深度学习在缺陷修复者推荐中的应用*
2017-06-05王千祥
胡 星,王千祥
北京大学 高可信软件技术教育部重点实验室,北京 100871
深度学习在缺陷修复者推荐中的应用*
胡 星,王千祥+
北京大学 高可信软件技术教育部重点实验室,北京 100871
目前许多软件项目使用缺陷追踪系统来自动化管理用户或者开发人员提交的缺陷报告。随着缺陷报告和开发人员数量的增长,如何快速将缺陷报告分配给合适的缺陷修复者正在成为缺陷快速解决的一个重要问题。分别使用长短期记忆模型和卷积神经网络两种深度学习方法来构建缺陷修复者推荐模型。该模型能够有效地学习缺陷报告的特征,并且根据该特征推荐合适的修复者。通过与传统机器学习方法(如贝叶斯方法和支持向量机方法)进行对比,该方法可以比较有效地在众多开发者中找出合适的缺陷修复者。
缺陷追踪;缺陷报告分配;深度学习
1 引言
目前的许多软件项目利用缺陷追踪系统来自动化或半自动化地管理和维护项目过程产生的缺陷报告。常见的缺陷追踪系统有Bugzilla、JIRA等。人们利用这些缺陷追踪系统进行软件缺陷的提交、记录、管理和追踪等。
用户或者开发人员通过提交缺陷报告来反映软件存在的问题。开发人员则根据这些缺陷报告来进一步完善软件,提高软件的质量。但是缺陷报告的解决需要显著的开销[1],尤其是当一个缺陷报告被提交后,管理员要花费一定时间去审核该报告是一个缺陷,还是一个值得考虑的新的需求,并且检查这个报告是否是一个重复的缺陷报告,确认之后,再为该报告寻找合适的修复人员。
为了降低缺陷修复分配负担,已经有许多针对软件缺陷修复者推荐的研究工作,例如利用机器学习的方法推荐缺陷修复者[2-3]。本文提出了利用深度学习的方法来自动推荐缺陷修复者。通过对大量已经分配缺陷修复者的缺陷报告进行学习,本文构造的模型可以提取缺陷修复者所修复缺陷的特征,从而为新提交的缺陷报告推荐合适的缺陷修复者。
本文分别利用长短期记忆模型(long-short term memory,LSTM)、卷积神经网络(convolutional neural network,CNN)两种深度学习方法对Eclipse项目的缺陷报告分别进行训练,并对得到的模型进行验证。结果表明,本文所提出的方法最高准确率分别为58.2%、60.3%,比传统的机器学习方法如贝叶斯方法和支持向量机(support vector machine,SVM)方法都有较大的提高。
本文组织结构如下:第2章介绍与本文相关的研究工作;第3章主要研究缺陷报告的相关内容,以及所用到的深度学习方法;第4章讨论本文构造的模型;第5章通过实验对本文提出的方法进行评估;第6章总结全文。
2 相关工作
自动化地为软件缺陷推荐修复者可以大幅度减少相关人员的工作量。目前已经有许多研究者针对软件缺陷修复者推荐展开了研究。
机器学习[4]是人工智能领域最能体现智能的一个分支。许多研究者利用机器学习的方法(例如贝叶斯方法和支持向量机方法)来进行缺陷修复者推荐。Čubranić将贝叶斯方法用于缺陷报告修复者推荐[2],利用贝叶斯分类法可以有效地进行多分类任务,其准确率在推荐Eclipse缺陷修复者时最高可以达到30%。支持向量机方法在文本分类任务中显示出卓越的性能,很快成为机器学习的主流技术。Anvik等人提出利用支持向量机方法来进行缺陷修复者推荐[3],其准确率最高为57%,相比贝叶斯方法提高了27%。这些机器学习方法通过对缺陷描述的文本进行处理,将文本转化为词袋形式,再采用机器学习相关方法进行缺陷修复者推荐。
