一种高效的船舶活动热点海域探测算法
2017-08-12杨乐包磊罗兵
杨 乐 包 磊 罗 兵
(海军工程大学电子工程学院 湖北 武汉 430033)
一种高效的船舶活动热点海域探测算法
杨 乐 包 磊 罗 兵
(海军工程大学电子工程学院 湖北 武汉 430033)
针对传统数据处理工具处理海洋船舶位置大数据效率低、空间特征不敏感的问题,引入SpatialHadoop空间大数据处理平台,提出一种基于SpatialHadoop的船舶活动热点海域探测算法。该算法结合空间索引和MapReduce分布式处理框架实现了基于区域统计的热点海域探测方法。从理论上分析,该方法能够高效地探测船舶活动热点海域。利用真实AIS数据进行实验,并从不同海域和算法运行效率两个方面对实验结果进行了对比分析,结果表明该算法具有有效的探测结果和较高的处理效率,验证了理论分析的正确性。
位置大数据 热点探测 空间大数据平台 空间索引
0 引 言
随着船载自动定位系统(AIS)的安装普及[1],规模巨大的海洋船舶活动所产生的轨迹数据呈现大数据态势。海洋船舶轨迹大数据富含位置信息和时间标识,属于位置大数据的范畴,具有数据量大、信息碎片化、单记录价值低和准确性低等位置大数据普遍拥有的特点[2]。海洋船舶位置数据与城市交通轨迹数据类似,在时空域内并不是均匀分布的,而是表现出明显的聚集特性,这种聚集性常用“热点海域”来表达。热点海域较其余海域而言,具有数据集中、信息丰富、模式多样等特点,因此热点海域的研究具有十分重要的价值。研究热点海域首先需要探测发现热点海域,有效的探测结果为热点海域的研究提供基础支撑。
热点海域探测是指通过某种方法识别船舶活动密集且彼此分离的区域或时段。该方向的研究国内外较少,但是对于船舶位置数据的分析与研究较为丰富,其主要涉及聚类分析、关联分析和异常检测等方向,也取得了一定的研究成果[3-5]。但是,大多研究仍沿用传统的分析工具,这导致船舶位置数据的分析面临着两大瓶颈问题:① 传统工具的串行处理方式无法满足海量位置数据对于处理速度的要求;② 传统工具的空间数据特征不敏感性制约着处理效率的提升。
针对上述问题,本文结合了位置数据热点探测相关方法,提出了基于空间大数据平台的热点海域探测算法。该算法弥补了传统位置数据热点探测算法串行计算方式和数据空间特征不敏感性的缺点,很好地提升了探测效率,为下一步热点海域模式挖掘和价值提取提供了支撑。文中采用真实AIS数据进行实验,实验结果也验证了该算法的高效性。
1 相关研究
1.1 空间大数据平台
大数据处理工具与方法的研究是目前研究的热点领域,分析该领域国内外研究现状可以发现,该领域的研究仍处于起步阶段。大数据处理工具的架构大多基于Hadoop技术,同时大量的研究集中在大数据分析方法上,支撑大数据平台开发的相关技术体系还没有形成[6]。关于大数据处理平台工具,国内已有一些研究开发,比如中国移动研究院研发的基于云计算平台的并行数据挖掘工具BC-PDM,厦门大学数据挖掘研究中心与台湾铭传大学、中华资料采矿协会合作开发的一套基于云计算的数据挖掘决策支持系统─—云端数据挖掘决策系统(MCU Smart Score),以及基于Hadoop中科院计算所研制的并行数据挖掘工具平台PDMiner。以上大数据处理工具只是实现了对事务性海量数据的并行化挖掘分析,并没有针对空间数据进行特殊设计,还无法高效存储、分析和挖掘空间数据。关于空间大数据平台,国外已有相关研究实践,明尼苏达大学计算科学与工程系Ahmed和Mohamed两人基于Hadoop大数据平台进行拓展,开发了一款专门用于空间大数据处理的平台SpatialHadoop[7]。该平台改变了传统Hadoop数据存储的堆文件方式,使用全局索引和局部索引相结合的两级大数据空间索引结构。该空间索引结构为平台提供了数据空间特征的敏感性,使数据的选取十分高效,从而提高了空间数据的处理效率。目前该平台提供空间Grid、Rtree和R+tree三类空间索引。
