可见-近红外高光谱图像技术快速鉴别激光打印墨粉
2017-06-01刘猛,申思*,王楠
刘 猛, 申 思*, 王 楠
(1. 文件检验鉴定公安部重点实验室(中国刑警学院), 辽宁 沈阳 100035;2. 浙江警察学院 刑事科学技术系, 浙江 杭州 310053; 3. 司法部司法鉴定科学技术研究所, 上海 200063)
可见-近红外高光谱图像技术快速鉴别激光打印墨粉
刘 猛1,2, 申 思1,2*, 王 楠3*
(1. 文件检验鉴定公安部重点实验室(中国刑警学院), 辽宁 沈阳 100035;2. 浙江警察学院 刑事科学技术系, 浙江 杭州 310053; 3. 司法部司法鉴定科学技术研究所, 上海 200063)
为了使用快速、无损的方法区分激光打印文件使用的墨粉种类,利用高光谱成像技术结合化学计量法对6种激光打印墨粉的光谱数据进行建模和种类鉴别的研究。利用可见-近红外高光谱成像仪采集400~1 000 nm波段内的光谱数据,采用Savitzky Golay 平滑、标准化、多元散射校正和标准正态变量变换4种方法分别对光谱数据进行预处理,而后分别建立随机森林(RF)、K最近邻(KNN)、支持向量机(SVM)、偏最小二乘判别分析(PLS-DA)和簇类独立软模式(SIMCA)模型,进而实现激光打印墨粉的种类鉴别。利用准确率、拒识率和误识率3个指标作为模型评价标准。实验结果显示,SVM和PLS-DA模型的效果最佳,准确率为100%,拒识率和误识率为0。基于可见-近红外高光谱成像技术可以实现激光打印墨粉的快速种类鉴别。
高光谱图像; 墨粉种类鉴别; 化学计量法; 支持向量机; 偏最小二乘判别分析
1 引 言
近年来,计算机技术和电子化办公的全面推广大大提升了打印文件在社会生活中的使用频率,刑事案件与民事纠纷中涉及打印文件的情况也与日俱增。印刷技术的不断发展致使伪造打印文件的成本明显降低,仿真程度却逐步提升,鉴别难度也不断增大。因此,伪造打印文件的案件数目不断攀升,造假的对象包括商业合同、银行票据、证件门票等,对社会经济活动造成极大的危害。
激光打印墨粉的种类鉴别是变造文件和伪造文件检验的主要方法之一,也是近年来文件检验学者的研究热点。许可等[1]利用激光显微拉曼光谱仪对30种激光打印墨粉进行区分,最终将其分为5大类。张清华等[2]采用主成分分析和系统聚类法对31种墨粉的红外光谱进行聚类分析与建模,基于前两个主成分的墨粉样本聚类效果明显,同时在第三主成分方向上黑白与彩色激光墨粉样本获得良好的区分。罗仪文等[3]使用激光剥蚀电感耦合等离子体质谱剥蚀墨迹并检测18种元素的信号,将24个样品区分为15类,区分率为94.6%。上述文献虽已取得了相应成果,但大都是把墨粉分为若干个大类,无法做到细致、精确的区分。
高光谱图像技术集光谱检测和图像检测于一体,再结合化学计量法,能够全面而有效地分析光谱信息,目前已经广泛应用于农产品和食品检测[4-7]等诸多领域。至于文件检验领域,已经有国外学者发表了相关成果。
