基于LDA主题模型的分布式信息检索集合选择方法
2017-07-18何旭峰陈根才王敬昌
何旭峰,陈 岭,陈根才,钱 坤,吴 勇,王敬昌
(1. 浙江大学 计算机科学与技术学院,浙江 杭州 310027; 2. 浙江鸿程计算机系统有限公司,浙江 杭州 310009)
基于LDA主题模型的分布式信息检索集合选择方法
何旭峰1,陈 岭1,陈根才1,钱 坤1,吴 勇2,王敬昌2
(1. 浙江大学 计算机科学与技术学院,浙江 杭州 310027; 2. 浙江鸿程计算机系统有限公司,浙江 杭州 310009)
该文针对分布式信息检索时不同集合对最终检索结果贡献度有差异的现象,提出一种基于LDA主题模型的集合选择方法。该方法首先使用基于查询的采样方法获取各集合描述信息;其次,通过建立LDA主题模型计算查询与文档的主题相关度;再次,用基于关键词相关度与主题相关度相结合的方法估计查询与样本集中文档的综合相关度,进而估计查询与各集合的相关度;最后,选择相关度最高的M个集合进行检索。实验部分采用Rm、P@n和MAP作为评价指标,对集合选择方法的性能进行了验证。实验结果表明该方法能更准确的定位到包含相关文档多的集合,提高了检索结果的召回率和准确率。
集合选择;分布式信息检索;LDA
1 引言
随着网络信息的膨胀,传统的集中式信息检索在面对海量数据时往往不堪重负。分布式信息检索系统[1](distributed information retrieval,DIR)将大范围分布的异构数据联合起来,形成一个逻辑整体,为用户提供强大的信息检索能力,被用来解决海量数据的存储检索问题。DIR系统通常由一个代理服务器和很多检索服务器组成。代理服务器提供统一的查询接口,负责将查询请求分发给各检索服务器。
将查询请求发送给所有信息集检索将导致大量的网络带宽消耗和较低的系统响应速度。集合选择,就是对每个查询请求,在代理服务器上决策出选择哪些信息集去检索,使得在较少的信息集合中检索,得到尽可能多的相关文档。
近十年来在分布式信息检索集合选择领域进行了许多研究,这些研究大抵可分为以下三类。
(1) 将集合中包含的文档看成一个逻辑整体,一个集合即是一个超大“文档”(big document),将计算查询与集合的相关度就转化为计算查询与文档相关度,按相关度的高低对各集合排序。
CORI[2]方法采用INQUERY推理网络计算集合相关度,关键词的权重用TF-IDF的方法计算。然后利用各集合与查询包含的词和词的权重,计算各集合与查询的相关度。Xu和Croft[3]建立语言模型并用集合和查询词的KL距离(Kullback-Leibler divergence)计算集合相关度,Si等人[4]基于语言模型以单个集合为语料库,通过各个语料库生成查询词的概率计算集合相关度。Yuwono等人提出了CVV方法[5],该方法引入了线索有效性(cue validity)的概念来描述词t对属于集合Ci中的文档和属于其他集合的文档的区分度。以上方法将各个集合中的所有文档看成一个逻辑上的统一整体,从而将分布式的集合选择问题转化为传统的查询词对文档的检索问题,然而由于虚拟文档与真实的文档之间实际上存在着很大的不同,如文档长度、主题等,以上方法倾向于选择小的、主题较少的集合,而不是大的、主题复杂、包含相关文档更多的集合,不适用于集合大小不均匀的环境。
(2) 估算集合中包含的与查询相关的文档数目,以相关文档数目的多少对各集合排序,从而选择排名较高的集合检索。
ReDDE[6]、CRCS[7]通过基于查询采样方法对各集合采样,构建中心样本,通过查询词和被采样文档的信息,估计各个集合和文档的相关度。SUSHI[8]方法在ReDDE方法及CRCS方法的基础上,通过曲线拟合的方法,用中心样本集检索结果中各文档的得分,估计原集合中各文档的得分,从而得到各集合的得分。以上方法通过估计各个集合包含的与查询相关的文档数,按包含文档数目从高到低对集合排序,能够有效定位到包含相关文档数目更多的集合。然而,对于返回topN个结果的检索请求,与查询最相关的文档未必包含在相关文档数目最多的集合,从而不会被检索到。
(3) 计算集合与查询的相关度得分,按得分的高低对集合排序。
SHiRE[9]将查询检索中心样本的结果构造成树结构,通过三种不同的遍历该树的次序的方法(Lex-S、Rank-S和Conn-S),分别得到三种不同的确定样本集检索结果影响的指数衰减数的方法,并以此指数衰减数确定文档对应集合的得分。
Cetintas等人提出基于历史查询的集合选择方法[10],通过历史查询结果指导新查询,新查询利用历史相似查询的结果进行集合选择。刘颖等人提出了基于历史点击数据的集合选择方法[11],通过历史查询的用户点击结果,以及新查询与历史查询的相似度,估计新查询与各集合的相关度。然而由于词语普遍存在二义性且查询比较简短,查询并不总能准确的表达出用户的信息需求,导致一些相关度得分高的文档和查询并不相关。
