企业财务危机预警集成预测模型比较分析研究
2016-11-24赵越
赵越

摘要:本文采用Bagging和Adaboost作为集成模型,并采用神经网络(NN)、支持向量机(SVM)和决策树(DT)作为集成的基分类器。实验结果表明,以决策树作为基分类器的Ababoost模型具有最好的预测效果,该模型对我国上市公司财务的预警是有效的,并且具有较好的财务危机预警效果。
关键字:企业财务危机预警;集成模型;Bagging;Adaboost
1 引言
建立有效的财务危机预警模型是金融机构一项非常重要而艰巨的任务。财务危机预警模型可以用来预测上市公司的财务是否发生问题。如果预测模型不能正常运行,如预测错误率很高,它会导致不正确的决策,并很可能会由此导致严重的金融危机和灾难。
财务危机预警模型也可以表示为一类具有输入和输出的二分类问题。也就是说,预测模型将每个样本分类到2个预定义的类。对于财务危机预警问题,输出结果即为发生财务危机或者未发生财务危机。单变量分析方法最早应用于企业财务危机预警领域,Beaver(1966)[1]等是较早采用单变量分析法预测企业状况的学者,并在研究中发现对企业财务状况判别能力高的财务指标和关键要素。Ohlson(1980)[2]发现Logistic模型更适合描述企业发生财务危机与否和财务比率指标之间的非线性关系。自上世纪50年代人工智能技术,如决策树、支持向量机、神经网络、概率神经网络等分类器成为预测企业财务危机较常用的方法。Odom(1990)[3]最先运用神经网络模型对企业财务状况进行预测。
已有研究表明,分类器集成技术在预测精度和误差等方面都要优于单一分类器模型和传统的统计方法。集成分类器是针对同一问题通过组合一组分类器进行解决的,最终的分类结果根据每个分类器的组合从而最终得到。常用的集成方法包括Bagging和Adaboost。West(2005)[4]研究了用于对神经网络进行集成的cross-validation,bagging,boosting三类集成策略,并证明多分类器集成方法的预测能力优于单一模型。Alfaro(2008)[5]对比了使用AdaBoost集成方法和神经网络模型的预测企业破产的精度,结果显示AdaBoost集成方法有效降低了神经网络的泛化错误。
虽然许多相关的研究已经证明了集成分类器优于许多单分类器,但是在企业财务危机预警领域,关于集成模型的应用还缺少全面的对比及分析。所以本文选取了Bagging和Adaboost集成模型,同时选取了神经网络(NN)、支持向量机(SVM)和决策树(DT)作为集成的基分类器,重点讨论如何构建财务危机预警的最优集成分类器模型。
2 集成模型
集成学习方法是机器学习的新兴领域。近些年来,采用集成模型对企业财务危机进行预警的研究也呈上升趋势。集成模型的目的在于将多个具有一般性能的弱分类器整合成为具有较强分类性能的集成模型。也就是说,用于集成的基分类器能够有效弥补其它基分类器所产生的不足,从而获得比单分类器更好的预测效果,显著的提高预测模型的泛化能力。