Brauns运用傅里叶变换的高光谱图像进行添改文件检验,准确识别了红、黑、蓝三色圆珠笔书写的添改字迹[8]。Gal等[9]运用可见-红外高光谱仪对19种不同牌型号的黑色喷墨墨水进行种类鉴别,使用主成分分析法提取光谱特征,并根据第一、二主成分权重将墨粉分为几个大类。Khan等[10]指出常规的主成分分析法在油墨光谱种类鉴别方面的应用效果不够理想,因此在此基础上提出了改进后的稀疏主成分分析法,用于区分蓝色、黑色圆珠笔油墨,准确率较常规的主成分分析提高了15%。
由此可知,当前虽然已经有学者利用高光谱图像技术鉴别打印墨粉的种类,但仅使用了主成分分析法提取光谱特征,并没有结合化学计量法,实验结果也不够精确。因此本文运用高光谱图像技术,结合化学计量法,尝试对6种激光打印墨粉进行种类鉴别,获得了较为精确的分类结果。
2 材料与方法
2.1 材料
我们收集了市场常见的3个品牌共计6种不同型号的激光打印机,均随机配置原装黑色硒鼓或墨盒,打印机和墨粉型号见表1,统一使用银河瑞雪80 g/m2复印纸,黑白打印。设计包含中文、数字和标点符号的样本文档,每台激光打印机需打印30份该文档作为实验样本。为保证样本的随机性和连续性,样本的收集工作分6次完成,每次每台打印机打印5份样本,每批样本的打印间隔为一周,历时5周,共收集到180张实验样本。

表1 激光打印机信息列表
2.2 高光谱图像数据采集
高光谱图像采集系统主要包括可见-近红外成像光谱仪(HyperSpec VNIR)、CCD镜头、150 W卤素灯和线性控制台。光谱范围为400~1 000 nm,光谱分辨率为1.23 nm,共计488个波段;扫描次数为20次,曝光时间为4 ms,线性控制台移动速度为3.72 mm/s。
为了消除系统光源强度分布不均匀造成的噪声和暗电流噪声,需要对光谱数据进行黑白标定[11]。采集标定白板的反射光谱W和暗电流反射光谱D,带入公式(1):
(1)
其中I是原始数据,R为标定后的高光谱数据。完成黑白标定后,从每一份样本中提取尺寸为450 mm×490 mm的感兴趣区(ROI),并利用掩膜分割前景(文字)和背景(白纸)图像,仅提取ROI内文字部分的平均光谱曲线,即为该样本的墨粉光谱曲线。每类墨粉有30份样本,其中25份作为训练集数据,5份作为预测集数据,最终得到150个训练集数据,30个预测集数据。
2.3 光谱预处理
正式开始高光谱数据分析之前,还应考虑实验样本表面不均引起的散射现象、暗电流和仪器噪声引起的光谱曲线不重复现象和基线漂移现象,以及不同样本成分之间相互干扰引起的背景因数和多重共线性等无用信息对光谱曲线的影响[12]。为了达到较好的种类鉴别模型,需要使用光谱预处理技术消除以上不良影响。本文利用Unscrambler 9.7 (CAMO, Norway)软件,对样本的光谱曲线分别进行了Savitzky Golay 平滑(S.G Smooth)、标准化(Normalize)、多元散射校正(MSC)和标准正态变量变换(SNV)4种预处理,具体结果和性能比较见下文。
2.4 建模方法
针对实验样本的光谱数据,分别建立随机森林模型(Random Forest, RF)[13-15]、K最近邻模型(K-Nearest Neighbor, KNN)[16]、支持向量机模型(Support Vector Machine, SVM)[17-19]、偏最小二乘判别分析模型(Partial Least Square-discrimination Analysis, PLS-DA)[20]和簇类独立软模式模型(Soft independent modeling of class analogy, SIMCA)[21-22]。其中,PLS-DA算法在SIMCA-P 11.5 (Umetrics AB)软件中实现,其他算法通过 Matlab R2010 (Mathworks, USA)平台中的自编代码实现。
