非均匀数据分布下的MapReduce连接查询算法优化*
2017-06-05张敬伟尚宏佳钱俊彦
张敬伟,尚宏佳,钱俊彦,周 萍,杨 青+
1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
2.桂林电子科技大学 广西云计算与大数据协同创新中心,广西 桂林 541004
3.桂林电子科技大学 广西自动检测技术与仪器重点实验室,广西 桂林 541004
非均匀数据分布下的MapReduce连接查询算法优化*
张敬伟1,2,尚宏佳1,钱俊彦1,周 萍3,杨 青3+
1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
2.桂林电子科技大学 广西云计算与大数据协同创新中心,广西 桂林 541004
3.桂林电子科技大学 广西自动检测技术与仪器重点实验室,广西 桂林 541004
MapReduce分布式计算框架有助于提升大规模数据连接查询的效率,但当连接属性分布不均匀时,其简单的散列策略容易导致计算节点间负载不均衡,影响作业的整体性能。针对连接查询操作中的数据倾斜问题,研究了MapReduce框架下大规模数据连接查询操作的优化算法。首先对经典的改进重分区连接查询算法进行实验分析,研究了传统MapReduce计算框架下连接查询操作的执行流程,找出了基于MapReduce计算框架的连接查询算法在数据分布不均匀时的性能瓶颈;进而提出了组合分割平衡分区优化策略,设计并实现了基于组合分割平衡分区优化策略的改进型连接查询算法。实验结果表明,提出的优化策略在大规模数据的连接查询处理上很好地解决了数据倾斜带来的性能影响,具有好的时间性能和可扩展性。
连接查询;MapReduce;数据倾斜
1 引言
多样化的应用促进了数据的快速积累,GB、TB级的数据分析已成为常态。在互联网领域,全球最大中文搜索引擎百度,收录了全世界万亿个网页,数据总量接近1 000 PB(http://chgcx.sirt.edu.cn/a/2015/ 12/06/2015120619241012299.html)。在零售业,沃尔玛每小时都会积累2.5 PB的消费数据(http://news. hexun.com/2016-05-13/183843576.html)。在金融行业,国内“银联”银行卡发行量接近40亿张,每天需处理超过600亿次交易,年新增的数据量也达到数十PB。上述的大规模数据及其分析应用中,连接查询操作是最频繁使用的算子之一,连接查询操作的性能对大规模数据分析效率具有重要影响。
MapReduce计算架构具有较好的可扩展性、高可用性以及容错性,被广泛地应用于大规模数据分析相关工作中。然而,大规模数据中经常会出现数据分布不均匀的情况,采用MapReduce计算框架的连接查询操作并不总是十分有效,会导致各计算节点负载不均衡,降低连接查询操作效率,影响大规模数据分析性能。因此,本文将致力解决大规模数据连接操作过程中数据分布不均匀导致作业性能下降的问题,提升大规模数据连接查询的效率。
2 相关工作
连接查询操作是关系型数据库的核心操作算子,在日志分析、联机分析处理等领域也被频繁使用,大规模数据的连接查询需借助MapReduce计算框架来提升性能。目前,针对MapReduce计算框架下的连接查询操作及其优化工作可归纳为以下3类。
(1)基于传统MapReduce框架的连接优化研究。该类研究不需要对数据重新进行组织,实现过程也较为简单,但应对复杂连接查询操作时,往往需要多个连续的MapReduce作业,执行过程较为复杂。文献[1]设计了两表等值连接的标准重分区连接算法,在云数据管理系统中有较好的应用,但当数据量较大时,Reduce阶段可能会出现内存溢出。文献[2]为了解决标准重分区连接算法内存消耗较大的问题,设计了改进标准重分区连接算法,一定程度降低了Reduce阶段对内存容量的要求。文献[1]设计了当两表数据量相差很大时,仅需一个无Reduce阶段的MapReduce作业且具有很高效率的广播连接算法,但当两张表数据量都较大时,Map阶段可能会出现内存溢出。文献[2]在广播算法的基础上设计了半连接算法,对较小表进行过滤,减少了广播过程中数据传输量和Map阶段的内存消耗,但需连续的3个作业才能完成,执行过程较为复杂。文献[2]设计了分片半连接算法,更细粒度地对较小表进行过滤,进一步减少了广播过程中数据传输量和Map阶段的内存消耗,但同样存在执行过程较为复杂的不足。文献[3]设计了冗余重分区算法来处理两表非等值连接,利用二维矩阵较为简洁地完成了复杂的非等值连接操作,但在数据混洗阶段网络传输代价较大。文献[4]设计了两表相似度连接的算法,滤掉不可能成为最终结果的数据,有效地减少了网络传输代价,但其应用范围仅仅限于文本字符串的相似性连接。文献[5]设计了利用一个MapReduce作业处理星型连接与链式连接的多表等值连接算法,很大程度地简化了实现多表连接操作的复杂性,但随着连接表数目的增加,其中间数据量将急剧增加。文献[6]提出了网络感知多路连接算法,在多路连接方面具有较高效率,但仅适用于两张大表和多个放在同一个Reducer节点的小表,且两张大表之间必须有连接属性。文献[7]设计了基于数据本地化计算的连接查询处理算法,一定程度地提高了连接查询效率。
(2)基于改进MapReduce框架的连接优化研究。该类研究从集群层面对MapReduce计算框架进行改进,减少了连接查询过程中MapReduce作业的数目和中间数据量,但增加了算法的实现难度。文献[8]设计了Map-Reduce-Merge新型编程框架,在Reduce阶段后面附加一个Merge操作,加强了原有的Map-Reduce计算框架,可以方便地实现关系数据库中的连接和笛卡尔积操作。文献[9]将索引结构引入到Map-Reduce-Merge计算框架上,借助索引技术在Map-Reduce-Merge上实现数据剪枝预处理,缩小了待处理数据空间。文献[10]设计了Map-Join-Reduce的编程模型,在Map和Reduce之间增加一个Join操作,从多个数据源读取数据,利用一个MapReduce作业就可以完成多表连接操作。文献[11]为MapReduce增加了一个全局节点,用于接收、存储和更新少量的全局信息,对Mapper生成的中间结果进行过滤,减少了混洗代价和网络传输。
