Spark平台下的短文本特征扩展与分类研究*
2017-06-05赵衎衎李翠平
王 雯,赵衎衎,李翠平+,陈 红,孙 辉
1.中国人民大学 数据工程与知识工程教育部重点实验室,北京 100872
2.中国人民大学 信息学院,北京 100872
Spark平台下的短文本特征扩展与分类研究*
王 雯1,2,赵衎衎1,2,李翠平1,2+,陈 红1,2,孙 辉1,2
1.中国人民大学 数据工程与知识工程教育部重点实验室,北京 100872
2.中国人民大学 信息学院,北京 100872
短文本分类;特征扩展;关联规则;Spark平台
1 绪论
1.1 研究背景
短文本通常是指字数在160字以下的文本,被广泛应用于微博、论坛、短信、即时消息、邮件等网络应用中。相对长文本,短文本具有字数少、数据量大、实时性高、应用广泛等突出特性。短文本在日常网络沟通及信息获取中扮演了重要的角色,随着互联网的发展,互联网应用不断丰富,网民参与度日益上升,互联网产生的短文本数量呈指数增长。以微博为例,微博是一个基于用户关系圈的信息获取、传播及分享平台,其中微博内容为140字以下的典型的短文本,用户可以随时随地更新关于日常生活、新闻热点等的见闻。据微博2016年3月发布的《2015年微博消费者白皮书》[1]显示,截至2015年12月,微博日活跃用户(day active users,DAU)数量达到1.06亿,同比增长32%。以2015年热门互联网金融事件“e租宝”话题为例,围绕该话题,参与人数达到6万人,总共被提及22.7万次,达到1.9亿的阅读人数;从垂直领域角度讲,涉及“美食”话题的微博数量达到10.8亿条,互动博文数量超过900亿次。数据是21世纪最宝贵的财富,随着短文本数据的增加,如何有效利用丰富的数据资产,产生巨大的再生价值,成为当下学术及工业领域研究热点。短文本分类技术在话题追踪、舆情分析、信息检索等多方面具有重要的研究及应用价值。
1.2 问题提出
短文本作为文本的一种特殊类型,分类流程大致相同,即:给定带标签C的文档集D,定义函数F,求解每个文档d与类别c的关系映射,并根据映射F,预测未知类别文档集合D′对应的类别C′。该过程描述如图1所示。
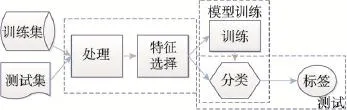
Fig.1 Process of text classification图1 文本分类过程图
关于长文本分类的研究开始较早,且研究成果显著,如K近邻、朴素贝叶斯、支持向量机等算法在不同文本分类问题中得到广泛应用,并针对不同数据集及测试标准得到较好的分类效果。然而,因短文本实时性强、数据量大、字数少、特征维度高、特征稀疏等特性,导致上述传统分类方法在处理短文本时,分类效果不佳。相对于长文本,短文本分类的瓶颈及挑战主要体现在以下三方面:
(1)因特征维数高采用传统的针对长文本进行处理的方法,如分词、TF-IDF、去停用词(stop word)等操作时,很容易丢失短文本的语义信息。
(2)因特征稀疏,使用传统的长文本分类方法,如K-近邻(K-nearestneighbor,KNN)、朴素贝叶斯(naive Bayes,NB)、神经网络(neural network,NN)、支持向量机(support vector machine,SVM)进行分类时,无法有效选择特征,构造向量空间。
(3)因数据量大,实时性要求高,传统短文本分类方法,如支持向量机算法,在处理大数据集短文本时面临吞吐量及执行效率的问题。
1.3 研究现状
特征扩展是解决短文本特征维度高且特征稀疏问题的有效方式,近年来得到广泛的研究及应用。具体特征扩展的研究方向总结如下:
(1)使用知识库如WordNet或Wikipedia[2-3]等,可以发现绝大部分词与词之间的语义关系,但是对于在知识库中没有收录的词语就无效了。
(2)借助外部文本[4],如搜索引擎搜索的结果,进而扩展短文本的特征[2,5-6]。将短文本特征作为关键词,以搜索引擎返回结果对短文本进行扩展,原特征与扩展后的特征之间关联性较高,但实现难度较大,比较耗时,同时在一定程度上依赖于搜索引擎结果的好坏。