除此之外,文献[5]分析了Mozilla和Eclipse开源社区上的缺陷修复者重复现象,通过建立修复者关系重置图来提高推荐缺陷修复者的准确率。
随着深度学习的发展,许多研究者将深度学习用于文本分类。Kim[6]在2014年提出用CNN来进行文本分类。该方法采用的网络结构非常简单,但取得了较好的效果。Zhou等人[7]提出利用LSTM方法进行文本分类。本文将缺陷报告看成一种特殊的文本,分别借鉴了Zhou和Kim的工作,将CNN和LSTM方法用于推荐缺陷报告修复者。
3 背景
3.1 缺陷报告
缺陷追踪系统中的缺陷报告按照一定的格式组织,极大地方便了开源软件的自动化管理和维护。图1为Eclipse项目的一个缺陷报告,Eclipse采用Bugzilla作为其缺陷追踪系统。当一个缺陷报告被创建时,其缺陷报告编号、报告者、创建时间等将会自动生成,报告者可以根据自己的缺陷报告选择产生该缺陷的产品或组件,不仅如此,用户还可以指出其使用的操作系统、版本,缺陷的具体描述等。项目开发者和用户以添加评论的方式来对缺陷进行讨论,寻找合适的缺陷解决方法。缺陷报告的其他部分如状态、分配的修复者等会随着时间发生变化,其变化与缺陷报告在其生存周期所处的阶段有关。
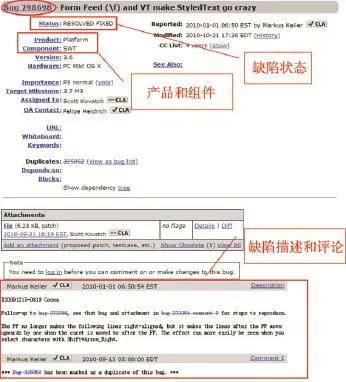
Fig.1 Asample of bug report from Eclipse图1 Eclipse缺陷报告例子
对于一个状态为“新建”的缺陷,缺陷追踪系统相应项目管理员会将这个缺陷指派给合适的开发人员,通知其进行修复,然后将这个缺陷报告的状态修改为“已指派”(ASSIGNED)。开发人员修复指派给自己的缺陷或主动修改缺陷,并将缺陷状态改为“已处理”(RESOLVED)。之后管理员对修复后的缺陷进行测试验证,如果缺陷确实被修复,则将缺陷状态改为“已确认”(VERIFIED),然后这个缺陷被关闭,状态最终变为“已关闭”(CLOSED)。
并不是所有的缺陷都会被修复,可能的处理方式还有重复的、不合法的、不可重现的以及无法修复等。对于这样的缺陷,当开发人员产生处理方案(RESOLUTION)后(如DUPLICATE、INVALID、WONTFIX等),缺陷状态变为“已处理”(RESOLVED)。当然,一个缺陷报告被关闭之后,还可能因为很多原因再次打开,状态变为“再次打开”(REOPEN),再次开启生命周期。一个缺陷报告的生命周期如图2所示,其中灰色部分为根据缺陷报告的内容给出的解决方案。
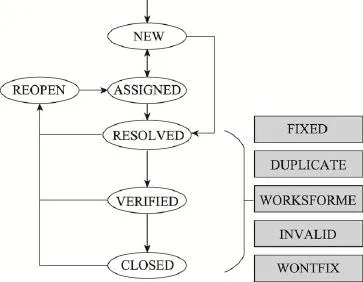
Fig.2 Life-cycle of a bug report图2 缺陷报告生命周期
3.2 深度学习
随着云计算与大数据时代的到来,计算能力得到大幅度提高,训练数据收集更加方便。这大大缓解了传统训练的低效性,降低了过拟合的风险。以“深度学习”为代表的复杂计算模型开始受到人们的关注。深度学习是机器学习研究中的一个新的领域,多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类[8]。
3.2.1 LSTM
LSTM模型是RNN[9]的一个变种,循环神经网络相对于传统的前馈神经网络,其特点是可以存在有向环,将上次的输出作为本次的输入[10]。但是原生的RNN存在一定的问题,即后面时间节点对于前面时间节点感知力下降。LSTM克服了这一缺点,可以学习长期依赖信息,近期经过Graves等人[11]进行改良和推广后,开始得到广泛的应用。