将不同的基分类器的预测结果进行组合得到最终的预测结果,这些用于组合的基分类器可以通过不同的训练数据集产生,也可以通过不同的分类算法产生:
2.1 Bagging
Bagging首先通过自助抽样法,从初始训练数据集中有放回的对样本进行抽样,形成不同的训练数据集。进而采用某一分类算法分别用各个训练数据集对基分类器模型进行训练,从而形成不同的基分类器模型。最后采用多数投票法融合各个基分类器的预测结果。已有研究表明,Bagging采用的自助抽样法和多数投票法能够有效降低模型的方差从而提高预测的精度。
2.2 Adaboost
在Adaboost中,各个分类器是连续生成的。即Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的基分类器,然后把这些基分类器通过多数加权投票的方法进行整合形成一个最终的强分类器。Adaboost的算法如下:
假设有训练样本集 ,代表一个二分类问题中训练样本的对应输出。当经过第t次迭代时,每个训练样本的权重表示为 。每个训练样本的初始权重为1/n,样本的权重随着迭代的增加而不断的更新。在t次迭代时,Adaboost根据权重分布生成新的训练样本集,并使用新的训练样本生成基分类器,通过ft表示。Et代表分类器ft的错误率,可以通过式(1)进行计算:
(1)
根据容易分类的样本分配较小权重,较难分类的样本分配较大权重的基本思想,样本的权重通过式(2)进行更新:
(2)
式(2)中的αt和lit分别通过式(3),(4)计算得到:
(3)
(4)
将以上得到的权重进行标准化处理,可以得到 (5)。
当进行T次迭代时,将有T个弱分类器用于集成。Adaboost通过加权投票集成法得到最终的分类结果。
3 实证研究
3.1 样本描述
本文采用的上市公司的财务数据样本均通过CCER经济金融数据库获取。采用沪深两市中的上市公司因为连续两年以上财务状况异常而被“特别处理(Special Treatment,ST)”作为分类器的分类标准。基于此,本文选取2009-2014年首次被证监会“特别处理”的上市公司,共计167家上市公司作为发生财务危机的公司样本。并根据同行业和相似总资产选取准则,选取了167家财务健康的上市公司作为配对样本进行实验。基于既有的的指标选取原则,本文分别从市场价值、营运能力、资本结构、偿债能力、盈利能力和成长能力6个方面选取了38个财务指标作为构建财务预警模型的输入。具体包含的指标内容如表1所示:
3.2 实验设计
本文选取了神经网络(NN),支持向量机(SVM)和决策树(DT)三个常用的预测模型作为集成的基分类器。使用神经网络作为基分类器,主要需要确定网络层神经元的数量,本文采用经验法对其进行设置,即网络层的神经元数量一般设置为 ,其中m是输入层神经元的个数,即输入财务指标集的数量,n是输出层的神经元个数,即是否发生财务危机,a是一个0-10之间的常数。采用支持向量机作为集成的基分类器时,采用径向基函数(RBF)作为其核函数,并利用交叉验证法寻找最优的惩罚系数C和核参数σ。