(3)基于背景语料库,采用不同算法挖掘背景语料中的潜在“特征”。Phan[7]、Chen[8]等人使用主题模型LDA(latent Dirichlet allocation)[9]来计算文本之间的相似性。通过与传统直接采用SVM分类算法进行短文本分类相比,取得了较好的加速效果。采用LDA进行特征扩展首先需要一个较大的背景文档集,其次LDA主题模型以纯概率为基础,不考虑组成词之间的联系[10-11]。并且由于采用不同的特征权重计量标准,导致后期扩展结果很大程度上依赖于特征权重归一化处理的结果。文献[12]提出一种基于频繁项集考虑语义关联性的特征扩展方式,通过背景语料库挖掘各类别频繁项集,使用频繁项集对原短文本各类别特征进行扩展。使用频繁项集进行特征扩展的方法在解决短文本特征稀疏问题的同时考虑到特征之间的语义关联,文中实验结果显示,特征扩展后使用SVM分类的效果相对于普通SVM算法在准确率和召回率方面都能得到较大的提升。上述研究中采用卡方检验的方式选取影响因子较大的前K个特征值,对选出的特征值在后续计算中,不再计算初始特征值权重。如对类别C1按照卡方检验结果选取特征值(t1,t2,t3),针对扩展语料库的挖掘,存在频繁项集{t3,t4},则扩展后特征值为(t1,t2,t3,t4)。该计算方法是对模型的一种简化,但忽略特征值的权重可能导致模型无法真实反映现实应用。
文献调研结果显示,当数据集较小时,对特征扩展后的短文本进行分类,准确率明显上升,但当数据集较大时,短文本本身面临较大的吞吐量瓶颈,扩展后的短文本因特征补充,数据量增大,分类压力更加突出。随着MapReduce思想的成熟及应用,关于分布式计算框架上并行数据处理成为大数据环境下解决吞吐量问题的有效方式[13]。
1.4 本文贡献
针对短文本分类过程中面临的瓶颈问题,本文在上述文献调研的基础上,提出基于关联规则挖掘的特征扩展方法,进行Spark平台上短文本特征扩展与分类研究。本文贡献总结为以下几方面:
(1)提出基于关联规则挖掘算法进行特征扩展的方法,并在特征扩展的过程中保留特征权重。通过特征扩展的方式对短文本特征稀疏问题进行优化。
(2)对扩展后的短文本采用支持向量机算法进行分类,并针对短文本特性,对cascade SVM算法支持向量选择过程提出基于距离选择的改进方法。
(3)针对目前短文本信息量大,对计算能力、实时性要求较高等特性,提出Spark平台上先特征扩展再分类的两步短文本分类方法,构建Spark平台上高效的短文本分类器。
1.5 论文组织结构
本文组织结构如下:第1章介绍短文本定义、应用及短文本分类的巨大研究价值,通过对分类过程的简要分析,介绍目前分类瓶颈及相应研究现状,在上述基础上提出Spark平台上基于关联规则挖掘的短文本特征扩展方法,并指出本文主要贡献;第2章介绍基于关联规则挖掘的短文本特征扩展方法的思想、伪代码及算法选择;第3章介绍基于距离选择的层叠支持向量机算法;第4章实现Spark平台上短文本特征扩展及分类实验,通过多组实验,从分类准确率及效率提升的角度,验证本文提出的Spark平台上的短文本分类方法在分类效率及分类准确率上的有效性;第5章对全文进行总结,并指出未来工作方向。
2 短文本特征扩展
如上文介绍,相比于长文本,短文本因特征维度高,特征稀疏,在分类过程中特征抽取及特征展示阶段面临较大的瓶颈,进而在分类过程中,分类准确率表现不佳。下面介绍如何借助背景语料库,采用关联规则挖掘的方式,对短文本特征进行扩展。
2.1 方法描述
基于关联规则的特征扩展方法要求对比短文本特征及背景语料库关联规则,使用背景语料库中的关联规则对短文本特征进行补充。该方法实现过程如图2所示。
记数据集D为目标短文本数据集,S={d1,d2,…, dn}为与目标短文本相关的语料库,如目标短文本D为新闻标题数据集,则语料库S可以是对应的新闻正文内容。以集合T={t1,t2,…,tk}表示语料库S的特征集合,集合C={c1,c2,…,cm}表示数据集D和S的所有类别。以 sup(t)表示特征 t的支持度,sup(T)= Count(Dt)/Count(D),Count(Dt)表示文本集中包含特征t的文档的数量,Count(D)表示文档总数。以conf(t,c)表示关联规则t≥c成立的置信度,conf(t,c)=Count(t,c)/ Count(Dt),Count(t,c)表示t、c共同出现的文档数,Count(Dt)表示出现特征t的文档数。当sup(T)超过最小支持度限制α时,称集合T中子项之间具有一致性。如T包含t1、t2两个子项,已知t1属于类别C,则称Tendency(t2)=c。以Conf(t1→t2)表示关联规则t1→t2的置信度,以V(t)表示原短文本特征t的权重。
首先对于原短文本特征,保留原特征值的权重,对背景语料库,挖掘关联规则,计算特征置信度,以置信度和原特征的权重乘积作为扩展特征的权重值。如t3为原特征集与频繁项集的共同特征,假设关联规则t3→t4,且Conf(t3→t4)=0.8,原t3权重V(t3)= 0.2,则扩展后特征t4权重V(t4)=0.8×0.2=0.16。
2.2 伪代码
特征扩展过程以短文本数据集和背景语料库关联规则作为输入,分别记为d和s,其中d={<t1,v1>,<t2,v2>,…,<tk,vk>},数据集中包含k个短文本特征。
