模糊非参数统计检验及在老龄化社会调查领域的应用
2017-07-24王忠玉吴柏林
王忠玉+吴柏林

摘 要:在社会科学研究中,许多事物的测算或观测结果往往不是精确的数据,而是或多或少具有模糊属性的数据。中国人口老龄化问题越来越突出,至2015年底,我国60周岁及以上老年人口数量为22 182万,占总人口16.15%。关注老年人的生活议题显得十分重要。在研究老年人问题时,因研究对象都曾经历不同时空背景与人生阅历,个体间存在的差异极大,如何准确获得有关老年人的生活、医疗等信息,为国家和政府决策提供真实客观的信息,则是一项紧迫的任务。依据老年人身的身心发展特质,探索利用模糊理论的软计算,设计出模糊数据调查表,提出反模糊化变换。同时,运用中位数检验及方差检验,建立统计参数为模糊数或模糊区间时的小样本非参数模糊统计检验方法,并给出具体调查事例加以说明。
关键词:模糊数据;反模糊化变换;模糊非参数统计检验;老龄化社会
中图分类号:F24 文献标志码:A 文章编号:1673-291X(2017)17-0001-10
一、刻画模糊性的模糊理论
1.模糊理论
模糊理论源于1965年美国伯克利(Berkeley)大学L.A.Zadeh教授在《信息与控制(Information and Control)》期刊上所发表的论文。模糊集合(Fuzzy sets)理论至今已有60多年的发展历史。
模糊理论是以模糊集合为基础,其基本思想是以模糊现象为研究对象。如何使用明确的数学方式表达模糊性呢?Zadeh简单地将具有0与1两个值的特征函数 IA(x)扩展成 [0,1]区间,称此函数为隶属度函数(membership function)。隶属度函数在模糊理论上扮演着中心角色,它是从传统集合的特征函数所衍生来的,以此刻画元素对模糊集合的隶属度,其范围介于0到1之间。对于元素和集合的关系,传统集合用特征函数描述,即当x∈A,则I(x)= 1;当x?埸A时,则I(x)= 0。Zadeh提出,当元素属于某集合的程度越大,则其隶数度值越接近1,反之则越接近0。这样方法可将介于“是”与“不是”之间的所有状态表示出来了。
2.隶属度函数
用传统集合定义具有模糊性的语言变量时,常会造成许多不合理的现象。假如今天假设A、B、C三人,年纪各为59、60、75岁,其中A、B两人虽只差1岁,只有B算老人,A却不属于老人。很明显,这样相当不合理。对于传统的二分法与人类思维格格不入的问题,利用隶属度函数能得到较合理的答案。如果某人认为70岁绝对属于老年,则其隶属度函数值自然为1,而59岁几乎可算是老人,则其隶属度函数值为0.9,此表示59岁属于老年的程度有0.9。这样,可绘出模糊集合老年人的隶属度函数图(图1)。
和传统集合的特征函数比较,隶属度函数是将特征函数平滑化了。而且,隶属度函数让每个年龄层都拥有一个介于0到1之间的值,来代表人年老的程度。相较于传统集合的特征值,在刻画具有模糊性的事物概念时,用模糊集合的隶属度函数来解释更为适当。