1.2 热点区域探测
由于海洋船舶交通位置数据与犯罪位置数据、交通轨迹数据在数据特征上存在着极大的相似性,加之犯罪热点区域探测和交通轨迹热点区域探测的一些理论方法对于热点海域的探测具有十分重要的借鉴意义。因此可将热点海域探测问题、犯罪热点区域探测问题以及交通轨迹热点区域探测问题统称为位置数据热点区域探测问题。
关于位置数据热点区域探测方法的研究,主要是面向小量数据集。成熟的探测方法可分为两大类:基于离散点的热点区域探测方法和基于区域统计数据的热点区域探测方法[8]。基于离散点的热点区域探测方法主要是指模式分析中的空间聚类方法,主要有统计法、分割法、层次聚类法和密度估计法。基于区域统计数据的热点区域探测方法,一般是指以某固定大小的区域为单位子区域计算每个子区域内的位置点总量、位置点密度等统计指标,再利用相关算法确定某时段内的“热点区域”或者某区域内的“热点时间段”,也可对热点区域数据类型进行分析,从而探测“热点类型”。两类方法的区别在于:前者基于离散点进行聚类处理,探测结果精度相对较高,而计算复杂度非常高;而后者基于子区域位置数据点统计结果进行处理,结果的精确度相对减小,但是计算复杂度降低的程度更加可观。热点海域探测对于探测结果精度的要求并非很高,使用基于离散点的热点探测方法造成精度冗余的同时又增加了算法的复杂度,因此本文采用基于区域统计的热点海域探测方法。
对于海洋船舶交通大数据而言,热点海域的实时探测和海量历史积累数据的热点区域探测处理对于算法计算速度的要求非常高。基于区域统计的热点海域探测方法虽然在一定程度上降低了计算复杂度,但是仍不满足实际要求。因此,本文引入空间大数据处理平台,提出了一种基于SpatialHadoop的热点海域探测算法,较大程度上提高了计算效率。
2 热点海域探测算法
2.1 算法设计思路
船舶热点海域探测算法是在已知的全海域寻找船舶分布比较密集的网格子海域集,其算法内容包括:基于SpatialHadoop平台实现敏感海域船舶位置数据提取,网格化分区和网格子海域内船舶数量统计的MapReduce化,以及使用迭代裁剪的方法获取热点海域。
基于SpatialHadoop平台的敏感海域数据提取的实现首先需要为全球海域数据建立空间Rtree索引。空间Rtree索引的建立包括数据分割,本地索引建立和全区索引建立三个阶段。在数据分割阶段需要满足三个要求:① 每个分割块的数据量满足HDFS块大小;② 空间相邻的位置点被分割在同一个块内;③ 所有分割块的负载均衡。本地索引是为数据分割结果建立Rtree索引,以便实现节点内数据的快速查找。全局索引建立于节点之间,索引文件存储于主节点,一旦MapReduce开始运行,可快速定位存储数据的子节点位置。然后,使用SpatialHadoop自带的区域查询功能,获取敏感区域的船舶位置数据集。区域查询是在Rtree空间索引结构之上实现的MapReduce并行化数据提取处理。该功能首先基于Rtree索引结构滤除不包含查询区域的数据分区,接着针对剩余的数据分区实行并行化筛选处理。基于SpatialHadoop平台实现敏感海域船舶位置数据提取的技术框架见图1。

图1 敏感海域船舶位置数据提取技术图
获取敏感海域船舶位置数据之后,由于敏感海域范围的粗略性,需要进行细化分区统计处理。该步采用网格化分区方法对敏感海域船舶位置数据进行分区处理,并统计每个子网格内的船舶数量。由于船舶位置数据实例的相互独立性,因此可以采用MapReduce编程框架进行并行化处理。Map函数的数目由网格子海域分区的数量确定,在Map阶段实现船舶位置数据与网格子海域的匹配。由于Map与Reduce阶段不涉及Map间的数据交换,每个Map函数对应一个Reduce函数,因此Reduce函数的数量与Map函数保持一致,在Reduce阶段实现网格子海域船舶数量的统计。
