基于主成分初始化与双字典学习的图像分类方法
2017-06-12张玉兰张家林余义斌
张玉兰,张家林,余义斌
(五邑大学 信息工程学院,广东 江门 529020)
基于主成分初始化与双字典学习的图像分类方法
张玉兰,张家林,余义斌
(五邑大学 信息工程学院,广东 江门 529020)
为解决字典学习训练测试消耗时间过长、迭代次数多、识别率及计算效率不高的问题,本文提出一种基于主成分初始化的双字典学习方法,将PCA方法引入双字典学习模型,通过对每类样本矩阵奇异值分解,保留样本95%的主成分作为双字典学习的初始子字典,以此充分利用已有样本的全局信息,并减少字典学习的迭代次数.在扩展的YaleB、AR数据库和手写数字字符集MNIST库上的分类实验表明,相对其他分类方法,本文方法大大减少了训练和测试时间,并提高了识别率.
主成分初始化;双字典学习;解析字典;合成字典;图像分类
字典学习(dictionary learning,DL)目前已经广泛应用于图像处理、机器视觉和模式识别等领域,但它对有复杂局部结构的自然图像处理效果不好,所以通常采用结构化的合成字典[1-2]对图像的复杂局部结构建模.目前,有鉴别能力的字典学习方法主要有基于稀疏表示的鲁棒人脸识别的鉴别字典学习[1]、标签连续的KSVD (LC-KSVD)的鉴别字典学习[3]、有监督的鉴别字典学习[4]以及基于结构的非连贯性和共同特征的鉴别字典学习[2]等.由于稀疏编码对分类更有效,因此众多的字典学习方法采用l0范数或l1范数来对稀疏问题进行正则化,并针对所有类别,学习一个通用字典,自发地在稀疏编码系数中得到分类器,提高分类准确率.虽然有学者提出了提高效率的方法[5-6],但l0或l1范数正则化过程仍然面临多次迭代、效率较低的问题.文献[7]提出投影双字典学习(dictionary pair learning,DPL)方法,通过线性映射得到稀疏表示系数,同时学习一个解析字典和合成字典:利用解析字典对样本稀疏表示,用合成字典对样本进行重构,从而达到分类目的.此方法的稀疏表示系数由简单的线性投影函数逼近获得,且应用了类标签信息,提高了稀疏编码的识别能力,减少了训练和测试时间.但该方法把解析字典P和合成字典D都初始化为单位Frobenius范数随机矩阵,没有利用样本的任何信息,字典学习的过程仍需要多次迭代,仍存在改进的空间.
主成分分析(principle component analysis,PCA)[8]是模式识别中一种重要的特征提取方法,其基本思想是从样本图像中提取主要成分,保留原始数据大部分信息,减少数据冗余,降低高维数据的维数,进而提高计算效率,解决高维数据处理的瓶颈问题.目前PCA在模式识别中的应用有二维主成分分析[9]和基于Gabor小波表示的核主成分分析[10]等.本文将PCA方法引入到双字典学习模型中,提出基于主成分初始化的双字典学习方法.通过对每类样本矩阵奇异值分解(singular value decomposition,SVD),保留样本95%的主成分作为双字典学习的初始子字典,以提高字典学习的效率和识别率.
1 基于主成分初始化的双字典学习
1.1 DPL模型



因此,A=PX是块对角矩阵.另外,用结构化的合成字典D的子字典Dk从稀疏编码A中重构出X时,使用的代价函数为

综合以上分析可得DPL模型:

1.2 字典对的初始化
PCA一般由Karhunen-Loeve变换实现[12],实质是建立一个新的坐标系,将样本数据的主轴沿着特征矢量对齐,去除原来数据向量各分量之间的相关性而保留主要信息分量,以达到降维目的.实际中可通过奇异值分解(SVD)来获得样本的主成分.
本文采用PCA对字典对D和P初始化,初始化合成字典D为样本矩阵奇异值分解(SVD)的前m个特征值对应的归一化特征向量(m为字典的原子个数),初始化解析字典P为D的转置.对同一类(第k类)样本图像矩阵做SVD分解,有:

由于图像发生旋转、位移变换、镜像变换时,其奇异值不会发生变化,因此用SVD能更精确提取图像主成分.较大奇异值对应的特征向量代表了某一类图像的主成分,不同的类对应的主成分是不同的.一般,保留所有特征值之和95%对应的特征向量就能保持样本数据的主要特征,剩余的较小的特征值对样本数据特征的贡献很小,m是保留样本数据95%主要特征需要的特征值的个数.这样大大提高了字典训练的效率,又能更精确描述样本空间的主要特征,且能使算法收敛更快.
1.3 优化求解
目标函数式(5)是一个非凸函数,引进矩阵A=PX,式(5)可转化为
最小化求解可以在以下两步中交替进行:
1)固定D和P,更新A

这是一个标准最小二乘问题,对A求导,并令其等于0,可得解析解:
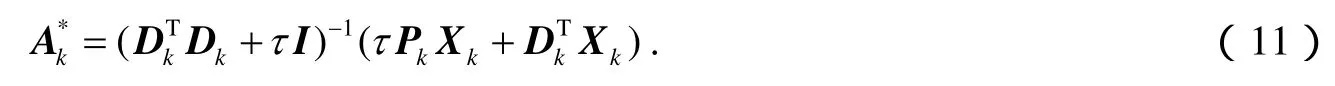
2)固定A,更新D和P

P的解析解为
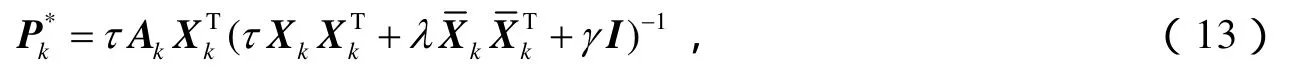

利用ADMM算法求解式(14),可得

字典对D和P是分类算法的输出.从式(12)可以发现,第一个子目标函数用于学习鉴别解析字典,提升字典P的鉴别能力;第二个子目标函数用于学习合成字典,使解析字典产生的稀疏系数对原输入信号的重构误差最小.当最优化收敛时,鉴别和表示能力达到平衡.基于主成分初始化的双字典学习算法归纳如下:
5)输出字典对D和P.
2 图像分类方法


图1 扩展的YaleB数据库上,文献[7]和本文的重构编码和重构误差对比图

3 实验结果与分析
在2.0 GHz Intel CPU和8 G内存的笔记本电脑上,分别将基于线性最近邻子空间分类器(NSC)、稀疏表示分类(SRC)[2]、线性支持向量机(SVM)分类、标签连续的KSVD(LC-KSVD)[4]、投影双字典学习(DPL)[1]以及本文方法在扩展的YaleB[13]、AR[14]两个人脸数据库和手写字符集MNIST库上进行实验,比较其识别率及训练测试时间.
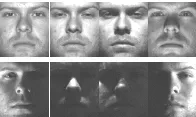
图2 扩展YaleB数据库样本图像

图3 AR数据库样本图像

图4 MNIST数据库样本图像
扩展的YaleB人脸数据库取自38个人的2 414张图片,主要受光照和人脸表情的影响.AR数据库包含了取自70个男性和50个女性共120人的1 680张图片,主要受光照、表情的影响.图2和图3分别是扩展的YaleB和AR数据库的部分样本图像,图4是手写数字字符集MNIST库的部分样本图像.对于扩展的YaleB数据库,随机选每个人的一半图片用于训练,另一半用于测试,样本特征维数为504.对于AR数据库,随机选每个人的10张图片用于训练,剩下的4张用于测试,样本特征维数为540.在实验中,取0.05,对于扩展的YaleB数据库,m取14,取0.003;AR数据库,m取8,取0.005,实验结果如表1所示.对于MNIST数据库,选取60 000张样本训练,10 000张样本用于测试,取0.1,m取150,取0.003,实验结果如表2所示.