基本的LSTM单元结构如图3所示。LSTM模型中,其核心就是细胞(cell)的状态。传统的RNN神经元和一般神经网络的感知机没什么区别,而LSTM中,每个神经元是一个“记忆细胞”,细胞里有一个“输入门”、一个“遗忘门”和一个“输出门”。在“输入门”中,根据当前的数据流来控制接受细胞记忆的影响;接着,在“遗忘门”中更新该细胞的记忆和数据流;然后,在“输出门”中产生输出更新后的记忆和数据流。LSTM模型的关键就在于“遗忘门”,它可以控制训练时梯度在这里的收敛性,同时也可以保持长期的记忆性。
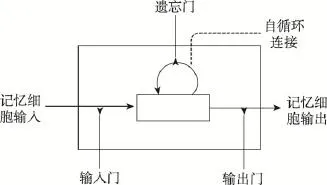
Fig.3 Structure of LSTM cell图3 LSTM细胞结构图
3.2.2 卷积神经网络
卷积神经网络[6]是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点。
卷积神经网络复合多个“卷积层”和“采样层”对输入信号进行加工,然后在连接层实现与输出目标之间的映射。每个卷积层都包括多个特征映射(feature map),每个特征映射是一个由多个神经元构成的“平面”,通过一种卷积滤波器提取输入的一种特征。
在文献[6]中,利用卷积神经网络来进行文本分类取得了很大进展。其网络结构非常简单,但取得了很好的效果。
鉴于卷积神经网络可以很好地提取输入数据的特征,本文将卷积神经网络用于软件缺陷修复者推荐,利用卷积神经网络来提取软件缺陷报告的特征,通过分析软件缺陷与修复者之间的联系,来给未分配缺陷推荐适合的缺陷修复者。
59例受调查者在初次问卷调查时均不认为肾脏病患病率与高血压、糖尿病相近;再次问卷调查时,23例(39.0%)认为肾脏病患病率与高血压、糖尿病相近,其中,讲座组中认同者多于其他两组(P<0.01)。
本文将缺陷报告信息看成是一种文本,因此将缺陷推荐修复者问题转化为文本分类问题。利用卷积神经网络可以很好地提取文本特征,通过训练提取缺陷特征,从而匹配相应的缺陷修复者。
4 方法
4.1 数据获取与预处理
本文选取Eclipse项目已解决的缺陷报告,在获取数据时,采用Scrapy爬虫框架,获得的数据以json格式存储。
本文在获取数据时选取分类标识符为“Eclipse”的缺陷报告,并且筛选出报告提交日期为2010年之后的缺陷报告。为了最大程度地获得有缺陷修复者的缺陷报告,在筛选时还限定了处理方案,只抽取处理方案为“FIXED”的缺陷报告。通过分析发现,Eclipse项目中,assigned-to字段中的缺陷修复者并不完全是真实的开发人员,而是有些缺陷分配给了默认的邮箱,例如“ProjectInbox”,因此为了减少这种情况的影响,在获取数据时过滤了这种情况。对于每个缺陷报告,获取“title”、“description”、“product”、“component”、“assigned-to”这5个字段的内容,其表示含义如表1所示。

Table 1 Meaning of data field表1 数据字段表示含义
通过定义这些抽取规则,共获得12 316条缺陷报告,缺陷修复者有208人。
另外,在对开发人员进行分析时发现,有些开发人员在近几年内所修复的缺陷数目较少,可能原因是该开发人员近几年在该项目中并不活跃。对于这种情况,将缺陷分配给这些开发人员并不是一个明智的选择,因此过滤了解决缺陷个数不足50个的开发人员。最终共获取到11 211条缺陷报告,缺陷修复者有51人。
4.2 数据处理