Wauer等人[12]提出了基于本体论的方法,该方法首先选取一组特定的主题,然后将查询与集合分别表示成关于这一组主题的向量,利用向量余弦计算相关度。但是该方法只能在特定的、主题集中的数据集下选取一组特定的主题,很难推广到其他数据集。
针对第三类集合选择方法存在查询与集合间语义关系分析不准确的问题,本文提出基于LDA[13]主题模型的集合选择方法LBCS。由于LDA主题模型克服了pLSI模型的过度拟合问题,同时,相比于聚类模型,LDA主题模型通过多个主题,可对大文档集进行更为准确的描述,因此,LDA主题模型在信息检索中得到了广泛的应用[14-16]。本文尝试在集合选择过程中引入LDA主题模型,以实现对查询和集合间语义关系的准确描述;同时,通过引入查询扩展,避免因查询词稀疏而产生的主题漂移问题。本文的主要工作如下。
(1) 在计算查询与样本集文档的相关度中,提出了基于关键词相关度和基于主题相关度结合的方法来估计查询与样本集中各文档的综合相关度的计算方法。
(2) 在计算查询与文档的主题相关度时,充分考虑二者潜藏的语义关系,提出了基于LDA主题模型的计算方法。
(3) 在得到查询与样本集中文档的综合相关度后,考虑各文档所属的原集合信息,提出了计算查询与集合相关度的方法。
(4) 设计实验对比了本文提出的LBCS集合选择方法和ReDDE、CRCS方法在测试集上的检索召回率和准确率,通过实验数据说明了方法的性能。
1 LBCS集合选择方法
1.1 分布式信息检索架构与LBCS方法流程
分布式信息检索系统结构如图1所示,由一个检索代理服务器和一组检索服务器构成。其中检索服务器中存放着各自的信息集合,并独立地检索各自的信息集合。检索代理服务器负责为每次的查询选择合适的检索集合及检索结果的合并。本文主要关注检索集合的选择问题。
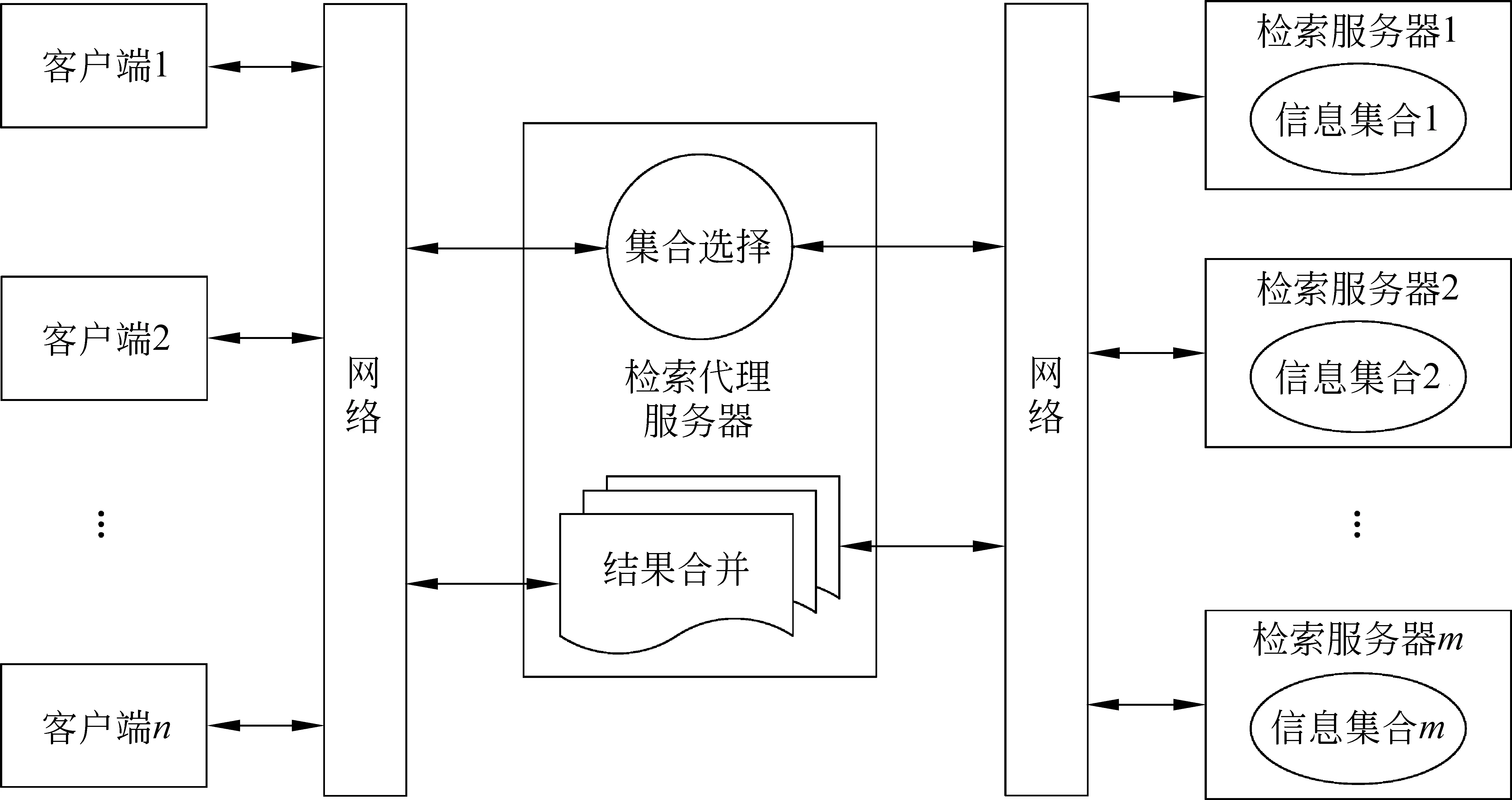
图 1 分布式检索体系结构
LBCS方法的总体流程图如图2所示,分为在线和离线两部分,离线部分包括: (1)检索代理服务器使用基于查询的采样方法[17]。对各集合采样,对于每个查询,各个集合返回前三个检索结果,在检索代理服务器上构建样本集;(2)检索代理服务器对样本集预处理,构建倒排索引,同时对样本集建立LDA主题模型,推导出主题—词分布φ,以及文档—主题分布θ。在线部分包括: (1)查询检索倒排索引,计算查询与各文档关键词相关度(计算方法见1.3.1节); (2)通过历史查询得到新查询的扩展查询,同时利用扩展查询和LDA主题模型推断出的分布计算查询与各文档主题相关度(计算方法见1.3.2节); (3)得到查询与样本集中各文档的综合相关度(计算方法见1.3节),并按相关度高低对各文档排序,然后以此计算查询与各集合的相关度(计算方法见1.4节),并按相关度高低对各集合排序;(4)选择排序结果最靠前的M个集合,将检索请求发送到这些集合。
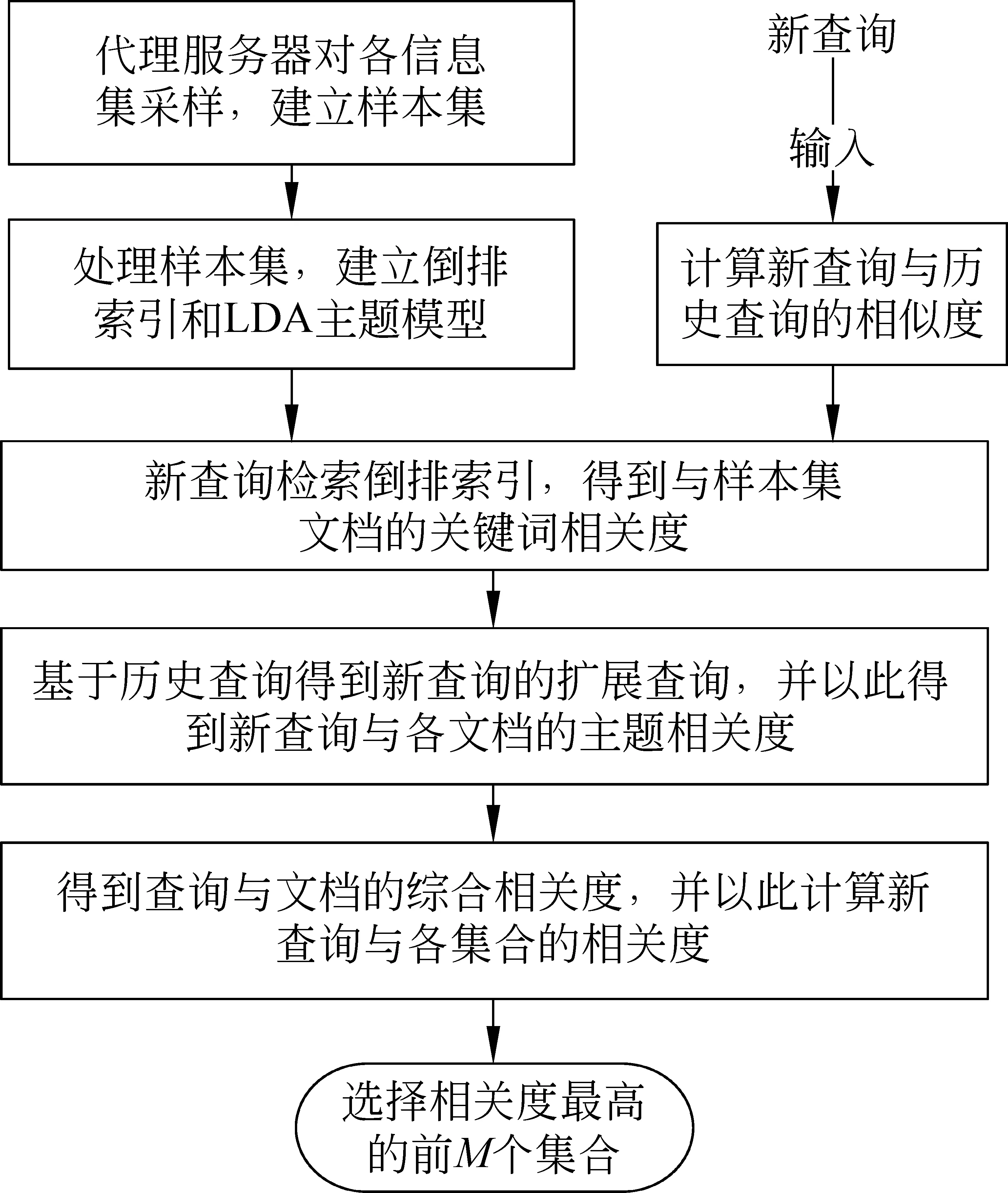
图 2 LBCS方法的总体流程图
在实际的系统中,各检索服务器的信息集合的内容不会一成不变,因而离线预处理部分需要定期的触发执行,从而不断的更新样本集合,为集合选择提供依据。而基于查询的采样方法和基于LDA的主题建模方法需要消耗不短的时间,为了保证在进行数据预处理时,检索系统能正常提供服务,需要以离线方式运行数据预处理模块。即假设当前存在样本集合Sample_1,集合选择利用样本集Sample_1的数据提供服务,当触发数据预处理模块时,集合选择继续使用样本集Sample_1的数据,直到数据预处理完成得到建模后的样本集Sample_2,集合选择再切换到使用样本集Sample_2的数据,然后删除原样本集Sample_1。
1.2 LDA主题模型
LDA主题模型,是一种完全的概率生成模型,目的是要以一种非监督的机器学习方法,由信息集各文档的词与词频的静态信息学习出信息集中文档与主题、主题与词的概率模型,然后按照学习出的概率模型可以有效的识别语料库或大规模文档集中隐藏的主题信息。LDA通过基于词袋的方法,将文档的文本信息转为成了形式化的数学统计信息。LDA生成文档集中的各个文档的步骤可以描述如下。
(1) 首先从文档集中任意选取一篇未读文档di;
(2) 基于狄利克雷参数α,从文档—主题分布θ中选取一个与文档di相关的主题zk;
(3) 对于选取到的主题zk,基于参数β,从主题—词分布φ中选取一个与该主题相关的词tj;
