针对舆情数据的去重算法①
2017-06-07张庆梅
张庆梅
(中国科学技术大学 软件学院,苏州 215123)
针对舆情数据的去重算法①
张庆梅
(中国科学技术大学 软件学院,苏州 215123)
针对在数据服务中舆情去重不可避免且缺乏理论指导的问题,通过研究SimHash、MinHash、Jaccard、Cosine Similarty经典去重算法,以及常见的分词和特征选择算法,以寻求表现优异的算法搭配,并对传统Jaccard和SimHash进行了改进分别产生新算法:基于短文章的Jaccard和基于Cosine Distance的SimHash.针对比较对象众多实验效率低下的问题,提出了先纵向比较筛选出优势算法,然后横向比较获得最佳搭配,最后综合比较的策略,并结合3000舆情样本实验证明:改进的SimHash比传统的SimHash具有更高的精度和召回率;改进的Jaccard较传统Jaccard,召回率提高了17%,效率提高了50%;MinHash+结巴全模式分词和Jaccard+IKAnalyzer智能分词在保持精度高于96%的条件下,都具有75%以上的高召回率,且稳定性很好.其中MinHash去重效果略低于Jaccard,但特征比较时间较短,综合表现最好.
舆情数据;去重算法;相似度计算;大数据服务
据中国互联网络信息中心统计,截止到2015年12月,我国社交网站、微博等社交应用的网民使用率达77.0%[1],新媒体逐渐成为网民表达意见和看法、行使公民权利的重要渠道和方式[2],是用户获取和分享“新闻热点”、“兴趣内容”、“专业知识”、“舆论导向”的重要平台[3].从社会学角度来看,这些舆情信息反映了民众的社会政治态度,有着强大的监督力度[4].而舆情信息的价值远远不止其传播性所带来的社会监督力度,在金融领域也广泛被使用.由于舆情信息可以准确反映个人和企业的信用状况,目前已有大数据服务公司采集舆情数据,然后加工分析为金融机构在信用评定、风险评估方面提高参考.然而随着大数据时代的到来,抓取的舆情数据重复性冗余急剧增大[5],这些重复的数据严重影响后期的加工处理和客户体验.据调研,目前的去重技术大多针对网页,专门针对舆情数据的却很少.因此对于舆情数据服务,迫切需要针对舆情开展去重研究来解决数据重复带来的一系列问题.本文通过对几种经典去重算法在舆情数据方面的表现进行研究,并分析不同实现方式的去重算法之间的精度、召回率和效率的差异,寻求在舆情去重上表现优异的算法,为舆情数据服务在机器去重方面提供参考.
1 相关技术和实现方法
本文将整个去重分为三个步骤:首先是分词,将一篇文章转化为词语列表;然后是对文章进行特征选择,实现文章特征属性的提取;最后是基于相似度计算的去重算法进行去重.因此关键技术包括分词、特征选择、相似度计算.每种技术中本文都有多种候选算法,相关技术的研究对象如表1所示.

表1 相关技术的研究对象
1.1 分词
本文的分词具体指中文分词,目的是将汉字序列切分成由词语组成的序列[6].分词算法的不同将直接影响去重效果.本文尝试通过比较不同分词算法对舆情去重效果的影响,来获得最适合舆情去重的分词方法.本文选用中文分词中比较常用的3种分词方法:结巴分词、IKAnalyzer分词和HanLP分词,其中结巴分词包含3种模式:精确模式、全模式和搜索引擎模式.IKAnalyzer包含2种分词模式:细粒度模式和智能模式.HanLP包含8个分词器:标准分词、NLP分词、索引分词、N最短路径分词、最短路径分词、CRF分词、极速词典分词和繁体分词.由于本文的舆情样本全部是简体中文,因此本文只将前7种分词纳入此后的研究中去.
1.2 特征选择
选用较小维度的特征代表整个文本正文的过程就是特征选择.在本文中将几种常见的特征选择纳入研究范围,分别是:词频、TF-IDF和TextRank.这三种特征选择都是权重特征,适合与Cosine Similarity和SimHash算法结合使用.