船舶活动热点海域的获取是建立在网格子海域船舶数量统计结果的基础之上实现的。通过迭代裁剪敏感海域中对船舶存在密度没有贡献或者贡献较小的网格子海域,直至满足最终的热点海域船舶存在密度阈值,具体的裁剪方法在后文有详细描述。
2.2 算法高效性理论分析
从理论角度分析,该算法较传统方法有更高的执行效率,其主要表现在两个方面:
(1) 并行化处理
该算法从敏感海域位置数据提取、网格化分区和网格子海域内船舶数量统计均采用了并行化处理方式。因此该算法并行化程度强,与传统串行方法相比较而言,必然较大程度上提高了执行效率。
(2) 空间数据索引
在并行化基础之上,该算法建立了位置数据空间索引。该算法在并行化处理之前基于空间索引结构已经滤除了大量的不相关数据分区。因此,减少了计算量,提高了计算效率。性能远远优于传统的串行处理方法,与优于纯粹的算法并行化。
2.3 算法具体实现步骤
(1) 建立全球海域船舶位置数据Rtree索引。
(2) 设定敏感海域C,提取敏感海域船舶位置数据。
(3) 计算敏感海域C的初始船舶存在密度,记为ρ0(船舶存在密度计算公式为:ρ=Q/S,其中Q表示海域的船舶总量,S表示海域面积;初始船舶存在密度ρ0=Q0/S0,其中Q0表示敏感海域的初始船舶总量,S0表示敏感海域初始面积)。
(4) 将敏感海域C按经纬度平均划分为N(N=X×Y,X为行数Y为列数)块网格子海域,并分别记为Rij(i表示行号,j表示第列号),统计网格子海域Rij内的船舶数量。
(5) 裁剪C的任意行网格子海域Ri或列网格子海域Rj,使裁剪后海域C的船舶存在密度最大并记为ρ(如果裁剪多行网格子海域或多列网格子海域或多行列网格子海域组合后,海域C的船舶存在密度相同,那么同时裁剪该多行或多列或多行列组合)。
(6) 判断C的存在密度ρ是否满足条件:ρ≥n×ρ0,如果满足算法结束,否则返回执行步骤5(其中n∈N+)。
为了读者更清楚地了解裁剪步骤,本节提供一个裁剪示例。设有敏感海域C,其中Q0=50,S0=25,计算得ρ0=2。将全海域C平均划分为25(X=Y=5)个子海域,存在密度阈值取n=3。经过三次迭代裁剪后获得最终结果,裁剪具体过程见图2。

图2 海域裁剪过程图
3 实验结果及分析
3.1 实验环境
实验选取4台计算机搭建SpatialHadoop平台,计算机系统采用Ubuntu Linux 14.04,SpatialHadoop版本采用SpatialHadoop 2.3,其中1台机器作为Master和JobTracker控制节点,其余3台机器作为Slave和TaskTracker计算节点。机器的基本配置见表1。

表1 各个节点的基本配置
3.2 实验数据选取
实验数据选自真实的AIS历史数据。AIS是海上船舶自动定位数据,数据属于结构化数据,有着规整的数据格式,十分利于实验处理。本实验选取2012年1月的全球AIS数据,数据量约102 GB。实验之前,对数据采取预处理操作,剔除了错误数据和格式有误数据。
选取南沙群岛及周边海域作为敏感海域,通过查阅世界地图确定粗略的南沙岛屿经纬度范围为110°E~118°E,4°N~12°N,其中包括远洋海域数据(南沙海域)和近岸海域数据(马来西亚西海岸)。
3.3 结果对比分析
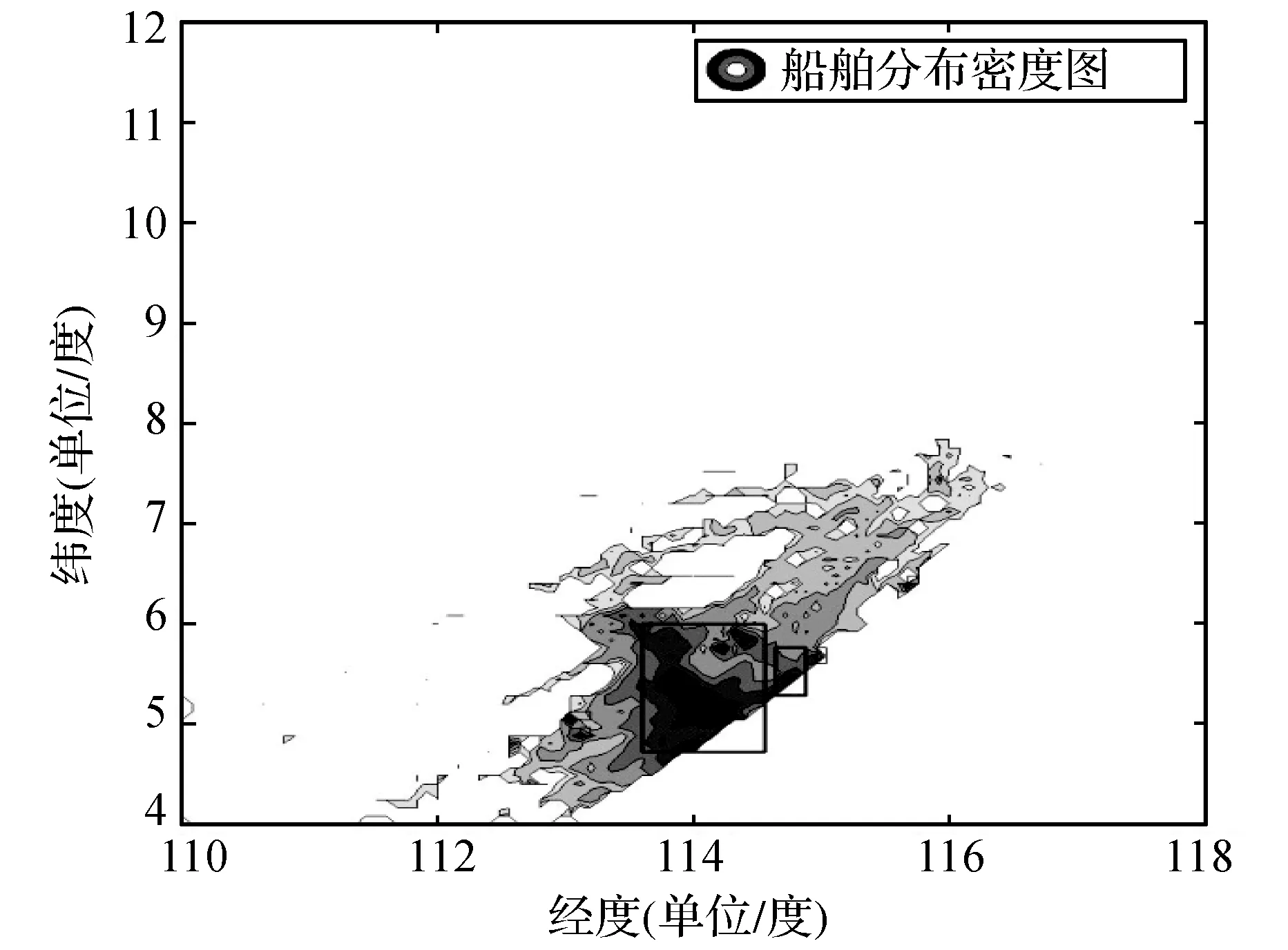
获取敏感海域船舶交通位置数据后,依照经纬度将敏感海域等值网格化,网格的划分数量确定为100×100个网格。统计各网格内船舶数量并绘制海域船舶存在密度图态势图,如图3所示。

图3 海域船舶存在密度态势图