(4) 重复步骤(2)、(3)直到生成了文档di中的所有的词,将文档di标记为已读;
(5) 重复步骤(1)、(2)、(3)、(4)直到遍历完文档集中所有文档。
文档在主题空间服从多项式分布θ,主题和文档集中的所有词服从多项式分布φ,其中θ和φ的先验分布是狄利克雷分布,分别带有参数α和β。
LDA主要利用模型作者提出的变分-EM算法[13]和现在常用的Gibbs抽样法[18],来推断其参数,其结果包括文档—主题分布P(z|d,θ),主题—词分布P(w|z,φ)。本文使用Gibbs抽样法作为LDA参数的推理方法,利用LDA推断出的文档—主题分布与主题—词分布,计算查询词和文档的主题相关度。
1.3 查询与样本集文档相关度
定义1扩展查询。查询q={t1,t2, ...,tm},另一组查询为{p1,p2, ...,pn},其中每个查询pi都可以表示为一组词的形式pi={tpi_1,tpi_2, ...,tpi_mi},则查询q基于这组查询{p1,p2, ...,pn}的扩展查询q′ ={t1,t2, ...,tm,tp1_1,tp1_2, ...,tp1_m1, ...,tpn_1,tpn_2, ...,tpn_mn},扩展查询q′中的每个词的影响度为该词所属的原查询与查询q的相似度,即对于词t∈q′且t∈pi,词t在扩展查询q′中的影响度efft=sim(q|pi),其中sim(q|pi)为计算查询pi与查询q相似度的函数。
定义2词与文档主题相关度。一个词t与一组主题{z1,z2, …,zk}相关的概率为{Pt1,Pt2, …,Ptk},文档d与这组主题相关的概率为{Pd1,Pd2, …,Pdk},那么词t与文档d的主题相关度,即对于主题{z1,z2, …,zk},t和d相关的概率P(t,d) =Pt1×Pd1+Pt2×Pd2+… +Ptk×Pdk。
定义3查询与文档主题相关度。一个查询q由一组词{t1,t2, …,tj}构成,这组词对查询q的影响度分别为{eff1, eff2,..., effj},查询与文档的主题相关度即为查询中的各个词与文档的主题相关度,以及该词在查询中的影响度之积的累加和,即P(q,d) =P(t1,d) ×eff1+P(t2,d) ×eff2+… +P(tj,d) ×effj。
LDA主题模型提供了一种新的基于主题的文档建模方式,然而仅仅使用LDA主题模型本身用于检索过于粗糙而影响检索结果,使用LDA主题模型与传统检索方法结合有利于提高检索准确率。
文档与查询的得分由两部分线性组成,一部分是基于LDA主题模型的文档和查询的主题相关度,另一部分是基于词的文档与主题的关键词相关度。样本集当中的各文档与查询q的综合相关度为式(1)所示。
Score(di,q)=λ×Scorelda(di,q)+
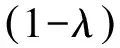
其中,λ取值为[0, 1]。各文档按照相关度排序,排序的结果用于估计集合和查询的相关度。
1.3.1 查询与样本集文档关键词相关度
式中,tfi为查询q或文档di中词ti出现的频率,idfi为逆向查询频率,dfi为包含ti的文档数,|S|为样本集文档总数。
1.3.2 查询与样本集文档主题相关度
由于查询通常包含的词较短,而词的二义性普遍存在,直接利用主题—词分布φ推断其主题过于粗糙导致不够准确,从而影响检索效果。LBCS方法使用历史查询词来扩展当前查询词,利用扩展查询来推断当前查询的主题。
由定义1可知,扩展查询中各词的影响度,与两个查询的相似度有关。查询q与历史查询p的相似度计算函数sim(p|q)需要满足以下条件: 首先,sim(p|q)的取值范围在[0, 1];其次,两个完全相同的查询相似度为1,即sim(p|q)=1;最后,两个查询的相似性越高,则sim(p|q)的值越大。相似度函数计算如式(6)所示。
其中,result(q)和result(p)分别为查询q和查询p检索样本集合得到的返回结果的文档集合。N(result(q)∩result(p))表示查询q和查询p检索结果中相同文档数,N(result(q)∪result(p))表示查询q和查询p检索结果中的文档总数(去重)。
扩展查询q′中的词tj与文档di在LDA主题模型中得出的主题{z1,z2, …,zk}上的主题相关度计算如式(7)所示。
其中,P(tj|zx,φ)为通过主题—词分布φ可以得到查询q中的词tj与主题zx相关的概率。而另一个P(zx|di,θ)为通过文档—主题分布θ得到的样本集中的文档di与主题zx相关的概率。
通过扩展查询q′中各个词与文档的主题相关度,可以得到扩展查询q′与文档di的主题相关度,计算如式(8)所示。
其中,eff(tj)为词tj对扩展查询q′的影响度。
