应用于虚拟机整合的算法有基于贪心算法、基于蚁群算法等启发式算法。在基于贪心算法的启发式算法中,文献[5]使用贪心算法来确定负载的虚拟机整合到轻载的物理机上的顺序,文献[6]为了保持物理机之间的负载平衡使用了最小负载的负载平衡算法。另外在基于蚁群算法的启发式算法中,文献[7]将虚拟机整合看作多目标组合优化问题,提出基于蚁群系统的虚拟机整合算法(ACS-VMC),应用自适应在线启发式优化算法[9]得到一个近似最优解,该算法是目前利用蚁群算法解决虚拟机整合问题中较优的方法之一。文献[8]中将蚁群系统与基于向量代数的服务器资源利用率捕捉技术[10]结合,提出基于向量代数的虚拟机整合算法(AVVMC)。该算法的主要思想是设置上下利用率阈值并保持它们之间的一个节点的总CPU利用率。当利用率超过上阈值时,虚拟机是负载平衡再分配,当利用率低于下阈值时,虚拟机是整合再分配。但是在以上文献中都是以单种群作为考虑的方向,相比较多种群蚁群算法(MACA)[11]在解的多样性上会有欠缺,在进行虚拟机整合时容易造成局部最优的问题,进而对减少能耗和虚拟机迁移次数造成一定的影响。
本文中,首次将多种群蚁群算法引入到虚拟机整合问题中,提出基于多种群蚁群算法的虚拟机整合算法(MACA-VMC)。该算法改进了贪心算法和蚁群算法在虚拟机整合过程中的缺陷。MACA-VMC算法利用人造蚂蚁整合虚拟机,其思想是根据当前资源需求来减少活跃的物理机的数量,这些蚂蚁通过特定的目标函数并行地建立迁移计划。为了评估算法的可行性,我们通过CloudSim[12]模拟真实工作负载的轨迹,分别与上文提到的ACS-VMC算法和AVVMC算法作比较,仿真结果表明MACA-VMC在减少能耗和虚拟机迁移次数方面要胜过ACS-VMC和AVVMC。
1 系统模型
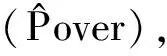
(1) 如果当前CPU利用率超过了环境中物理机的容量,那么这个物理机就可以定义为超载物理机。
(2) 如果预测的CPU利用率大于CPU可利用的容量,这个物理机视为预测超载物理机。
(3) 如果当前CPU利用率的值低于CPU总利用率的阈值,此物理机为轻载物理机。根据研究分析,一般当阈值达到50%时为最好结果。
(4) 其他各种运行状态的物理机都定义为标准物理机。
每一个物理机都包括一个多核的CPU。CPU的性能可以按照每秒处理的百万级的机器语言指令数(MIPS)来定义。在任意一个给定的时间,一个云数据中心经常同时为很多个用户提供服务。用户提交他们的请求给物理机,然后物理机把任务分配给N个虚拟机。每一个请求的长度有成千上万的指令(MI)来划分。
图1描述了所提到的系统模型,它包括两个类型的代理:局部代理和全局代理。在每一个物理机中存在一个局部代理,通过观察物理机的最近资源利用率来确定物理机的状态。全局代理充当一个监督者,并且利用基于信息熵的异类多种群蚁群算法的虚拟机整合算法来优化虚拟机放置。

图1 虚拟机整合系统模型
它们的工作流程如下:
(1) 局部代理(LA)监视CPU的利用率并且将物理机分类。
(2) 全局代理(GA)收集每一个物理机的状态,并且利用基于多种群蚁群算法的虚拟机整合算法建立一个全局最优的迁移计划,将在算法描述部分具体描述。
(3) 全局代理发送命令给监视器(VMMs)来执行虚拟机迁移整合任务,该命令决定了哪些虚拟机需要迁移到哪些目的机上。
(4) 当VMM从GA收到指令后开始执行真实的虚拟机迁移计划。
2 算法描述

