大豆凝集素(SBA)含量遗传分析与QTL定位
2017-06-22杨明亮李宁李海燕隋美楠王继安
杨明亮,李宁,李海燕,隋美楠,王继安*
(1.东北农业大学大豆研究所,哈尔滨150030;2.东北农业大学文法学院,哈尔滨150030)
大豆凝集素(SBA)含量遗传分析与QTL定位
杨明亮1,李宁2,李海燕1,隋美楠1,王继安1*
(1.东北农业大学大豆研究所,哈尔滨150030;2.东北农业大学文法学院,哈尔滨150030)
大豆凝集素(Soybean agglutinin,SBA)为大豆中含量较高、作用较强主要抗营养因子之一,影响大豆食品和饲料安全,降低或去除大豆籽粒和产品中凝集素成为大豆食品和饲料工业亟待解决问题。文章以合丰45号(高SBA含量)×太平川黑豆(低SBA含量)杂交组合及衍生201个稳定株系组成的F7∶8重组自交系(RIL)群体为试验材料,在3年(2011~2013)1个样点(哈尔滨)种植环境下对大豆凝集素含量作遗传模型和QTL分析。结果表明,SBA含量符合2对主基因+多基因混合遗传模型;利用134对多态性SSR引物扩增RIL群体,构建遗传图谱,对SBA含量相关作QTL分析。共检测到4个与SBA含量相关QTL,每个QTL均重复检出2次,稳定性较好,其中SbaHTC1-1(Satt139~Satt578)和SbaHTD1b-1(Satt537~Satt189)2个QTL位点两年检测结果加性效应值均达显著水平,且遗传贡献率较高,为主效QTL。利用分子标记遗传图谱,定位与SBA含量相关QTL,为改良大豆凝集素含量提供理论依据和技术支持。
大豆;大豆凝集素(SBA)含量;遗传分析;QTL
大豆作为重要油料作物,成熟种子含有丰富蛋白质,在人类膳食结构中占有重要地位,是动物饲料蛋白质主要来源[1]。大豆中含有若干种抗营养因子,包括大豆凝集素、胰蛋白酶抑制剂、低聚糖、致甲状腺肿素、植酸和抗维生素因子等,阻碍营养物质吸收,甚至有毒害作用[2]。大豆凝集素(Soybean agglutinin,SBA)是大豆中含量高、作用较强抗营养因子之一,影响大豆食品及饲料安全性。SBA是一类结构各异非免疫源性专一性糖结合蛋白质[3],在动物肠道中不易被蛋白酶水解,干扰消化酶分泌,抑制肠道对营养物质吸收,动物生长受阻甚至停滞[4]。饲用或食用前大豆必须加工处理,失活SBA等抗营养成分,提高豆制品或饲料营养吸收利用率[5]。但处理过程易造成其他营养成分损失,增加生产成本。大豆凝集素遗传机制和分子标记研究较少,无法满足低SBA含量育种需要[2,6]。因此,开展有关SBA含量相关研究,对低SBA含量品种育成具有指导意义,对饲料工业和畜牧业发展具有积极推动作用[1,7]。
本研究立足于种质资源创新与利用,为食品和饲料加工企业提供可直接利用低SBA含量品种。以黑龙江省生产中广泛应用主栽品种合丰45号(高SBA含量)与野生种太平川黑豆(低SBA含量)为亲本,杂交衍生RIL群体对SBA含量作主基因+多基因混合遗传模型分析,并以SSR分子标记构建大豆遗传图谱,定位SBA含量相关基因。为大豆低SBA含量育种、分子辅助选择及相关基因图位克隆等奠定理论基础。
1 材料与方法
1.1 材料
1.1.1 RIL群体构建材料
本研究以高SBA含量品种合丰45号为母本,低SBA含量品种太平川黑豆为父本杂交,经南繁加代,采用单粒传法连续自交7代,建成具有201个稳定株系的F7∶8重组自交系(RIL)群体。
1.1.2 血凝法检测SBA含量原理