我国从个人税收递延型商业养老保险开始试点,探索建立我国个人养老金体系。试点区域为上海市、福建省(含厦门市)和苏州工业园区,为期一年。我国个人养老金计划坚持账户多元化金融投资的方向,待试点结束后,还将根据试点情况有序扩大参与的金融机构和产品范围,将公募基金等产品纳入个人商业养老账户投资范围。
将之归一化得到原查询q与文档di的主题相关度,即
查询q与文档d的综合相关度计算的伪代码如算法1所示,首先,计算查询向量q的模和文档向量和查询向量的内积(第2~7行),计算文档向量d的模并计算查询与文档的关键词相似度,将相似度除以相似度最大值归一化,得到查询与文档关键词相关度(第8~12行)。然后,通过历史查询生成原查询q的扩展查询q′(第13行),计算扩展查询q′与文档的主题相关度,并将相似度除以相似度最大值归一化,得到原查询q与文档的主题相关度(第14~19行)。最后,计算查询q与文档的综合相关度(第20行),返回各文档的综合相关度(第22行)。

算法1:docsScore(q)输入:查询语句q输出:样本集中文档与查询的综合相关度1:FOReachdocumentdinthesamplecollection2: FOReachtermtinq3: normQ=getWeigth(q,t)×getWeigth(q,t);4: IF(d.contains(t))Then5: dotProduct+=getWeight(d,t)×getWeight(q,t);6: ENDIF7: ENDFOR8: FOReachtermtinq9: normD=getWeigth(d,t)×getWeigth(d,t);10: termSim=dotProduct/sqrt(normQ+normP);11: score_keyword=termSim/max(termSim);12:ENDFOR13:Expandqueryq′=Expand(q);14:FOReachtopiczinLDAmodel15: FOReachtermt′inq′16: p_qd+=getProbability(t′,z,φ)×getProbability(z,d,θ)×weight(t′|q′);17: score_lda=p_qd/max(p_qd);18:ENDFOR19:ENDFOR20:scorelist[d]=λ×score_lda+(1-λ)×score_keyword;21:ENDFOR22:RETURNscorelist[];
1.4 查询与集合相关度
将样本集里的各文档,按照与查询相关度从高到低排序,对于采样自不同集合中的两个文档,显然与查询相关度更高、排名更靠前的文档所在集合与查询的相关度更高。同时,在样本集的检索结果中,属于某集合的文档数量越多,则该集合对查询的贡献度越大,集合相关度就越高。
检索结果中的每个文档对其所在集合相关度的相关度权重为:
其中,dk为样本集中与查询的综合相关度排名为k的文档,Score(dk, q)为文档dk与查询q的综合相关度,|S|为样本集的文档总数,γ为样本集中与查询相关文档的阈值,表示与查询相关的有效文档数量,参数ratio表示检索结果的相关文档数占样本集文档总数的比例。
集合的大小也是评价集合相关度的重要因素。假设两个集合在样本集top γ个检索结果中拥有相同数量文档,由于基于查询的采样每个集合返回的被采样文档的总数目几乎相同,那么显然更大的集合可能包含有更多的相关文档。综合考虑上述因素,LBCS按如下的方式估计集合Ci与查询的相关度,即
其中,|Ci|为集合Ci包含的文档总数,Sci为样本集中采样自Ci的文档,|Sci|为样本集中采样自Ci的文档总数。
查询与集合相关度计算的伪代码如算法2所示,通过算法1得到样本集中文档与查询的综合相关度(第1行),对样本集中文档按其与查询的综合相关度从高到低排序得到排序列表(第2行)。选择排名大于阈值γ的文档(第4行),计算该文档对其所在集合与查询的相关度的影响(第5行),计算集合与查询的相关度(第6、7行),并返回各集合的相关度的得分(第9行)。

算法2:colRelevance(q)输入:查询语句q输出:各集合与查询的综合相关度1: scorelist=docsScore(q);2: ranklist=Rank(scorelist);3: FOReachdocumentdrankedkinranklist4: IF((k<γ)ANDdisincollectioncThen5: R_d=scorelist[d]×sqrt(1-k/γ);6: collist[c]+=R_d×NumOfDocs[c]/NumOfDoc[c_sample];7: ENDIF8: ENDFOR9: RETURNcollist[];
