我国35个中心城市综合发展水平研究
2017-07-19王秋红
王秋红,赵 乔
(西北师范大学 经济学院,甘肃 兰州 730070)
我国35个中心城市综合发展水平研究
王秋红,赵 乔
(西北师范大学 经济学院,甘肃 兰州 730070)
经济的全球化、区域化已成为当今时代主旋律,分析比较我国重要城市的综合发展水平,可以充分发挥地区优势,为政府部门进行宏观调控提供一定的参考。文章利用聚类分析、判别分析、主成分分析和因子分析四大方法,选取反映城市社会经济发展的综合发展水平指标作为原始变量,研究了2015年全国35个中心城市综合发展水平。发现了各中心城市之间的发展差异,北京和上海等东部沿海城市发展水平遥遥领先,而中西部地区城市综合发展水平明显偏低。
中心城市;聚类分析;判别分析;主成分分析;因子分析
一、引言
在经济全球化、区域化和聚团化的大背景下,建立各具特色的区域分工和合作格局,充分发挥地区比较优势,是实现我国经济长期快速、健康、协调发展目标,增强国家和各地区经济实力的重要措施。改革开放以来,各省市均将经济建设作为发展的首要任务,我国经济实现迅猛发展,中心城市是各地区政府的发展重点,它们代表该地区经济社会发展的高水平,发挥着在区域和省域经济社会发展中的辐射和带动作用。因此,在衡量我国各区域经济社会发展状况时,有必要先对个别中心城市的发展现状进行考察,通过研究其自身的优劣势,根据其自身特点制定适宜的城市发展战略具有重要理论价值和现实意义。
中心城市是区域经济的核心和区域开发的重要依托,其在区域经济开发中的地位和作用日益受到国际学术界的关注。这几年来,已经有大量学者运用多种方法对我国城市发展水平进行分析。如冯丹(2006)[1]采用主成分分析和聚类分析法,对四川省社会发展水平进行分析;彭丽等(2009)[2]、张萌等(2010)[3]利用因子分析对重庆市的发展水平进行了排名;汪海凤等(2012,2013)[4-5]基于因子分析对我国高新区综合发展水平展开研究;丁红艳等(2016)[6]以新疆各地州市为样本,用因子分析法提取综合经济实力、工业发展和农业发展三个主因子;吴玉鸣(2016)[7]运用熵值法、聚类分析法等,对比了环渤海地区和西部能源“金三角”地区的经济水平。