SBA具有4个与细胞表面糖分子特异性结合位点,可在细胞间形成稳定交叉连接结构,使分散于体系中细胞凝集。SBA对兔、人等血红细胞具有较强凝集力。SBA凝集活力(效价)与SBA含量呈高度线性关系[5,8]。因此,利用血凝反应(Heamagglutination)测定SBA活力,通过比较标准样品与待测样品血凝活力,定量检测SBA。
主要试剂:SBA标准品(Sigma),其他试剂均为分析纯,试验兔子购自东北农业大学动物医学院试验动物中心。
1.1.3 QTL定位材料
DNA提取:盛花期从RIL群体201个稳定株系中随机选取具有代表性单株,每株取1~2片健康幼嫩叶,液氮速冻后于-86℃超低温冰箱保存,待用。
SSR检测:选用已整合到大豆公共遗传图谱上的SSR引物500对,按照美国农业部大豆基因组数据库soybase(http://www.soybase.org/)中提供大豆微卫星序列,由上海博亚生物技术有限公司合成。
1.2 试验方法
1.2.1 SBA含量检测—血凝法(Heamagglutination)
本研究利用血凝法检测SBA含量,SBA提取、兔血红细胞悬液制备、含量检测、效价评定和计算公式均参照文献[7]。
1.2.2 SBA含量遗传规律分析
运用植物数量性状主基因+多基因混合遗传模型分析方法,对RIL群体连续3年3个世代P1、P2和RIL作SBA含量遗传模型分析。通过极大似然法和IECM算法估计各世代、各成分分布参数(平均数、比例和方差),估计最大似然函数值。进一步计算AIC值,以AIC值最小原则入选最佳模型,并作适合性测验,包括均匀性检验(U21,U22,U23)、Smirnov检验(nW2)、Kolmogorov检验(Dn),以最少统计量达到显著水平模型为最佳遗传模型,依据最小二乘法利用其各成分分布参数估计相应遗传参数。主要遗传参数包括:平均值(m),加性效应值(d)、互作值(i或i*)、方差(δ2)、遗传率(h2%)等。利用南京农业大学章元明博士提供分析软件分析。
1.2.3 遗传连锁图谱构建
利用Mapmaker/exp 3.0对RIL群体134个SSR标记作行遗传连锁图构建。‘group’命令作SSR标记间(LOD=2.0)分组,连锁群标记数<8用‘compare’命令排序,对与标记数较多连锁群先用高信息量8个标记排序,再用‘try’命令确定剩余标记位置,用‘ripple’命令反复梳理,Kosambi函数将重组率转换成遗传图距(cM),最后‘map’命令定图距,构建群体SSR标记遗传连锁图谱,Mapchart2.1绘图[9]。
1.2.4 QTL定位
运用WinQTLCartographer v2.0,采用复合区间作图法(Composite Interval Mapping,CIM)确定性状QTL数目和染色体位置。LOD值大于2.0作为QTL存在阈值,利用Kosambi函数将重组率转化为遗传图距(cM)。单位距离选择Cent Morgan,作图时,步精度(Walk speed)选择2 cM,显著性阈值(Threshold)=11.50,输出以LOD值形式显示,对大豆凝集素(SBA)含量作QTL分析[10]。
2 结果与分析
2.1 RIL群体SBA含量遗传分析
P1、P2和HT-RIL群体SBA含量表型次数分布(见表1),2011年,HT-RIL群体SBA含量频数分布在10.20~12.51、17.16~19.47 mg·g-1区间内有2个明显峰值;2012年,在5.73~8.00、17.17~19.44、21.74~24.02 mg·g-1区间内有3个明显峰值;2013年,在3.25~5.40、16.17~18.31 mg·g-1区间内有2个明显峰值(见表1);根据混合分布理论可初步判断,HT-RIL群体SBA含量可能由主基因控制,也可能存在多基因遗传。