2 实验
2.1 测试集
实验使用的测试集为TREC数据集The ClueWeb09 Dataset Category B,包含有五千多万个英文网页,压缩后大小为229.9 GB。实验中,数据集被随机划分成100个大小不等的集合,这些集合中包含的文档数最多为123.3万篇,最少为14.3万篇,平均为50.2万篇,压缩后集合大小,最大为 6.25 GB,最小为821 MB,平均为2.29 GB。
TREC给出了基于该测试集的50个真实查询话题(TREC topic1-50),以及每个查询所对应的相关文档。
2.2 评价指标
Rm(召回率)、P@n(前n个检索结果的准确率)及平均准确率MAP通常被用作集合选择方法的评价指标。
其中,Ei为测试的集合选择方法选择的第i个集合中包含的相关文档的总数,Bi为理想的集合选择方法选择的第i个集合(理想的集合选择方法按集合中相关文档总数从多到少排序)中包含的相关文档的总数,Rm的值越大,说明被测的集合选择方法选出的集合序列越接近理想的集合排序。P@n表示在集合选择方法选出的集合中检索,返回前n个结果的准确度,P@n的值越大,则检索的准确度越高。本文中,Rm与P@n都是50个查询的平均值。
2.3 实验设置
2.3.1LBCS参数设置
本文的LBCS方法包含两个参数: λ和ratio。其中,λ为主题相关度得分在综合相关度得分的权重,λ越大表示主题相关度得分在综合相关度得分中影响更大。实验中设置λ=0.3,后面的实验结果也证明了λ取值0.3将获得不错的检索效果。参数ratio表示检索结果的相关文档数占样本集(所有集合)文档总数的比例,ratio过大将会引入许多不相关文档,ratio过小可能会过滤掉许多相关文档。Callan指出[6]在基于查询的采样中,样本集中相关文档数占样本集文档总数的比例取值为0.002~0.005。实验中设置ratio=0.003。
2.3.2LDA参数设置
在通过基于查询的采样方法对各集合采样构成样本集后,需要对样本集中的文档建立LDA主题模型。按照研究中的通常设定[16],设置α=50/K,β=0.01,实验显示α和β的值对最终检索效果的影响很小。另外需要确定的参数是LDA的迭代次数Iterations和主题数目K。采用Gibbs抽样法推断LDA的分布,迭代次数Iterations越大,推断出的分布越接近真实分布,但同时需要的时间也更长。图3显示了当K=400,M=5,n=10时,Iterations对检索结果准确度的影响,当Iterations小于170时,检索结果的准确率随着迭代次数Iterations的增加而显著的提高,而当Iterations大于170时,检索结果的准确率趋于平稳,本文选取Iterations=200。
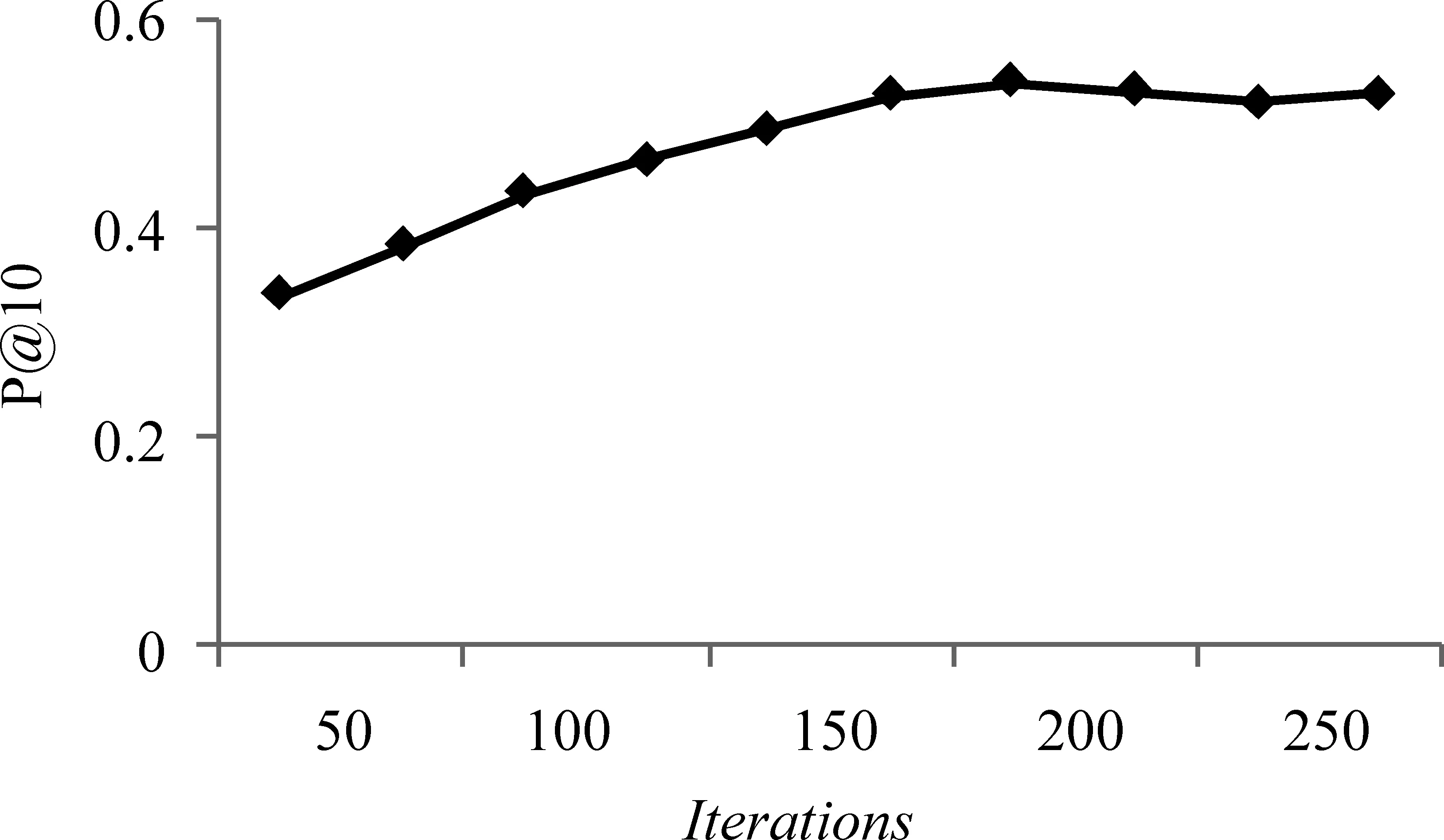
图 3 当K=400,M=5,n=10时,不同Iterations值对检索结果准确度的影响
选取合适的主题数目对建立的主题模型的优劣同样有着重要的影响。主题数过小不能充分的反映文档集合的主题,主题数过多建模时耗时越长。图4显示了当M=5,n=10时,主题数的多少对检索结果准确度的影响,当K到达一定数目时检索结果的准确率趋于平稳,实验证明取K=400能得到很好的检索效果。
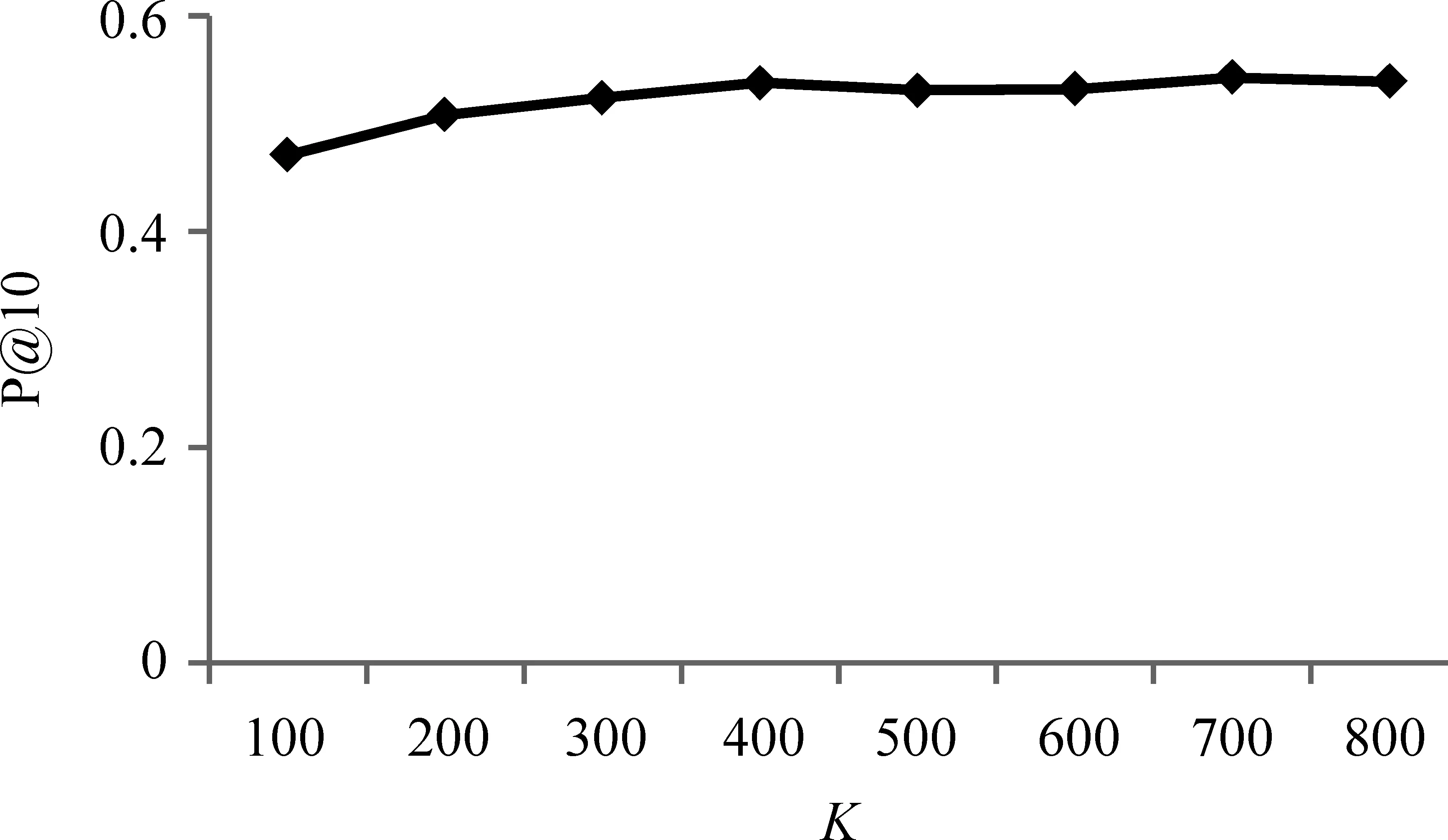
图4 当M=5,n=10时,不同主题数对检索结果准确度的影响
2.3.3 基准方法
ReDDE方法作为基准方法广泛地用于集合选择方法的研究,因而被本文选作基准的对比方法之一。由于CRCS(e)方法的效果显著得好于CRCS(l)[7],因而选择CRCS(e)方法作为基准的对比方法之一。在对比方法中,参数均按照原文中的设置,ReDDE方法的参数相关文档占样本集文档的比例取0.003,CRCS(e)方法的两个参数分别取1.2和2.8。
2.3.4 采样参数设置
实验采用基于查询的采样方法[18]获取各集合的描述信息。从查询日志随机选取1个查询作为初始查询词;每轮检索中,每个集合返回其检索结果的前3个文档加入到样本集合,并从样本集文档中随机抽取1个关键词作为下一轮检索的关键词。当样本集中的文档数量大于或等于所有集合总文档数的3%时,即停止采样。
2.3.5 合并策略
实验中采用两次往返的查询方式的检索合并策略。第一次统计全局信息;第二次将查询与全局信息发送到要检索的集合,以计算出文档的全局评分,使各文档的评分具有可比性。对于topn的查询,被检索的集合返回n个检索结果,检索代理服务器合并各集合返回的结果。
2.4 实验结果与分析
