用于垃圾邮件识别的“词频-筛”混合特征选择方法*
2017-06-21陈俊颖周顺风闵华清
陈俊颖 周顺风 闵华清
(华南理工大学 软件学院∥广州市机器人软件及复杂信息处理重点实验室, 广东 广州 510006)
用于垃圾邮件识别的“词频-筛”混合特征选择方法*
陈俊颖 周顺风 闵华清
(华南理工大学 软件学院∥广州市机器人软件及复杂信息处理重点实验室, 广东 广州 510006)
文中针对当下愈发泛滥的垃圾邮件,分别使用朴素贝叶斯分类和支持向量机分类法对当前日益泛滥的垃圾邮件进行识别、分类,将“词频-筛”混合特征选择方法应用于分类器模型中,以提高分类器的识别性能.同时,通过考虑更全面的分类概率情况,改进朴素贝叶斯分类模型,进一步提升朴素贝叶斯分类器的识别性能.最后通过实验得到了该垃圾邮件识别系统的准确率、召回率和F1值等分类识别性能指标.实验结果表明,“词频-筛”混合特征选择方法能有效提高垃圾邮件分类器的识别性能,而且使用成本敏感方法的分类输出调节模块也能大大降低分类器将正常邮件误判为垃圾邮件的概率,因此,文中设计的垃圾邮件识别系统具有较强的实用性,可以在实际工作、生活中使用.
垃圾邮件识别;混合特征选择方法;朴素贝叶斯;支持向量机
截至2015年12月,中国网民数量已达 6.88亿[1].互联网服务渗透进人们日常生活的方方面面,其中电子邮件作为当前主流的一种通讯方式,是人们进行日常工作和生活交流的重要渠道.但近年来垃圾邮件的愈发泛滥给人们的工作和生活带来不良影响,也对社会经济造成巨大损失,因此改进垃圾邮件识别方法具有现实意义.
垃圾邮件识别的通用模式是:收集充分的垃圾邮件数据,通过机器学习的方法基于垃圾邮件数据集训练出智能垃圾邮件分类器[2- 3],然后使用该智能分类器对新邮件进行识别分类.其中,智能分类器所使用的典型分类模型有:朴素贝叶斯分类[4]、支持向量机分类[5]、Boosting分类[6]、k近邻分类[7]和决策树分类[8]等等.
文中对垃圾邮件识别的特征选择方法[9]进行优化,提出“词频-筛”混合特征选择方法,该方法混合多种邮件特征应用于分类模型中.此外,还对朴素贝叶斯分类模型进行优化,考虑更全面的分类概率情况.最后针对不同邮件数据集进行多种相关实验,验证了“词频-筛”混合特征选择方法对垃圾邮件识别性能的改进,测试了不同的分类模型和成本敏感方法对分类器识别性能的影响.
1 垃圾邮件识别系统设计及算法
1.1 系统概述
本研究的垃圾邮件识别分类系统模块结构如图1所示.
由图1可以看出,待分类识别的邮件首先经过邮件预处理模块,将邮件转化为文本信息,对中英文做分词处理,并且将数据转换为空间向量模型.接着,进入特征选择模块.在这个模块中,为了减少系统分类识别的运算时间和去除部分噪声,在待分类邮件的全部特征中选择合适的特征, 组成特征子集作为邮件分类器的特征集合.然后,针对选定特征集合,在邮件分类器模块对邮件进行分类识别.最后,采用成本敏感方法对邮件分类器的输出结果进行调节,降低分类器将正常邮件误判为垃圾邮件的概率,从而得到最终的邮件分类结果.
其中,邮件分类器模型是通过机器学习的方法训练获得的.在分类器训练过程中,使用降维后的邮件分类训练数据集,通过机器学习的相关分类识别算法训练得到一个垃圾邮件分类器,用于待分类邮件的分类识别.