(3)基于数据索引的连接优化研究。该类研究利用索引对数据进行有效过滤,一定程度地提高了连接查询的效率,但需要对数据进行重新组织。文献[12]在Hadoop和Hive的基础上,设计了HadoopDB系统,充分利用传统关系型数据库中的索引及查询优化机制提高连接查询的效率,但其索引的容错性较弱。文献[13]利用MapReduce提供的用户自定义函数构建索引设计了Hadoop++系统,使用寄宿索引技术提高数据查询和连接效率,但其索引构建代价较高。文献[14]针对Hadoop++建立索引代价较高的不足,提出了HAIL,给每个文件的不同备份建立相应的索引,提高数据查询和连接的效率。文献[15]基于垂直分组设计了多表连接的混合系统Llama,将多表连接查询分解为无数据耦合的多个子查询,大大地减少了MapReduce作业数。文献[16]提出了CoHadoop系统,改变副本放置策略来提高数据连接查询效率,但不具有普遍适用性。文献[17]提出了Tenzing系统,在MapReduce框架上融合了ColumnIO、BigTable、GFS、MySQL等系统实现对SQL的支持,对底层数据进行数据过滤和数据索引,提高连接查询效率。
上述研究工作均致力于基于MapReduce计算框架的大规模数据连接操作及其优化,优化出发点均在集群层面上,对数据分布不均匀给大规模数据连接查询操作带来的影响考虑不够充分。本文将充分研究数据不均匀分布对大规模数据连接效率的影响及优化,最大程度地提升数据连接查询的性能,进而提高大规模数据分析的效率。
3 连接查询
连接查询在数据分析中非常重要,也是关系数据库中最主要的操作之一,主要包括内连接、外连接和交叉连接等。由于内连接较常用,本文围绕内连接展开研究。
3.1 问题的描述
TPC-H基准数据集是查询和事务处理常用性能测试数据集[18],为了简化描述且不失一般性,以TPCH中CUSTOMER和ORDERS两张表的连接查询操作为例,设计连接查询用例,本文研究的连接查询算法将围绕该查询用例进行讨论。给定关系表CUSTOMER和ORDERS,其中表CUSTOMER包含属性custkey、custname等,表ORDERS包含属性orderkey、custkey等;两表通过属性custkey进行连接,CR和CS分别表示表CUSTOMER和ORDERS相关的选择条件,查询用例的SQL描述如下:
SELECT ORDERS.orderkey,CUSTOMER.custname
FROM ORDERS INNER JOIN CUSTOMER
ON ORDERS.custkey=CUSTOMER.custkey
WHERE CRAND CS
3.2 问题的定义
设参加连接查询的两张表分别为R和S,R约定为主表,S约定为从表,ri和si分别为R和S的属性,nr和ns分别为R和S的属性个数,则表R和S的属性集合R′和S′可表示为:
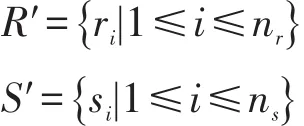
其中,属性x∈R′∩S′,y∈R′,z∈S′。不失一般性,连接条件约定为R.x=S.x;查询条件约定为CR和CS;投影属性约定为P;连接操作可以描述为σR.x=S.x(R×S);投影操作可以描述为πP(R×S)。本文的连接查询可以定义为:

上述给出的SQL查询用例的关系代数表达式如下:

4 连接查询算法
首先基于传统MapReduce计算框架,实现了改进重分区连接查询(improved repartition join query,IRJQ)算法并展开实验分析;接着,针对IRJQ算法在数据分布不均匀下各计算节点负载不均衡导致效率低下的问题,设计了组合分割平衡分区优化策略(combination and division partition strategy,CDPS),进而实现了基于组合分割平衡分区优化策略的改进型连接查询算法(IRJQ+CDPS)。
4.1 基于传统MapReduce连接查询算法
改进重分区连接查询算法是借助于传统Map-Reduce计算框架连接查询操作的一种典型实现方式,该算法仅仅需要一个MapReduce作业就能完成连接查询操作,特别是在Reduce端较小内存消耗,使得它被广泛地应用于大规模数据分析中。在Map阶段完成对连接属性的解析和标记,以HashPartition为核心完成Shuffle过程,在Reduce阶段完成连接操作。图1给出了IRJQ算法的计算框架和执行流程。
IRJQ算法的运行过程主要分为Map、Shuffle和Reduce共3个阶段。其中Map阶段完成两表的连接属性的解析和标记操作,以及查询属性的解析;Shuffle阶段负责相同hash值分组从Map端到Reduce端的传递;Reduce阶段则将来自不同表的连接属性和查询值进行连接。
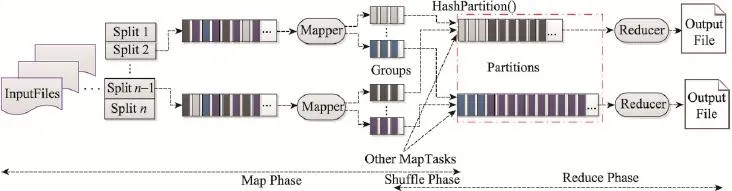
Fig.1 Computation framework and implementation process of IRJQ algorithm图1 IRJQ算法的计算框架和执行流程
4.1.1 Map阶段的属性提取和标记过程
MapTaski任务获取输入分片InputSpliti,读取Input-Spliti中源表属性和所有记录。对记录MapRecordij根据不同的源表属性,解析出对应的连接属性join_keyij和查询属性query_valueij。在连接属性join_keyij前加上源表标记tag组成复合连接属性composite_keyij,将<composite_keyij,query_valueij>以key/value形式输出,完成属性提取和标记。
如果输入分片InputSpliti来自ORDERS表,从MapRecordij中解析出custkeyij和orderkeyij,在custkeyij的前面加一个数字“1”组成复合的输出键“1”+custkeyij,将<“1”+custkeyij,orderkeyij>以key/value键值对的形式输出,完成对记录中属性的提取和标记过程。同样,如果输入分片InputSpliti来自CUSTOMER表,从MapRecordij解析出custkeyij和custnameij,在custkeyij的前面加一个数字“0”组成复合的输出键“0”+custkeyij,以key/value键值对的形式将<“0”+custkeyij,custnameij>输出。其中,在来自于CUSTOMER表中记录的连接属性custkeyij前面加标记“0”,而来自于ORDERS表中记录的连接属性custkeyij前面加标记“1”,是为了在Shuffle过程中,使得CUSTOMER表中记录排在ORDERS表中记录的前面,这样在Reduce阶段只用缓存CUSTOMER表中的记录,减少Reduce阶段对内存的消耗。其算法描述如下:
算法1属性解析和标记算法


4.1.2 Shuffle阶段的哈希分区过程
