基于双向长短时记忆模型的中文分词方法*
2017-06-21张洪刚李焕
张洪刚 李焕
(北京邮电大学 信息与通信工程学院, 北京 100876)
基于双向长短时记忆模型的中文分词方法*
张洪刚 李焕
(北京邮电大学 信息与通信工程学院, 北京 100876)
中文分词是中文自然语言处理中的关键基础技术之一.目前,传统分词算法依赖于特征工程,而验证特征的有效性需要大量的工作.基于神经网络的深度学习算法的兴起使得模型自动学习特征成为可能.文中基于深度学习中的双向长短时记忆(BLSTM)神经网络模型对中文分词进行了研究.首先从大规模语料中学习中文字的语义向量,再将字向量应用于BLSTM模型实现分词,并在简体中文数据集(PKU、MSRA、CTB)和繁体中文数据集(HKCityU)等数据集上进行了实验.实验表明,在不依赖特征工程的情况下,基于BLSTM的中文分词方法仍可取得很好的效果.
深度学习;神经网络;双向长短时记忆;中文分词
中文分词是中文自然语言处理中的关键基础技术之一,是其他中文文本任务(如命名实体识别、句法分析、语义分析等)的前期关键处理环节,其分词的准确性对中文自然语言处理尤为重要.
传统机器学习方法在中文分词领域取得了飞速发展,有着丰富的分词算法,如最大正向匹配、最大逆向匹配、双向匹配等基于词典的方法.基于词典的分词算法针对输入的中文句子,通过与词典进行对比,将输入的中文句子分成单字或多字组成的词,从而达到分词的目的.然而,由于中文句子是连续的文字,存在大量的歧义和未登录词问题,严重影响最终的切分效果.
(1) 中文歧义识别.歧义是指同样一个句子,有多种切分方法.中文歧义一般分为交集型歧义、覆盖型歧义和真歧义.对于一个句子,必须根据上下文语境,才能得到正确的分词结果.
(2) 未登录词识别问题.由于中文本身所具有的复杂性,不存在包含所有中文词语的词典,待切分语句中很有可能存在词典中没有收录的词,即未登录词.未登录词包含地名、人名等,严重影响了中文分词的准确率和效率.
传统分词方法依赖于词典匹配,不能很好地解决中文歧义和未登录词问题.为解决这两个关键问题,很多研究工作集中于基于字标注的中文分词方法.基于字标注的中文分词方法假设一个词语内部文本高内聚,词语的边界与外部文字低耦合.通过统计的机器学习方法判断词边界是当前中文分词的主流做法,主要使用序列标注模型进行BMES标注.Xue[1]提出了基于HMM模型的字标注分词方法,刘群等[2]提出了基于层叠隐马模型的汉语词法分析方法,Peng等[3]提出了基于子分类的CRF模型进行中文分词.对于字标注中文分词方法的改进包括设计更多高效的特征[4]和引入更多的标签选择[5]以及将无监督机器学习算法中使用的特征引入到有监督方法中[6]等.然而,传统机器学习算法依赖于人工设计的特征,而一个特征的有效性需要反复尝试和验证.因此,中文分词任务的特征工程是一个巨大的挑战.
近些年来,随着深度学习的兴起,基于神经网络的模型被更多地运用于自然语言处理领域,如词性标注、命名实体识别、情感分类等任务.Collobert等[7]设计了SENNA系统,利用神经网络解决了英文序列标注问题;Zheng等[8]利用SENNA系统实现了中文分词和词性标注,并提出一个感知机算法加速训练过程;Chen等[9]将门控递归神经网络(GRNN)运用于中文分词任务中,取得了很好的效果.研究表明,深度学习在避免了繁琐的特征工程的情况下,在自然语言处理领域取得了巨大的成功.
但是,这些研究提出的方案和模型,并没有充分挖掘神经网络在自然语言处理任务上的潜力.在中文分词任务中,句子序列上下文依赖信息对中文分词的准确性起着重要的作用.而传统的循环神经网络(RNN)只能利用句子序列的上文信息,无法利用未来信息.为了解决这个问题,文中提出一个基于双向长短时记忆(BLSTM)的神经网络模型,以有效利用序列数据中的上下文依赖信息.
