基于K-means聚类的大学生综合素质评定方法
2017-06-29冯小芹胡晓辉孙晨旭向朝参喻赛萱
冯小芹,何 宏,胡晓辉,孙晨旭,向朝参,喻赛萱
(1.中国人民解放军后勤工程学院, 重庆 401331; 2.四川文轩职业学院, 成都 611330)
基于K-means聚类的大学生综合素质评定方法
冯小芹1,何 宏1,胡晓辉1,孙晨旭1,向朝参1,喻赛萱2
(1.中国人民解放军后勤工程学院, 重庆 401331; 2.四川文轩职业学院, 成都 611330)
随着教育改革呼声的提高,科学评定高等院校学生的综合能力素质成为各大高校的焦点。民主测评常常被作为大学生综合素质能力的评定方法,然而由于民主测评的不确定性和不可控性以及学生实际综合能力的复杂性,如何基于民主测评来客观、可靠、准确地评定学生综合素质能力是一大难题。针对该问题,提出了基于K-均值聚类的大学生综合素质评定方法。首先将民主测评数据处理成数据矩阵,然后通过K-均值聚类进行数据矩阵的预处理,剔除不准确、不可靠的民主测评数据,最后根据保留数据进行学员综合能力素质评定。基于重庆某高校12个专业278名学生的实际民主测评数据的实验结果表明:所提方法能够较为客观、准确地评定学生综合素质。同时,理论分析表明算法复杂度较小。
民主测评;K-均值聚类;学员综合素质能力
随着时代的发展、科技的进步,国力的竞争越来越取决于劳动者的素质。高校作为国家高素质人才培养的摇篮,为社会提供专业精、能力强、素质高的新型综合人才是时代赋予的一个新任务[1]。大学生综合素质评定是实现这个任务的关键一环[2]。一方面,评估结果可以作为反馈,检验高等教育改革成果,指导高等教育进一步地改革和完善;另一方面,大学生综合素质评估有利于大学生人才资源的合理分配,做到人尽其才[3]。在实际操作中,量化指标数据是开展学生综合素质评定的基础,而数据采集方法的科学性决定了所得数据的客观性,也影响着评价结果的公平性与合理性[4]。
传统的大学生综合素质评定大多数都是通过考试采集数据而后进行评定的,可这并不能代表学生综合素质[2],因为考试所得的数据并不能综合表现学员素质。为打破目前大学生综素质评定数据采集不够全面的现状,本文提出了一个新的方法:先获取民主测评数据,针对民主测评数据进行K-均值聚类,剔除相应的不准确数据;然后将保留的数据重新整理,计算出每位学员的排名期望;最后根据排名期望进行排序,得到学员排名情况。其中K-均值聚类较好地剔除了测评数据中的不准确数据,运用平等原则,较好地得到了每位学员的排名期望。同时,针对评定方案设计了相应算法,并运用模拟实验验证了方案的可行性。实验通过方差与考察进行评估,发现实验结果具有很强的可靠性。基于K-均值聚类剔除数据的民主测评方法可以较准确、可靠及客观地解决问题,而且方案的求解算法复杂度较低,较好地增强了方案求解的时间效益。