当所有输入分片完成属性的提取和标记后,需要将分组划分到合适的分区,以保证各Reducer节点拥有相等的分组数目。在传统MapReduce框架中对分组的划分过程是以HashPartition为核心完成的,读取分组Groupi中的连接属性join_keyi,计算连接属性join_keyi对应的哈希值HashCodei,将HashCodei和分区的数目做取余运算得到对应的分区PartitionNumi。其中,连接属性join_keyi一般是以字符串的形式出现,为了保证所分区拥有相等数目的分组,连接属性join_keyi的哈希值HashCodei计算策略较为重要,默认情况下使用JDK中String类的hashcode()方法。计算字符串join_keyi的长度length,读取字符串join_ keyi在内存中的存储地址并保存在字符数组val[]中,最后做一个length次的迭代运算HashCodei=31*h+ val[i++]得到哈希值HashCodei,即为对应的分区。其算法描述如下:
算法2哈希分区算法


4.1.3 Reduce阶段的连接过程
ReduceTaski任务从多个MapTask的本地磁盘中拉取属于自己的中间数据,将数据进行排序、分组和合并等操作,得到多个分组组成的集合GroupSeti。分组Groupij中的记录以<composite_key,query_value_ List>键和多个值组成的序列对形式存在,且每一个分组内所有来自于CUSTOMER的记录都排在来自ORDERS表的记录之前。对分组Groupij中的记录ReduceRecordp,读取复合连接属性composite_keyp,从复合连接属性composite_keyp中解析出连接属性join_ keyp和源表标记tag,遍历查询属性的序列query_ value_Listp。
如果tag为“0”,表明该记录来自于CUSTOMER表,将查询属性序列query_value_Listp中的每一个cust_query_valueq分别和连接属性join_keyp以<join_ keyp,cust_query_valueq>键值对的形式保存于缓存集合ReduceBufferi中。如果tag为“1”,表明该记录来自于ORDERS表,对序列query_value_Listp中的各查询属性order_query_valueq分别在缓存集合ReduceBufferi中查询其连接属性join_keyp是否存在。如果存在,就从缓存集合ReduceBufferi中读取该连接属性join_ keyp对应的查询属性cust_query_valueq,并将<order_ query_valueq,cust_query_valueq>以键值对的形式输出;如果缓存ReduceBufferi中查询其连接属性join_ keyp不存在,则读取序列query_value_Listp中的下一条查询记录order_query_value(q+1),直到序列query_ value_Listp中的所有记录遍历完成。其算法描述如下:
算法3连接查询算法
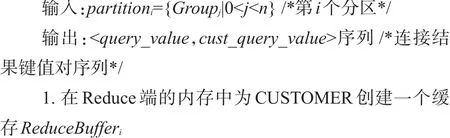

4.1.4 算法性能分析
实验平台环境和实验数据集详细见5.1节,实验的评价标准为整个作业运行时间。连接条件定义为CUSTOMER.custkey=ORDERS.custkey,实验采用测试用例SQL描述如下:
SELECT ORDERS.orderkey,CUSTOMER.custname
FROM ORDERS INNER JOIN CUSTOMER
ON CUSTOMER.custkey=ORDERS.custkey
为了较全面评估IRJQ算法的性能,将CUSTOMER的连接率设定为0.1%、20%和50%,ORDERS数据的倾斜率设定为0.2、0.5和0.8。其中,连接率定义为CUSTOMER中有购买记录的用户所占的比率;倾斜率定义为某一分组数据量在整个数据集中所占的比率。
实验1数据倾斜时不同连接率下IRJQ算法时间性能分析。固定CUSTOMER表中的数据量,不断增加ORDERS中的数据量,对比分析IRJQ算法在数据倾斜时不同连接率下的时间性能。其中,CUSTOMER中记录数目固定为8 000万条,连接率分别取0.1%、20%和50%;ORDERS中的记录数目分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图2所示。
实验结果表明,ORDERS中的连接属性不均匀分布对IRJQ算法时间性能影响较大,随着ORDERS中的数据量及倾斜率增大,其时间性能大幅度下降。这主要是因为传统MapReduce框架为了保证所有的分区有相同数目的分组,以哈希分区策略完成对分组的划分。
假设ORDERS共有m条记录,倾斜率为α,且倾斜分组数目为1;CUSTOMER共有n条记录,连接率为β;Reduce阶段共有k个分区。则每个分区的分组数目为,倾斜分组中的记录数目为m×α,非倾斜分组中的记录数目约为,倾斜分区中的记录数目约为,非倾斜分区中的记录数目约为,倾斜分区与非倾斜分区间的记录数目差约为。可以很清楚地看出,随着ORDERS中记录数目m或者倾斜率α的增加,倾斜分组的记录数目m×α变得越来越大,倾斜分组和非倾斜分组间的数据量差也会越来越大。当α→1或者m→∞时,,即ORDERS中数据分布严重不均匀或者数据量较大会导致多个分区间的数据量相差巨大,造成Reduce阶段负载严重不均衡,最终影响整个作业的时间性能。
4.2 基于改进型MapReduce连接查询算法
IRJQ算法在数据分布均匀的情况下拥有较好的时间性能和稳定性,然而当数据分布不均匀时,Reduce阶段会因为多个分组数据量相差较大导致负载不平衡,严重影响了算法的时间性能和稳定性。针对IRJQ算法的这种不足,本文设计和实现了组合分割平衡分区优化策略,形成MapReduce计算框架下基于组合分割平衡分区优化策略的改进型连接查询算法(IRJQ+CDPS)。图3给出了IRJQ+CDPS算法的计算框架和执行流程。
IRJQ+CDPS算法以改进重分区连接查询算法为基础,分为3个阶段Map、Shuffle和Reduce。Map和Reduce阶段同IRJQ算法一致,其核心改进体现在Shuffle过程中的组合分割平衡分区优化策略,保证了在数据倾斜时Reduce阶段的负载均衡。
4.2.1 ORDERS表连接属性频率分布统计
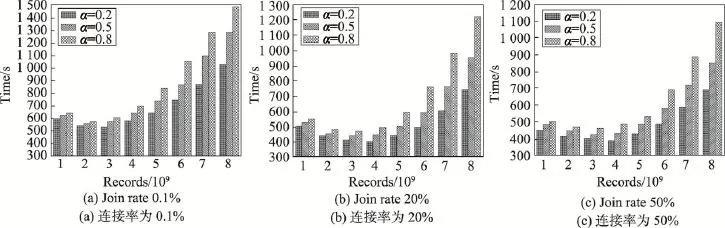
Fig.2 Time performance comparison of IRJQ algorithm under skewed data图2 数据倾斜下IRJQ算法时间性能对比分析