可见目前大部分文献都是对我国某区域的发展水平进行评价,对多城市综合发展水平进行比较的研究且四大多元统计方法结合运用的相对较少。因此本文选取了全国35个中心城市作为样本单位,所有数据取自《中国统计年鉴 2015》,选用SPSS19.0软件进行分析。首先用聚类分析对样本城市进行经济状况分类,用判别分析对重点城市进行检验,再用主成分分析找出衡量城市综合发展水平的核心指标,根据指标评估城市发展绩效,最后用因子分析对其发展现状进行定量对比分析。其中判别分析和因子分析为文章实证分析的重点。
二、实证分析
根据现实依据可初步判断,我国中西部城市综合发展水平差异较大,大部分东部城市优于西部城市;影响城市综合发展水平的因素有经济水平、环境水平、福利水平等,它们之间通常具有关联性;综合发展水平较高的城市各项指标水平都较高。把以上结论作为本文的假设和预测,进而用四大分析方法验证其准确性。
(一)聚类分析
首先将数据进行标准化变换,消除量纲影响。设定指标zx1~zx12的含义分别为非农业人数(万人)、工业总产值(万元)、货运总量(万吨)、批发零售住宿餐饮业从业人数(万人)、地方政府预算内收入(万元)、城乡居民年底储蓄额(万元)、在岗职工数(万人)、在岗职工工资总额(万元)、人均居住面积(平方米)、每万人拥有公共汽车数(辆)、人均铺装道路面积(平方米)、人均公共绿地面积(平方米)。
采用Q型系统聚类法中的离差平方和法对除深圳、兰州、南京、银川外的全国31个中心城市综合发展水平进行分类,距离计算采用平方欧氏距离法。由聚类顺序表(见表1),第一步是样本12和样品17进行聚类,距离系数为0.127;第二步是样本5和样本19进行聚类,距离系数为0.332,该结果将在第五步用到;第三步是样本3和样本15进行聚类,距离系数为0.588,该结果将在第六步用到。以此类推,31个样本经过30步最终聚成一个大类。绘制聚类冰柱图(图略)可以得到同样的结果。
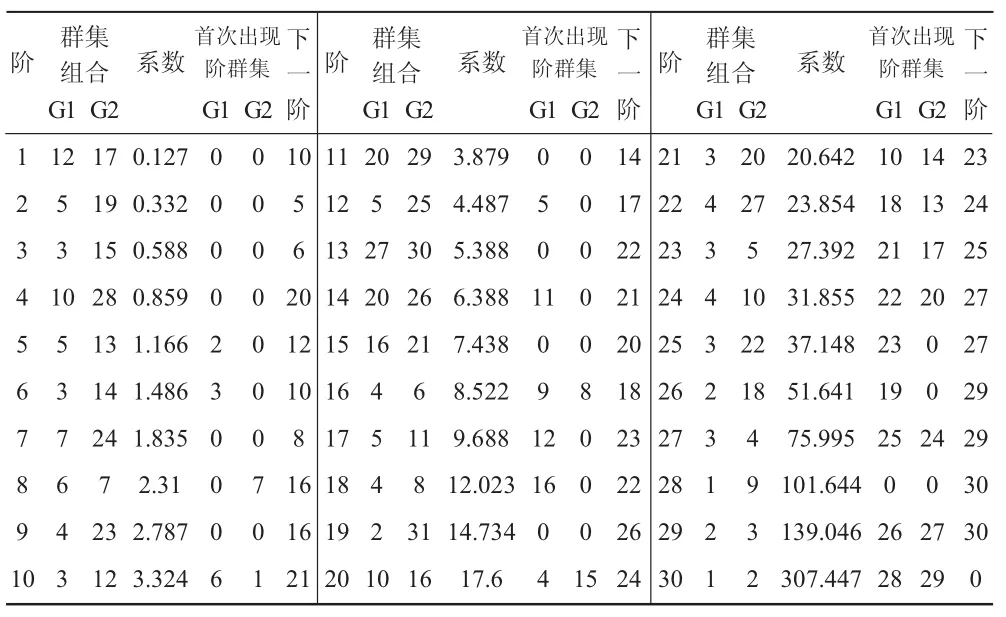
表1 聚类顺序表(G1,G2分别代表群集1,2)