1 基于BLSTM的模型构建
中文分词任务可以看成是基于单字的序列标注任务.与其他基于字的分词方法相似,文中采用BMES标注方式来对汉字进行标注.对于多字词,词语中的第一个汉字标签为B,中间字的标签为M,最后一个汉字标签为E;对于单字词,其标签为S.
1.1 模型框架和流程
基于神经网络的序列标注任务常用的模型框架主要由三部分构成,第1部分利用词向量(Word Embedding)技术将输入的中文字符转成一个向量矩阵,中间部分是典型的神经网络结构,最后一层是标签判别层,利用Softmax方法输出句子序列的标签信息,具体模型框架如图1所示.
对于一个长度为n的句子c(1∶n),文中选取一个包括上下文和当前字、长度为ω的词窗,其中上文和下文均为(ω-1)/2个字.图中第1层输入长度为ω的原始文本,经过第1层将每个字转换成其相对应的长度为d的向量vi,将ω个向量组成ω×d的输入矩阵x(t)作为神经网络的输入层.从输入层到隐藏层的函数为
z(t)=W1x(t)+b1
(1)
式中,W1表示输入层到隐藏层的连接权值矩阵,b1为隐藏层的偏置参数矩阵.

图1 中文分词模型框架
h(t)=σ(z(t))
(2)
输出层函数为
y(t)=W2h(t)+b2
(3)
式中,W2表示隐藏层到输出层的权值矩阵,b2为输出层的偏置参数矩阵,y(t)为当前字被打上不同标签的概率.
笔者在这个框架的基础上进行改进,在中间神经网络部分引入BLSTM,其能够有效利用句子序列中的上下文依赖信息.
1.2 相关原理介绍
1.2.1 词向量
词向量技术是将深度学习引入自然语言处理的核心技术,该技术使用一个稠密的特征向量代替原来的one-hot稀疏向量来表示每个词汇.研究表明,这种特征向量能够很好地表示词的语义和句法信息[10].
具体地,笔者使用训练语料集中包含的所有字单元建立一个大小为d×N的汉字字典矩阵D,其中d为每个字向量的长度,N为字典的大小.汉字字典包含系统中可以处理的所有汉字和用于表示除这些汉字以外的其他字符(如数字、标点、未登录字等)的替代符号.每个字都可以从字典中找到对应的字向量来代替,输入的句子可以由一个实值的矩阵表示.研究表明,使用大规模无监督学习得到的字向量作为输入矩阵的初始值比随机初始化有着更优的效果[11].
1.2.2 传统RNN
传统RNN的核心思想是在网络隐藏层中增加节点间的互连.通过这种连接,隐藏层能够保存并利用历史信息来辅助处理当前数据,网络结构如图2所示.
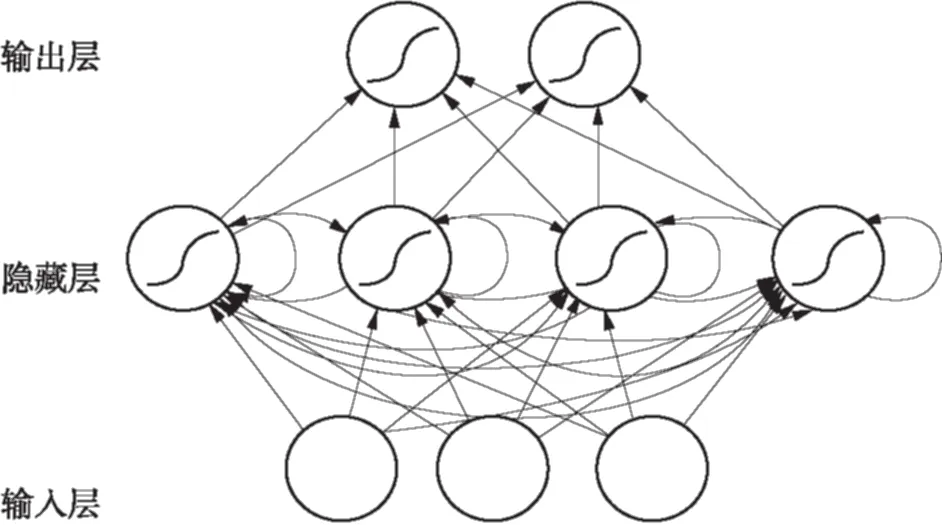
图2 RNN网络结构示意图
将RNN网络按时间进行展开的网络结构如图3所示.