本文利用深度学习方法来学习“title”、“description”、“product”、“component”这4个字段的内容,从而提取缺陷报告的特征。通过观察分析,发现在Eclipse项目中,一个开发人员所负责的缺陷大多属于一个产品和组件。不仅如此,一个缺陷报告的标题高度概括了该缺陷的特征,而缺陷的描述是对这些特征进行展开分析。基于此,将文本进行了权重处理:
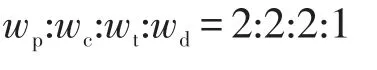
公式中的变量wp、wc、wt、wd分别表示Eclipse项目缺陷报告产品(product)、组件(component)、标题(title)和描述(description)的权重。
通过观察缺陷报告的文本,发现缺陷报告中有许多术语是缩写词,例如“API”,“SWT”等。这些词在进行文本处理时,会被认为是非英文单词而被过滤掉。然而这些缩写词往往是描述缺陷的关键,对于缺陷报告的分配结果非常重要。因此,本文将缺陷报告中常见的缩写词进行替换,例如:

在缺陷报告的描述中,有许多用户和开发人员提供了出现缺陷的程序方法。如图4,在缺陷报告(缺陷编号为299631)的描述中,开发人员提出了恢复方法“org.eclipse.jdt.internal.corext.refactoring.reorg. JavaMoveProcessor.canUpdateReferences()”这一需求。普通的文本处理无法对方法名进行处理,这样导致缺陷的部分特征丢失。针对这一现象,本文对缺陷报告中出现的方法名进行切割,利用切割后的单词来最大程度地反映方法所表示的含义。首先以方法名中的“.”作为切割符,得到预处理的方法名集合;之后分别对集合中的元素进行处理,利用正则表达式以大写字母作为单词之间的界限进行分割;最后处理过后的结果为“[org”,“eclipse”,“jdt”,“internal”,“corext”,“refactoring”,“reorg”,“Java”,“Move”,“Processor”,“can”,“Update”,“References”]。
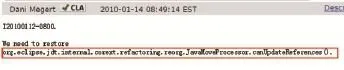
Fig.4 Bug description with function图4 含方法的缺陷描述
除此之外,还对缺陷报告中的文本做了其他一些处理。将所有字母改成小写;缺陷报告中有许多描述包含html字符,然而这些字符并不是描述缺陷的关键,因此将文本中的html字符去掉;依次进行分句和分词的操作;分词操作之后,将非英文单词、停用词过滤掉,并且利用正则匹配去除标点符号;对单词进行词型转换,例如将does、did统一转化为do。
此时得到的单词序列还不能直接用于训练,需要将词转化为向量。本文利用word2vec[12-13]工具将缺陷报告的信息转化为向量。利用word2vec对缺陷报告进行训练,可以把对文本内容的处理简化为k维向量空间中的向量运算,本文将单词转为100维的向量进行处理。而向量空间上的相似度可以用来表示文本语义上的相似度。例如:“Paris”为“France”的首都,“Rome”为“Italy”的首都,因此“Paris”和“France”的向量距离与“Rome”和“Italy”的向量距离很相近。利用word2vec工具经过训练,根据“Paris”、“France”、“Italy”的向量,可以得到“Rome”的词向量表示。同样的对于“king”、“man”、“queen”和“women”,已知其中3个词的向量,通过word2vec训练可以得到另一个词的向量。
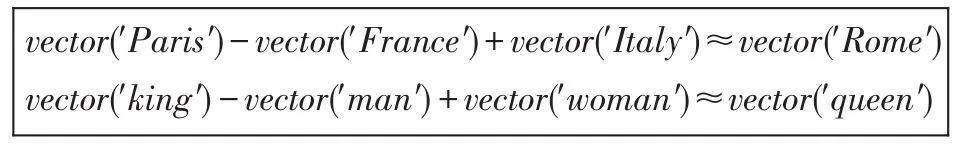