图5显示当分别选择1~10个集合时,ReDDE、CRCS(e)和LBCS三种集合选择方法在这50个查询下的平均召回率Rm值。在分别选择1~10个集合时,LBCS方法在每个集合数的召回率的值都高于ReDDE方法和CRCS(e)方法,较ReDDE方法和CRCS(e)方法分别平均提高14.2%和19.9%,当选择的集合数增大的时候,LBCS的Rm值增长更快。
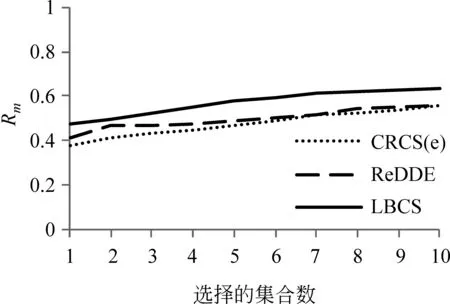
图 5 三种集合选择方法的召回率
实验结果表明,LBCS相较于ReDDE、CRCS(e)有更高的召回率,说明基于LDA主题模型的集合选择方法能有效地挖掘出查询和集合的语义层面的关系,使得LBCS能更准确地选择到包含更多相关文档的集合。
表1~表4显示了ReDDE、CRCS(e)和LBCS三种集合选择方法返回n个检索结果的准确率 P@n 结果对比,当三种集合选择方法分别选择相关度最高的2,5,7,10个集合进行检索时,50个查询分别返回5,10,15,20,30,40,50个结果的平均准确率。当选择2,5,7,10个集合进行检索时,LBCS较ReDDE准确率分别平均提高7.8%,8.8%,5.6%,4.8%,LBCS较CRCS(e)准确率分别平均提高8.7%,10.5%,6.8%,7.0%。结果表明,LBCS相比于ReDDE和CRCS(e)在选择相同集合数目时有更高的准确率,说明LBCS相比于ReDDE和CRCS(e)能够选择到与查询更相关的集合。

表1 选择2个集合时两个方法的准确率

表2 选择5个集合时两个方法的准确率
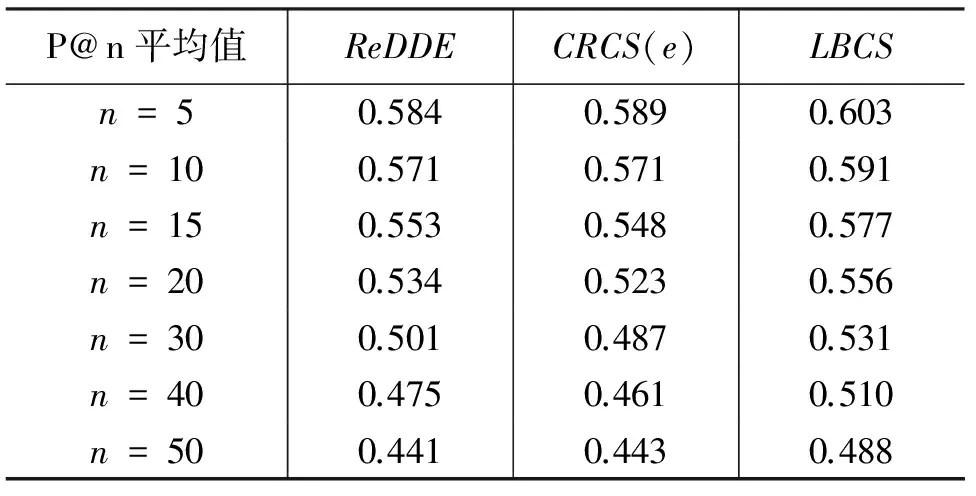
表 3 选择7个集合时两个方法的准确率

表 4 选择10个集合时两个方法的准确率
另外可以看到,当返回相同数量的检索结果时,选择的集合数目越多,三种方法的准确率越高。当选择同样数目的集合时,返回的结果数n值越大,即返回的检索结果越多,三种方法的准确率越低,说明随着返回的检索结果数目变大,更多的不相关文档会混入其中,并且当选择的集合越少时,随着返回结果数的增加,混入的不相关文档比例更大。
图6显示了对于50个查询(TREC topic1-50),CRCS(e)、REDDE和LBCS分别在选择2,5,7,10个集合时前10个结果的MAP值。当选择2,5,7,10个集合进行检索时,LBCS较ReDDE的MAP值分别平均提高9.2%,5.1%,3.7%,2.9%,LBCS较CRCS(e)的MAP值分别平均提高8.2%,7.7%,4.7%,3.8%。结果表明,LBCS相比于ReDDE和CRCS(e)在选择相同集合数目时有更高的MAP值,说明LBCS相比于ReDDE和CRCS(e)在得到相同的召回率时,检索结果的准确度更高。
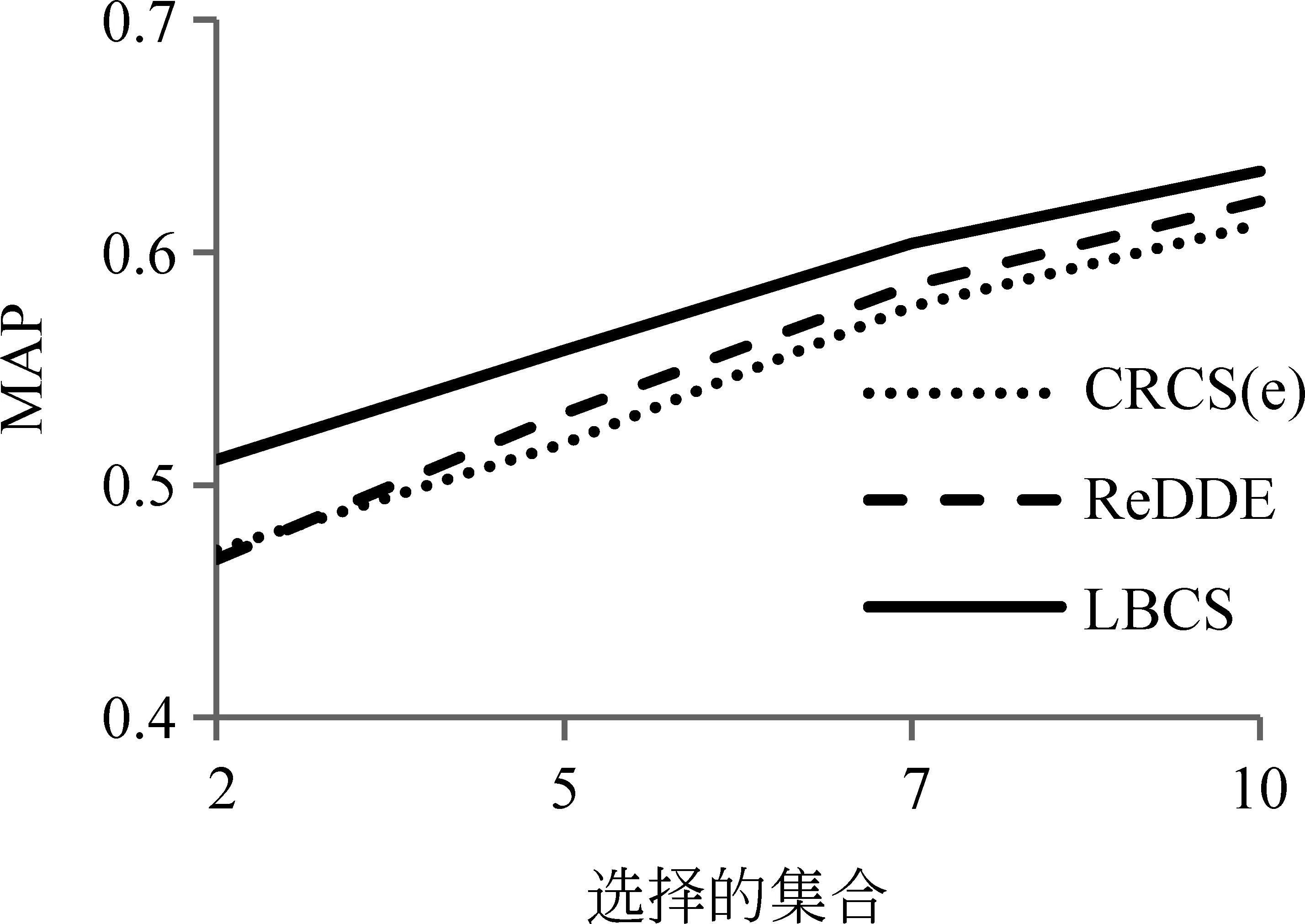
图 6 三种集合选择方法的MAP
3 结语
集合选择是分布式信息检索系统中的重要环节,可有效减少网络带宽消耗,减少检索时的计算开销,提高分布式信息检索系统的效率。本文提出基于LDA主题模型的集合选择方法LBCS,引入LDA方法对样本集建立主题模型。实验结果表明,LDA主题模型能有效挖掘查询与集合潜在的语义关系,从而选择到与查询更相关的集合,有效提高了最终检索结果的准确率及召回率。
本集合选择方法主要以提高检索准确率与召回率为目标设计的,然而在实际应用中,可能需要考虑更加复杂的因素,如检索服务器的吞吐率、负载、响应时间、各检索服务器的检索策略等。若能充分考虑DIR系统的性能及检索的准确度与召回率,建立统一的集合选择模型将是一个很好的研究方向。
[1] Callan J. Distributed information retrieval. Croft W B. Advances in information retrieval[M]. USA: Kluwer Academic Publishes, 2000: 127-150.
[2] Callan J P, Lu Z, Croft W B. Searching distributed collections with inference network[C]// Proceedings of the 18th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1995: 21-28.
[3] Xu J, Croft W B. Cluster-based language models for distributed retrieval[C]// Proceedings of the 22nd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1999: 254-261.