1.2.1 词频
词频是指词语出现的次数,词频统计通常不单独被使用,一般是结合其他算法一起使用,应用范围涉及中文分词、研究热点分析、文本分析等诸多方面[7-9].常用词频的计算方式是获取某个词在文章中出现的次数,但这种计算方式忽略了文章有长短之分.当文章篇幅差距很大,将不能准确体现文章内容之间的差异性.因此在本文采用的是相对词频,它对的计算公式如式(1)所示.
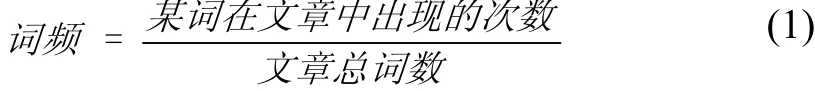
1.2.2 TF-IDF
TF-IDF和词频同样都是常用的加权技术,但相比于词频,TF-IDF能够反映整个词在一个文本集合或者语料库中的“重要程度”,词频仅仅在一定程度上反映一个词在一篇文章的重要程度,没有将整个文本库的大小考虑进去.TF-IDF广泛应用于自动关键词提取、文本摘要提取等[10,11].TF-IDF的主要思想是词语的重要性随着这个词在文本出现的次数成正比,同时随着它在整个文本集合中出现的频率成反比,某个词在文章中的重要程度越大,TF-IDF的值就越大.了解TF-IDF首先了解逆文档频率,词频和逆文档频率的乘积就是TF-IDF,逆文档频率(IDF)的计算公式如式(2)所示.
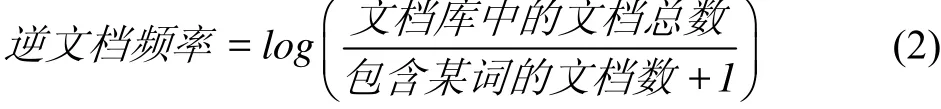
1.2.3 TextRank
TextRank是受启发于PageRank,PageRank最开始是用于网页相关性和重要性的评估,获取网页排序,提高用户对搜索引擎检索结果的满意度,此算法由Google的创始人谢尔盖•布林和拉里•佩奇在1998年提出[12].PageRank的计算公式如式(3)所示.
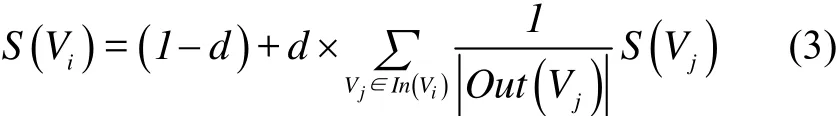
S(Vi)表示网页i的重要性,d是阻尼系数,通常设为0.85.In(Vi)是指向网页i的链接集合,Out(Vi)表示网页i指向的网页集合,|Out(Vi)|表示网页i指向的网页集合的元素个数.整个计算需要经过多次迭代,初始设置网页重要性为1.
TextRank计算对象从网页转化为文本中的词语或者句子,每个词语或句子根据此算法会得到相应的权重.具体计算公式如式(4)所示.
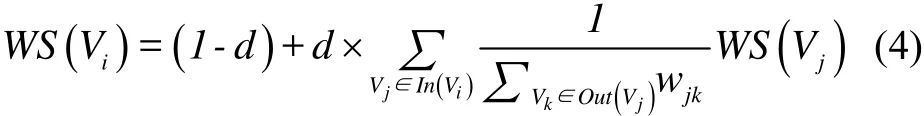
本文利用此特征选择主要是获取不同词语的权重值,即把每个词语看成一个节点(Vi).当计算对象是词语时,因为 wjk取值都为 1,TextRank就蜕变成PageRank.不过式4中的变量含义有所变化,S(Vi)表示文本中词语i的重要性,In(Vi)是文章中指向词语i的词语集合,|Out(Vi)|表示文章中词语i指向的词语集合的元素个数.词语之间的相邻关系,依赖于窗口大小的设置,一个窗口中的任意两个词语之间都是相邻的,并且边都是无向无权的.由于TextRank需要经过多次迭代,因此特征获取的时间复杂度很高.