首先,初始化短文本特征集exd_d为空集。遍历一次数据集,取每个短文本特征tm,对于每个关联规则s的左右两端特征ti和tj,若tm=tj且tj既不在d中,也不在exd_d中,则计算tj的权重w=Conf(tm→tj)× V(tm),并将 <tj,w>加入到exd_d中。最后,exd_d= exd_d∪d即为扩充后的短文本特征集合。
为简化记录,以AR-FeatureExtension表示基于关联规则挖掘的特征扩展方法,其中s表示背景语料库S对应的关联规则数据集。
遍历关联规则挖掘的结果,对于每个关联规则对,如一方出现在原短文本数据集,另一方不存在,则将后者扩充到原短文本中,新加入的特征权重值为原短文本对应特征权重与关联规则置信度的乘积。
2.3 Spark平台上特征扩展算法选择
本文在使用关联规则进行扩展特征挖掘的过程中,针对常用的关联规则挖掘算法Apriori算法和FPGrowth算法,采用MapReduce思想设计并行Apriori算法(MR-Apriori)和并行FP-Growth算法(MR-FP-Growth),后期通过对比实验选择Spark平台上关联规则挖掘效果较好的算法作为特征扩展阶段的基础算法。
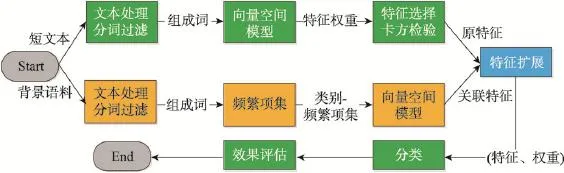
Fig.2 Feature extension and classification of short text图2 短文本特征扩展及分类过程
2.3.1 MR-Apriori算法
Spark平台上MR-Apriori算法实现过程中,对每次迭代采用MapReduce思想。Map阶段先由各计算节点根据本地数据集,产生局部频繁模式;Reduce阶段由主节点进行聚集操作,产生全局频繁模式,最后进行关联规则的挖掘。Spark平台上MR-Apriori算法执行过程如图3所示。
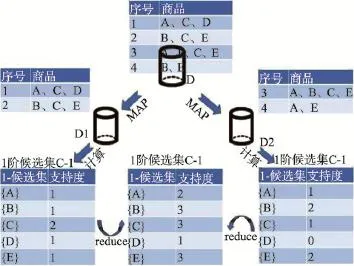
Fig.3 Process of MR-Apriori图3 MR-Apriori算法执行过程
Apriori算法的最重要特点是在挖掘关联规则的过程中引入候选集的概念,以原始数据集D为输入,最终得到了1至K阶的频繁模式集。
首先,并行扫描数据集,将D分为N个分区,各节点根据本地数据分区生成本地1阶候选集,将结果返回给主节点,再进行数据聚合,产生1阶候选集C-1。对C-1进行剪枝,从而生成1阶频繁项集L-1。
在此基础上,可生成2到K阶频繁项集。并行扫描数据库,判断是否存在K-1阶频繁项集(K>1)。若存在,则对K-1阶频繁项集进行连接操作,产生候选集C-K,各节点计算本地K阶候选集内各元素的支持度并将结果返回给主节点,主节点聚合数据后产生K阶候选集和支持度,对其进行剪枝后生成K阶频繁项集L-K。若不存在,则令K=K+1,重新判断,多次迭代,直至没有新的候选集产生。
2.3.2 MR-FP-Growth算法
Spark平台上的MR-FP-Growth算法在实现过程中,各执行步骤之间存在递归关系,因此采用数据集划分的方法,算法执行过程中执行3次MapReduce过程。Spark平台上使用MR-FP-Growth进行频繁模式及关联规则挖掘过程如图4所示。
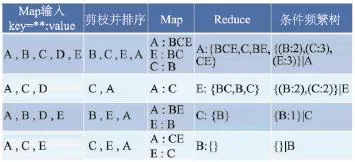
Fig.4 Process of MR-FP-Growth图4MR-FP-Growth算法执行过程
上述算法执行过程中包括MapReduce及生成条件频繁树两个阶段,对应的执行流程如下:
步骤1把数据库分成连续的不同的分区,每一个分区分布在不同的机器上。
步骤2执行第一次MapReduce过程,计算F_list,即item的support count。
步骤3将F_list中item分成Q组,形成group_list,每个group都被分配唯一的group_id,并包含一组item。
步骤4并行FP-Growth,执行第二次MapReduce操作。具体的,在Map阶段,利用步骤1的数据库分区,处理数据库分区中的每一条transaction,将transaction细分成item,每个item根据group_list映射到合适的group中。Map过程后,属于同一个group的item集合聚合到同一台机器上。在Reduce阶段,根据Map过程中产生的集合,进行本地FP-Growth计算。
步骤5聚合各机器结果形成全局FP-Growth计算值。
3 短文本分类
对扩展后的短文本进行分类过程中采用cascade SVM算法[13-15],通过并行的方式加速短文本分类效率。本文在应用cascade SVM算法时,根据短文本特性,引入参数α,提出根据文本集大小调整参数α,从而按照距离选择支持向量的方式[16]。
3.1 方法描述