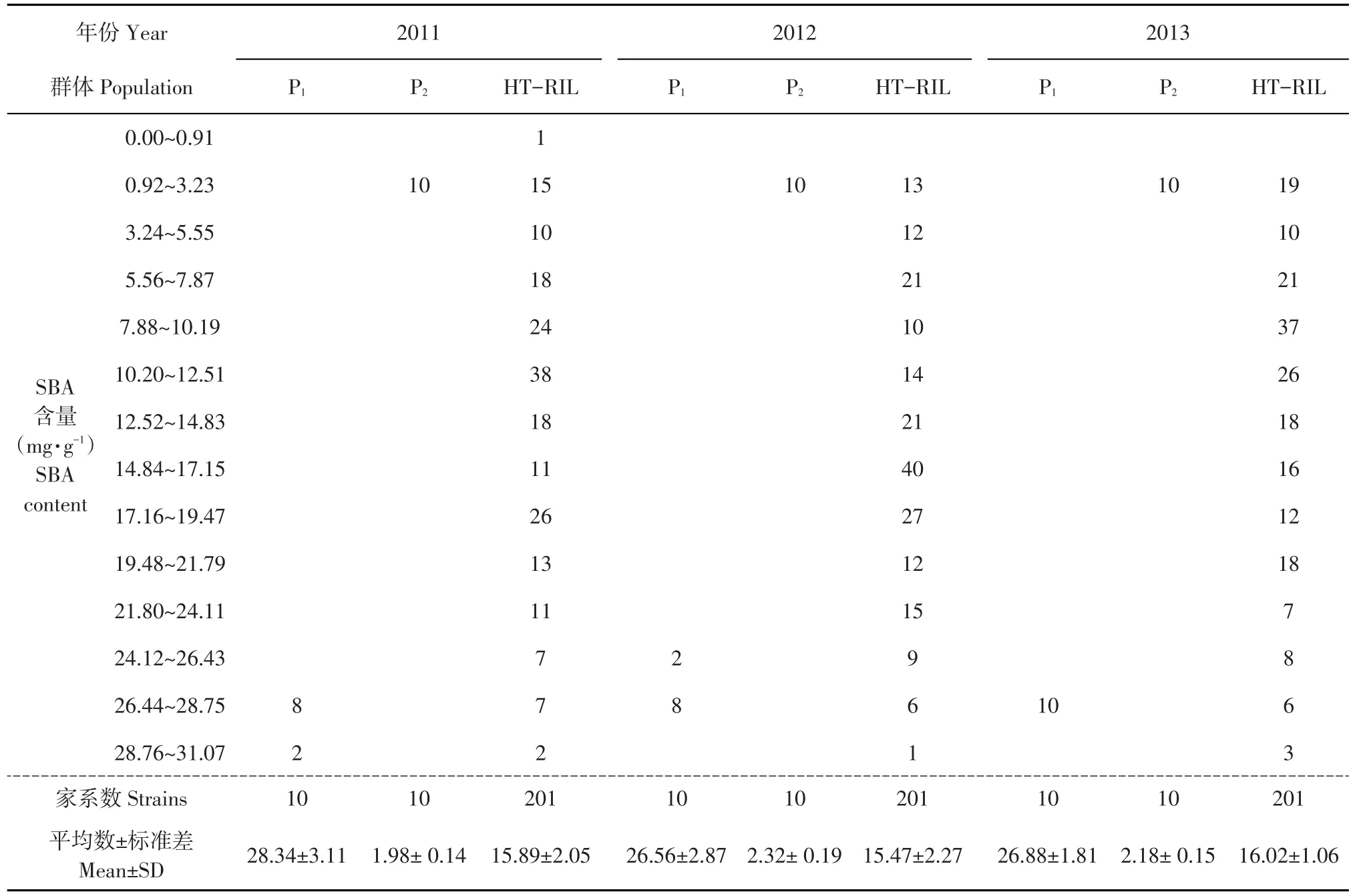
表1 合丰45×太平川黑豆的P1、P2、F7∶8RIL群体SBA含量次数分布Table 1Frequency distribution of SBA content in P1,P2,F7∶8RIL populations in the cross of Hefeng 45×Taipingchuan black soy
2.1.1 RIL群体SBA含量最适遗传模型分析
根据章元明等[11-12]提出主基因+多基因混合遗传模型,利用P1、P2和RIL群体三世代,作SBA含量最佳遗传模型分析,由RIL群体SBA含量次数分布情况估计7类53个模型极大似然函数值(Max likelihood value)和AIC值(AIC value),最优遗传模型选择依据AIC值最小原则,选择几个AIC值接近模型作适合性检验,以统计量显著变量最少原则,确定最佳模型。
2011年模型D-1、E-1-2、E-2-1和F-1的AIC值较低,且4个模型间AIC值与极大似然数值差异不显著。入选模型依据统计量均匀性检验(U1,U2,U3),Smirnov检验(nW2)以及Kolomogorov检验(D)作适合性检验(见表2),模型D-1、E-1-2和F-1分别有1、4、2个统计量达显著水平,且E-2-1 AIC值最低。因此,SBA含量最佳遗传模型为E-2-1模型,该模型为2对主基因(连锁)+多基因(加性)模型,且主基因效应为加性-上位性效应。
2012年3个模型B-1-8、E-1-0和E-1-1的AIC值较低,入选模型作适合性检验(见表2),模型B-1-8有5个统计量达显著水平,模型E-1-0和E-1-1分别有1个量统计量达显著水平且模型E-1-1的AIC值更低。因此,SBA含量最佳遗传模型为E-1-1模型,该模型为2对主基因(独立)+多基因(加性)模型,且主基因效应为加性-上位性效应。
2013年4个模型B-2-1、E-2-0、E-2-5和G-2的AIC值较低,入选模型作适合性检验(见表2),模型B-2-1和E-2-0分别有3和2个统计量达显著水平,模型E-2-5和G-2均无统计量达显著水平,但模型E-2-5适合性检验统计量水平更低,且AIC值更低。因此,SBA含量最佳遗传模型为E-2-5,该模型为2对主基因(连锁)+多基因(加性)模型,且主基因效应为显性上位性效应。

表2 RIL群体SBA含量入选模型的适合性检验Table 2Test for goodness-of-fit of candidate models for the SBA content of RIL population
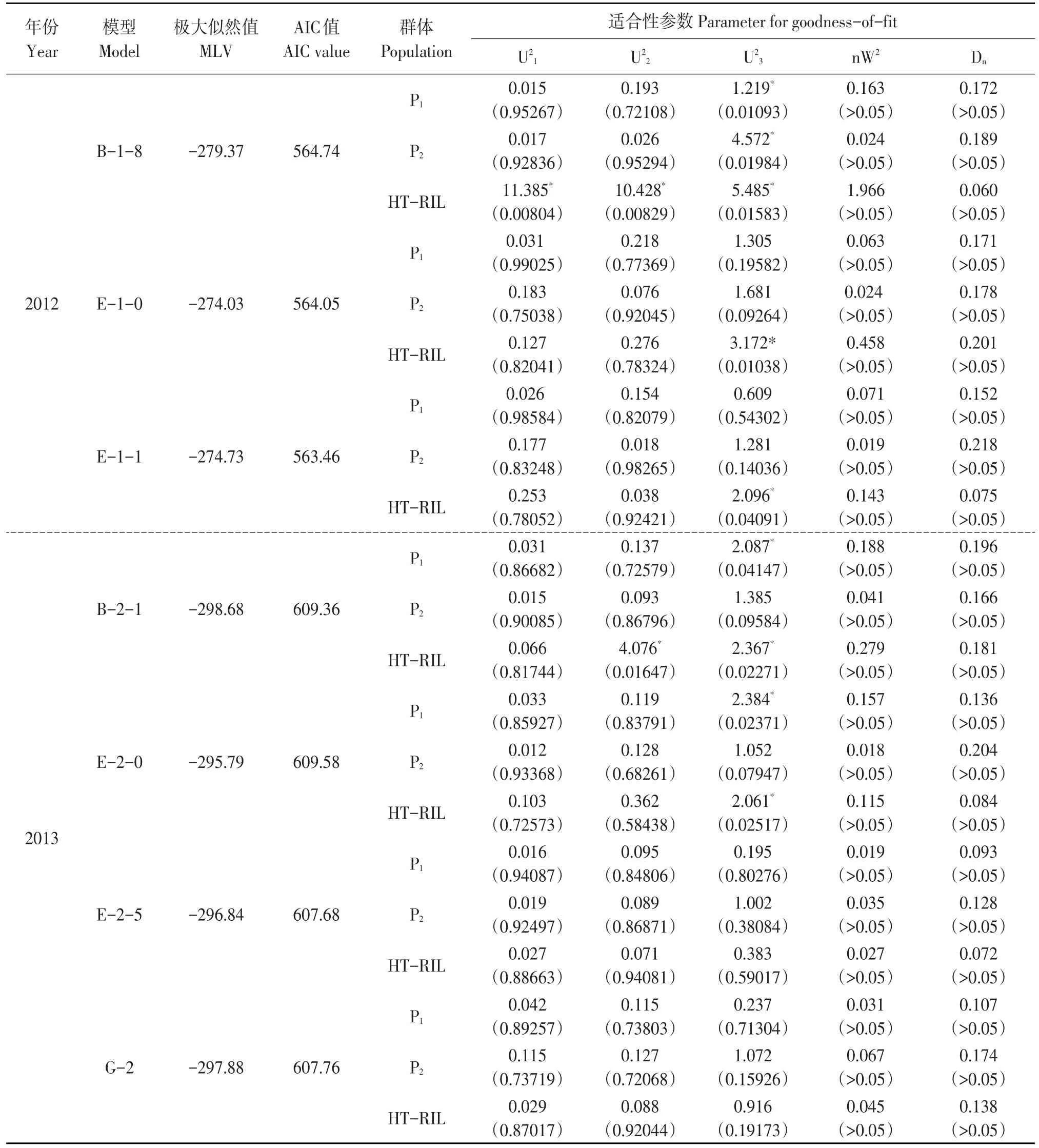
续表
RIL群体3年最佳遗传模型为2对(独立或连锁)主基因(加性-上位+显性上位)+多基因(加性)混合遗传模型。根据所估计成分分布参数,最小二乘法估算遗传参数。
2.1.2 RIL群体SBA含量遗传参数估计
利用P1、P2和RIL群体3世代联合分析法作遗传模型分析及遗传参数估算SBA含量(见表3、4)。SBA含量遗传相对复杂,为2对主基因+多基因遗传模型,主基因效应和遗传方式不同。加性效应提高SBA含量,但加加互作对SBA含量提高幅度较小。SBA含量主基因遗传率各年均显著高于多基因遗传率,说明主基因贡献对SBA含量具有重要作用。