通常,隶属度函数可分为离散型与连续型两类。离散型隶属度函数是以穷举法直接给定有限模糊集合内每个元素的隶属度。而连续型隶属度函数则是利用几种常用的函数形式(s函数、z函数、Π函数、三角形函数、梯形函数、高斯(钟型)函数)来描述模糊集合。在连续型隶属度函数的形式中,以三角形、梯形、钟形等隶属度函数容易理解,并且能满足大部分的研究设计。梯形隶属度函数,因计算方便且贴近语意的模糊性,是本文所采用的。
隶属度函数的设计与建立并不具有唯一性,关于年老概念的模糊集合用以如下的隶属度函数描述之:
这样的隶属度函数可以完全表达出模糊集合,如μ年老表达出年老模糊集合的含义。
隶属度函数是模糊理论最基本的概念,它不仅可描述模糊集合的性质,更可对模糊集合进行量化,并利用精确的数学方法来分析和处理模糊信息。要建立足以表达模糊概念的隶属度函数,并不是一件容易的事。原因在于隸属度函数的建立脱离不了个人主观意识,故没有通用定理或公式,一般是根据经验或统计来加以建立。
二、模糊数与反模糊化变换
当统计参数为模糊数或模糊区间的情况时,很难利用传统统计检验方法处理。当收集到模糊数或模糊区间样本时,想要利用传统统计检验方法,首先要定义模糊样本的排序问题。利用模糊理论,说明模糊问卷调查以及模糊数的建立,并提出反模糊化转换,以解决统计检验中数据排序的问题。
1.模糊数
一般地说,模糊数可分成两大类。一类是离散型模糊数,由离散型隶属度函数所定义;另一类是连续型模糊数,由连续型隶属度函数所定义。连续型模糊数,依其隶属度函数的形状可分为:(1)实数区间模糊数;(2)三角形模糊数(Triangular fuzzy number);(3)梯形模糊数(Trapezoidal fuzzy number);(4)钟形模糊数(Bell shaped fuzzy number);(5)不对称模糊数(Non-symmetric fuzzy number),分别由各自的隶属度函数所定义。
三角形模糊数虽有计算简单的优点,但梯形模糊数更接近于实际情况,也为大多数逻辑系统所接受。当考察前三者关系时,可将梯形模糊数看成是实数区间模糊数及三角模糊数的特例(梯形的上底近于0)。下面,首先定义模糊数。
定义2.1 模糊数
设U是论域,令{A1,A2…,An}为论域U的因子集,μ是一个将[0,1]映射到实数的函数,即μ:U→[0,1]。设有论域U的陈述句X,其相对于因子集隶数度函数用{μ1(X),μ2(X),...,μn(X)}表示,则陈述句X的模糊数可表示成:
当 b=c,X是三角形模糊数。
当 a=b,c=d,X是实数区间模糊数。
例 2.1 离散型模糊数的表示法
设X是某老人一天出外活动时间(小时),用模糊数表示为μn(X),论域U可看成整数论域,即出外活动时数。设U={1,2,3,4,5,6},老人一天出外走动的时间的隶属度函数为 {μ1(X)=0,μ2(X)=0.2,μ3(X)=0.5,μ4(X)=0.2,μ5(X)=0.1,μ6(X)=0},则老人一天出外活动时间的模糊数可表示为