为了解决数据倾斜导致连接算法时间性能下降的不足,本文对严重倾斜的连接属性分组采用分割分区策略,不严重或不倾斜的连接属性分组采用组合分区策略。其中,首先需要解决的问题就是要得到ORDERS表中连接属性的频率分布情况。该过程由一个独立的MapReduce作业完成,MapTaski任务获取对应的输入分片inputspliti,读取记录MapRecordij,解析出MapRecordij的连接属性join_keyij,然后将<join_ keyij,1>以key/value的形式输出到对应的分组中。多个拥有不同连接属性的分组经过Shuffle过程的分区操作,被从Map端传送到Reduce端。这里使用的分区策略是MapReduce计算框架默认的哈希分区策略。ReduceTaski任务对来自多个Map端的分组进行排序、分组和合并等操作得到对应的分区,读取分组Groupi的连接属性join_keyij和value_Listij。其中value_ Listij为从Map阶段传送过来的具有相同连接属性的多个“1”组成的序列,将value_Listij中所有的“1”求和得到对应连接属性join_keyij的频率frequencyij。最后将<join_keyij,frequencyij>以key/value的形式输出,完成对ORDERS表中连接属性出现频率的统计。
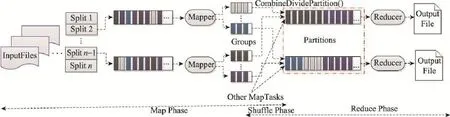
Fig.3 Computation framework and implementation process of CDPS+IRJQ algorithm图3 IRJQ+CDPS算法的计算框架和执行过程
4.2.2 严重倾斜分区和不严重或不倾斜分区划分
在得到了ORDERS表中连接属性的频率分布后,一个非常重要的问题就是如何准确地找到那些连接属性严重倾斜的分组。一个常见的方法就是计算所有连接属性分组中key/value键值对数目的平均值AVG,每个分组通过和平均值AVG的比较来确认是否严重倾斜。如果某个分组中key/value键值对数目小于平均值AVG,那么就认为该分组为不严重或不倾斜分组,将对其采用组合分区策略;同样,如果某个分组中key/value键值对数目大于或等于平均值AVG,那么就认为该分组为严重倾斜分组,将对其采用分割分区策略。所有分组的key/value键值对数目平均值AVG计算方式如下:
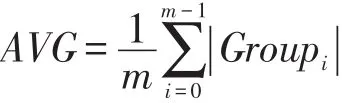
其中,|Groupi|表示第i个分组中key/value键值对的数目;m表示分组Group的个数。很明显,key/value键值对数目的平均值AVG决定了分组是否严重倾斜。如果严重倾斜分组太多,AVG也会变得更接近严重倾斜分组,从而保证了较为准确地划分出严重倾斜分组和不严重或不倾斜分组。
4.2.3 组合分割平衡分区优化策略
针对数据分布不均匀导致的倾斜问题,将那些不严重倾斜或不倾斜连接属性的分组,组合成较大的分组,然后再将组合后的大分组划分到各Reducer节点中,而那些严重倾斜连接属性的分组等划分到各Reducer节点中。
不严重倾斜或不倾斜属性分组的组合分区策略,根据每个分组中数据量的大小组合成较大的分组,在组合过程中最大程度地保证组合后的多个大分组数据量大致相等,然后将组合后的分组分别传递到Reduce端,使所有的Reduce端具有近似相等的负载量,达到负载均衡的目的。这种组合分区策略是典型NP难解问题,采用启发式的方法得到次优解,即优先分配较大分组,接着在剩下的分组中选择数据量最多的分组分配到负载最小的分区上。根据每个分组{G1,G2,…,Gm}的数据量大小进行降序排列;然后,将前n个分组分配给{r1,r2,…,rn}n个Reducer节点,这样rn的负载量最小;接着,选择{r1,r2,…,rn}中当前负载量最小的ri,将Gn+1分配给ri;重复上一步,依次将Gj分配给负载量最小的ri,只到所有的分组分配完成,达到Reduce阶段的负载均衡。
严重倾斜连接属性分组的分割分区策略,组合分区策略应对倾斜不是很严重的分组时往往具有较好的负载均衡效果,当面对那些严重倾斜的分组时,有些较大分组数据量的大小要比其他多个较小分组组合之后的数据量还要大,从而导致无论怎么分配组合都无法达到在Reduce端的负载均衡,离人们所期望的效果相差甚远。假设GSet={G1,G2,G3,G4,G5}= {2 000,700,360,150,80},PSet={P1,P2,P3},使用组合分区策略:{G1→P1},{G2→P2},{G3→P3},接下来即使把G4、G5都分配到P3上也达不到负载平衡。但是,可以将这些严重倾斜连接属性分组等划分成n份,将这n等份分别发到n个分区中,在Reduce端就可以得到一个比较好的负载平衡效果。
算法4组合分割平衡分区优化算法

5 实验与结果分析
在大规模数据分析过程中,数据分布不均匀对连接查询操作的性能有非常大的影响。本文设计和实现了IRJQ+CDPS算法和IRJQ算法,并以实验的方式对两者的时间性能和Reduce阶段最大负载量进行对比与分析。
5.1 实验平台环境和数据集
实验平台由16台高性能服务器构成,1台设为主控节点,15台设为计算节点,分布在两个机架上面,每个机架有独立的路由器。每个节点配有2个处理核心,2.4 GHz主频,8 GB内存和1.5 TB的本地存储磁盘,操作系统为Red Hat Linux 5.6。使用Hadoop 1.1.2版本的系统作为集群环境,每个节点配置2个MapTask任务和2个ReduceTask任务,HDFS的块大小设定为128 MB,每一个数据块的副本数设置为3,其他各项参数均采用默认设置。
使用TPC-H基准测试集生成工具产生用于连接查询操作实验的数据集,并采用其中的CUSTOMER和ORDERS两个数据表来做连接操作。其中,CUSTOMER表中的数据量分别取1 000万条、2 000万条、3 000万条、4 000万条、5 000万条、6 000万条、7 000条和8 000万条;ORDERS中数据量分别取10亿条、20亿条、30亿条、40亿条、50亿条、60亿条、70亿条和80亿条。为了更好地评估IRJQ+CDPS算法的性能,将ORDERS数据倾斜率设定为0.2、0.5和0.8。
实验的评价标准为时间性能和Reduce端最大负载量。其中,时间性能简单设定为整个作业运行的总时间;Reduce端的最大负载量设定为所有分区中最大那个分区的数据量。
5.2 实验与结果
为了和带有区间范围的连接查询和低选择性的连接查询相区分,将一般性连接查询定义为全表范围的连接查询。
5.2.1 全表范围的连接查询对比实验
对两种连接查询算法全表范围连接查询的性能进行对比分析,连接条件设定为CUSTOMER.custkey=ORDERS.custkey,测试用例SQL描述如下:
SELECT ORDERS.orderkey,CUSTOMER.custname
FROM ORDERS INNER JOIN CUSTOMER
ON CUSTOMER.custkey=ORDERS.custkey