本文提出对层叠支持向量机在支持向量选择时的方法优化,在每次迭代过程中,SVM训练结束后,计算训练集中各个样本到超平面的距离,得到距离d1,d2,…,dn,计算样本到分类超平面的距离,并将样本按照到超平面的距离升序排列。设定选择参数α,α∈(0,1),对升序排列后的样本,选择前α的样本作为支持向量,一方面作为下一级SVM训练过程的输入,另一方面在反馈调整环节,充分利用该样本集,对每次迭代过程中产生的SVM进行调整[17-18]。如α=0.1,则对排序后的样本选择10%作为支持向量。具体过程如图5所示。
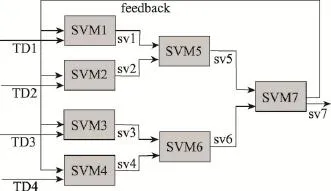
Fig.5 Process of cascade SVM algorithm图5 层叠支持向量机执行过程图
图5所述的短文本分类实例描述如下:
(1)短文本数据集TD被划分为4份,由4个计算节点根据本地训练数据集并行训练,每个计算节点产生一个超平面,即SVMi。
(2)每个计算节点,计算本地子训练集中的样本到超平面的距离,并将样本按距离升序排列,选择前α的样本作为本次计算过程产生的支持向量svi。如图6中上下两个实例,分别表示α=0.3及α=0.7时对应的支持向量。
(3)将步骤(2)产生的svi作为第二次迭代过程的训练集输入,并将数据重新组合分配,同理得到下一级子超平面及支持向量。
(4)重复上述步骤,直至训练出一个超平面SVM及对应的支持向量sv,并将生成的sv作为下一次优化调整的输入,判断一次分类过程的准确性。
(5)重复上述过程,直至产生的sv′与上一次产生的sv之间差集为空,或小于设定值。
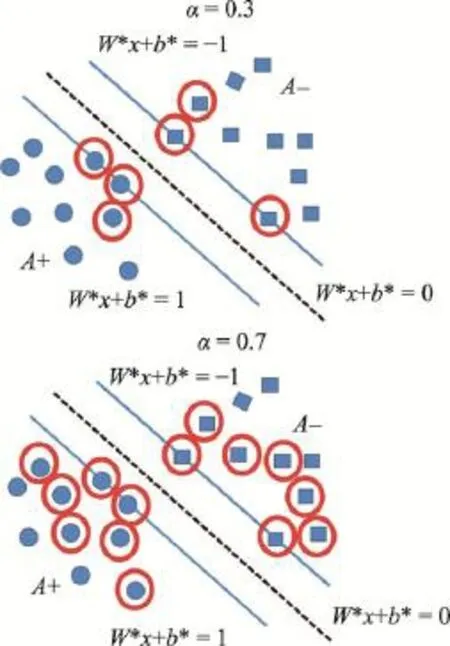
Fig.6 Example ofα-cascade-SVM图6 α-cascade-SVM示例图
3.2 伪代码
基于距离选择的层叠支持向量机以训练集、选择参数α和终止条件阈值β作为输入。
首先进行一次MapReduce产生一个超平面及支持向量:对数据集进行划分,训练出子SVMi,扫描训练集计算样本点与超平面的距离并排序,再以α为比例选择样本作为支持向量,合并后生成SVM及sv。
接下来进行判断,若sv′-sv>β,则重复第一步,通过多次迭代,最终生成SVM模型及支持向量。
4 Spark平台上特征扩展与分类实验
本文采用搜狗实验室提供的18个频道搜狐新闻数据集,包含国内、国际、体育、娱乐、社会等。数据集包括新闻标题及新闻内容,文本采用原新闻标题数据集作为短文本数据集,内容数据集为背景语料库数据集。分别采用37 KB,330 KB,3 MB,33 MB,330 MB,1.4 GB等6个大小不同的数据集进行实验。每个数据集中新闻标题短文本数据约占5%,背景语料数据约占95%。
实验在有6个集群节点的分布式计算平台Spark上进行,该Spark集群部署为Standalone模式,其中包括1个主节点和5个计算节点,每个节点配有4个物理核,内存为6.6GB。集群为Linux系统,配置Spark1.6.0,同时部署Hadoop2.6.0提供如HDFS等底层支持。
实验1不同关联规则挖掘算法效率对比。
使用上述6个背景语料数据集分别采用MR-Apriori和MR-FP-Growth算法进行基于关联规则挖掘的特征扩展,设置支持度为0.1,置信度为0.5,各算法执行时间如表1和图7所示。
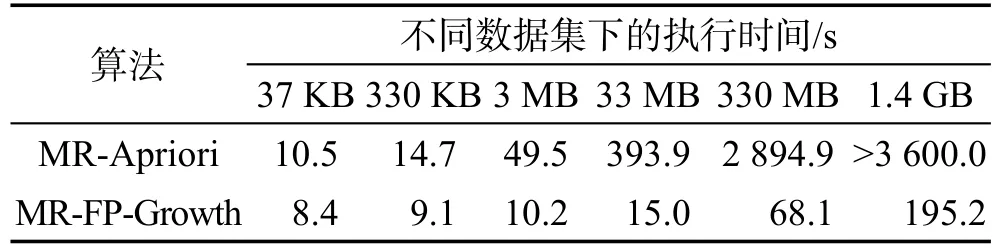
Table 1 Execution costs of MR-Apriori and MR-FP-Growth表1 MR-Apriori和MR-FP-Growth算法执行时间对比
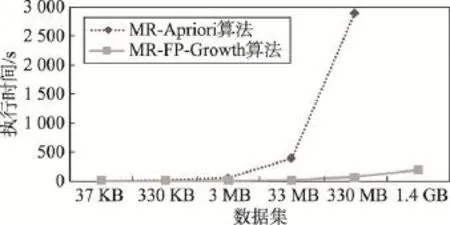
Fig.7 Execution costs of MR-Apriori and MR-FP-Growth图7MR-Apriori和MR-FP-Growth算法执行时间对比
图7中虚线表示不同数据集采用MR-Apriori算法进行特征扩展在Spark集群上的执行时间,实线表示不同数据集采用MR-FP-Growth算法在Spark集群上的执行时间。首先对比关联规则挖掘结果,每种数据集下,采用两种算法得到的扩展后的数据集相同。
由图7可知,当数据集较小时,采用两种算法进行特征扩展效果相当。当数据集较大(本实验中,超过3 MB)时,MR-Apriori算法执行耗时显著上升,MR-FP-Growth算法执行耗时增长较平缓。当数据集达到330 MB时,MR-Apriori算法执行时间为MRFP-Growth算法的42倍,且当数据集继续增大,达到1.4 GB时,Apriori执行过程中频繁发出内存不足的警告,算法执行时间超过1 h。
根据上述实验结果,选择MR-FP-Growth算法为本文特征扩展的基础算法,后续实验利用该算法,研究影响特征扩展效果的因素。