2.1 单个种群算法描述
每一个物理机p∈P上可能放置一个或多个虚拟机。在虚拟机迁移计划中,每一个物理机都是一个潜在的源物理机,因为有可能已有虚拟机寄宿在此物理机上。同样一个虚拟机可以迁移到所有其他的物理机上,所以所有其他的物理机都是潜在的目的物理机。因此首先创建一套元组T,每一个元组t∈T其中包含三个元素:源物理机Pso,要迁移的虚拟机v,目的物理机Pde,其描述如下:
t=(pso,v,pde)
(1)
虚拟机整合算法的输出量是一个迁移计划,得到的结果是在不降低性能的前提下可以用最少的活跃的物理机来满足所有虚拟机的要求。此算法的目标函数描述如下:
(2)
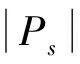
在算法的最后,当选择的迁移计划被执行时,通过将虚拟机迁移到活跃的物理机上来约束活跃的物理机的数量。一个物理机当且仅当不可能有虚拟机从此物理机迁移到其他物理机并且此物理机不在寄宿虚拟机时此物理机才会关闭为睡眠模式。其定义如下:
Ps={∀p∈PVp=∅}
(3)
其中,Vp是在一个物理机P上的虚拟机集合。
在本文把信息素放置在式(1)定义的元组中。每一个蚂蚁nA利用随机状态转移规则来选择下一个元组进行寻路。在蚁群系统中状态转移规则叫作伪随机比例规则。通过此规则,一个蚂蚁k通过下式选择元组s进行寻路,其描述如下:
(4)
其中,τ表示信息素的数量,η特定元组的启发式值,β是启发式值对信息素数量的影响因子。Tk∈T是元组T中蚂蚁k寻路剩余没有走过的元组。q∈[0,1]是均匀分布的随机变量,q0∈[0,1]为参数。S是通过式(7)给出的概率分布公式选出的随机变量,一个蚂蚁k随机选择元组s进行下一个寻路的概率ps定义如下:
(5)
元组s启发式值ηs定义如下:
(6)
其中,CPde是目的物理机Pde的总容量值,UPde是目的物理机Pde的已使用容量值,Uv是元组s中的虚拟机已使用的容量值。启发式值η依据CPde和UPde+Uv之间标量值的不同的乘法逆元素。这会使得虚拟机迁移从而减少利用率低的物理机的数量。而且,约束UPde+Uv≤CPde避免了目的物理机变为超载物理机。
除了随机状态转换规则以外,在所有蚂蚁已完成迁移计划之后还利用了全局和局部信息素更新规则,全局信息素更新规则定义如下:
(7)
(8)
α∈(0,1]是信息素信息素衰变参数,M+最好的全局迁移计划。
当一个蚂蚁穿过一个元组同时制定迁移计划时,应用局部信息素踪迹规则,其定义如下:
τs=(1-ρ)·τs+ρ·τ0
(9)
其中,ρ∈(0,1]类似于α和τ0是最初的信息素标准,τ0定义如下:
(10)
当一个种群完成搜索后,根据每只蚂蚁所求的ps值,来计算该种群的信息熵,具体公式如下:
(11)
其中,n表示该种群的蚂蚁数,对于所求得的种群信息熵,将用作种群间信息素的交流所选取种群的依据。
单个种群算法伪代码如下:
算法1单个种群算法流程
1:M+=∅,MS=∅
2:∀t∈Tτt=τ0
3: fori∈[1,nI] do
4: fork∈[1,nA] do

6: fort∈Tdo
7: generate a random variable q with a uniform distribution between 0 and 1
8: ifq>q0then
9: computeps∀s∈Tby using (5)
10: end if
11: choose a tuplet∈Tkto traverse by using (4)
13: apply local update rule in (9) ont
14: update used capacity vectorsUpsoandUpdeint
17:Mk=Mk∪{t}
18: else
20: end if
21: end for
22:MS=MS∪{Mk}
23: end for
24:M+=arg maxMk∈MS{f(Mk)}
25: apply global update rule in(7)on alls∈T
26: end for

一次迭代后,所有的蚂蚁都完成了它们的迁移计划,把所有的特定迁移计划Mk加入到迁移计划集MS中(第22行);利用目标函数式(2)计算所有Mk∈MS的目标函数值,把其中目标函数值最高的迁移计划赋给全局最优迁移计划M+(第24行);同时利用全局信息素更新规则式(7)、式(8)更新全局最优迁移计划当中的元组。最后,所有的迭代都完成后算法输入全局最优迁移计划M+。
2.2 种群间信息素的交流
在算法中,种群的交流是以一定的时间间隔来进行的,并且这种时间间隔并非固定不变,而是依据所有群体的信息熵来进行确定,也就是随着所有种群的收敛情况而改变。种群交流时间间隔gap满足:
gap=k1·e
(12)
其中,k1为常数,h为子群体的个数,si为第i个子群体的信息熵。
交流群体的选择是根据各个群体的信息熵来确定的。设群体i选择群体j作为进行信息交流的对象,则j可由式(13)决定。
(13)
其中,si、sj为当前时刻群体i和j的信息熵。由此信息熵大的群体会选择信息熵小的群体来交流信息,使得信息熵小的群体信息素分布相对集中通过和信息熵大的群体的交流可以平衡自己的信息素分布。而同样信息熵大的群体分布较分散和信息熵小的群体的交流可以集中自己的信息素分布。
当确定群体j作为群体i的交流对象,我们根据式(14)进行信息素的更新。
(14)