例2.2 连续型模糊数的表示法
(1)如果老人一天晚上的睡觉时间约6—8小时,可得到一组实数区间模糊数,记为[6,8],如图3所示。
其对应的隶属函数关系如下:
μx(x)=1, 6≤x≤80, x<6;x>8
(2)如果老人一天的晚上睡觉时间约6小时且不少于5小时,不多于8小时,则我们可得到一组三角形模糊数(图4),记为[5,6,8]。
(3)如果老人晚上睡觉时间通常约为5~8小时且不少于4小时,不多余10小时,则我们可得到组一梯形模糊数(图5),记为[4,5,8,10]。
实际上,上述(1)实数区间模糊数与(2)三角形模糊数,可被看成是梯形模糊数的特例,即分别标记为[6,6,8,8]与[5,6,6,8]。
2.模糊数问卷调查表设计
在调查时,有别于传统问卷设计的模糊问卷设计决定了抽样的模糊数是离散型还是连续型。下面运用事例说明,如何设计与收集模糊数问卷调查的方法及技巧。
例2.3 离散型模糊数问卷调查
某个项目要调查6位老人,对生活津贴、医疗体系、休闲联谊活动、无障碍设施、交通方便、宗教等事项所感重要性的隶属度进行选择,可各予以十枚硬币,令其依心中感受的重要性将不定数量之硬币放置各个项目上,同时必须全数用完。于是得到6组离散型模糊数的结果,如表1。
如果利用传统问卷调查形式,也就是規定每位受访者只能勾选一意愿最高项目,则对受访者而言,所勾选选项应是心目中的隶数度最高者。其结果如表2。
比较以上两种调查形式,由传统问卷调查可知,六种选项中以医疗体系(众数最高)最为老人所关切。利用模糊问卷调查的结果,则是交通方便(模糊众数最高)最被关切。实际上,传统问卷调查方式会舍弃许多信息,不如模糊问卷接近现实情况。
例3.4 连续型模糊问卷调查
连续型模糊语意量表是另一种形式的模糊问卷调查。由于其易于理解,也适用于老人议题的社会调查。比如,某个项目要调查以前从科学研究的老年人,问询他们什么年龄段是最容易探索出成果的“黄金年龄”,这可设计如下形式的量表(图6),请受访者以签字笔将最确切的“黄金年龄”部分以粗线段涂黑,随即令受访者在粗线段左、右分别画上左括号、右括号表示或可称得上“黄金年龄”。从而,得出一组梯形模糊数。
注意,当询问的内容是类别变量时,则只可能设计为离散型模糊问卷(如例2.3)。当询问的内容是连续尺度或序列尺度时,则可设计为离散型模糊问卷,也可设计为连续型模糊问卷(参看例3.1)。至于采取何种方式,这时要视所研究的问题或受访者能否依指示操作而定。
3.反模糊化变换
反模糊化变换是将模糊数转变成实数的一种方法。不论离散型模糊数(类别变量的离散型模糊数除外)还是连续型模糊数,都通过反模糊化变换转变为反模糊化值。定义如下。
定义2.3 离散型模糊数的反模糊化值
例2.5 求离散型模糊数的反模糊化值
设X为老人一天出外走动时间(小时),其论域U={1,2,3,