实验2参数α对实验结果的影响。
本实验中选择短文本数据集A,该数据集包含63 260条短文本新闻标题,以及18个分类标签。按照6∶4的比例,取37 956条数据作为训练集,25 304条作为测试集数据。首先进行改进前的层叠支持向量机算法实验,记录实验结果中支持向量数量、准确率及执行时间,实验结果记作E1。测试设置不同距离选择参数α={0.1,0.2,0.3,0.4,0.5,0.6},通过实验统计支持向量、准确率及执行时间,结果如表2所示。
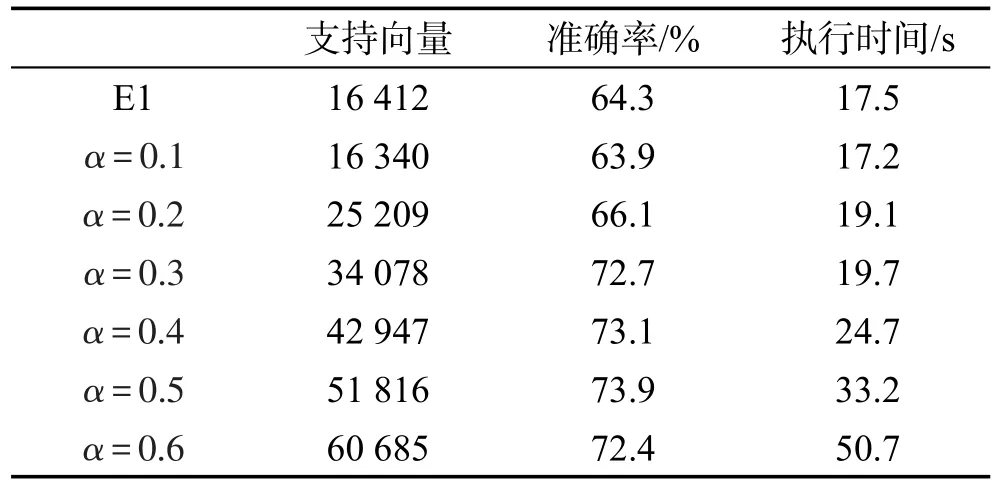
Table 2 Influence ofαto category results表2 参数α对实验结果影响统计表
实验结果采用组合图的形式描述,如图8所示。
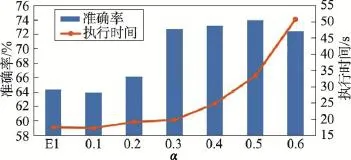
Fig.8 Influence ofαto accuracy and running time图8 参数α对准确率及执行时间影响统计图
图8中横坐标表示实验分组类别,柱形图表示不同参数α对应的分类准确率结果(对应左侧纵坐标),折线图表示不同参数α对应的分类执行时间(对应右侧纵坐标)。由表2可知,随着α值增加,支持向量数增加,准确率上升,执行时间上升。由图8可知,当α较小时,准确率及执行时间上升较明显,随着α增大,本实验中α>0.3时,准确率上升速度放缓,执行时间上升速度增加。
根据上述实验,综合考虑分类准确率及分类时间,针对该数据集选择α=0.3,使用最小的执行时间代价换相对较高的准确率提升。根据上述实验过程,分别对3.3节中的搜狗新闻数据集进行上述实验,通过调整参数α的值,统计不同参数下对应的支持向量数据、准确率及执行时间,并采用上述的对比方式,针对每一数据集,综合考虑参数α对分类准确率及执行时间的影响,选取性价比相对较高的参数α设置,各数据集及相对最优α值对应关系如表3所示。

Table 3 Relation ofαand data sets表3 数据集与参数α对应关系表
如表3所示,数据集大小为3 MB时,对应相对较优α值为0.4;数据集大小为33 MB时,对应相对较优α值为0.3;数据集为1.4GB时,对应相对较优α值为0.2。
实验3数据划分块数对特征扩展及分类的影响。
特征扩展及分类过程中,分别将数据分块,每个计算节点每个计算阶段处理其中几块子数据集。为验证参数n1、n2对整个短文本分类效率的影响,以上述330 MB数据为例,进行不同n1、n2设置的组合实验,实验结果如表4和图9所示。
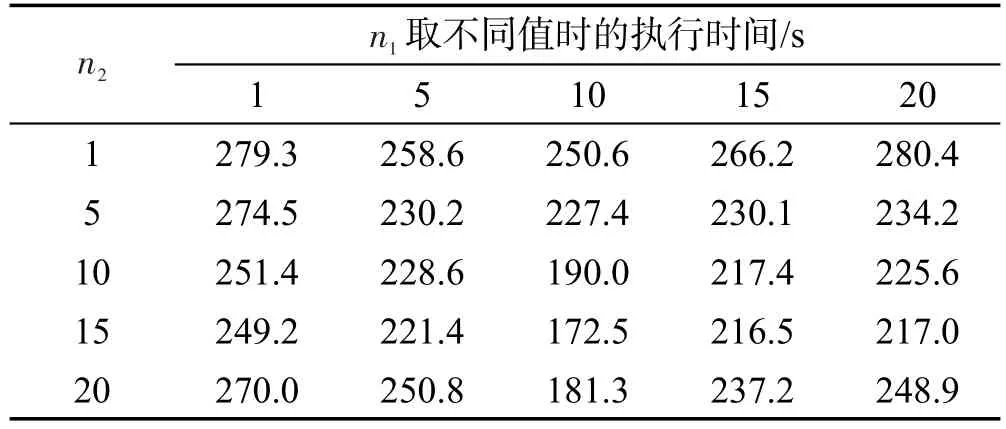
Table 4 Influence of cluster partitions to efficiency表4 集群数据分区数对分类效率的影响
图9中横坐标表示分类阶段参数n2,即分类过程中数据划分块数,每个n2值对应5个不同n1取值,由左至右分别表示n1为1、5、10、15、20。由图9可知,对330 MB数据集,特征扩展阶段分区数n1固定时,对不同参数n2,当n2=15时,整体分类效率最高;当固定分类阶段分区数量n2,调整特征扩展阶段分区数量n1时,对不同参数n1,当n1=10时,整体分类效率最高。即对330 MB数据集,当特征扩展阶段分区数为10,分类阶段分区数为15时,整体分类效率最高,相应分类时间为172.5 s,执行时间相比于分类效率最低时(280.4 s),约提升60%。
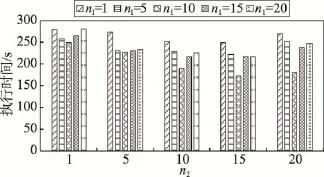
Fig.9 Influence of cluster partitions to efficiency图9 集群分区数对分类效率的影响
实验4特征扩展及分类优化对准确率的影响。
分别设计不进行特征扩展和分类优化(E1)、特征扩展后分类不优化(E2)及既特征扩展又分类优化(E3)的3组实验,每组实验针对不同数据集分别测试。实验结果如图10所示。
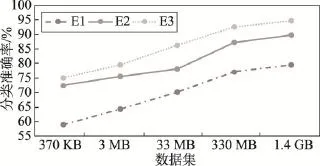
Fig.10 Accuracy comparison图10 分类准确率对比图
由图10可知,特征扩展及分类优化阶段均对分类准确率的提升发挥重要的作用,其中特征扩展约得到10.3%的准确率提升,分类优化约得到5.2%的准确率提升;当数据集较小时(本实验中小于33 MB),特征扩展对准确率提升作用较明显,随着短文本数据集的增加,特征扩展的准确率提升幅度相对下降。
实验5特征扩展及分类优化对效率的影响。
为验证本文提出的Spark平台上基于特征扩展的短文本分类方法的效率,将本文提出的特征扩展与分类优化方法与传统单机上短文本分类算法进行对比,统计各数据集下不同算法的执行效率,通过对比实验,分析本文提出的短文本分类方法的分类效率。实验结果统计如图11所示,E4表示单机数据,E5表示集群数据。