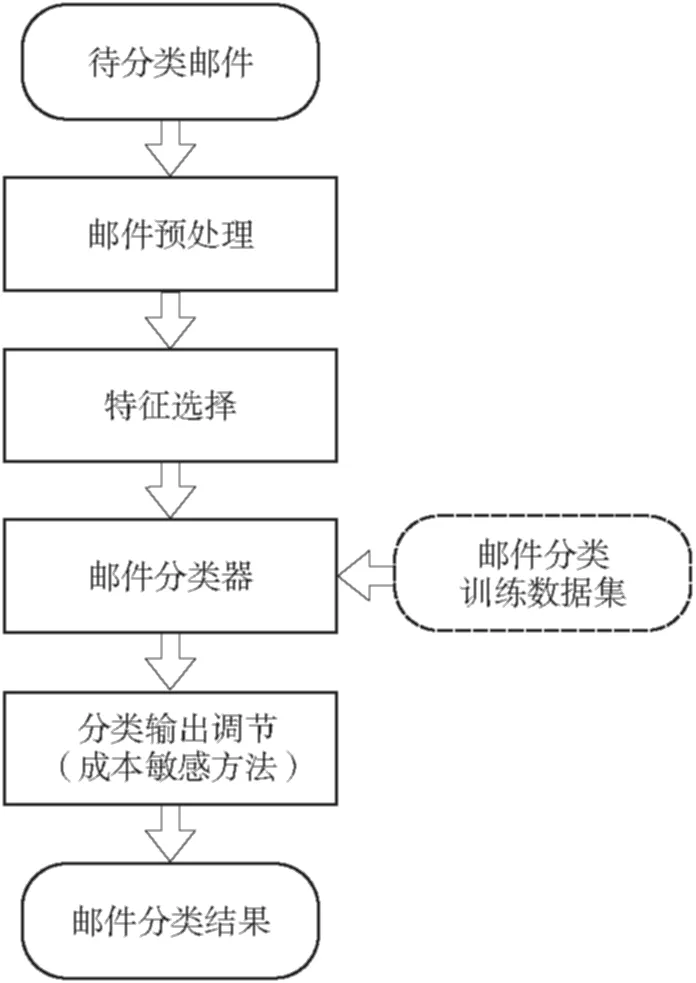
图1 垃圾邮件识别分类系统模块结构图
Fig.1 Modular structure diagram of spam identification system
1.2 邮件预处理模块
邮件一般分为主题、正文、图片和附件,主题和正文可认为均是文本.文本内容需转化为空间向量模型[10].其中,空间向量的权重计算方法一般有词频、文档频率和词频-逆向文档频率[11].使用空间向量模型可以很方便地记录文本信息,便于后期使用机器学习方法进行邮件识别分类.
不同于英文文本有着天然的分词结构,在将中文文本转化为空间向量模型时,必须对其进行分词处理[12].目前中文文本的分词方法有词典匹配法和字标注法.可参考的中文自动分词开源项目有:friso中文分词、Ansj分词、盘古分词和结巴分词等.
1.3 特征选择模块
当邮件数量巨大时,邮件的总特征集合将会过大,这将导致邮件分类器训练和分类的时间过长,并且将引入过多噪声.因此有必要进行特征降维[13].文中采用特征选择的方法来实现特征降维.文本分类中常用的特征选择方法有词频、信息增益[14]、互信息[15]、卡方检测[16]等.
这些传统的特征选择算法在分类器的分类识别性能上有着类似的表现,因此文中提出混合特征选择方法——词频-筛,综合上述特征选择方法的优点,提升垃圾邮件分类器的分类识别性能.
1.4 邮件分类器模块
1.4.1 基于朴素贝叶斯的分类器
文中讨论的朴素贝叶斯分类器模型有:二项独立模型[17]和多项式模型[18].
在二项独立模型中,假设邮件文档d包含特征单词w1,w2,…,wn,组成特征集wd,分类训练数据集中所有邮件文档的特征单词集合构成总特征集W(特征总数为N),在总特征集W中随机抽取出特征wk(1≤k≤N),如果特征wk在邮件文档d中出现,称wk∈wd,则邮件文档d属于邮件类别Ci(i=1,2;分别代表正常邮件类别和垃圾邮件类别)的概率如下:
(1)
二项独立模型仅统计一个特征单词是否在文档中出现;而多项式模型在二项独立模型的基础上将单词出现的频数也纳入考量.如果特征wk在邮件文档d中出现f次,则邮件文档d属于邮件类别Ci的概率如下:
(2)
1.4.2 基于支持向量机的分类器
支持向量机算法中,对于选定的n个特征,将每个样本数据视为一个n维空间里的向量,向量在每个维度上的值由权重计算方法确定.权重计算方法一般有布尔权重、词频权重和词频-逆向文档频率权重等.