实验2全表范围连接查询的不同倾斜率下时间性能对比实验。固定ORDERS表中数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在全表范围连接查询的不同倾斜率下的时间性能。其中,CUSTOMER中记录数固定为8 000万条,连接率为100%;ORDERS中记录数分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图4所示。
实验结果表明,当ORDERS中数据量较少时,IRJQ算法拥有较好的时间性能;随着ORDERS中数据量的增加,IRJQ算法的时间性能快速下降,而IRJQ+CDPS算法的时间性能逐步转好;当ORDERS中数据量增加到一定程度,IRJQ+CDPS算法拥有非常好的时间性能,且整个过程中IRJQ+CDPS算法拥有较好的稳定性。这主要是因为IRJQ+CDPS算法相对于IRJQ算法较为复杂,当ORDERS中数据量较少时,数据分布不均匀导致的Reduce阶段的负载不均衡不是很明显,IRJQ+CDPS算法负载均衡优化策略带来的时间性能优势相对于复杂的执行流程带来额外的时间开销还是太小;随着ORDERS中数据量的增加,数据分布不均匀导致的Reduce阶段的负载不均衡越来越明显,复杂的执行流程带来额外的时间开销相对于IRJQ+CDPS算法优化策略带来的时间性能优势可以忽略不计,IRJQ+CDPS算法的时间性能优势也越来越明显。
实验3全表范围连接查询的不同倾斜率下Reduce阶段最大负载量对比实验。固定ORDERS中的数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在全表范围连接查询的不同倾斜率下Reduce阶段的最大负载量。其中,CUSTOMER中记录数目固定为8 000万条,连接率为100%;ORDERS中记录数目分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图5所示。
实验结果表明,在整个实验过程中,与IRJQ算法相比,IRJQ+CDPS算法在Reduce阶段的最大负载量一直较低;并且随着ORDERS中数据量和倾斜率的增大,IRJQ+CDPS算法的这种负载均衡优势越来越明显。这主要是因为IRJQ算法在Shuffle阶段采用的是哈希分区,只能保证Reduce阶段多个分区间拥有相等的分组数,而无法保证每个分组拥有相等的数据量,更加无法保证Reduce阶段的负载均衡;而IRJQ+CDPS算法在Shuffle阶段采用了组合分割平衡分区优化策略,对不严重或不倾斜的分组采用组合分区策略,严重倾斜的分组采用分割策略,每个分组拥有近似相等的数据量,很好地保证了Reduce阶段的负载均衡。
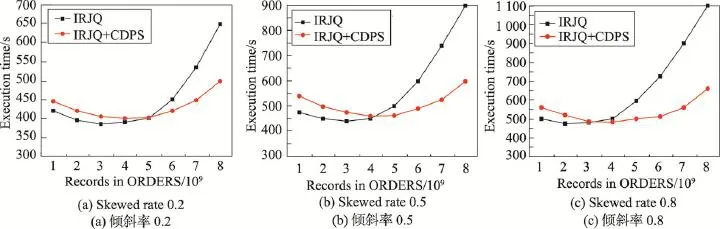
Fig.4 Time performance comparison of full-join queries under different data skewed rates图4 不同倾斜率下全表连接查询时间性能对比
5.2.2 带有区间范围的连接查询对比实验
对两种连接查询算法带有区间范围连接查询的性能进行对比分析,连接条件设定为CUSTOMER. custkey=ORDERS.custkey,选择条件设定为207 290<CUSTOMER.custkey<291050,测试用例SQL描述如下:
SELECT ORDERS.orderkey,CUSTOMER.custname
FROM ORDERS INNER JOIN CUSTOMER
ON CUSTOMER.custkey=ORDERS.custkey
WHERE 207290<CUSTOMER.custkey<291050
实验4带有区间范围连接查询的不同倾斜率下时间性能对比实验。固定ORDERS表中的数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在带有区间范围连接查询的不同倾斜率下的时间性能。其中,CUSTOMER中记录数固定为8 000万条,连接率为100%;ORDERS中记录数分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图6所示。
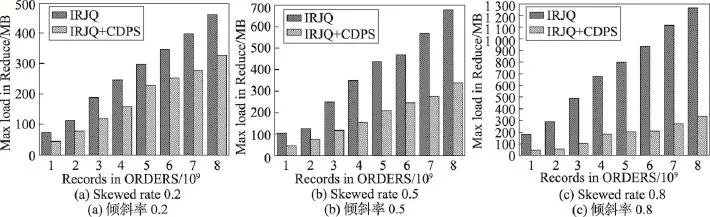
Fig.5 Maximum load of Reduce comparison for full-join queries under different data skewed rates图5 不同倾斜率下全表连接查询Reduce端最大负载量对比
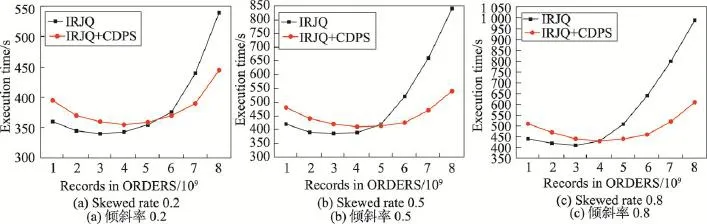
Fig.6 Time performance comparison of range queries under different data skewed rates图6 不同倾斜率下范围查询时间性能对比
实验结果同实验2类似,当ORDERS中数据量较少时,IRJQ算法拥有较好的时间性能;随着ORDERS中数据量的增加,IRJQ算法的时间性能快速下降,而IRJQ+CDPS算法的时间性能逐步转好;当ORDERS中数据量达到一定程度时,IRJQ+CDPS算法拥有非常好的时间性能,且整个过程中IRJQ+CDPS算法拥有较好的稳定性。同时,相比于实验2,实验4中的IRJQ+CDPS算法的组合分割平衡分区策略带来的时间性能优势稍微降低。这主要是因为,相比于全表范围的连接查询,带有区间范围连接查询的查询范围较小,相同的输入数据量下,Reduce阶段需要缓存的数据量较小,一定程度减少了数据分布不均匀对整个连接查询算法时间性能的影响。
实验5带有区间范围连接查询的不同倾斜率下Reduce阶段最大负载量对比实验。固定ORDERS表中的数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在不同倾斜率下Reduce阶段的最大负载量。其中,CUSTOMER中记录数固定为8 000万条,连接率为100%;ORDERS中记录数分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图7所示。
实验结果同实验3类似,在整个实验过程中,IRJQ+CDPS算法在Reduce阶段的最大负载量一直较低,并且随着ORDERS中数据量和倾斜率的增大,IRJQ+CDPS算法的这种负载均衡优势越来越明显。这主要是因为,IRJQ算法在Shuffle阶段采用的是哈希分区,在数据分布不均匀时,只能保证Reduce阶段多个分区间拥有相等的分组数,而无法保证每个分组有相等的数据量,更加无法保证Reduce阶段的负载均衡;而IRJQ+CDPS算法在Shuffle阶段采用了组合分割平衡分区优化策略,每个分组拥有近似相等的数据量,很好地保证了Reduce阶段的负载均衡。