3 实验结果与讨论
3.1 光谱数据预处理
光谱数据预处理的方法有许多,但是针对不同的光谱采集对象和建模方法,各种预处理方法的效果也不尽相同。本文选择S.G Smooth、MSC、SNV和Normalize 4种预处理方法,分别对样本的光谱数据进行预处理操作。
出于优化模型性能的目的,我们使用选定的5种建模方法,分别依据未经预处理的原始光谱数据和4种预处理方法处理后的数据建模,将分类结果的准确率作为评价标准。具体数据记录于表2,每列的最大值加粗显示。

表2 光谱数据预处理方法的性能比较
对于RF、KNN和SIMCA 3种模型,光谱数据的预处理能够在不同程度上优化分类结果:MSC和SNV的原理近似,二者处理后的数据均取得了相同的结果;Normalize方法与SNV的区别在于前者是基于光谱阵列来对一组光谱进行处理,而后者是基于光谱阵行对一条光谱进行处理,大多数情况下,后者的效果更好。
但是对于SVM和PLS-DA分类器,原始光谱数据的分类结果明显优于MSC、SNV和Normalize处理后的数据而稍逊于S.G Smooth方法,该方法是以上两种分类器的最佳预处理方法。
总之,对于不同的分类器,光谱数据是否需要预处理、适合哪种预处理方法等问题,答案均不一致。因此应普遍尝试各种预处理方法,用以构造性能最佳的分类模型。
3.2 模型的建立与评价标准
3.2.1 随机森林模型的建立
随机森林的基本思想是基于Bootstrap法每次随机抽取相同数量的样本,构成n个训练集S1,S2,…,Sn,分别对应生成n棵决策树C1,C2,…,Cn,每棵树都从M维输入数据中随机选取m(m≪M)维数据,确定最佳分裂点。每棵树尽可能地生长,最终采用投票制决定分类结果。在该模型建立过程中,通过计算袋外错误率(Out-of-bag error)确定生成树的数量n=50;m的取值通常是M的因数,通过遍历法发现,m=69时模型效果最佳。
3.2.2KNN模型的建立
KNN算法认为如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。因此,k值的确定是建模的核心问题。由于该算法的运算速度较快,因此同样选择了遍历法,k=5时获得最佳模型。
3.2.3SVM模型的建立
SVM算法在解决非线性、小样本及在高维模式识别中表现出特有优势,近年来受到诸多关注,也在不断发展。对于非线性问题,需要借助核技巧,通过一个非线性变换将输入空间对应于特征空间,使得输入空间中的超曲面模型对应于特征空间中的超平面模型,从而在特征空间中求解线性支持向量机就可以完成分类[23],此时的优化函数为:
(2)
(3)
(4)
其中K(xi,xj)是核函数;C是惩罚因子,用于实现算法复杂度和错分样本的比例的折中。常用的核函数包括线性核函数、多项式核函数、径向基核函数以及Sigmoid核函数,每个核函数都有核参数g。SVM模型的优劣,直接取决于惩罚参数C和核参数g的选择。本文采用了网格搜索法[24],初步搜索范围是:
(5)
其中k∈[-5,20],l=[3,-20],结合V重交叉验证,寻找最佳参数。实验结果证明,确定各类核函数的最佳参数后,线性核函数的分类效果明显优于其他核函数,相应的参数为C=220,g=2-4。
3.2.4 PLS-DA模型的建立
PLS-DA算法是基于PLS方法建立的样本分类变量与光谱特征间的回归模型。首先按照样本实际类别特征赋予校正集样本的分类变量值,再利用PLS回归方法对校正集样本的光谱与样本对应的分类变量进行回归分析,建立光谱特征与分类变量间的PLS模型。对于K类分类问题,每个样本的判别结果包含K个0~1之间的数值,对应每个类别;待分类样本属于判别结果大于阈值cut-offvalue的类。由此可知,预测集样本的判别结果并非只有一类,也可能同时被归为多个类别,或不属于任何类别,这类模型被称为多类方法根据实验,cut-offvalue取值0.5时,模型R2Y值为0.957,Q2值为0.849,说明模型的吻合度和预测能力都达到较高的水平。

图1PLS-DA三维分布图。(a)全部样本的PC1、PC2、PC3分布图;(b)S1、S5样本的PC1、PC2、PC3分布图;(c)S2、S3、S4样本的PC1、PC2、PC4分布图。
Fig.1PLS-DA3Dscatterplots. (a)ScatterplotsonPC1,PC2andPC3ofallthesamples. (b)ScatterplotsonPC1,PC2andPC3ofS1andS5. (c)ScatterplotonPC1,PC2andPC4ofS2,S3andS4. (Multi-classesmethod)。
图1是PLS-DA模型的三维权重分布图,其中半透明圆球为模型的95%置信区间。图1(a)是全部样本在PC1-PC3方向上的分布,大致分为3簇:S6、S1-S5、S2-S3-S4。S6样本的分布稍显零散,部分样本处于置信区间外,但仍与其他样本的距离较远,不妨碍样本的种类区分。由图1(a)可知,3簇样本间的距离较远,容易区分。若坐标系中仅显示S1和S5样本,结果见图1(b),可知二者基本可被区分,但有个别S5样本混入S1区域内,可能造成混淆。图1(c)是S2、S3、S4样本在PC1、PC2和PC4上的分布,3类样本基本可以被区分,但是S2与S3分类边界稍模糊,可能造成混淆。
3.2.5SIMCA模型的建立
SIMCA方法也是多类方法,基本原理是针对每个类进行独立的主成分分析,采用交叉验证的预测残差平方和(PRESS)值选择主成分,建立主成分回归模型,然后依据模型对未知样本分类。实验证明,显著性水平(Significancelevel)为10%时,模型效果达到最佳。
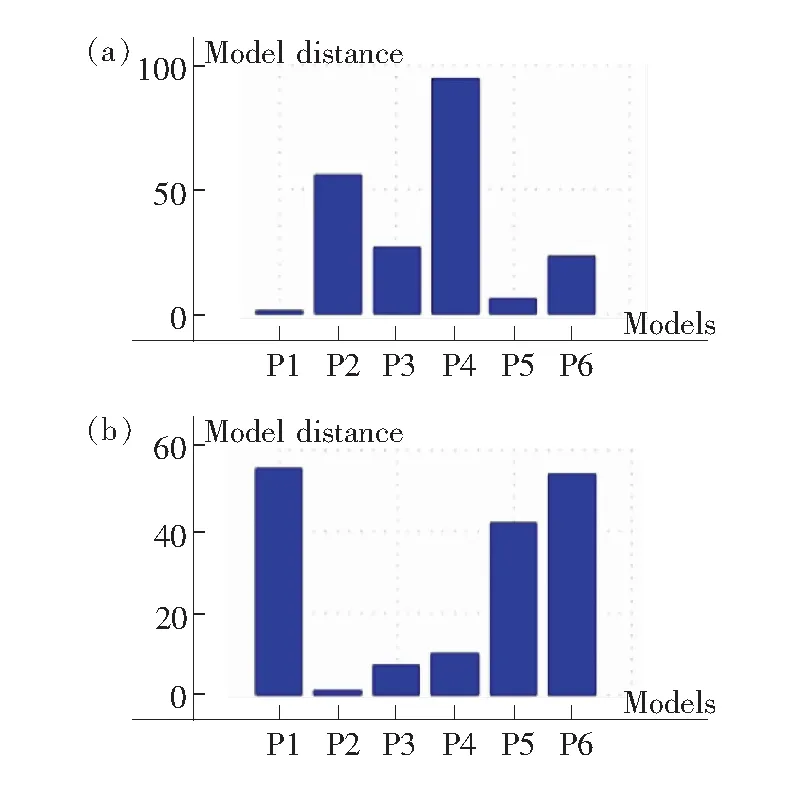
图2 各主成分模型间的距离。(a)各模型与P1模型的距离;(b)各模型与P2模型的距离。
Fig.2DistancebetweenPCAmodels. (a)DistancewithmodelP1. (b)DistancewithmodelP2.
