一种基于DCFC的XML检索结果聚类方法
2017-08-10余宏胡晓蓉
余宏,胡晓蓉
(豫章师范学院信息科学系,南昌330013)
一种基于DCFC的XML检索结果聚类方法
余宏,胡晓蓉
(豫章师范学院信息科学系,南昌330013)
提出一种有效的XML文档检索结果聚类方法,基于PB-DCFC的思路,根据XML文档的特点,对XML文档包含的显著标签路径进行聚类,是一种间接的聚类方法。该方法具有聚类效率高,聚类结果的簇标签表达自然,容易理解。
江西省社会科学“十二五”(2015年)规划项目(No.15TQ01)
0 引言
目前大多数的搜索引擎都存在着对用户查询意图不明确,返回结果过多等问题。搜索引擎返回的内容中有相当大一部分并非查询用户真正想要的信息,用户需要逐条打开返回的结果进行人工甄别以找到相关的信息。为此,如何对搜索引擎返回的查询结果进行挖掘,帮助用户提取相关知识是近年来的一个研究热点。其中,对检索结果按主题内容进行聚类挖掘,抽取聚类结果簇的语义标签,方便用户在与自己的查询意图相符的聚类结果簇中查找所需的信息,或者根据聚类反馈的结果进一步提出更准确的查询表达式。从而达到减少用户浏览无关信息的数量,缩短用户检索相关信息的时间。
XML已经成为Web上进行数据表示和交换的通用格式之一,其应用也越来越广泛。与普通的扁平文档不同,XML文档是一种半结构化数据,具有层次性,而且能进行自描述,因此,XML文档除了具有内容信息,还携带有一定的结构和语义信息。对检索结果进行聚类挖掘能有效的改善搜索引擎的服务质量,因此,针对XML文档检索,本文利用XML文档的结构和语义信息进行检索结果的聚类分析,以提高用户进行XML查询的质量和效率。
1 相关工作
1.1 XML检索介绍
XML数据模型:XML属于典型的半结构化数据,具有层次性,而且能进行自描述,既可以用它表示关系、对象等结构化数据,也可用于半结构化及非结构化数据的描述。典型的XML文档结构如下(文档1)所示。

XML文档一般建模为有序标签树,将XML文档中每个元素(或属性)抽象为一个结点,父元素与子元素之间、元素与其属性之间的关系均用对应结点间的实线边表示,包含文本信息的叶子结点、元素属性与属性值之间的关系则用虚线表示。示例文档1对应的标签树如图1所示。
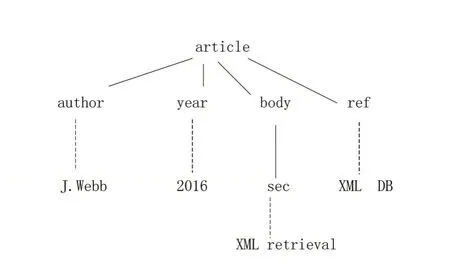
图1 示例文档1对应的标签树
XML检索查询:传统的文本检索仅限于内容(CO)的查询,而XML检索不仅支持CO查询,而且还有内容和结构查询(CAS)查询。一般,用Xpath表达式来表示查询的结构约束,用about(path,string)函数表达内容约束。例如:/article/body/sec[about(.XML retrieval)]。
定义1标签路径(Tag Path)[7]:对XML标签树中的任一结点V,其标签路径记为从根结点到V结点所经历的标签有序列表。如图1中sec结点的标签路径为:article.Body.sec。
1.2 检索结果聚类
对检索结果进行聚类挖掘的研究大多针对无结构的平面文档,诸如对Web搜索结果进行聚类,而针对半结构化的XML数据的检索结果进行聚类的研究还不多见。对XML检索结果进行组织的方法大体可以分为两类:基于文档(document-based)的方法和基于标签(label-based)的方法。
基于文档(document-based)的方法,其聚类的过程如图2(a)所示。该类方法一般使用文档特征间的相似性来对文档集进行聚类,文档的特征比较多的采用关键词向量表示。聚类成一个个簇后,再从每个簇中抽取有代表性的词或句子作为簇的标签来对簇进行描述Anton Leuski[1]和Scatter/Gather[2]就是采用该类方法。基于文档的方法通常产生non-over-lapped簇,并且标签质量易受聚类的准确性的影响。尽管可以用簇的数目和相似性阈值来控制聚类的过程,但还是很难选出适合于用户阅读和理解的标签值。