图3 RNN展开结构示意图
图中的每个节点表示在每个时刻RNN网络的一层.w1表示输入层到隐藏层的连接权值,w2表示从上一时刻隐藏层到当前时刻隐藏层的连接权值,w3表示隐藏层到输出层的权值.在RNN中,每一个时刻的权值都是共享的,当前时刻的输出依赖于上一时刻.
第t时刻隐藏层的输出为
h(t)=g(Uh(t-1)+Wx(t)+b)
(4)
式中,U为RNN中输入层到隐藏层的权值矩阵,W为隐藏层到输出层的权值矩阵,x(t)为第t时刻的输入,b为偏置参数,g通常选用tanh函数作为激活函数.模型的迭代过程从t=1时刻开始,随着t的增长,迭代使用式(4)进行计算.
1.2.3 双向RNN
对自然语言处理领域的许多任务来说,未来的信息和历史信息同样重要.例如,在命名实体识别任务中,对于当前词的识别,在它之前和在它之后的词语信息一样重要.但是,传统的RNN只能单向输入序列信息,无法利用未来的信息.于是,Schuster等[12]提出了双向RNN(BRNN),核心思想是将序列信息分两个方向分别输入模型中,模型使用两个隐藏层分别保存两个方向输入数据的信息,并将相应的输出连接到相同的输出层.BRNN的展开形式如图4所示.

图4 BRNN展开结构示意图
Fig.4 Schematic diagram of an unrolled bidirectional recurrent neural network
BRNN理论上可以让模型在处理当前数据的时候同时利用到整个序列的上下文信息.
1.2.4 LSTM
传统的RNN展开后相当于一个多层的神经网络,当层数过多时会导致参数训练的梯度消失问题,从而导致长距离历史信息损失.因此,传统RNN在实际应用时,能够利用的历史信息非常有限.
为了弥补传统RNN的缺陷,Hochreiter等[13]提出了LSTM,替代传统RNN隐藏层中的RNN网络,用于解决RNN的梯度消失问题.LSTM单元结构如图5所示.
LSTM设计了记忆单元用于保存历史信息.历史信息分别受到输入门、遗忘门、输出门的控制.LSTM被成功应用于多个自然语言处理任务中,如文本分类[14]、机器翻译[15]、语言模型[16]等.
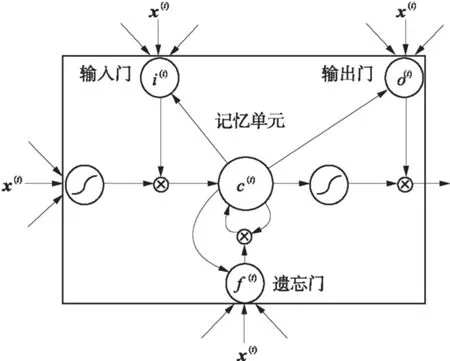
图5 LSTM单元结构示意图
设h为LSTM的单元输出,c为LSTM记忆单元的值,x为输入的数据.LSTM记忆单元的更新如下步骤所示:

(5)
(2) 在LSTM中,输入门用于控制当前数据对记忆单元的影响.设输入门的状态值为i(t),i(t)的计算除了受当前输入数据x(t)和上一时刻LSTM单元输出值h(t-1)的影响之外,还受到上一时刻记忆单元值c(t-1)的影响,bi为偏置参数,则有
i(t)=σ(Wxix(t)+Whih(t-1)+Wcic(t-1)+bi)
(6)
式中,σ取值范围为(0,1).
(3) 遗忘门用于控制历史信息对于当前记忆单元状态值的影响.设遗忘门的值为f(t),bf为偏置参数,则有
f(t)=σ(Wxfx(t)+Whfh(t-1)+Wcfc(t-1)+bf)
(7)
(4) 设c(t)为当前时刻记忆单元的状态值,则有
(8)
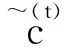
(5) 设输出门的输出状态值为o(t),用于控制记忆单元状态值的输出,bo为偏置参数,则有
o(t)=σ(Wxox(t)+Whoh(t-1)+Wcoc(t-1)+bo)
(9)
(6)最后,LSTM单元的输出计算公式为
h(t)=δ(o(t),tanh(c(t)))
(10)
LSTM通过输入门、遗忘门和输出门的设计,使得LSTM具有保存、读取和更新长距离历史信息的能力.