2011年SBA含量遗传在最佳遗传模型E-2-1条件下,RIL群体4个成分均值分别为20.75、12.50、7.662和3.196,权重分别为0.368、0.338、0.179和0.115。主基因遗传率为69.37%,多基因遗传率为24.33%,SBA含量遗传中,主基因连锁遗传且贡献率较大,多基因遗传贡献率较小。
2012年SBA含量遗传在最佳遗传模型E-1-1条件下,RIL群体4个成分均值分别为24.571、17.042、12.496和5.582,权重分别为0.271、0.238、0.263和0.228。主基因遗传率为58.37%,多基因遗传率为37.55%,SBA含量遗传中,主基因(独立遗传)与多基因遗传贡献率较大。
2013年SBA含量遗传在最佳遗传模型E-2-5条件下,RIL群体3个成分均值分别为21.065、12.107和7.498,权重分别为0.254、0.478、和0.269。主基因遗传率为62.46%,多基因遗传率为26.63%,SBA含量遗传中,主基因连锁遗传且贡献率大于多基因遗传贡献率。
2.2 RIL群体SBA含量分布及QTL适合性分析
采用血凝法测定RIL群体及亲本SBA含量(见表5),亲本间SBA含量差异较大,RIL群体SBA含量多数介于双亲之间,存在个别超亲现象。SBA含量变幅分别为0.91~31.09 mg·g-1(2011)、1.14~30.89 mg·g-1(2012)、1.09~29.08 mg·g-1(2013),表现为正向超亲分别占1.99%、2.49%、1.49%,负向超亲分别占6.47%、5.98%、5.47%。RIL群体SBA含量变异系数分别为55.87%~70.09%,说明RIL群体SBA含量具有丰富遗传变异,可作为QTL定位理想群体(见图1),开展SBA含量QTL分析。

表3 入选模型各成份分布均值及权重Table 3Mean and weight of component distributions of selected models

表4 RIL群体SBA含量遗传参数估计值Table 4Estimate of bivalent parameters for the SBA content of RIL population

表5 3年RIL群体SBA含量统计分析Table 5Statistical analysis of SBA content for parents and RIL population in different environments

图1 3年RIL群体SBA含量频数分布Fig.1Frequency distribution of SBA content for parents and RIL population in different year
2.3 RIL群体遗传图谱构建与QTL分析
2.3.1 RIL群体遗传图谱构建
以合丰45号和太平川黑豆为亲本,有性杂交,构建含有201个具有代表性株系RIL永久群体。选用500对SSR引物,选出140对在亲本间产生多态性引物。利用140对引物评估RIL群体,有134对引物表现良好多态性。
RIL群体基于SSR分子遗传图谱共含有12条连锁群,包含134个SSR标记,与Cregan定义12条连锁群相对应(见图2),SSR标记总长约为1252.9 cM,平均图距9.78 cM,每个连锁群上标记数变化区间为7~17个,长度为62.8~135.7 cM,平均图距为6.28~15.29 cM。其中最大连锁群为K,总长为135.7 cM,最小连锁群为M,总长为62.8 cM。如表6所示,HT-RIL群体SSR标记分布均匀,A2、 C2、D1a、K、O等5个连锁群上分布标记数均超过10个SSR标记,这5个连锁群上共有73个SSR分子标记,占标记总数54.48%。