4,5,6},其隶属度函数分别为{μ1(X)=0,μ2(X)=0.2,μ3(X)= 0.5,μ4(X)=0.2,μ5(X)=0.1,μ6(X)=0},则老人一天出外走动时间的反模糊化值为 :
1×0+2×0.2+3×0.5+4×0.2+5×0.1+6×0=3.2 小时
至于连续型模糊数的反模糊化变换,则考虑代表连续性的模糊集合,即代表不确定事件之一的梯形模糊集合。当获得梯形样本时,我们感兴趣的是它在实数直线上所代表的值,即反模糊化值。在实际应用时,采取一个普遍化的非线性单位间变换,而非原始的线性单位间的变换。
当将梯形数据合理且有意义地转化成实数时,需要确定两件事,即变换数据必须是(1)有限维度的;(2)此类参数的相依性必需是平滑的(即可微分的)。用数学语言表示,就是此转换群是一个李群(Lie group)。
当决定变换并实施后,要有一个新值y= f(x)取代原始梯形数据。在理想条件下,这个新量y是正态分布的。当决定如何变换时,由于可能再次变换单位,代表量x的数值变换并非唯一。
定义2.4 梯形模糊数在实数直线的反模糊化变换
3.3反模糊化转换的一些性质
对于梯形模糊数的反模糊化变换,可将其性质归纳如下:
性质3.2 模糊数A趋近精确数,是反模糊化变换后值RA 趋近于重心cx的充分且必要条件。
性质3.3 模糊数A趋近模糊数,是反模糊化变换后值RA 趋近于重心cx + 1的充分且必要条件。
性质3.4 考虑两梯形模糊数Ai,Aj。其重心 (cxi与cxj)距离 >1,是“重心 (cxi与cxj)的排序与反模糊化变换后值 (RAi与RAj)的排序方向不变”的充分但非必要条件。
性质3.5 考虑两梯形模糊数Ai,Aj。其反模糊化变换后值 (RAi与RAj)距离 >1,是其反模糊化转换后值 (RAi与RAj)的排序与重心(cxi与cxj)的排序方向不变”的充分但非必要条件。
三、中位数检验
1.模糊中位数
当样本数不多或数据数有序数据或数据的测量值不稳定但大小关系仍存在时,我们可用中位数代替平均值探讨总体的集中趋势。非参数统计法经常探讨具有这类特性的总体的中位数关系。当样本为模糊数而非精确数时,可推广传统的中位数为模糊中位数。模糊中位数和传统中位数相同,不会受到样本极端值影响,因此是稳健性的集中趋势估计量。
下面分别针对离散型与连续型两类模糊中位数做进一步探讨。连续型模糊中位数较离散型复杂,其隶数度函数常以区间均匀分布或不对称梯形分布两种情形表达。而区间分布可视为不对称梯形分布的特例,本文仅对不对称梯形分布做深入研究。
定义3.1 离散型模糊中位数
例3.1 离散型模糊中位数应用于银发族每月基本生活费的调查
政府为老人提供多项的福利政策,比如中低收入老人生活津贴、照顾高龄老人特别照顾津贴等。考虑到最近时期市场上各种食品价格出现上涨,某个课题组想要了解老人一个月基本生活费用大致需多少钱?这个调查采用模糊中位数方式收集数据。以下是针对6位银发老人,利用离散型模糊问卷调查表所得的关于每月基本生活费的隶属度选择,如表4。