5.2.3 低选择性的连接查询对比实验
对两种连接查询算法低选择性连接查询的性能进行对比分析,连接条件设定为CUSTOMER.custkey=ORDERS.custkey,选择条件设定为CUSTOMER. custkey=23 698,测试用例SQL描述如下:
SELECT ORDERS.orderkey,CUSTOMER.custname
FROM ORDERS INNER JOIN CUSTOMER
ON CUSTOMER.custkey=ORDERS.custkey
WHERE CUSTOMER.custkey=23698
实验6低选择性连接查询的不同倾斜率下时间性能对比实验。固定ORDERS表中的数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在低选择性连接查询的不同倾斜率下的时间性能。其中,CUSTOMER中记录数固定为8 000万条,连接率为100%;ORDERS中记录数分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图8所示。
实验结果同实验4类似,当ORDERS中数据量较少时,IRJQ算法拥有较好的时间性能;随着ORDERS中数据量的增加,IRJQ算法的时间性能快速下降,而IRJQ+CDPS算法的时间性能逐步转好;当ORDERS中数据量达到一定程度时,IRJQ+CDPS算法拥有非常好的时间性能,且整个过程中IRJQ+CDPS算法拥有较好的稳定性。同时,相比于实验4,实验6中的IRJQ+CDPS算法的平衡分区带来的时间性能优势有所降低。这是主要是因为,相比于带有区间范围的连接查询,低选择性连接查询的查询范围较小,相同的输入数据量下,Reduce阶段需要缓存的数据量较小,一定程度减少了数据分布不均匀对整个连接查询算法时间性能的影响。
实验7低选择性连接查询的不同倾斜率下Reduce阶段最大负载量对比实验。固定ORDERS表中的数据量,不断增加CUSTOMER中的数据量,对比分析IRJQ算法和IRJQ+CDPS算法在低选择性连接查询的不同倾斜率下Reduce阶段的最大负载量。其中,CUSTOMER中记录数固定为8 000万条,连接率为100%;ORDERS中记录数分别取10亿、20亿、30亿、40亿、50亿、60亿、70亿和80亿,倾斜率分别取0.2、0.5和0.8。实验结果如图9所示。
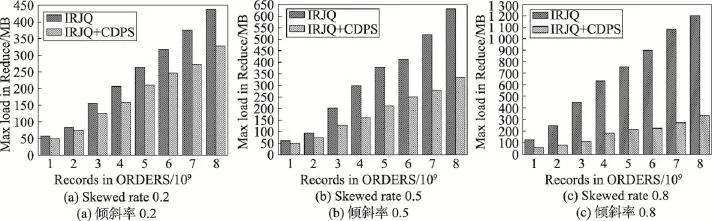
Fig.7 Maximum load of Reduce comparison for range queries under different data skewed rates图7 不同倾斜率下范围查询Reduce端最大负载量对比
实验结果同实验5类似,在整个实验过程中,IRJQ+CDPS算法在Reduce阶段的最大负载量一直较低,并且随着ORDERS中数据量和倾斜率的增大,IRJQ+CDPS算法的这种负载均衡优势越来越明显。这主要是因为,IRJQ算法在Shuffle阶段采用的是哈希分区,在数据分布不均匀时,只能保证Reduce阶段多个分区间拥有相等的分组数,而无法保证每个分组有相等的数据量,更加无法保证Reduce阶段的负载均衡;而IRJQ+CDPS算法在Shuffle阶段采用了组合分割平衡分区优化策略,每个分组拥有近似相等的数据量,很好地保证了Reduce阶段的负载均衡。
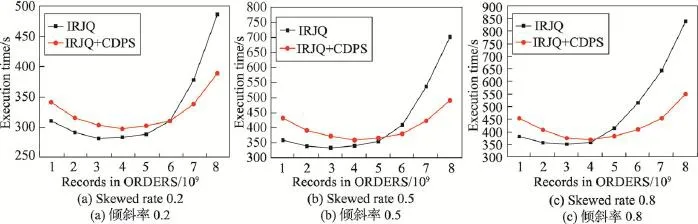
Fig.8 Time performance comparison of low-join-rate queries under different data skewed rates图8 不同倾斜率下低连接率查询时间性能对比
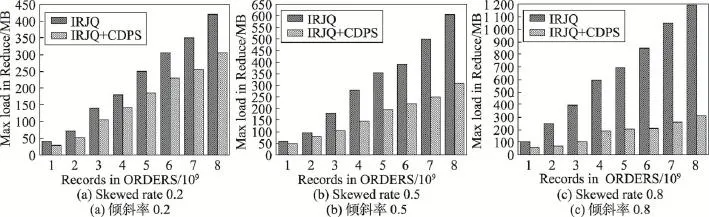
Fig.9 Maximum load of Reduce comparison for low-join-rate queries under different data skewed rates图9 不同倾斜率下低连接率查询Reduce端最大负载量对比
5.3 结果分析
从上面的实验结果中可以看到,不论是在全局范围的连接查询操作,还是带有区间范围的连接查询操作,亦或是低选择性连接查询操作,相对于IRJQ算法,IRJQ+CDPS算法在时间性能和Reduce端最大负载量两方面均具有非常大的优势。
在时间复杂度方面,当ORDERS中数据量较少时,IRJQ算法拥有较好的时间性能;随着ORDERS表中数据量的增加,IRJQ算法的时间性能快速下降,而IRJQ+CDPS算法的时间性能逐步转好;当ORDERS表中数据量达到一定程度时,IRJQ+CDPS算法拥有较好的时间性能。这主要是因为,IRJQ+CDPS算法相对于IRJQ算法较为复杂,当ORDERS中数据量较少时,数据分布不均匀导致的Reduce阶段的负载不均衡不是很明显,IRJQ+CDPS算法的优化策略带来的时间性能优势相对于复杂的执行流程带来额外的时间开销还是太小;随着ORDERS中数据量的增加,数据分布不均匀导致的Reduce阶段的负载不均衡不是越来越明显,复杂的执行流程带来额外的时间开销相对于IRJQ+CDPS算法的优化策略带来的时间性能优势可以忽略不计,IRJQ+CDPS算法的时间性能优势也越来越明显。
在Reduce端的最大负载量方面,整个实验过程中,IRJQ+CDPS算法在Reduce阶段的最大负载量一直较低,并且随着ORDERS中数据量和倾斜率的增大,IRJQ+CDPS算法的这种负载均衡优势越来越明显。这主要是因为,IRJQ算法在Shuffle阶段采用的是哈希分区,在数据分布不均匀时,只能保证Reduce阶段多个分区间拥有相等的分组数,而无法保证每个分组有相等的数据量,更加无法保证Reduce阶段的负载均衡;而IRJQ+CDPS算法在Shuffle阶段采用了组合分割平衡分区优化策略,很好地保证了Reduce阶段的负载均衡。
6 小结
连接查询是大规模数据分析的核心操作算子之一,数据倾斜在大规模数据分析中普遍存在,且对借助于MapReduce计算框架的连接查询算法的效率具有较大影响。本文主要针对连接查询操作中的数据倾斜问题,研究MapReduce框架下大规模数据连接查询操作的优化算法。首先,以较为常见的改进重分区连接查询算法为例,研究借助于传统MapReduce计算框架连接查询操作的执行流程,找出基于Map-Reduce计算框架连接算法在数据分布不均匀时的性能瓶颈;进而,提出了组合分割平衡分区优化策略,形成了MapReduce计算框架下基于组合分割平衡分区优化策略的改进型连接查询算法。实验结果表明,提出的优化策略在大规模数据连接查询处理上很好地解决了数据倾斜对其性能的影响,具有较好的时间性能和可扩展性。