1.3 相似度计算
相似度计算是指是在特征选择的基础上通过去重算法来求取文章之间相似度的过程,是自然语言处理和数据挖掘中常用的操作.本文参考网页去重的经典算法,将 Jaccard、Cosine Similarity、SimHash和MinHash纳入研究范围,对于传统实现方式, MinHash有两种:基于单Hash函数的MinHash算法和基于多Hash函数的MinHash算法,其余的各有一种.本文除了实现传统的算法之外,还对传统Jaccard和SimHash进行改进分别产生新的算法:基于短文章的Jaccard和基于Cosine Distance的SimHash.
2 基于相似度计算的去重算法
对于不同的应用场景,考虑到数据规模、时间开销,去重算法的选择会有所不同.本文在此分析不同算法的去重原理以及时间开销,从理论上分析不同算法的优缺点,并给出具体的实现步骤.为不同需求的应用场景在去重算法的选择上提供参考.
2.1 Jaccard算法
Jaccard系数,又称Jaccard相似度系数,用来评估两个集合之间的相似度和分散度[13],Jaccard系数越大表明两篇文章的相似度越大.利用Jaccard去重,首先将文章通过分词转化为由词语构成的特征集合,通过检查两个集合的Jaccard系数是否超过指定的阈值来判断文章是否重复.
1)传统的Jaccard
传统的Jaccard,基于Merge算法,通过求取两个文章的特征集合交集和并集的长度比例来衡量文章之间的距离.计算公式如式(5)所示.
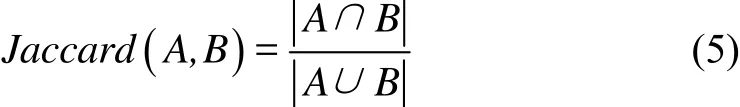
从实现的原理上看,传统的Jaccard算法,并没有将两篇文章的长度差异考虑进去,假设两篇文章重复的文章长度差异很大,例如一个包含1500个单词,一个包含500个单词,两篇文章的单词交集长度是500,利用传统的Jaccard计算两篇文章距离,结果是:0.25,传统 Jaccard的阈值一般在0.5以上,在这种情况下,就很容易漏判长度差异大的重复文章.此外Merge算法的时间复杂度是O(m+n)(m和n是两个集合的长度),不是很高,但当文章篇幅很长,数据规模很大时,这个时间开销将会非常庞大.因此Jaccard算法不适应文章篇幅普遍较长、数据规模较大的业务场景.
2)基于短文章的Jaccard
针对传统Jaccard对属于包含关系重复的文章识别能力低的问题,本文提出一种基于短文章的Jaccard,通过求取两个特征集合交集占短文章集合长度的比例来衡量两文章的距离.以下简称改进的Jaccard,计算公式如式(6)所示.
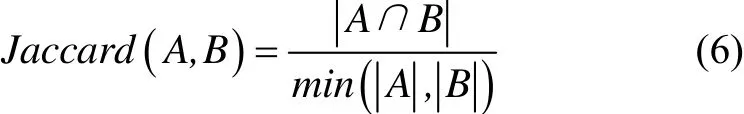
在这种改进下,属于包含关系的重复文章,即使文章长度差异很大,求取的文章Jaccard系数也会随文章相似程度的增大而增大.对于传统Jaccard中的例子,使用改进的Jaccard计算,两篇文章的距离就是1,即完全重复,符合实际情况.改进的Jaccard的时间复杂度和传统Jaccard相同,但是相比传统的Jaccard少了求并集的过程,因此时间消耗要少.
2.2 Cosine Similarity算法
Cosine Similarity又称Cosine Distance,与几何中的向量余弦夹角很相似.当把一篇文章的特征抽象成一个向量时,可以使用这种方式计算文章之间的相似度,计算公式如式(7)所示.
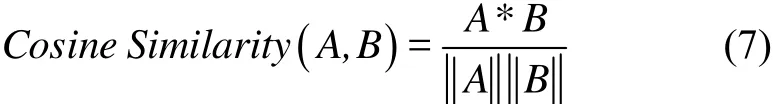
具体实现步骤如下:

对于Step 3向量坐标的转化,需要遍历集合unionS中的元素,并依次判断每个元素在待转化向量中的存在情况,因此整个相似度计算的时间复杂度平均为O(n*m)(n为并集的长度,m为待转化向量的长度),相比于Jaccard,时间开销更大.