1 相关研究成果
近年来国内关于学生的综合素质评定已做了大量的研究,提供了很多的可行方案。文献[5]采用数据挖掘的方法,通过分析,应用萨蒂层次分析法对大学生综合素质进行评定。文献[6]基于模糊聚类算法,应用组合赋权法对成绩进行赋权,以此对学生综合素质进行评定。文献[7]利用层次分析法确定综合素质评价指标权重,评价了复合型人才综合素质。文献[8-9]设计了一种问卷调查法来对大学生的素质能力进行评定,并根据调查问卷数据对指标因素进行效度分析,主要包括内容效度、效标效度和结构效度。文献[10]为了构建学生的综合素质评定平台,先根据相关规章制度拟定候选指标体系,然后根据集体讨论和分析筛选指标,最后请专家论证这个指标体系。文献[11]为了构建学生素质能力评定指标体系,先根据学生核心职业素养的基本要素结构模型和问卷调查统计结果构建指标体系,然后运用德尔菲专家咨询法对评定指标进行筛选、修正和确认。这些研究都是关于大学生的综合素质能力评定,文献[5-7]主要还是基于成绩权重的评定,不能评定出学员综合素质的强弱。文献[8-11]则是吸纳众意,制定评价指标来进行评定,这种评定主观性较强,科学性不高,而且方案实施起来也较复杂。
本文提出了一个新的方向,对同专业学员的排名进行民主测评得到初始数据,侧重于学员的实际表现情况而非分数;然后应用K-均值聚类算法剔除掉噪音数据,解决了上述方案存在的问题,既方便又可行。
2 解决问题的方法
民主测评是召集若干知情人对被考核人的表现进行评定的一种考核方法,具有良好的群众性和民主性,既可以互相促进又可以互相监督[12],在学生综合素质评定问题上可以较为客观、可靠地得到学生排名情况[13]。
针对学生综合素质的民主测评,首先根据专业相关测评数据建立专业内的评定矩阵Rm×n。评定矩阵设定如下:
其中:Rm×n表示第Rm×n个测评人;Sj表示专业内j学号学生;xij表示第i个测评人为第j学号学生给定的排名,且i=1,2,…,m,j=1,2,…,n。
根据评定矩阵计算专业内每位学生的排名期望。由第i个测评人给第j号学生的排名概率rij可得第j号学生排名期望Ej,计算公式为
(1)