观察图3易见,远洋海域数据与近岸海域数据在数据密度上存在较大的差异,直接影响算法处理结果的准确性,因此将远洋海域数据与近岸海域数据区分处理。依据我国南海划界九段线将研究海域划分为远洋海域和近岸海域,划分结果见图3,其中虚线以上为远洋海域,虚线以下为近岸海域。
下面从不同海域和算法性能两个角度对实验结果和算法性能进行了对比分析。
3.3.1 不同海域实验结果对比
实验对近岸海域数据与远洋海域数据分别进行处理,根据处理结果绘制热点海域面积占比与热点海域船舶数量占比随n值增大的变化趋势,如图4所示。

(a) 近岸海域

(b) 远洋海域图4 热点海域面积占比与热点海域船舶数量占比随n值增大变化趋势图
由图4可见,随n值增大,热点海域船舶数量占比和热点海域面积占比普遍呈减小趋势。但是,热点海域船舶数量占比减小的速度较为平稳,减小速度没有明显的变小或变大趋势,而热点海域面积占比的减小速度随n值增大呈下降趋势,以致于最后热点海域面积占比趋于稳定。由此可见,随n值增大热点海域面积占比存在一个临界稳定值,此临界稳定值对应的算法探测结果可被确定为热点海域。
另外,近岸海域与远洋海域相比较而言,近岸热点海域临界稳定值对应的n值较大且随n值增大近岸热点海域船舶数量占比下降速度较慢。这与近岸海域船舶存在密度普遍较大,船舶空间分布较均匀的事实相一致,这证实了算法的有效性和实验结果的正确性。
基于上图实验结果分析,选取n=100和n=39为近岸海域和远洋海域的热点海域探测阈值,并将所对应的热点海域探测结果显示在船舶存在密度态势图中,见图5。
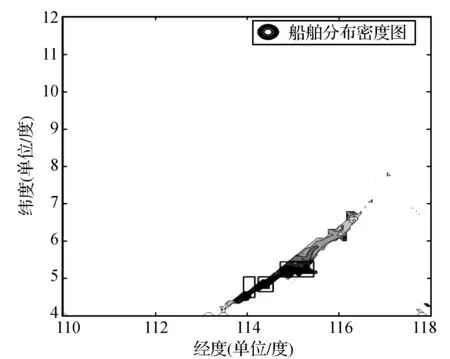
(a) 近岸海域
(b) 远洋海域图5 热点海域探测结果显示图
3.3.2 算法性能比较
选择不同的网格划分数量,比较基于传统处理工具的探测算法与基于SpatialHadoop的探测算法的运行速度,实验结果见表2。

表2 算法执行速度比较表
由表2可见,基于SpatialHadoop船舶交通位置数据热点海域探测算法执行速度明显快于基于传统工具的船舶交通位置数据热点海域探测算法,与实验设计的初衷相符,同时验证了SpatialHadoop平台在处理空间大数据上的优势。
4 结 语
对于海洋船舶交通位置大数据分析而言,传统处理工具与方法暴露出时间复杂度高,空间特征不敏感等缺点。针对这些缺点,本文提出了基于SpatialHadoop的热点海域探测算法。该算法结合了空间数据索引和MapReduce并行化处理方法,很好地解决了上述缺点。
正如前文所述,船舶活动热点海域具有数据集中、信息丰富、模式多样等特点。热点海域内部信息提取与模式挖掘具有十分重要的价值与意义。利用相关统计与挖掘方法分析热点海域,这是下一步研究的内容之一。同时,海洋探测较普通空间位置探测而言存在其独特性。将更多地挖掘分析海洋探测较普通空间位置探测的特点,提出适应性更强的海洋探测算法。
[1] Iphar C, Napoli A, Ray C. Data Quality Assessment For Maritime Situation Awareness[J]. Remote Sensing and Spatial Information Sciences, 2015, 2(3): 291-295.
[2] 刘经南, 方媛, 郭迟,等. 位置大数据的分析处理研究进展[J]. 武汉大学学报(信息科学版), 2014, 39(4):379-385.
[3] Scrofani J W, Tummala M, Miller D, et al. Behavioral detection in the maritime domain[C]// System of Systems Engineering Conference. IEEE, 2015:380-385.