2.3 SimHash算法
SimHash是由Charikar在2002年提出的去重算法,主要用于海量文本的去重工作[14].SimHash对文章进行相似度计算,需要两步,首先特征提取形成指纹,然后根据指纹进行特征比较,计算相似度.
1)传统的SimHash
传统的SimHash首先将一篇文章转化为由k位0/1构成的指纹(k通常取32或64),然后利用Hamming Distance(海明距离)来对两篇文章的指纹进行相似计算.海明距离是指两串二进制编码对应比特位取值不同的比特数目,海明距离越大则相似度越小.由于SimHash能将一篇文章转化为k位的字符,相比于Jaccard和Cosine Similarity,能大大降低特征比较的维度.虽然多了特征提取的步骤,但对于大数据服务,一篇文章只需在入库时进行一次特征提取,然后将形成的指纹保存下来,而特征比较会在每次去重时都要基于指纹进行多次.因此对于大规模的数据去重, SimHash具有绝对优势的去重效率.传统的SimHash的具体实现步骤如下:


(2)基于Cosine Distance的SimHash
在对Cosine Distance和传统SimHash研究的基础上,本文提出基于Cosine Distance的SimHash,以下简称SimHashCosine.该SimHash特征提取只保留传统SimHash实现步骤的Step1.1-1.4,然后利用Cosine Distance来计算指纹之间的相似度,最后通过判断是否超过给定的阈值来判定是否重复.两种SimHash的时间开销差异主要体现在是特征比较上,若n为指纹码的长度,m为阈值(n>m),传统的SimHash相似度计算利用Hamming Distance,时间复杂度最坏情况是O(n),最小只有O(m),而SimHashCosine,相似度计算利用Cosine Distance,时间复杂度至少O(n),且时间频度至少是传统SimHash的3倍,因此在特征比较效率上传统的SimHash更高一点.
2.4 MinHash算法
MinHash和SimHash一样,能对文章进行很好的降维,适用于大规模的网页去重工作[15].MinHash经过特征提取,将一篇文章最终转化为n个最小Hash函数值构成的特征集合,然后基于Hash函数值集合获取Jaccard距离来衡量相似度.
1)基于单Hash函数的MinHash
基于单 Hash函数的 MinHash,以下简称MinOneHash,在进行特征提取仅使用了一个Hash函数,然后使用传统的基于Merge算法的Jaccard计算相似度,具体的实现步骤如下:

2)基于多Hash函数的MinHash
基于多 Hash函数的 MinHash,以下简称MinMutilHash,使用n个Hash函数进行特征提取(n>1),特征提取的步骤:对于事先确定的n个Hash函数,对于每个Hash函数,按照约定的顺序都对文章的词语集合s中的所有词语进行Hash操作,形成各自的Hash函数值集合,然后各自从各自的Hash函数值集合中筛选出最小Hash值,n个Hash函数最终获得n个最小值.由于特征提取计算维度的扩大,相对于MinOneHash,时间复杂度较高.但MinMutilHash相似度计算法是根据Broder提出的最小独立置换概念,通过求得两个Hash函数值集合中对应位置Hash值相同的元素数目来评估相似度,特征比较的时间复杂度是 O(n),相比于MinMutilHash的O(m+n),特征比较效率要高.
3 实验测试及分析
3.1 测试方案设计
由于涉及算法众多,以排列组合的形式进行组合测试需要耗费大量时间.因此本文针对表1所列算法,先纵向比较剔除明显劣势的算法,然后横向比较获得各个去重算法最适宜的分词算法和特征选择,最后对去重表现良好的候选算法,进行进一步优化后再综合测试比较的策略.
本文以精度、召回率、计算时间来衡量算法的去重效果.精度是衡量算法准确性的指标,公式如式(8)所示.召回率是衡量算法查全程度的指标.公式如式(9)所示

考虑到大数据服务对数据准确性的要求,去重效果的衡量标准以精度优先,精度越高表示去重效果越好;其次是召回率,召回率越高去重效果越好;在精度相差不大时,优先选择召回率高的算法,相差不大的标准是正负差值不超过1%;计算时间最后考虑.计算时间中包括两部分:特征提取时间,特征比较时间.在大数据服务的舆情去重中,对一篇文章特征提取只需要进行一次,特征比较则会进行很多次,因此对于不同的去重算法,算法特征比较时间要优于特征提取时间考虑.测试样本统一使用包含3000真实舆情文章的数据集.