基于民主测评的客观性,可知该测评的实施是建立在互等原则上的,即对每一名测评人持有的信任度相同[14]。换句话说,就是每一名测评人给出的测评数据在总测评数据中所占的权重相等。由此可得
最后将学生的排名期望以从小至大进行排序,按排序确定专业内每名学生的排名。
上述方法可较为客观、可靠地得到学生排名情况,同时很好地体现了民主测评的民主性和群众性。但此方法存在一个主要问题,即对针对相关测评数据建立的评定矩阵Rm×n如何做预处理。
民主测评的可靠性需要数据支撑[15],然而随着数据量增多,不准确数据量也会增多,对民主测评的可靠性影响随之也会增加[16]。由此可见,数据量的多少对民主测评可靠性具有双重影响,导致民主测评适用性在很大程度上受到制约[17]。
针对该问题,本文建立了基于K-均值聚类的不准确数据剔除方法,对民主测评进行预处理,大大提高了民主测评的适用性,较好地打破了这种制约。
3 基于K-均值聚类的数据剔除方法
K-均值聚类是一种经典的聚类方法,主要作用是根据属性将对象划分成多个互斥的组或簇。划分的主要思想为:定义簇内点的均值为簇的形心,基于形心的划分技术[18],以簇内高相似性和簇间低相似性为目标进行最后划分。此方法适用于多维度空间,同时运用迭代方法求解可以大大降低计算复杂度,提高算法性能[19]。
在对评定矩阵Rm×n进行分析时,要将每一个测评人数据看做一个多维向量点,即矩阵每一行看做一个向量。基于K-均值聚类处理多维空间的优越性,在处理Rm×n基础上使用K-均值聚类无疑是可行的。
3.1 方法
针对民主测评,首先对评定矩阵Rm×n分析,矩阵每一行可看做一个样本点,每一列可看做样本的一个属性。对样本点及样本属性进行编号,如下所示:
1)Pi给定的排名为数据中第i个样本点;
2)Sj表示的值为样本点中第j个属性的值。
对基于K-均值聚类做如下定义:
3.1.1 剔除原则的定义
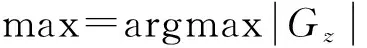
3.1.2 簇数k的定义
簇数k不仅是K-均值聚类必设参数[20],而且是后续数据剔除的重要参考指标,如何设定k影响整个模型的效能,为此必须结合相应问题定义其值。
从K-均值算法自身出发,可定义k=1,2,…,m。从问题出发,可知数据只需分为准确数据与不准确数据两类,当k取值越大时,对数据产生的稀释作用也就越大[21],即每个簇所表示的准确与不准确性的界线越模糊,这是问题所不允许的。由此可知k的取值不能过大,定义k=1,2,3。
对于k=1,明显违背剔除原则,即此种情况不加以考虑。