图2是各类墨粉的主成分模型之间的距离,可视为不同种墨粉之间的区分度,数值越大说明二者越容易区分。图2(a)以S1模型为参照,可知S4与S1之间差别最大,但S5和S1的距离较小;图2(b)以S2模型为参照,可知与S2最接近的模型是S3。比较图1和图2,可以发现二者表达的信息可以相互印证。
3.2.6 模型评价标准
基于以上5种模型,我们选择准确率(Accuracy)、拒识率(Falserejectrate)和误识率(Falseacceptrate)作为模型评价依据。准确率是通过判别模型将预测集中a类样本准确判别为a类的概率,拒识率是未能将a类样本判别为a类的概率,误识率是将其他类样本错误识别成a类的概率。其中准确率越接近100%,拒识率和误识率越接近0,模型的性能越好。
3.3 激光打印墨粉光谱数据分类结果
为了建立墨粉光谱曲线与墨粉种类之间的关系,我们分别建立了RF、KNN、SVM、PLS-DA和SIMCA模型,并运用准确率、拒识率和误识率3个参数分析判别结果。前文提到每类墨粉采集了30份光谱数据样本,每次建模时都从中随机抽取25份作为建模集,剩余5份作为预测集。照此方案,5种分类算法均运行40次,所有结果的平均值作为该方法分类能力的体现,具体数据记录于表3。
RF、KNN和SVM均属于单一类别(Single-class)分类器,错误分类的样本既是被拒识,又是被误识,因此拒识率等于误识率。通过表3的数据可知,RF模型的准确率虽已达到90%,但仍是5种分类模型中表现最差者。KNN模型性能略优于RF,但是不如SVM和PLS-DA——准确率均为100%,而且拒识率和误识率均为0。
PLS-DA和SIMCA作为多类模型,拒识率和误识率则不一定相同。比较二者的分类结果,可知虽然SIMCA的准确率较之RF和KNN有显著提高,但是误识率与RF相同。这与SIMCA的建模方法有关——对于多维数据,不同类别的子空间非常接近,形成不必要的重叠(Overlapping),导致一个样本被同时判定为几类墨粉。
错分样本原本归属的类别与分类器给出的类别为易混淆墨粉类别。表3中的记录说明RF、KNN和SIMCA分类器错分的样本均集中在S1-S5和S2-S3之间,与PLS-DA模型和SIMCA模型展示的结果吻合,更进一步说明了以上两组样本的高光谱数据特征较为接近,区分难度大于其他种类。其中S1、S2和S3均是佳能LBP系列打印机原装墨粉,而S5是惠普5100原装墨粉。由此可知不同品牌的激光打印墨粉也有可能具备相似的光谱属性,因此在文件检验鉴定工作中,打印机品牌不足以也不应该作为区分墨粉种类的依据。

表3 激光打印墨粉光谱预测集分类结果
4 结 论
利用高光谱图像技术,结合化学计量法,能够有效完成激光打印墨粉的种类鉴别。通过高光谱成像仪提取400~1 000nm波段的光谱信息,并据此建立了RF、KNN、SVM、PLS-DA和SIMCA统计模型,取得了较为理想的分类结果。比较分析结果表明,SVM和PLS-DA模型的效果最佳,准确率为100%,拒识率和误识率为0;SIMCA、KNN和RF的效果依次变差。
为了最大程度地优化分类模型,建模之前需要通过实验确定是否需要进行光谱数据预处理以及应当选择何种预处理方法。
对于成分接近、光谱属性相似的激光打印墨粉,利用高光谱数据分类时仍有可能出现混淆的现象,该问题的解决方法有待进一步探索。
[1] 许可, 梁鲁宁, 连园园. 线聚焦显微激光拉曼光谱技术区分激光打印墨粉 [J]. 中国司法鉴定, 2011(2):27-30. XU K, LIANG L N, LIAN Y Y. Classification toners of laser printers with micro Raman spectroscopy [J].Chin.J.ForensicSci., 2011(2):27-30. (in Chinese)
[2] 张清华, 杨旭, 罗仪文, 等. 红外光谱结合化学计量学方法在激光打印原装黑色墨粉分析中的应用研究 [J]. 中国司法鉴定, 2014(5):28-33. ZHANG Q H, YANG X, LUO Y W,etal.. Analysis of original black toner of laser printers by infrared spectroscopy coupled with chemometrics [J].Chin.J.ForensicSci., 2014(5):28-33. (in Chinese)
[3] 罗仪文, 徐彻, 张清华, 等. LA-ICP-MS对激光打印原装黑色墨粉元素成分的分析 [J]. 中国司法鉴定, 2015(1):27-32. LUO Y W, XU C, ZHANG Q H,etal.. Discrimination of original black toner by laser ablation inductively coupled plasma mass spectrometry [J].Chin.J.ForensicSci., 2015(1):27-32. (in Chinese)
[4] 冯愈钦, 吴龙国, 何建国, 等. 基于高光谱成像技术的长枣不同保藏温度的可溶性固形物含量检测方法 [J]. 发光学报, 2016, 37(8):1014-1022. FENG Y Q, WU L G, HE J G,etal.. Detection method of soluble solid of jujube at different preservative temperature based on hyper-spectral imaging technology [J].Chin.J.Lumin., 2016, 37(8):1014-1022. (in Chinese)
