基于矩阵分解的个性化推荐系统研究
2017-07-18张时俊王永恒
张时俊,王永恒
(湖南大学 信息科学与工程学院,湖南 长沙 410082)
基于矩阵分解的个性化推荐系统研究
张时俊,王永恒
(湖南大学 信息科学与工程学院,湖南 长沙 410082)
随着社交网络的快速发展,用户在使用社交应用时会产生大量有价值的数据。通过对社交网络进行数据挖掘,发现隐藏在数据中关联用户与物品之间的偏好关系。然后对用户建模分析,选择合适的推荐引擎进行个性化物品推荐,这是一个非常有价值的研究方向。该文重点研究矩阵分解算法对处理大规模用户与物品评分矩阵的推荐效果,为了提高推荐的准确度展开了对用户社交关系和隐性反馈的研究,在组合预测模型中加入社交关系、人口统计学信息配置项、用户的消费记录等隐因子项,通过实验验证了扩展之后的混合预测模型在RMSE值上比SVD算法降低了0.259 475,在推荐性能有较大幅度的提高。
矩阵分解;个性化推荐系统;社交网络;用户建模
1 引言
随着社交网络和电子商务的快速发展,推荐系统在学术界和工业界的研究变得日益火热。搜索引擎和推荐系统都是解决信息过载问题的有力工具,搜索引擎是一种主动式搜索信息工具,用户通过关键字在搜索引擎上找到想要的信息。推荐系统是自主的提供信息推荐工具,它学习用户的历史行为数据,获取用户的兴趣偏好,将物品列表以topN顺序推荐给用户。推荐系统广泛应用于社交网络中,近年来越来越多的用户在使用社交网络,如国外的Facebook、Twitter国内的微博等。据2014年新浪微博用户发展报告可知,微博的月活跃用户数为1.67亿,用户每天发布博文数量超过1亿条。基于社交网络如此巨大的用户和数据,在本文中将搭建基于社交网络的推荐系统平台。服务于信息生产者,向信息消费者推荐社交网络上对他们有价值的信息流;或者服务于商品厂家,将商品厂家的产品推荐给潜在感兴趣的用户。推荐系统的任务就是联系用户和物品,将合适的物品推荐给合适的用户。本文的课题是基于微博做个性化推荐研究,结合微博上丰富的上下文信息(如用户之间的社交关系、用户隐性反馈)实现高准确度的个性化物品推荐。
目前基于社交网络的推荐研究在国内可以分为三类: (1)信息流的会话推荐,如文献[1]使用推荐系统将用户可能感兴趣的微博靠前放置,帮助用户更快更好的获得信息;(2)给用户推荐好友,增加用户社交圈子,如文献[2]主要是为用户做好友推荐,挖掘出用户潜在有价值的好友去关注扩大用户的社交圈子;(3)利用用户的社交网络信息对用户进行个性化物品推荐,实现用户与商家互赢,如在文献[3]中作者用LDA主题模型[4]向用户推荐物品,以及文献[5]中的基于微博营销,作者用数据挖掘相关技术推荐物品给潜在用户。本文着重研究物品推荐,难点在于用户与物品的规模较大,评分数据稀疏,用户的反馈数据隐藏在海量数据中,获取和建模较难,混合预测模型参数的学习开销较大。
在基于矩阵分解的推荐系统研究上,国内外的一些研究工作具体如下。如Pu 等人基于SVD 从训练数据中重构一个潜在特征的空间,也就是将missing rating 给补上,并用hyper graph模型证明理论[6]。Liu等人将上下文信息作为多维用户物品评分矩阵,它区别于一般的二维用户物品评分矩阵,可提高关联评分的准确度[7]。Pagare等人将用户社交关系考虑进来,重新设计一个目标优化函数[8]。Jamali将社交网络中用户之间的信任度考虑进来,并得到不错的推荐效果[9]。Ma等人通过考虑社交网络中的上下文信息进行更加精准的推荐[10]。这些国内外最新的研究成果很大地促进了推荐算法在工业界和学术界的发展。
对于社交推荐系统,研究者研究的重点和难点,主要分为三个方面。首先是用户的兴趣偏好和物品的特征提取。在推荐系统中初始用户的兴趣偏好存在初始数据不够多,兴趣偏好精度不够细等问题;其次是研究的多维度问题,在推荐过程中为了提高推荐的准确度,需要考虑各种上下文信息,在不同的维度下推荐的结果会不一样,只有充分利用用户的反馈数据,以及涉及用户和物品的上下文信息,才会获取更加准确的推荐效果;最后是推荐性能评价指标问题,用户对算法准确度的敏感度、算法对物品的普适度、选择何种评价指标是推荐系统领域研究的难点。
本文中针对以上重点和难点做了以下几部分工作。首先基于微博提出了一个离线的推荐系统框架,框架包括用户兴趣建模模块和推荐引擎模块;其次基于矩阵分解算法结合微博系统的上下文特征对矩阵分解模型做了多个部分的扩展,比如对引入的上下文信息,包括人口统计学信息(如年龄、性别)、互相关注的好友集合、用户的消费记录等。本文通过不同方式将不同类型数据建模在同一混合预测模型中,充分地优化了预测模型的性能。通过实验验证了扩展之后的混合预测模型在RMSE值上比SVD算法降低了0.259 475,在推荐性能上有较大幅度的提高。
2 用户建模
新浪微博是国内最大的微博平台,数以亿计的用户在微博上传播与自身相关的信息。对用户建模的目的是获取一个增量式的用户配置文件[11](user profile)。通过微博爬虫系统爬取用户的微博文本数据、用户的上下文数据、用户的注册数据,从而构建成用户的配置文件。由于微博用户中存在大量的垃圾用户(僵尸粉、广告推销账号)、各类机构认证平台(包括政府机构、高校、新闻平台、报纸媒介、电视平台、明星等)。这些用户在微博平台主要发表与本身无关的信息,如僵尸粉是为了作为成为别的用户粉丝的一员而存在,它们不会或者很少发表有关自身的博文;再如各类机构认证平台(如@湖南大学),这些账号是为了宣传各自机构的相关信息,所发表的信息也不会关联自身与物品的偏好。而普通用户关注自己感兴趣的账号,发表的微博内容一部分会关联用户本身与某些物品之间的信息,还会与自己的社交好友进行互动。所以,我们研究的用户就是普通用户。
为了过滤掉垃圾用户,在对用户进行数据爬取前,需要对用户进行预处理。用户预处理[12]可以减少无价值用户带来大量数据处理所占用的资源。本文系统将用户活跃度、用户行为总和作为过滤指标对垃圾用户处理。对于认证用户(包括蓝V和橙V),经过观察发现,这部分账号与我们所研究的用户对象是不相匹配的,也排除在用户集合之外。得到用户集合之后,根据用户ID爬取与用户相关的大量文本信息。在处理这些文本信息时,本文主要要获取的是基于用户有价值的信息,包括用户在过往历史上发表的微博内容、用户与其好友在评论上的互动、用户的注册信息。通过机器学习算法对微博内容分类:(a)用户消费记录,(b)用户对某物的偏好信息,(c)用户潜在的需求信息,(d)其他。对微博文本分类之后,对文本的处理分为三个部分:中文分词、特征提取、情感分析。对于a类文本只需要提取用户与物品消费记录。对于b类文本需要进行情感分析[13],微博短文本情感分析主要有两种方法:情感词典和机器学习方法。对于c类文本的处理等同于a类文本的处理,即提取出用户与物品之间的需求记录。d类信息不做处理,无须存储到用户的user profile中。
配置每个用户的user profile,用xml或son文本格式对用户信息标记存储。这种半结构化文档格式在对文档进行向量化操作时具有简单、快速的优势。User profile存在增加、修改、删除、解析等行为。存储在用户建模文件中的这些数据分为三层:
(1) 评分数据构成了评分矩阵M的初始数据。
(2) 潜在用户需求数据通过评分函数转化成评分矩阵继续存储到矩阵M中。
(3) 还有一层是用于训练预测模型,其分为三类: (a)用户消费记录,(b)人口统计学信息如年龄、性别等,(c)用户之间的社交关系,即互相关注的好友UID集合。
3 评分函数
对用户的配置文件进行处理,第一层——用户与物品的偏好信息直接存储到评分矩阵M中。第二层用户对物品潜在的需求信息将通过一个评分函数R[见公式(1)]计算出评分值,也存储到矩阵M中。评分函数需要考虑两个方面,一个是用户u已经评分了的所有物品的平均值,另一个是计算得到用户与用户之间的相似度,然后将不同的用户在同一物品的评分差与这两个用户之间的相似度相乘,对该项式进行正规化。
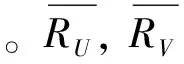
计算用户对物品的评分的主要思想是计算与用户关联的物品集合准确的评分,一般而言是用户潜在的需求物品。用一个数组存储已确认的用户对物品评分,通过设计一个评分函数描述用户对物品的不确定评分转换为确定评分。在评分函数中主要的计算量体现在计算用户之间的相似度。对计算评分函数的算法描述如算法1所示,其中floor()函数为向下取整函数,ceil()函数为向上取整函数:

算法1:计算用户U对物品I的评分(1-5)1:Input:user_avg_rating[USER_NUM]:存储每个用户已经评分了的所有物品的平均值。2:ψ:对同一物品I评分的所有用户集合。3:M:用二维数组存储用户与物品的评分值。从该数据结构中读取出不同用户对不同物品的评分值。4:Output:RUI:用户U对物品I的评分值,将其存放到M中5:while(v∈ψ):6:computeKbyEq.37:K∗=(RVI-RV)8:endwhile9:computeRUIbyEq.1,对RUI整合如下:RUI=floor(RUI);if(floor((RUI-floor(RUI))×10)<5)ceil(RUI);Otherwise{11:Update:user_avg_rating[USER_NUM],M
4 矩阵分解
矩阵分解算法[15]是近几年来在推荐系统领域最流行的算法,特别是在Netflix大赛的激励下许多基于矩阵分解去解决推荐系统问题的论文层出不穷。矩阵分解能充分利用各种因素的影响,如社交关系、上下文信息等,可以带来更好的推荐结果,具有非常优秀的可扩展性。矩阵分解通俗来说就是如何通过降维的方法将评分矩阵补全,用户的评分行为可以表示成一个评分矩阵R,其中R[u][i]就是用户u对物品I的评分。但是用户不会对所有物品进行评分,所以这个评分矩阵中很多元素是空的,这些空的元素称为缺失评分,因此评分预测从某种意义上说就是填空,如果一个用户对一个物品没有评过分,那么推荐系统就要预测这个用户是否会对这个物品进行评分,及会评多少分。
4.1 奇异值分解
矩阵分解一般采取SVD[16]及PCA[17]方法。SVD是一种重要的矩阵分解方法,如公式(4)所示,在实际应用中只关心矩阵的主特征,前10%甚至1%的奇异值之和就占有全部奇异值的90%以上,所以可以忽略较小的奇异值,用一部分较大的奇异值来近似描述矩阵。在应用中可以降低运算复杂度,减少存储内存。
k是一个远远小于m、n的数值,右边的矩阵相乘的结果是一个近似A的矩阵。SVD常用来降维,在实际应用中将输入评分矩阵映射到一个低纬空间,然后分析潜在的用户与物品之间的偏好关系。基于LatentFactorModel[18],通过最小化损失函数的方式学习用户特征矩阵和物品特征矩阵。最基础的分解公式为等式(5),评分矩阵R被分解成两个低纬矩阵VT∈Rl×m,U∈Rl×n。这两个矩阵将用户和物品投影到一个相同的l维度空间,这个空间是不定性的,它可以看成是影响用户对物品进行评分的各个因素。
加上预测基准的的评分预测模型Bias-SVD,其可表示为公式(6),μ表示全局评分的平均数,bi是物品偏置项,bu是用户偏置项。实际学习中bi和bu是经过学习训练等式(7)得到的。
4.2 组合预测模型
在每个用户的userprofile中第三层的a类消费记录作为隐性反馈加入到预测模型中。我们不管用户是否对物品进行评价或者评价程度,只需要确定这种消费是否发生。用一个二值矩阵表示[19],0 表示用户未对物品消费,1 表示用户已经消费过物品。此时预测模型为公式(8)。其中Ru包含了用户u评价过的物品以及通过评分函数获得的物品集合,yj是一个指示函数用户u对物品j消费过则值为1,否则值为0。