3 实验及结果分析
3.1 仿真实验环境
本文使用CloudSim工具包搭建实验环境,并在Eclipse中运行实验,通过Eclipse输出实验的结果,其中包括数据中心的能耗和虚拟机迁移次数。实验模拟了一个涵盖多个不同物理机的数据中心,设置了50台主机以及50台虚拟机来模拟云计算的数据中心。选择了两个在CloudSim里的服务器配置:HP ProLiant ML110 G4 (Intel Xeon 3040,2 cores×1 860 MHz,4 GB),HP ProLiant ML110 G5 (Intel Xeon3075,2 cores×2 660 MHz,4 GB)。该环境足以满足评估基于多核CPU架构的资源管理方法所需的硬件配置。为了评估提出的算法的有效性,我们选取了两种现存的较优的虚拟机整合算法ACS-VMC算法和AVVMC算法作为比较对象,验证相同实验配置下的能耗和虚拟机迁移。
3.2 数据中心的能耗
计算一个数据中心的物理资源的总的能耗需要考虑应用程序的工作量。计算单个物理机的能量大小时,主要考虑它的CPU使用效率、内存使用状态、硬盘占用情况和网卡的使用情况。大量研究表明CPU所消耗的能量比内存、存储器和网络接口消耗的多的多。因此,通常用一个物理机的CPU利用率表示该物理机的资源利用率,即该物理机主机的能耗。同样的本文中也用CPU利用率来代表该物理主机的能耗,其中我们利用基于线性回归的LiRCUP[13]预测短期内物理机的CPU利用率。
为了更好地表明仿真结果的真实可靠性,我们分别对仿真实验进行了8次迭代,如图2和图3分别比较了1次迭代到8次迭代下的能量消耗和平均能耗,可以明显看出MACA-VMC算法的能耗要少于ACS-VMC和AVVMC的能耗。AVVMC算法的能耗高达5.0 kW·sec以上,ACS-VMC算法的耗能量在4.9 kW·sec左右,而MACA-VMC算法的能耗仅仅只有不到4.8 kW·sec,且该算法下的能耗较为稳定。由此可见,虚拟机整合耗能量方面上,MACA-VMC算法远远优于另外两者。

图2 每次迭代能耗比较

图3 各种算法平均能耗
3.3 迁移次数
动态虚拟机整合是一个耗费资源的计算过程,它会使源物理主机的部分CPU资源消耗增加,源物理主机与目的主机之间的带宽资源消耗增加,迁移虚拟机上的服务暂停,总的整合迁移时间增加。因此,本文算法的目标之一是使迁移次数尽可能的少。在CloudSim中虚拟机迁移的时长近似于在源物理机和目的物理机网络带宽链路之间需要内存分配给虚拟机的迁移时间。在仿真实验中使用1 Gbps的网络链路。如图4所示,在每次迭代实验中,MACA-VMC算法的虚拟机迁移次数都在4次左右徘徊,比较稳定;而ACS-VMC算法的虚拟机迁移次数最多时能达到30次以上,最少时也有8次,AVVMC算法的虚拟机迁移次数同样最多时能达到30次左右,最少时也有10次以上,而且以上两种算法没有规律可寻。显然MACA-VMC算法的虚拟机迁移次数明显少于ACS-VMC算法和AVVMC算法的虚拟机迁移次数。