2.3.2 SBA含量相关QTL定位
采用复合区间作图法(CIM)对RIL群体作1点(哈尔滨)3年(2011~2013)大豆凝集素(SBA)含量QTL分析(见表7)。
2011年,检测到2个QTL位点,SbaHTC1-1和SbaHTD1b-1分别定位于C1和D1b连锁群,分别位于SSR标记Satt139-Satt578和Satt537-Satt189之间,LOD值分别为3.53和8.89,遗传贡献率分别为12.04%和19.28%,加性效应值分别为0.65和0.88,SbaHTC1-1在遗传图谱中位置与标记Satt139遗传距离为3.67 cM,SbaHTD1b-1与标记Satt537遗传距离为14.17 cM。

图2 基于SSR标记的大豆分子遗传图谱Fig.2Soybean molecular genetic map based on the SSR markers
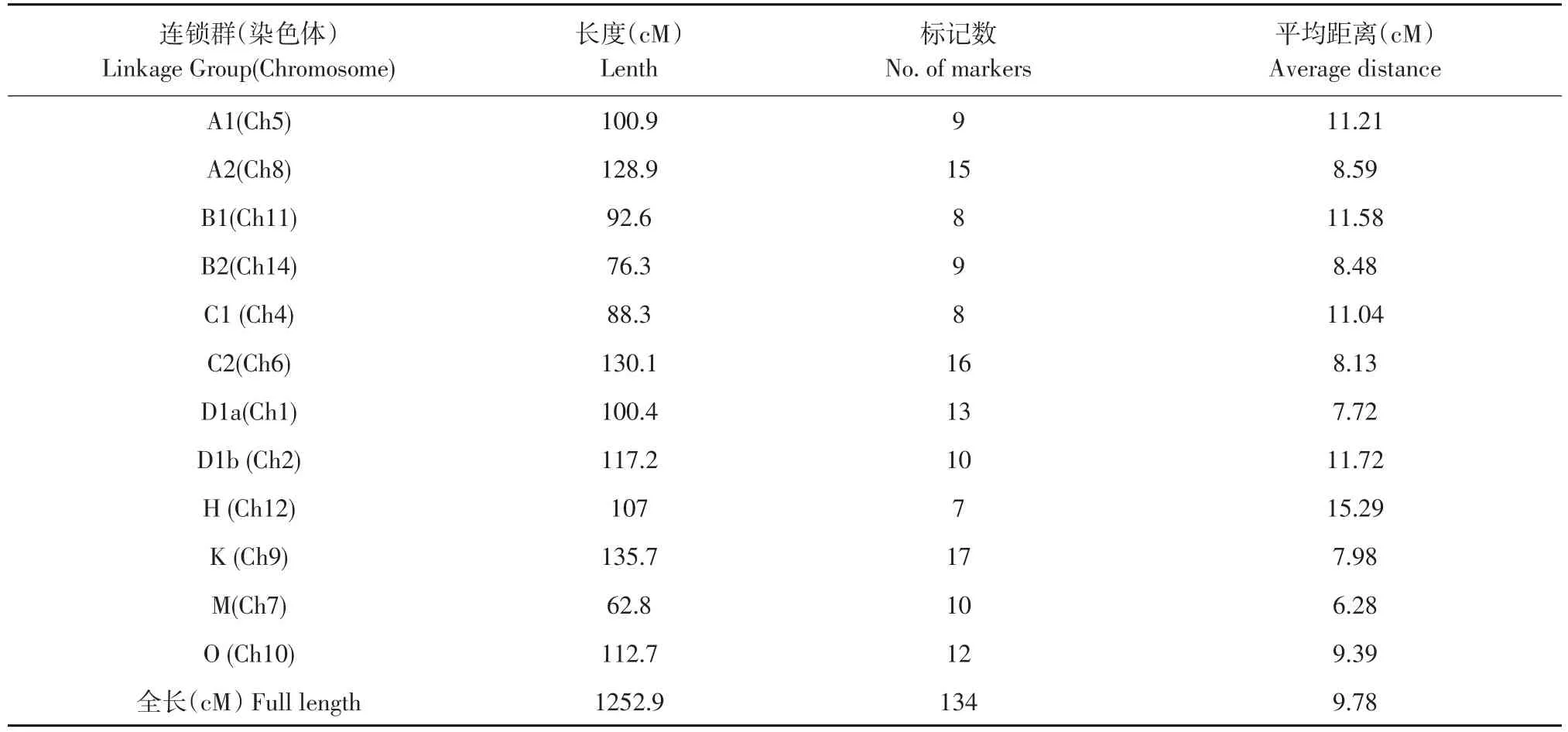
表6 HT-RIL群体SSR标记在所建遗传图谱上分布Table 6Distribution of SSR markers on the map of HT-RIL population
2012年,检测到3个QTL位点,SbaHTA1-1、SbaHTC1-1和SbaHTH-1分别定位于A1、C1和H连锁群,分别位于SSR标记Satt545~Satt300、Satt139~Satt578和Satt302~Satt541之间,LOD值分别为5.95、5.87和3.13,遗传贡献率分别为22.64%、9.47%和16.24%。SbaHTC1-1在遗传图谱中位置与标记Satt545遗传距离为21.28 cM;SbaHTC1-1与标记Satt139遗传距离为6.35 cM;SbaHTC1-1与标记Satt302遗传距离为4.65 cM。
2013年,检测到3个QTL位点,SbaHTA1-1、SbaHTD1b-1和SbaHTH-1分别定位于A1、D1b和H连锁群,分别位于SSR标记Satt545~Satt300、Satt537~Satt189和Satt302~Satt541之间,LOD值分别为5.73、6.39和2.32,遗传贡献率分别为11.06%、14.68%和21.04%,SbaHTC1-1在遗传图谱中位置与标记Satt545遗传距离为19.56cM;SbaHTD1b-1与标记Satt537遗传距离为12.47 cM;SbaHTH-1与标记Satt302遗传距离为2.45 cM。

表7 RIL群体SBA含量相关QTL定位Table 7QTL tagging of SBA content in HT-RIL populations

图3 RIL群体SBA含量相关QTL定位连锁图谱Fig.3Genetic linkage map of QTL related to soybean agglutinin content in RIL populations
RIL群体大豆凝集素(SBA)含量3年QTL定位结果(见图3)。大豆凝集素(SBA)含量相关QTL主要位于A1,C1,D1b和H连锁群上,被检测出2次,解释表型变异率分别为11.06%~22.64%,9.47%~12.04%,14.68%~19.28%和16.24%~21.04%。值s得注意的是,在检测到4个连锁群上SBA含量相关QTL位点,无一位点3年检测连续出现,可见4个QTL位点遗传受环境影响较大。