为了避免训练样本因为一次抽样而使得模型的测试产生有偏的结果,采用10-折交叉验证作为模型的验证方法。即将样本数据随机划分为互斥的10组,用其中9组作为训练样本,剩余1组作为测试样本,重复这一过程,直至每组都做过一次测试样本,并计算最终正确分类的样本数量占总样本数量的值来评估分类器的性能。
3.3 评价标准
本文分别采用整体预测准确率(Accuracy)、第一类错误率(type I error)和第二类错误率(type II error)作为评判模型优劣的评价标准。融合矩阵及各个评价标准的定义如下所示:
3.4 实验结果与分析
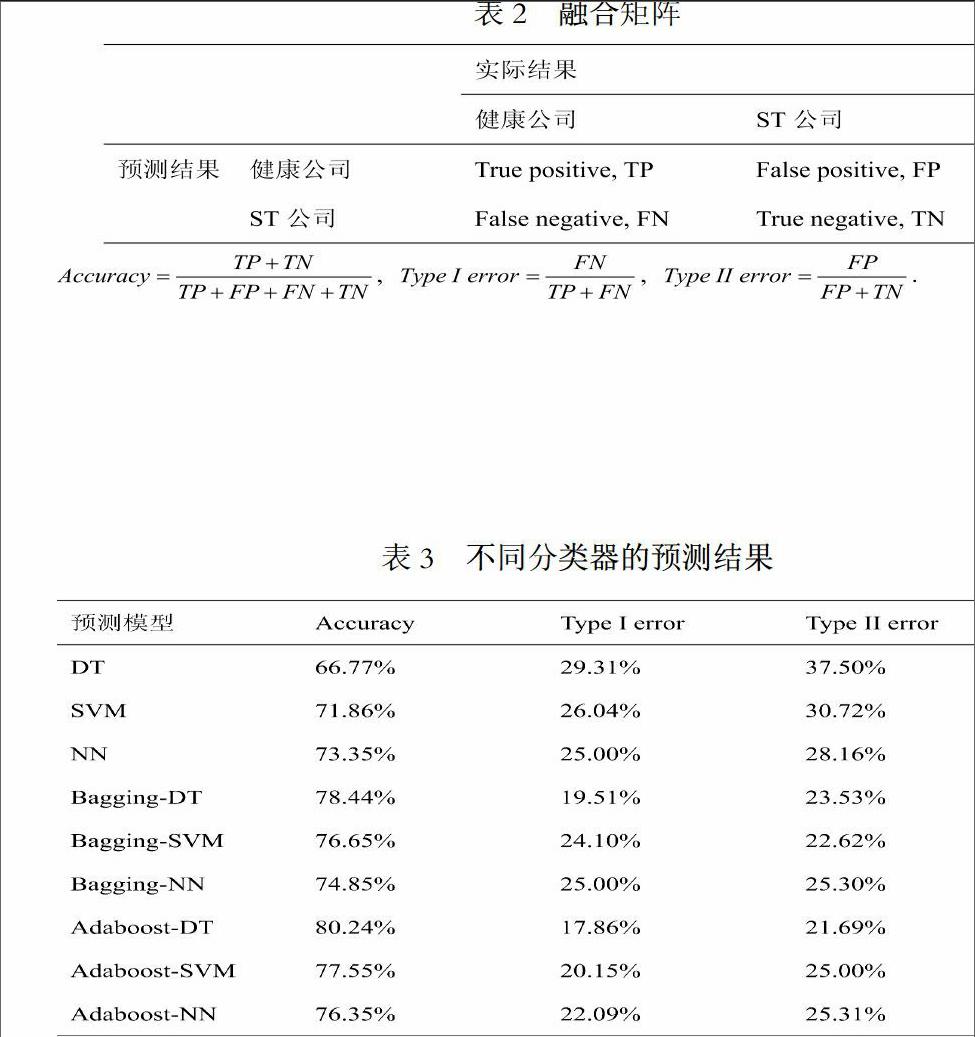
为了分析以下两个问题,一是在企业财务危机预警中Bagging和Adaboost两类集成模型预测能力的差异,二是NN,DT和SVM分别与Bagging和Adaboost集成后预测能力的差异。本实验共进行了9组实验,来较全面的分析以上两个问题。具体实验结果见表3:
从表3可以看出,当使用Adaboost作为集成框架,DT作为集成的基分类器时,构建的模型具有最好的预测性能,准确率达到了80.24%,第一类错误率为17.86%,第二类错误率为21.69%。而采用Adaboost-SVM和Adaboost-NN的预测结果分类别77.55%和76.35%。同时可以看出,无论选择哪种预测算法作为集成的基分类器,Adaboost集成框架的预测效果都优于Bagging,因为Adaboost具有更好的泛化性能和降低方差的能力。
4 结论
既往研究中,关于分类器集成方法在企业财务危机预警中的作用没有被充分挖掘。所以本文对集成方法进行了较全面的研究和比较分析。本文选取了企业财务危机预警中常用了两个集成模型:Bagging和Adaboost,用于比较。同时,每个集成模型都分别与神经网络、决策树和支持向量机相结合,用于判断集成模型的性能。实验表明,Adaboost-DT具有最优的预测能力。此外,相比于其它集成模型,Adaboost-DT具有更好的效率。所以,在未来关于企业财务危机预警的实践应用中,该模型为管理者和投资者提供了一个较好的决策工具。
参考文献:
[1] Altman E.I. Financial Ratios, Discriminant Analysis, and the Prediction of Corporate Bankruptcy. Journal of Finance, 1968:589~609.
[2] Ohlson. James A. Financial Ratios and the Probabilistic Prediction of Bankruptcy.Journal of Accounting Research. 1980,(18): 109~131.