[4] Si L, Jin R, Allan J. et al. A language modeling framework for resource selection and results merging[C]// Proceeding of ACM Conference on Information and Knowledge Management. McLean, Virginia, USA, 2002: 391-397.
[5] Yuwono B, Lee D L. Server ranking for distributed text retrieval systems on the Internet[C]// Proceedings of International Conference on Database Systems for Advanced Applications. 1997, 97: 41-49.
[6] Si L, Callan J. Relevant document distribution estimation method for resource selection[C]// Proceedings of the 26th International ACM SIGIR Conference on Research and Development in Informaion Retrieval. ACM, 2003: 298-305.
[7] Shokouhi M. Central-rank-based collection selection in uncooperative distributed information retrieval[M]. Advances in Information Retrieval. Springer Berlin Heidelberg, 2007: 160-172.
[8] Thomas P, Shokouhi M. SUSHI: Scoring scaled samples for server selection[C]// Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2009: 419-426.
[9] Kulkarni A, Tigelaar A S, Hiemstra D, et al. Shard ranking and cutoff estimation for topically partitioned collections[C]// Proceedings of the 21st ACM International Conference on Information and Knowledge Management. ACM, 2012: 555-564.
[10] Cetintas S, Si L, Yuan H. Learning from past queries for resource selection[C]// Proceedings of the 18th ACM Conference on Information and Knowledge Management. ACM, 2009: 1867-1870.
[11] 刘颖, 陈岭, 陈根才. 基于历史点击数据的集合选择方法[J]. 浙江大学学报 (工学版), 2013, 47(1): 23-28.
[12] Wauer M, Schuster D, Schill A. Integrating explicit semantic analysis for ontology-based resource selection[C]// Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services. ACM, 2011: 519-522.
[13] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of Machine Learning Research, 2003, 3: 993-1022.
[14] 张俊林, 孙乐, 孙玉芳. 基于主题语言模型的中文信息检索系统研究[J]. 中文信息学报, 2005, 19(3): 14-20.
[15] 刘振鹿, 王大玲, 冯时,等. 一种基于LDA的潜在语义区划分及Web文档聚类算法[J]. 中文信息学报, 2011, 25(1): 60-65.