[1]Olston C,Reed B,Srivastava U,et al.Pig a not-so-foreign language for data processing[C]//Proceedings of the 2008 International Conference on Management of Data,Vancouver, Canada,Jun 9-12,2008.New York:ACM,2008:1099-1110.
[2]Blanas S,Patel J M,Ercegovac V,et al.A comparison of join algorithms for log processing in MapReduce[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data,Indianapolis,USA,Jun 6-11, 2010.New York:ACM,2010:975-986.
[3]Okcan A,Riedewald M.Processing theta-joins using Map-Reduce[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data,Athens,Greece, Jun 12-16,2011.New York:ACM,2011:949-960.
[4]Vernica R,Carey M J,Li Chen.Efficient parallel set similarity joins using MapReduce[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis,USA,Jun 6-10,2010.New York:ACM,2010: 495-506.
[5]Afrati F N,Ullman J D.Optimizing multiway joins in a Map Reduce environment[C]//Proceedings of the 13th International Conference on Extending Database Technology,Lausanne,Switzerland,Mar 22-26,2010.New York:ACM,2011: 1282-1298.
[6]Slagter K,Hsu C H,Chung Y C,et al.SmartJoin:a networkaware multiway join for MapReduce[J].Cluster Computing, 2014,17(3):629-641.
[7]Zhao Yanrong,Wang Weiping,Meng Dan,et al.Efficient join query processing algorithm CHMJ based on Hadoop[J]. Journal of Software,2012,23(8):2032-2041.
[8]Yang H C,Dasdan A,Hsiao R L,et al.Map-Reduce-Merge: simplified relational data processing on large clusters[C]// Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data,Beijing,Jun 11-14,2007. New York:ACM,2007:1029-1040.
[9]Yang H C,Parker D S.Traverse:simplified indexing on large Map-Reduce-Merge clusters[C]//LNCS 5463:Proceedings of the 14th International Conference on Database Systems for Advanced Applications,Brisbane,Australia,Apr 21-23, 2009.Berlin,Heidelberg:Springer,2009:308-322.
[10]Jiang D,Tung A K H,Chen Gang.Map-Join-Reduce:toward scalable and efficient data analysis on large clusters[J]. IEEE Transactions on Knowledge and Data Engineering, 2011,23(9):1299-1311.
[11]Ding Linlin,Wang Guoren,Xin Junchang,et al.ComMap Reduce:an improvement of MapReduce with lightweight communication mechanisms[C]//LNCS 7239:Proceedings of the 17th International Conference on Database Systems for Advanced Applications,Busan,Korea,Apr 15-19,2012.Berlin,Heidelberg:Springer,2012:150-168.
[12]Abouzeid A,Bajda-Pawlikowski K,Abadi D,et al.Hadoop-DB:an architectural hybrid of MapReduce and DBMS technologies for analytical workloads[C]//Proceedings of the 35th International Conference on Very Large Data Bases,Lyon, France,Aug 24-28,2009.NewYork:ACM,2009:922-933.
[13]Dittrich J,Quiané-Ruiz J A,Jindal A,et al.Hadoop++:making a yellow elephant run like a cheetah(without it evenoticing) [C]//Proceedings of the 36th International Conference on Very Large Data Bases,Singapore,Sep 13-17,2010.New York:ACM,2010:515-529.