在准备好样本数据集后,将训练数据集和训练参数(包括支持向量机的松弛变量、高斯核函数的宽度参数等)加载进支持向量机中,训练完成后即得到对应的垃圾邮件分类器.在保证准确度的前提下,为了减少分类器训练时间,随机从数据集中选择部分样本,将支持向量机的松弛变量和高斯核函数的宽度参数按照一定的步长进行调整,最终选择可以使分类器泛化错误率最小的松弛变量和宽度参数作为训练数据集的最终参数.
1.5 分类输出阈值调节模块
在垃圾邮件的分类识别中,将一封正常邮件识别为垃圾邮件导致的损失较大,可以通过成本敏感[19]方法降低分类识别决策的成本.成本敏感方法通过求解最大收益的方式来调整分类识别决策:假设当前判定邮件A是垃圾邮件的概率为PA,误判垃圾邮件的损失为x,误判正常邮件的损失为y,正确判定邮件的收益为z,那么将邮件A识别为垃圾邮件产生的总收益为
cs=PAz-(1-PA)y
(3)
而将邮件A识别为正常邮件的总收益为
cn=(1-PA)z-PAx
(4)
当且仅当
(5)
判定为正常邮件的收益较大.由于不等式右侧的x、y、z均为常数,因此令不等式右侧分数等于常数值H,这就是将邮件判定为正常邮件的临界阈值条件.针对不同数据集设定不同的阈值H,以平衡分类器的准确率和召回率,降低分类器的决策成本.
2 特征选择方法优化和分类模型算法优化
2.1 混合特征选择方法
文中的特征选择模块采用了混合特征选择方法.常用的特征选择方法有:词频、信息增益、互信息、卡方检测等.词频法是指统计每个特征词出现的频率,设定合理的阈值过滤掉部分高频词和低频词.类似于“我”、“这个”和“是”这样的高频词对分类决策基本没有影响,过滤后可减少训练和分类的时间;而低频词则多为噪声,过滤后可提高分类的准确性.信息增益是指按照信息熵的原则,将所有的词按照对分类后熵的影响大小排序,选择增益较大的词,即对分类影响较大的词作为特征子集.互信息用于测定两个随机变量间的相关性,统计特征单词与各个类别的互信息后取加权平均值.卡方检测是统计学中计算随机变量间相关性的常用方法之一,它同时考虑了特征存在和不存在的两种情况.
在上述常用特征选择方法的基础上,文中提出一种新的混合特征选择方法:词频-筛.该方法首先将所有特征单词按照词频排序,依次选择词频序列中的每个单词,如果该词出现在某个作为“筛”(筛选)用途的特征选择算法的特征词排序的第m位之后,那么过滤掉该词,否则就将该词作为特征子集保留;继续选择词频序列里的下一个特征词,进行同样的筛选.m一般可以取总特征数的40%、50%或60%,根据实际数据集来确定.作为“筛”的特征选择算法可以使用信息增益、互信息和卡方检测等方法.混合特征选择方法首先考虑了高频词的分类能力,而后将分类能力弱的高频词过滤,综合了词频法和其他特征选择算法的优点.
混合特征选择方法的优势在于:智能地去除了词频法中对分类无实际作用或者有反作用的高频词,而在运算上只增加了一次按照特征选择方法将特征排序的过程,该方法可以让分类器获得稳定的识别性能提升.