对于k=2,3,设定数据中存在好、中和差3种数据,其中好与中都可看做准确数据,而差只能看做不准确数据。当数据集存在5个好数据、3个中数据和6个差数据时,k=2与k=3则可能出现如图1所示情况。
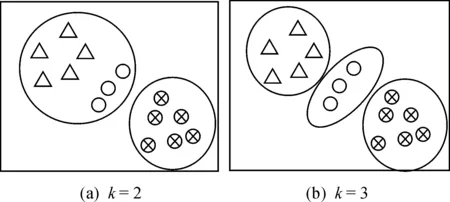
图1 k=2与k=3的两种情况
由图1可知,依据剔除原则k=3得到的结果为6个差数据,k=2得到的结果为5个好数据与3个中数据,为提高方法的适用性,k=3显然不具参考性。
综合上述分析,基于民主测评问题定义k的取值为2。
3.1.3 簇内点均值的定义
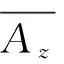
(2)
3.1.4 点到均值点距离的定义
(3)
3.1.5 方法评价指标的定义
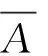
则方差S的计算公式为
(4)
最后结合上述定义设定如下求解步骤:
步骤1 给定簇数k=2。
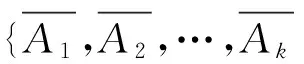
步骤3 根据式(3)分别计算各样本点与各簇均值点的距离,将各样本点划入最近均值点所属的簇中。
步骤4 由式(2)重新计算各簇均值点,判断新均值点与原有均值点是否都相同。若相同则终止求解,以现有聚类情况作为最终结果,否则将新均值点替换原有均值点转到步骤3继续计算。
3.2 求解算法
由上述K-均值聚类的求解步骤得到了K-均值聚类的求解算法,如表1所示。
根据表1可知算法复杂度为O(mkt),其中:m是对象总数;k为簇数;t是迭代次数。该算法复杂度适中。
由此可见,基于K-均值聚类的剔除不准确数据法适用性强、准确性高,可以大大提高民主测评评定学生综合素质方法的实用性和可靠性。

表1 K-均值剔除算法
4 实验
4.1 实验方法和设置
为验证基于K-均值聚类剔除不准确数据方法的民主测评具有良好的适用性和可靠性,对重庆某高校12个专业278名学生进行民主测评,得到了民主测评数据。使用Matlab2012搭建实验环境,硬件配置为:处理器为Intel(R) Core(TM) i5-2430,CPU为2.40 GHz,RAM为4.00 GB(3.07 GB 可用)。
首先将12个专业的民主测评数据进行处理,整理成相应的评定矩阵,然后根据表1所示算法,运用Matlab编写程序剔除各专业不准确数据,得到评定矩阵的预处理结果,并根据本文所提方法计算各专业内学生的期望排名,以期望排名进行学生综合素质评定,最后以方差分析与现实考察评估基于K-均值聚类剔除不准确数据方法的效能。