绘制系统聚类的树状图(见图1)可以把31个样品分为3类,能更好地反映我国的情况:第一类是上海、北京这类文化、经济发达的国家政治、金融中心城市;第二类是天津、重庆、广州这类重要港口、直辖市和改革开放前沿地带;第三类是福州、长沙、石家庄等其他发展水平一般的城市。
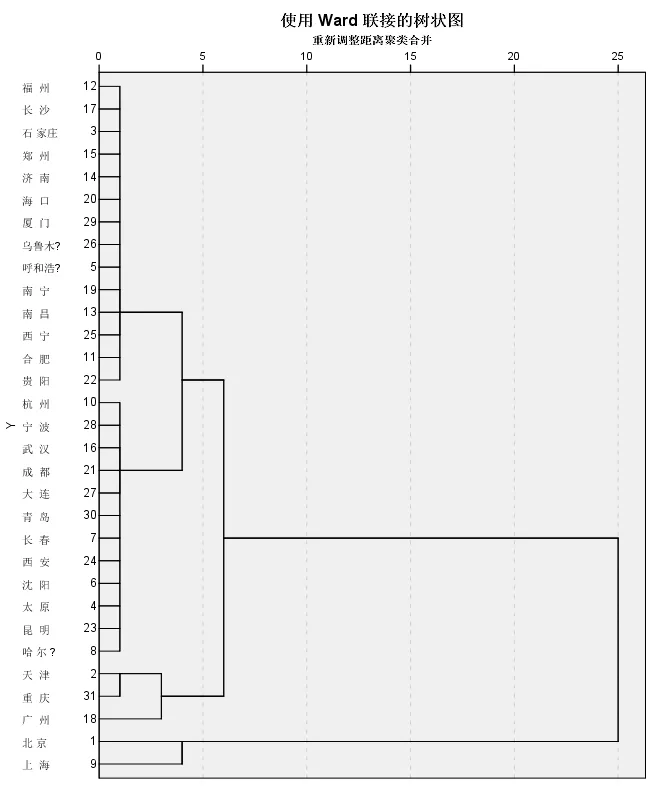
图1 系统聚类的树状图
(二)判别分析

表2 判别函数的特征值(左)及对判别函数的显著性检验结果表(右)
根据上文将31城市分成3类。设定深圳、兰州、南京、银川四个城市为待估分类。由于本文预测变量为12个,类别数为3,因此判别函数的个数为 2(即 min(3-1,12)=2)。判别函数的特征值越大,表明该函数越具有区别力。由表2(左)第一个判别函数的特征值为97.160,第二个判别函数的特征值为4.416。
表2(右)中“1到 2”表示两个判别函数的平均数在3个级别间的差异情况。“2”表示在排除第一个判别函数后,第二个函数在3个级别间的差异情况。从最后的显著性概率SIG来看,其两个判别函数的效果显著。
由标准化的典型判别式函数系数可得判别函数分别为:
F1=1.124x1-2.713x2-0.157x3+1.983x4+4.173x5-1.561x6-2.256x7+1.607x8+0.115x9-0.304x10+0.066x11-0.456x12
F1=1.151x1+0.089x2+0.089x3-2.526x4-1.235x5-1.741x6-0.421x7+4.020x8+0.767x9-0.142x10-0.351x11+0.490x12
根据判别函数,将各变量的值带入其中进行计算可得到判别分数,根据各观测量的两个判别分数可得到区域图或散点图(图略),SPSS中该图是以根据每个个案计算出的判别分数为坐标,一点则判别函数1为横轴,一点则判别函数2为纵轴所绘制的,可看出在图中分出了三个区域,也标出了各类中心(用*表示)。
由分类函数系数表可建立3个分类函数:
Q1=73.336x1-161.441x2-7.910x3+117.873x4+