1.2.5BLSTM
BLSTM将BRNN和LSTM这两种改进的RNN模型组合在一起,在双向RNN模型中使用LSTM记忆单元.BLSTM在多项自然语言处理任务中表现出色,如序列标注[17]、手写数字识别[18]、视频字幕提取[19].BLSTM是文中重点研究的模型.
1.2.6Dropout
Dropout是一种防止神经网络模型过拟合的技术,由Srivastava等[20]在2014年提出.Dropout在模型训练的时候,随机选取一定比例p的隐藏节点不工作.不工作的节点对应的权值在当前训练中不更新.但是在模型使用时,应用所有的节点,将网络恢复.Dropout技术可用于解决深度神经网络模型在训练过程中的过拟合问题,能有效降低错误率,提升系统性能.
2 实验结果及分析
2.1 数据集与实验环境
文中选用了4种常见数据集(PKU、MSRA、CTB、HKCityU)进行实验.在实验过程中,将数据集的前90%作为训练集,后10%作为测试集.实验采用了分词评测常用的P(准确率)、R(召回率)和F(综合指标F 值)等评测指标.实验在内存为8G的Linux系统上进行,采用的编程语言为Python,并利用GPU对模型训练进行加速.
2.2 实验结果
2.2.1 字向量长度设置
文中采用word2vec方法[21],在大规模的无标注语料上进行字向量训练,将训练完成的字向量作为本次实验的词向量.
字向量的长度对中文分词的速度和准确度都起着至关重要的作用.文中采用不同长度的字向量,基于BLSTM模型和PKU数据集进行了第1步实验,实验结果见表1.
表1 不同长度的字向量的BLSTM性能对比
Table 1 Performance of BLSTM with different embedding dimensions
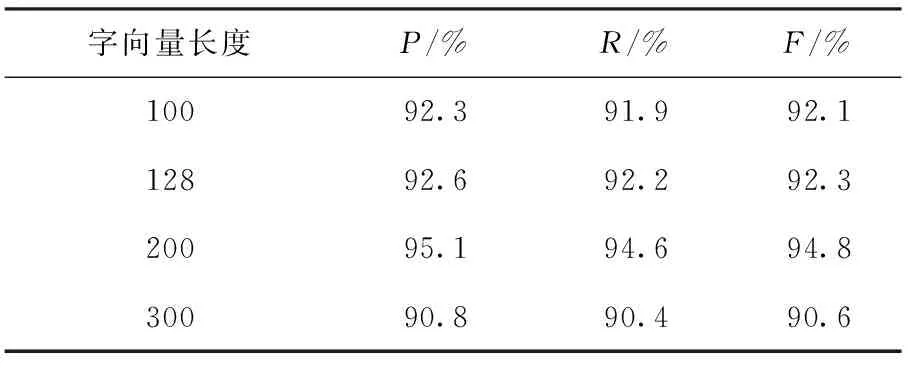
字向量长度P/%R/%F/%10092.391.992.112892.692.292.320095.194.694.830090.890.490.6
由实验结果可知,模型在字向量长度为200时,性能达到最优.当字向量长度大于200之后,模型变得更难训练且性能下降,说明在将字向量应用到中文分词中时,向量长度不应过大.
2.2.2 Dropout设置
Dropout可以防止神经网络模型过拟合.文中采用不同的Dropout 比例,在PKU数据集上进行了实验,结果见表2.
表2 不同Dropout比例的BLSTM性能对比
由实验结果可知,当Dropout比例为20%时,模型性能达到最优,但并没有显著提升.当Dropout 比例为50%时,由于训练中不工作的节点过多,模型欠拟合,导致性能下降.
2.2.3 初始化方式设置
为了验证字向量初始化对中文分词效果的影响,本实验对字向量初始化和随机初始化这两种初始化方式分别在PKU数据集上进行实验,实验结果见表3.

表3 不同初始化方式的BLSTM性能对比
由实验结果可知,使用训练好的字向量作为输入矩阵的初始值相比随机初始化,有着更优的性能.