相反,基于标签(label-based)的方法根据对文档成分的统计分析(诸如词条的出现频率),首先从检索结果中抽取信息项(词或短语)作为标签,然后把含有相同信息项的文档形成一个个簇。其过程如图2(b)所示。我们把这种聚类过程称为“Description Comes First Clustering”,简称 DCFC。Zeng et al.[3]将聚类问题看成是显著短语排序问题。首先抽取显著短语(作为候选簇名)并计分排序;然后,将文档指派给相关的显著短语以形成候选簇;最后通过对候选簇进行归并形成最终簇。M.Lalmas et al.[4]把聚类问题看作是对搜索结果建索引,这里的索引即为标签列表。Hiroyuki et al.[5]提出了一些标签选择标准。
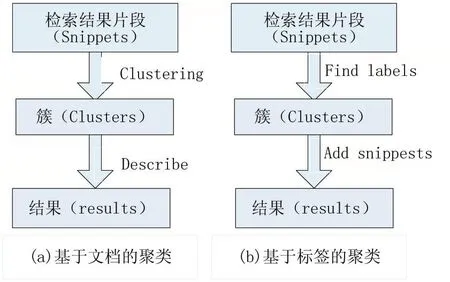
图2 基于文档和基于标签的文档聚类过程
2 XML检索结果的DCFC方法
检索结果聚类与传统的文档聚类有所差别,它要求簇标签能精确描述类别(Browsable Summaries),一个文档可以属性多个簇(Overlap),聚类速度要快(Speed)。基于这些要求和XML文档自身的特点,本文提出了一种先抽取显著路径作为标签后聚类的XML检索结果聚类方法(PB_DCFC),与其他方法直接计算XML文档间距离不同,该方法对结果包含的显著路径聚类。PB_DCFC方法有两个优点:第一,聚类结果的簇标签表达自然,容易理解;第二,算法的复杂度是线性的。
2.1 特征抽取和建立索引模型
文本特征抽取是指为了量化表示文本信息,从文档中抽取出特征关键词,用它对原始文档进行建模,用于描述和代替原始文本。从而将计算机对文本的识别转化为对该文档模型的操作和计算。目前,比较常见的是将文档特征词量化为向量空间模型(VSM)。
在本文提出的XML_DCFC方法中,抽取XML文档的标签路径作为文档特征。理由是:(1)XML标签路径包含了文档的结构和语义信息。标签是对嵌入其中的文本内容的概括。(2)一篇文档中不同的标签路径数目比较少,相对于传统的用关键词作为特征,可以降低文档特征空间的维数,从而提高聚类的效率。
本文的方法中使用标签路径作为结果簇的候选标签。我们认为,有利于浏览聚类结果和定位想要的文档的路径既不能太稀少也不能太频繁。TF-IDF是纯文本搜索引擎中对索引项计算权值得基本标准。本文对TF-IDF作相应的改进,将索引项的“粒度”放大到路径,词频代之以路径相对频率,故本文用以下标准计算文档D中的标签路径TPi的权重。
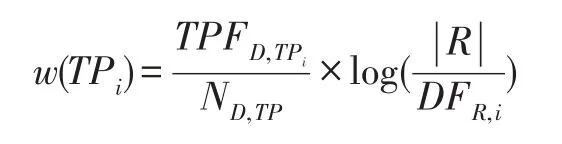
在抽取文档的特征项后,接下来要设计特定的数据结构将特征项描述的文档模型存储到计算机中,以保证动态数据的高效存储及文档之间相似度的计算。我们使用类似倒排文档列表(Inverted Files List)模型。倒排列表结构如图3所示。但本文采用的倒排表的索引项不是单个词语,而是显著标签路径。
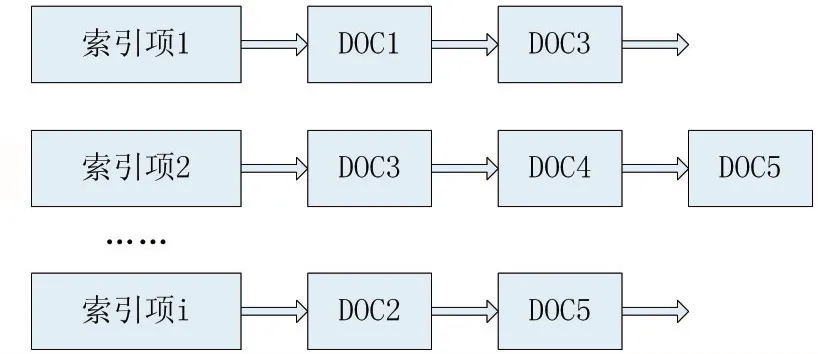
图3 倒排表结构
2.2 相似性计算
由于本文采取的是一种间接的聚类方法,即用显著标签路径来代表文档,文档之间的相似性就转化为计算显著路径之间的相似性问题。显著路径用词袋模型表示,其特征由它所包含的标签名构成。在这里要做一些预处理:去除出现在结果集中50%以上或少于3篇文档中的标签名;其次,出现在查询表达式中的标签名也必须去除,这相当于信息检索中的停用词处理。另外,考虑到根结点的特殊性,把根结点单独考虑,基于这样的考虑,有相同的根结点的文档相似度较高。
采用以下方法度量标签路径(Tag Path)之间的相似度:
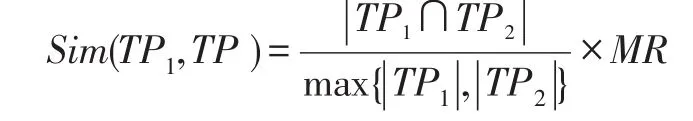
计算簇之间的相似性类似,簇中心用簇中各标签路径所含的标签名的并集表示。
2.3 聚类算法
用于文本聚类的算法常用的有以G-AHC(Agglom⁃erative Hierarchical Clustering)为代表的凝聚层次法和以K-means为代表的平面划分法。这两类算法各有优缺点,前类算法比较健壮,并独立于被聚类对象的顺序,但计算复杂度比较高;后类算法的优点是计算复杂度低,但很难以求出全局最优解[7]。此外,算法中k值及初始划分需要事先设定,而且这些预设值对聚类结果影响较大,难以保证聚类结果质量的稳定性。本文对以上两类算法进行了综合并加以改进,以克服它应用于检索结果聚类的不足。
算法描述:
输入:检索结果集中抽取的显著路径集
输出:M个簇,使得簇内文档相似或相关


3 PB-DCFC的系统体系结构