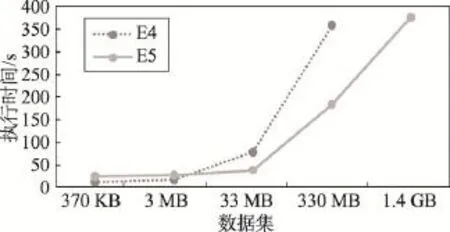
Fig.11 Efficiency comparison of cluster and local图11 单机与集群执行效率对比图
图11中虚线表示单机上采用传统cascade SVM算法进行短文本分类的执行时间,实线表示采用本文提出的Spark平台上的特征扩展并分类优化的短文本分类技术的执行时间。
由上述实验结果可知,当数据集较小时,本文提出的短文本分类方式执行效率低于传统短文本分类方法执行效率,随着数据集增大,E5增长相对较缓慢,当数据集达到1.4 GB时,传统分类方法分类时间超过半小时,本文提出的短文本分类方法约需要376.2 s,分类效率约为传统单机上短文本分类算法的4倍。该实验验证了本文提出的分类方法在面向大数据集分类时,在吞吐能力和分类效率上的有效性。
5 总结
本文在特征扩展阶段,将关联规则挖掘阶段产生的项扩充到原短文本时,采用置信度与原短文本特征值直接相乘的方法,该方法相比于传统使用支持向量机算法进行短文本分类的方法,在分类准确率及分类效率上均得到较好的提升。但实验过程中,对特征扩展过程中新特征权重计算方式缺乏对比,后期针对该问题,继续设计可行的平滑公式,对扩展后的特征计算方式进行优化。其次,本文分类实验过程中,集群环境中算法运行效率相对单机环境虽然相对较高,但从加速比看,加速效果还有提升的空间,目前尚未达到线性加速比,后期针对该问题继续寻找优化与改进的空间。
[1]Weibo white paper on consumer in 2015[EB/OL].[2016-06-12].http://data.weibo.com/report/reportDetail?id=318.
[2]Ning Yahui,Fan Xinghua,Wu Yu.Short text classification based on domain word ontology[J].Computer Science,2009, 36(3):142-145.
[3]Fan Yunjie,Liu Huailiang.Research on Chinese short text classification based on Wikipedia[J].New Technology of Library&Information Service,2012,28(3):47-52.
[4]Liu Jinling,Yan Yunyang.SMS text classification method based on context[J].Computer Engineering,2011,37(10): 41-43.
[5]He Hui,Chen Bo,Xu Weiran,et al.Short text feature extraction and clustering for Web topic mining[C]//Proceedings of the 3rd International Conference on Semantics,Knowledge and Grid,Xi'an,China,Oct 29-31,2007.Washington: IEEE Computer Society,2007:382-385.
[6]Wang Zuli.An improved method of short text feature extraction based on words co-occurrence[C]//Proceedings of the 2nd International Conference on Electric Technology and Civil Engineering,Wuhan,China,May 18-20,2012.Washington:IEEE Computer Society,2012:266-269.
[7]Phan X H,Nguyen L M,Horiguchi S.Learning to classify short and sparse text&Web with hidden topics from largescale data collections[C]//Proceedings of the 17th International Conference on World Wide Web,Beijing,Apr 21-25, 2008.New York:ACM,2008:91-100.