2.2 朴素贝叶斯分类算法优化
文中在朴素贝叶斯二项独立模型中,在考虑式(1)的前提下,同时考虑文档d中未出现特征wk的情况,则文档d属于类别Ci的概率如下:

(6)
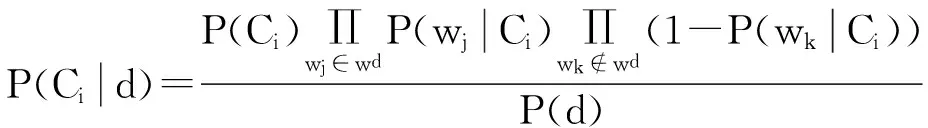
(7)
根据朴素贝叶斯分类算法,判断文档d的类别q为某个类型Q,当且仅当d的判断条件B(d)为
(8)
同样地,在多项式模型中也同时考虑文档d中未出现特征wk的情况,则文档d属于类别Ci的概率如下:
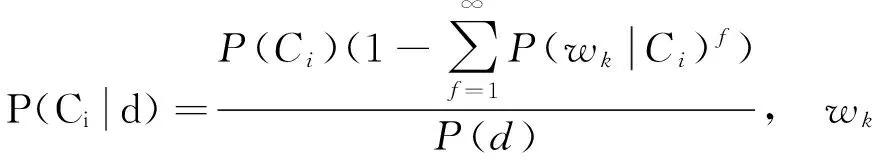
(9)
通过计算等比数列的和,式(9)简化为
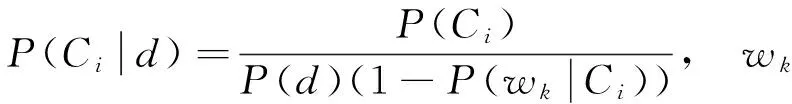
(10)
根据朴素贝叶斯分类算法,判断文档d的类别q为某个类型Q,当且仅当d的判断条件B(d)为
(11)
式中, fj表示wj出现的次数.
以上对朴素贝叶斯分类模型进行的优化,考虑了更全面的分类概率情况,可以提高分类模型的识别准确性.
3 实验设计和实验结果分析
3.1 实验环境和实验评价指标
文中所有实验代码均使用Python程序设计语言编写,实验中对任意选择后的数据集均进行十折交叉验证[20],实验结果取10次测试结果的平均值.
文中使用的数据集有:笔者收集的垃圾邮件数据集(数据集1)和TREC2007(国际文本信息检索会议TextRetrievalConference2007)垃圾邮件数据集(数据集2).数据集1的邮件文档数据来自于笔者的邮箱,共计811封邮件,包括490封垃圾邮件和321封非垃圾邮件;该数据集将主要用于评价垃圾邮件识别算法的实用性和泛化能力.数据集邮件均去除了附件,保留了主题、发件人、正文及附件文件名等信息.
垃圾邮件识别性能的评价指标有:准确率、召回率和F1测试值等[21].按照垃圾邮件分类器对邮件的预测,定义a表示预测实际非垃圾邮件为非垃圾邮件的数量、b表示预测实际垃圾邮件为非垃圾邮件的数量、c表示预测实际非垃圾邮件为垃圾邮件的数量、d表示预测实际垃圾邮件为垃圾邮件的数量.
此外,定义准确率(p)为
(12)
定义召回率(R)为
(13)
则F1测试值定义为
(14)
F1测试值综合考虑识别算法的查准和查全的能力;同时,由于需要减少误判的概率,即要求召回率尽量大,因此文中将准确率、召回率和F1值作为分类识别性能的主要评价指标.
3.2 混合特征选择方法对识别性能的影响
3.2.1 对朴素贝叶斯分类器识别性能的影响
为了完整测试各个特征选择算法对朴素贝叶斯分类器识别性能优化的幅度,在数据集1上,依次使用词频法、信息增益法、互信息法、卡方检测法和3种混合特征选择方法.混合特征选择方法Ⅰ、Ⅱ、Ⅲ分别使用了信息增益、互信息和卡方检测等“筛”排序前50%的特征词中,词频排序前1 200、700和1 300的特征词.
应用上述特征选择方法选择对应的最优特征集作为特征子集后,使用基于多项式模型的朴素贝叶斯分类模型对数据集进行识别分类,分类识别性能见表1.