3.2 纵向比较
3.2.1 分词算法的比较
为了保证实验结果不受特征选择的影响,在本实验中对词语都不进行特征选择,为了保证实验结果不受去重算法的影响,在本实验中去重算法统一使用传统的SimHash.测试结果如表2所示.
表2 基于结巴分词不同模式的去重测试结果
由表2可得,精度:IKAnalyzer智能>HanLP CRF>结巴全模式分词>90.5%,召回率:IKAnalyzer智能>HanLP CRF>结巴全模式分词>55.5%,因此保留IKAnalyzer智能、HanLP CRF和结巴全模式.
3.2.2 特征选择算法的比较
本文继续使用SimHash算法,分词算法选用IKAnalyzer智能分词,以无加权为参照,观察不同特征选择下去重效果的差.实验结果如表3所示.

表3 基于不同特征选择的去重测试结果
由表3可得,无加权和TextRank去重表现最好,但是根据实验发现TextRank特征提取时间很长导致总计算时间太长,且更换其他分词算法时,结合TextRank的去重效果都有所降低,因此舆情去重在此只保留无加权.
3.2.3 去重算法比较
去重算法的比较研究部分主要任务是从Jaccard、SimHash、MinHash中各筛选出一种,然后和Cosine Similarity进行比较.测试结果如表4所示.
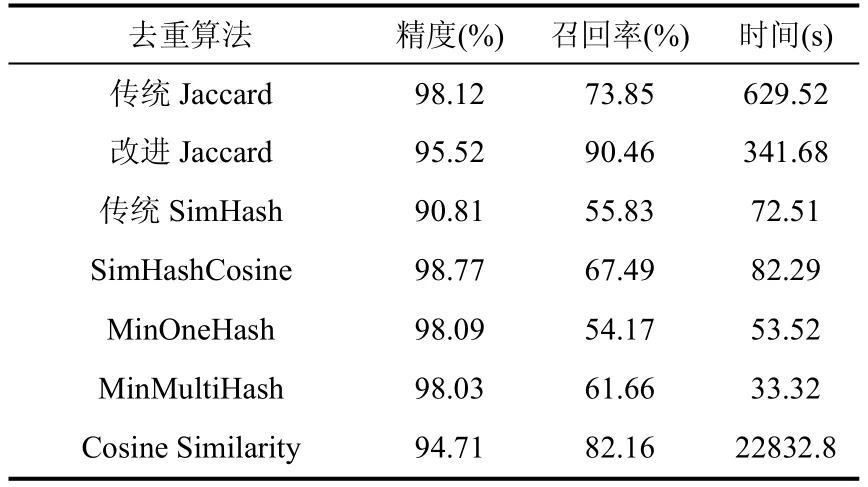
表4 不同去重算法的测试结果
由表4可知:
① 在精度和召回率上,SimHashCosine同时高于SimHashHamming,保留SimHashCosine.
②MinMultiHash精度略低于MinOneHash,但两者相差不大,且在召回率和特征比较时间上, MinMultiHash相比于MinOneHash具有绝对优势,因此保留MinMultiHash.
③Cosine Similarity时间花费太大,确定舍去.
④ 传统的Jaccard精度明显高于改进的Jaccard,但改进的Jaccard召回率和特征效率明显高于传统的Jaccard,各具明显优势,实际使用时可以根据场景需求进行选择,在面向金融行业的大数据服务中,以精度优先保留传统的Jaccard.
3.3 横向比较
在算法横向比较部分,分词算法保留IKAnalyzer智能、HanLP CRF和结巴全模式,排除使用特征选择,因此在横向比较部分主要研究保留的分词算法对去重算法的影响.便于表示在此将IKAnalyzer智能、HanLP CRF、结巴全模式分词分别简称为智能、CRF、全模式.横向比较结果如表5所示.