(8)
在每个用户的userprofile中第三层的b类为人口统计学信息,如用户的年龄,性别,职业等。这些信息对预测用户与物品之间的兴趣程度也有非常大的影响。在预测模型中应该将这些信息加入进去。因此使用双线性模型[20]对人口统计学信息中的年龄和性别建模。将年龄分为k个组,每个组按照性别分为二类,所以得到2k个组。令g(u)为用户u所属的组编号(1<=g(u)<=2k)。eg(u)是单位向量第g(u) 值为1,其余为0.w为参数矩阵将向量空间映射到一个k维空间。βi为系数向量。加上双线性模型之后的预测模型为式(9)。
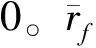
4.3 预测模型参数学习
用一个平方损失函数表示我们需要获得的学习结果,该函数表示如式(11)所示。
然后对该损失函数求最小解。采用SimonFunk[21]提出的随机梯度下降法,对训练集中的所有评分进行循环,对于每一个评分值,计算实际评分与计算评分的误差[见式(12)],通过求参数的偏导数找到最快速的下降方向,迭代优化参数bu、bi、Uu、Vv、W如式(13)~式(17)所示。
其中,r表示学习速率,eui表示真实评测值和预测值之间的偏差。对参数进行学习的过程,会趋于一个拟合的状态。通过迭代能得到预测之后的用户物品的评分矩阵,通过排序、过滤等操作最终得到一个TopN的物品推荐列表。
5 实验
实验基于新浪微博爬取的大量微博数据,包括用户所有微博文本、用户人口统计学信息(如性别年龄等)、用户的社交关系(即用户关注的好友列表)。因为缺乏合适的数据集,在用户建模阶段根据HTMUNIT开源工具开发了基于微博的爬虫系统,一共抓取了63 641个用户,2 484 455条微博内容。经过预处理得到10 847个用户,对每个用户建模分析,将每个用户的人口统计学信息、社交关系中关注的好友列表都存储在数据库中。数据集规模如表1所示。