表1 使用不同特征选择方法的朴素贝叶斯分类器(多项式模型)对数据集1的识别性能
Table 1 Identification performance of naive Bayes classifier (using polynomial model) with different feature selection methods applied to dataset 1
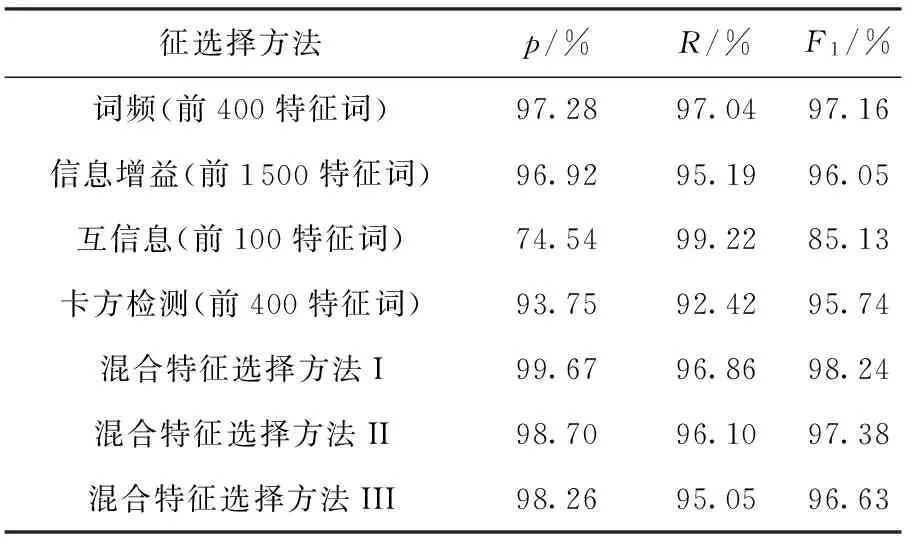
征选择方法p/%R/%F1/%词频(前400特征词)97.2897.0497.16信息增益(前1500特征词)96.9295.1996.05互信息(前100特征词)74.5499.2285.13卡方检测(前400特征词)93.7592.4295.74混合特征选择方法I99.6796.8698.24混合特征选择方法II98.7096.1097.38混合特征选择方法III98.2695.0596.63
从表1可以看出,基于互信息的特征选择方法虽然召回率最优,但准确率过低,影响实际使用;而混合特征选择方法I则在F1值评价指标中优于其他特征选择方法.
3.2.2 对支持向量机分类器识别性能的影响
文中分别使用不同的特征选择方法,选择对应最优的前3 000个特征作为特征子集,使用基于布尔权重的支持向量机对数据集1进行识别分类,分类器识别性能见表2.
表2 使用不同特征选择方法的支持向量机分类器(布尔权重)对数据集1的识别性能
Table 2 Identification performance of support vector machine classifier (using Bool weighting) with different feature selection methods applied to dataset 1
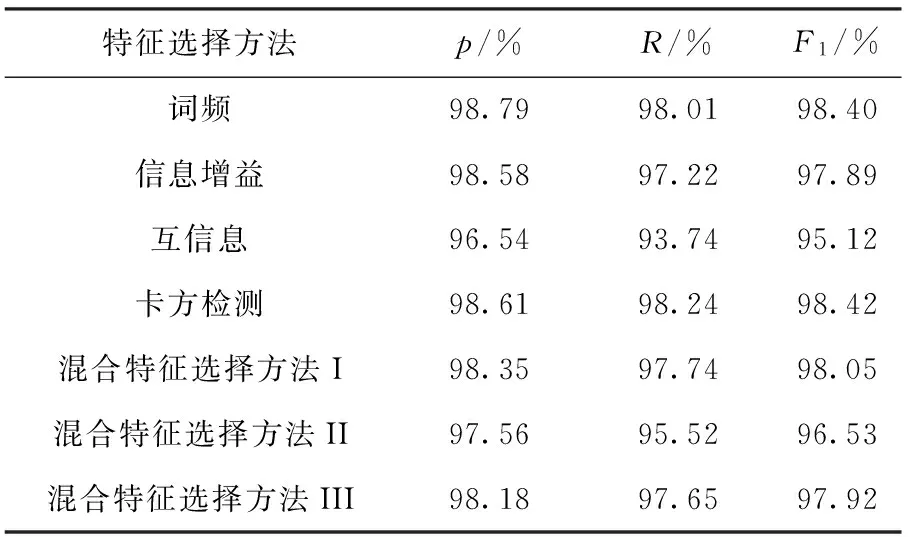
特征选择方法p/%R/%F1/%词频98.7998.0198.40信息增益98.5897.2297.89互信息96.5493.7495.12卡方检测98.6198.2498.42混合特征选择方法I98.3597.7498.05混合特征选择方法II97.5695.5296.53混合特征选择方法III98.1897.6597.92
这里选择3 000特征词是为了保证分类器的运算效率.混合特征选择方法I、II、III分别使用信息增益、互信息和卡方检测作为“筛”算法,选择特征数量同样为3 000.