4.2 实验结果和分析
4.2.1 数据剔除结果和分析
初始簇均值点是随机产生的[23],要得到较好实验结果必须在专业内进行多次实验。由于专业1~12中专业1与专业3的数据量相对较多且测评人也相对较广泛,可知其相对具有代表性,所以下面以具有代表性的专业1与专业3为例进行实验。
实验分别对专业内各种可能情况进行求解,得到专业内每种情况下的方差色图。专业1与专业3的方差色图如图2所示。
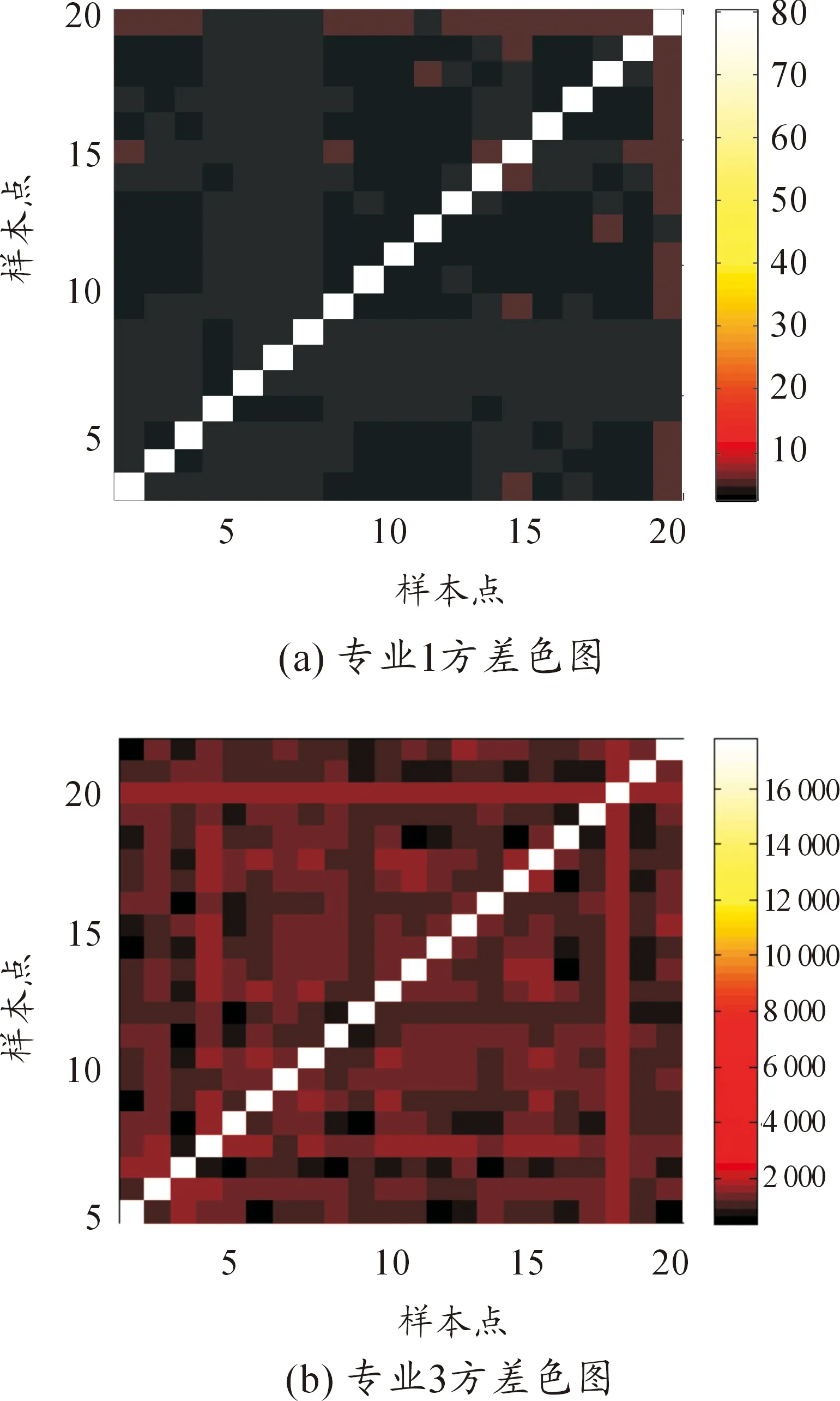
图2 专业1与专业3方差色图
图2横轴、纵轴表示样本点,样本点组合不同代表初始簇均值点的情况不同,图像颜色越深表示该种情况下得到的方差越小,反之越大。
通过观察方差色图,发现当初始簇均值点不同时,方差也存在不同且方差之间相差较大。为此,分别对专业1与专业3中不同情况取得的方差与专业内最小方差的差值进行分析,得到图3所示的方差差值图。
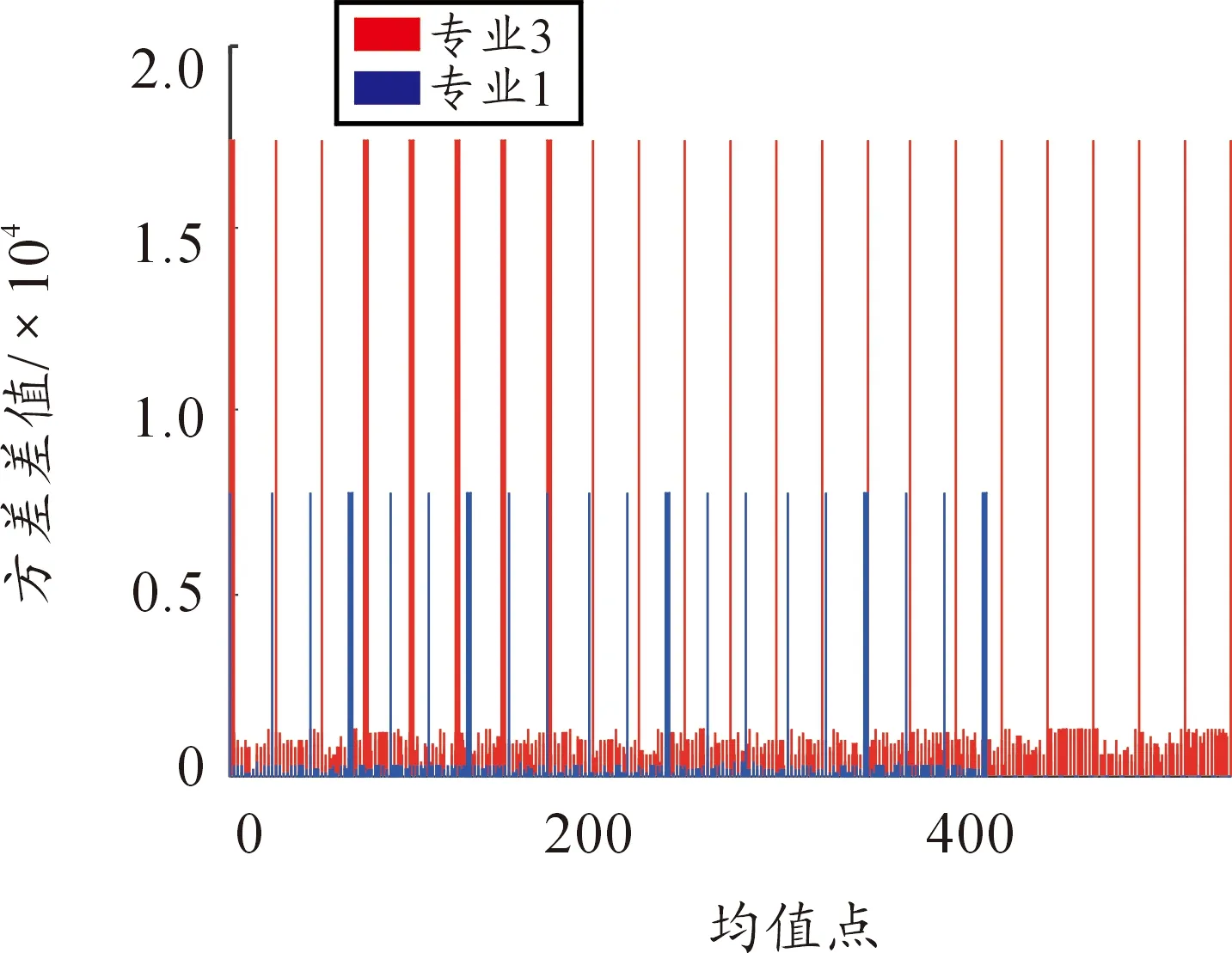
图3 专业1与专业3方差差值图
根据图3可清楚地知道专业内不同情况间的方差差值普遍较大,基本保持在几百的基础上,有些可达到上千。由此,对于专业内初始簇均值点不同的情况不能一概而论,需从问题实际出发寻找比较符合题意的结果。
综上分析,实验采取最小原则,选取方差最小情况下的结果为该专业数据剔除的最终实验结果。如专业1最终结果的方差为230.9,初始簇均值点为第10个与第14个样本点;专业3最终结果的方差为356.1,初始簇均值点为第5个与第10个样本点。
同理,对各专业进行相应实验,得到了各专业方差最小时的数据保留情况,如表2所示。
根据原始民主测评数据了解到专业2中样本点4、17、20、21,专业3中样本点20,专业5中样本点9、10、11、12、13都有明显错误。观察表2可知上述样本点都被很好地剔除了。以上结果说明基于K-均值聚类剔除数据的方法具有良好效能。为进一步评定该方法具有良好效能,结合本文的评定指标,将剔除前后各专业样本点方差进行比较,结果如图4所示。

表2 各专业数据保留结果

图4 数据剔除前后方差比较
由图4可以清楚看出:K-均值聚类在数据剔除方面具效果非常好,即基于K-均值聚类剔除数据方法进行评定矩阵的预处理是可行、有效的,且该方法可以大大提高民主测评的适用性和准确性。
4.2.2 排名结果和分析