表1 数据集规模
采用均方根误差RMSE和评价绝对误差MAE对实验结果进行评价。这两个评价指标的值越低表示预测的准确度越高。然后是平均准确率MAP@3,值越大表示越准确。
预测模型在不同规模训练集下取得的评测值如表2所示,从表中可以观察到训练集的规模越大,RMSE和MAE值越小,表示预测用户对物品的评分准确度越高。该实验K值为100,是固定的,K表示将潜在用户特征向量及潜在物品特征向量映射到K维的矩阵空间,K也可以理解为选取用于预测的特征数量。
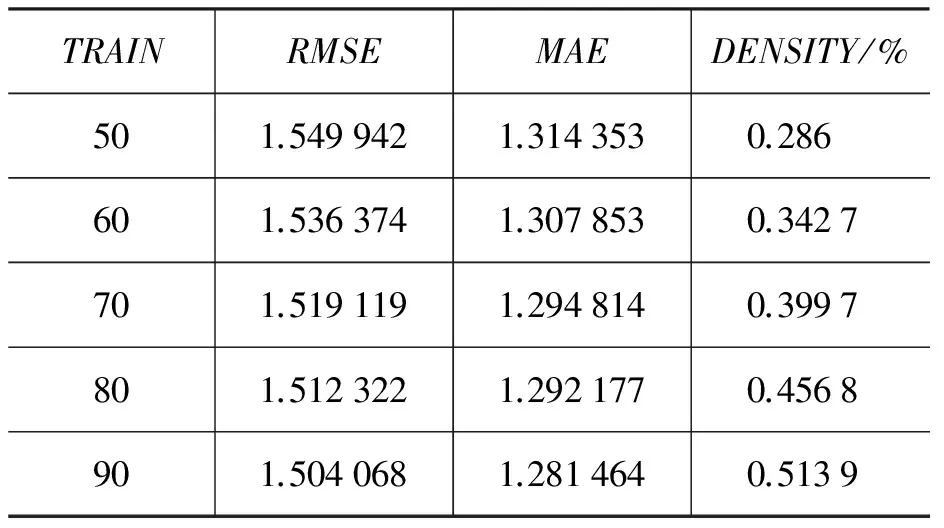
表2 预测模型在不同规模训练集下取得的评测值
图1和图2表示在不同K值下,相同的训练规模80下的RMSE和MAE值的变化范围。从图中可以观测到选取的K值不是越大越好,而是要选择最合适的K值才能得到最准确的预测值。在本次实验中K为60时,推荐的准确度最高。这也反映了矩阵分解算法在推荐系统里对结果的解释没有协同过滤那么直接。

图1 预测模型在不同K值下的RMSE值

图2 预测模型在不同K值下的MAE值
表3表示在相同数据集,相同训练规模80%下,基于用户的协同过滤算法(Based User CF)、基于物品的协同过滤算法(Based Item CF)、SVD、预测模型(prediction Model)得到的评测值RMSE和MAE。从表3可以看到在数据集下,矩阵分解算法预测准确度优于协同过滤算法,预测模型预测准确度优于SVD。

表3 不同算法的评测值
另一个实验评价指标采用平均准确率MAP@3,其值越大表示推荐精度越高即预测模型越准确,表4表示相同数据集下,加入不同信息融合的预测模型运行的结果。从该表中看到实验号为3到8加入不同类别的建模信息都能有效的提高模型的准确度,其中加入用户社交关系信息实验指标增加的幅度最大,表示用户社交关系信息对模型的提高最大。