从表2中可以得出,在支持向量机分类器中,使用词频法和卡方检测法作为特征选择方法可以使分类器获得很接近的分类识别性能,所以一般情况下直接统计词频,选择部分高词频词作为特征子集即可获得良好的分类识别性能.值得注意的是,在支持向量机这样的线性分类器中,使用混合特征选择方法并没有达到更好的效果,整体分类识别性能与非混合型传统特征选择方法相近.
此外,综合对比表1,可以发现针对不同的特征选择方法,支持向量机分类器的识别性能跟朴素贝叶斯分类器的识别性能相比,相对平稳.然而朴素贝叶斯分类器的优势是实现简单,增量更新方便,更易在现实应用场景中使用.
3.3 分类模型对识别系统性能的影响
除了测试验证不同特征选择方法对朴素贝叶斯分类器和支持向量机分类器识别性能的影响外,文中还测试不同分类模型对朴素贝叶斯分类器和支持向量机分类器的识别性能影响.
3.3.1 概率模型对朴素贝叶斯分类器识别性能的影响
针对数据集1和数据集2,分别使用二项独立模型和多项式模型测试朴素贝叶斯分类器相应的准确率、召回率和F1测试值.
数据集1中的邮件绝大多数为中文邮件,从垃圾邮件和非垃圾邮件中各选取300封邮件作为数据集.上述600封邮件的总特征数约为30 000,选择词频由高到低处于第101位到1 000位的词作为特征子集.测试结果为:使用二项独立模型计算得出的准确率、召回率和F1值分别为95.27%、96.41%和95.77%;而使用多项式模型计算得出的准确率、召回率和F1值分别为97.07%、97.35%和97.16%.
使用同样的方法,在数据集2上进行测试.由于邮件样本数量巨大,因而随机选择400封垃圾邮件和400封非垃圾邮件作为邮件数据集;另外,选择词频排名前1 000的词作为特征子集.测试结果为:使用二项独立模型计算得出的准确率、召回率和F1值分别为98.71%、93.93%和96.22%;而使用多项式模型计算得出的准确率、召回率和F1值分别为96.77%、97.45%和97.07%.
通过上述测试结果可以看到,多项式模型针对不同数据集在各项评测指标中相较于二项独立模型均更优.原因是多项式模型中包含了词频数据,使分类器获得更多有效信息.
3.3.2 权重模型对支持向量机分类器识别性能的影响
文中在数据集1和数据集2上,分别采用布尔权重、词频权重作为权重模型,使用词频特征选择法测试支持向量机分类器相应的准确率、召回率和F1测试值,实验测试结果如下:在数据集1上,使用布尔权重计算得出的准确率、召回率和F1值分别为97.82%、97.23%和97.50%;使用词频权重计算得出的准确率、召回率和F1值分别为98.15%、90.89%和94.29%.在数据集2上,使用布尔权重计算得出的准确率、召回率和F1值分别为99.03%、99.02%和99.01%;使用词频权重计算得出的准确率、召回率和F1值分别为98.17%、86.53%和91.85%.
从上述测试结果可以发现,使用布尔权重的支持向量机分类器的分类识别性能要优于使用词频权重的支持向量机分类器,而且在统计数据上也更为简单.
3.4 阈值调节对识别性能的影响
使用成本敏感方法对分类器输出结果进行阈值调节,测试分类器的识别性能.在数据集1上使用基于词频概率模型的朴素贝叶斯分类模型,选择词频由高到低处于第101位到1 000位的词作为特征子集,依次测试调节阈值后的分类器各项识别性能指标,实验结果见表3.