3 讨论与结论
3.1 大豆凝集素(SBA)含量比较
不同品种及加工工艺的大豆产品中SBA含量差异较大(见表8)。杨丽杰等利用火箭免疫电泳技术研究黑龙江省13个不同大豆品种SBA含量,结果表明SBA含量变异幅度为1.99~4.99 mg·g-1,高蛋白质含量大豆品种SBA含量低。李振田等利用酶联免疫吸附测定方法检测不同大豆品种和生豆粕SBA含量,结果表明大豆品种SBA含量变异幅度为2.9~7.1 mg·g-1,生豆粕与普通大豆SBA含量差异不显著[13]。戴大章等[14]和杨明亮等[7]研究表明,利用血凝法测定SBA含量,变异幅度为1.88~37.50 mg·g-1,试验精确度和准确性较高,简便易行,成本低廉。不同大豆品种和产品SBA含量差异显著,变异幅度较大,为SBA含量遗传研究和分子辅助选择奠定基础。不同测定方法对SBA含量检测影响较大,利用免疫学原理检测值和变幅均显著低于血凝法。因此,选择合适检测方法对于研究SBA含量遗传和分子辅助选择至关重要。本研究利用血凝法对SBA含量的测定结果与戴大章等结果一致[14],表明该方法试验重演性较好,具有经济、高效、精准等优点,可作为大规模种质资源和后代群体SBA含量检测方法。

表8 不同方法测定大豆凝集素(SBA)含量Table 8Different determination of SBA's content
3.2 RIL群体在遗传模型分析中应用
大豆数量性状表型受环境影响较大,且表型测量存在误差,遗传模型组成非常复杂[15,18]。王贤智对大豆产量相关性状[15]、姜振峰对大豆油分和蛋白质含量[10]、李海燕对大豆维生素E[16]、邢光南对大豆抗豆卷叶螟和筛豆龟蝽[9]等数量性状作遗传分析,结果表明,大豆数量性状遗传模型一般由多基因、2对主基因+多基因、3对主基因+多基因等遗传模型组成,且不同环境和遗传背景下主基因与多基因遗传方式及遗传效应差异显著[17]。章元明[12]和盖钧镒[18]等研究表明RIL群体不含显性效应,遗传参数较少,用于统计分析数据为家系平均值,环境和误差影响较小,可准确研究两个主基因座位间作用方式及效应,较分离世代(F2、F3、B1、B2)更适合大豆数量性状遗传机制研究。通过田间试验设计、分析世代选择、样本容量大小、数据处理方式等因素控制可有效提高分离分析法精确性。
本研究利用RIL群体分析大豆凝集素(SBA)含量遗传模型,结果表明,大豆凝集素(SBA)含量遗传模型为2对主基因+多基因模型,但不同年份主基因及多基因遗传效应存在差异,受环境影响较大。这与姜振峰[10]对大豆蛋白质含量多年多点遗传模型分析结果相似,认为大豆蛋白质遗传符合2对主基因+多基因模型,由于SBA是大豆蛋白质组成中含量较高功能和储藏蛋白,因此在遗传模式上具有相似性。
3.3 大豆遗传图谱构建
遗传图谱构建在作物研究中具有重要作用,Song等[19]以5个经典作图群体(Minsoy×Noirl,Minsoy× Archer,Archer×Noirl,Clark×Harosoy,A81-356022(Glycine max)×PI468916(Glycine soja))对Cregan等[20]整合大豆“公共图谱”解密,补充新SSR标记420个,标记间遗传距离为2.5cM,标记总数已达1 849个。这张整合图谱包含标记数量多、图谱密度高,应用广泛,对大豆分子标记、分子辅助育种、图位克隆等领域发展具有借鉴作用。