2.2.4 实验结果分析和比较
经过上述3次实验,文中采用长度为200的字向量和20%的Dropout比例进行实验,并将实验结果与其他学者的实验结果进行比较.各个模型的实验结果对见表4,和其他学者的实验结果对比见表5.

表4 BLSTM与BRNN、LSTM模型的性能对比
表5 BLSTM和其他学者的实验结果(F值)对比
表4列出了BLSTM、BRNN和LSTM等神经网络模型的实验结果(F值).对比表明,BLSTM模型在简体中文和繁体中文中都取得了很好的分词效果;在相同的数据集上,BLSTM比LSTM、BRNN取得了更优的实验结果.
表5列出了笔者与其他学者的实验结果.其中,Zhao等[22]基于CRF模型,提出了一个中文分词系统;Zhang等[23]采用基于词的分词算法,从整个词中提取所需特征;Collobert等[7]提出了基于子分类的CRF模型进行中文分词,采用了大量的人工设计的特征;Sun等[24]从大量的无标注语料中提取额外信息,从而进行中文分词.这些学者都采用了大量复杂的人工设计的特征.由表5可知,文中在没有进行特征工程的情况下,比这些传统的方法取得了相近甚至更优的实验结果,充分说明了深度学习在中文分词任务中的优越性,也说明了特征工程在分词任务中的重要作用.
3 结语
文中针对自然语言处理中的中文分词任务,基于BLSTM构建了一个深度神经网络模型,能够有效利用序列长距离信息和序列上下文信息.模型在不依赖特征工程的情况下,利用字向量作为特征表示,在标准数据集上取得了很好的效果.实验表明,BLSTM是一种有效的中文分词方法,具有无限的潜力.同时,文中提出的模型也适用于其他序列标注任务.
尽管文中提出的模型在中文分词任务中取得了很好的效果,但仍有需改进的地方.比如,字向量的表示对模型的性能有着重要的影响,应在更具一般性、更大规模的语料集上进行无监督学习来获得更优的字向量;文中提出的BLSTM模型是单层网络结构,可以使用多层网络来优化模型;在预处理时,可以利用卷积神经网络(CNN)进行多模型组合使用,以提高模型的性能.这些改进方法都有待进一步的研究和探索.
[1] XUE N.Chinese word segmentation as character tagging [J].Computational Linguistics Chinese Language Processing,2003,8(1):29- 48.
[2] 刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析 [J].计算机研究与发展,2004,41(8):1421- 1429. LIU Qun,ZHANG Hua- ping,YU Hong- kui,et al.Chinese lexical analysis using cascaded hidden Markov model [J].Journal of Computer Research and Development,2004,41(8):1421- 1429.
[3] PENG F,FENG F,MCCALLUM A.Chinese segmentation and new word detection using conditional random fields [C]∥Proceedings of the 20th International Conference on Computational Linguistic.Geneva:Aossciation for Computational Linguistics,2004:562- 568.
[4] TANG B,WANG X,WANG X.Chinese word segmentation based on large margin methods [J].International Journal on Asian Language Processing,2009,19(2):55- 68.
[5] ZHAO H,LI M,LU B,et al. Effective tag set selection in Chinese word segmentation via conditional random field modeling [C]∥Proceedings of the 20th Pacific Asia Conference on Language Information and Computation.Wuhan:Chinese Information Processing Socienty of China,2006:87- 94.
[6] ZHAO H. Integrating unsupervised and supervised word segmentation:the role of goodness measures [J].Information Sciences,2011,181(1):163- 183.
[7] COLLOBERT R,WESTON J. A unified architecture for natural language processing:deep neural networks with multitask learning [C]∥Proceedings of the 25th International Conference on Machine Learning.Helsinki:International Machine Learning Society (IMLS),2008:160- 167.
[8] ZHENG X,CHEN H,XU T. Deep learning for Chinese word segmentation and POS tagging [C]∥Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.Seattle:Association for Computational Linguistics,2013:647- 657.
[9] CHEN X,QIU X,ZHU C,et al.Gated recursive neural network for Chinese word segmentation [C]∥Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Confe-rence on Natural Language Processing.Beijing:Association for Computational Linguistics,2015:567- 572.
[10] COLLOBERT R,WESTON J,BOTTOU L,et al. Natural language processing (almost) from scratch [J]∥Journal of Machine Learning Research,2011,12(1):2493-2537.