471.801x5-160.342x6-167.231x7+158.438x8+3.481x9-53.137x10+5.498x11-23.894x12-643.872
Q2=16.545x1-6.698x2+1.372x3-20.696x4-1.391x5-40.544x6-14.685x7+82.816x8+5.082x9-10.340x10-6.706x11+2.780x12-22.689
Q3=-6.621x1+9.439x2+1.438x3-6.325x4-28.806x5+12.309x6+10.154x7-13.262x8-0.874x9-0.294x10-1.294x11+0.781x12-4.559
将各变量的值带入这三个判别函数模型进行计算,对得到的3个数进行比较,将每个样本分到数值较大的类中。根据样本数据分类情况图(图略)可得各个样本数据及4个待判样本数据分类情况,可以清楚地看出4个待判样本有1个归为第二类,3个归为第三类。
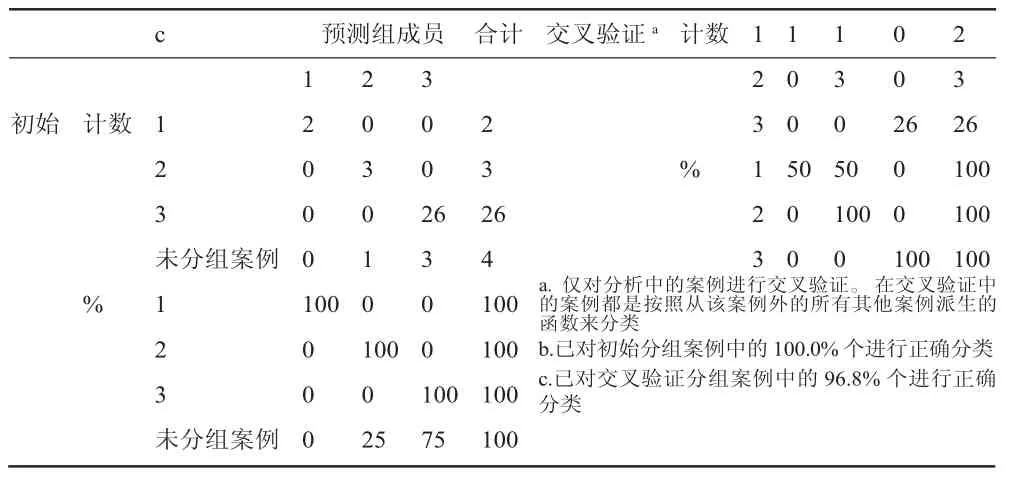
表3 分类结果表
分类结果表(见表3)中,对角线显示的为准确预测个数,其余为错误预测个数。可得已经分类的31个样本全部正确,正确率为100%。以这31个个案为先验数据,将待分类的4个个案分别分入 1、2、3 类的各有 0、1、3 个。
(三)主成分分析
由表4,“合计”部分为各因子对应的特征根,“方差的%”部分为各因子对应的方差贡献率,“累计%”部分为累计贡献率。前3个主成分已经解释了总方差的87%以上,故可以选择前3个主成分进行分析。
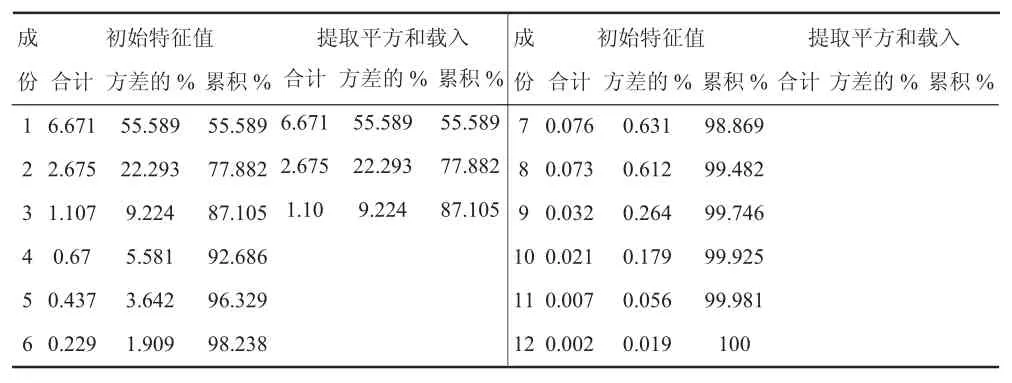
表4 特征值和方差贡献表
结合主成分分析碎石图(见图2)的特征根曲线拐点及特征值,可以看出,前三个主成分的折线坡度较陡,而后面就逐渐趋于平缓,该图从另一个角度说明了取前三个主成分为宜。
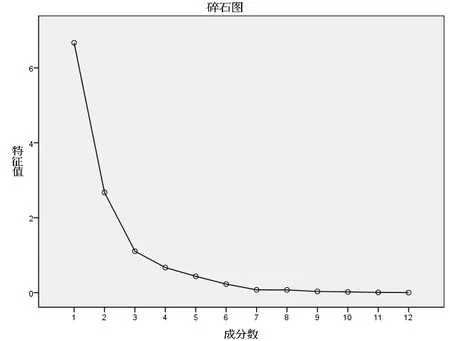
图2 主成分分析碎石图
由于旋转前的因子载荷矩阵不是主成分分析中所需的标准化正交向量,通过计算出标准化特征向量,得到标准化正交特征向量矩阵。继而得出主成分的计算公式:
y1=0.34x1+0.33x2+0.32x3+0.31x4+0.37x5+0.38x6+0.36x7+0.38x8+0.02x9+0.08x10+0.09x11+0.09x12
y1=-0.2x1+0.16x2-0.13x3-0.12x4+0.04x5-0.02x6-0.13x7-0.02x8+0.28x9+0.55x10+0.57x11+0.43x12
y1=0.14x1+0.25x2+0.31x3-0.38x4+0.12x5-0.06x6-0.14x7-0.15x8+0.69x9-0.12x10-0.05x11-0.34x12
再由特征值和方差贡献表所示的各主成分分析的方差百分比(第一主成分占55.589%,第二主成分占22.293%,第三主成分占9.224%)计算出综合得分函数,公式为Y综=0.55589y1+0.22293y2+0.09224y3。则排序后的各主成分及综合得分情况如表5所示,通过综合得分的高低,可知各城市综合发展水平的高低,其中上海最高,西宁最低。
(四)因子分析
在进行因子分析之前,首先应该在标准化数据基础上确定待分析的原有若干变量是否适合因子分析,要求原有变量之间有强相关性,否则无法从中综合出能反映某些变量共同特征的少数公共因子变量来。常用相关性检验有:反映像相关矩阵检验、巴特利特球形检验、KMO检验。
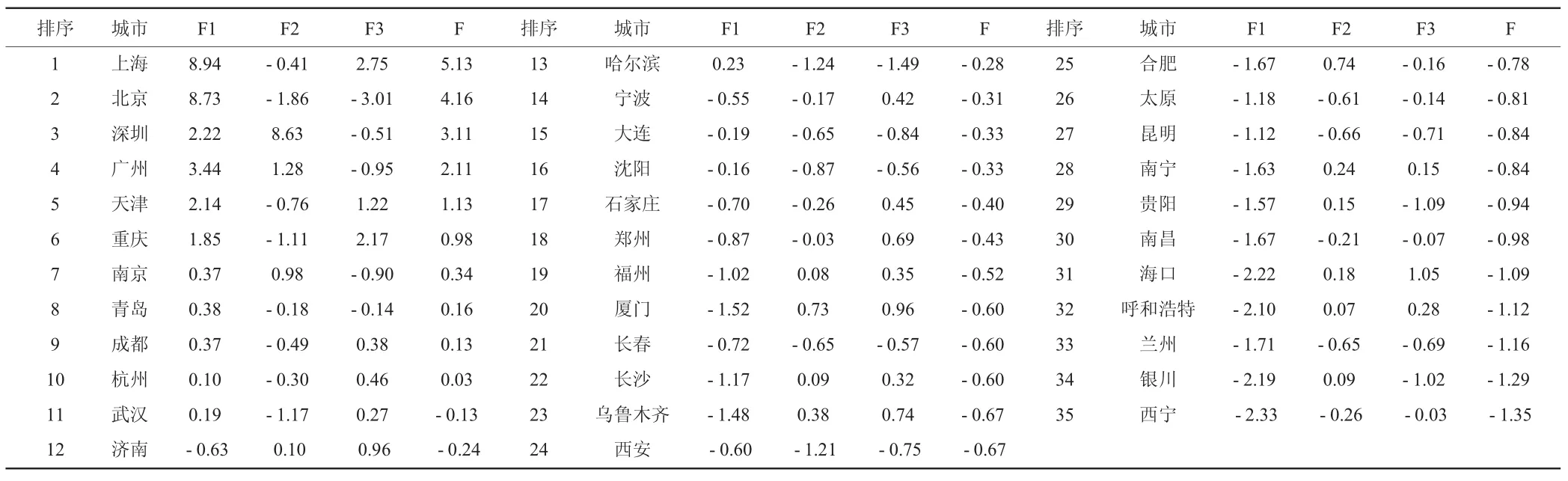
表5 主成分分析得分及综合得分表
如果相关系数矩阵中大部分相关系数都小于0.3且未通过统计检验,那么这些变量就不适合做因子分析。也就是说如果相关性较低,则他们不可能共享公共因子,只有相关性较高时,才适合于因子分析。表6所示这些变量适合做因子分析,指标反映信息有很大重叠。
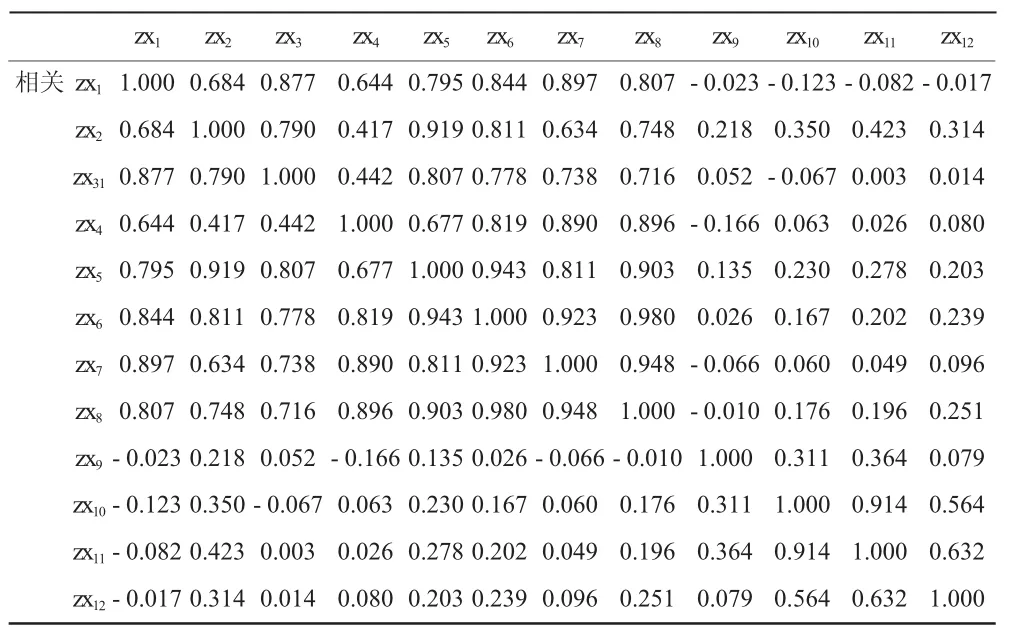
表6 因子分析中相关系数矩阵
如表7(左),KMO检验中,当所有变量间的简单相关系数平方和远大于偏相关系数平方和时,KMO值趋近于1,KMO值越接近1,变量间存在的相关性越强,越适合做因子分析,具体表现为0.9以上非常适合、0.8~0.9 很适合、0.7~0.8 适合、0.6~0.7一般、0.5~0.6不太适合、0.5以下不适合。表中KMO检验值为0.723,适合做因子分析。