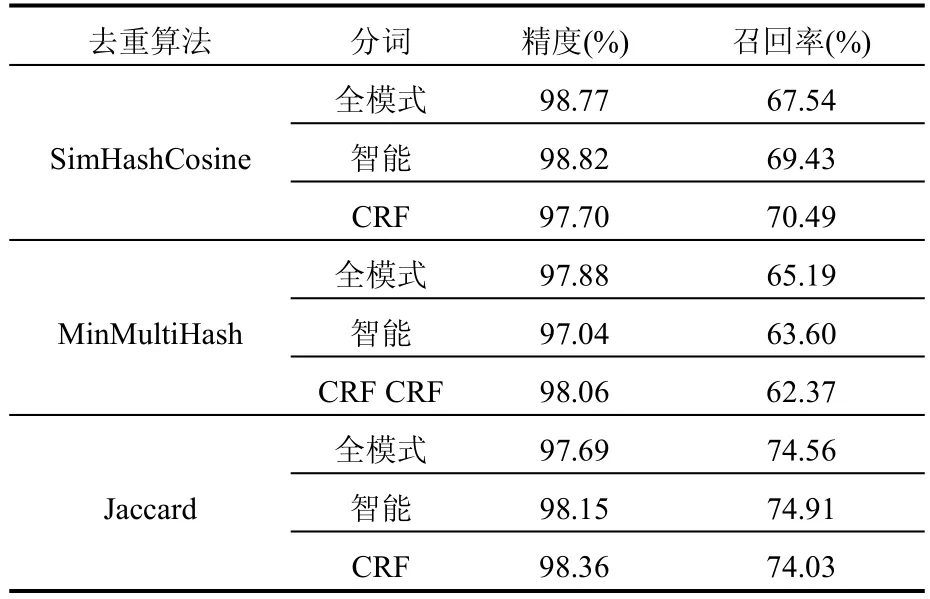
表5 横向比较结果
由表5可知:
① 精度优先原则,SimHashCosine与IKAnalyzer智能结合效果最高.
②MinMultiHash与三种分词方法结合时,全模式和CRF精度最高且相差很小,考虑全模式的召回率明显高于CRF,确定MinMultiHash和全模式结合.
③Jaccard与三种分词方法结合时,召回率和精度都相差不大,但特征比较时间,全模式:1018.42s,智能:638.54s,CRF:861.57s,其中IKAnalyzer智能模式最短,因此选择智能模式和Jaccard结合.
3.3 综合比较
算法横向比较后筛选出这3种算法: MinMultiHash+结巴全模式、Jaccard+IKAnalyzer智能、SimHashCosine+IKAnalyzer智能.阈值的不同,会导致去重结果有很大差异,此处研究这3种算法去重效果随着阈值的变化情况.此外本文认为一个好的去重算法,应当在保持较高精度时召回率也很高,算法的特征比较时间短,算法的稳定性较好.这个稳定性主要体现在在整个阈值取值范围内,精度和召回率随阈值的整体变化是否比较平稳.本文以折线图的形式展示每种算法随着阈值的改变,精度和召回率的变化趋势.精度随阈值的变化折线图如图1所示,召回率随阈值变化折线图如图2所示.如果一个算法的某个阈值精度少于80%或召回率低于40%,相应阈值下的精度和召回率都不再被显示.

图1 精度随阈值的变化折线图
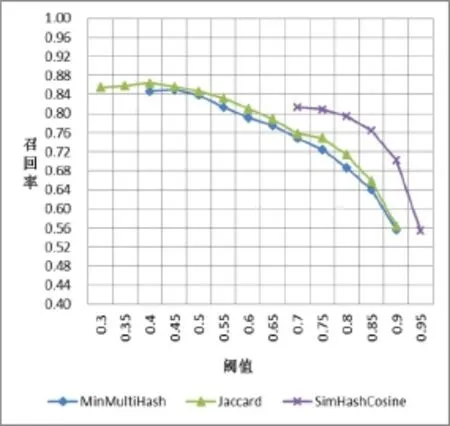
图2 召回率随阈值的变化折线图
由图1和2很明显可以看出:
①Jaccard和MinMultiHash在很大的阈值变化范围内,都能同时保证较高的精度和较高的召回率.
②Jaccard始终以微弱的优势,在精度和召回率上高于MinMultiHash.
③ 算法的稳定性排序:Jaccard>MinMultiHash> SimHashCosine.
④ 结合表4观察,MinMultiHash特征比较时间远小于Jaccard.
因此在舆情去重场景中,对算法精度和召回率非常高,推荐Jaccard;追求较高的精度和召回率,同时对时间的要求也很高的情况,推荐MinMultiHash.