[14]Dittrich J,Quiané-Ruiz J A,Richter S,et al.Only aggressive elephants are fast elephants[C]//Proceedings of the 38th International Conference on Very Large Data Bases,Istanbul, Turkey,Aug 27-31,2012.NewYork:ACM,2012:1591-1602.
[15]Lin Yuting,Agrawal D,Chen Chen,et al.Llama:leveraging columnar storage for scalable join processing in the Map-Reduce framework[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens,Greece,Jun 12-16,2011.New York:ACM,2011: 961-972.
[16]Zhang Yanfeng,Gao Qixin,Gao Lixin,et al.Priter:a distributed framework for prioritized iterative computations [C]//Proceedings of the 2nd ACM Symposium on Cloud Computing,Cascais,Portugal,Oct 26-28,2011.New York: ACM,2011:1-13.
[17]Chattopadhyay B,Lin Liang,Liu Weiran,et al.Tenzing a SQL implementation on the MapReduce framework[C]//Proceedings of the 37th International Conference on Very Large Data Bases,Seattle,USA,Aug 29-Sep 3,2011.New York: ACM,2011:1318-1327.
[18]Zhu Haitong.Efficient star join for column-oriented data store in the MapReduce environment[D].Shanghai:East China Normal University,2012.
附中文参考文献:
[7]赵彦荣,王伟平,孟丹,等.基于Hadoop的高效连接查询处理算法[J].软件学报,2012,23(8):2032-2041.
[18]祝海通.MapReduce环境中基于列存储的一种高效的星型连接方法[D].上海:华东师范大学,2012.

ZHANG Jingwei was born in 1977.He received the Ph.D.degree from East China Normal University in 2012. Now he is an associate professor at Guilin University of Electronic Technology,and the member of CCF.His research interests include Web data analysis and management,query optimization technologies,massive data management and storage,etc.
张敬伟(1977—),男,山东蓬莱人,2012年于华东师范大学获得博士学位,现为桂林电子科技大学计算机与信息安全学院副教授,CCF会员,主要研究领域为Web数据分析与管理,查询优化技术,海量数据管理和存储等。

SHANG Hongjia was born in 1989.He is an M.S.candidate at School of Computer and Information Security,Guilin University of Electronic Technology.His research interests include database technology and distributed computing,etc.
尚宏佳(1989—),男,湖北随州人,桂林电子科技大学计算机与信息安全学院硕士研究生,主要研究领域为数据库技术,分布式计算等。

QIAN Junyan was born in 1973.He received the Ph.D.degree from Southeast University in 2008.Now he is a professor at Guilin University of Electronic Technology,and the senior member of CCF.His research interests include software engineering,program analysis and verification,information security and VLSI fault tolerance technologies,etc.
钱俊彦(1973—),男,浙江嵊县人,2008年于东南大学获得博士学位,现为桂林电子科技大学计算机与信息安全学院教授,CCF高级会员,主要研究领域为软件工程,程序分析与验证,信息安全,VLSI容错技术等。

ZHOU Ping was born in 1961.She is a professor at Guilin University of Electronic Technology.Her research interests include speech signal processing and intelligent control,etc.
周萍(1961—),女,河北唐山人,桂林电子科技大学电子工程与自动化学院教授,主要研究领域为语音信号处理,智能控制等。

YANG Qing was born in 1976.She is an associate professor at Guilin University of Electronic Technology.Her research interests include massive data management and large-scale intelligent information processing,etc.
杨青(1976—),女,广西恭城人,桂林电子科技大学电子工程与自动化学院副教授,主要研究领域为海量数据管理,大规模智能信息处理等。
Join Query Optimization Based on MapReduce under Skewed Data*
ZHANG Jingwei1,2,SHANG Hongjia1,QIAN Junyan1,ZHOU Ping3,YANG Qing3+
1.Guangxi Key Laboratory of Trusted Software,Guilin University of Electronic Technology,Guilin,Guangxi 541004,China
2.Guangxi Cooperative Innovation Center of Cloud Computing and Big Data,Guilin University of Electronic Technology,Guilin,Guangxi 541004,China
3.Guangxi Key Laboratory of Automatic Measurement Technology and Instrument,Guilin University of Electronic Technology,Guilin,Guangxi 541004,China
+Corresponding author:E-mail:gtyqing@hotmail.com
ZHANG Jingwei,SHANG Hongjia,QIAN Junyan,et al.Join query optimization based on MapReduce under skewed data.Journal of Frontiers of Computer Science and Technology,2017,11(5):752-767.
MapReduce,a classic distributed computing environment,can improve the performance of join query on large-scale data,but when the join attributes do not follow a uniform distribution,the pure hash strategy in traditional MapReduce will lead to load imbalance over computing nodes,which will reduce the performance of overall task.Aiming at the data skew problem in the join query,this paper studies the join query optimization based on MapReduce computing framework.Firstly,this paper conducts experimental analysis for the improved repartitioning join query algorithm,studies the execution phases of join query based on traditional MapReduce computing framework,and finds the performance bottlenecks of join query on MapReduce computing framework when data do not follow a uniform distribution.Based on the above,this paper designs and implements an improved join query optimization algorithm,which is based on an execution strategy by integrating the combination segmentation method and equilibrium partitioning method.The experimental results show that the proposed optimization method provides a good solution for distributed join query on large-scale skewed datasets,and presents an excellent time performance and scalability.
join query;MapReduce;skewed data
10.3778/j.issn.1673-9418.1604022
A
TP311.130
*The National Natural Science Foundation of China under Grant Nos.U1501252,61363005,61462017(国家自然科学基金);the Natural Science Foundation of Guangxi under Grant Nos.2014GXNSFAA118353,2014GXNSFAA118390,2014GXNSFDA118036(广西自然科学基金);the High Level Innovation Team of Colleges and Universities in Guangxi and Outstanding Scholars Program Funding (广西高等学校高水平创新团队及卓越学者计划);the Program of Guangxi Cooperative Innovation Center of Cloud Computing and Big Data(广西云计算与大数据协同创新中心基金项目);the Guangxi Cooperative Innovation Center of IOT and Industrialization (广西物联网技术与产业化推进协同创新中心资助项目).
Received 2016-04,Accepted 2016-06.
CNKI网络优先出版:2016-06-27,http://www.cnki.net/kcms/detail/11.5602.TP.20160627.0929.006.html