由于样本数n=6为偶数,x (3)f= 13000,x (4)f= 16000 而对应x (3)f,x (4)f的样本值为:
注意,离散型模糊样本的中位数仍是离散型模糊数。若利用传统的问卷调查方式,也就是规定每位受访者只能勾选一个意愿最高的选项,则对于受访者而言,所勾选的选项应是心中的隶属度最高者。其结果如表5。
从表5数据中,可以得到6位受访者的选择价格,依小到大排序是:8 000,10 000,10 000,15 000,20 000,25 000元或8 000,10 000,10 000,15 000,20 000,25 000元。而利用传统中位数的取法,取出结果是10 000元。可以知道,当用传统问卷方式进行调查,无法真正反映受访者完整的想法。因为传统中位数只能考虑受访者最高意愿,所以利用模糊样本中位数,结合模糊众数的理论来思考,更能合理又真实地分析这类问题。
定义3.2 连续型模糊样本中位数
设Ai=[ai,bi,ci,di],i =1,2,…,n,是一组梯形模糊数。根据在实数直线的反模糊化值定义,计算Ai=[ai,bi,ci,di]的反模糊化值RAi,令RA (i)为将RAi排序后而得到的有序样本值,则定义梯形模糊样本中位数为:
例3.2连续型模糊样本中位数应用于回味人生岁数的探讨
苏格拉底说过,“不经过反省的人生,是不值得活的。”回味是人在午夜做梦时,时常会梦到的念头,如儿时父母的呵护、与朋友相处的时光、工作的现实和理想,在各阶段的人生际遇等。下面是连续型模糊问卷调查表,是对9位受访者“回味人生的岁数”的梯形模糊数,并依定义计算出其反模糊化值,如表6。
从表6数据中,可以得到9位受访者对回味人生岁的数梯形模糊数的反模糊化值,由小到大的排列为16.5,18.6,32.1,
40.9,59.1,60.7,72.1,72.7,73.2。根據模糊样本中位数定义,当 n=9时,中位数为第5位,可得模糊梯形中位数是59.1。由此可知,9位受访者所代表的总体认为值得的回味的人生岁数约为59.1岁。
2.中位数检验法
当抽取元素的总体是非正态分布,其分布形式未知或样本数少时,如采用传统统计检验法,将导致过多推论,使结论变得不可信。此时可采用非参数统计方法。非参数统计经常利用中位数代表数据的集中趋势。
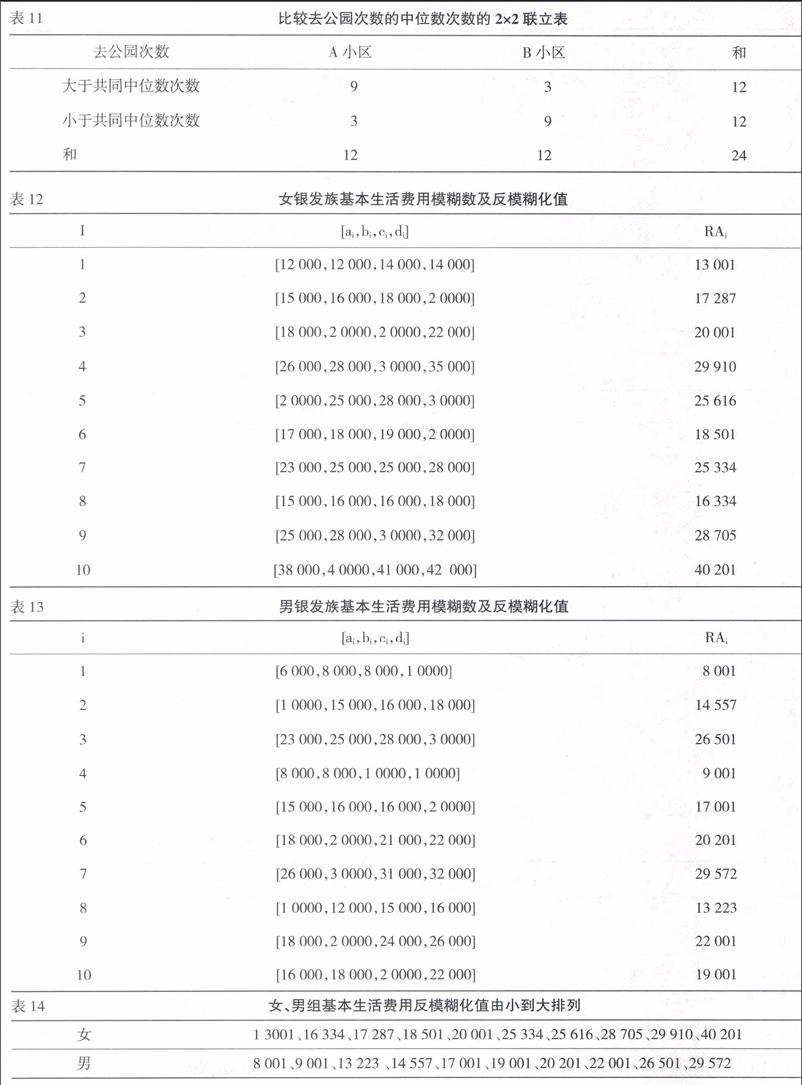
非参数统计的中位数检验有多种方法。而由Mood所提出的中位数检验法,采用卡方检验法的统计量,可用于检验两组独立样本来自的总体是否具有相同的中位数,应用非常广泛。模糊数的中位数检验,不论是离散型还是连续型模糊数,都要使用各模糊数的反模糊化值。此检验方法是将两组独立样本混合后,找出共同中位数,再分别算出两组样本大于或小于共同中位数的个别次数,制成2×2联立表,如表7。
检验的假设形式为:
双尾检验:H0:两组样本所来自的总体的中位数相等,当χ2<χ2 (α,1)H1:两组样本所来自的总体的中位数不相等,当χ2≥χ2 (α,1)
这个检验法的理论基础是,当两组样本来自的总体具有相同中位数,则依共同中位数划分的大于或小于共同中位数的实际次数,必与单纯因概率所造成的大于或小于共同中位数的理论次数相去不远。因此卡方值不应超越临界值,所以当卡方值大于临界值时,应拒绝H0。
例3.3 检验A、B两小区的老者每周去公园次数是否相等
设有A、B两小区邻近公园,想要检验A、B两小区的老者每周去公园次数是否相等。由A、B两小区分别抽取13、12位老者,得各人每周去公园的次数模糊数,并计算其反模糊化值,整理成表8、9及10。
当取α=0.05,检验A、B两小区老人每周去公园次数之中位数是否相等?具体方法如下:
假设为H0:两小区每周去公园次数之中位数相等H1:两小区每周去公园次数之中位数不相等
混合后共同中位数是5.4,整理得联立表,如表11。
用中位数次数的联立表(表11),计算统计量
即差异显著,故拒绝接受H0。这表示A、B两小区老人,每周去公园次数之中位数有可能不相等。由前例可知,此中位数检验法并不限制A,B两组的样本数必须相等。
例3.4 检验男、女银发族所认为的每月基本生活费用是否相等
某个项目想要检验男、女银发族所认为的每月基本生活费用是否相等,由女、男银发族各随机抽取10人所认为的每月基本生活费用,得其基本生活费用模糊数及反模糊化值,整理成表12、13及14。
现以α=0.05,检验女、男两组银发族老人每月基本生活费用之中位数是否相等?具体方法如下:
假设为H0:女、男两组银发族老人每月基本生活费用之中位数相等H1:女、男两组银发族老人每月基本生活费用之中位数不相等
即差异不显著,故接受H0。这表示男、女两组银发族老人每月基本生活费用之中位数可能相等。
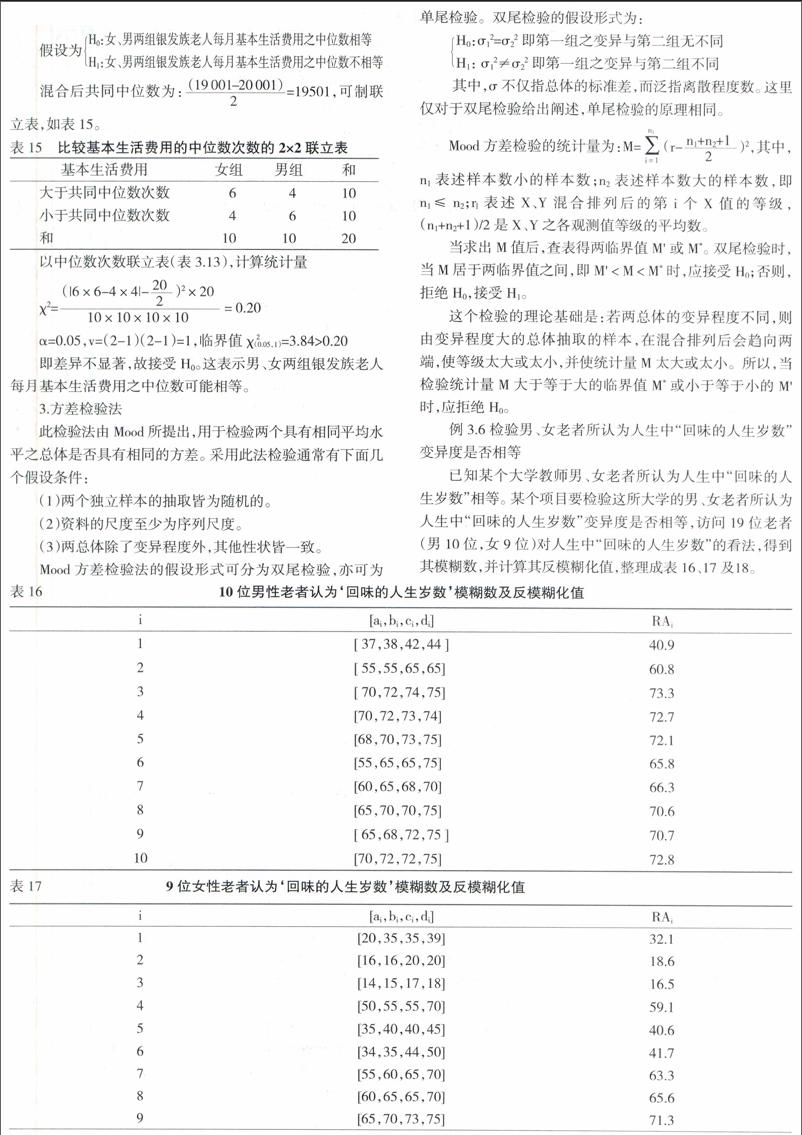
3.方差检验法
此检验法由Mood所提出,用于检验两个具有相同平均水平之总体是否具有相同的方差。采用此法检验通常有下面几个假设条件:
(1)两个独立样本的抽取皆为随机的。
(2)资料的尺度至少为序列尺度。
(3)两总体除了变异程度外,其他性状皆一致。
Mood方差检验法的假设形式可分为双尾检验,亦可为单尾检验。双尾检验的假设形式为:
H0:σ12=σ22即第一組之变异与第二组无不同H1: σ12≠σ22即第一组之变异与第二组不同
其中,σ不仅指总体的标准差,而泛指离散程度数。这里仅对于双尾检验给出阐述,单尾检验的原理相同。