表1 不同方法在扩展YaleB数据库和AR数据库上的识别结果

表2 在手写数字字符集MNIST库上的识别结果
由表1知:与其他五种方法相比,本文提出的基于主成分初始化的双字典学习方法在两个人脸数据库上的识别率均为最高,且训练时间也远远低于LC-KSVD和DPL,在识别率和计算效率上都有一定的改善.由表2可知,在手写数字字符集MNIST库上,本文方法优于传统的双字典学习方法.
4 结论
基于主成分初始化的双字典学习选用样本信号95%的主成分作为初始字典,能有效捕捉样本空间的本质特征.在利用样本全局信息的基础上,同时学习一个字典对(解析字典用于样本编码,合成字典用于重构样本),引入类标签信息,提高图像分类的准确性.实验证明,在扩展的YaleB、AR数据库和MNIST数据库上,相对其他图像分类方法,本文提出的方法大大减少了训练和测试时间,并提高了识别率.本文提出的算法也可应用于其他模式识别、机器学习、图像分类等问题的求解.
[1] WRIGHT J, YANG A Y, GANESH A, et al.Robust face recognition via sparse representation [J].IEEE transactions on pattern analysis and machine intelligence, 2009, 31(2): 210-227.
[2] RAMIREZ I, SPRECHMANN P, SAPIRO G.Classification and clustering via dictionary learning with structured incoherence and shared features [C]//2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).San Francisco: IEEE, 2010: 3501-3508.
[3] JIANG Zhuomin, LIN Zhe, DAVIS L S.Label consistent K-SVD: learning a discriminative dictionary for recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2651-2664.
[4] MAIRAL J, PONCE J, SAPIRO G, et al.Supervised dictionary learning [C]//Advances in neural information processing systems.Whistler: NIPS, 2009: 1033-1040.
[5] LEE H, BATTLE A, RAINA R, et al.Efficient sparse coding algorithms [C]//Advances in neural information processing systems.Whistler: NIPS, 2006: 801-808.
[6] HALE E T, YIN Wotao, ZHANG Yin.Fixed-point continuation for l1-minimization: methodology and convergence [J].SIAM Journal on Optimization, 2008, 19(3): 1107-1130.
[7] GU Shuhang, ZHANG Lei, ZUO Wangmeng, et al.Projective dictionary pair learning for pattern classification [C]//Advances in Neural Information Processing Systems.Montréal: NIPS, 2014: 793-801.
[8] ABDI H, WILLIAMS L J.Principal component analysis [J].Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(4): 433-459.
[9] YANG Jian, ZHANG D, FRANGI A F, et al.Two-dimensional PCA: a new approach to appearance-based face representation and recognition [J].IEEE transactions on pattern analysis and machine intelligence, 2004, 26(1): 131-137.
[10] LIU Chengjun.Gabor-based kernel PCA with fractional power polynomial models for face recognition [J].IEEE transactions on pattern analysis and machine intelligence, 2004, 26(5): 572-581.
[11] SOLTANOLKOTABI M, ELHAMIFAR E, CANDES E J.Robust subspace clustering [J].The Annals of Statistics, 2014, 42(2): 669-699.
[12] 苏宏涛.基于统计特征的人脸识别技术研究[D].西安:西北工业大学,2004.
[13] GEORGHIADES A S, BELHUMEUR P N, KRIEGMAN D J.From few to many: illumination cone models for face recognition under variable lighting and pose [J].IEEE transactions on pattern analysis and machine intelligence, 2001, 23(6): 643-660.
[14] MARTINEZ A M, BENAVENTE R.The AR face database [R].Barcelona: CVC, 1998: 1-8.
[责任编辑:熊玉涛]
A Method of Image Classification Based on Principal Component Initialization and Dictionary Pair Learning
ZHANG Yu-lan, ZHANG Jia-lin, YU Yi-bin
(School of Information Engineering, Wuyi University, Jiangmen 529020, China)
To solve the problem of consuming too much time, too many iterations, and low accuracy of recognition and low efficiency of computing in the training and testing process, a method of principal component initialization is introduced into the dictionary pair learning (DPL) model in this paper.Through the singular value decomposition of each class of samples, the principal components analysis (PCA) is introduced into the DPL model, which retains 95 percent of the principal components as the initial sub-dictionary.This can take full advantage of the global information of the samples and reduce the iteration numbers in computing.Classification experiments on the Extended YaleB Database, AR Database and hand-written digital character set MNIST Database show that our method can greatly reduce the training and testing time and achieve higher accuracy compared with other classification methods.
principal component initialization; dictionary pair learning; analysis dictionary; synthesis dictionary; image classification
TP391.4
A
1006-7302(2017)02-0027-06
2016-12-12
广东高校省级重点平台和重大科研项目特色创新项目(自然科学类)(2015KTSCX148);浙江省信号处理重点实验室开放课题(ZJKL_4_SP-OP2014-05);广东省大学生创新和创业培训项目(201511349090).
张玉兰(1990—),女,河南商城人,在读硕士生,主要研究方向为图像处理、字典学习、稀疏表示和模式识别;余义斌,副教授,博士,硕士生导师,通信作者,主要研究方向为机器视觉与图像处理.