[8]Chen Mengen,Jin Xiaoming,Shen Dou.Short text classification improved by learning multi-granularity topics[C]// Proceedings of the 22nd International Joint Conference on Artificial Intelligence,Barcelona,Spain,Jul 16-22,2011. Menlo Park,USA:AAAI,2011:1776-1781.
[9]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. The Journal of Machine Learning Research,2003,3:993-1022.
[10]Vo D T,Ock C Y.Learning to classify short text from scientific documents using topic models with various types of knowledge[J].Expert Systems with Applications,2015,42 (3):1684-1698.
[11]Hu Yongjun,Jiang Jiaxin,Chang Huiyou.A new method of keywords extraction for Chinese short-text classification[J]. New Technology of Library and Information Service,2013, 29(6):42-48.
[12]Zhang Zhifei,Miao Duoqian,Gao Can.Short text classification using latent Dirichlet allocation[J].Journal of Computer Applications,2013,33(6):1587-1590.
[13]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[C]//Proceedings of the 6th Conference onSymposium on Operating Systems Design and Implementation,San Francisco,USA,Dec 6-8,2004.Berkeley,USA: USENIXAssociation,2004:107-113.
[14]Keerthi S S,Shevade S K,Bhattacharyya C,et al.Improvements to Platt's SMO algorithm for SVM classifier design [J].Neural Computation,2006,13(3):637-649.
[15]Platt J C.Fast training of support vector machines using sequential minimal optimization[M]//Advances in Kernel Methods.Cambridge,USA:MIT Press,1999:185-208.
[16]Song Ge,Ye Yunming,Du Xiaolin,et al.Short text classification:a survey[J].Journal of Multimedia,2014,9(5):635-643.
[17]Li Haoyuan,Wang Yi,Zhang Dong,et al.PFP:parallel FP-growth for query recommendation[C]//Proceedings of the 2008 ACM Conference on Recommender Systems,Lousanne,Switzerland,Oct 23-25,2008.New York:ACM,2008: 107-114.
[18]Joachims T.Making large-scale support vector machine learning practical[M]//Advances in Kernel Methods.Cambridge, USA:MIT Press,1999:169-184.
附中文参考文献:
[1]新浪微博数据中心.2015微博消费者白皮书[EB/OL].[2016-06-12].http://data.weibo.com/report/reportDetail?id=318.