如表7(右),巴特利特球形检验中,如果相关系数矩阵中统计量的值较大,且其相伴概率小于显著性水平,则拒绝相关系数矩阵是单位阵的原假设,原变量间存在相关性,适合做因子分析,表中显示球形检验的值为678.795,自由度为66,p值为0,小于0.05,故通过检验。

表7 KMO(左)和 Bartlett检验(右)
如果变量之间存在较强相互重叠传递影响,变量中确实能提取出公因子,则偏相关系数较小,即若反映像相关矩阵中某些元素绝对值较大,说明变量不适合做因子分析。因此,由反映像矩阵(略)也可得出变量间存在相关性、适合做因子分析的结论。
由表8显示前3个特征值大于1,同时这三个因子的方差贡献率占了87.105%,说明提取这3个公共因子可以解释原变量的绝大部分信息。此外,从因子分析碎石图(图略)也可看出趋势从第三个因子后趋于平稳,所以总体上应选取保留3个因子。
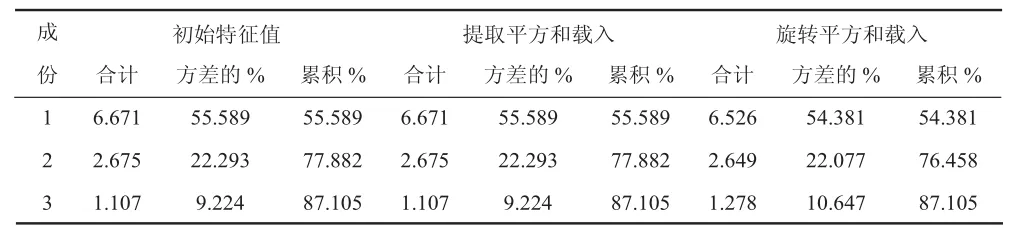
表8 成分1~3特征值与方差贡献表
表9是旋转前的因子载荷矩阵,表的底部显示出该表是用主成分方法对数据进行抽取,抽取了3个主成分。表10是旋转后的因子载荷矩阵,其按照方差最大正交旋转法对因子载荷矩阵进行旋转,将每个有最大负荷的因子的变量数最小化,简化对因子的解释。
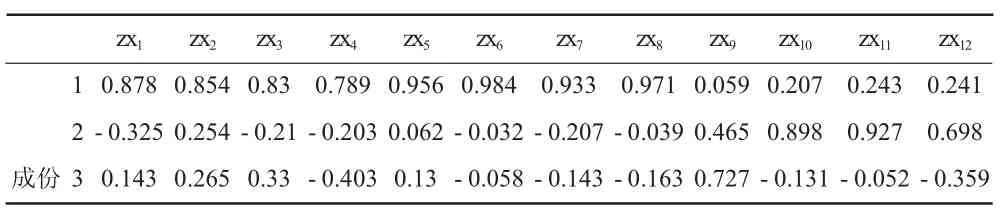
表9 旋转前成份矩阵a
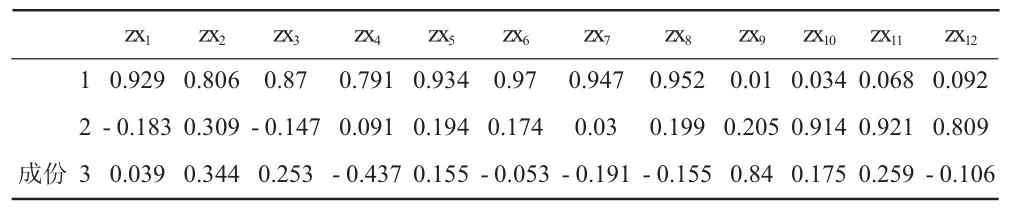
表10 旋转成份矩阵a
可见在因子载荷矩阵未经旋转时,因子变量在许多变量上均有较高的载荷,从旋转后的因子载荷矩阵表可以看出,因子1在zx1至zx8上有较大载荷,反映非农业人口数及在岗职工数和工资水平、第二第三产业水平、地方政府预算内收入及城乡居民储蓄水平等情况,可以命名为经济发展因子;因子2在指标zx9上有较大载荷,反映人均居住面积情况,可以命名为居住环境因子;因子3在指标zx10,zx11,zx12上有较大载荷,反映每万人拥有公共汽车数、人均拥有铺装道路面积、人均公共绿地面积的情况,可以命名为公共服务因子。