表3 基于成本敏感方法调节的朴素贝叶斯分类器对数据集1的识别性能
Table 3 Identification performance of cost-sensitive adjustment method-based Bayes classifier applied to dataset 1

阈值设定p/%R/%F1/%097.0797.3597.161093.6297.9295.642094.1398.6296.253093.1998.6895.79
从表3可以看出,朴素贝叶斯分类器的召回率随着分类阈值的提高而稳步上升,同时F1值有下降的趋势.
4 结语
文中设计了一个垃圾邮件识别系统,对垃圾邮件识别系统的各个模块都进行了详细的描述说明.在传统特征选择方法和朴素贝叶斯分类模型上,都进行了相应的优化:采用“词频-筛”混合特征选择方法,综合了词频法和其他特征选择算法的优点,以使分类器获得稳定的分类识别性能提升;考虑更全面的分类概率情况,改进朴素贝叶斯分类模型,提高了朴素贝叶斯分类器的识别性能.实验数据集1的测试结果表明,将文中所述的分类方法运用到实际生活中时,能提高垃圾邮件判断的准确性和可靠性,具有较强的实用性价值.
文中设计了多个实验,测试验证不同的特征选择方法、不同的分类模型和成本敏感阈值调节方法对垃圾邮件识别系统的召回率和F1值等分类识别性能指标的影响,得到有实践意义的实验结果数据.基于文中的实验结果分析,可以得出以下结论:
(1)使用了“词频-筛”混合特征选择方法的朴素贝叶斯分类器的分类效果要优于不使用混合特征选择方法的朴素贝叶斯分类器.
(2)支持向量机分类器的效果一般情况下优于使用了“词频-筛”混合特征选择方法的朴素贝叶斯分类器,但朴素贝叶斯分类器可以通过阈值调节等方法改进自身的召回率,并且支持训练数据集的增量更新,从而取得更好的效果.
(3)“词频-筛”混合特征选择方法在支持向量机分类器中的应用效果不如在朴素贝叶斯分类器中的应用效果好,这是后续研究工作中要着重研究解决的问题.
因此,未来的工作将在支持向量机分类器中探索更适合的混合特征选择方法.
[1] 中国互联网络信息中心.中国互联网络发展状况统计报告 [DB/OL].(2016- 01- 22)[2016- 01- 30].http:∥www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201601/t20160122_53271.htm.
[2] GUZELLA T S,CAMINHAS W M.A review of machine learning approaches to Spam filtering [J].Expert Systems with Applications,2009,36(7):10206- 10222.
[3] JACKOWSKI K,KRAWCZYK B,WOZNIAK M.Application of adaptive splitting and selection classifier to the spam filtering problem [J].Cybernetics and Systems,2013,44(6/7):569- 588.
[4] ZHANG L,JIANG L,LI C.A new feature selection approach to naive Bayes text classifiers [J].International Journal of Pattern Recognition and Artificial Intelligence,2016,30(2):1650003.
[5] IOSIFIDIS A,GABBOUJ M.Multi- class support vector machine classifiers using intrinsic and penalty graphs [J].Pattern Recognition,2016,55:231- 46.
[6] REN D,QU F,LV K,et al.A gradient descent boosting spectrum modeling method based on back interval partial least squares [J].Neurocomputing,2016,171:1038- 1046.
[7] HU J,LI Y,YAN W- X,et al.KNN- based dynamic query- driven sample rescaling strategy for class imbalance learning [J].Neurocomputing,2016,191:363- 373.
[8] MA L,DESTERCKE S,WANG Y.Online active learning of decision trees with evidential data [J].Pattern Recognition,2016,52:33- 45.
[9] GUYON I,ELISSEEFF A.An introduction to variable and feature selection [J].Journal of Machine Learning Research,2003,3:1157- 1182.
[10] TURNEY P D,PANTEL P.From frequency to meaning:vector space models of semantics [J].Journal of Artificial Intelligence Research,2010,37(1):141- 188.
[11] AIZAWA A.An information-theoretic perspective of tf-idf measures [J].Information Processing & Management,2003,39(1):45- 65.
[12] Gao J F,Li M,Wu A,et al.Chinese word segmentation and named entity recognition:a pragmatic approach [J].Computational Linguistics,2005,31(4):531- 574.