4.3 缺陷修复者预测模型
本文利用深度学习方法训练缺陷修复者推荐模型。该模型的流程如图5所示。收集到的数据经过4.2节的处理后,将缺陷报告生成深度学习模型可以识别的数据集。缺陷向量和其对应的修复者<bugVec, assignee>组成了用于训练的数据集合。其中bugVec是由4.1节训练的词向量组成的句向量,assignee表示这个缺陷报告所分配的缺陷修复者。数据集随后被分为不相交的两个集合,一部分用于训练,另一部分用于验证所构造的模型。通过训练得到的模型可以提取未分配缺陷修复者的缺陷报告的特征,并根据这些特征为缺陷报告推荐合适的修复者。
本文分别利用LSTM和CNN两种方法来对训练集进行训练,并对得到的模型进行验证分析。下面详细介绍如何利用LSTM和CNN方法进行模型训练。
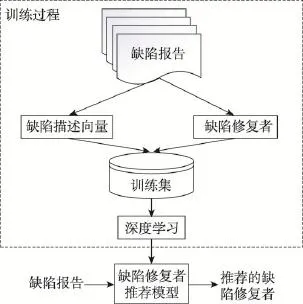
Fig.5 Overall workflow of bug report assignment recommendation图5 缺陷修复者推荐模型流程图
4.3.1 基于LSTM的训练模型
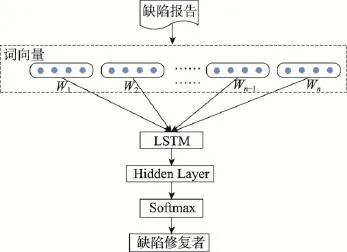
Fig.6 Structure of LSTM training model图6 LSTM训练模型结构
本文使用最经典的LSTM模型[14]来对缺陷报告进行训练。具体训练模型如图6所示。缺陷报告以词向量组成的句向量形式输入到网络中,经过3.2.1节介绍的LSTM模型加工后与一个全连接的隐藏层相连接。该隐藏层的神经元个数与数据集中的缺陷修复者个数相等。经过模型的训练,得到100个缺陷特征用于缺陷修复者推荐。本文采用Softmax回归(http://ufldl.stanford.edu/tutorial/supervised/Softmax-Regression/)作为训练模型的分类器,Softmax分类器在多分类问题上十分有效。
在训练过程中利用随机梯度下降(stochastic gradient descent,SGD)算法[15]来自动调节学习速度。在训练过程中选择缺陷报告最频繁出现的前20 000个单词。在训练过程中还引入了Dropout策略,在每次迭代中随机放弃一部分训练好的参数。通过这种方法,可以防止过拟合现象的产生。
4.3.2 基于CNN的训练模型
本文借鉴了Kim在句子分类时所用到的卷积神经网络[6],整个网络结构如图7所示。
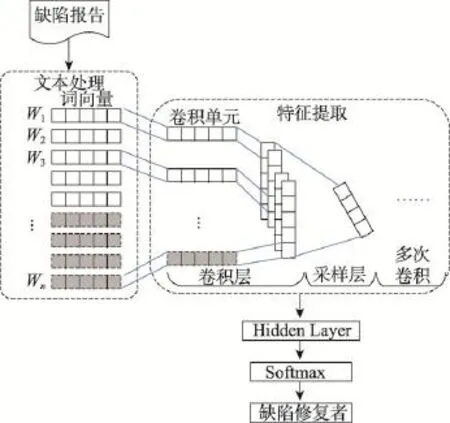
Fig.7 Structure of CNN training model图7 CNN训练模型结构
在进行训练之前,先对句子进行Embedding处理,将文本转为向量。输入层是句子中单词所对应的词向量组成的矩阵。在本文的模型中,句子输入按照最长的处理,不足的部分进行补0处理(例如图中灰色部分)。假设最长的句子有n个单词,每个单词对应的词向量维度为k,则输入的矩阵为n×k。
输入层通过卷积操作得到若干个特征图。卷积单元也是k维,因此特征图的列数为1维;之后采样层采用Max-Pooling的方法,重复上述卷积和采样过程,搭建多层网络。经过特征学习,提取出缺陷的128个特征,利用这些特征进行缺陷修复者的推荐。与LSTM模型类似,模型的采样层输出通过全连接的方式连接一个Softmax的分类层,使用SGD来调节训练速度,并且也使用Dropout策略防止过拟合现象的产生。