将表2中各专业的保留样本点作为民主测评数据,重新组建评定矩阵,结合式(1)计算得到专业内每个学员的排名期望,根据排名期望展开排序得到各专业学员的排名情况,如表3所示。表3中数字代表各专业学员学号,按排名顺序进行排序,专业以编号表示。

表3 各专业排名情况
笔者走访了各专业知情人士(知情人士主要包括专业内部分学生、专业内各科老师、学生导师、学校机关干部、学校部分领导等),具体走访流程如下:首先让知情人士说出其对专业内各人员的主体印象与看法;然后将实验得出的排名结果公示给知情人士议论并促其说出自己的意见;最后统筹知情人士对排名的意见。
从统筹结果可知:大部分知情人士比较认可实验所得排名,即表3给出的各专业排名情况比较贴近与符合现实情况。由此可见,基于K-均值聚类剔除数据的民主测评方法在处理学生综合素质评定方面具有较好的适用性、客观性和可靠性,而且数据处理灵活、实用,具有很强的可操作性,算法复杂度较低,具有较可观的时间效益。
5 结束语
本文在综合素质评定的大背景下,为了解决了“唯分数至上”的问题,提出了民主测评获取初始数据的方法。为了保证数据的相对准确、客观,应用K-均值聚类算法剔除了不准确数据。评估实验的结果验证了本文所提出的基于K-均值聚类剔除数据的民主测评方法的科学性和可靠性。
K-均值聚类算法对于数据的剔除还有一定随机性,即不同随机初始中心值导致的最终结果不一样,同时K-均值聚类在剔除数据方面还可能出现一些偶然性,即难以彻底剔除噪音数据。下一步将尝试用层次聚类算法和密度聚类算法来管理数据,增强民主测评评定学生综合素质方法的可靠性和适用性。期望通过层次聚类改善K-均值聚类随机性强的问题,运用密度聚类改进K-均值聚类难以彻底剔除噪音数据的问题。
同时为做到对数据剔除好坏的整体把握,下一步将尝试从各样本点间的相关性入手,通过分析剔除前后各样本点间的相关性判断数据剔除的好坏程度。
[1] 温家宝.百年大计,教育为本[EB/OL].[2009-01-04].http://news.xinhuanet.com/newscenter/2009-01/04/content_10601461_1.htm.
[2] 郑小丽.基于WEB的学生综合素质评估管理系统的分析与设计[D].昆明:云南大学,2012.
[3] 李娜.大学生综合素质测评体系构建与完善[J].教育教学论坛,2016(5):56-57.
[4] 魏茵.基于模糊综合评判的大学生综合素质测评系统的设计与实现[D].西安:西安建筑科技大学,2015.
[5] 王坤.基于数据挖掘的大学生综合素质评定系统[J].河北软件职业技术学院学报,2008,10(4):57-59.