XML检索结果首先被扫描解析以获取有关路径文档频率和标签文档频率的统计信息,并生成显著路径的倒排表。数据清洗主要是去除显著路径中在检索结果集中频繁出现或在检索查询表达式中出现过的标签。接下来根据相关的统计信息对显著路径执行聚类算法。聚类算法执行完后,簇的内容是显著路径,然后根据倒排列表把与显著路径相关联的文档作为簇的内容,显著路径作为簇标签的形式来呈现聚类结果。PBDCFC的系统体系结构如图4所示。
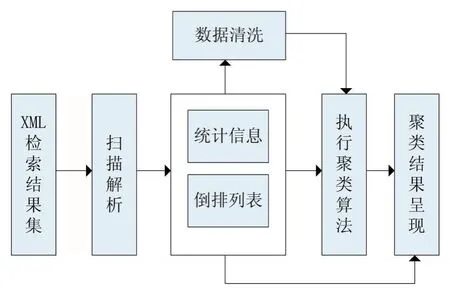
图4 PB_DCFC的系统体系结构
4 结语
本文提出的基于标签路径对XML检索结果进行聚类的方法综合考虑了XML文档具有语义结构性的特点和检索结果聚类不同于普通文档聚类的特点,具有效率高,聚类结果可读性强等优点。
[1]Anton Leuski.Evaluating Document Clustering for Interactive Information Retrieval.
[2]M.Hearst,J.Pedersen,Reexamining the Cluster Hypothesis:Scatter/gather On Retrieval Results.Proceedings of SIGIR'96,1996:76-84.
[3]Hua-jun Zeng,Qi-Cai He,et al.Learning to Cluster Web Search Results.SIGIR'04,July 25-29,2004,Shffield,South Yorkshire UK.
[4]M.Lalmas et al.Improving Quality of Search Results Clustering with Approximate Matrix Factorisations ECIR 2006,LNCS 3936,2006:167-178.
[5]Hiroyuki Toda,Ryoji Kataoka.A Search Result Clustering Method Using Informatively Named Tntities WIDM'05,November 5,2005,Bremen,Germany.
[6]韩家炜,Kamber M.数据挖掘:概念与技术[M].北京:机械工业出版社,2002.
[7]余宏,万常选.基于XML的检索结果聚类方法研究,计算机工程,2010(1):85-90.
A XML Retrieval Results Clustering Method Based on DCFC
YU Hong,HU Xiao-rong
(Department of Information Science,Nanchang Teachers'College,Nanchang 330013)
Proposes a novel approach called Path-Based,Description label Comes First Clustering(PB-DCFC)for XML retrieval results.Instead of comparing XML documents structure and clustering them directly,the salient paths contains in retrieval result documents contain docu⁃ments a set of similar salient paths.This clustering approach offers much high performance,and provides user readable clustering result.
余宏(1977-),男,硕士,讲师,研究方向为数据挖掘、数字媒体技术
2017-03-28
2017-06-05
1007-1423(2017)17-0040-05
10.3969/j.issn.1007-1423.2017.17.008
XML;检索结果;聚类;标签路径
胡晓蓉(1961-),男,江西南昌人,本科,副教授,研究方向为软件技术
XML;Retrieval Results;Clustering;Tag Path