[2]宁亚辉,樊兴华,吴渝.基于领域词语本体的短文本分类[J].计算机科学,2009,36(3):142-145.
[3]范云杰,刘怀亮.基于维基百科的中文短文本分类研究[J].现代图书情报技术,2012,28(3):47-52.
[4]刘金岭,严云洋.基于上下文的短信文本分类方法[J].计算机工程,2011,37(10):41-43.
[11]胡勇军,江嘉欣,常会友.基于LDA高频词扩展的中文短文本分类[J].现代图书情报技术,2013,29(6):42-48.
[12]张志飞,苗夺谦,高灿.基于LDA主题模型的短文本分类方法[J].计算机应用,2013,33(6):1587-1590.

WANG Wen was born in 1992.She is an M.S.candidate at School of Information,Renmin University of China. Her research interests include text mining and parallel data processing.
王雯(1992—),女,山东邹市人,中国人民大学信息学院硕士研究生,主要研究领域为文本挖掘,并行数据处理。

ZHAO Kankan was born in 1991.He is a Ph.D.candidate at School of Information,Renmin University of China. His research interests include recommender system,data fusion and big data analysis.
赵衎衎(1991—),男,陕西渭南人,中国人民大学信息学院博士研究生,主要研究领域为推荐系统,数据融合,大数据分析。

LI Cuiping was born in 1971.She is a professor at School of Information,Renmin University of China.Her research interests include database technology,data mining,social network analysis and social recommendation.
李翠平(1971—),女,博士,中国人民大学信息学院教授,主要研究领域为数据库技术,数据挖掘,社交网络分析,社会推荐。

CHEN Hong was born in 1965.She is a professor at School of Information,Renmin University of China.Her research interests include database technology and hardware based high performance computing.
陈红(1965—),女,博士,中国人民大学信息学院教授,主要研究领域为数据库技术,新硬件平台下的高性能计算。

SUN Hui was born in 1977.She is a lecturer at School of Information,Renmin University of China with a Ph.D.degree in Tsinghua University.Her research interests include data mining and high-performance database.
孙辉(1977—),女,博士,中国人民大学信息学院讲师,主要研究领域为数据挖掘,高性能数据库。
Feature Extension and Category Research for Short Text Based on Spark Platform*
WANG Wen1,2,ZHAO Kankan1,2,LI Cuiping1,2+,CHEN Hong1,2,SUN Hui1,2
1.Key Laboratory of Data Engineering and Knowledge Engineering,Renmin University of China,Beijing 100872, China
2.School of Information,Renmin University of China,Beijing 100872,China
+Corresponding author:E-mail:licuiping@ruc.edu.cn
WANG Wen,ZHAO Kankan,LI Cuiping,et al.Feature extension and category research for short text based on spark platform.Journal of Frontiers of Computer Science and Technology,2017,11(5):732-741.
Short text classification is often confronted with some limitations including high feature dimensions, sparse feature existences and poor classification accuracy,which can be solved by feature extension effectively. However,it decreases the execution efficiency greatly.To improve classification accuracy and efficiency of short text,this paper proposes a new solution,association rule based feature extension method which is designed on Spark platform.Given a background data set of short text corpus,firstly extend origin corpus and complement the features by mining the association rules and the corresponding confidences.Then apply a new cascade SVM(support vector machine)algorithm based on distance to choose during classification.Finally design the feature extension and classification algorithm of short text on Spark platform and improve the efficiency of short text processing through distributed algorithm.The experiments show that the new method gains 4 times of efficiency improvement compared with the traditional method and 15%increase in classification accuracy,in which the accuracy of feature extension and classification optimization is 10%and 5%respectively.
short text classification;feature extension;association rule;Spark platform
10.3778/j.issn.1673-9418.1608041
A
:TP391
*The National Social Science Foundation of China under Grant No.12&ZD220(国家社会科学基金).
Received 2016-08,Accepted 2016-10.
CNKI网络优先出版:2016-10-31,http://www.cnki.net/kcms/detail/11.5602.TP.20161031.1650.010.html
摘 要:短文本分类经常面临特征维度高、特征稀疏、分类准确率差的问题。特征扩展是解决上述问题的有效方法,但却面临更大的短文本分类效率瓶颈。结合以上问题和现状,针对如何提升短文本分类准确率及效率进行了详细研究,提出了一种Spark平台上的基于关联规则挖掘的短文本特征扩展及分类方法。该方法首先采用背景语料库,通过关联规则挖掘的方式对原短文本进行特征补充;其次针对分类过程,提出基于距离选择的层叠支持向量机(support vector machine,SVM)算法;最后设计Spark平台上的短文本特征扩展与分类算法,通过分布式算法设计,提高短文本处理的效率。实验结果显示,采用提出的Spark平台上基于关联规则挖掘的短文本特征扩展方法后,针对大数据集,Spark集群上短文本特征扩展及分类效率约为传统单机上效率的4倍,且相比于传统分类实验,平均得到约15%的效率提升,其中特征扩展及分类优化准确率提升分别为10%与5%。