本研究构建由134个SSR标记组成,包括12个连锁群的大豆分子遗传连锁图谱,与Cregan和Song等图谱中连锁群相对应[19-20]。但标记位点较少,标记间空隙较大。因此,后续研究中可进一步筛选不同类型标记(如ARLP、RAPD、SCAR、SNP等标记)解密图谱,使图谱更加饱和,为基因精细定位和图位克隆提供可靠依据[21]。张志刚等认为利用高通量、并行化和高灵敏度基因芯片技术对RIL群体作DNA序列分析,可解释目标性状相关基因之间表达量变化及遗传关系[22]。梁士博等认为基于高通量、高密度SNP标记新一代测序技术(Nextgeneration sequencing,NGS)平台,可利用RIL等群体估计全基因组SNPs独立表型效应,确定复杂数量性状位点间表达关系,为基于SNP技术预测育种奠定技术[23]。
3.4 大豆凝集素(SBA)含量QTL检测
目前国内外与大豆凝集素(SBA)含量相关QTL检测鲜有报道。邢光南认为多年多点或多群体定位QTL可验证QTL存在真实性[9]。姜振峰利用单群体多年多点数据作蛋白质含量QTL定位,获得40个相关QTL位点,大部分位点遗传贡献率较小,多数为微效基因,受环境、遗传背景、群体性质等影响较大。由于基因型间和基因型-环境间存在互作效应,寻找稳定主效QTL位点难度较大。但发现在C2和Dla连锁群上分布控制大豆蛋白含量基因簇,对大豆蛋白质含量遗传与分子标记研究具有重要作用[10],对大豆凝集素遗传研究和QTL定位具有借鉴意义。
本研究以较大RIL群体样本(201个株系)为基础,分析SBA含量遗传机制和相关QTL位点,共检测到与SBA含量相关主效QTL 4个,分别位于A1,C1,D1b和H连锁群上,分别位于Satt545~Satt300、Satt537~Satt189、Satt139~Satt578和Satt302~Satt541标记间,解释表型变异分别为11.06%~22.64%,9.47%~12.04%,14.68%~19.28%和16.24%~21.04%,1个试点3年被检出次数均为2次,说明SBA含量相关QTL位点受环境影响较大。结合遗传模型分析结果可知,SBA含量遗传模型为2对主基因+多基因混合遗传模型,不同环境影响主基因作用方式和遗传效应不同,这与QTL定位结果相似,与姜振峰对大豆蛋白质含量研究结果相近[10]。李海燕认为分离分析法对目标性状主基因和多基因遗传率估计偏高,而QTL位点遗传贡献率偏低,在QTL定位前作RIL群体表型分离分析十分必要,当分离分析获得性状主基因遗传率较低时,可能检测不到QTL位点[17]。SbaHTC1-1(Satt139~Satt578)和SbaHTD1b-1(Satt537~Satt189)2个QTL位点2年检测结果加性效应值均达显著水平,加性效应代表非等位基因间互作,可以遗传,且两位点遗传贡献率均较高。本研究定位群体相对较大,因此,检测到QTL真实存在。研究结果仍需反复验证,确定与大豆凝集素含量紧密连锁稳定QTL位点,实现大豆凝集素含量后代群体分子辅助选择。
[1]杨丽杰,李素芬,张永成,等.黑龙江几个大豆品种中抗营养因子含量的分析[J].大豆科学,1999,18(1):77-80.
[2]丁安林,王燕,常汝镇.大豆抗营养因子及其改良[J].大豆科学, 1994,13(1):72-76.
[3]孙册,朱政,莫汉庆.凝集素[M].北京:科学出版社,1986.
[4]吴莉芳,秦贵信,孙玲,等.大豆凝集素及其对动物健康的影响[J].大豆科学,2007,26(2):259-263.
[5]戴大章,陈妙月,叶均安,等.理化处理对大豆凝集素活性的影响[J].营养学报,2004,26(3):223-226.