[11] SANTOS C N,XIANG B,ZHOU B.Classifying relations by ranking with convolutional neural networks [C]∥Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.Beijing:Association for Computational Linguistics,2015:626- 634.
[12] SCHUSTER M,PALIWAL K.Bidirectional recurrent neural networks [J].IEEE Transactions on Signal Processing,1997,45(11):2673- 2681.
[13] HOCHREITER S,SCHMIDHUBER J.Long short-term memory [J].Neural Computation,1997,9(8):1735- 1780.
[14] LIU P,QIU X,CHEN X,et al.Multi-timescale long short-term memory neural network for modelling sentences and documents [C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon:Association for Computational Linguistics,2015:2326- 2335.
[15] SUTSKEVER I,VINVALS O,LE Q V.Sequence to sequence learning with neural networks [J].Advances in Neural Information Processing Systems,2014,4:3104-3112.
[16] SUNDERMEYER M,SCHLÜTER R,NEY H.LSTM neural networks for language modeling [C]∥Proceedings of 13th Annual Conference of the international Speech Communication Association.Portland:Interspeech,2012:194- 197.
[17] MA X,HOVY E. End- to- end sequence labeling via bi- directional lstm- cnns- crf [J].arXiv preprint arXiv∶1603.01354,2016.
[18] 商俊蓓. 基于双向长短时记忆递归神经网络的联机手写数字公式字符识别 [D].广州:华南理工大学,2015.
[19] WANG C,YANG H,BARTZ C,et al.Image captioning with deep bidirectional lstms [C]∥Proceedings of the 2016 ACM on Multimedia Conference.Amsterdam:Association for Computating Machinery,2016:988- 997.
[20] SRIVASTAVA N,HINTON G,KRIZHEVSKY A,et al.Dropout:a simple way to prevent neural networks from overfitting [J].The Journal of Machine Learning Research,2014,15(1):1929- 1958.
[21] MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vector space [J].arXiv preprint arXiv:1301.3781,2013.
[22] ZHAO H,HUANG C,LI M,et al. An improved Chinese word segmentation system with conditional random field [C]∥Proceedings of the Fifth Sighan Workshop on Chinese Language Processing.Tianjin:Association for Computational Linguistics,2006:599- 605.
[23] ZHANG Y,CLARK S.Chinese segmentation with a word- based perceptron algorithm[C]∥Proceedings of the Meeting of the Association for Computational Linguistics.Prague:Association for Computational Linguistics,2007:840- 847.
[24] SUN W,XU J.Enhancing Chinese word segmentation using unlabeled data [C]∥Proceedings of Conference on Empirical Methods in Natural Language Processing.Edinburgh:A Meeting of Sigdat,A Special Interest Group of the ACL,2011:970- 979.
Chinese Word Segmentation Method on the Basis of Bidirectional Long-Short Term Memory Model
ZHANGHong-gangLIHuan
(School of Information and Communication Engineering, Beijing University of Posts and Telecommunications,Beijing 100876, China)
Chinese word segmentation is one of the fundamental technologies of Chinese natural language processing.At present,most conventional Chinese word segmentation methods rely on feature engineering,which requires intensive labor to verify the effectiveness. With the rapid development of deep learning, it becomes realistic to learn features automatically by using neural network.In this paper, on the basis of bidirectional long short-term memory (BLSTM) model,a novel Chinese word segmentation method is proposed.In this method,Chinese cha-racters are represented into embedding vectors from a large-scale corpus,and then the vectors are applied to BLSTM model for segmentation. It is found from the experiments without feature engineering that the proposed method is of high performance in Chinese word segmentation on simplified Chinese datasets(PKU, MSRA and CTB) and traditional Chinese dataset(HKCityU).
deep leaning;neural network;long-short term memory;Chinese word segmentation
2016- 12- 08
国家自然科学基金青年基金资助项目(61601042) Foundation item: Supported by the National Natural Science Foundation of China for Young Scientists(61601042)
张洪刚(1974-),男,副教授,主要从事模式识别研究.E-mail:zhhg@bupt.edu.cn
1000- 565X(2017)03- 0061- 07
TP 391
10.3969/j.issn.1000-565X.2017.03.009