当求出M值后,查表得两临界值M'或M*。双尾检验时,当M居于两临界值之间,即M' 这个检验的理论基础是:若两总体的变异程度不同,则由变异程度大的总体抽取的样本,在混合排列后会趋向两端,使等级太大或太小,并使统计量M太大或太小。所以,当检验统计量M大于等于大的临界值M*或小于等于小的M'时,应拒绝H0。 例3.6 检验男、女老者所认为人生中“回味的人生岁数”变异度是否相等 已知某个大学教师男、女老者所认为人生中“回味的人生岁数”相等。某个项目要检验这所大学的男、女老者所认为人生中“回味的人生岁数”变异度是否相等,访问19位老者(男10位,女9位)对人生中“回味的人生岁数”的看法,得到其模糊数,并计算其反模糊化值,整理成表16、17及18。 当取α=0.05,检验回首人生岁月中的男、女,其所认为值得回味人生的岁数,是否变异程度不同?具体方法是: 采双尾检验H0:σ12=σ22即男、女组所认为‘回味的人生岁数变异度无不同H1: σ12≠σ22即男、女组所认为‘回味的人生岁数变异度不同 利用排序后的数据,表19,求其统计量M α=0.05,n1=9、n2=10 M =(1-10)2 +(2-10)2+(3-10)2+(4-10)2+(6-10)2+(7-10)2+(9-10)2+(10-10)2+(15-10)2=281 查表得出,临界值M'=154,M*=386,M' 这表示,回首人生回味的岁月,男、女测试结果变异程度有可能相同。由前例可知,此方差检验法并无不限制受检验的两组样本数必须相等。 四、结论 本文研究设计模糊数据的调查表,提出反模糊化转换的定义,建立模糊中位数检验方法,对社会科学中涉及老年人有模糊特性的表述结果的模糊数据,给出了非参数统计分析,并举例说明,得出更为准确的符合实际情况的分析和检验。同时,对结果进行方差检验,可以发现,这些信息对国家和政府制定政策及决策是十分重要的。因此,本文针对中国人口老龄化的有关信息的收集及统计分析,提出了一种有效的模糊统计分析与非参数检验方法,具有广泛的应用价值和前景。 参考文献: [1] 王忠玉.模糊数据与统计分析[J].中国统计,2009,(9):56-57 [2] 王忠玉,吴柏林《模糊数据统计学[M].哈尔滨:哈尔滨工业大学出版社,2008. [3] 王忠玉,吴柏林.模糊数据均值方法及应用研究[J].统计与信息论坛.2010,(10):13-17. [4] 王忠玉,吴柏林.模糊数据问卷调查表的设计及应用[J].经济研究导刊,2012,(14):174-178. [5] 王忠玉,吴柏林.一类模糊数据的相关系数研究[J].经济研究导刊,2015,(2):248-251. [6] Klir,G..J.,Yuan,B.Fuzzy Sets,Fuzzy Logic,and Fuzzy Systems[M].NJ: World Scientic.Publishing Co.Ltd.1995. [7] Zimmermann,H.J.,Fuzzy Set Theory and its Applications,4 edition[M].北京:世界图书出版公司,2011. [8] Voxman,W.Canonical Representation of Discrete Fuzzy Numbers.Fuzzy Sets and Systems,118,457-466,2001.