[6]杨明亮,宋雯雯,康明,等.大豆凝集素含量测定方法的改进与种质资源分析[J].大豆科学,2008,27(2):310-314.
[7]杨明亮,王继安.大豆凝集素含量测定及聚类分析[J].大豆科技,2009(5):20-24.
[8]张惟杰.糖复合物生化研究技术[M].杭州:浙江大学出版社, 1999.
[9]邢光南.大豆抗豆卷叶螟和筛豆龟蝽的鉴定、遗传和QTL分析[D].南京:南京农业大学,2007.
[10]姜振峰.大豆油分和蛋白质含量遗传效应及与环境互作效应QTL分析[D].哈尔滨:东北林业大学,2010.
[11]章元明,盖钧锰,王建康.利用回交B1和B2及F2群体鉴定数量性状两对主基因+多基因混合遗传模型并估计其遗传效应[J].生物数学学报,2000,15(3):358-366.
[12]章元明,盖钧锰,王永军.利用P1,P2和DH或RIL群体联合分离分析的拓展[J].遗传,2001,23(5):467-470.
[13]李振田,谯仕彦,李德发,等.间接抑制酶联免疫吸附法测定大豆凝集素方法的建立[J].中国畜牧杂志,2004,40(8):9-11.
[14]戴大章,陈妙月,叶均安,等.血凝法测定饲料中植物凝集素含量[J].中国兽医学报,2005,25(4):438-440.
[15]王贤智.大豆产量相关性状的遗传与稳定性分析及QTL定位研究[D].北京:中国农业科学院,2008.
[16]李海燕,仲伟杰,陈颖,等.大豆维生素E含量遗传初探[J].东北农业大学学报,2013,44(7):22-26.
[17]李海燕.大豆维生素E含量的遗传分析及QTL定位[D].哈尔滨:东北林业大学,2010.
[18]盖钧镒,章元明,王建康.植物数量性状遗传体系[M].北京:科学出版社,2003.
[19]Song Q J,Marek L F,Shoemaker R C,et al.A new integrated genetic linkage map of the soybean[J].Theoretical and Applied Genetics,2004,109(1):122-128.
[20]Cregan P B,Mudge J,Fickus E W,et al.Two simple sequence repeat markers to select for soybean cyst nematode resistance coditioned by the rhg1 locus[J].Theoretical and Applied Genetics, 1999,99(5):811-818.
[21]李文滨,赵雪.2009年大豆分子标记及辅助选择育种研究进展[J].东北农业大学学报,2010,41(1):139-148.
[22]张志刚,杨晓萍,梅正鼎,等.基因芯片技术在作物中的研究进展及展望[J].江西棉花,2016,28(1):3-5.
[23]梁士博,刘佳莹,刘杰,等.NGS技术在作物基因组研究中的应用[J].中国生物工程杂志,2017 37(2):111-120.
Genetic and QTL analysis of Soybean agglutinin(SBA)content
YANG Mingliang1,LI Ning2,LI Haiyan1,SUI Meinan1,WANG Ji'an1(Institute of Soybean Research, Northeast Agricultural University,Harbin 150030,China;2.School of Humanities and Law, Northeast Agricultural University,Harbin 150030,China)
Soybean agglutinin(SBA)was one of the antinutritional factors with stronger function and higher content in soybean,that could be an serious impact on the safety of the soybean food and feed.Reducing or eliminating SBA in soybean seed and products had become important on soybean food and feed industry.In order to map steady and repeatable QTLs of SBA content,a F7∶8RIL population containing 201 lines derived from cross between Hefeng 45 as female and Taipingchuan blacksoy as male parent were used in this experiment.Analysis of QTL and genetic model on SBA content was carried out in different environments.The results of separation analysis showed that SBA content accord with the 2 major genes+more gene hybrid genetic model.134 pairs of SSR primers had been used to analysis in RIL population,further construction of genetic map and QTL analysis for SBA content were conducted.The result of QTL analysis showed that 4 QTL were detected associated withSBA content in different environments.Each QTL were detected stability in different environment.Two QTL of SbaHTD1b-1 and SbaHTC1-1 reached significant level and explained higher phenotypic variation in different environments.These QTL might provide the valuable information for soybean molecular marker assistant breeding selection.
soybean;Soybean agglutinin(SBA)content;genetic analysis;QTL
Q786
A
1005-9369(2017)05-0009-12
时间2017-5-23 12:24:01[URL]http://kns.cnki.net/kcms/detail/23.1391.S.20170523.1224.004.html
杨明亮,李宁,李海燕,等.大豆凝集素(SBA)含量遗传分析与QTL定位[J].东北农业大学学报,2017,48(5):9-20.
Yang Mingliang,Li Ning,Li Haiyan,et al.Genetic and QTL analysis of Soybean agglutinin(SBA)content[J].Journal of Northeast Agricultural University,2017,48(5):9-20.(in Chinese with English abstract)
2017-04-05
国家自然科学基金面上项目(31671717)
杨明亮(1981-),男,博士研究生,研究方向为大豆遗传育种及生物技术。E-mail:yml5418@126.com
*通讯作者:王继安,研究员,博士生导师,研究方向为大豆遗传育种及生物技术。E-mail:wangsoy@163.com