文本使用ReLU(rectified linear units)作为神经元的激活函数,ReLU在训练深度结构模型时,不易趋于饱和态,从而加快了训练的收敛速度。同时ReLU还能生成稀疏的激活输出向量,从而有效地减少计算开销。
5 方法评估
对于LSTM、CNN两种深度学习方法构造出来的两个模型,本文利用Eclipse的缺陷报告的训练集分别进行训练,得到两个缺陷报告修复者推荐模型,然后利用测试集分别进行准确率验证。
本文通过随机划分不同的训练集来进行缺陷报告的训练学习,并通过不同的测试集来进行验证。结果如图8所示:对于不同大小的训练集,LSTM、CNN方法最高准确率分别为58.6%和62.4%。随着训练集的增长,两种深度学习方法准确率总体上都是呈上升趋势。因为随着数据的增多,深度学习方法能从这些数据中学到的特征越多,进而能更加准确地推荐缺陷的修复者。
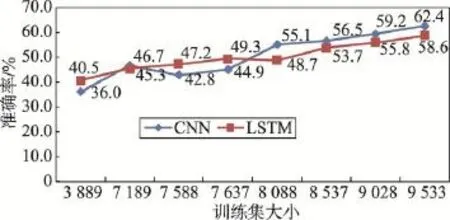
Fig.8 Precision of LSTM model and CNN model图8 LSTM和CNN模型的准确率
从图8中可以看出,LSTM在训练集大小为7 000~ 8 000这个阶段时,效果要优于CNN方法,因为LSTM更擅长处理序列数据,缺陷报告的文本具有一定的上下文语义,所以LSTM在训练集较少时有较好的效果。然而,随着训练集越来越多,CNN方法准确率的增长速度更快。因为CNN在学习文本特征方面要优于LSTM方法,CNN方法可以在大批量的数据训练中学到更多的缺陷特征,进而推荐合适的缺陷修复者。
对比参考文献的结果,贝叶斯方法[1]和支持向量机[3]方法在Eclipse项目上的准确率最高为30%、57%。可以发现,利用深度学习方法比传统的机器学习方法可以更加有效地为缺陷报告推荐缺陷修复者。这是因为利用深度学习方法可以自动地学习缺陷报告的特征,缺陷报告经过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,可以有效地推荐缺陷修复者。
6 总结
本文通过利用深度学习方法,分别使用LSTM和CNN模型对Eclipse项目缺陷进行训练学习,并进行缺陷修复者推荐,其准确率比传统机器学习方法如贝叶斯分类法和支持向量机方法都有较大的提高。因为利用深度学习方法,可以更好地学习修复缺陷的特征,从而为新提交的缺陷报告分配合适的修复者。
另外,本文仅考虑了对已分配缺陷修复者的缺陷报告进行训练学习,然后给缺陷报告推荐适合的缺陷修复者。如果进一步对缺陷之间的关系进行分析,会进一步提高推荐缺陷修复者的准确率。
[1]Kim S,Whitehead E J.How long did it take to fix bugs?[C]// Proceedings of the 2006 International Workshop on Mining Software Repositories,Shanghai,May 22-23,2006.New York:ACM,2006:173-174.
[2]Čubranić D.Automatic bug triage using text categorization [C]//Proceedings of the 16th International Conference on Software Engineering&Knowledge Engineering,Banff, Canada,Jun20-24,2004.Red Hook,USA:Curran Associates,2004:92-97.