[16] Wei X, Croft W B. LDA-based document models for ad-hoc retrieval[C]// Proceedings of the 29th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2006: 178-185.
[17] Callan J, Connell M. Query-based sampling of text databases[J]. ACM Transactions on Information Systems, 2001, 19(2): 97-130.
[18] Porteous I, Newman D, Ihler A, et al. Fast collapsed gibbs sampling for latent dirichlet allocation[C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2008: 569-577.
ALDATopicModelBasedCollectionSelectionMethodforDistributedInformationRetrieval
HE Xufeng1, CHEN Ling1, CHEN Gencai1,QIAN Kun1,WU Yong2, WANG Jingchang2
(1. College of Computer Science and Technology, Zhejiang University, Hangzhou, Zhejiang 310027, China; 2. ZheJiang Hongcheng Computer System Co.,Ltd., Hangzhou, Zhejiang 310009, China)
Considering that different collections have different contributions to the final search results, a LDA topic model based collection selection method is proposed for distributed information retrieval. Firstly, the method acquires information about the representation of each collection by query-based sampling. Secondly, a method using the LDA topic model is proposed to estimate the relevance between the query and a document. Thirdly, a method based on both term and topic is proposed to estimate the relevance between the query and the sample documents, by which the relevance between the query and collections can be estimated. Finally, M collections with the highest relevance are selected for retrieving. Experiment results demonstrates that the proposed method can improve the accuracy and recall of search results.
collection selection; distributed information retrieval; LDA

何旭峰(1989—),硕士研究生,主要研究领域为信息检索。

陈岭(1977—),通信作者,博士,副教授,主要研究领域为普适计算、数据库。

陈根才(1950—),教授,主要研究领域为人工智能、数据库。
1003-0077(2017)03-0125-09
2016-02-13定稿日期: 2016-05-26
“核高基”国家科技重大专项(2010ZX01042-002-003);国家自然科学基金(60703040,61332017);浙江省重大科技专项(2011C13042,2013C01046);中国工程科技知识中心(CKCEST-2014-1-5)
TP391
: A