[13] GUYON I,ELISSEEFF A.An introduction to feature extraction [M]∥Guyon I,Gunn S,Nikravesh M,Zadeh L A.Feature extraction:foundations and applications.New York:Springer,2006:1- 24.
[14] 任永功,杨荣杰,尹明飞,等.基于信息增益的文本特征选择方法 [J].计算机科学,2012,39(11):127- 130. REN Yong-gong,YANG Rong-jie,YIN Ming-fei,et al.Information-gain-based text feature selection method [J].Computer Science,2012,39(11):127- 130.
[15] 娄铮铮,叶阳东.基于最大化交叉互信息的对称IB算法[J].计算机学报,2016,39(8):1- 15. LOU Zheng-zheng,YE Yang-dong.Symmetric information bottleneck based on maximization inter-correlated mutual information [J].Chinese Journal of Computers,2016,39(8):1- 15.
[16] 丁海勇,史文中.利用卡方分布改进N-FINDR端元提取算法 [J].遥感学报,2013,17(1):122- 137. DING Hai-yong,SHI Wen-zhong.Fast N-FINDR algorithm for endmember extraction based on chi- square distribution [J].Journal of Remote Sensing,2013,17(1):122- 137.
[17] OJALA T,PIETIKAINEN M,MAENPAA T.Multiresolution gray-scale and rotation invariant texture classification with local binary patterns [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(7):971- 987.
[18] TOH K A,YAU W Y,JIANG X.A reduced multivariate polynomial model for multimodal biometrics and classifiers fusion [J].IEEE Transactions on Circuits and Systems for Video Technology,2004,14(2):224- 233.
[19] 凌晓峰,Sheng Victor S.代价敏感分类器的比较研究[J].计算机学报,2007,30(8):1203- 1212. LING Charles X,SHENG Victor S.A comparative study of cost- sensitive classifiers [J].Chinese Journal of Computers,2007,30(8):1203- 1212.
[20] KOHAVI R.A study of cross-validation and bootstrap for accuracy estimation and model selection [C]∥Proceedings of 14th International Joint Conference on Artificial Intelligence.Montreal:Morgan Kaufmann,1995:1137- 1143.
[21] TANTUG A C N,ERYIGIT G L.Performance analysis of Naive Bayes classification,support vector machines and neural networks for spam categorization [C]∥Proceedings of Advances in Soft Computing.Berlin:Springer,2006:495- 504.
“Word Frequency- Filtering”Hybrid Feature Selection Method Applied to Spam Identification
CHENJun-yingZHOUShun-fengMINHua-qing
(School of Software Engineering∥Guangzhou Key Laboratory of Robotics and Intelligent Software,South China University of Technology,Guangzhou 510006,Guangdong,China)
In order to solve the increasingly rampant spam problem, naive Bayes and support vector machine classification methods are used to identify spam emails in this paper.In this method,“word frequency-filtering” hybrid feature selection method is applied to classification models to improve the identification performance of classifiers, and the identification performance of naive Bayes classification method is enhanced by considering more comprehensive classification probability cases.Moreover, some experiments are designed to test and verify the identification performance of the spam detection system in terms of accuracy rate, recall rate andF1score.The results show that the proposed “word frequency-filtering” hybrid feature selection method can improve the identification performance of spam classifiers effectively, and that the classification output adjustment module based on the cost-sensitive me-thod can greatly reduce the probability that the classifier mistakes a non-spam email as a spam email.In conclusion, the spam identification system designed and implemented in this paper possesses strong practicability and applicability in practical work and life.
spam identification; hybrid feature selection method; naive Bayes; support vector machine
2016- 05- 03
广东省自然科学基金资助项目(2016A030310412);广东高校省级重点平台及科研项目-青年创新人才类项目(2015KQNCX003);广州市科技计划重点实验室项目(15180007);广州市科技计划项目(201707010223) Foundation item: Supported by the Natural Science Foundation of Guangdong Province of China (2016A030310412)
陈俊颖(1984-),女,讲师,博士,主要从事高性能成像和模式识别研究.E-mail:jychense@scut.edu.cn
1000- 565X(2017)03- 0082- 07
TP 391.43
10.3969/j.issn.1000-565X.2017.03.012