[5] 刘燕德, 邓清. 基于高光谱成像技术的脐橙叶片的叶绿素含量及其分布测量 [J]. 发光学报, 2015, 36(8):957-961. LIU Y D, DENG Q. Measurement of chlorophyll distribution in navel orange leaves based on hyper-spectral imaging technique [J].Chin.J.Lumin., 2015, 36(8):957-961. (in Chinese)
[6] 吴龙国, 何建国, 刘贵珊, 等. 基于NIR高光谱成像技术的长枣虫眼无损检测 [J]. 发光学报, 2013, 34(11):1527-1532. WU L G, HE J G, LIU G S,etal.. Non-destructive detection of insect hole in jujube based on near-infrared hyperspectral imaging [J].Chin.J.Lumin., 2013, 34(11):1527-1532. (in Chinese)
[7] 鲍一丹, 陈纳, 何勇, 等. 近红外高光谱成像技术快速鉴别国产咖啡豆品种 [J]. 光学 精密工程, 2015, 23(2):349-355. BAO Y D, CHEN N, HE Y,etal.. Rapid identification of coffee bean variety by near infrared hyperspectral imaging technology [J].Opt.PrecisionEng., 2015, 23(2):349-355. (in Chinese)
[8] BRAUNS E B, DYER R B. Fourier transform hyperspectral visible imaging and the nondestructive analysis of potentially fraudulent documents [J].Appl.Spect., 2006, 60(8):833-840.
[10] KHAN Z, SHAFAIT F, MIAN A. Automatic ink mismatch detection for forensic document analysis [J].PatternRecognit., 2015, 48(11):3615-3626.
[11] EDELMAN G J, GASTON E, VAN LEEUWEN T G,etal.. Hyperspectral imaging for non-contact analysis of forensic traces [J].ForensicSci.Int., 2012, 223(1-3):28-39.
[12] RINNAN Å, VAN DEN BERG F, ENGELSEN S B. Review of the most common pre-processing techniques for near-infrared spectra [J].TrACTrendsAnalyt.Chem., 2009, 28(10):1201-1222.
[13] BREIMAN L. Random forests [J].Mach.Learn., 2001, 45(1):5-32.
[14] BREIMAN L, CUTLER A. Random forests [EB/OL]. (2004-06-06) [2016-04-15]. http://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm.
[15] LIAW A, WIENER M. Classification and regression by random forest [J].RNews, 2002, 2-3:18-22.
[16] GUO G D, WANG H, BELL D,etal..KNNModel-basedApproachinClassification[M]. Berlin Heidelberg: Springer, 2003:986-996.
[17] DEVOS O, RUCKEBUSCH C, DURAND A,etal.. Support vector machines (SVM) in near infrared (NIR) spectroscopy: focus on parameters optimization and model interpretation [J].Chemom.Intell.Labor.Syst., 2009, 96(1):27-33.
[18] BELOUSOV A I, VERZAKOV S A, VON FRESE S J. A flexible classification approach with optimal generalisation performance: support vector machines [J].Chemom.Intell.Labor.Syst., 2002, 64(1):15-25.