[3]Anvik J,Hiew L,Murphy G C.Who should fix this bug?[C]//Proceedings of the 28th International Conference on Software Engineering,Shanghai,May 20-28,2006.New York: ACM,2006:361-370.
[4]Joachims T.A statistical learning model of text classification with support vector machines[C]//Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New Orleans,USA,Sep 9-13,2001.NewYork:ACM,2001:128-136.
[5]Jeong G,Kim S,Zimmermann T.Improving bug triage with bug tossing graphs[C]//Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering,Amsterdam,Aug 24-28,2009.New York:ACM,2009:111-120.
[6]Kim Y.Convolutional neural networks for sentence classification[J].arXiv:1408.5882v2,2014.
[7]Zhou Chunting,Sun Chonglin,Liu Zhiyuan,et al.A C-LSTM neural network for text classification[J].arXiv:1511. 08630,2015.
[8]Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7): 1527-1554.
[9]Graves A.Supervised sequence labelling with recurrent neural networks[M]//Studies in Computational Intelligence.Berlin,Heidelberg:Springer,2012:385.
[10]D'Informatique D E,Ese N,Esent P,et al.Long short-term memory in recurrent neural networks[J].EPFL,2001,9(8): 1735-1780.
[11]Graves A,Eck D,Beringer N,et al.Biologically plausible speech recognition with LSTM neural nets[C]//LNCS 3141: Proceedings of the 1st International Workshopon Biologically Inspired Approaches to Advanced Information Technology,Lausanne,Switzerland,Jan 29-30,2004.Berlin, Heidelberg:Springer,2004:127-136.
[12]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv:1301.3781, 2013.
[13]Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]// Proceedings of the 27th Annual Conference on Neural Information Processing Systems,Lake Tahoe,USA,Dec 5-8, 2013:3111-3119.
[14]Hochreiter S,Schmidhuber J.Long short-term memory[J]. Neural Computation,1997,9(8):1735-1780.
[15]Bottou L.Large-scale machine learning with stochastic gradient descent[C]//Proceedings of the 19th International Conference on Computational Statistics,Paris,Aug 22-27,2010. Berlin,Heidelberg:Springer,2010:177-186.

HU Xing was born in 1993.She is a Ph.D.candidate at Peking University.Her research interest is software engineering.
胡星(1993—),女,北京大学博士研究生,主要研究领域为软件工程。

WANG Qianxiang was born in 1970.He is a professor at Peking University.His research interests include software engineering and system software,etc.
王千祥(1970—),男,博士,北京大学教授,主要研究领域为软件工程,系统软件等。
Application of Deep Learning in Recommendation of Bug ReportsAssignment*
HU Xing,WANG Qianxiang+
Key Lab of High Confidence Software Technologies(Peking University),Ministry of Education,Beijing 100871, China
+Corresponding author:E-mail:wqx@pku.edu.cn
HU Xing,WANG Qianxiang.Application of deep learning in recommendation of bug reports assignment. Journal of Frontiers of Computer Science and Technology,2017,11(5):700-707.
Open source projects typically support an open bug repository to which developers and users can report bugs.As the increase in bug reports and developers,it is a challenge to assign large amounts of bug reports effectively to the appropriate developers.This paper applies two deep learning approaches,long-short term memory and convolutional neural network,to learn the features of bug reports and then makes assignments.Deep learning approaches are expert in learning features and making assignments effectively with the help of features.Compared to the traditional machine learning approaches such as Bayesian learning and support vector machine,the proposed approach can assign bug reports to developers effectively.
issue tracking;bug report assignment;deep learning
10.3778/j.issn.1673-9418.1609033
A
:TP311.5
*The National Natural Science Foundation of China under Grant Nos.61672045,61421091(国家自然科学基金);the National Basic Research Program of China under Grant No.2015CB352201(国家重点基础研究发展计划(973计划)).
Received 2016-08,Accepted 2016-10.
CNKI网络优先出版:2016-10-31,http://www.cnki.net/kcms/detail/11.5602.TP.20161031.1652.028.html