[6] 丁庆彬.模糊综合评判法在大学生综合素质评判中的应用[J].唐山师范学院学报,2007,29(5):48-51.
[7] 张俊霞.基于组合赋权的地方本科大学生综合素质评价研究[J].科技广场,2014(6):20-24.
[8] 陆伊.基于胜任力的大学生综合素质评价指标体系研究[D].苏州:苏州大学,2007.
[9] 李曼丽.大学生通识教育课程实施效果评价研究[J].教育发展研究,2014(3):37-43.
[10]白玉珊.基于电子平台的学生综合素质评价研究[D].石家庄:河北师范大学,2009.
[11]林勇.基于模糊综合评判的高校学生综合素质评价系统的研究和实现[D].成都: 电子科技大学,2008.
[12]刘昕.当前党政领导干部民主测评的深层困境[J].人民论坛·学术前沿,2014(7):80-89..
[13]罗中枢.干部民主推荐、民主测评的科学性探析[J].新视野,2012(5):49-53.
[14]张红霞.提升民主测评质量要实现“三个转变”[J].领导科学,2016(4):46-47.
[15]曲向阳.警惕民主测评失真失实[J].中国党政干部论坛,2013(11):88-88.
[16]刘昕.人才测评对优化党政领导干部民主测评的启示[J].中共贵州省委党校学报,2015(6):83-89.
[17]王爱民.党政领导干部选拔任用中民主测评问题及对策研究[D].长春: 吉林大学,2009.
[18]蒋帅.K-均值聚类算法研究[D].西安: 陕西师范大学,2010.
[19]左进,陈泽茂.基于改进K均值聚类的异常检测算法[J].计算机科学,2016,43(8):258-261.
[20]高丑光,林都,鲜浩.基于K均值的软件测试集用例约简算法研究[J].微电子学与计算机,2016,33(5):133-136.
[21]单冬红,李玮瑶.基于约束性过滤的改进K均值挖掘算法研究[J].科技通报,2013,29(4):171-173.
[22]杨小勇.方差分析法浅析——单因素的方差分析[J].实验科学与技术,2013,11(1):41-43.
[23]王秀和.利用K均值算法改进后的蚁群优化算法对高光谱图像聚类研究[J].科技通报,2015(3):202-206.
(责任编辑 杨黎丽)
K-Means Cluster Based Ability Evaluation Method for University Students
FENG Xiao-qin1, HE Hong1, HU Xiao-hui1, SUN Cheng-xu1, XIANG Chao-can1, YU Sai-xuan2
(1.Logistic Engineering University, Chongqing 401331, China; 2.Sichuan Winshare Vocational College, Chengdu 611330, China)
It is critical for the university to accurately evaluate the ability of students with the development of education reform. However, it is very difficult to evaluate the students’ ability reliably and objectively due to the extremely complex ability of students. As a result, this paper proposed a K-means cluster based ability evaluation method for university students. Firstly, we pre-process the data of democratic appraisal, followed by eliminating the inaccurate data using K-means cluster. At last, according to the remaining accurate data, we rate the students’ ability. The real experiments show that, our method can accurately evaluate the students’ ability based on the real democratic assessment data of 278 students of 12 majors in a university at Chongqing. Moreover, the theoretical analysis illustrates that the time complexity is low.
democratic appraisal; K-means cluster; student ability
2016-11-16 基金项目:国家自然科学基金资助项目(61502520)
冯小芹(1984—),女,四川宣汉人,硕士研究生,讲师,主要从事军队管理学研究,E-mail:45390285@qq.com。
冯小芹,何宏,胡晓辉,等.基于K-means聚类的大学生综合素质评定方法[J].重庆理工大学学报(自然科学),2017(5):125-132.
format:FENG Xiao-qin, HE Hong, HU Xiao-hui,et al.K-Means Cluster Based Ability Evaluation Method for University Students[J].Journal of Chongqing University of Technology(Natural Science),2017(5):125-132.
10.3969/j.issn.1674-8425(z).2017.05.021
TP393
A
1674-8425(2017)05-0125-08