表4 不同组合预测模型的准确度
6 结语
本文基于新浪微博系统,对普通用户进行建模分析,获得用户非常丰富的人口统计学信息和用户在历史文本中表现用户与物品之间有价值的信息,以及基于用户的上下文信息(主要包括用户之间的社交关系)。预测模型基于SVD算法,通过组合上述数据构建一个组合预测模型,充分利用了用户的反馈数据,比如将用户的消费记录作为物品的隐因子加入到预测模型中,通过实验发现能较大提高模型的预测精确度。采用双线性模型对人口统计学信息建模,作为配置项加入到预测模型中。社交关系是最重要的上下文信息,在现在的推荐系统研究中,上下文信息是研究的重要部分,本文将用户的社交关系作为物品的隐因子加入到预测模型中,通过实验验证了该预测模型具备更加优异的预测准确度。
[1] 慕福楠. 面向微博用户的推荐多样性研究[D]. 哈尔滨工业大学硕士学位论文, 2013.
[2] 石丽丽. 面向微博用户的内容与好友推荐算法研究与实现[D]. 北京邮电大学硕士学位论文, 2014.
[3] 张晓婕. 基于微博用户兴趣模型的个性化广告推荐研究[D]. 华东师范大学硕士学位论文, 2014.
[4] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. the Journal of machine learning research, 2003, 3: 993-1022.
[5] 王利. 基于数据挖掘技术的微博营销系统的设计与实现[D]. 华中科技大学硕士学位论文, 2013.
[6] Pu L, Faltings B. Understanding and improving relational matrix factorization in recommender systems[C]//Proceedings of the 7th ACM conference on Recommender systems. ACM, 2013: 41-48.
[7] Liu X,Aberer K. SoCo: a social network aided context-aware recommender system[C]//Proceedings of the 22nd international conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2013: 781-802.
[8] Pagare R, Patil S A. Social recommender system by embedding social regularization[C]//Proceedings of Advance Computing Conference (IACC), 2014 IEEE International. IEEE, 2014: 471-476.
[9] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010: 135-142.
[10] Ma H, Zhou T C,Lyu M R, et al. Improving recommender systems by incorporating social contextual information[J]. ACM Transactions on Information Systems (TOIS), 2011, 29(2): 9.
[11] Manzato M G, Goularte R. A multimedia recommender system based on enriched user profiles[C]//Proceedings of the 27th Annual ACM Symposium on Applied Computing. ACM, 2012: 975-980.
[12] 崔春生. 不同推荐系统输入的聚类实现[J]. 应用泛函分析学报, 2014, 16(2): 121-128.
[13] Xiong X B, Zhou G, Huang Y Z, et al. Dynamic evolution of collective emotions in social networks: a case study of Sina weibo[J]. Science China Information Sciences, 2013, 56(7): 1-18.
[14] 项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.203-204.
[15] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the fourth ACM conference on Recommender systems. ACM, 2010: 135-142.
[16] Rokach L, Shapira B, Kantor P B. Recommender systems handbook[M]. New York: Springer, 2011.
[17] Jolliffe I. Principal component analysis[M]. John Wiley & Sons, Ltd, 2002.
[18] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. Computer, 2009 (8): 30-37.
[19] 余秋宏. 基于因子分解机的社交网络关系推荐研究[D]. 北京邮电大学硕士学位论文, 2013.
[20] Tenenbaum J B, Freeman W T. Separating style and content with bilinear models[J]. Neural computation, 2000, 12(6): 1247-1283.
[21] Funk S. Netflix update: Try this at home[DB/OL], http://sifter.org/simon/;journal/20061211.html(2006).
PersonalizedRecommenderSystemBasedonMatrixFactorization
ZHANG Shijun, WANG Yongheng
(College of Information Science and Engineering Hunan University, Changsha, Hunan 410082, China)
With the development of social network, there is a large amount of valuable information produced by social network users. This paper focused on the personification recommender system based on matrix factorization. In order to improve the recommender systems, we study the user social relationship and the implicit feedback of user. We add in the matrix factorization optimization function by a social regularization, a demographic information configuration item, and the consumer records as item’s latent factor bias. Experiments indicates a decrease in RMSE by 0.259475 achieved by the proposed method than SVD algorithm.
matrix factorization; personalized recommender system; social network; user mode

张时俊(1991—),硕士,主要研究领域为推荐系统、数据挖掘。

王永恒(1973—),博士,副教授,主要研究领域为大数据、数据流处理及人工智能。
1003-0077(2017)03-0134-06
2016-02-21定稿日期: 2016-05-07
国家自然科学基金(61371116)
TP391
: A