用方差极大法作因子转换。各因子综合因子得分为F=0.54381F1+0.22077F2+0.10647F3。进行计算并排序后得到因子得分及综合因子得分情况如表11所示。
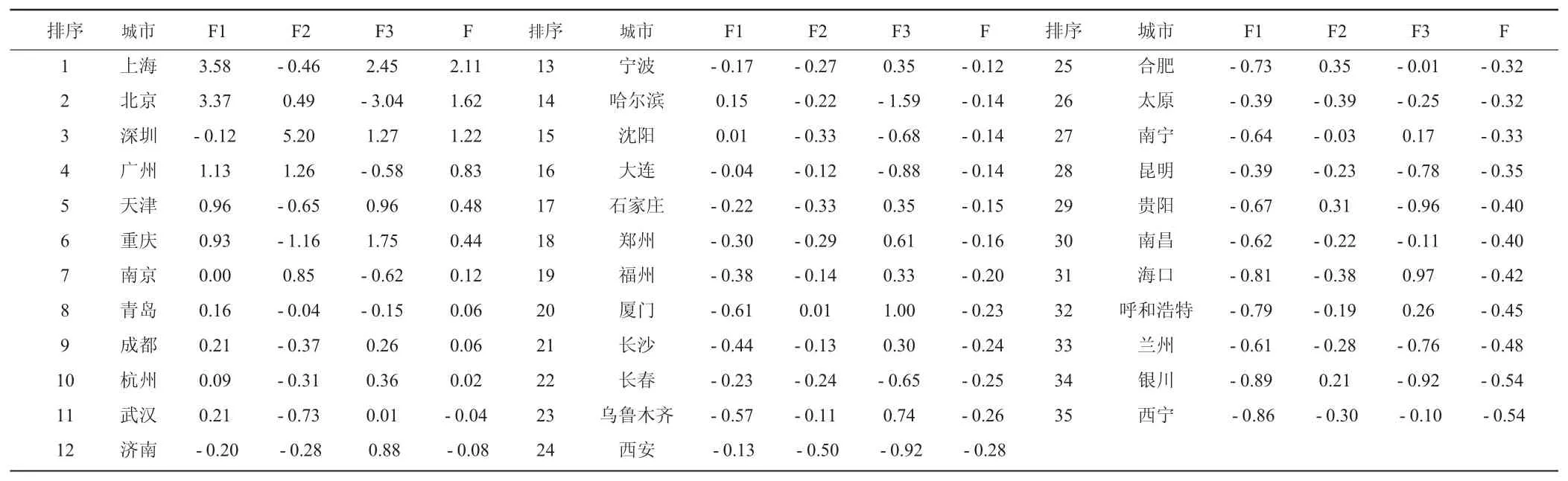
表11 因子得分及综合因子得分情况表
若综合因子得分为正,则意味着城市综合发展水平位于平均水平之上,得分为负则反之。可以看出,综合因子得分的结果上海最高,以下依次是北京、深圳、广州、天津等,西宁最低,较符合实际。主成分分析与因子分析的结果大致上是一样的,只在少数城市上有一些区别。
另外,北京、上海地区经济发展水平明显高于其他城市,而西部地区大部分城市经济水平位于全国平均水平之下。深圳、广州、南京等南方城市居住环境水平最高,这应该与气候、污染水平以及人口密度分布有关。上海、深圳、重庆、厦门、天津等直辖市和经济发展水平较高的城市公共服务质量也较高。而综合排名较低的城市居住和公共服务质量往往都很低。文章所得的结论基本与前期假设和预测一致。
三、结论与建议
本文分析评价了全国35个中心城市的社会经济发展水平。研究可得,各中心城市发展水平差异较为显著。北京和上海等东部沿海城市在全国35个中心城市中遥遥领先。推断由于改革开放以来,我国经济中心一直处于东部沿海地区,并且国家在经济政策上给予极大优惠;其次东部地区得天独厚的地理位置优势使交通运输发达,这也进一步促进经济发展,且改革开放后几十年来,政府大规模的资金投入使得东部地区实现了资本的迅速积累,经济发展水平逐年提升。同时,中西部地区许多城市综合发展水平明显偏低。推断不仅有自然条件的影响,也有历史影响因素。但主要原因是改革开放时我国采用的梯度式区域发展战略。当前国家实施西部大开发和一带一路战略就是为了加快这些城市发展以带动周边地区经济发展,这关系到我国国民经济能否持续高速发展。
针对全国发展地区失衡的状态,我国政府应该加强相应的宏观政策,具体提出以下措施:加大上海开发开放力度,建设国际中心城市;充分发挥经济各特区的“先发效应”作用,再创经济区新辉煌;加大西部中心城市投资力度,带动西部发展;顺应潮流,结合国情,调整城市发展战略;设立“综合经济开发试验区”,实施区域性扶贫开发。总之,我们要加快沿海地区经济的发展,从而来带动中西部城市的崛起,达到我国整体跨越式发展的目的[8]。