[19] SANTOS F, GUYOMARC'H P, BRUZEK J. Statistical sex determination from craniometrics: comparison of linear discriminant analysis, logistic regression, and support vector machines [J].ForensicSci.Int., 2014, 245:204.e1-e8.
[20] BARKER M, RAYENS W. Partial least squares for discrimination [J].J.Chemom., 2003, 17(3):166-173.
[21] WOLD S. Pattern recognition by means of disjoint principal components models [J].PatternRecognit., 1976, 8(3):127-139.
[22] MUEHLETHALER C, MASSONNET G, ESSEIVA P. Discrimination and classification of FTIR spectra of red, blue and green spray paints using a multivariate statistical approach [J].ForensicSci.Int., 2014, 244:170-178.
[23] 李航. 统计学习方法 [M]. 北京: 清华大学出版社, 2012:116. LI H.StatisticalLearningMethod[M]. Beijing: Tsinghua University Press, 2012:116. (in Chinese)
[24] HSU C W, CHANG C C, LIN C J. A practical guide to support vector classification [EB/OL].(2016-05-19) [2016-06-26]. http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf.

刘猛(1988-),男,山东东平人,硕士,助教,2014年于中国公安大学获得硕士学位,主要从事物证鉴定方面的研究。

E-mail: liumeng@zjjcxy.cn王楠(1988-),女,福建福州人,硕士,工程师,2013年于华东政法大学获得硕士学位,主要从事文件检验和痕迹检验方面的研究。

E-mail: wangn@ssfjd.cn申思(1989-),女,河南开封人,硕士,助教,2011年于中国刑事警察学院获得硕士学位,主要从事文件检验鉴定方面的研究。
E-mail: shengsi@zjjcxy.cn
Rapid Identification of Black Toner Variety by Visible and Near Infrared Hyperspectral Imaging Technology
LIU Meng1,2, SHEN Si1,2*, WANG Nan3*
(1.KeyLaboratoryofTheQuestionedDocumentExamination(ChinaCriminalPoliceUniversity),MinistryofPublicSecurityofChina,Shenyang100035,China;2.DepartmentofForensicScience,ZhejiangPoliceCollege,Hangzhou310053,China;3.InstituteofForensicScience,MinistryofJustice,PRC,Shanghai200063,China)
In order to develop rapid and non-destructive method for identification of laser printer toner, six kinds of black toner were identified rapidly by combining hyperspectral imaging technique and five kinds of statistical learning method. Method: a visible and near-infrared hyperspectral imaging system covering the spectral range of 400-1 000 nm was set up to capture hyperspectral images of toner samples. Savitzky Golay smooth, normalize, multiple scatter correction and standard normal varite were applied as preprocessing method. After that, five statistical learning methods, including Random Forest (RF), K-nearest Neighbor (KNN), Support Vector Machine (SVM), Partial Least Square-discriminant analysis (PLS-DA) and Soft Independent Modeling of Class Analogy (SIMCA) were applied to establishment of discriminant models based on the full spectra. The properties of discriminant models were compared and valued by three parameters, precision, false reject rate (FRR) and false accept rate (FAR). Result: Among all discriminant models, the SVM and PLS-DA model show the best identification result, the precision is 100%, FRR and FAR are both 0. Conclusion: black toner could be identified by visible and near-infrared hyperspectral imaging technique combined with statistical learning method rapidly.
hyperspectral imaging; toner identification; statistical learning method; SVM; PLS-DA
1000-7032(2017)05-0662-07
2016-11-09;
2016-12-15
文件检验鉴定公安部重点实验室(中国刑事警察学院)课题(2015KFKT09); 浙江警察学院校局合作项目(2016XJY014)资助 Supported by Key Laboratory of The Questioned Document Examination(China Criminal Police University), Ministry of Public Security of China(2015KFKT09); School and Bureau Cooperation Program of Zhejiang Police College(2016XJY014)
O433.4; DF794.2
A
10.3788/fgxb20173805.0662
*CorrespondingAuthors,E-mail:shengsi@zjjcxy.cn;wangn@ssfid.cn