4 结语
舆情是大数据服务中一种重要的数据产品,但随着大数据时代的来临,舆情服务必须解决重复严重的问题才能提供更高质量的数据.本文通过对分词算法、特征选择和去重算法进行实验研究,并对传统的Jaccard和SimHash进行了改进.提出了先纵向比较,后横向比较,最后综合比较的实验策略,通过此实验策略筛选出了舆情去重表现突出的算法搭配.随着舆情研究的深入,在今后可将Hadoop算法纳入研究范围,以提高算法的去重效率.
1中国互联网信息中心.2016年第37次中国互联网络发展状况 统 计 报 告 .http://www.cnnic.net.cn/gywm/xwzx/rdxw/ 2016/201601/t20160122_53293.htm.[2016].
2魏超.新媒体技术发展对网络舆情信息工作的影响研究.图书情报工作,2014,58(1):30–34.
3胡洋,刘秀荣,魏娜,张么九,刘婉行,钮文异.北京健康教育微博体系初建参与者网络及微博使用习惯的现状分析.中国健康教育,2014,30(8):706–708.
4吴绍忠,李淑华.互联网络舆情预警机制研究.中国人民公安大学学报,2008,14(3):38–42.
5贺知义.基于关键词的搜索引擎网页去重算法研究[硕士学位论文].武汉:华中师范大学,2015.
6龙树全,赵正文,唐华.中文分词算法概述.电脑知识与技术, 2009,5(10):2605–2607.
7刘洪波.词频统计的发展.情报科学,1991,12(6):69–73.
8朱小娟,陈特放.基于SVM的词频统计中文分词研究.微计算机信息,2007,23(30):205–207.
9华秀丽,朱巧明,李培峰.语义分析与词频统计相结合的中文文本相似度量方法研究.计算机应用研究,2012,29(3):833–836.
10王景中,邱铜相.改进的TF-IDF关键词提取方法.计算机科学与应用,2013,35(10):2901–2904.
11 Cho J,Shivakumar N,Garcia-Molina H.Finding Replicated WebCollections.AcmSigmodRecord,2000,29(2):355–366.
12黄德才,戚华春.PageRank算法研究.计算工程,2003,32(4): 145–146.
13 Real R,Vargas JM.The Probabilistic Basis of Jaccard's Index of Similarity.Systematic Biology,1996,45(3):380–385.
14 Sood S,Loguinov D.Probabilistic Near-Duplicate Detection Using SimHash.Acm Conference on Information,New York,2011:1117–1126.
15 Rao BC,Zhu E.Searching Web Data using MinHash LSH. International Conference on Management of Data,New York,2016:2257–2258.
Duplicate RemovalAlgorithm for Public Opinion
ZHANG Qing-Mei
(School of Software Engineering,University of Science and Technology of China,Suzhou 215123,China)
In big data services,duplicate removal of public opinion information is inevitable,and it lacks theoretical guidance.There is a research on the classical duplicate removal algorithm such as SimHash,MinHash,Jaccard,Cosine Similarty,as well as common segmentation algorithm and feature selection algorithm in order to seek excellent performance of the algorithm.The Jaccard based on short article and the SimHash algorithm based on Cosine Distance are proposed to improve the traditional algorithms.Aiming at the problem of the low efficiency of experiment on many research subjects,the strategy is adopted that filters out algorithm of obvious advantages by vertical comparison firstly, and gets the most appropriate algorithm collocation by horizontal comparison secondly,at last,makes a comprehensive comparison.The experiment of 3000 public opinion samples shows that improved SimHash has better effect than traditional SimHash;improved Jaccard increases the recall rate by 17%and improves the efficiency by 50%compared with traditional Jaccard.Under the condition that the accuracy is higher than 96%,MinHash+Jieba full pattern word segmentation and Jaccard+IKAnalyzer intelligent word segmentation has more than 75%recall rate and good stability. MinHash is a bit weak than Jaccard in the aspect of removal effect,yet has the best comprehensive performance and shorter feature comparison time.
public opinion data;duplicate removal algorithm;similarity computation;big data service
2016-08-28;收到修改稿时间:2016-09-27
10.15888/j.cnki.csa.005745