中国客观上正逐渐形成多个经济区,而各个经济区都必须以一定的中心城市为依托,加大全国中心城市的开发开放力度,对带动全国或区域经济的发展具有重要作用。经济的全球化、区域化和聚团化已成为当今时代经济的主旋律。建立各具特色的区域分工和合作格局,充分发挥地区比较优势,是实现我国经济长期快速、健康、协调发展的目标,是增强国家和各地区经济实力的重要措施。
[1]冯丹.四川省社会发展水平综合测评研究[D].西南财经大学,2006.
[2]彭丽,秦趣,苏维词,2009.重庆市县域综合发展水平差异的时空特征分析[J].世界地理研究(3):61-67.
[3]张萌,曹令秋,2010.基于因子分析综合评价方法的区域城乡经济发展水平监测的实证研究——以重庆为例[J].经济地理(9):1440-1443,1472.
[4]汪海凤,赵英,2012.我国国家高新区发展的因子聚类分析[J].数理统计与管理(2):270-278.
[5]汪海凤,赵英,2013.基于因子分析的我国各省市高新技术企业成长性比较研究[J].科技管理研究(4):59-64.
[6]丁红艳,陈建,张敏,2016.基于因子分析和聚类分析的新疆各地区经济发展水平综合评价[J].数学的实践与认识(4):36-43.
[7]吴玉鸣,刘鲁艳,2016.城市工业空间布局与区域协调发展水平综合评价及差异——环渤海地区与西部能源“金三角”比较[J].经济地理(7):91-98,113.
[8]方创琳,张永姣,2014.中国城市一体化地区形成机制、空间组织模式与格局[J].城市规划学刊(6):5-12.
(责任编辑:D 校对:R)
F299.23
A
1004-2768(2017)06-0097-05
2017-01-11
王秋红(1965-),女,河南洛阳人,西北师范大学经济学院教授,研究方向:产业经济、国际贸易;赵乔(1992-),女,山东济南人,西北师范大学经济学院硕士研究生,研究方向:国际贸易。赵乔为通讯作者。