图4 虚拟机迁移次数
4 结 语
本文中提出了一个较新的基于多种群蚁群算法的虚拟机整合算法(MACA-VMC)。该算法通过整合虚拟机来减少活跃的物理机数量进而降低数据中心的能耗。相比于基于蚁群系统的虚拟机整合算法和基于向量代数的虚拟机整合算法,MACA-VMC算法降低了能耗,减少了虚拟机的迁移次数。
在未来的工作中,我们计划研究一些其他的启发式算法进一步对虚拟机整合算法进行优化改进。此外我们还计划将多种群蚁群算法作为一个延伸的虚拟机管理者,在公开的云平台上评估真实云环境下的虚拟机整合算法的性能。
[1] Wang B, Qi Z, Ma R, et al. A survey on data center networking for cloud computing[J]. Computer Networks the International Journal of Computer & Telecommunications Networking, 2015, 91(C):528-547.
[2] Ye K J, Wu Z H, Jiang X H, et al. Power Management of Virtualized Cloud Computing Platform[J]. Chinese Journal of Computers, 2012, 35(6):1262.
[3] Vogels W. Beyond Server Consolidation[J]. Queue, 2008, 6(1):20-26.
[4] Feller E, Morin C, Esnault A. A Case for Fully Decentralized Dynamic VM Consolidation in Clouds[C]// IEEE, International Conference on Cloud Computing Technology and Science. IEEE, 2012:26-33.
[5] Wood T, Shenoy P, Venkataramani A, et al. Sandpiper: Black-box and gray-box resource management for virtual machines[J]. Computer Networks the International Journal of Computer & Telecommunications Networking, 2009, 53(17):2923-2938.
[6] Ajiro Y, Tanaka A. Improving Packing Algorithms for Server Consolidation[C]// International Computer Measurement Group Conference, December 2-7, 2007, San Diego, Ca, Usa, Proceedings. 2007:399-406.
[7] Farahnakian F, Pahikkala T, Liljeberg P, et al. Utilization Prediction Aware VM Consolidation Approach for Green Cloud Computing[C]// IEEE, International Conference on Cloud Computing. 2015:381-388.
[8] Ferdaus M H, Murshed M, Calheiros R N, et al. Virtual Machine Consolidation in Cloud Data Centers Using ACO Metaheuristic[C]// European International Conference on Parallel Processing. 2014:162a-167a.
[9] Dorigo M, Gambardella L M. Ant colony system: a cooperative learning approach to the traveling salesman problem[J]. IEEE Transactions on Evolutionary Computation, 1997, 1(1):53-66.
[10] Ashraf A, Porres I. Using Ant Colony System to Consolidate Multiple Web Applications in a Cloud Environment[C]// Euromicro International Conference on Parallel, Distributed and Network-Based Processing. 2014:482-489.
[11] 赵君, 马中, 刘驰,等. 一种多目标蚁群优化的虚拟机放置算法[J]. 西安电子科技大学学报(自然科学版), 2015, 42(3):173-178.
[12] Calheiros R N, Ranjan R, Beloglazov A, et al. CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms[J]. Software Practice & Experience, 2011, 41(1):23-50.
[13] Farahnakian F, Liljeberg P, Plosila J. LiRCUP: Linear Regression Based CPU Usage Prediction Algorithm for Live Migration of Virtual Machines in Data Centers[C]// Euromicro Conference Series on Software Engineering and Advanced Applications. 2013:357-364.
VIRTUALMACHINEINTEGRATIONBASEDONMULTIPLEANTCOLONIESALGORITHMFORCLOUDCOMPUTING
Wang Yaning Yuan Chunmiao*Sun Xuemei
(CollegeofComputerScienceandSoftwareEngineering,TianjinPolytechnicUniversity,Tianjin300387,China)
In the development of cloud computing, high energy consumption of the data center has been widespread concerned, and the virtual machine integration is one of the means to solve the problem of high energy consumption. Virtual machine migration is a method of the number of virtual machines by the physical machine to migrate to make some of physical machines can sleep or enter low-power mode, which reduces power consumption of the cloud data center. In this paper, we present a multiple ant colonies algorithm to implement virtual machines consolidation. The proposed approach finds a near-optimal solution based on a specified objective function. It verifies through experiment that this algorithm outperforms existing virtual machines consolidation approaches in terms of energy consumption and the number of virtual machines migration.
Data center Energy consumption VM integration Multiple ant colonies
2016-09-12。国家自然科学基金青年科学基金项目(61402329)。王亚宁,硕士,主研领域:云计算,智能优化算法。苑春苗,副教授。孙学梅,副教授。
TP3
A
10.3969/j.issn.1000-386x.2017.08.005