[4] Iphar C, Napoli A, Ray C. Detection of false AIS messages for the improvement of maritime situational awareness[C]// Oceans’2015, Oct 2015, Washington, DC, United Stateds.
[5] Liu B, De Souza E N, Matwin S, et al. Knowledge-based clustering of ship trajectories using density-based approach[C]// IEEE International Conference on Big Data. IEEE, 2014:603-608.
[6] 宫夏屹, 李伯虎, 柴旭东,等. 大数据平台技术综述[J]. 系统仿真学报, 2014, 26(3):489-496.
[7] Eldawy A, Mokbel M F. SpatialHadoop: A MapReduce framework for spatial data[C]// IEEE, International Conference on Data Engineering. IEEE, 2015:1352-1363.
[8] 陆娟, 汤国安, 张宏,等. 犯罪热点时空分布研究方法综述[J]. 地理科学进展, 2012, 31(4):29-35.
ANEFFICIENTHOTSPOTSDETECTIONALGORITHMOFVESSELSACTIVITY
Yang Le Bao Lei Luo Bing
(SchoolofElectronicEngineering,NavalUniversityofEngineering,Wuhan430033,Hubei,China)
Traditional data processing tools were inefficient and not sensitive to spatial characteristics when processing traffic location big data of marine vessel. Aiming at the problem, the SpatialHadoop platform is introduced and a hotspots detection algorithm based on this platform is proposed. The algorithm combined the spatial index with MapReduce distributed processing framework which realized the method of hotspots detection based on regional statistics. In theory, the method could efficiently detect hotspots of vessels activities. Experiment was done on the real AIS data and the result indicated that the method had effective detection result and higher efficiency.
Position big data Hotspots detection SpatialHadoop Spatial index
2016-07-26。杨乐,硕士生,主研领域:时空数据挖掘。包磊,教授。罗兵,讲师。
TP311
A
10.3969/j.issn.1000-386x.2017.08.053
